

代理(Agent)工作的 Token 帳單正在失控:多步驟工具呼叫、長上下文規劃、以及延伸的輸出,讓原本看似低廉的單價 Token 變成非常昂貴的月度帳單。業界的應對方式——串起更長的推理軌跡來衝高基準測試分數——只會讓經濟效益更差,而不是更好。
Ling-2.6-flash 是另一種模型的思維。它採用混合線性注意力架構(Hybrid Linear Attention),在 4× H20 硬體上可達到每秒 340 個 token,提供 2.2 倍於 Nemotron-3-Super 的預填充吞吐量,並且完成完整的 Artificial Analysis Intelligence Index 只需約 1500 萬個輸出 token——大約是 Nemotron-3-Super 所消耗的 十分之一。簡而言之:Ling-2.6-flash 是一個 104B MoE 模型(7.4B 活躍參數),擁有 256K 上下文視窗,專為代理工作負載最佳化,在這些場景中,速度、成本與穩定性遠比單一頭條基準測試來得重要。現已於 Novita AI 上線。
什麼是 Ling-2.6-flash?
Ling-2.6-flash 是一種稀疏混合專家語言模型,總參數 104B,每次前向傳播的活躍參數為 7.4B。由 Ling 團隊(InclusionAI)開發,定位為「即時」類別模型——專為生產環境中 token 消耗與延遲是實際成本的代理部署而設計。
- 總參數 104B / 活躍參數 7.4B — MoE 架構,高稀疏性
- 256K token 上下文視窗 — 透過混合線性注意力實現
- 在 4× H20(TP=4)上可達 340 tokens/s 的峰值吞吐量
- 混合 1:7 MLA + Lightning 線性注意力 — 長上下文下吞吐量提升 4 倍
- 頂尖代理基準測試 — BFCL-V4(67.04)、PinchBench(81.10)、IFBench(58.10)、Multi-IF Turn-3(74.85)領先
- BF16、FP8 與 INT4 變體 — 計劃透過 Linghe 開源釋出
- 經過生產環境驗證 — 上線幾天內在 OpenRouter 上每日處理約 1000 億個 token
混合線性架構:Ling-2.6-flash 如何在規模下變得更快
多數 MoE 模型將標準 Transformer 注意力與稀疏 FFN 層配對。Ling-2.6-flash 則將大部分注意力替換為 Lightning 線性層,形成 1:7 MLA + Lightning 線性混合。注意力成本隨上下文長度線性增長而非二次增長——這對於長時間的代理會話至關重要。
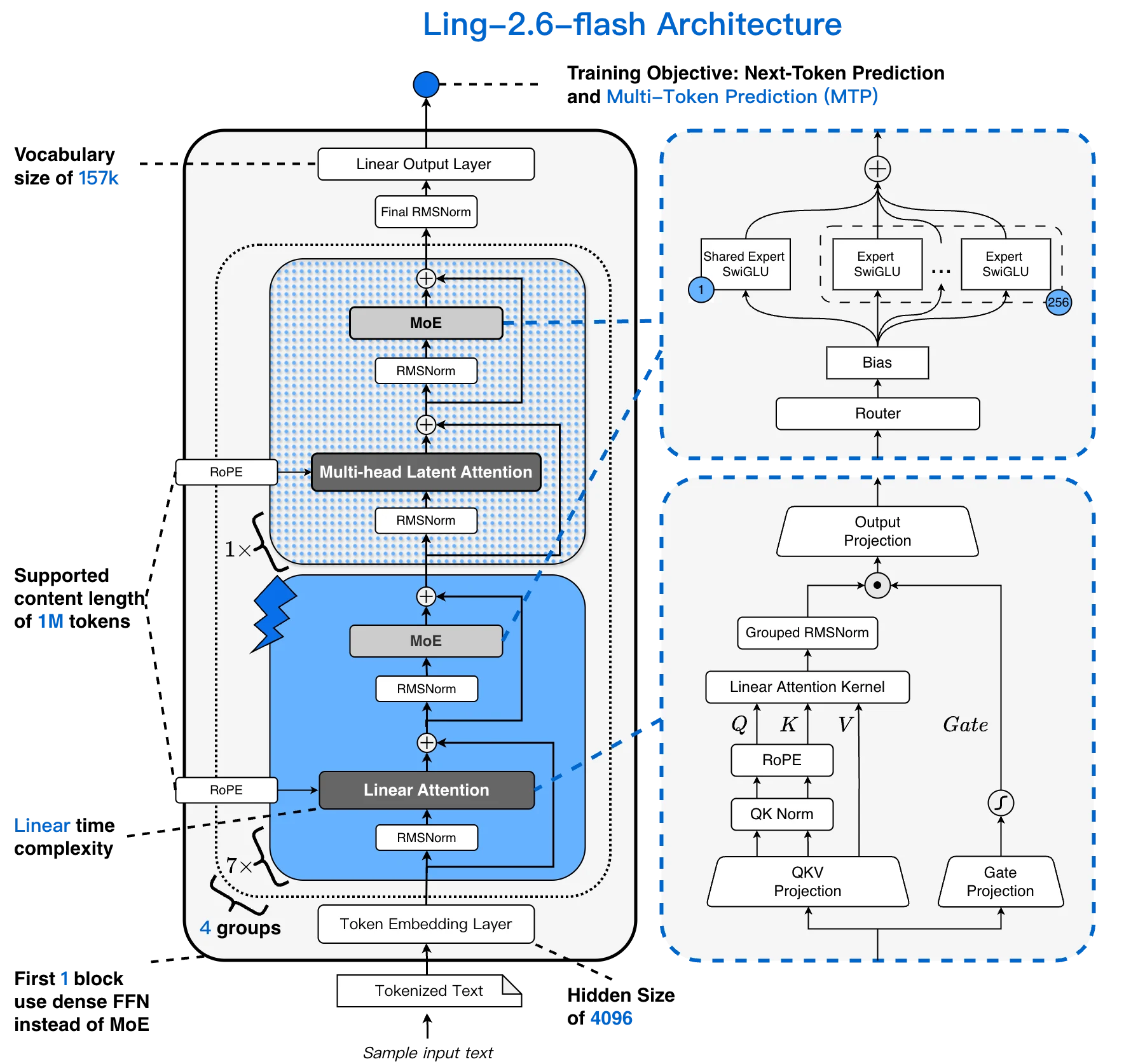
Ling-2.6-flash 架構:15.7 萬詞彙量,256K 上下文,1:7 MLA + Lightning 線性混合,256 個可選擇的專家 [來源:Ling 官方部落格]
解碼吞吐量:長輸出下最高可達 4.38 倍
在 4× H20-3e(TP=4,批次大小 32)上,Ling-2.6-flash 在 65,536 token 輸出長度下達到相對於 GLM-4.5-Air 基線的 4.38 倍標準化解碼吞吐量。Qwen3.5-122B-A10B 為 1.90 倍;Nemotron-3-Super 為 3.37 倍。隨著任務輸出長度增加,差距持續擴大。
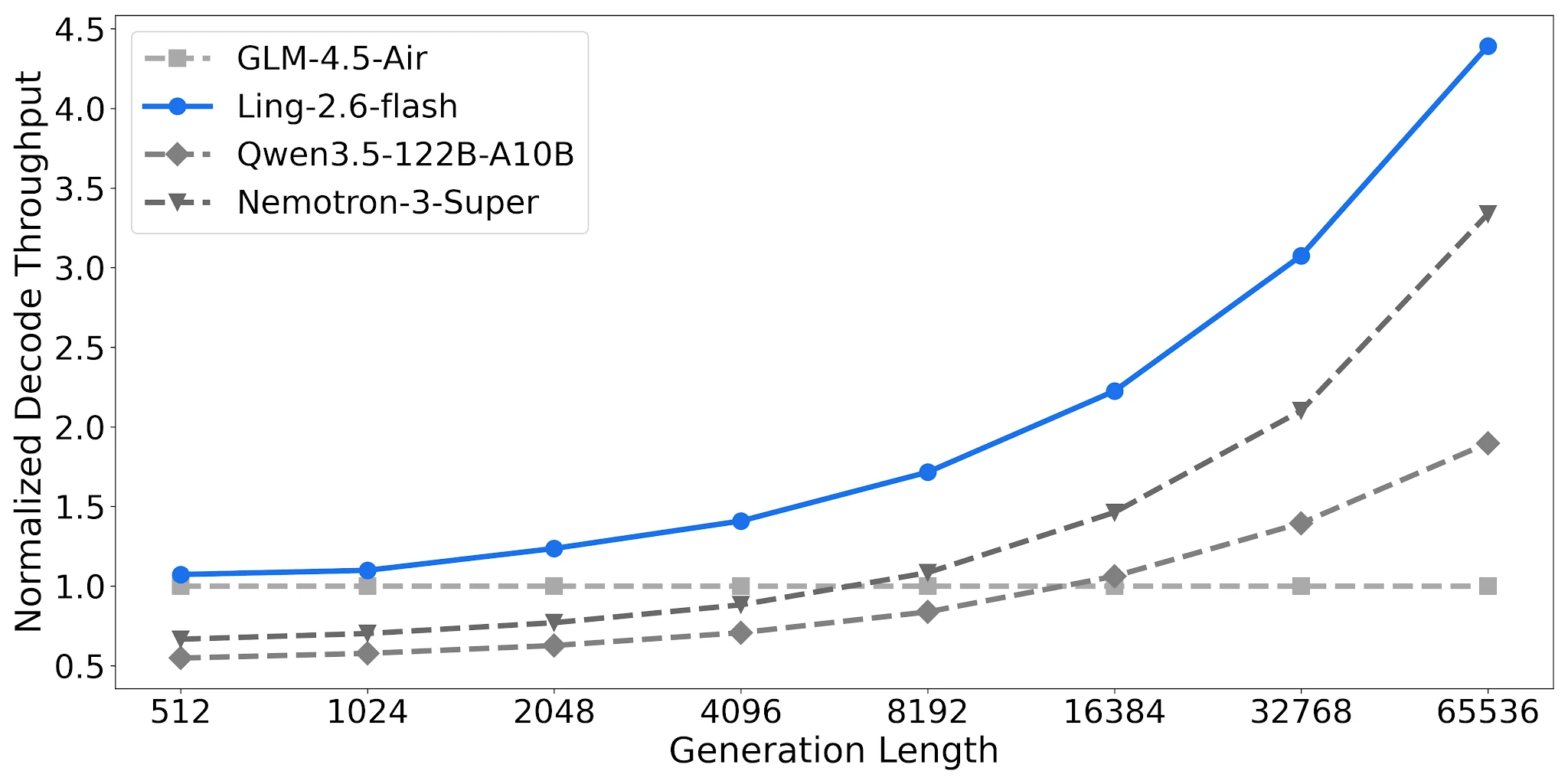
解碼吞吐量比較,4× H20-3e,TP=4,Batch=32 [來源:Ling 官方部落格]
預填充吞吐量:長上下文下為 Nemotron 的 2.2 倍
Ling-2.6-flash 在 65K 上下文下達到約 4.68 倍標準化預填充吞吐量,而 Nemotron-3-Super 約為 2.12 倍。對於具有長系統提示詞的 RAG 管道與多輪代理,這直接降低了每次請求的成本。
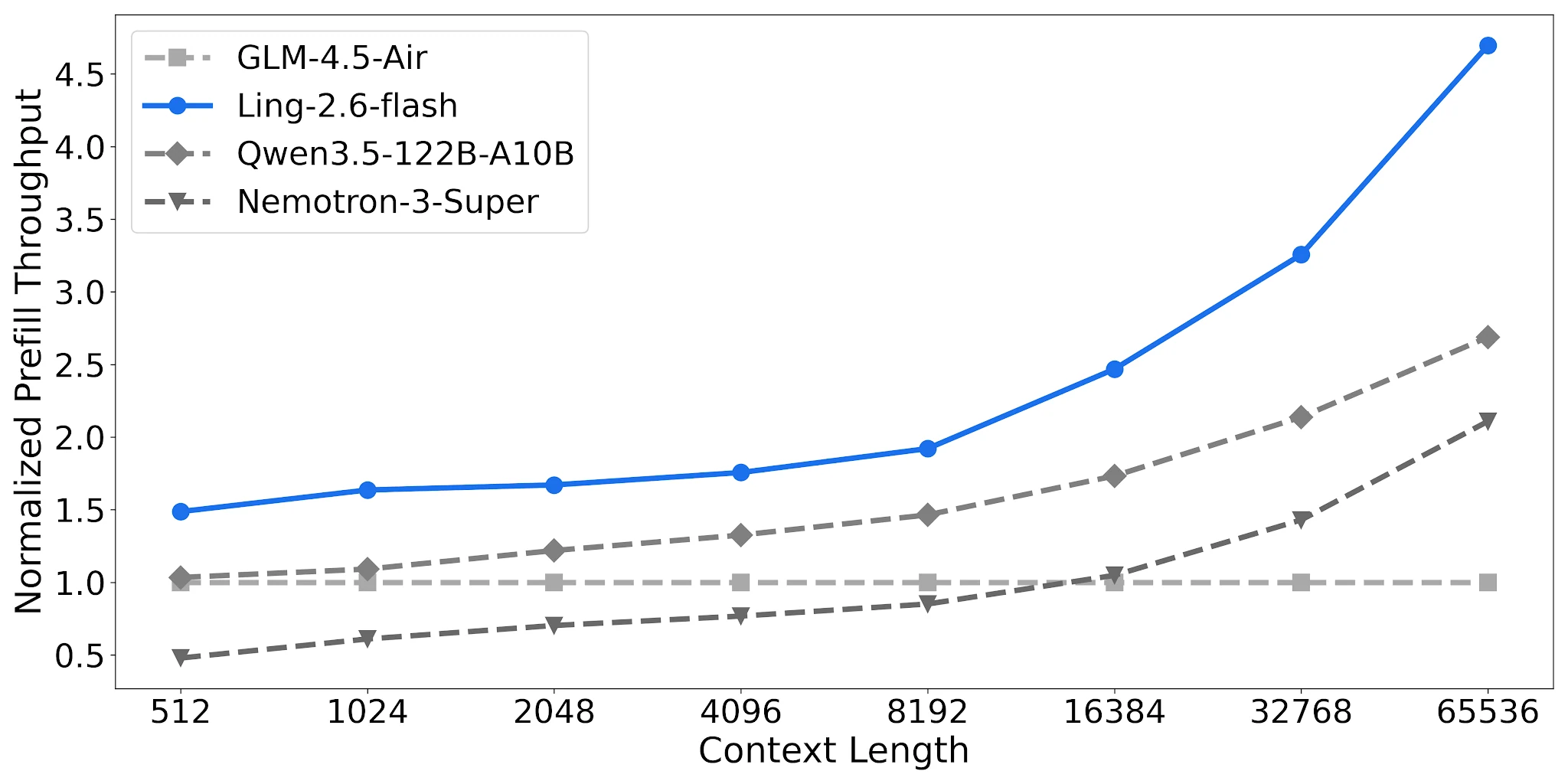
預填充吞吐量比較,4× H20-3e,TP=4,Batch=32 [來源:Ling 官方部落格]
Token 效率:解決相同基準測試只需 1500 萬 vs 1.1 億個 token
在完整的 Artificial Analysis Intelligence Index 上,Ling-2.6-flash 使用約 1500 萬個輸出 token。Nemotron-3-Super 則使用 1.1 億個以上——約為 7 倍——用於一個在代理任務上分數更低的模型。對於每天執行數十萬個代理任務的應用程式,這個差距直接反映在成本預算上。
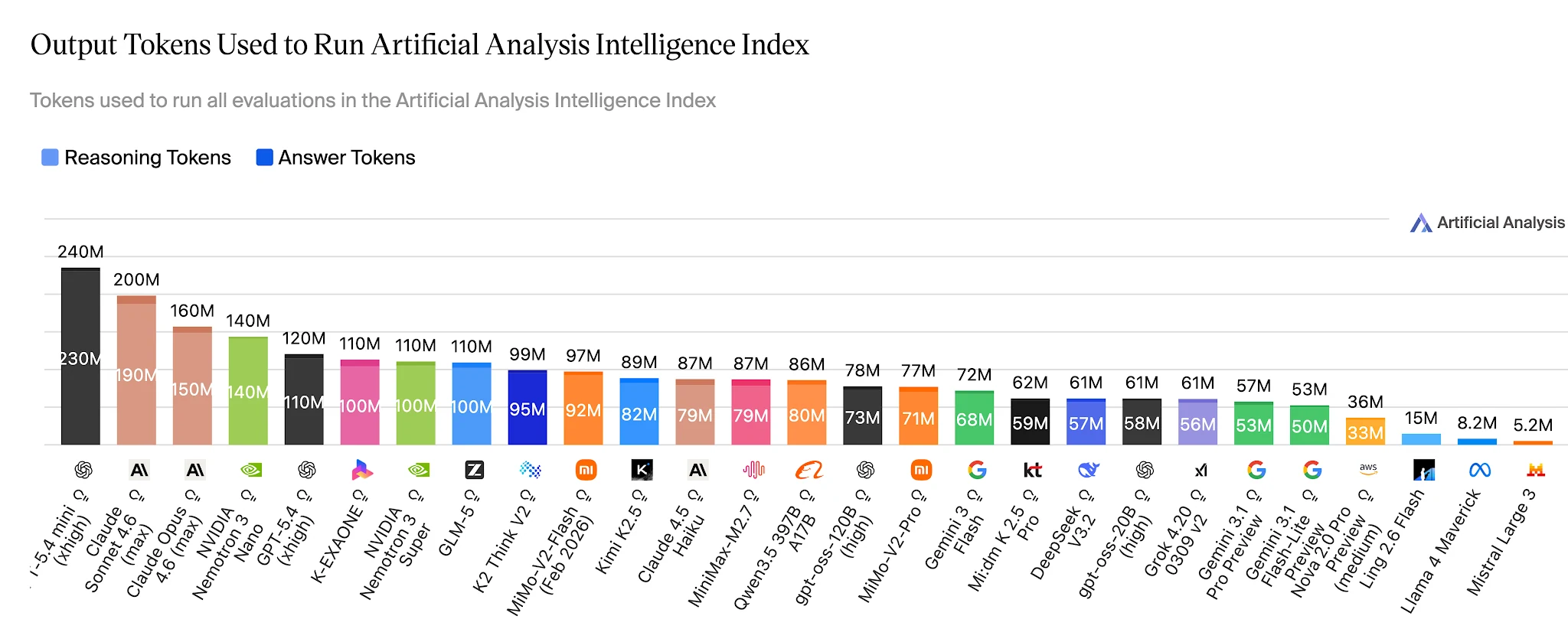
完成 Artificial Analysis Intelligence Index 所需的輸出 token——Ling 2.6 Flash:約 1500 萬 vs Nemotron-3-Super:約 1.1 億+ [來源:Artificial Analysis]
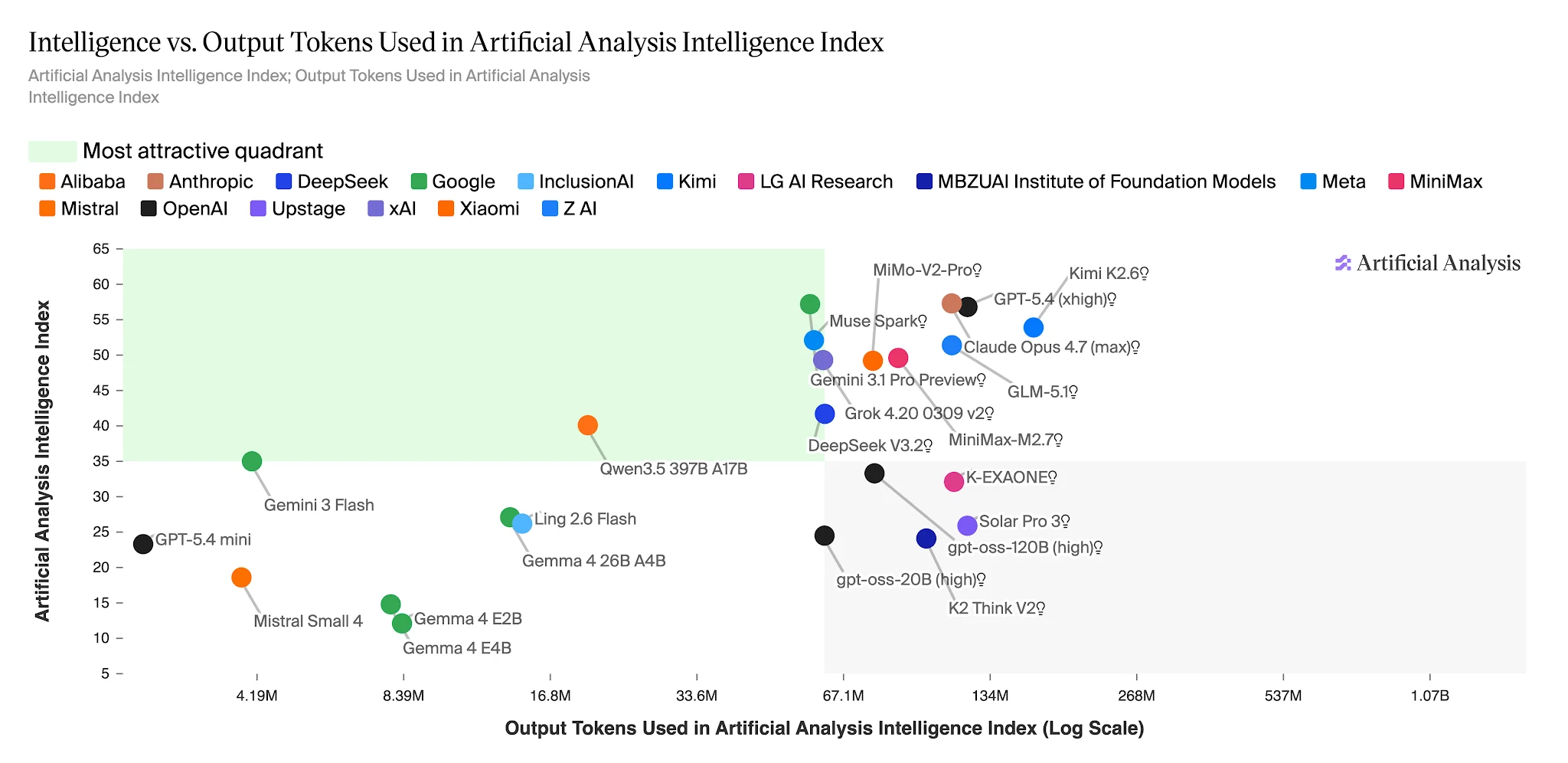
智慧 vs. 輸出 Token:Ling 2.6 Flash 落在高效區 [來源:Artificial Analysis]
基準測試結果:Ling-2.6-flash 領先的領域
在 7 個類別的 19 項基準測試中,與 Qwen3-57B-A14B、Qwen3.5-122B-A10B、GLM-4.5-Air、Nemotron-3-Super 和 MiniMax-M1-80k 進行比較:
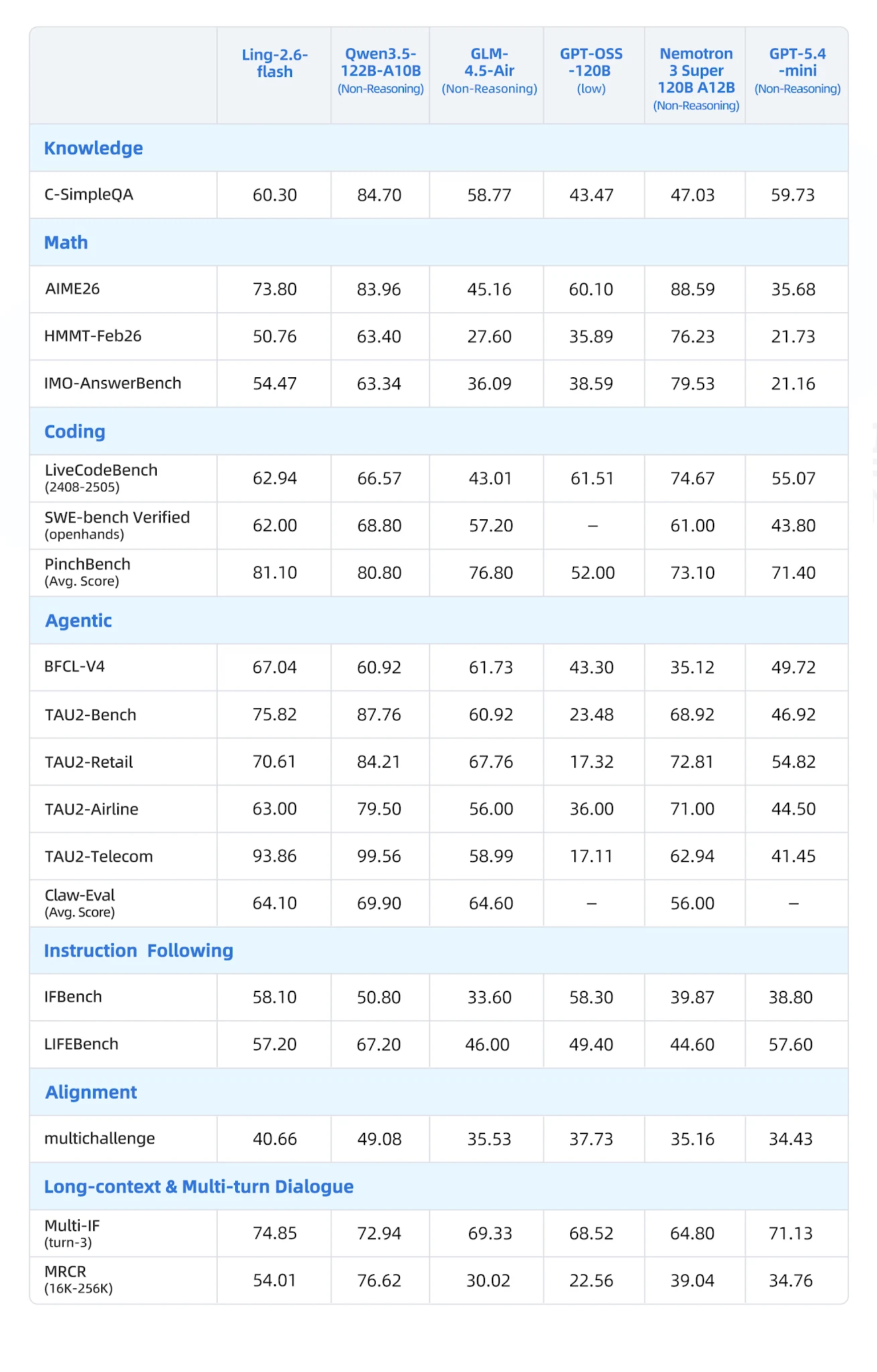
全面基準測試表 [來源:Ling 官方部落格]
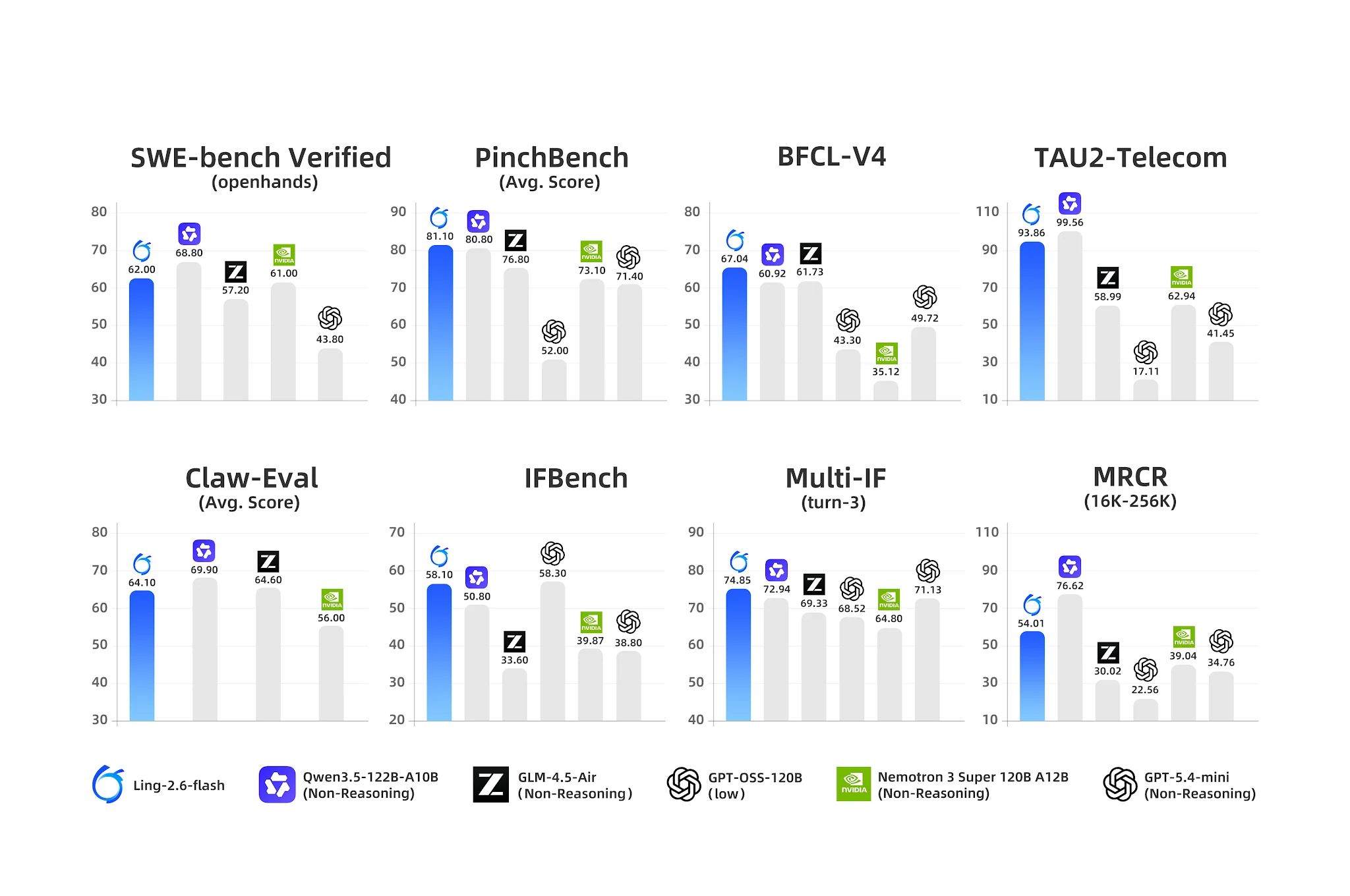
代理基準測試:Ling-2.6-flash 在工具使用與多輪 IF 方面領先 [來源:Ling 官方部落格]
Ling-2.6-flash 領先的地方
- BFCL-V4(函式呼叫): 67.04 — 最接近的競爭對手 Nemotron 為 35.12(差距 90%)
- PinchBench(代理任務): 81.10 vs. Nemotron 73.10
- IFBench(指令遵循): 58.10
- Multi-IF Turn-3: 74.85 — 強大的多輪指令持續性
- LongBench-v2: 54.80 — 長上下文類別中最佳
- CCAlignBench(中文): 7.44 — 所有測試模型中最高
其他模型領先的地方
- 數學(AIME 2025、MATH-500): Nemotron-3-Super 與 Qwen3 推理變體勝出
- 程式碼(LiveCodeBench): Qwen3.5-122B-A10B 領先;Ling 具有競爭力但非頂尖
- GPQA-Diamond: GLM-4.5-Air 與 Nemotron 分數較高
快速比較表
| 模型 | 活躍參數 | BFCL-V4 ↑ | PinchBench ↑ | 65K 解碼 TP ↑ | 輸出 Token ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7.4B | 67.04 | 81.10 | 4.38× | ~1500 萬 |
| Nemotron-3-Super | 49B 總計 | 35.12 | 73.10 | 3.37× | ~1.1 億+ |
| Qwen3.5-122B-A10B | 10B | — | 78.20 | 1.90× | — |
| GLM-4.5-Air | — | 50.67 | 73.30 | 1.00×(基線) | — |
| MiniMax-M1-80k | — | 44.07 | 75.70 | — | — |
| Qwen3-57B-A14B | 14B | 52.32 | 76.30 | — | — |
由 Novita AI 支援,存取 Ling-2.6-flash
Ling-2.6-flash 現已可用。在 OpenRouter 上試用——免費層級,無需設定:
立即開始使用 OpenRouter — inclusionai/ling-2.6-flash:free。提供免費層級,相容 OpenAI 的客戶端無需修改程式碼。
Ling-2.6-flash 可與 LangChain、LlamaIndex 和 OpenAI Agent SDK 搭配使用——無需適配器或程式碼變更。支援串流、函式呼叫和結構化輸出。可將其與 Novita Agent Sandbox 結合,在推論之外提供安全的程式碼執行環境。
社群怎麼說
Ling-2.6-flash 在正式揭曉前以 “Elephant Alpha” 的名稱在 OpenRouter 上線。幾天之內就處理了約 1000 億個 token,並在未經任何公告的情況下登上了平台熱門排行榜。
「Ling-2.6-flash 有點工作導向。比大型模型精簡約 75%。還是有些模板化,但寫程式碼時——幾乎完美。」
— 早期使用者在 X/Twitter 上
「剛剛在幾個 llama.cpp 程式碼任務上試了 Ling-2.6-flash。比預期好很多。可靠地處理工具呼叫,而且不會用不必要的解釋填充輸出。」
— 早期使用者在 Reddit 上
「精簡 75%」的評論正好對應了 Artificial Analysis 基準測試中 1500 萬 vs. 1.1 億的 token 差距。訓練目標似乎獎勵直接、完整的答案——在生產規模下,這個特性會在成本節省上產生複合效應。
誰應該使用 Ling-2.6-flash?
- ✅ 高流量函式呼叫 / 工具使用代理 — BFCL-V4 大幅領先
- ✅ 多輪代理會話 — 在長對話歷史中表現一致
- ✅ 長上下文 RAG 管道 — 256K token 視窗,線性成本預填充
- ✅ 成本敏感的生產部署 — 輸出 token 約為 Nemotron 的 1/7
- ✅ 中文應用 — CCAlignBench 最高分
- ❌ 數學競賽 / AIME 風格推理 — 請改用 Nemotron 或 Qwen3 推理變體
- ❌ 追求最高程式碼基準測試分數 — Qwen3.5-122B-A10B 領先
開始使用
Ling-2.6-flash 現已可用。透過 OpenRouter 模型頁面 存取——免費層級立即生效,相容 OpenAI 的客戶端無需修改程式碼。Agent Sandbox 也可同時使用,適合需要結合推論與安全執行的團隊。
常見問題
什麼是 Ling-2.6-flash?
Ling-2.6-flash 是一個 104B MoE 模型(7.4B 活躍參數),採用混合線性注意力,256K 上下文視窗,推論速度最高可達 340 tokens/s——專為代理工作負載最佳化。
如何透過 API 使用 Ling-2.6-flash?
使用 OpenRouter 搭配您的 Novita AI API 金鑰(BYOK)。在 openrouter.ai/settings/integrations 新增您的 Novita 金鑰,選擇 Novita 作為提供者,並透過相容 OpenAI 的端點將請求路由到 inclusionai/ling-2.6-flash:free:
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer YOUR_OPENROUTER_API_KEY
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "YOUR_NOVITA_API_KEY"
},
"messages": [{"role": "user", "content": "Hello!"}]
}
完整設定請參閱 OpenRouter BYOK 文件。使用 BYOK 時,OpenRouter 不收取任何費用——您直接依免費層級價格支付給 Novita。
Ling-2.6-flash 與 Nemotron-3-Super 比較如何?
Ling 在 BFCL-V4(67.04 vs 35.12)、PinchBench(81.10 vs 73.10)上領先,且輸出 token 約少 7 倍。Nemotron 在數學方面領先。對於代理工作負載,Ling-2.6-flash 是更經濟的選擇。
上下文視窗是多少?
256K token(262,144),由於混合線性注意力,預填充成本為線性。長 RAG 與多輪會話可有效擴展。
Ling-2.6-flash 是開源的嗎?
BF16、FP8 和 INT4 變體以及 Linghe 核心計劃開源釋出。時間表待定——請查看 Ling 官方網站 獲取更新。
您可能也喜歡
- Kimi K2.6:開源代理,可連續 13 小時編寫程式碼 — 1T MoE 模型,256K 上下文,SWE-Bench Pro 得分 58.6%
- Novita AI 上的 GLM-5.1 API:長時程代理模型 — 在 SWE-Bench Pro 上以 58.4 分領先,可自主執行長達 8 小時的程式碼任務
- 2026 年開源模型的頂尖推論 API 提供者 — 比較 Novita AI、Together AI、Fireworks、DeepInfra 和 Groq



