

- ¿Qué es Ling-2.6-flash?
- Arquitectura lineal híbrida: cómo Ling-2.6-flash se vuelve más rápido a escala
- Eficiencia de tokens: 15M vs. 110M para resolver los mismos benchmarks
- Resultados de benchmarks: dónde lidera Ling-2.6-flash
- Tabla comparativa rápida
- Accede a Ling-2.6-flash respaldado por Novita AI
- Lo que la comunidad está diciendo
- ¿Quién debería usar Ling-2.6-flash?
- Comienza
- Preguntas frecuentes
Las facturas de tokens de agentes se están disparando: llamadas a herramientas en múltiples pasos, planificación con contexto largo y salidas extendidas convierten lo que parece un precio barato por token en una factura mensual muy costosa. La respuesta de la industria —encadenar trazas de razonamiento más largas para subir los puntajes de los benchmarks— empeora la economía, no la mejora.
Ling-2.6-flash es un modelo diferente. Construido sobre una arquitectura de atención lineal híbrida, alcanza hasta 340 tokens/s en hardware 4× H20, ofrece 2.2× el rendimiento de prefill de Nemotron-3-Super, y utiliza solo ~15M tokens de salida para completar el índice completo de Artificial Analysis Intelligence — aproximadamente una décima parte de lo que consume Nemotron-3-Super. En resumen: Ling-2.6-flash es un modelo MoE de 104B (7.4B activos) con una ventana de contexto de 256K, optimizado para cargas de trabajo de agentes donde la velocidad, el costo y la estabilidad importan más que un solo benchmark destacado. Ya está disponible en Novita AI.
¿Qué es Ling-2.6-flash?
Ling-2.6-flash es un modelo de lenguaje sparse Mixture-of-Experts con 104B parámetros totales y 7.4B parámetros activos por paso forward. Desarrollado por el equipo de Ling (InclusionAI), está diseñado como un modelo de categoría “Instant” —optimizado para despliegues de agentes en producción donde el consumo de tokens y la latencia son costos reales, no solo titulares de benchmarks.
- 104B total / 7.4B parámetros activos — arquitectura MoE con alta dispersión
- Ventana de contexto de 256K tokens — habilitada por atención lineal híbrida
- Rendimiento máximo de 340 tokens/s en 4× H20 (TP=4)
- Atención lineal híbrida 1:7 MLA + Lightning Linear — 4× rendimiento en contextos largos
- Mejores benchmarks de agentes — lidera BFCL-V4 (67.04), PinchBench (81.10), IFBench (58.10), Multi-IF Turn-3 (74.85)
- Variantes BF16, FP8 e INT4 — lanzamiento open-source planeado a través de Linghe
- Validado en producción — ~100B tokens diarios en OpenRouter a los pocos días del lanzamiento
Arquitectura lineal híbrida: cómo Ling-2.6-flash se vuelve más rápido a escala
La mayoría de los modelos MoE combinan atención transformer estándar con una capa FFN dispersa. Ling-2.6-flash reemplaza la mayor parte de la atención con una capa Lightning Linear, creando un híbrido 1:7 MLA + Lightning Linear. El costo de la atención crece linealmente con la longitud del contexto en lugar de cuadráticamente — algo crítico para sesiones largas de agentes.
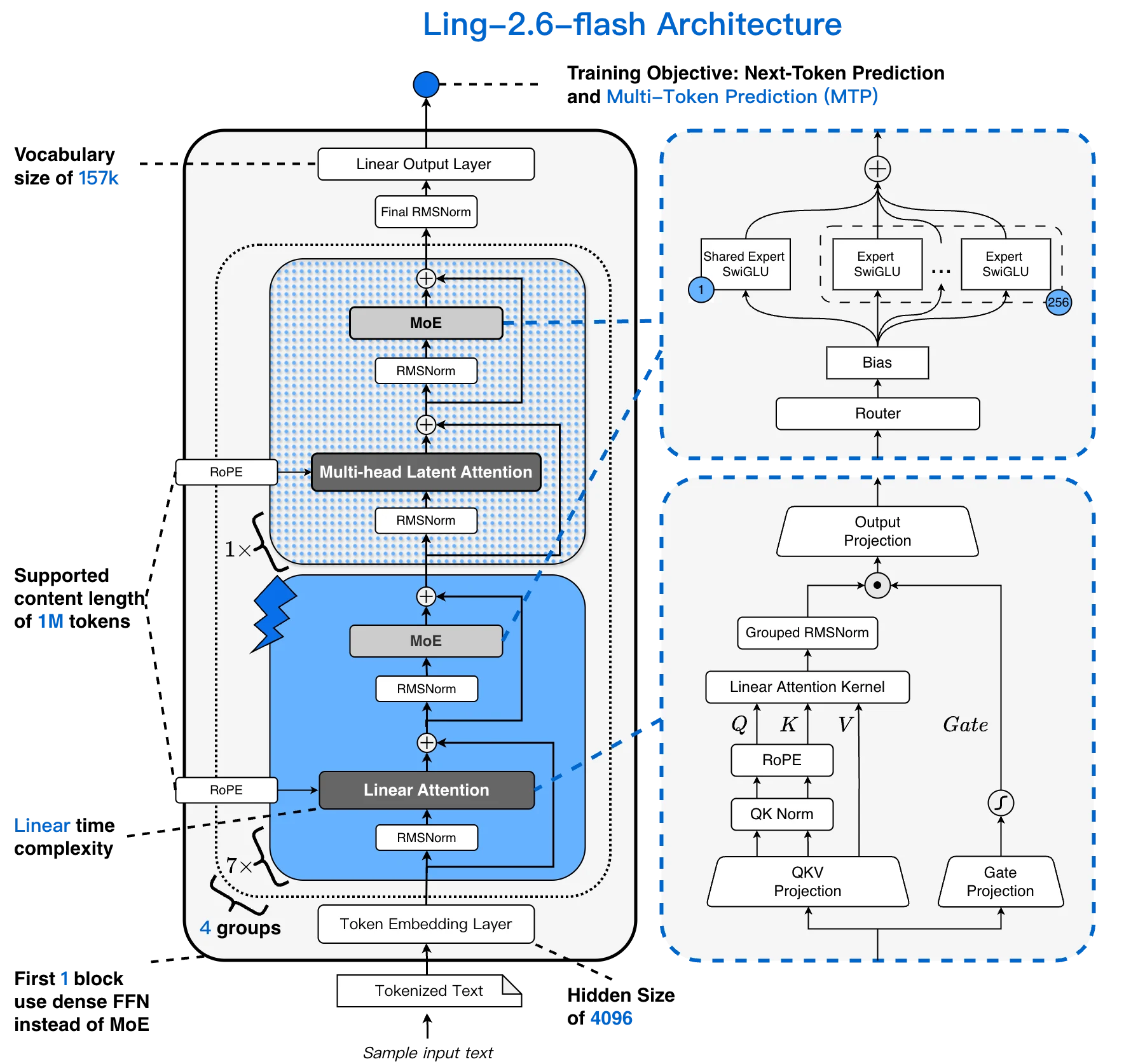
Arquitectura de Ling-2.6-flash: vocabulario de 157K, contexto de 256K, híbrido 1:7 MLA + Lightning Linear, 256 expertos seleccionables [Fuente: Blog Oficial de Ling]
Rendimiento de Decode: Hasta 4.38× en salidas largas
En 4× H20-3e (TP=4, tamaño de lote 32), Ling-2.6-flash alcanza 4.38× el rendimiento normalizado de decode a una longitud de salida de 65,536 tokens vs. la línea base GLM-4.5-Air. Qwen3.5-122B-A10B alcanza 1.90×; Nemotron-3-Super 3.37×. La brecha se amplía a medida que aumenta la longitud de la tarea de salida.
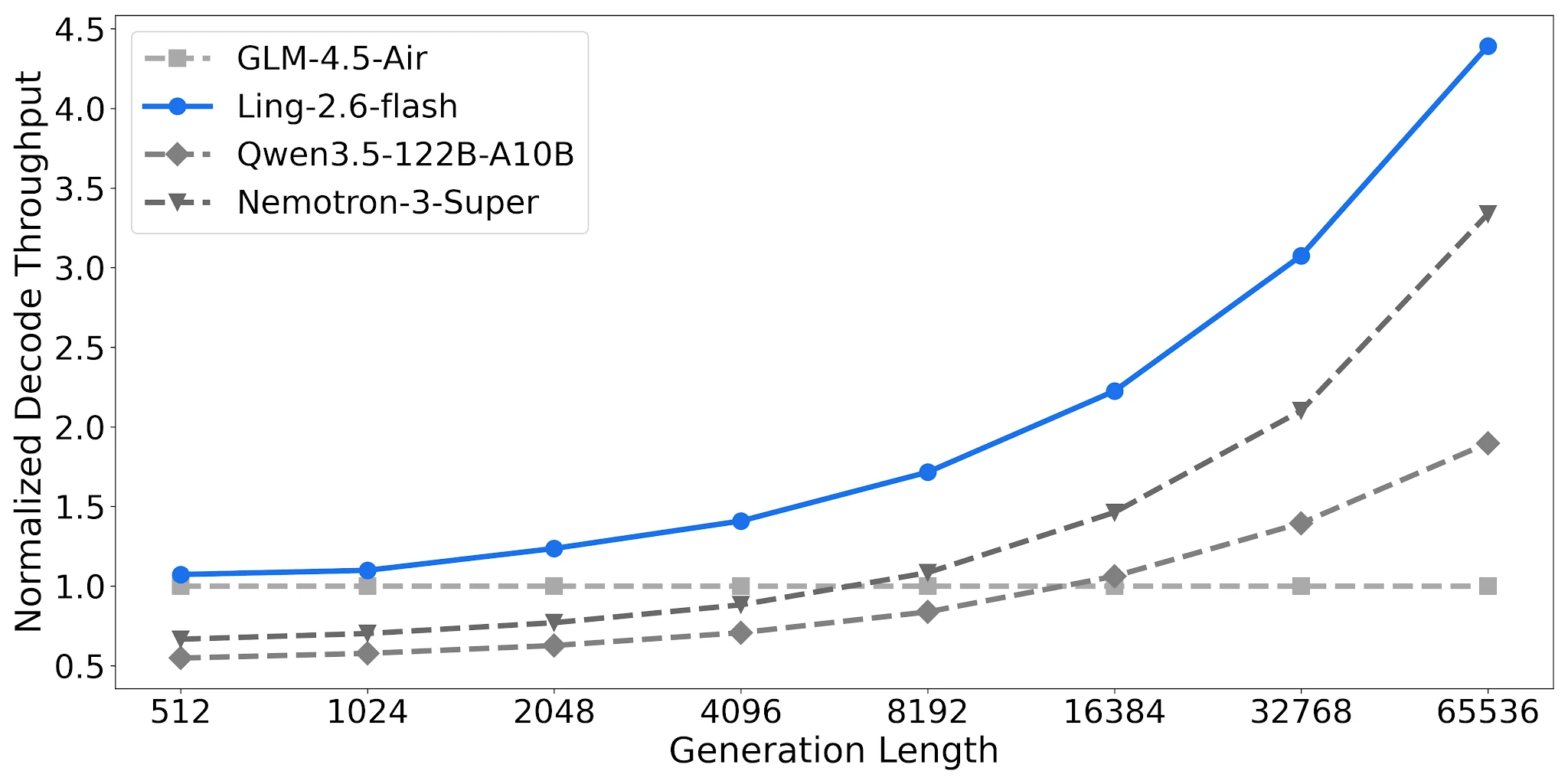
Comparación de rendimiento de decode, 4× H20-3e, TP=4, Lote=32 [Fuente: Blog Oficial de Ling]
Rendimiento de Prefill: 2.2× Nemotron en contextos largos
Ling-2.6-flash logra ~4.68× rendimiento normalizado de prefill a 65K de contexto vs. ~2.12× para Nemotron-3-Super. Para pipelines RAG y agentes de múltiples turnos con prompts de sistema largos, esto reduce directamente el costo por solicitud.
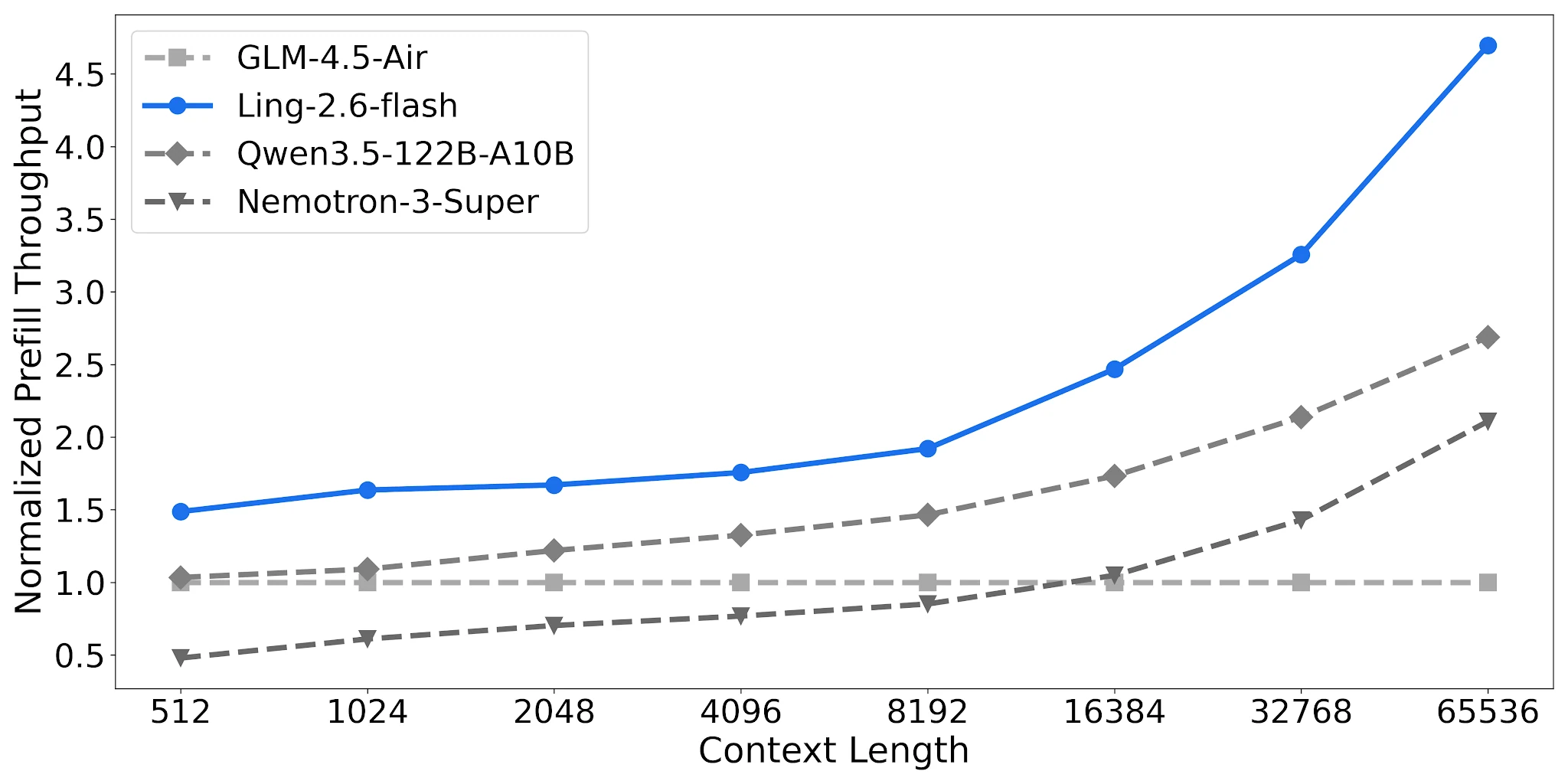
Comparación de rendimiento de prefill, 4× H20-3e, TP=4, Lote=32 [Fuente: Blog Oficial de Ling]
Eficiencia de tokens: 15M vs. 110M para resolver los mismos benchmarks
En el índice completo de Artificial Analysis Intelligence, Ling-2.6-flash utiliza ~15M tokens de salida. Nemotron-3-Super utiliza 110M+ — aproximadamente 7× más — para un modelo que obtiene puntuaciones más bajas en tareas de agentes. Para aplicaciones que ejecutan cientos de miles de tareas de agentes diariamente, esta brecha es una partida directa en un presupuesto de costos.
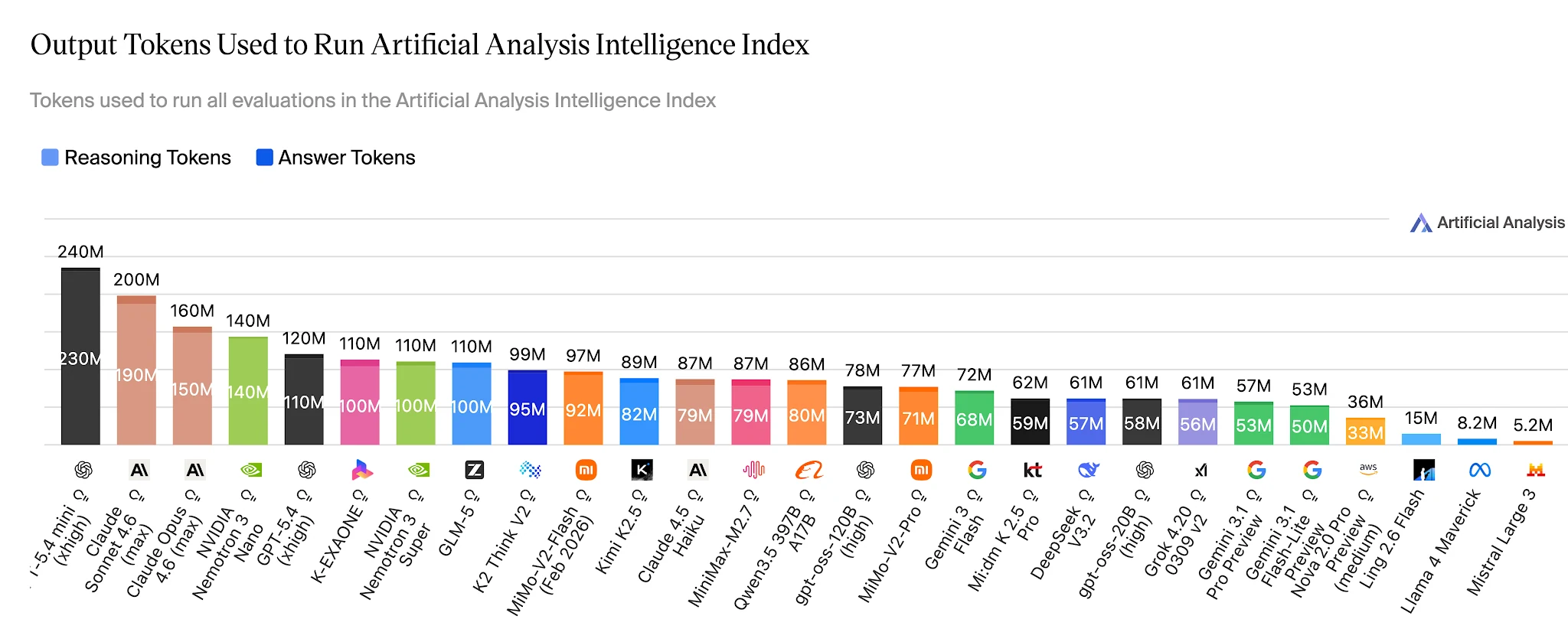
Tokens de salida para completar el índice Artificial Analysis Intelligence — Ling 2.6 Flash: ~15M vs Nemotron-3-Super: ~110M+ [Fuente: Artificial Analysis]
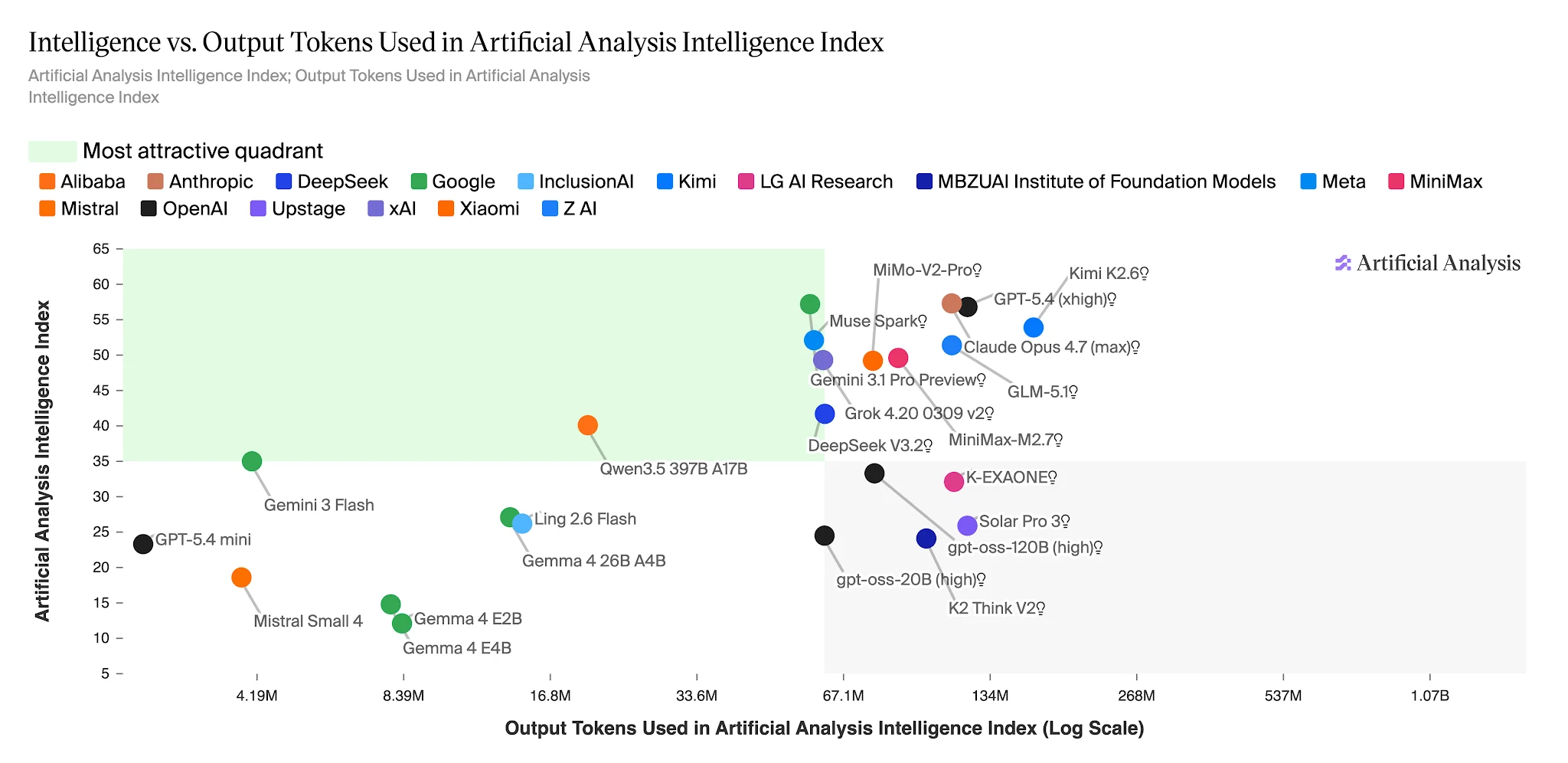
Inteligencia vs. Tokens de salida: Ling 2.6 Flash se ubica en la zona de alta eficiencia [Fuente: Artificial Analysis]
Resultados de benchmarks: dónde lidera Ling-2.6-flash
Evaluado en 19 benchmarks en 7 categorías contra Qwen3-57B-A14B, Qwen3.5-122B-A10B, GLM-4.5-Air, Nemotron-3-Super y MiniMax-M1-80k:
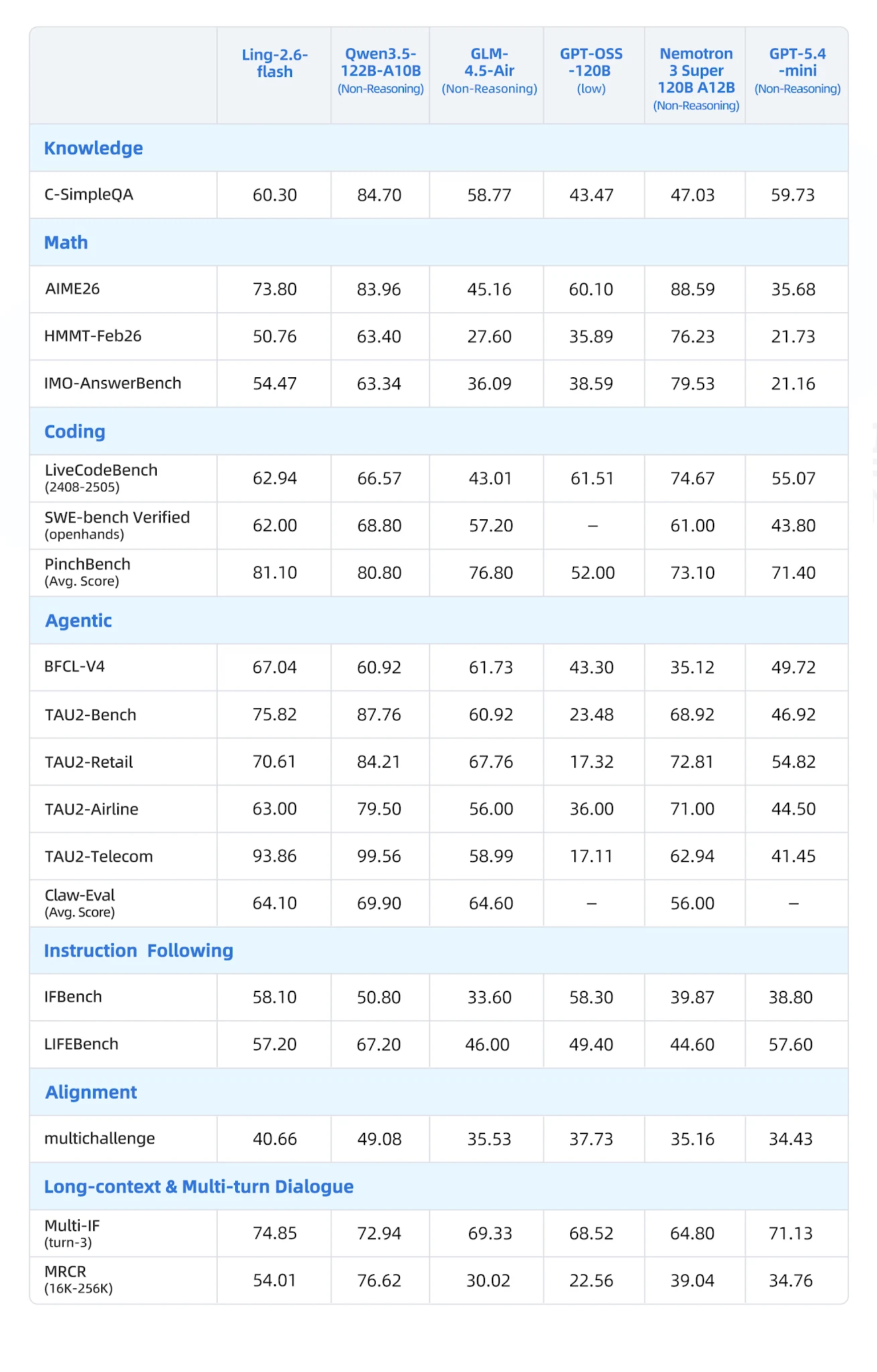
Tabla completa de benchmarks [Fuente: Blog Oficial de Ling]
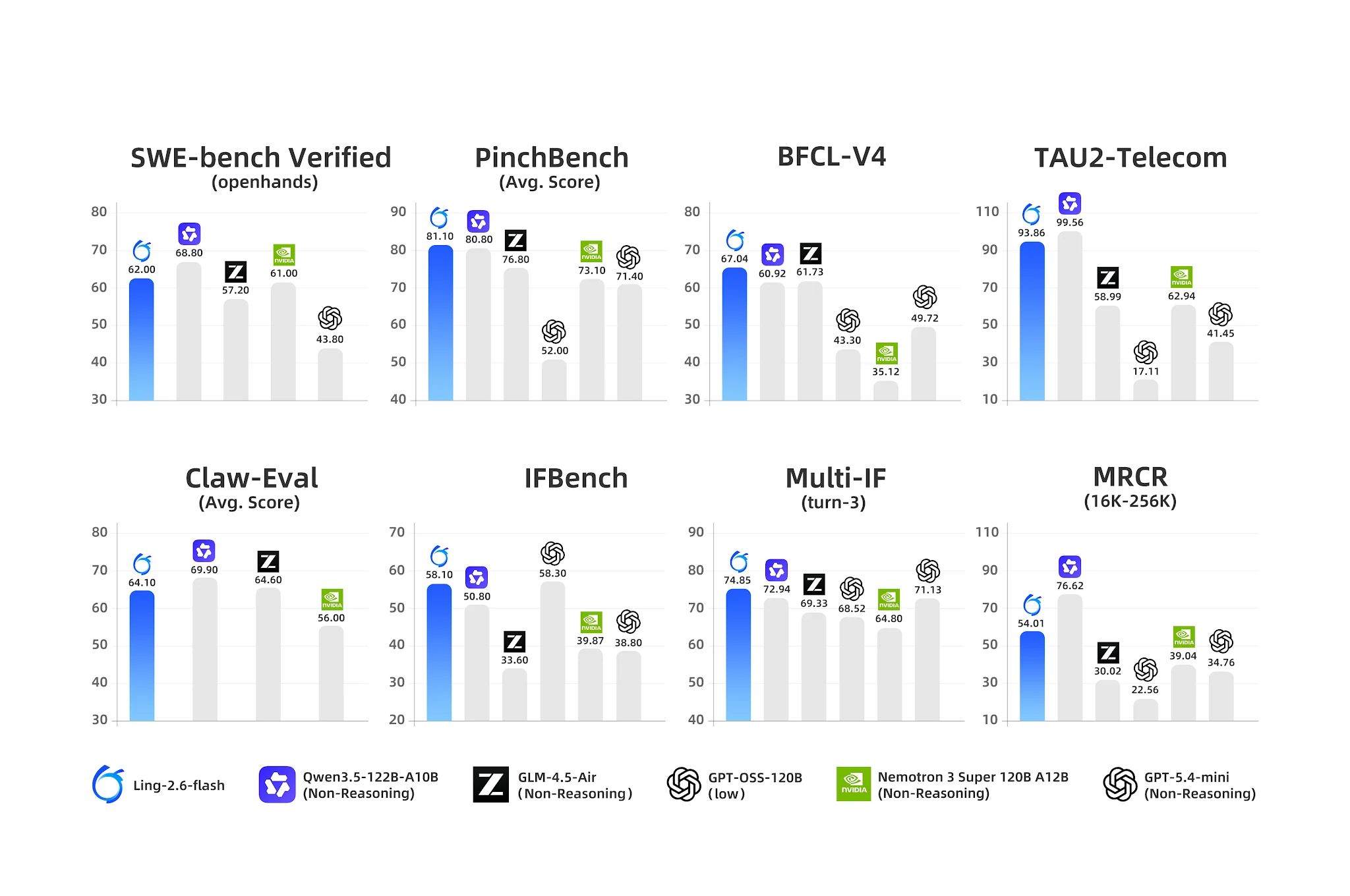
Benchmarks de agentes: Ling-2.6-flash lidera en uso de herramientas y IF multi-turno [Fuente: Blog Oficial de Ling]
Dónde lidera Ling-2.6-flash
- BFCL-V4 (Llamadas a funciones): 67.04 — competidor más cercano Nemotron con 35.12 (brecha del 90%)
- PinchBench (Tareas de agentes): 81.10 vs. Nemotron 73.10
- IFBench (Seguimiento de instrucciones): 58.10
- Multi-IF Turn-3: 74.85 — fuerte persistencia de instrucciones en múltiples turnos
- LongBench-v2: 54.80 — el mejor en la categoría de contexto largo
- CCAlignBench (Chino): 7.44 — el mejor entre todos los modelos probados
Dónde lideran otros
- Matemáticas (AIME 2025, MATH-500): Nemotron-3-Super y las variantes de razonamiento Qwen3 ganan
- Codificación (LiveCodeBench): Qwen3.5-122B-A10B lidera; Ling es competitivo pero no el mejor
- GPQA-Diamond: GLM-4.5-Air y Nemotron obtienen puntuaciones más altas
Tabla comparativa rápida
| Modelo | Parámetros activos | BFCL-V4 ↑ | PinchBench ↑ | Decode TP @ 65K ↑ | Tokens de salida ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7.4B | 67.04 | 81.10 | 4.38× | ~15M |
| Nemotron-3-Super | 49B total | 35.12 | 73.10 | 3.37× | ~110M+ |
| Qwen3.5-122B-A10B | 10B | — | 78.20 | 1.90× | — |
| GLM-4.5-Air | — | 50.67 | 73.30 | 1.00× (línea base) | — |
| MiniMax-M1-80k | — | 44.07 | 75.70 | — | — |
| Qwen3-57B-A14B | 14B | 52.32 | 76.30 | — | — |
Accede a Ling-2.6-flash respaldado por Novita AI
Ling-2.6-flash ya está disponible. Pruébalo en OpenRouter — nivel gratuito, sin configuración requerida:
Comienza en OpenRouter — inclusionai/ling-2.6-flash:free. Nivel gratuito disponible, no se necesitan cambios de código para clientes compatibles con OpenAI.
Ling-2.6-flash funciona con LangChain, LlamaIndex y OpenAI Agent SDK — no se necesita adaptador ni cambio de código. Son compatibles streaming, llamadas a funciones y salidas estructuradas. Combínalo con Novita Agent Sandbox para ejecución segura de código junto con inferencia.
Lo que la comunidad está diciendo
Ling-2.6-flash se lanzó en OpenRouter como “Elephant Alpha” antes de la revelación oficial. En pocos días había procesado ~100B tokens y encabezado la tabla de tendencias de la plataforma — sin ningún anuncio.
“Ling-2.6-flash está orientado al trabajo. Es aproximadamente un 75% menos verboso que los modelos grandes. Todavía tiene algo de relleno, pero cuando se trata de escribir código — es casi perfecto.”
— Usuario temprano en X/Twitter
“Acabo de probar Ling-2.6-flash en algunas tareas de codificación con llama.cpp. Mucho mejor de lo esperado. Maneja llamadas a funciones de manera confiable y no rellena la salida con explicaciones innecesarias.”
— Usuario temprano en Reddit
El comentario “75% menos verboso” coincide exactamente con la brecha de 15M vs. 110M tokens en los benchmarks de Artificial Analysis. El objetivo de entrenamiento parece recompensar respuestas directas y completas — una propiedad que se acumula en ahorros de costos a escala de producción.
¿Quién debería usar Ling-2.6-flash?
- ✅ Agentes de alto volumen de llamadas a funciones / uso de herramientas — liderazgo en BFCL-V4 por un amplio margen
- ✅ Sesiones de agentes de múltiples turnos — consistentes en historiales de conversación largos
- ✅ Pipelines RAG de contexto largo — ventana de 256K tokens, prefill de costo lineal
- ✅ Despliegues de producción sensibles al costo — ~7× menos tokens de salida que Nemotron
- ✅ Aplicaciones en idioma chino — mejor en CCAlignBench
- ❌ Razonamiento tipo competencia matemática / AIME — usar Nemotron o variantes de razonamiento Qwen3
- ❌ Máximo rendimiento en benchmarks de codificación — Qwen3.5-122B-A10B lidera
Comienza
Ling-2.6-flash ya está disponible. Accede a través de la página del modelo en OpenRouter — nivel gratuito disponible de inmediato, no se necesitan cambios de código para clientes compatibles con OpenAI. Agent Sandbox está disponible para equipos que combinen inferencia y ejecución segura.
Preguntas frecuentes
¿Qué es Ling-2.6-flash?
Ling-2.6-flash es un modelo MoE de 104B (7.4B activos) con atención lineal híbrida, ventana de contexto de 256K y velocidad de inferencia de hasta 340 tokens/s — optimizado para cargas de trabajo de agentes.
¿Cómo uso Ling-2.6-flash a través de la API?
Usa OpenRouter con tu clave API de Novita AI (BYOK). Agrega tu clave de Novita en openrouter.ai/settings/integrations, selecciona Novita como proveedor y enruta las solicitudes a inclusionai/ling-2.6-flash:free a través del endpoint compatible con OpenAI:
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer TU_CLAVE_API_OPENROUTER
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "TU_CLAVE_API_NOVITA"
},
"messages": [{"role": "user", "content": "¡Hola!"}]
}
Consulta la documentación de BYOK de OpenRouter para la configuración completa. Cuando se usa BYOK, OpenRouter no cobra comisiones — pagas directamente a Novita al precio del nivel gratuito.
¿Cómo se compara Ling-2.6-flash con Nemotron-3-Super?
Ling lidera en BFCL-V4 (67.04 vs 35.12), PinchBench (81.10 vs 73.10) y usa ~7× menos tokens de salida. Nemotron lidera en matemáticas. Para cargas de trabajo de agentes, Ling-2.6-flash es la mejor opción económica.
¿Cuál es la ventana de contexto?
256K tokens (262,144), con prefill de costo lineal gracias a la atención lineal híbrida. Las sesiones largas de RAG y multi-turno escalan eficientemente.
¿Ling-2.6-flash es open source?
Están planeados lanzamientos open-source de las variantes BF16, FP8 e INT4, así como los kernels Linghe. Fecha por determinar — consulta el sitio oficial de Ling para actualizaciones.
También te puede interesar
- Kimi K2.6: Agente Open-Source para Sesiones de Codificación de 13 Horas — Modelo MoE de 1T con contexto de 256K y 58.6% en SWE-Bench Pro
- API de GLM-5.1 en Novita AI: Modelo Agente de Horizonte Largo — Lidera SWE-Bench Pro con 58.4, ejecuta tareas de codificación autónomas durante 8 horas
- Principales Proveedores de API de Inferencia para Modelos Open-Source en 2026 — Compara Novita AI, Together AI, Fireworks, DeepInfra y DeepInfra



