

- Что такое Ling-2.6-flash?
- Гибридная линейная архитектура: как Ling-2.6-flash ускоряется в масштабе
- Эффективность токенов: 15M против 110M для решения одних и тех же бенчмарков
- Результаты бенчмарков: где Ling-2.6-flash лидирует
- Краткая сравнительная таблица
- Доступ к Ling-2.6-flash на базе Novita AI
- Что говорят участники сообщества
- Кому стоит использовать Ling-2.6-flash?
- Начните работу
- Часто задаваемые вопросы
Счета за агентные токены растут как снежный ком: многошаговые вызовы инструментов, долгое планирование контекста и расширенные выходные данные превращают то, что выглядит как дешёвая цена за токен, в очень дорогой ежемесячный счёт. Ответ индустрии — удлинять цепочки рассуждений для повышения бенчмарков — делает экономику только хуже, а не лучше.
Ling-2.6-flash — это модель другого рода. Построенная на гибридной архитектуре линейного внимания, она достигает до 340 токенов/с на оборудовании 4× H20, обеспечивает в 2,2 раза большую пропускную способность prefill, чем Nemotron-3-Super, и использует всего ~15M выходных токенов для прохождения полного индекса Artificial Analysis Intelligence Index — примерно одну десятую от того, что потребляет Nemotron-3-Super. Короче говоря: Ling-2.6-flash — это MoE-модель на 104B параметров (7.4B активных) с окном контекста 256K, оптимизированная для агентных нагрузок, где скорость, стоимость и стабильность важнее одного заголовочного бенчмарка. Теперь она доступна на Novita AI.
Что такое Ling-2.6-flash?
Ling-2.6-flash — это разреженная языковая модель типа Mixture-of-Experts с 104B общих параметров и 7.4B активных параметров за прямой проход. Разработанная командой Ling (InclusionAI), она относится к категории моделей «Instant» — оптимизированных для продуктивных агентных развёртываний, где потребление токенов и задержка являются реальными затратами, а не просто заголовками бенчмарков.
- 104B общих / 7.4B активных параметров — архитектура MoE с высокой разреженностью
- Окно контекста 256K токенов — реализовано за счёт гибридного линейного внимания
- Пиковая пропускная способность 340 токенов/с на 4× H20 (TP=4)
- Гибрид 1:7 MLA + Lightning Linear внимание — в 4 раза большая пропускная способность на длинных контекстах
- Лучшие агентные бенчмарки — лидирует в BFCL-V4 (67.04), PinchBench (81.10), IFBench (58.10), Multi-IF Turn-3 (74.85)
- Варианты BF16, FP8 и INT4 — открытый исходный код планируется через Linghe
- Проверено в продакшене — ~100B токенов в день на OpenRouter в течение нескольких дней после запуска
Гибридная линейная архитектура: как Ling-2.6-flash ускоряется в масштабе
Большинство MoE-моделей сочетают стандартное внимание трансформера с разреженным FFN-слоем. Ling-2.6-flash заменяет большую часть внимания на слой Lightning Linear, создавая гибрид 1:7 MLA + Lightning Linear. Стоимость внимания растёт линейно с длиной контекста, а не квадратично — это критически важно для длительных агентных сессий.
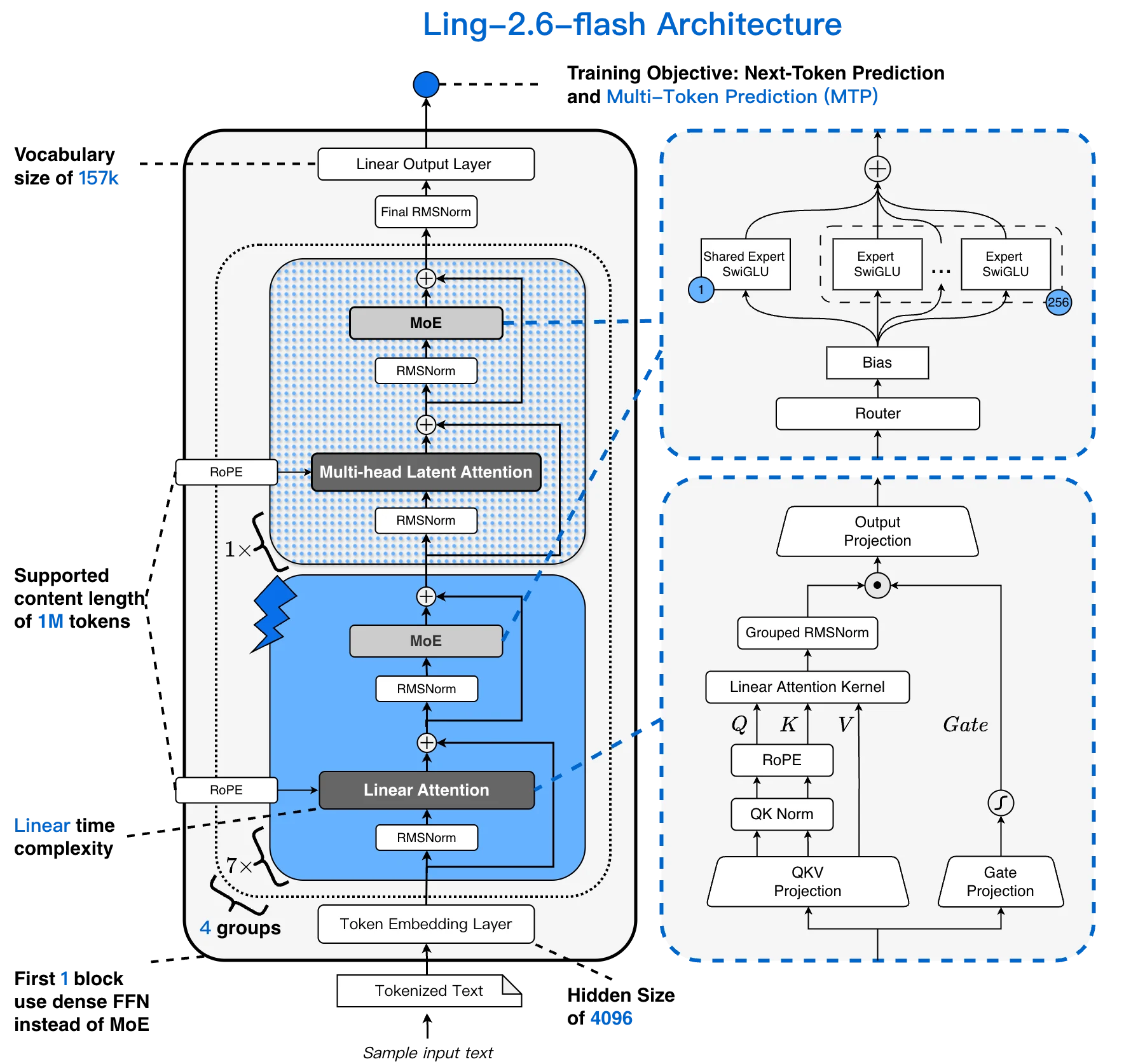
Архитектура Ling-2.6-flash: словарь 157K, контекст 256K, гибрид 1:7 MLA + Lightning Linear, 256 выбираемых экспертов [Источник: Официальный блог Ling]
Пропускная способность декодирования: до 4.38× на длинных выходах
На 4× H20-3e (TP=4, размер батча 32) Ling-2.6-flash достигает 4.38× нормализованной пропускной способности декодирования при длине выхода 65,536 токенов относительно базовой линии GLM-4.5-Air. Qwen3.5-122B-A10B достигает 1.90×; Nemotron-3-Super — 3.37×. Разрыв увеличивается с ростом длины выходных данных задачи.
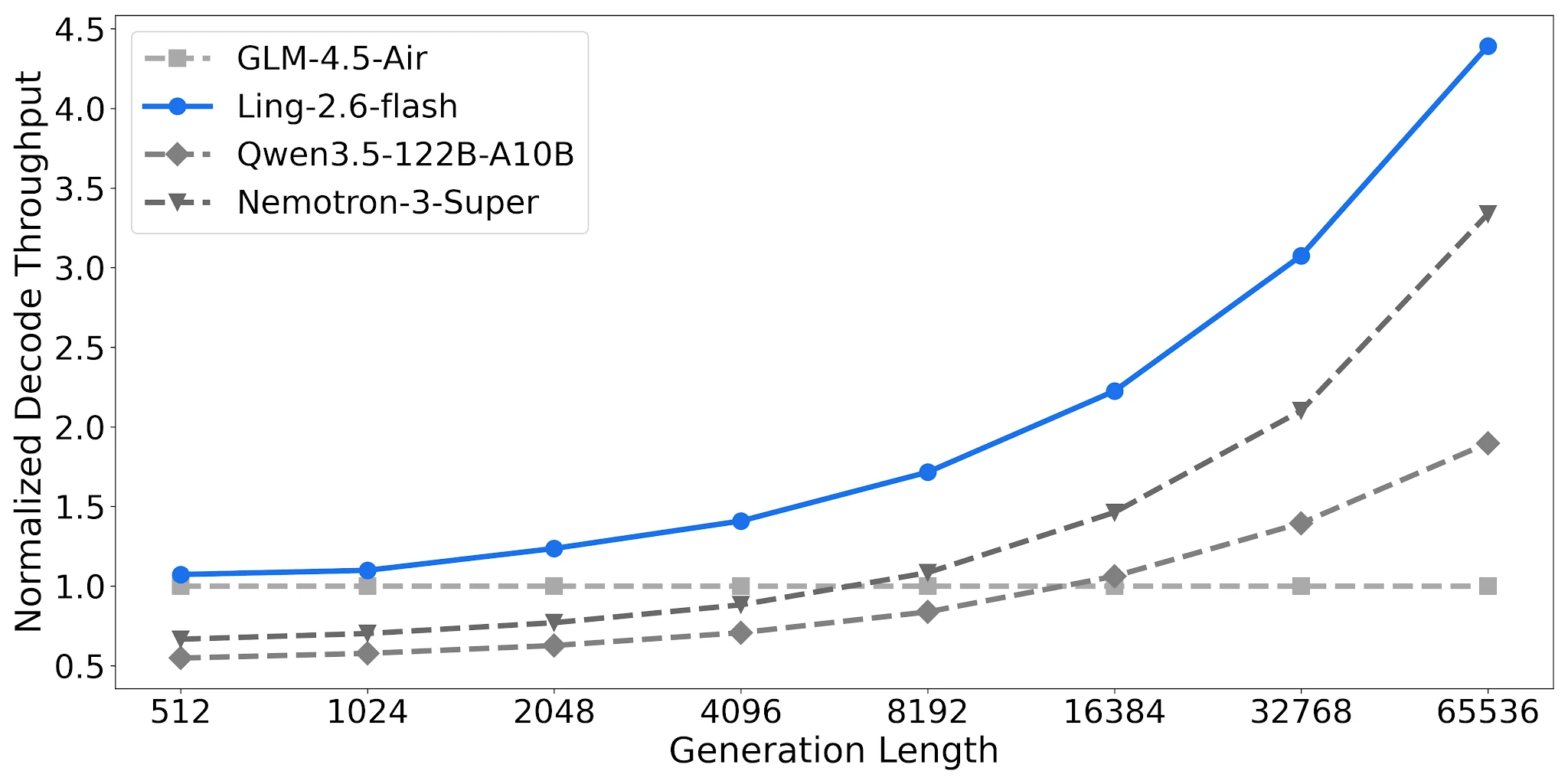
Сравнение пропускной способности декодирования, 4× H20-3e, TP=4, Batch=32 [Источник: Официальный блог Ling]
Пропускная способность Prefill: 2.2× Nemotron на длинных контекстах
Ling-2.6-flash достигает ~4.68× нормализованной пропускной способности prefill на контексте 65K против ~2.12× у Nemotron-3-Super. Для RAG-пайплайнов и многошаговых агентов с длинными системными промптами это напрямую снижает стоимость каждого запроса.
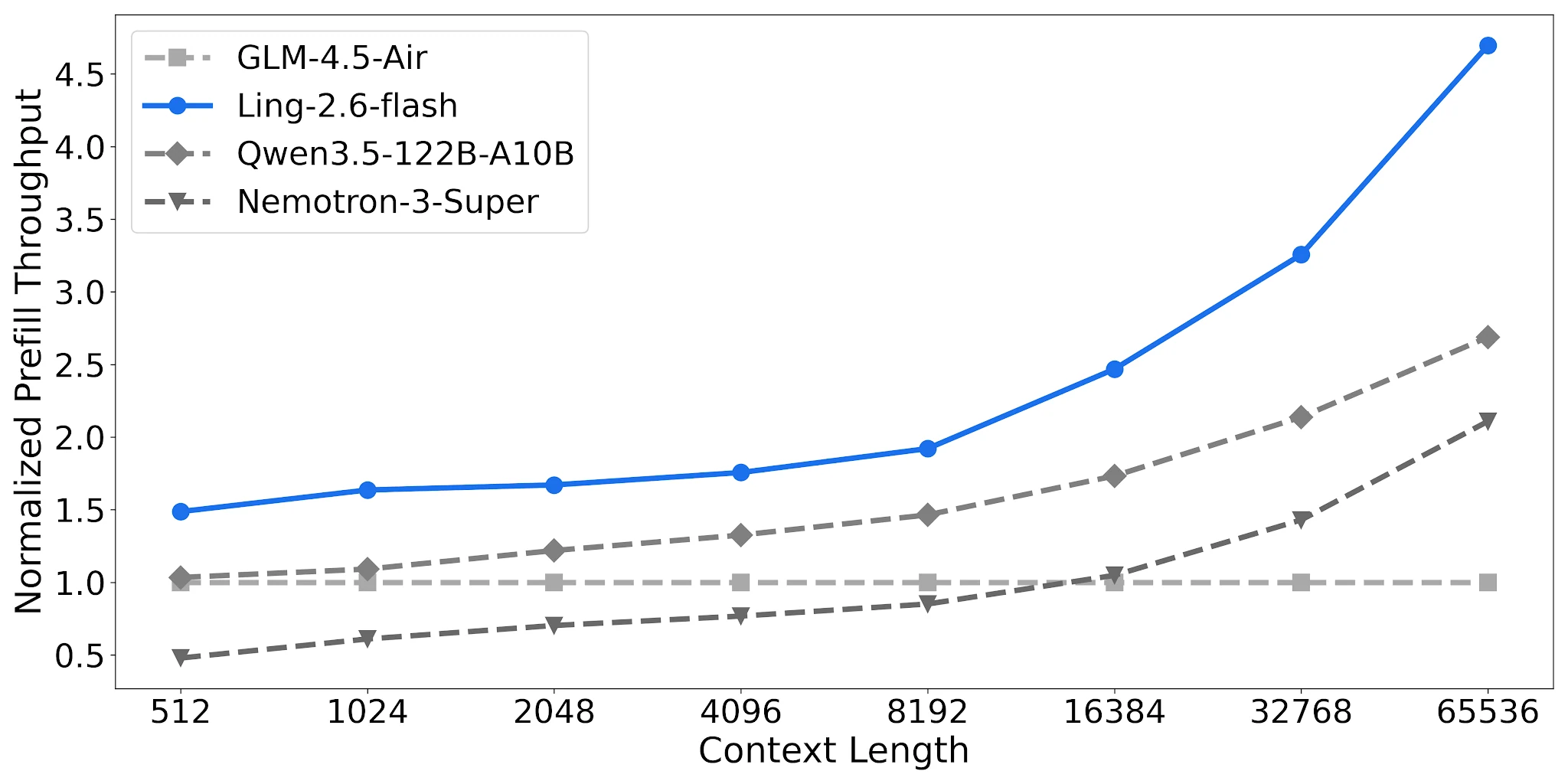
Сравнение пропускной способности Prefill, 4× H20-3e, TP=4, Batch=32 [Источник: Официальный блог Ling]
Эффективность токенов: 15M против 110M для решения одних и тех же бенчмарков
На полном индексе Artificial Analysis Intelligence Index Ling-2.6-flash использует ~15M выходных токенов. Nemotron-3-Super использует 110M+ — примерно в 7 раз больше — для модели, которая показывает более низкие результаты на агентных задачах. Для приложений, выполняющих сотни тысяч агентных задач ежедневно, этот разрыв превращается в прямую статью расходов в бюджете.
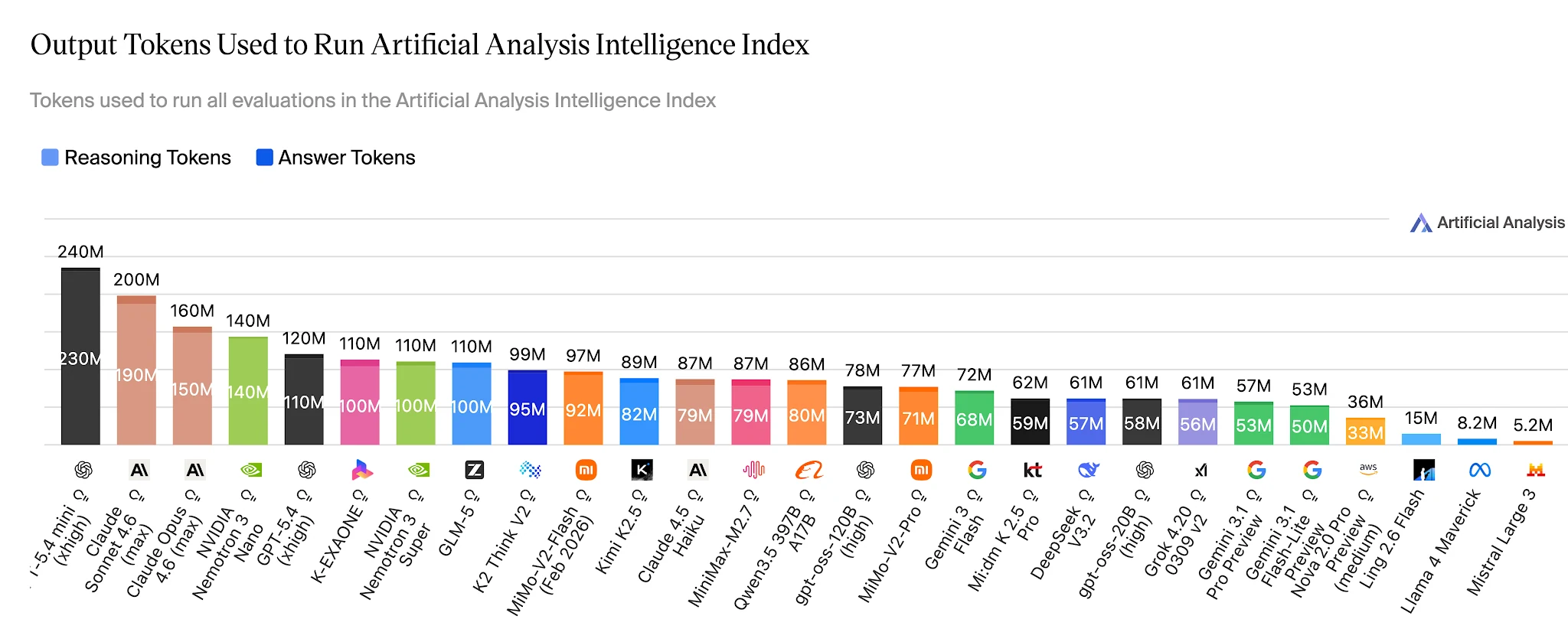
Выходные токены для прохождения Artificial Analysis Intelligence Index — Ling 2.6 Flash: ~15M vs Nemotron-3-Super: ~110M+ [Источник: Artificial Analysis]
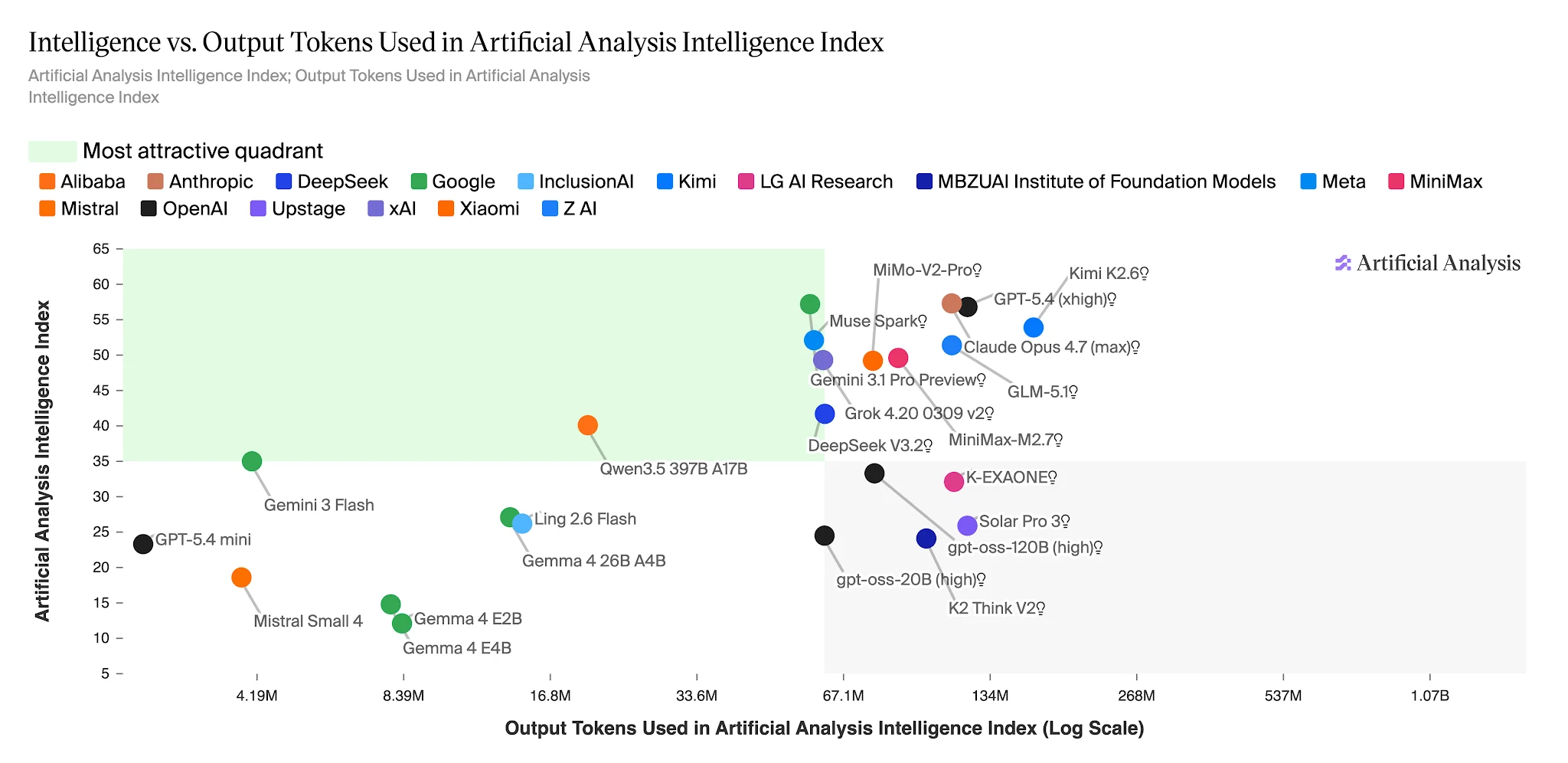
Intelligence vs. Выходные токены: Ling 2.6 Flash находится в зоне высокой эффективности [Источник: Artificial Analysis]
Результаты бенчмарков: где Ling-2.6-flash лидирует
Оценка на 19 бенчмарках в 7 категориях против Qwen3-57B-A14B, Qwen3.5-122B-A10B, GLM-4.5-Air, Nemotron-3-Super и MiniMax-M1-80k:
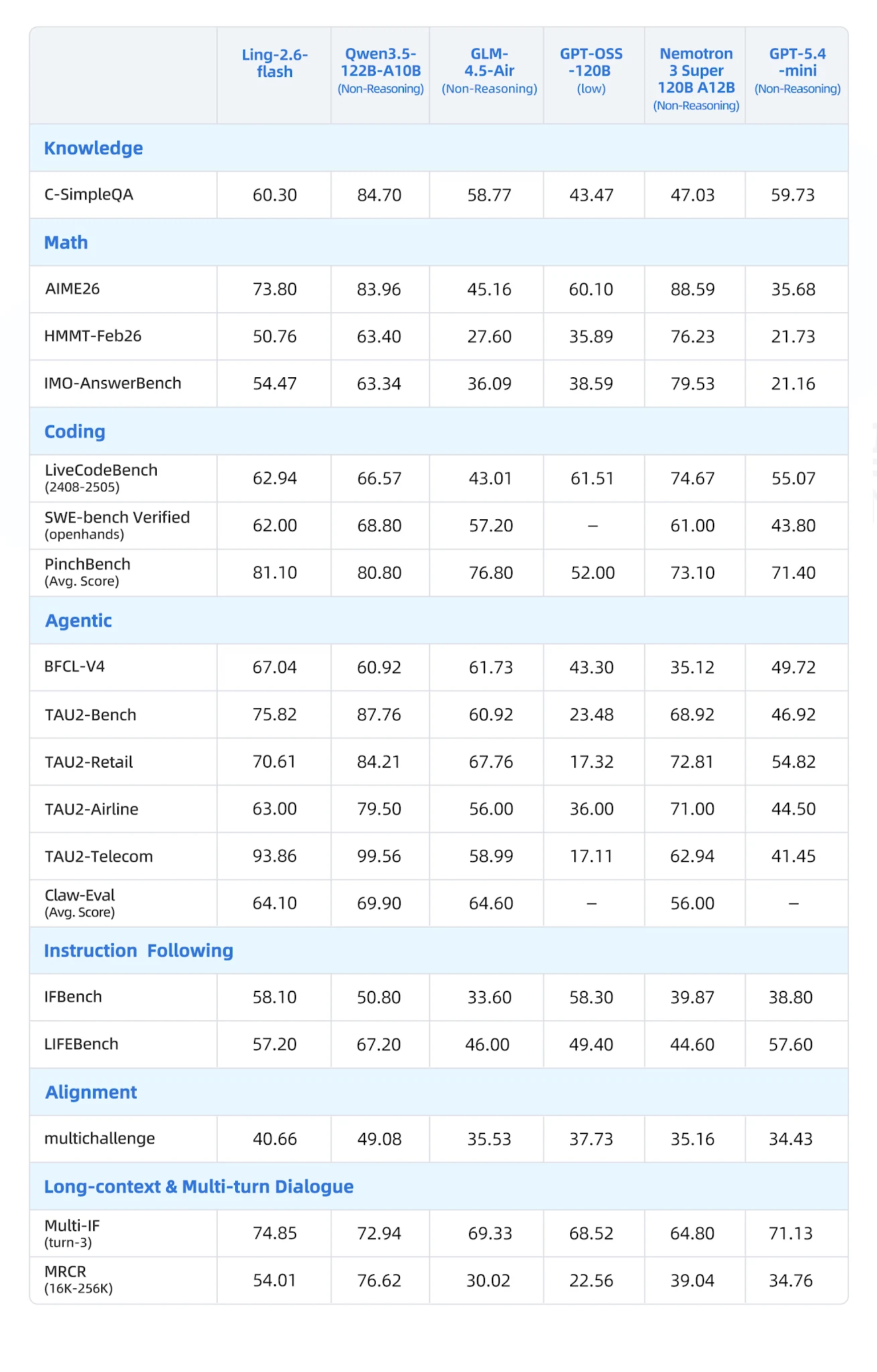
Полная таблица бенчмарков [Источник: Официальный блог Ling]
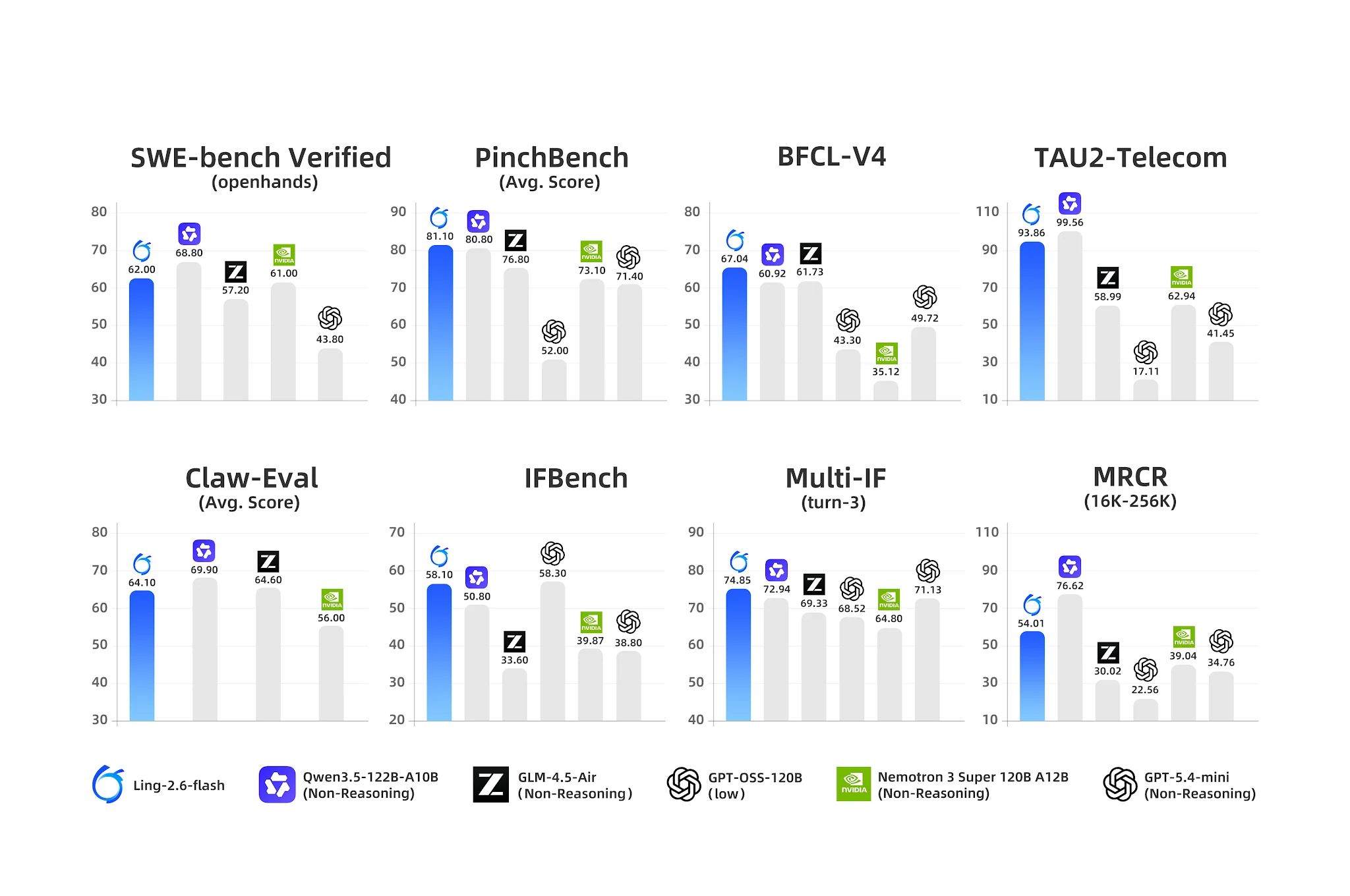
Агентные бенчмарки: Ling-2.6-flash лидирует в вызове инструментов и многошаговом IF [Источник: Официальный блог Ling]
Где Ling-2.6-flash лидирует
- BFCL-V4 (Вызов функций): 67.04 — ближайший конкурент Nemotron с 35.12 (отрыв 90%)
- PinchBench (Агентные задачи): 81.10 против Nemotron 73.10
- IFBench (Следование инструкциям): 58.10
- Multi-IF Turn-3: 74.85 — сильная устойчивость в многошаговом следовании инструкциям
- LongBench-v2: 54.80 — лучший в категории длинного контекста
- CCAlignBench (Китайский): 7.44 — лучший среди всех протестированных моделей
Где лидируют другие
- Математика (AIME 2025, MATH-500): побеждают Nemotron-3-Super и варианты Qwen3 с рассуждениями
- Программирование (LiveCodeBench): лидирует Qwen3.5-122B-A10B; Ling конкурентоспособна, но не на первом месте
- GPQA-Diamond: GLM-4.5-Air и Nemotron показывают более высокие результаты
Краткая сравнительная таблица
| Модель | Активные параметры | BFCL-V4 ↑ | PinchBench ↑ | Декодирование TP @ 65K ↑ | Выходные токены ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7.4B | 67.04 | 81.10 | 4.38× | ~15M |
| Nemotron-3-Super | 49B всего | 35.12 | 73.10 | 3.37× | ~110M+ |
| Qwen3.5-122B-A10B | 10B | — | 78.20 | 1.90× | — |
| GLM-4.5-Air | — | 50.67 | 73.30 | 1.00× (базовая линия) | — |
| MiniMax-M1-80k | — | 44.07 | 75.70 | — | — |
| Qwen3-57B-A14B | 14B | 52.32 | 76.30 | — | — |
Доступ к Ling-2.6-flash на базе Novita AI
Ling-2.6-flash доступна сейчас. Попробуйте на OpenRouter — бесплатный тариф, не требует настройки:
Начните работу на OpenRouter — inclusionai/ling-2.6-flash:free. Доступен бесплатный тариф, не требуется изменений кода для клиентов, совместимых с OpenAI.
Ling-2.6-flash работает с LangChain, LlamaIndex и OpenAI Agent SDK — не требуется адаптер или изменение кода. Поддерживаются потоковая передача, вызов функций и структурированные выходные данные. Используйте её вместе с Novita Agent Sandbox для безопасного выполнения кода вместе с инференсом.
Что говорят участники сообщества
Ling-2.6-flash запустилась на OpenRouter под названием «Elephant Alpha» до официального анонса. В течение нескольких дней она обработала ~100B токенов и возглавила трендовую таблицу платформы — без каких-либо объявлений.
«Ling-2.6-flash — это довольно рабочая модель. Примерно на 75% менее многословна, чем большие модели. Немного шаблонного кода ещё есть, но когда дело доходит до написания кода — она почти идеальна.»
— Ранний пользователь на X/Twitter
«Только что попробовал Ling-2.6-flash на нескольких задачах по программированию с llama.cpp. Намного лучше, чем ожидал. Надёжно обрабатывает вызовы инструментов и не раздувает вывод ненужными объяснениями.»
— Ранний пользователь на Reddit
Комментарий про «75% менее многословна» точно соответствует разрыву в 15M против 110M токенов на бенчмарках Artificial Analysis. Цель обучения, по-видимому, поощряет прямые, полные ответы — свойство, которое в производственном масштабе даёт экономию средств.
Кому стоит использовать Ling-2.6-flash?
- ✅ Агенты с высоким объёмом вызовов функций / использования инструментов — значительное лидерство в BFCL-V4
- ✅ Многошаговые агентные сессии — стабильность на длинных историях диалогов
- ✅ RAG-пайплайны с длинным контекстом — окно 256K токенов, prefill с линейной стоимостью
- ✅ Продуктивные развёртывания с чувствительностью к стоимости — ~7× меньше выходных токенов, чем у Nemotron
- ✅ Приложения на китайском языке — лучший результат в CCAlignBench
- ❌ Математические соревнования / рассуждения в стиле AIME — используйте Nemotron или варианты Qwen3 с рассуждениями
- ❌ Максимальная производительность в бенчмарках программирования — лидирует Qwen3.5-122B-A10B
Начните работу
Ling-2.6-flash доступна сейчас. Получите доступ через страницу модели на OpenRouter — бесплатный тариф доступен сразу, не требуется изменений кода для клиентов, совместимых с OpenAI. Agent Sandbox также доступен для команд, сочетающих инференс и безопасное выполнение.
Часто задаваемые вопросы
Что такое Ling-2.6-flash?
Ling-2.6-flash — это MoE-модель на 104B параметров (7.4B активных) с гибридным линейным вниманием, окном контекста 256K и скоростью инференса до 340 токенов/с — оптимизирована для агентных нагрузок.
Как использовать Ling-2.6-flash через API?
Используйте OpenRouter с вашим API-ключом Novita AI (BYOK). Добавьте ключ Novita на openrouter.ai/settings/integrations, выберите Novita в качестве провайдера и направляйте запросы к inclusionai/ling-2.6-flash:free через совместимую с OpenAI конечную точку:
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer YOUR_OPENROUTER_API_KEY
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "YOUR_NOVITA_API_KEY"
},
"messages": [{"role": "user", "content": "Hello!"}]
}
См. документацию OpenRouter по BYOK для полной настройки. При использовании BYOK OpenRouter не взимает комиссию — вы платите Novita напрямую по ценам бесплатного тарифа.
Как Ling-2.6-flash сравнивается с Nemotron-3-Super?
Ling лидирует в BFCL-V4 (67.04 против 35.12), PinchBench (81.10 против 73.10) и использует ~7× меньше выходных токенов. Nemotron лидирует в математике. Для агентных нагрузок Ling-2.6-flash является более выгодным экономическим выбором.
Каков размер окна контекста?
256K токенов (262,144), с prefill по линейной стоимости благодаря гибридному линейному вниманию. Длинные RAG-сессии и многошаговые сеансы масштабируются эффективно.
Является ли Ling-2.6-flash открытым исходным кодом?
Варианты BF16, FP8 и INT4, а также ядра Linghe планируются к выпуску с открытым исходным кодом. Сроки уточняются — следите за обновлениями на официальном сайте Ling.
Вам также может понравиться
- Kimi K2.6: Агент с открытым исходным кодом для 13-часовых сессий программирования — MoE-модель на 1T с контекстом 256K и 58.6% SWE-Bench Pro
- GLM-5.1 API на Novita AI: Долгосрочная агентная модель — лидирует в SWE-Bench Pro с 58.4, выполняет автономные задачи программирования до 8 часов
- Лучшие провайдеры API инференса для моделей с открытым исходным кодом в 2026 году — сравнение Novita AI, Together AI, Fireworks, DeepInfra и Groq



