

- Was ist Ling-2.6-flash?
- Hybride lineare Architektur: Wie Ling-2.6-flash im Maßstab schneller wird
- Token-Effizienz: 15M vs. 110M, um dieselben Benchmarks zu lösen
- Benchmark-Ergebnisse: Wo Ling-2.6-flash führt
- Kurzvergleichstabelle
- Zugriff auf Ling-2.6-flash, unterstützt von Novita AI
- Was die Community sagt
- Wer sollte Ling-2.6-flash verwenden?
- Erste Schritte
- Häufig gestellte Fragen
Die Kosten für Agent-Token explodieren: mehrstufige Tool-Aufrufe, Planung mit langem Kontext und lange Ausgaben verwandeln das, was nach einem günstigen Preis pro Token aussieht, in eine sehr teure monatliche Rechnung. Die Antwort der Branche – längere Reasoning-Ketten, um Benchmark-Ergebnisse zu verbessern – macht die Wirtschaftlichkeit noch schlechter.
Ling-2.6-flash ist ein andersartiges Modell. Basierend auf einer hybriden linearen Attention-Architektur erreicht es bis zu 340 Tokens/s auf 4× H20-Hardware, bietet 2,2× den Prefill-Durchsatz von Nemotron-3-Super und benötigt nur etwa ~15M Ausgabetokens, um den gesamten Artificial Analysis Intelligence Index zu absolvieren – etwa ein Zehntel dessen, was Nemotron-3-Super verbraucht. Kurz gesagt: Ling-2.6-flash ist ein 104B MoE-Modell (7,4B aktiv) mit einem 256K-Kontextfenster, optimiert für Agenten-Workloads, bei denen Geschwindigkeit, Kosten und Stabilität wichtiger sind als ein einzelner Benchmark-Wert. Es ist jetzt auf Novita AI verfügbar.
Was ist Ling-2.6-flash?
Ling-2.6-flash ist ein spärliches Mixture-of-Experts-Sprachmodell mit 104B Gesamtparametern und 7,4B aktiven Parametern pro Forward-Pass. Entwickelt vom Ling-Team (InclusionAI), ist es als Modell der Kategorie „Instant" konzipiert – optimiert für den produktiven Einsatz von Agenten, bei dem Token-Verbrauch und Latenz echte Kosten sind, nicht nur Benchmark-Schlagzeilen.
- 104B gesamt / 7,4B aktive Parameter – MoE-Architektur mit hoher Spärlichkeit
- 256K Token-Kontextfenster – ermöglicht durch hybride lineare Attention
- 340 Tokens/s Spitzendurchsatz auf 4× H20 (TP=4)
- Hybrid 1:7 MLA + Lightning Linear Attention – 4× Durchsatz bei langen Kontexten
- Top-Agent-Benchmarks – führend bei BFCL-V4 (67,04), PinchBench (81,10), IFBench (58,10), Multi-IF Turn-3 (74,85)
- BF16-, FP8- und INT4-Varianten – Open-Source-Veröffentlichung über Linghe geplant
- In Produktion validiert – ~100B tägliche Tokens auf OpenRouter innerhalb weniger Tage nach dem Start
Hybride lineare Architektur: Wie Ling-2.6-flash im Maßstab schneller wird
Die meisten MoE-Modelle kombinieren die Standard-Transformer-Attention mit einer spärlichen FFN-Schicht. Ling-2.6-flash ersetzt den Großteil der Attention durch eine Lightning Linear-Schicht und schafft so einen 1:7 MLA + Lightning Linear Hybrid. Die Attention-Kosten steigen linear mit der Kontextlänge statt quadratisch – entscheidend für lange Agenten-Sitzungen.
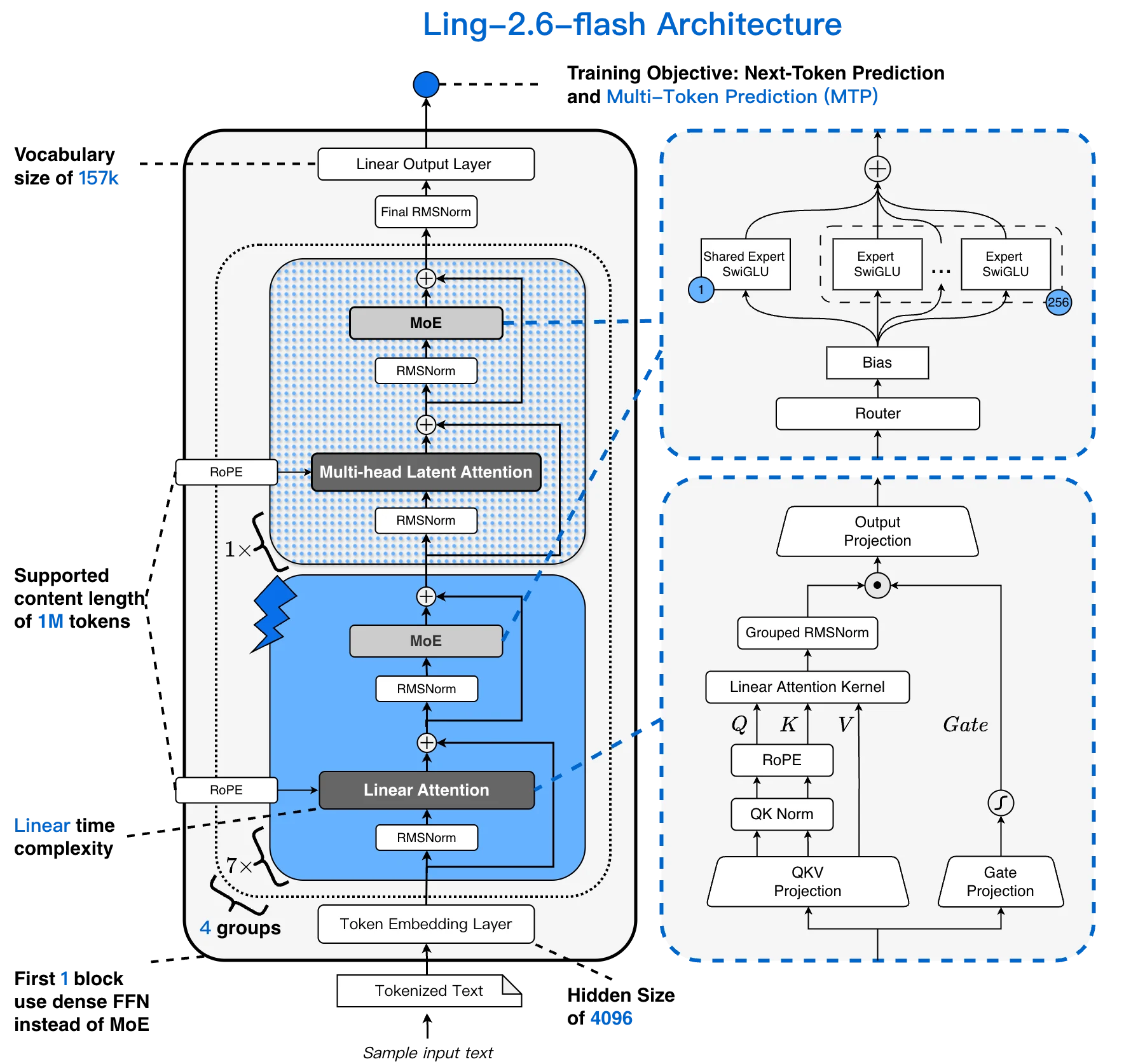
Ling-2.6-flash Architektur: 157K Vokabular, 256K Kontext, 1:7 MLA + Lightning Linear Hybrid, 256 wählbare Experten [Quelle: Ling Offizieller Blog]
Decode-Durchsatz: Bis zu 4,38× bei langen Ausgaben
Auf 4× H20-3e (TP=4, Batchgröße 32) erreicht Ling-2.6-flash 4,38× normalisierten Decode-Durchsatz bei einer Ausgabelänge von 65.536 Token im Vergleich zur GLM-4.5-Air-Baseline. Qwen3.5-122B-A10B erreicht 1,90×; Nemotron-3-Super 3,37×. Die Lücke vergrößert sich mit zunehmender Aufgabenausgabelänge.
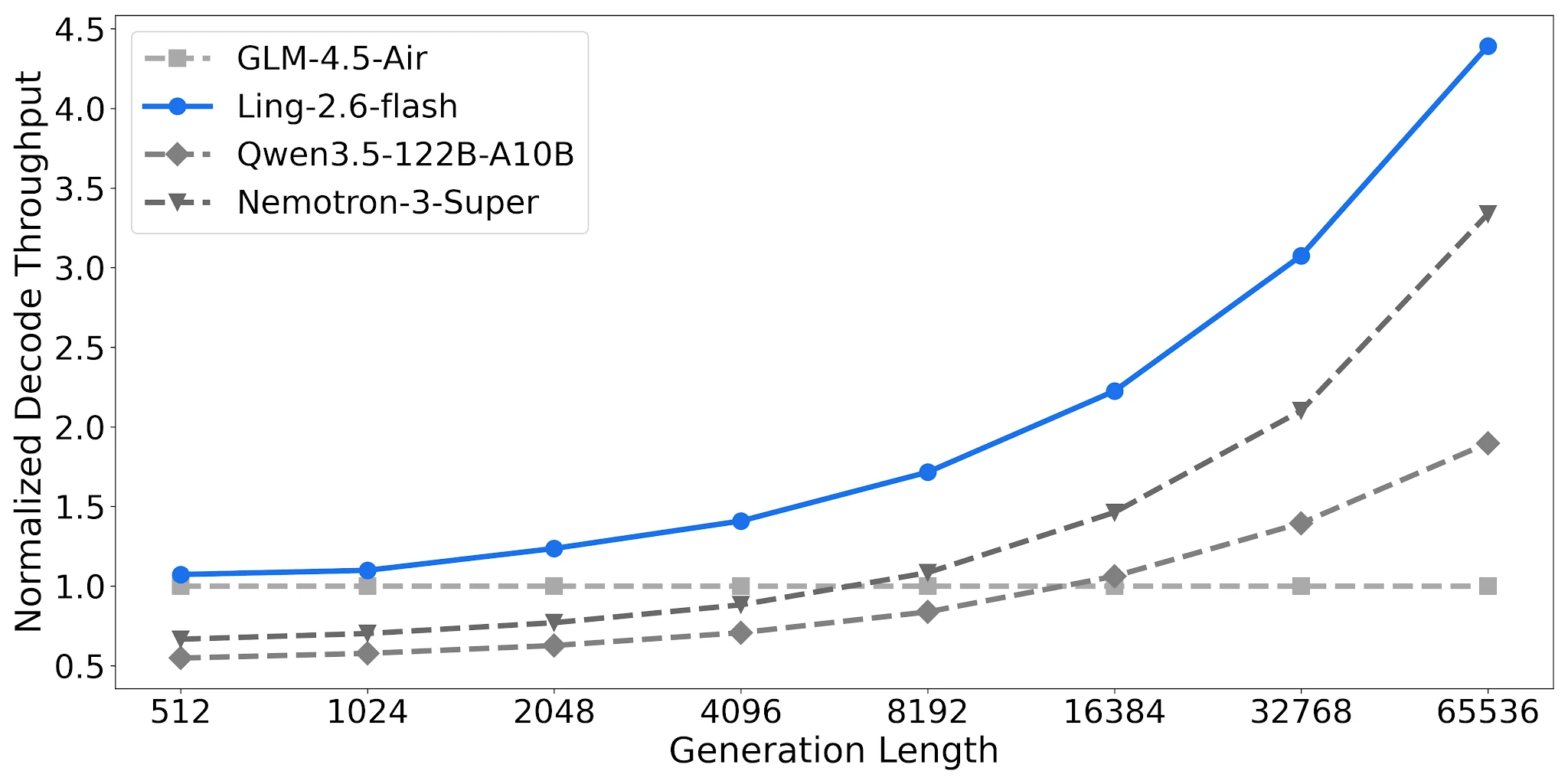
Decode-Durchsatz-Vergleich, 4× H20-3e, TP=4, Batch=32 [Quelle: Ling Offizieller Blog]
Prefill-Durchsatz: 2,2× Nemotron bei langen Kontexten
Ling-2.6-flash erreicht ~4,68× normalisierten Prefill-Durchsatz bei 65K Kontext vs. ~2,12× für Nemotron-3-Super. Für RAG-Pipelines und mehrstufige Agenten mit langen System-Prompts reduziert dies direkt die Kosten pro Anfrage.
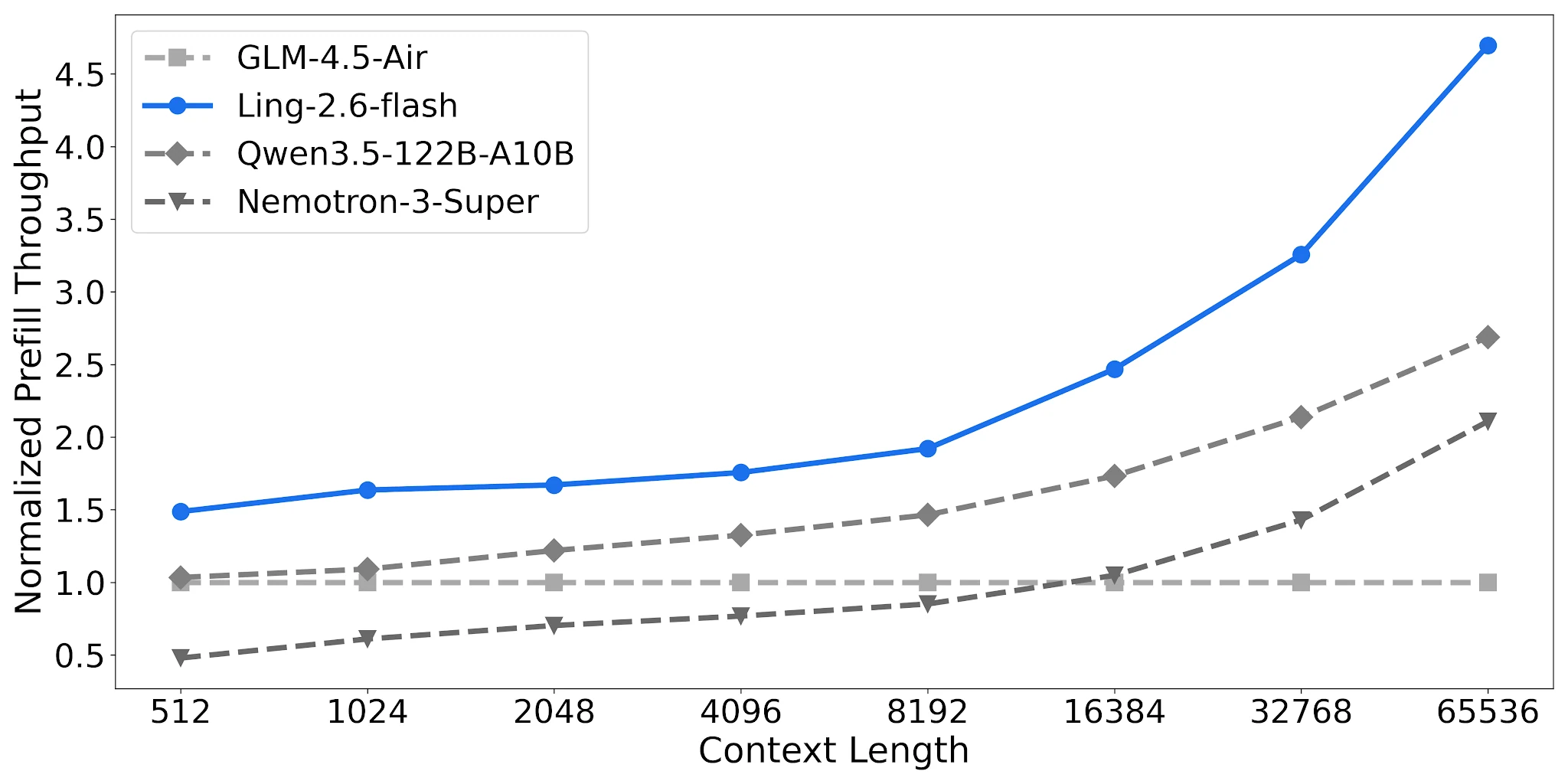
Prefill-Durchsatz-Vergleich, 4× H20-3e, TP=4, Batch=32 [Quelle: Ling Offizieller Blog]
Token-Effizienz: 15M vs. 110M, um dieselben Benchmarks zu lösen
Im gesamten Artificial Analysis Intelligence Index benötigt Ling-2.6-flash ~15M Ausgabetokens. Nemotron-3-Super benötigt 110M+ – etwa 7× mehr – für ein Modell, das bei Agentenaufgaben niedrigere Werte erzielt. Für Anwendungen, die täglich Hunderttausende von Agentenaufgaben ausführen, ist diese Lücke ein direkter Posten im Kostenbudget.
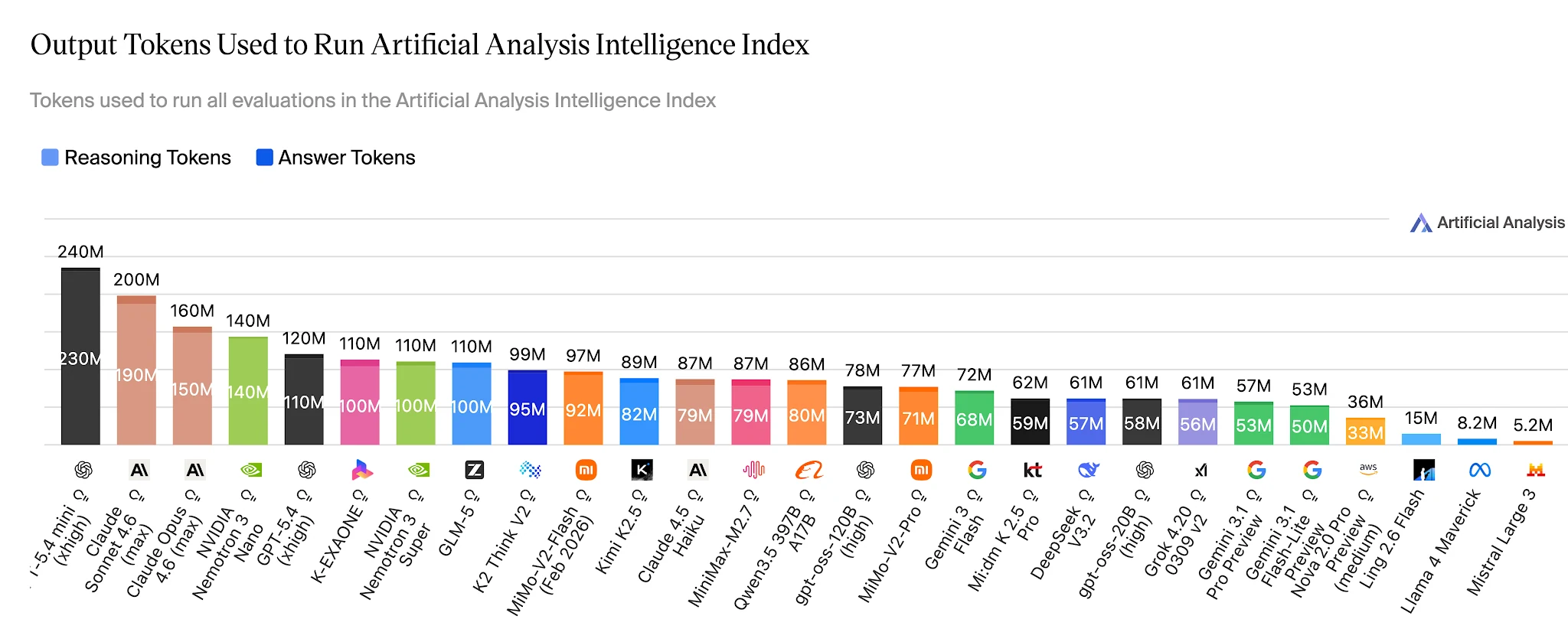
Ausgabetokens zum Absolvieren des Artificial Analysis Intelligence Index – Ling 2.6 Flash: ~15M vs. Nemotron-3-Super: ~110M+ [Quelle: Artificial Analysis]
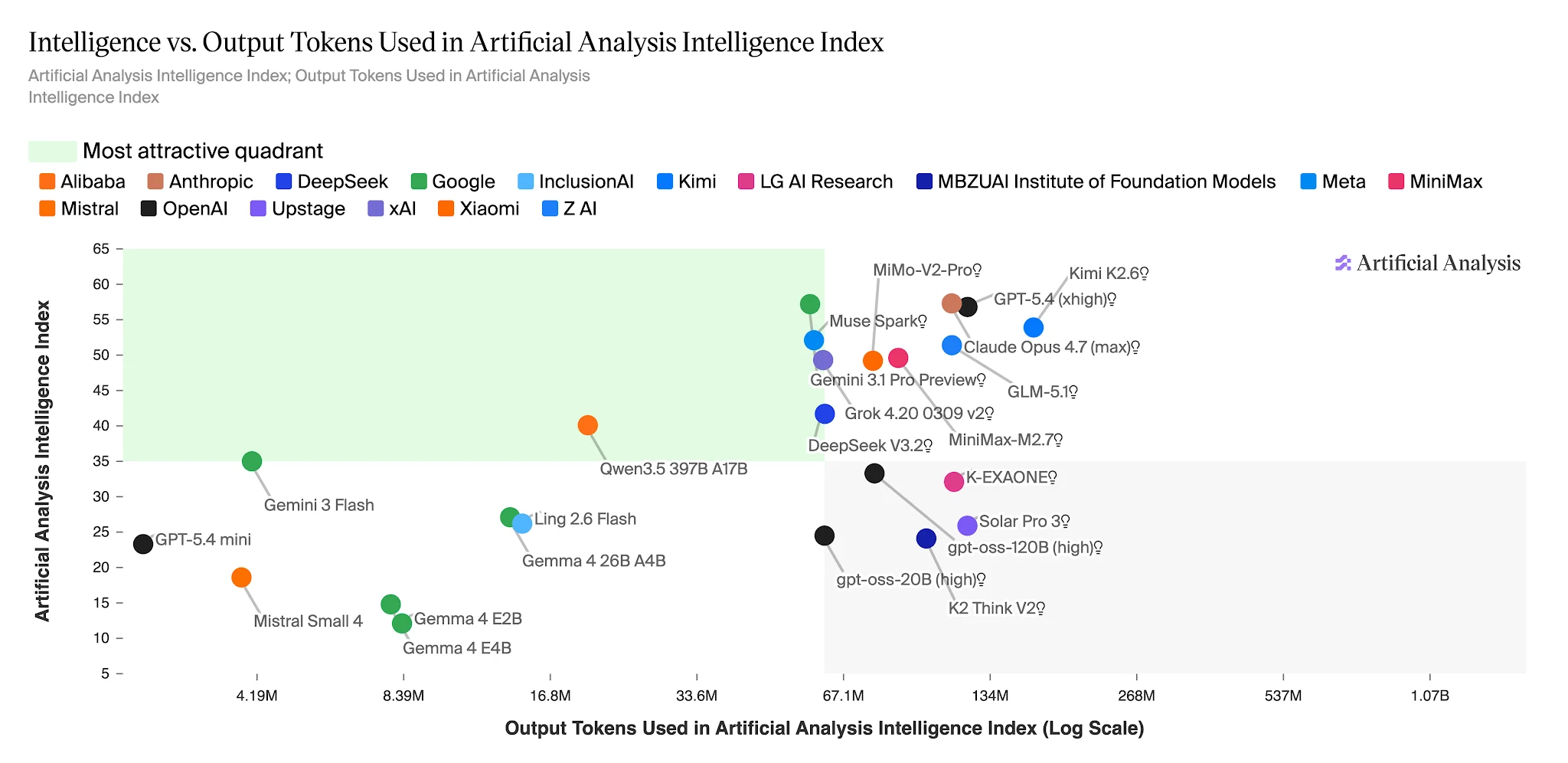
Intelligenz vs. Ausgabetokens: Ling 2.6 Flash liegt in der hocheffizienten Zone [Quelle: Artificial Analysis]
Benchmark-Ergebnisse: Wo Ling-2.6-flash führt
Bewertet auf 19 Benchmarks in 7 Kategorien gegen Qwen3-57B-A14B, Qwen3.5-122B-A10B, GLM-4.5-Air, Nemotron-3-Super und MiniMax-M1-80k:
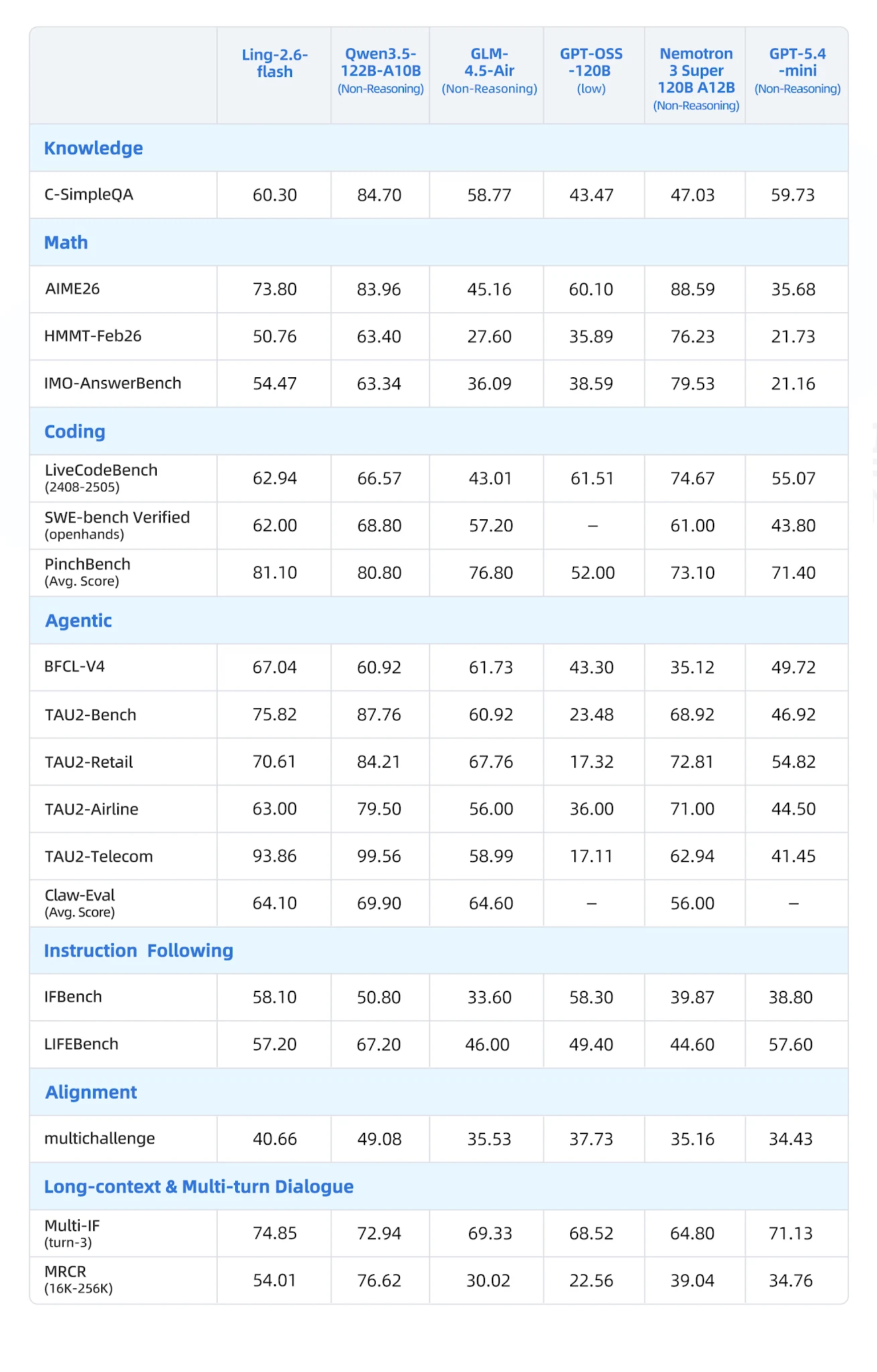
Umfassende Benchmark-Tabelle [Quelle: Ling Offizieller Blog]
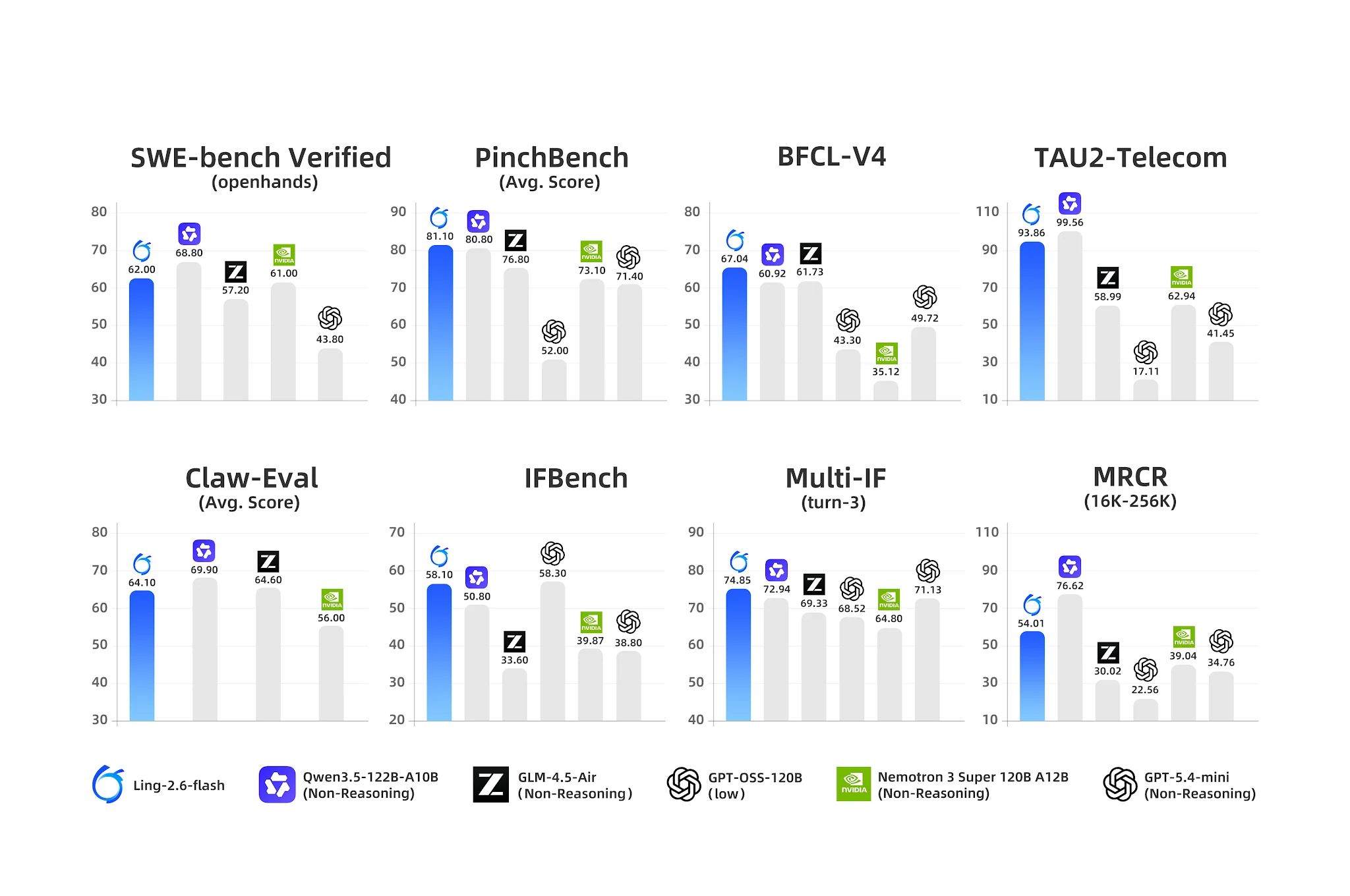
Agent-Benchmarks: Ling-2.6-flash führt bei Tool-Nutzung und mehrstufigem IF [Quelle: Ling Offizieller Blog]
Wo Ling-2.6-flash führt
- BFCL-V4 (Funktionsaufruf): 67,04 – nächster Konkurrent Nemotron bei 35,12 (90% Abstand)
- PinchBench (Agentenaufgaben): 81,10 vs. Nemotron 73,10
- IFBench (Instruktionsbefolgung): 58,10
- Multi-IF Turn-3: 74,85 – starke Persistenz bei mehrstufiger Instruktionsbefolgung
- LongBench-v2: 54,80 – Spitze in der Kategorie Langkontext
- CCAlignBench (Chinesisch): 7,44 – am besten von allen getesteten Modellen
Wo andere führen
- Mathematik (AIME 2025, MATH-500): Nemotron-3-Super und Qwen3-Reasoning-Varianten gewinnen
- Coding (LiveCodeBench): Qwen3.5-122B-A10B führt; Ling ist konkurrenzfähig, aber nicht an der Spitze
- GPQA-Diamond: GLM-4.5-Air und Nemotron erzielen höhere Werte
Kurzvergleichstabelle
| Modell | Aktive Parameter | BFCL-V4 ↑ | PinchBench ↑ | Decode TP @ 65K ↑ | Ausgabetokens ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7,4B | 67,04 | 81,10 | 4,38× | ~15M |
| Nemotron-3-Super | 49B gesamt | 35,12 | 73,10 | 3,37× | ~110M+ |
| Qwen3.5-122B-A10B | 10B | — | 78,20 | 1,90× | — |
| GLM-4.5-Air | — | 50,67 | 73,30 | 1,00× (Baseline) | — |
| MiniMax-M1-80k | — | 44,07 | 75,70 | — | — |
| Qwen3-57B-A14B | 14B | 52,32 | 76,30 | — | — |
Zugriff auf Ling-2.6-flash, unterstützt von Novita AI
Ling-2.6-flash ist jetzt verfügbar. Testen Sie es auf OpenRouter – kostenlose Stufe, keine Einrichtung erforderlich:
Loslegen auf OpenRouter — inclusionai/ling-2.6-flash:free. Kostenlose Stufe verfügbar, keine Codeänderungen für OpenAI-kompatible Clients erforderlich.
Ling-2.6-flash funktioniert mit LangChain, LlamaIndex und OpenAI Agent SDK – kein Adapter oder Codeänderung erforderlich. Streaming, Funktionsaufrufe und strukturierte Ausgaben werden alle unterstützt. Kombinieren Sie es mit Novita Agent Sandbox für sichere Codeausführung neben der Inferenz.
Was die Community sagt
Ling-2.6-flash wurde auf OpenRouter als „Elephant Alpha" vor der offiziellen Enthüllung gestartet. Innerhalb weniger Tage hatte es ~100B Tokens verarbeitet und die Trendwertung der Plattform angeführt – ohne Ankündigung.
„Ling-2.6-flash ist irgendwie arbeitsorientiert. Etwa 75% weniger wortreich als große Modelle. Immer noch etwas Standardtext, aber wenn es ums Schreiben von Code geht – es ist fast perfekt."
— Früher Nutzer auf X/Twitter
„Habe Ling-2.6-flash gerade bei ein paar llama.cpp-Coding-Aufgaben ausprobiert. Viel besser als erwartet. Verarbeitet Tool-Aufrufe zuverlässig und bläht die Ausgabe nicht mit unnötigen Erklärungen auf."
— Früher Nutzer auf Reddit
Der Kommentar „75% weniger wortreich" entspricht genau der Lücke von 15M gegenüber 110M Token bei den Artificial Analysis-Benchmarks. Das Trainingsziel scheint direkte, vollständige Antworten zu belohnen – eine Eigenschaft, die sich bei Produktionsskalierung in Kosteneinsparungen niederschlägt.
Wer sollte Ling-2.6-flash verwenden?
- ✅ Hochvolumige Funktionsaufrufe / Tool-Nutzungs-Agenten – BFCL-V4-Führung mit großem Abstand
- ✅ Mehrstufige Agenten-Sitzungen – konsistent über lange Gesprächsverläufe
- ✅ RAG-Pipelines mit langem Kontext – 256K Token-Fenster, Prefill mit linearen Kosten
- ✅ Kostensensitive Produktionsbereitstellungen – ~7× weniger Ausgabetokens als Nemotron
- ✅ Chinesischsprachige Anwendungen – Spitzenwert bei CCAlignBench
- ❌ Mathe-Wettbewerbe / AIME-ähnliches Reasoning – verwenden Sie Nemotron oder Qwen3-Reasoning-Varianten
- ❌ Maximale Coding-Benchmark-Leistung – Qwen3.5-122B-A10B führt
Erste Schritte
Ling-2.6-flash ist jetzt verfügbar. Greifen Sie über die OpenRouter-Modellseite darauf zu – kostenlose Stufe sofort verfügbar, keine Codeänderungen für OpenAI-kompatible Clients erforderlich. Die Agent Sandbox ist ebenfalls für Teams verfügbar, die Inferenz mit sicherer Ausführung kombinieren.
Häufig gestellte Fragen
Was ist Ling-2.6-flash?
Ling-2.6-flash ist ein 104B MoE-Modell (7,4B aktiv) mit hybrider linearer Attention, 256K Kontextfenster und bis zu 340 Tokens/s Inferenzgeschwindigkeit – optimiert für Agenten-Workloads.
Wie verwende ich Ling-2.6-flash über die API?
Verwenden Sie OpenRouter mit Ihrem Novita AI API-Key (BYOK). Fügen Sie Ihren Novita-Key unter openrouter.ai/settings/integrations hinzu, wählen Sie Novita als Anbieter aus und leiten Sie Anfragen an inclusionai/ling-2.6-flash:free über den OpenAI-kompatiblen Endpunkt weiter:
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer YOUR_OPENROUTER_API_KEY
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "YOUR_NOVITA_API_KEY"
},
"messages": [{"role": "user", "content": "Hello!"}]
}
Siehe OpenRouter BYOK-Dokumentation für die vollständige Einrichtung. Bei Verwendung von BYOK erhebt OpenRouter keine Gebühren – Sie zahlen Novita direkt zu den Preisen der kostenlosen Stufe.
Wie schneidet Ling-2.6-flash im Vergleich zu Nemotron-3-Super ab?
Ling führt bei BFCL-V4 (67,04 vs. 35,12), PinchBench (81,10 vs. 73,10) und benötigt ~7× weniger Ausgabetokens. Nemotron führt bei Mathematik. Für Agenten-Workloads ist Ling-2.6-flash die wirtschaftlichere Wahl.
Wie groß ist das Kontextfenster?
256K Token (262.144), mit Prefill zu linearen Kosten dank hybrider linearer Attention. Lange RAG- und mehrstufige Sitzungen skalieren effizient.
Ist Ling-2.6-flash Open Source?
BF16-, FP8- und INT4-Varianten sowie Linghe-Kernel sind für eine Open-Source-Veröffentlichung geplant. Zeitplan noch offen – prüfen Sie die offizielle Ling-Website auf Updates.
Das könnte Ihnen auch gefallen
- Kimi K2.6: Open-Source-Agent für 13-stündige Coding-Sessions – 1T MoE-Modell mit 256K Kontext und 58,6% SWE-Bench Pro
- GLM-5.1 API auf Novita AI: Langfristiges agentisches Modell – Spitzenwert bei SWE-Bench Pro mit 58,4, führt 8 Stunden lang autonome Coding-Aufgaben aus
- Top Inference API-Anbieter für Open-Source-Modelle im Jahr 2026 – Vergleich von Novita AI, Together AI, Fireworks, DeepInfra und Groq



