

智能体 Token 账单正在螺旋上升:多步骤工具调用、长上下文规划和扩展输出,使得原本看似便宜的每 Token 价格变成了非常昂贵的月度账单。行业对此的回应——更长的推理链以推高基准分数——让经济性问题雪上加霜。
Ling-2.6-flash 是一款截然不同的模型。它基于混合线性注意力架构构建,在 4× H20 硬件上可达到高达 340 tokens/s,预填充吞吐量是 Nemotron-3-Super 的 2.2 倍,并且完成完整的人工分析智能指数仅需约 1,500 万输出 Token——大约是 Nemotron-3-Super 消耗量的十分之一。简而言之:Ling-2.6-flash 是一款 104B MoE 模型(7.4B 激活参数),拥有 256K 上下文窗口,针对智能体工作负载进行了优化,在这些场景中速度、成本和稳定性比单一基准指标更重要。现已在 Novita AI 上可用。
什么是 Ling-2.6-flash?
Ling-2.6-flash 是一款稀疏混合专家语言模型,拥有 1040 亿总参数 和 每次前向传递 7.4B 激活参数。由 Ling 团队(InclusionAI)开发,它被设计为“即时”类别模型——针对生产级智能体部署进行了优化,其中 Token 消耗和延迟是真实成本,而不仅仅是基准测试的标题数字。
- 104B 总参数 / 7.4B 激活参数 — 高稀疏度的 MoE 架构
- 256K Token 上下文窗口 — 由混合线性注意力支持
- 4× H20 上的峰值吞吐量 340 tokens/s(TP=4)
- 混合 1:7 MLA + Lightning 线性注意力 — 长上下文下吞吐量提升 4 倍
- 顶级智能体基准 — 在 BFCL-V4(67.04)、PinchBench(81.10)、IFBench(58.10)、Multi-IF Turn-3(74.85)上领先
- BF16、FP8 和 INT4 变体 — 计划通过 Linghe 进行开源发布
- 生产验证 — 发布后数日内在 OpenRouter 上每日处理约 1000 亿 Token
混合线性架构:Ling-2.6-flash 如何实现规模加速
大多数 MoE 模型将标准 Transformer 注意力与稀疏 FFN 层配对。Ling-2.6-flash 将大部分注意力替换为 Lightning 线性层,形成 1:7 MLA + Lightning 线性混合。注意力成本随上下文长度线性增长而非二次增长——这对长智能体会话至关重要。
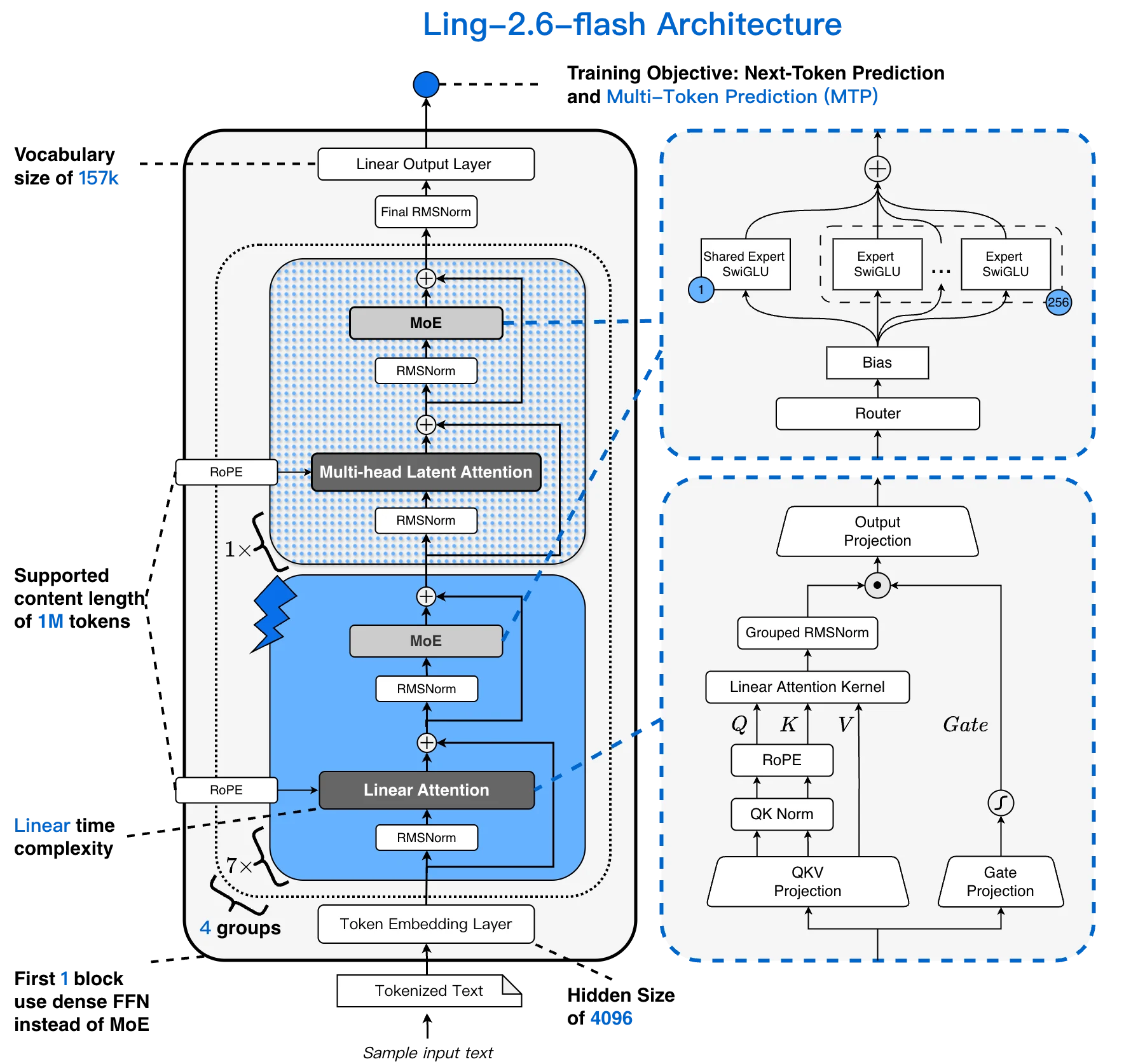
Ling-2.6-flash 架构:157K 词汇表、256K 上下文、1:7 MLA + Lightning 线性混合、256 个可选择专家 [来源:Ling 官方博客]
解码吞吐量:长输出下高达 4.38 倍
在 4× H20-3e(TP=4,批量大小=32)上,Ling-2.6-flash 在 65,536 Token 输出长度下达到 4.38 倍归一化解码吞吐量(相对于 GLM-4.5-Air 基线)。Qwen3.5-122B-A10B 达到 1.90 倍;Nemotron-3-Super 为 3.37 倍。差距随着任务输出长度增加而扩大。
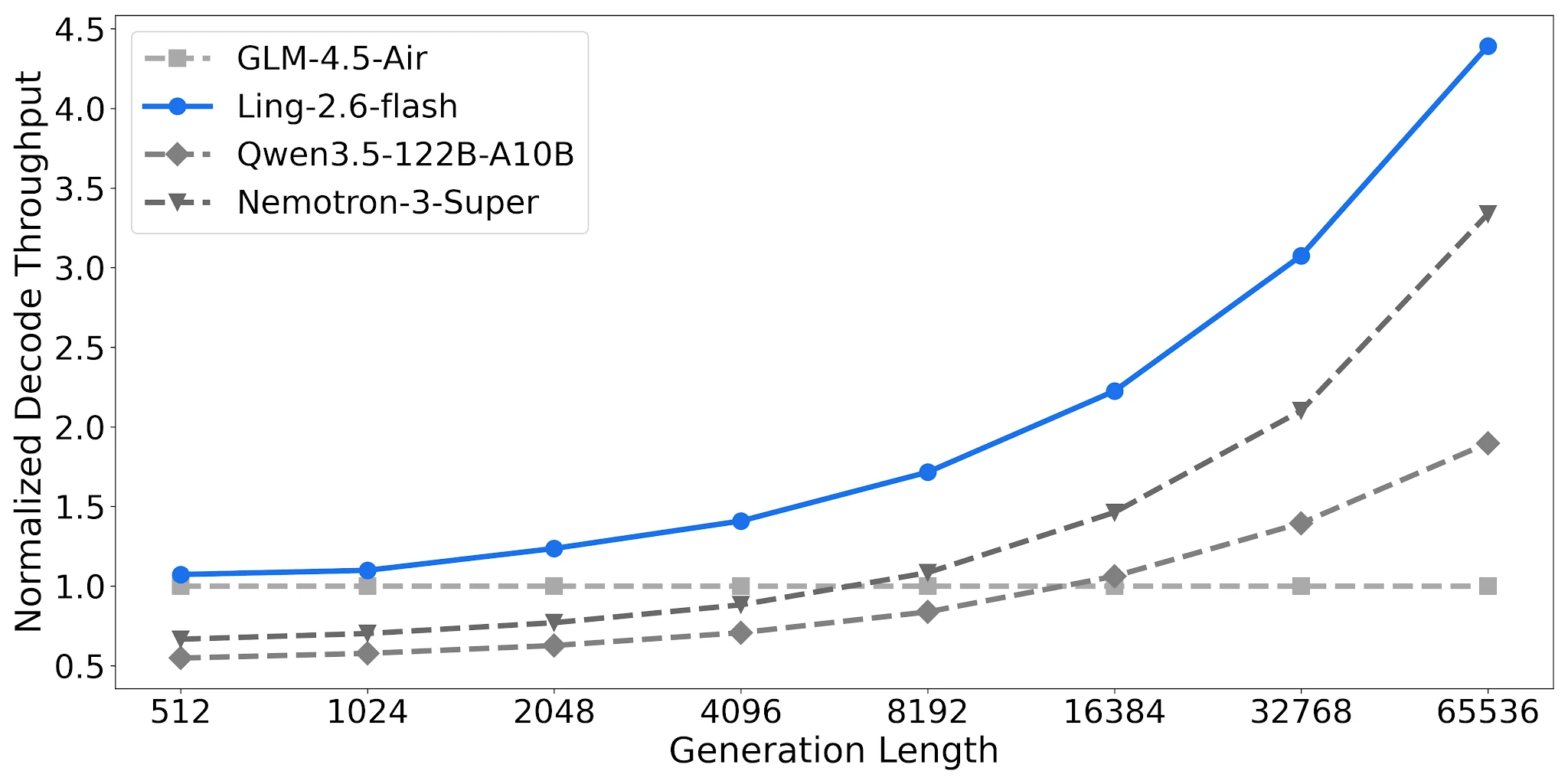
解码吞吐量对比,4× H20-3e,TP=4,Batch=32 [来源:Ling 官方博客]
预填充吞吐量:长上下文下是 Nemotron 的 2.2 倍
Ling-2.6-flash 在 65K 上下文中达到 约 4.68 倍归一化预填充吞吐量,而 Nemotron-3-Super 为约 2.12 倍。对于包含长系统提示的 RAG 流水线和多轮智能体,这直接降低了每次请求的成本。
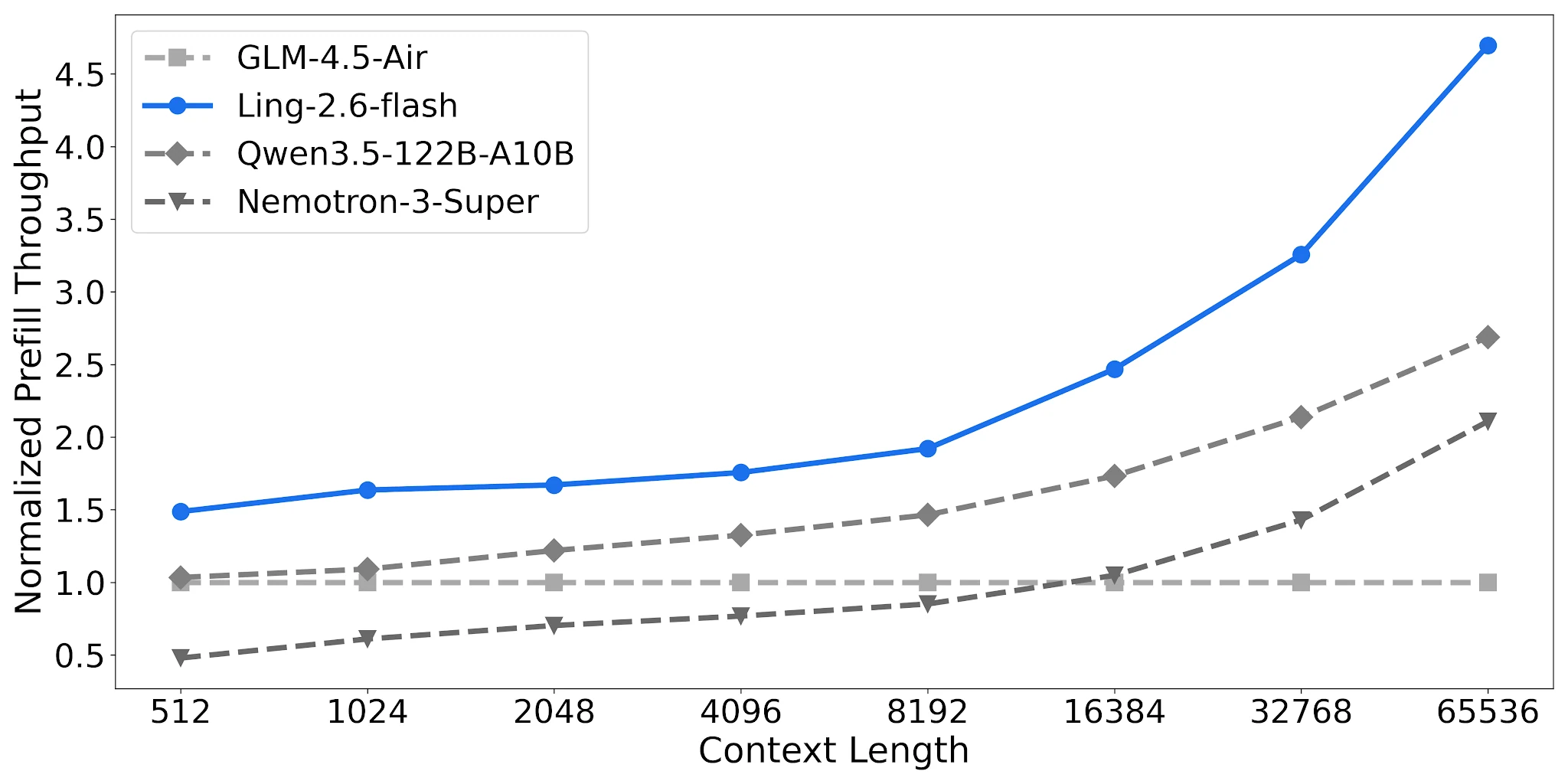
预填充吞吐量对比,4× H20-3e,TP=4,Batch=32 [来源:Ling 官方博客]
Token 效率:解决相同基准只需 1500 万 vs 1.1 亿 Token
在完整的人工分析智能指数上,Ling-2.6-flash 使用约 1,500 万输出 Token。Nemotron-3-Super 使用 1.1 亿以上——大约是 7 倍——而它在智能体任务上得分更低。对于每天运行数十万次智能体任务的应用程序,这一差距直接体现在成本预算中。
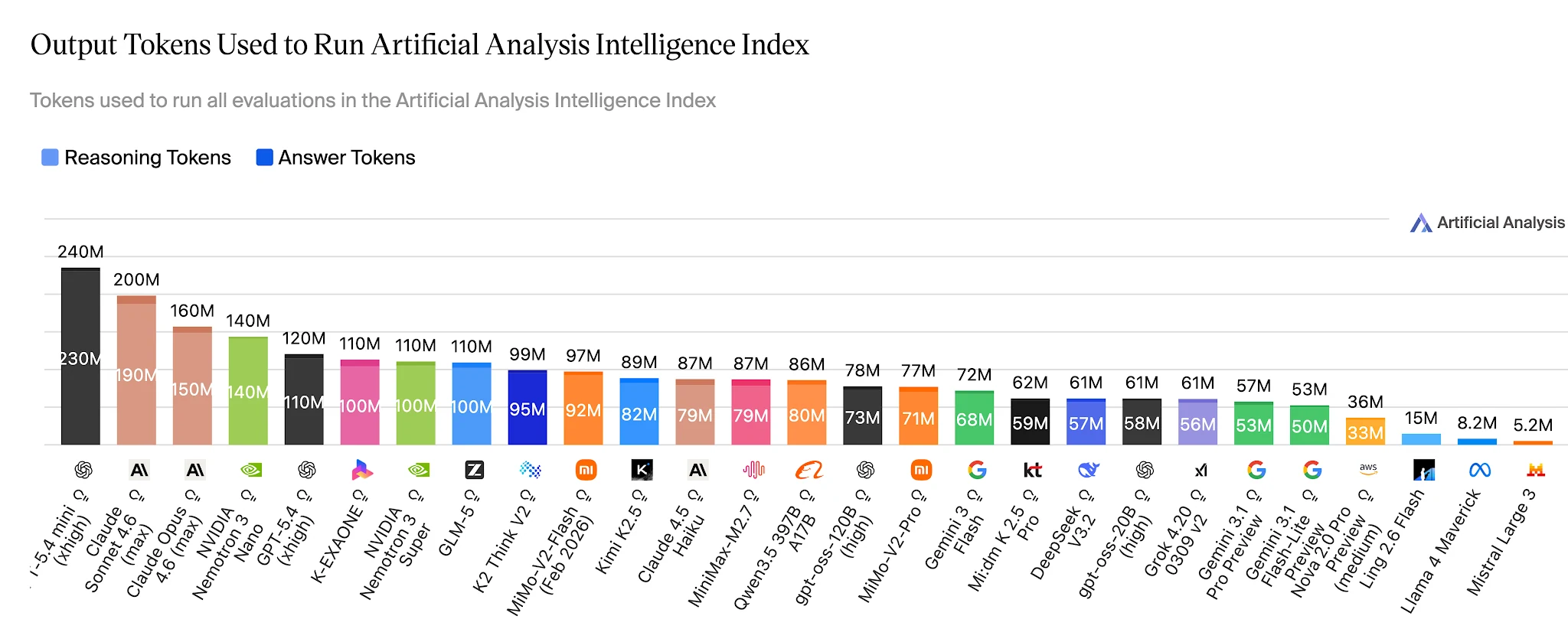
完成人工分析智能指数所需的输出 Token — Ling 2.6 Flash:约 1500 万 vs Nemotron-3-Super:约 1.1 亿以上 [来源:Artificial Analysis]
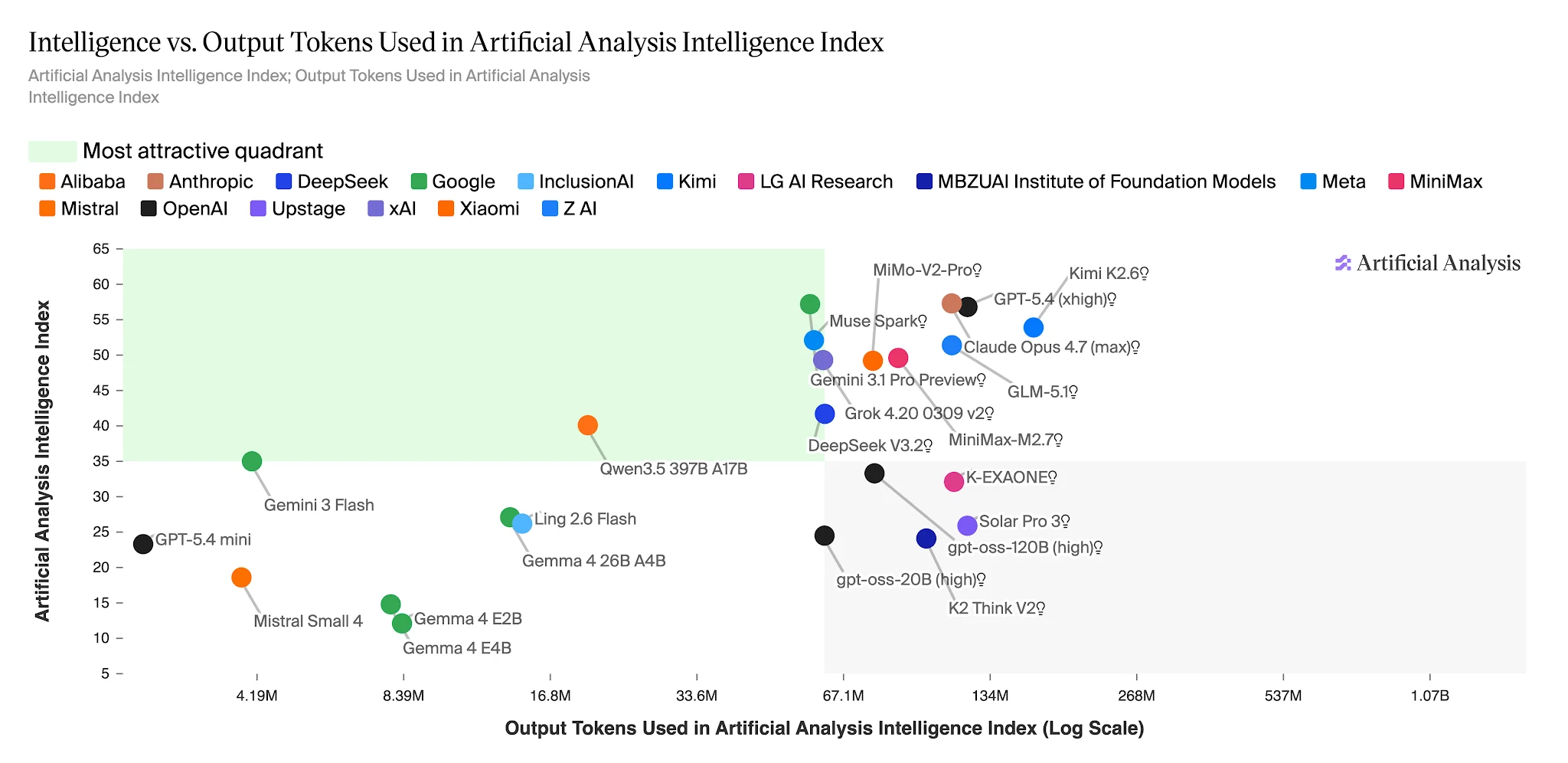
智能 vs. 输出 Token:Ling 2.6 Flash 位于高效区域 [来源:Artificial Analysis]
基准测试结果:Ling-2.6-flash 领先之处
在 7 个类别共 19 个基准测试中,与 Qwen3-57B-A14B、Qwen3.5-122B-A10B、GLM-4.5-Air、Nemotron-3-Super 和 MiniMax-M1-80k 进行对比:
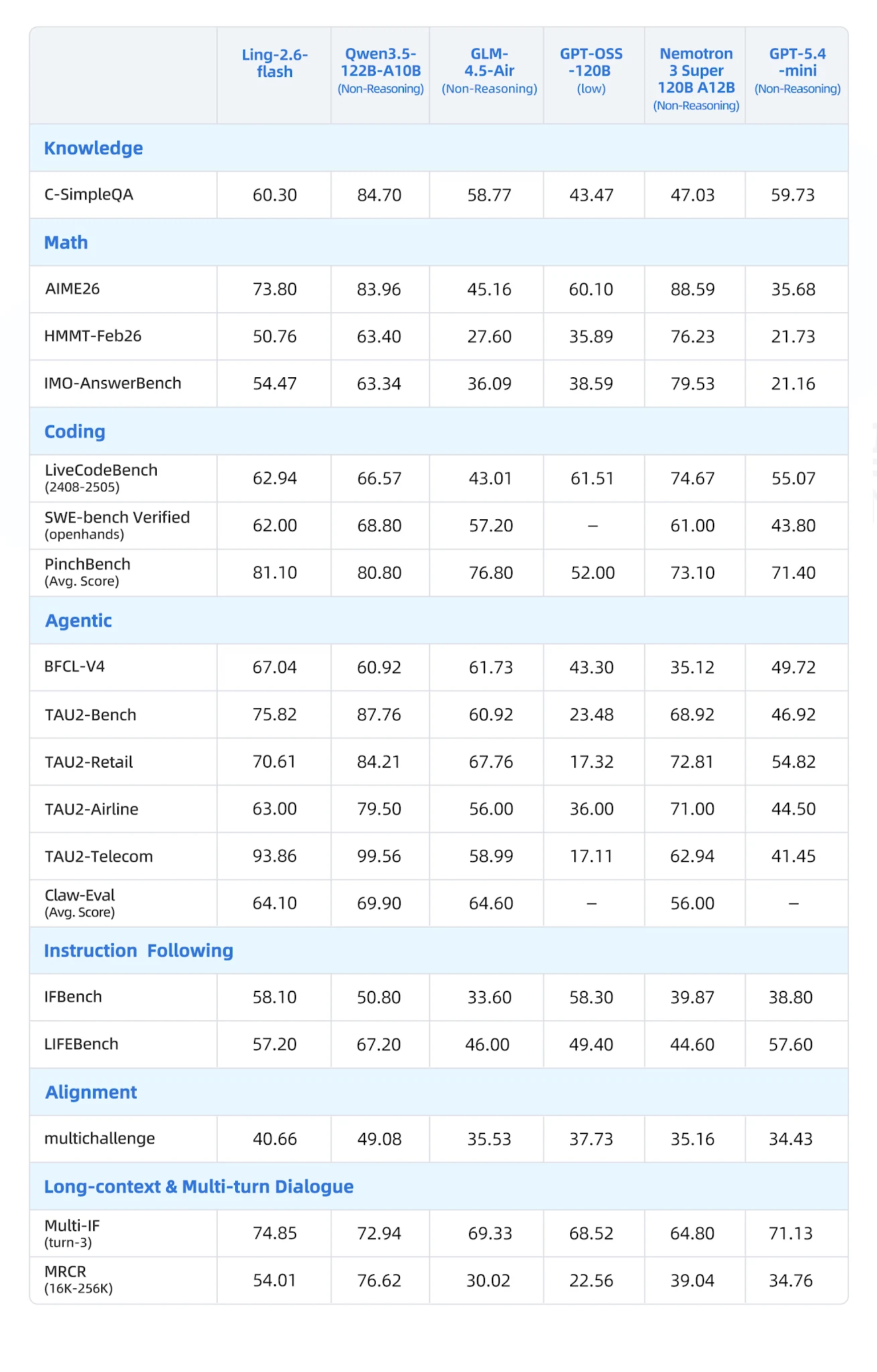
综合基准测试表 [来源:Ling 官方博客]
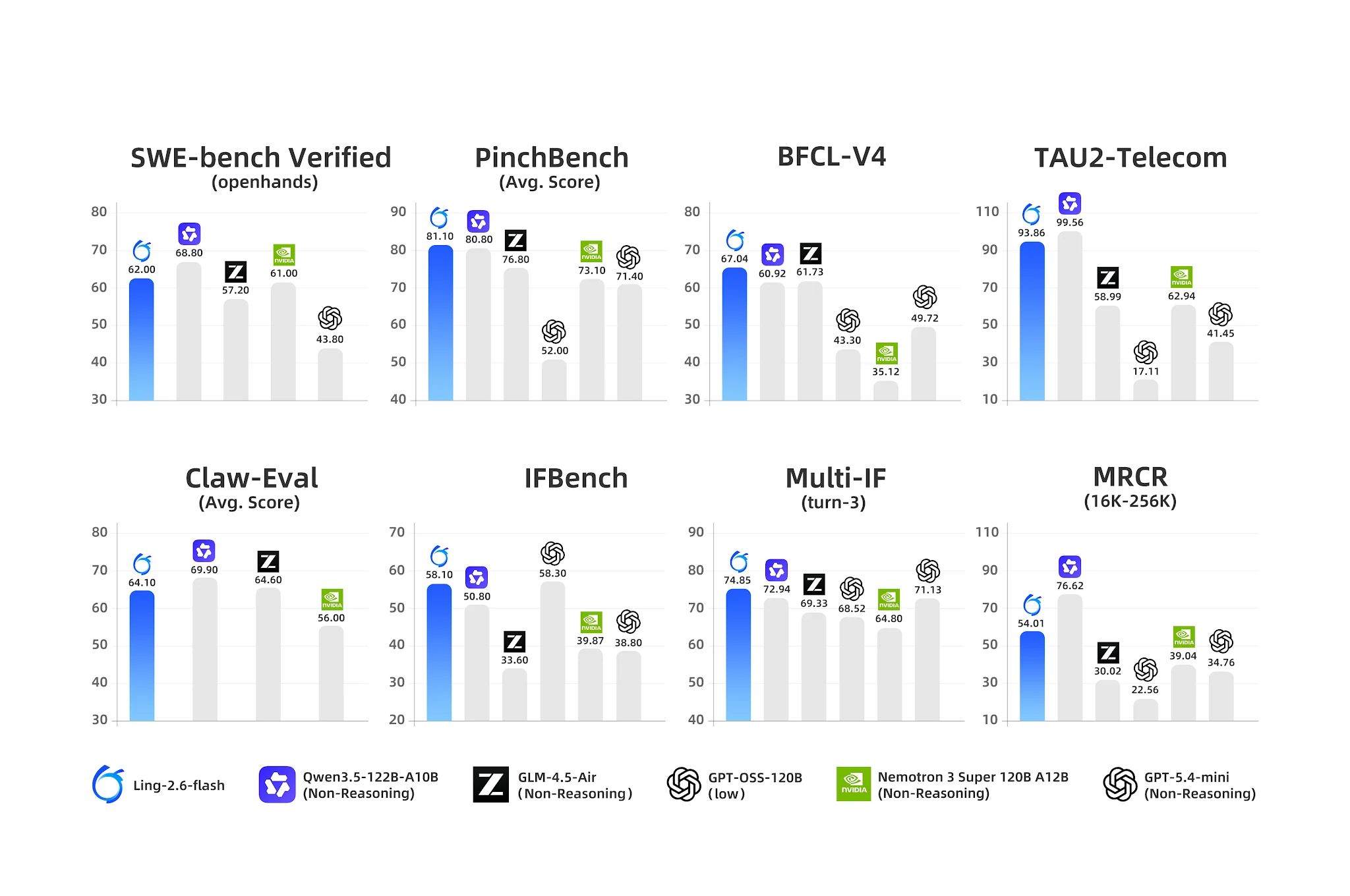
智能体基准:Ling-2.6-flash 在工具使用和多轮 IF 上领先 [来源:Ling 官方博客]
Ling-2.6-flash 领先之处
- BFCL-V4(函数调用): 67.04 — 最接近的竞争对手 Nemotron 为 35.12(差距 90%)
- PinchBench(智能体任务): 81.10 vs Nemotron 73.10
- IFBench(指令遵循): 58.10
- Multi-IF Turn-3: 74.85 — 强大的多轮指令保持能力
- LongBench-v2: 54.80 — 长上下文类别中最佳
- CCAlignBench(中文): 7.44 — 所有测试模型中最优
其他模型领先之处
- 数学(AIME 2025、MATH-500): Nemotron-3-Super 和 Qwen3 推理变体获胜
- 编码(LiveCodeBench): Qwen3.5-122B-A10B 领先;Ling 有竞争力但不是最佳
- GPQA-Diamond: GLM-4.5-Air 和 Nemotron 得分更高
快速对比表
| 型号 | 激活参数 | BFCL-V4 ↑ | PinchBench ↑ | 65K 解码吞吐量 ↑ | 输出 Token ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7.4B | 67.04 | 81.10 | 4.38× | 约 1500 万 |
| Nemotron-3-Super | 49B 总参数 | 35.12 | 73.10 | 3.37× | 约 1.1 亿以上 |
| Qwen3.5-122B-A10B | 10B | — | 78.20 | 1.90× | — |
| GLM-4.5-Air | — | 50.67 | 73.30 | 1.00×(基线) | — |
| MiniMax-M1-80k | — | 44.07 | 75.70 | — | — |
| Qwen3-57B-A14B | 14B | 52.32 | 76.30 | — | — |
通过 Novita AI 访问 Ling-2.6-flash
Ling-2.6-flash 现已可用。在 OpenRouter 上尝试 — 免费层,无需设置:
从 OpenRouter — inclusionai/ling-2.6-flash:free 开始。提供免费层,兼容 OpenAI 的客户端无需更改代码。
Ling-2.6-flash 可与 LangChain、LlamaIndex 和 OpenAI Agent SDK 配合使用,无需适配器或代码更改。支持流式输出、函数调用和结构化输出。将其与 Novita Agent Sandbox 配对,可在推理的同时进行安全代码执行。
社区评价
Ling-2.6-flash 在正式发布前以“Elephant Alpha”的名称在 OpenRouter 上推出。几天之内,它已处理约 1000 亿 Token 并登顶平台趋势排行榜——没有任何公告。
“Ling-2.6-flash 有点务实。比大模型少约 75% 的冗长。仍有一些模板化内容,但涉及编写代码时——它几乎完美。”
— X/Twitter 上的早期用户
“刚刚在几个 llama.cpp 编码任务上试用了 Ling-2.6-flash。比预期的好得多。可靠地处理工具调用,并且不会用不必要的解释填充输出。”
— Reddit 上的早期用户
“少 75% 的冗长”这一评论与 Artificial Analysis 基准测试中 1500 万 vs 1.1 亿 Token 的差距完全吻合。训练目标似乎奖励直接、完整的答案——这一特性在生产规模下会显著节约成本。
谁应该使用 Ling-2.6-flash?
- ✅ 高容量函数调用/工具使用智能体 — BFCL-V4 大幅领先
- ✅ 多轮智能体会话 — 在长对话历史中表现一致
- ✅ 长上下文 RAG 流水线 — 256K 窗口,线性成本预填充
- ✅ 成本敏感的生产部署 — 输出 Token 比 Nemotron 少约 7 倍
- ✅ 中文应用 — 最高的 CCAlignBench 分数
- ❌ 数学竞赛/AIME 风格推理 — 请使用 Nemotron 或 Qwen3 推理变体
- ❌ 最大化编码基准性能 — Qwen3.5-122B-A10B 领先
开始使用
Ling-2.6-flash 现已可用。通过 OpenRouter 模型页面 访问它 — 免费层立即可用,兼容 OpenAI 的客户端无需更改代码。Agent Sandbox 也可供同时需要推理和安全执行的团队使用。
常见问题
什么是 Ling-2.6-flash?
Ling-2.6-flash 是一款 104B MoE 模型(7.4B 激活参数),具有混合线性注意力、256K 上下文窗口和高达 340 tokens/s 的推理速度,针对智能体工作负载进行了优化。
如何通过 API 使用 Ling-2.6-flash?
使用 OpenRouter 并带上您的 Novita AI API 密钥(BYOK)。在 openrouter.ai/settings/integrations 添加您的 Novita 密钥,选择 Novita 作为提供商,然后通过兼容 OpenAI 的端点到 inclusionai/ling-2.6-flash:free 路由请求:
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer YOUR_OPENROUTER_API_KEY
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "YOUR_NOVITA_API_KEY"
},
"messages": [{"role": "user", "content": "Hello!"}]
}
完整设置请参见 OpenRouter BYOK 文档。使用 BYOK 时,OpenRouter 不收取费用——您直接以免费层定价向 Novita 付款。
Ling-2.6-flash 与 Nemotron-3-Super 相比如何?
Ling 在 BFCL-V4(67.04 vs 35.12)、PinchBench(81.10 vs 73.10)上领先,并且使用的输出 Token 少约 7 倍。Nemotron 在数学上领先。对于智能体工作负载,Ling-2.6-flash 是更经济的选择。
上下文窗口是多少?
256K Token(262,144),由于混合线性注意力,预填充成本呈线性。长 RAG 和多轮会话可高效扩展。
Ling-2.6-flash 是开源的吗?
BF16、FP8 和 INT4 变体以及 Linghe 内核计划开源发布。时间表待定——请查看 Ling 官方网站 以获取更新。
您可能还喜欢
- Kimi K2.6:用于 13 小时编码会话的开源智能体 — 1T MoE 模型,256K 上下文,SWE-Bench Pro 58.6%
- GLM-5.1 API on Novita AI:长周期智能体模型 — SWE-Bench Pro 以 58.4% 领先,可自主运行编码任务 8 小时
- 2026 年开源模型顶级推理 API 提供商 — 比较 Novita AI、Together AI、Fireworks、DeepInfra 和 Groq



