

- Qu’est-ce que Ling-2.6-flash ?
- Architecture linéaire hybride : comment Ling-2.6-flash devient plus rapide à l’échelle
- Efficacité token : 15M vs 110M pour résoudre les mêmes benchmarks
- Résultats des benchmarks : où Ling-2.6-flash est leader
- Tableau comparatif rapide
- Accéder à Ling-2.6-flash propulsé par Novita AI
- Ce que dit la communauté
- Qui devrait utiliser Ling-2.6-flash ?
- Commencer
- Questions fréquemment posées
Les factures de tokens pour les agents explosent : appels d’outils multi-étapes, planification long contexte, sorties étendues transforment un prix unitaire apparemment bas en une note mensuelle très élevée. La réponse de l’industrie – enchaîner des traces de raisonnement plus longues pour faire grimper les scores des benchmarks – aggrave l’économie, pas l’inverse.
Ling-2.6-flash est un modèle différent. Construit autour d’une architecture d’attention linéaire hybride, il atteint jusqu’à 340 tokens/s sur du matériel 4× H20, offre 2,2× le débit de préremplissage de Nemotron-3-Super et utilise seulement ~15M de tokens de sortie pour réaliser l’intégralité de l’Artificial Analysis Intelligence Index – environ un dixième de ce que consomme Nemotron-3-Super. En bref : Ling-2.6-flash est un modèle MoE de 104B (7,4B actifs) avec une fenêtre de contexte de 256K, optimisé pour les charges de travail d’agents où la vitesse, le coût et la stabilité comptent plus qu’un seul benchmark phare. Il est désormais disponible sur Novita AI.
Qu’est-ce que Ling-2.6-flash ?
Ling-2.6-flash est un modèle de langage sparse Mixture-of-Experts avec 104B paramètres totaux et 7,4B paramètres actifs par passage avant. Développé par l’équipe Ling (InclusionAI), il est conçu comme un modèle de catégorie « Instant » – optimisé pour les déploiements d’agents en production où la consommation de tokens et la latence sont des coûts réels, pas seulement des titres de benchmarks.
- 104B total / 7,4B paramètres actifs – architecture MoE à haute sparsité
- Fenêtre de contexte de 256K tokens – permise par l’attention linéaire hybride
- Débit de pointe de 340 tokens/s sur 4× H20 (TP=4)
- Attention hybride 1:7 MLA + Lightning Linear – 4× le débit sur de longs contextes
- Meilleurs benchmarks d’agents – leader sur BFCL-V4 (67,04), PinchBench (81,10), IFBench (58,10), Multi-IF Turn-3 (74,85)
- Variantes BF16, FP8 et INT4 – publication open-source prévue via Linghe
- Validé en production – ~100B tokens quotidiens sur OpenRouter quelques jours après le lancement
Architecture linéaire hybride : comment Ling-2.6-flash devient plus rapide à l’échelle
La plupart des modèles MoE associent une attention transformer standard à une couche FFN sparse. Ling-2.6-flash remplace la plupart de l’attention par une couche Lightning Linear, créant un hybride 1:7 MLA + Lightning Linear. Le coût de l’attention croît linéairement avec la longueur du contexte plutôt que quadratiquement – essentiel pour les longues sessions d’agents.
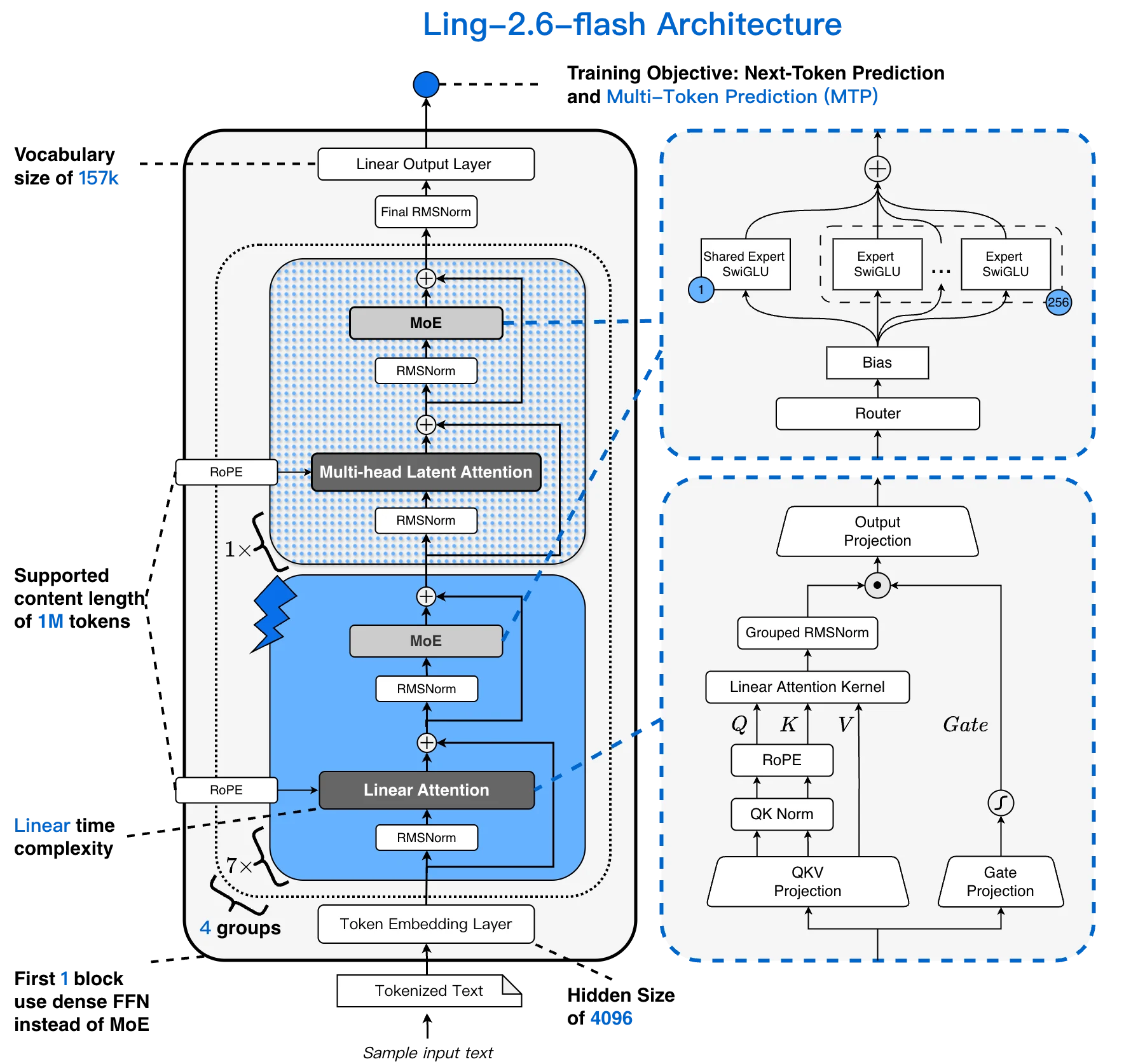
Architecture de Ling-2.6-flash : vocabulaire 157K, contexte 256K, hybride 1:7 MLA + Lightning Linear, 256 experts sélectionnables [Source : Blog officiel Ling]
Débit de décodage : jusqu’à 4,38× sur les longues sorties
Sur 4× H20-3e (TP=4, taille de lot 32), Ling-2.6-flash atteint 4,38× le débit de décodage normalisé à une longueur de sortie de 65 536 tokens par rapport à la référence GLM-4.5-Air. Qwen3.5-122B-A10B atteint 1,90× ; Nemotron-3-Super 3,37×. L’écart se creuse à mesure que la longueur de la tâche augmente.
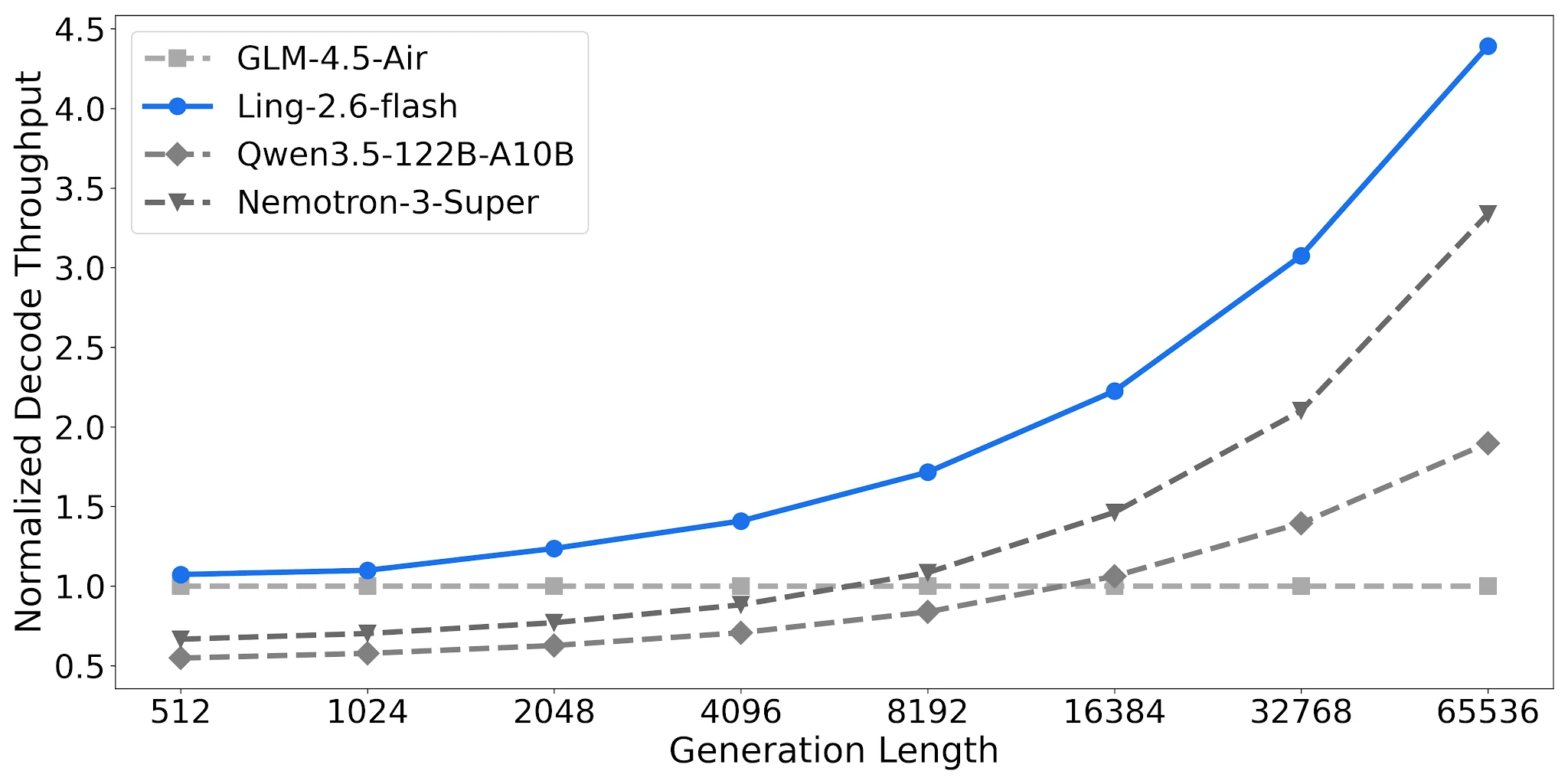
Comparaison du débit de décodage, 4× H20-3e, TP=4, Batch=32 [Source : Blog officiel Ling]
Débit de préremplissage : 2,2× Nemotron sur les longs contextes
Ling-2.6-flash atteint ~4,68× le débit de préremplissage normalisé à 65K de contexte contre ~2,12× pour Nemotron-3-Super. Pour les pipelines RAG et les agents multi-tours avec de longues invites système, cela réduit directement le coût par requête.
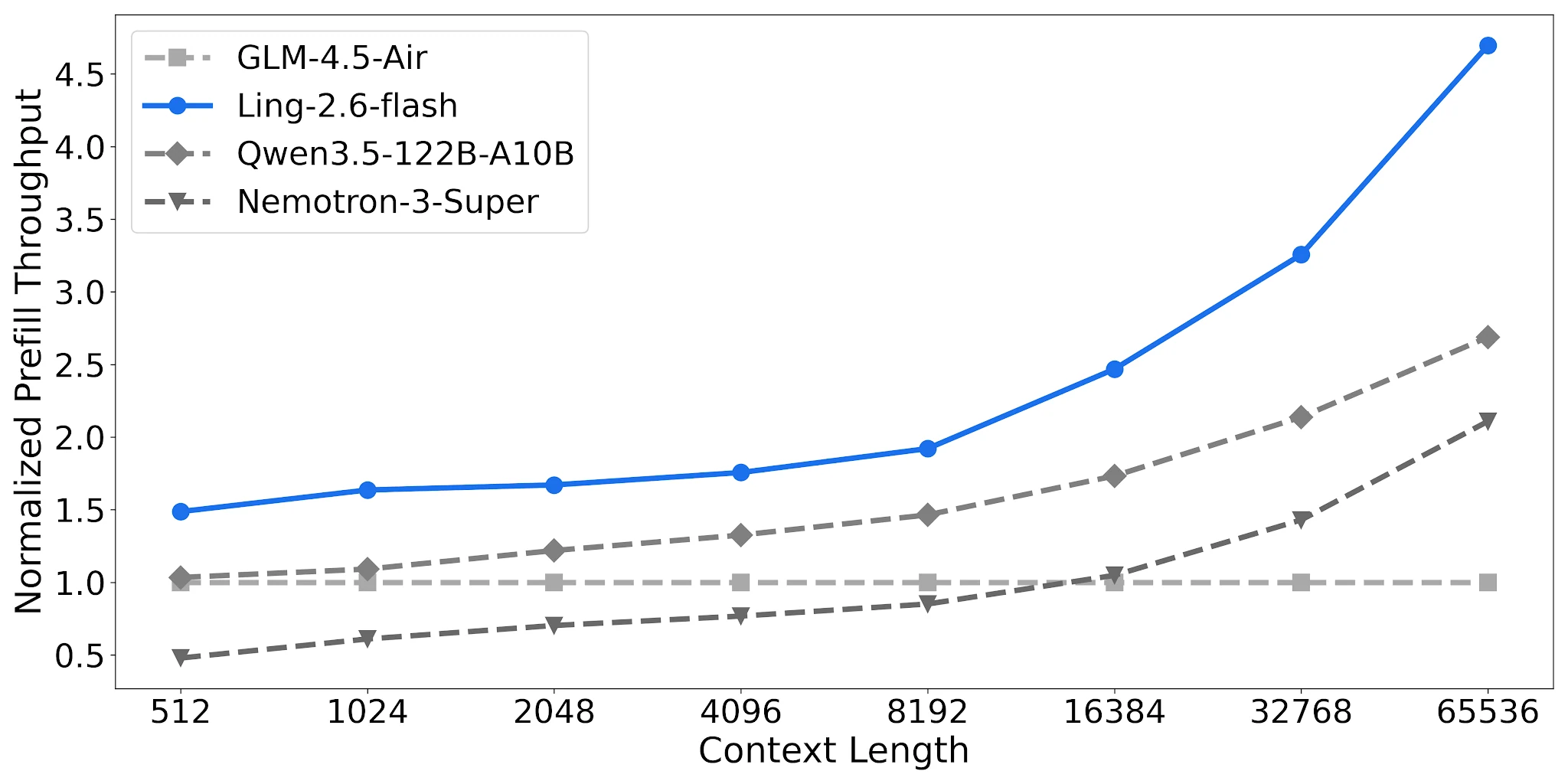
Comparaison du débit de préremplissage, 4× H20-3e, TP=4, Batch=32 [Source : Blog officiel Ling]
Efficacité token : 15M vs 110M pour résoudre les mêmes benchmarks
Sur l’intégralité de l’Artificial Analysis Intelligence Index, Ling-2.6-flash utilise ~15M de tokens de sortie. Nemotron-3-Super en utilise 110M+ – environ 7× plus – pour un modèle qui obtient des scores plus bas sur les tâches d’agents. Pour les applications exécutant des centaines de milliers de tâches d’agents par jour, cet écart est une ligne directe dans un budget de coûts.
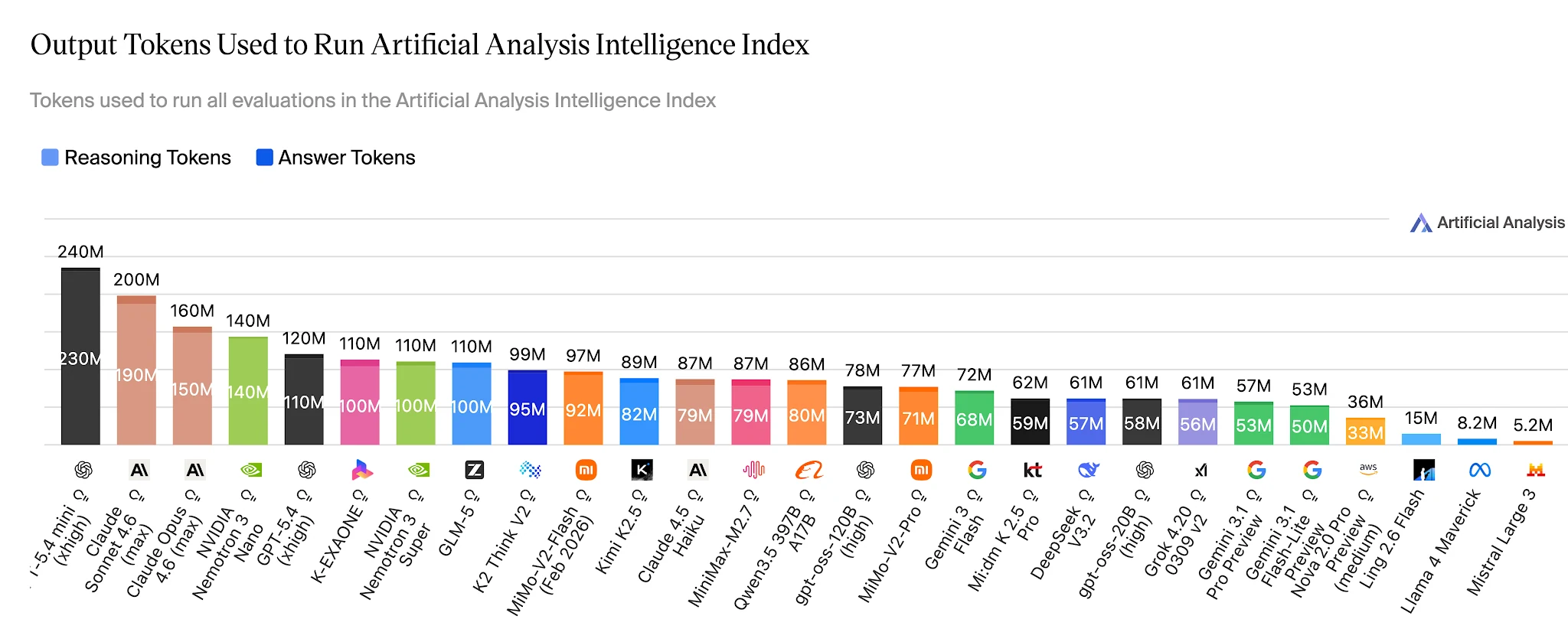
Tokens de sortie pour réaliser l’Artificial Analysis Intelligence Index – Ling 2.6 Flash : ~15M vs Nemotron-3-Super : ~110M+ [Source : Artificial Analysis]
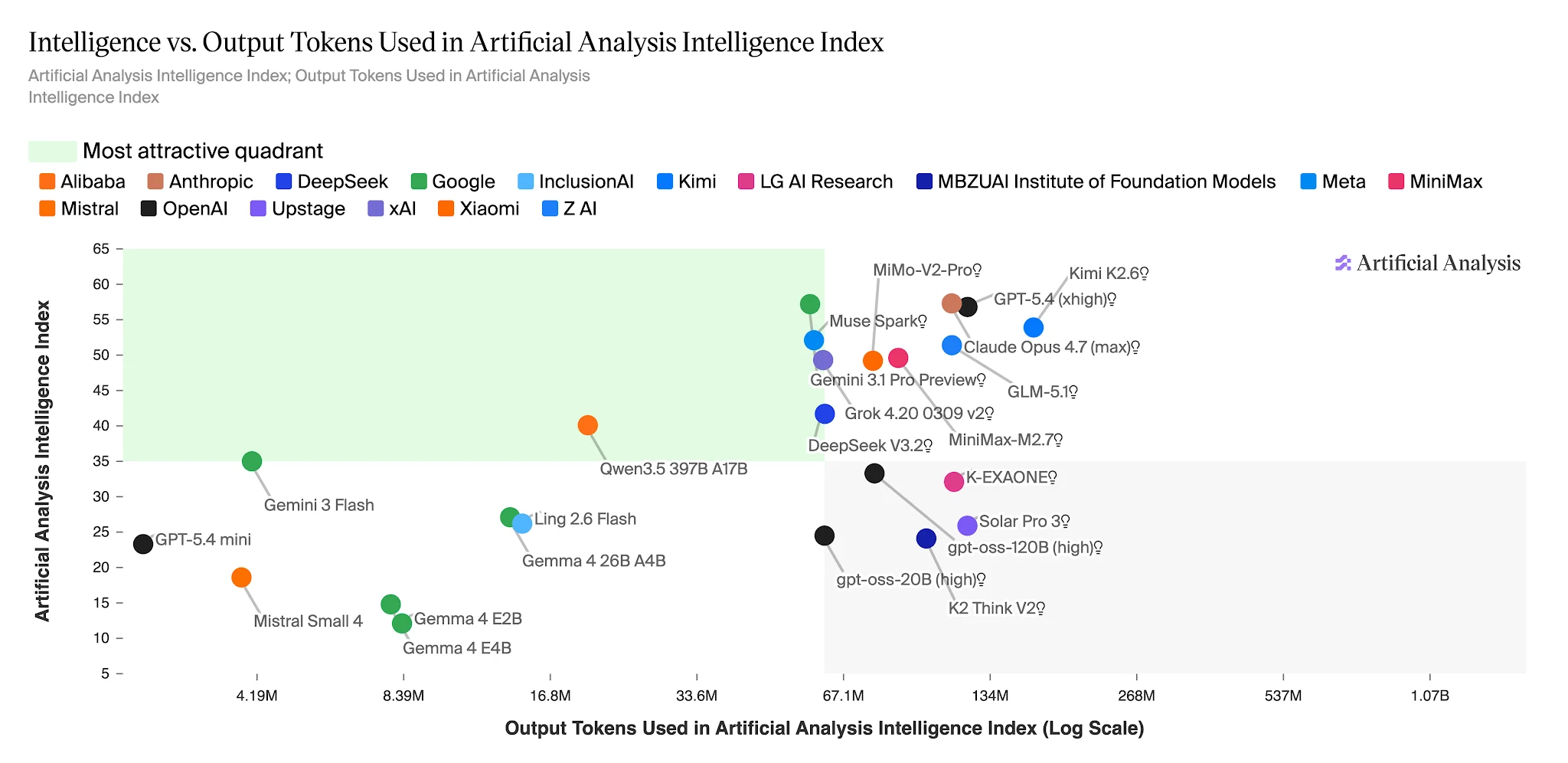
Intelligence vs. Tokens de sortie : Ling 2.6 Flash se situe dans la zone de haute efficacité [Source : Artificial Analysis]
Résultats des benchmarks : où Ling-2.6-flash est leader
Évalué sur 19 benchmarks dans 7 catégories contre Qwen3-57B-A14B, Qwen3.5-122B-A10B, GLM-4.5-Air, Nemotron-3-Super et MiniMax-M1-80k :
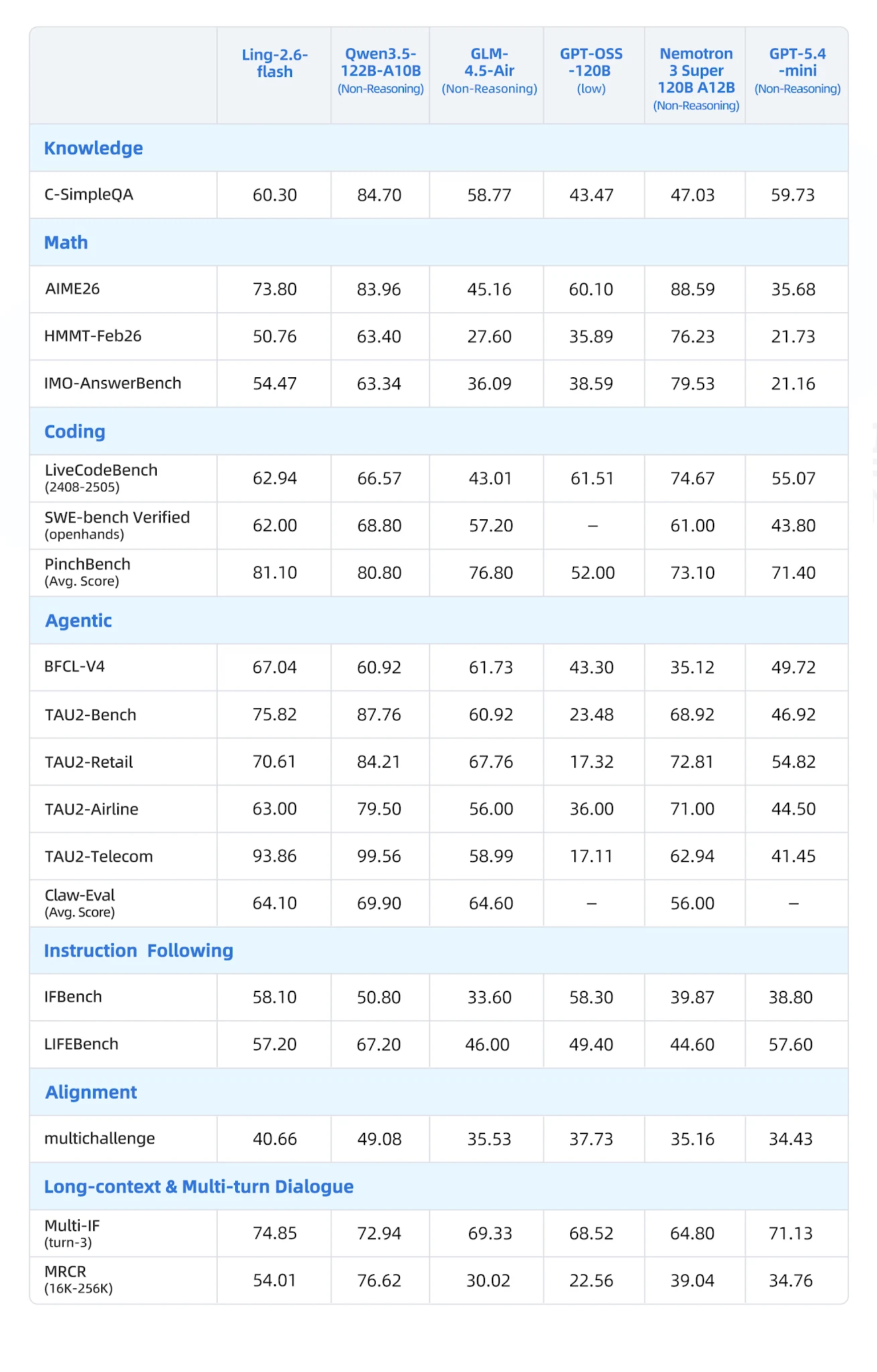
Tableau complet des benchmarks [Source : Blog officiel Ling]
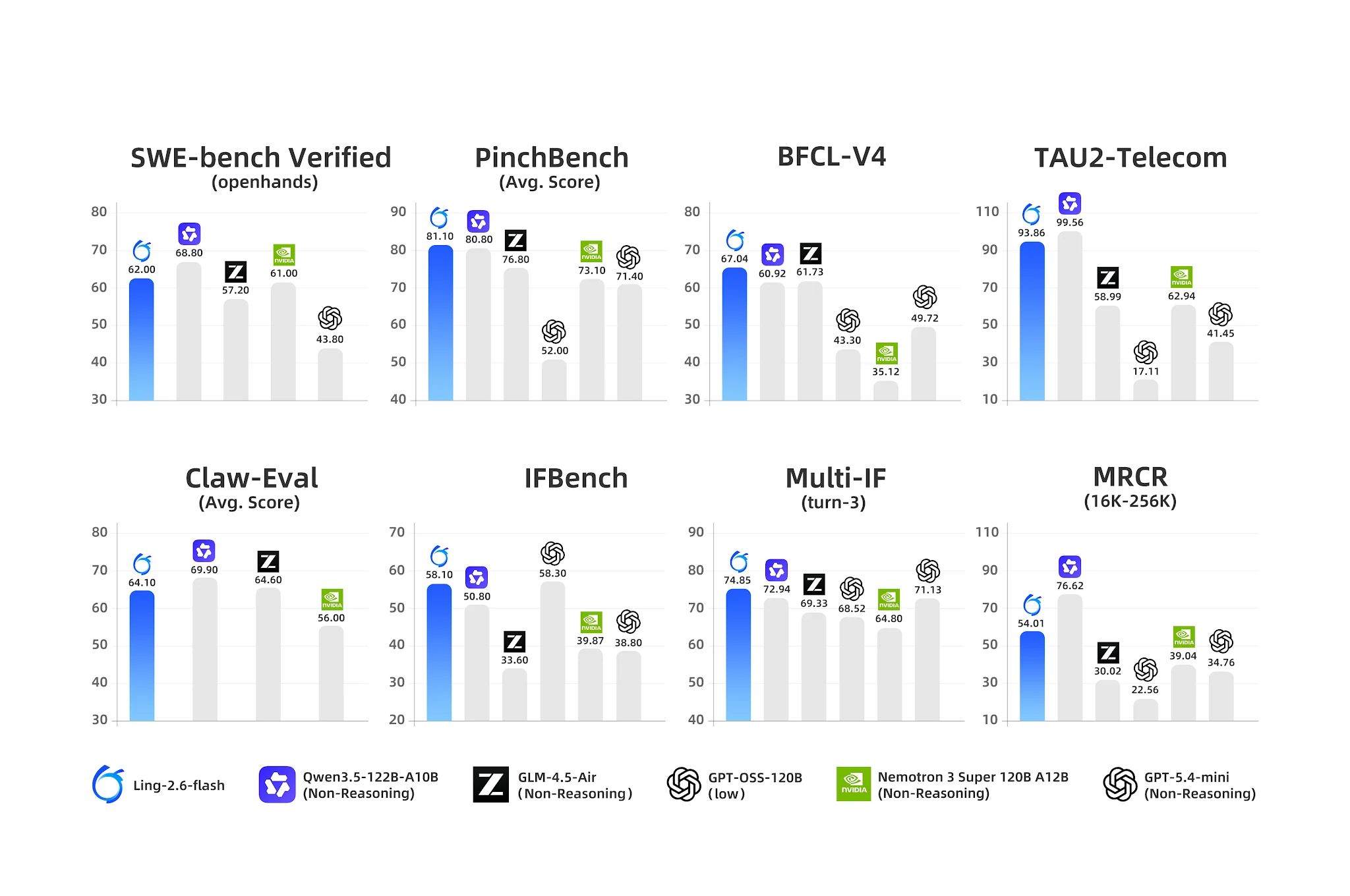
Benchmarks d’agents : Ling-2.6-flash leader sur l’utilisation d’outils et le multi-tours IF [Source : Blog officiel Ling]
Où Ling-2.6-flash est leader
- BFCL-V4 (Appel de fonctions) : 67,04 – concurrent le plus proche Nemotron à 35,12 (écart de 90%)
- PinchBench (Tâches d’agents) : 81,10 vs Nemotron 73,10
- IFBench (Suivi d’instructions) : 58,10
- Multi-IF Turn-3 : 74,85 – forte persistance des instructions multi-tours
- LongBench-v2 : 54,80 – meilleur dans la catégorie long contexte
- CCAlignBench (Chinois) : 7,44 – meilleur parmi tous les modèles testés
Où les autres sont leaders
- Mathématiques (AIME 2025, MATH-500) : Nemotron-3-Super et les variantes de raisonnement Qwen gagnent
- Codage (LiveCodeBench) : Qwen3.5-122B-A10B est leader ; Ling est compétitif mais pas en tête
- GPQA-Diamond : GLM-4.5-Air et Nemotron obtiennent des scores plus élevés
Tableau comparatif rapide
| Modèle | Paramètres actifs | BFCL-V4 ↑ | PinchBench ↑ | Débit décodage @ 65K ↑ | Tokens de sortie ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7,4B | 67,04 | 81,10 | 4,38× | ~15M |
| Nemotron-3-Super | 49B total | 35,12 | 73,10 | 3,37× | ~110M+ |
| Qwen3.5-122B-A10B | 10B | — | 78,20 | 1,90× | — |
| GLM-4.5-Air | — | 50,67 | 73,30 | 1,00× (référence) | — |
| MiniMax-M1-80k | — | 44,07 | 75,70 | — | — |
| Qwen3-57B-A14B | 14B | 52,32 | 76,30 | — | — |
Accéder à Ling-2.6-flash propulsé par Novita AI
Ling-2.6-flash est disponible dès maintenant. Essayez-le sur OpenRouter – niveau gratuit, aucune configuration requise :
Commencez sur OpenRouter — inclusionai/ling-2.6-flash:free. Niveau gratuit disponible, aucune modification de code nécessaire pour les clients compatibles OpenAI.
Ling-2.6-flash fonctionne avec LangChain, LlamaIndex et OpenAI Agent SDK – aucun adaptateur ni changement de code nécessaire. Le streaming, l’appel de fonctions et les sorties structurées sont tous pris en charge. Associez-le à Novita Agent Sandbox pour une exécution sécurisée de code en parallèle de l’inférence.
Ce que dit la communauté
Ling-2.6-flash a été lancé sur OpenRouter sous le nom « Elephant Alpha » avant la révélation officielle. En quelques jours, il avait traité ~100B de tokens et trônait en tête du classement des tendances de la plateforme – sans aucune annonce.
« Ling-2.6-flash est plutôt orienté travail. Environ 75 % moins verbeux que les gros modèles. Encore un peu de code passe-partout, mais quand il s’agit d’écrire du code – c’est presque parfait. »
— Utilisateur précoce sur X/Twitter
« Je viens d’essayer Ling-2.6-flash sur quelques tâches de codage llama.cpp. Bien mieux que prévu. Il gère les appels d’outils de manière fiable et n’alourdit pas la sortie avec des explications inutiles. »
— Utilisateur précoce sur Reddit
Le commentaire « 75 % moins verbeux » correspond exactement à l’écart de 15M vs 110M tokens sur les benchmarks d’Artificial Analysis. L’objectif d’entraînement semble récompenser les réponses directes et complètes – une propriété qui se cumule en économies de coûts à l’échelle de la production.
Qui devrait utiliser Ling-2.6-flash ?
- ✅ Agents d’appel de fonctions / d’utilisation d’outils à fort volume – leadership BFCL-V4 avec une large marge
- ✅ Sessions d’agents multi-tours – cohérent sur de longs historiques de conversation
- ✅ Pipelines RAG long contexte – fenêtre de 256K tokens, préremplissage à coût linéaire
- ✅ Déploiements en production sensibles aux coûts – ~7× moins de tokens de sortie que Nemotron
- ✅ Applications en chinois – meilleur CCAlignBench
- ❌ Compétitions mathématiques / raisonnement style AIME – utilisez Nemotron ou les variantes de raisonnement Qwen
- ❌ Performance maximale sur les benchmarks de codage – Qwen3.5-122B-A10B est leader
Commencer
Ling-2.6-flash est disponible dès maintenant. Accédez-y via la page du modèle OpenRouter – niveau gratuit immédiatement disponible, aucune modification de code nécessaire pour les clients compatibles OpenAI. L’Agent Sandbox est également disponible pour les équipes combinant inférence et exécution sécurisée.
Questions fréquemment posées
Qu’est-ce que Ling-2.6-flash ?
Ling-2.6-flash est un modèle MoE de 104B (7,4B actifs) avec attention linéaire hybride, fenêtre de contexte de 256K et une vitesse d’inférence pouvant atteindre 340 tokens/s – optimisé pour les charges de travail d’agents.
Comment utiliser Ling-2.6-flash via l’API ?
Utilisez OpenRouter avec votre clé API Novita AI (BYOK). Ajoutez votre clé Novita sur openrouter.ai/settings/integrations, sélectionnez Novita comme fournisseur, et acheminez les requêtes vers inclusionai/ling-2.6-flash:free via le point de terminaison compatible OpenAI :
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer YOUR_OPENROUTER_API_KEY
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "YOUR_NOVITA_API_KEY"
},
"messages": [{"role": "user", "content": "Hello !"}]
}
Consultez la documentation BYOK d’OpenRouter pour la configuration complète. En utilisant BYOK, OpenRouter ne facture aucun frais – vous payez Novita directement au tarif du niveau gratuit.
Comment Ling-2.6-flash se compare-t-il à Nemotron-3-Super ?
Ling est leader sur BFCL-V4 (67,04 contre 35,12), PinchBench (81,10 contre 73,10), et utilise ~7× moins de tokens de sortie. Nemotron est leader en mathématiques. Pour les charges de travail d’agents, Ling-2.6-flash est le meilleur choix économique.
Quelle est la fenêtre de contexte ?
256K tokens (262 144), avec un préremplissage à coût linéaire grâce à l’attention linéaire hybride. Les sessions RAG longues et multi-tours passent à l’échelle efficacement.
Ling-2.6-flash est-il open source ?
Les variantes BF16, FP8 et INT4 ainsi que les noyaux Linghe sont prévus pour une publication open-source. Calendrier à déterminer – consultez le site officiel de Ling pour les mises à jour.
Vous pourriez aussi aimer
- Kimi K2.6 : Agent open-source pour des sessions de codage de 13 heures – Modèle MoE 1T avec contexte 256K et 58,6% SWE-Bench Pro
- API GLM-5.1 sur Novita AI : Modèle agentique à long horizon – En tête du SWE-Bench Pro à 58,4, exécute des tâches de codage autonomes pendant 8 heures
- Meilleurs fournisseurs d’API d’inférence pour modèles open-source en 2026 – Comparez Novita AI, Together AI, Fireworks, DeepInfra et Groq



