

에이전트 토큰 비용이 급증하고 있습니다. 다단계 도구 호출, 긴 컨텍스트 계획, 확장된 출력으로 인해 겉보기에는 저렴한 토큰당 가격이 월간 청구서로는 매우 비싸집니다. 업계의 해결책인 추론 체인을 더 길게 늘려 벤치마크 점수를 높이는 방법은 경제성을 더욱 악화시킵니다.
Ling-2.6-flash는 다른 종류의 모델입니다. 하이브리드 선형 어텐션 아키텍처를 기반으로 구축되어, 4× H20 하드웨어에서 최대 340 tokens/s를 달성하고, Nemotron-3-Super 대비 2.2배의 프리필 처리량을 제공하며, 전체 Artificial Analysis Intelligence Index를 완료하는 데 단 약 1500만 개의 출력 토큰만 사용합니다. 이는 Nemotron-3-Super가 소비하는 양의 약 10분의 1에 불과합니다. 요약하자면, Ling-2.6-flash는 104B MoE 모델(7.4B 활성)이며 256K 컨텍스트 윈도우를 가지고 있어, 속도, 비용, 안정성이 단일 헤드라인 벤치마크보다 더 중요한 에이전트 워크로드에 최적화되었습니다. 이제 Novita AI에서 사용할 수 있습니다.
Ling-2.6-flash란 무엇인가요?
Ling-2.6-flash는 104B 총 파라미터와 순방향 패스당 7.4B 활성 파라미터를 가진 희소 전문가 혼합(Mixture-of-Experts) 언어 모델입니다. Ling 팀(InclusionAI)이 개발했으며, 토큰 소비와 지연 시간이 단순한 벤치마크 헤드라인이 아닌 실제 비용인 프로덕션 에이전트 배포에 최적화된 ‘인스턴트’ 카테고리 모델로 설계되었습니다.
- 104B 총 / 7.4B 활성 파라미터 — 높은 희소성을 가진 MoE 아키텍처
- 256K 토큰 컨텍스트 윈도우 — 하이브리드 선형 어텐션으로 가능
- 4× H20에서 최대 340 tokens/s 피크 처리량 (TP=4)
- 하이브리드 1:7 MLA + Lightning Linear 어텐션 — 긴 컨텍스트에서 4배 처리량
- 최고 에이전트 벤치마크 — BFCL-V4(67.04), PinchBench(81.10), IFBench(58.10), Multi-IF Turn-3(74.85) 선도
- BF16, FP8, INT4 변형 — Linghe를 통해 오픈소스 릴리스 계획
- 프로덕션 검증 완료 — 출시 며칠 만에 OpenRouter에서 일일 약 1000억 토큰 처리
하이브리드 선형 아키텍처: Ling-2.6-flash가 규모에 따라 더 빨라지는 방법
대부분의 MoE 모델은 표준 트랜스포머 어텐션을 희소 FFN 레이어와 짝지어 사용합니다. Ling-2.6-flash는 대부분의 어텐션을 Lightning Linear 레이어로 대체하여 1:7 MLA + Lightning Linear 하이브리드를 만듭니다. 어텐션 비용이 컨텍스트 길이에 따라 2차 함수가 아닌 선형으로 증가하며, 이는 긴 에이전트 세션에 매우 중요합니다.
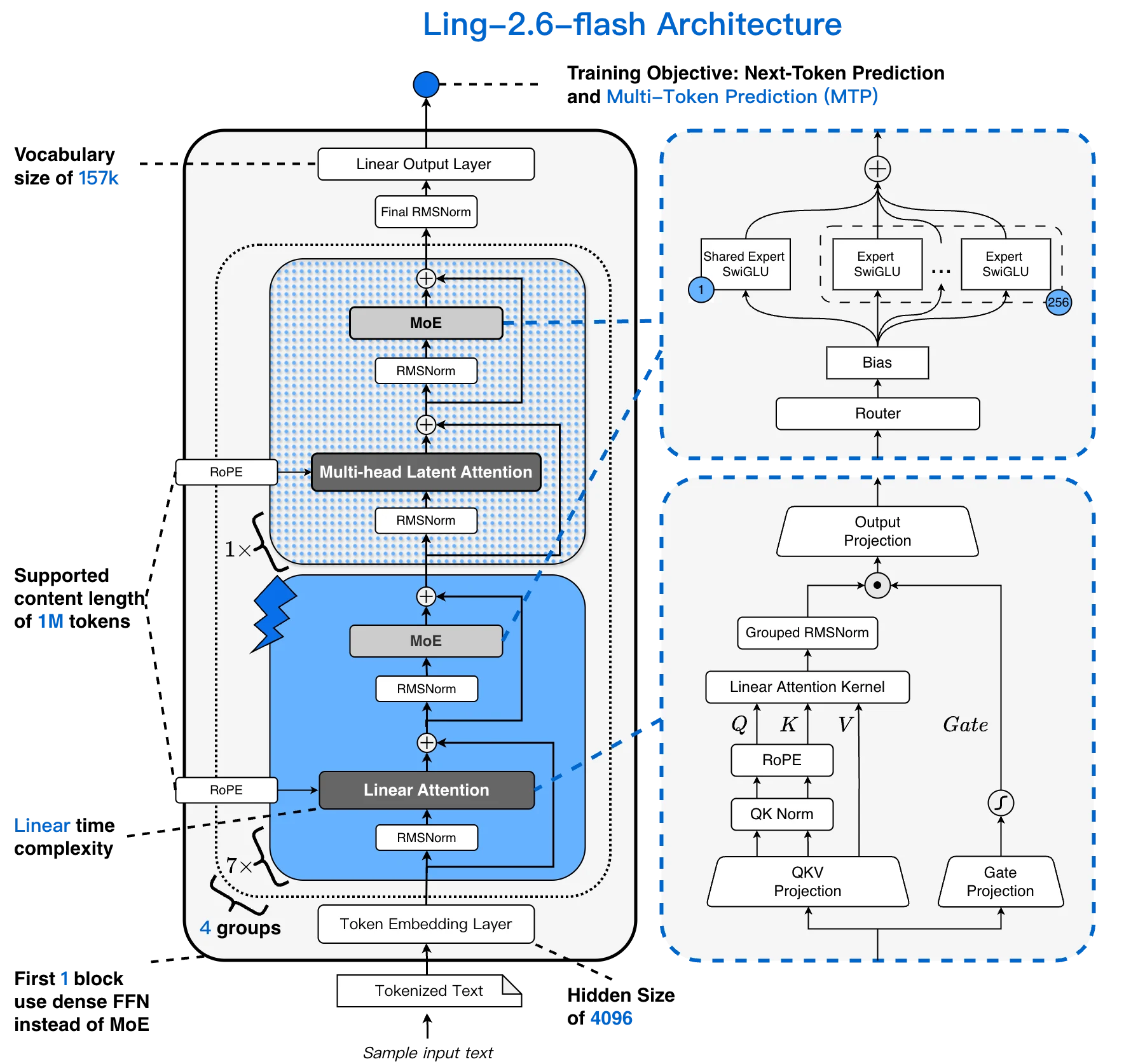
Ling-2.6-flash 아키텍처: 157K 어휘, 256K 컨텍스트, 1:7 MLA + Lightning Linear 하이브리드, 256개 선택 가능 전문가 [출처: Ling 공식 블로그]
디코드 처리량: 긴 출력에서 최대 4.38배
4× H20-3e(TP=4, 배치 크기 32)에서 Ling-2.6-flash는 65,536 토큰 출력 길이에서 GLM-4.5-Air 기준 대비 4.38배 정규화된 디코드 처리량에 도달합니다. Qwen3.5-122B-A10B는 1.90배, Nemotron-3-Super는 3.37배입니다. 작업 출력 길이가 증가함에 따라 격차는 더 커집니다.
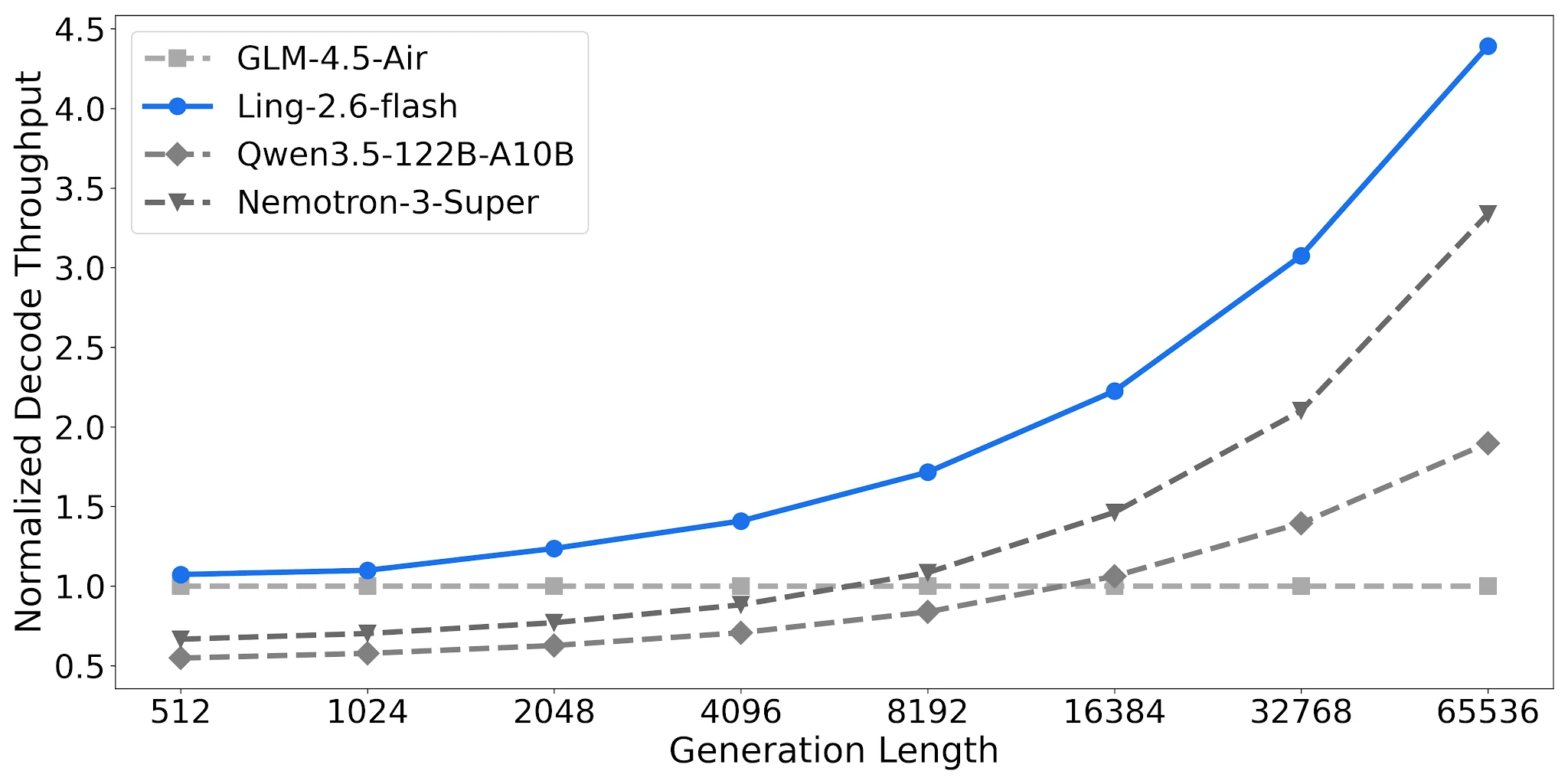
디코드 처리량 비교, 4× H20-3e, TP=4, 배치=32 [출처: Ling 공식 블로그]
프리필 처리량: 긴 컨텍스트에서 Nemotron 대비 2.2배
Ling-2.6-flash는 65K 컨텍스트에서 약 4.68배 정규화된 프리필 처리량을 달성하는 반면, Nemotron-3-Super는 약 2.12배입니다. 긴 시스템 프롬프트가 있는 RAG 파이프라인과 다중 턴 에이전트의 경우, 이는 요청당 비용을 직접적으로 줄여줍니다.
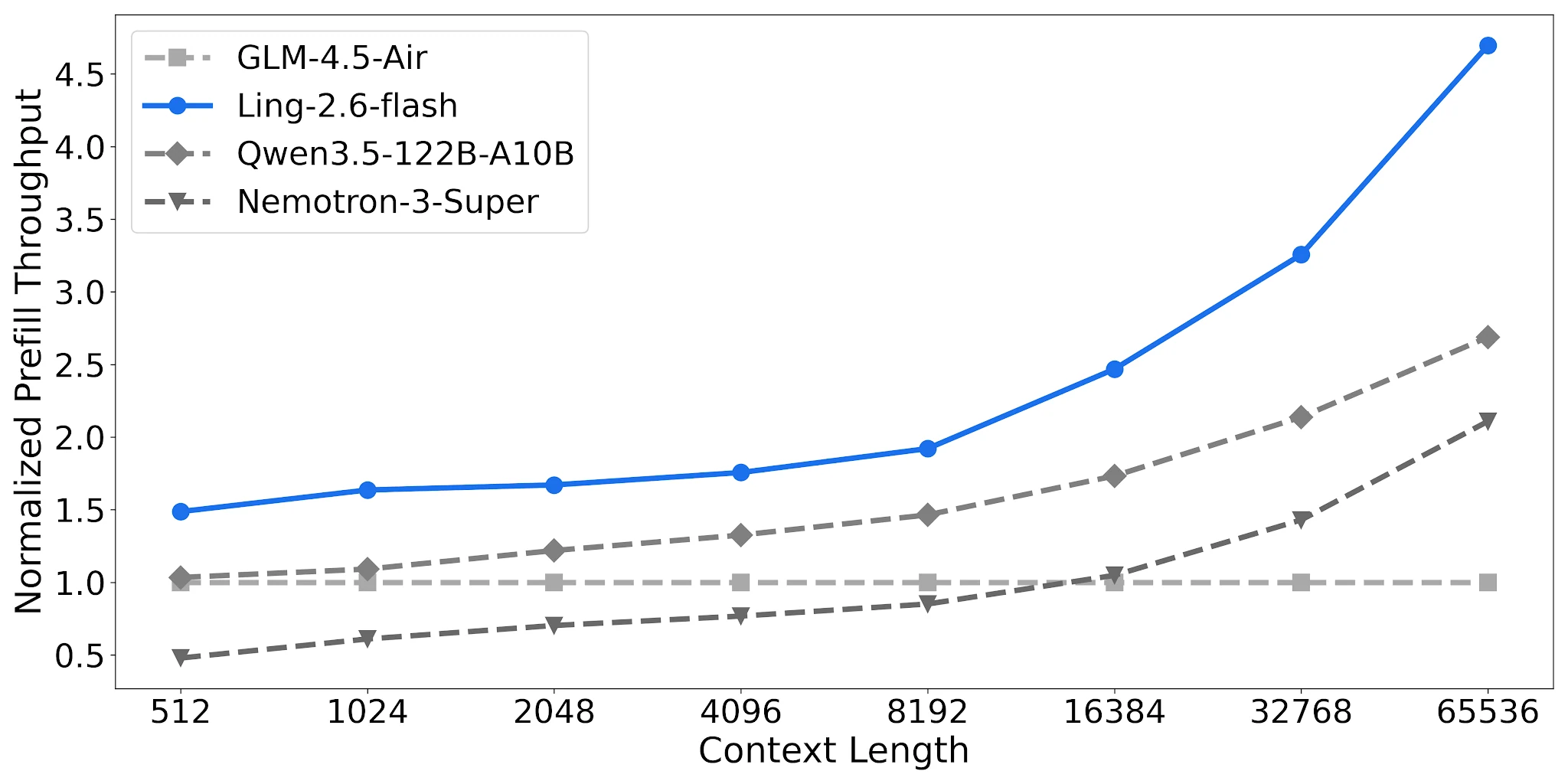
프리필 처리량 비교, 4× H20-3e, TP=4, 배치=32 [출처: Ling 공식 블로그]
토큰 효율: 동일한 벤치마크 해결에 1500만 vs 1억 1000만
전체 Artificial Analysis Intelligence Index에서 Ling-2.6-flash는 약 1500만 개의 출력 토큰을 사용합니다. Nemotron-3-Super는 에이전트 작업에서 더 낮은 점수를 받는 모델임에도 불구하고 1억 1000만 개 이상(약 7배)을 사용합니다. 매일 수십만 개의 에이전트 작업을 실행하는 애플리케이션의 경우, 이 차이는 비용 예산에 직접적인 항목입니다.
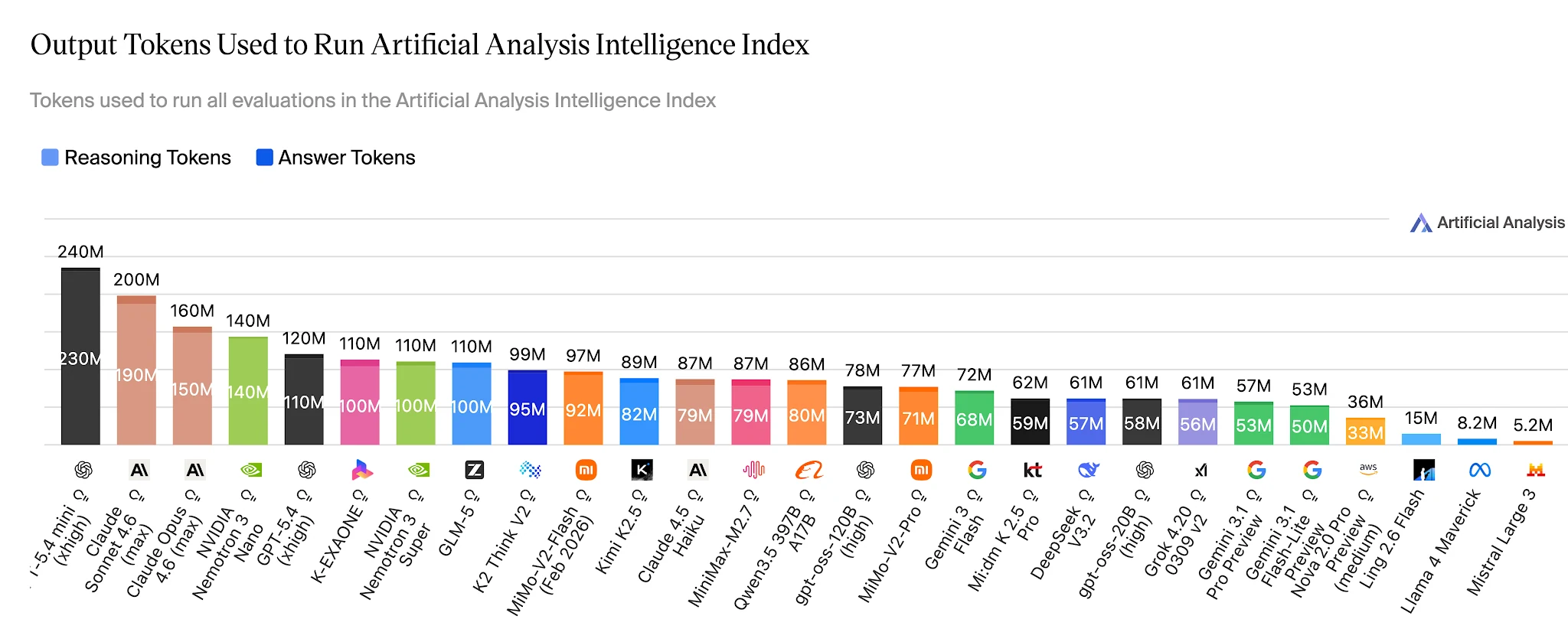
Artificial Analysis Intelligence Index 완료에 필요한 출력 토큰 — Ling 2.6 Flash: 약 1500만 vs Nemotron-3-Super: 약 1억 1000만+ [출처: Artificial Analysis]
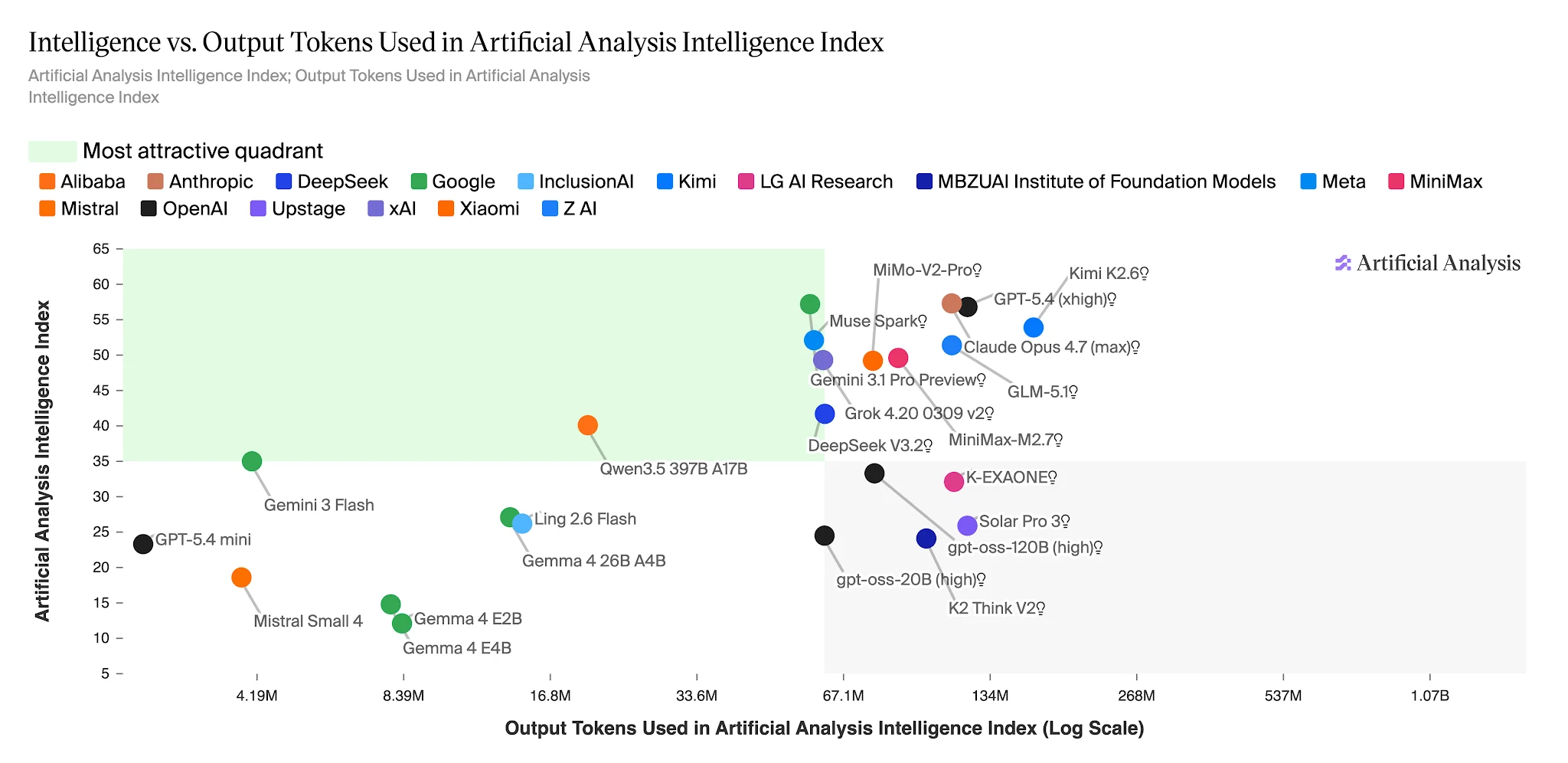
지능 vs. 출력 토큰: Ling 2.6 Flash는 고효율 영역에 위치 [출처: Artificial Analysis]
벤치마크 결과: Ling-2.6-flash가 앞서는 분야
Qwen3-57B-A14B, Qwen3.5-122B-A10B, GLM-4.5-Air, Nemotron-3-Super, MiniMax-M1-80k와 비교하여 7개 카테고리, 19개 벤치마크에서 평가:
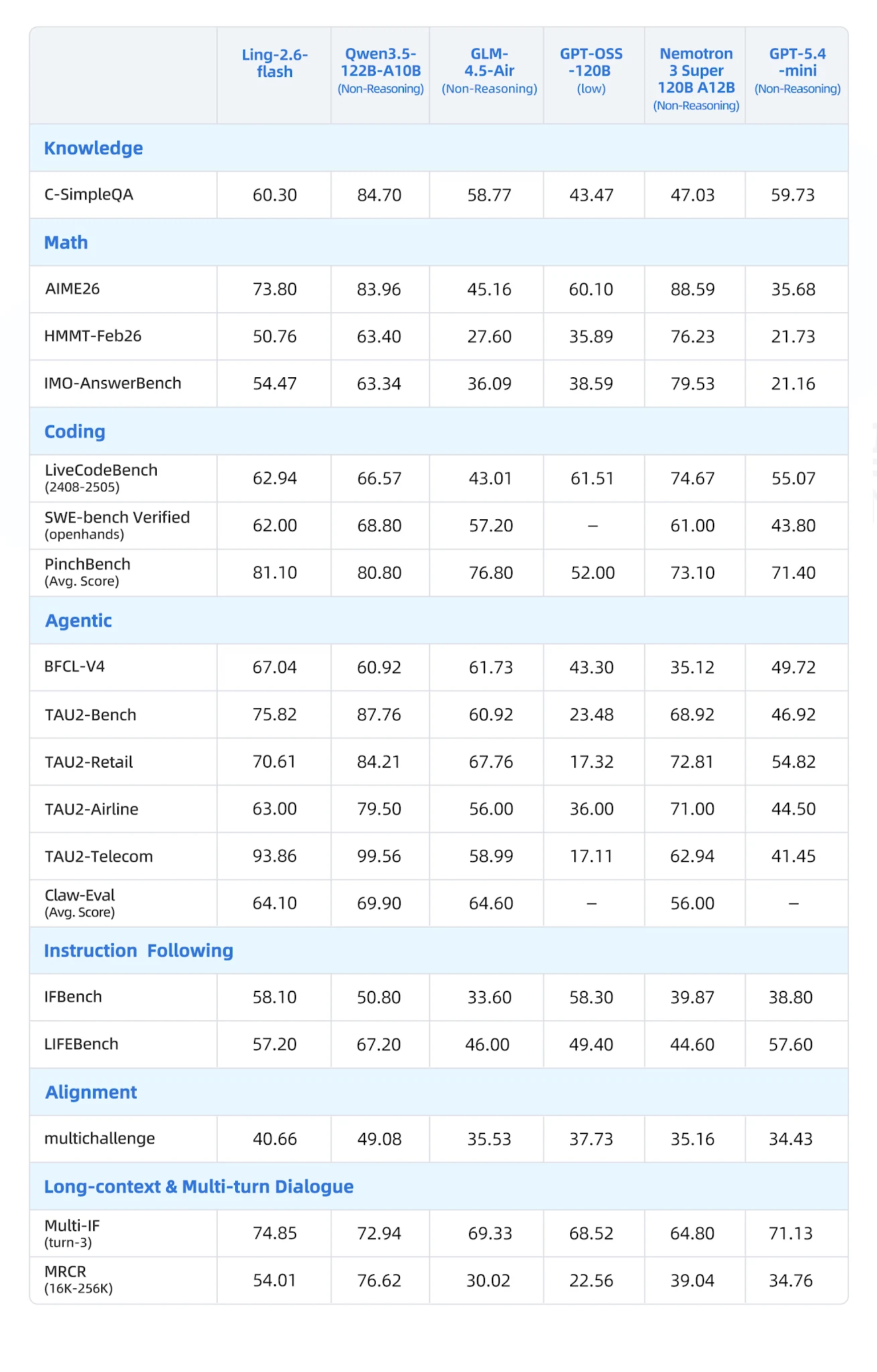
포괄적인 벤치마크 표 [출처: Ling 공식 블로그]
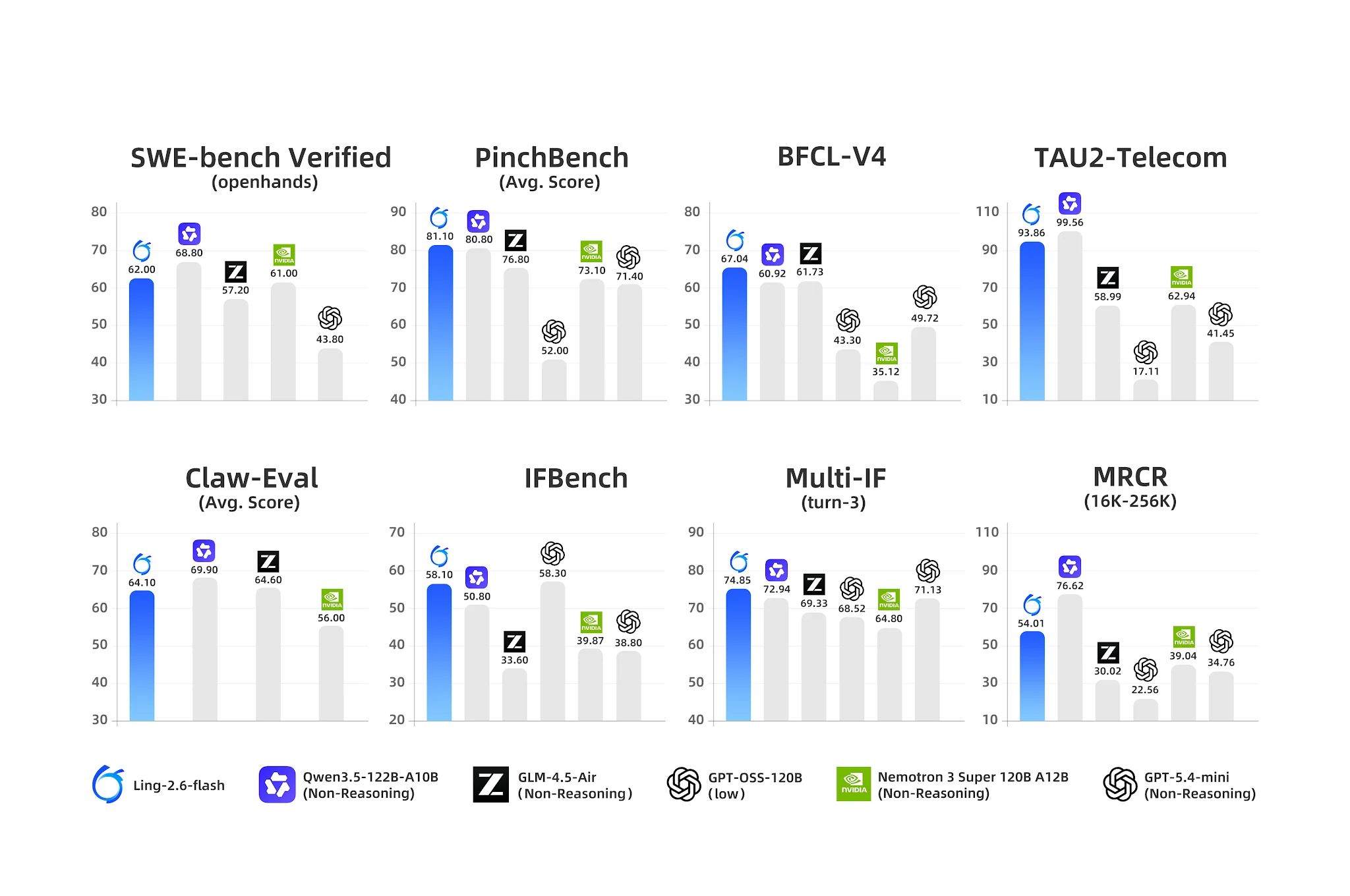
에이전트 벤치마크: Ling-2.6-flash는 도구 사용 및 다중 턴 IF에서 선도 [출처: Ling 공식 블로그]
Ling-2.6-flash가 앞서는 분야
- BFCL-V4 (함수 호출): 67.04 — 가장 가까운 경쟁자 Nemotron 35.12 (90% 격차)
- PinchBench (에이전트 작업): 81.10 vs Nemotron 73.10
- IFBench (명령 수행): 58.10
- Multi-IF Turn-3: 74.85 — 강력한 다중 턴 명령 지속성
- LongBench-v2: 54.80 — 긴 컨텍스트 카테고리 최고
- CCAlignBench (중국어): 7.44 — 테스트된 모든 모델 중 최고
다른 모델이 앞서는 분야
- 수학 (AIME 2025, MATH-500): Nemotron-3-Super 및 Qwen3 추론 변형이 우위
- 코딩 (LiveCodeBench): Qwen3.5-122B-A10B 선도; Ling은 경쟁력 있지만 최고는 아님
- GPQA-Diamond: GLM-4.5-Air 및 Nemotron 점수 더 높음
빠른 비교 표
| 모델 | 활성 파라미터 | BFCL-V4 ↑ | PinchBench ↑ | 65K에서 디코드 TP ↑ | 출력 토큰 ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7.4B | 67.04 | 81.10 | 4.38× | ~1500만 |
| Nemotron-3-Super | 49B total | 35.12 | 73.10 | 3.37× | ~1억 1000만+ |
| Qwen3.5-122B-A10B | 10B | — | 78.20 | 1.90× | — |
| GLM-4.5-Air | — | 50.67 | 73.30 | 1.00× (기준) | — |
| MiniMax-M1-80k | — | 44.07 | 75.70 | — | — |
| Qwen3-57B-A14B | 14B | 52.32 | 76.30 | — | — |
Novita AI 기반 Ling-2.6-flash 이용하기
Ling-2.6-flash를 지금 사용할 수 있습니다. OpenRouter에서 체험해보세요 — 무료 티어, 설정 불필요:
OpenRouter — inclusionai/ling-2.6-flash:free에서 시작하세요. 무료 티어 사용 가능, OpenAI 호환 클라이언트를 위한 코드 변경 불필요.
Ling-2.6-flash는 LangChain, LlamaIndex, OpenAI Agent SDK와 함께 작동하며, 어댑터나 코드 변경이 필요 없습니다. 스트리밍, 함수 호출, 구조화된 출력을 모두 지원합니다. 추론과 함께 안전한 코드 실행을 위해 Novita Agent Sandbox와 함께 사용하세요.
커뮤니티 반응
Ling-2.6-flash는 공식 공개 전에 OpenRouter에서 “Elephant Alpha” 로 출시되었습니다. 며칠 만에 약 1000억 토큰을 처리하고 별다른 발표 없이 플랫폼 트렌딩 리더보드 1위에 올랐습니다.
“Ling-2.6-flash는 일 중심적인 모델입니다. 큰 모델보다 약 75% 덜 장황합니다. 여전히 약간의 상용구가 있지만, 코드를 작성할 때는 거의 완벽합니다.”
— X/Twitter 초기 사용자
“방금 llama.cpp 코딩 작업 몇 개에 Ling-2.6-flash를 사용해봤습니다. 예상보다 훨씬 좋습니다. 도구 호출을 안정적으로 처리하고 불필요한 설명을 출력에 채우지 않습니다.”
— Reddit 초기 사용자
"75% 덜 장황하다"는 의견은 Artificial Analysis 벤치마크의 1500만 대 1억 1000만 토큰 격차와 정확히 일치합니다. 훈련 목표는 직접적이고 완전한 답변을 보상하는 것으로 보이며, 이는 프로덕션 규모에서 비용 절감 효과를 누적시킵니다.
Ling-2.6-flash는 누가 사용해야 하나요?
- ✅ 대규모 함수 호출/도구 사용 에이전트 — BFCL-V4에서 큰 차이로 선도
- ✅ 다중 턴 에이전트 세션 — 긴 대화 기록에서 일관됨
- ✅ 긴 컨텍스트 RAG 파이프라인 — 256K 토큰 윈도우, 선형 비용 프리필
- ✅ 비용에 민감한 프로덕션 배포 — Nemotron보다 약 7배 적은 출력 토큰
- ✅ 중국어 애플리케이션 — 최고 CCAlignBench
- ❌ 수학 경진대회 / AIME 스타일 추론 — Nemotron 또는 Qwen3 추론 변형 사용
- ❌ 최대 코딩 벤치마크 성능 — Qwen3.5-122B-A10B 선도
시작하기
Ling-2.6-flash를 지금 사용할 수 있습니다. OpenRouter 모델 페이지를 통해 접속하세요 — 즉시 무료 티어 사용 가능, OpenAI 호환 클라이언트를 위한 코드 변경 불필요. 추론과 안전한 실행을 결합하는 팀을 위해 Agent Sandbox도 함께 제공됩니다.
자주 묻는 질문
Ling-2.6-flash란 무엇인가요?
Ling-2.6-flash는 하이브리드 선형 어텐션, 256K 컨텍스트 윈도우, 최대 340 tokens/s 추론 속도를 갖춘 104B MoE 모델(7.4B 활성)로, 에이전트 워크로드에 최적화되었습니다.
API를 통해 Ling-2.6-flash를 어떻게 사용하나요?
OpenRouter를 Novita AI API 키(BYOK)와 함께 사용하세요. openrouter.ai/settings/integrations에서 Novita 키를 추가하고, 제공자로 Novita를 선택한 후 OpenAI 호환 엔드포인트를 통해 inclusionai/ling-2.6-flash:free로 요청을 라우팅하세요:
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer YOUR_OPENROUTER_API_KEY
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "YOUR_NOVITA_API_KEY"
},
"messages": [{"role": "user", "content": "Hello!"}]
}
전체 설정은 OpenRouter BYOK 문서를 참조하세요. BYOK 사용 시 OpenRouter는 수수료를 부과하지 않으며, 무료 티어 가격으로 Novita에 직접 지불합니다.
Ling-2.6-flash는 Nemotron-3-Super와 어떻게 비교되나요?
Ling은 BFCL-V4(67.04 vs 35.12), PinchBench(81.10 vs 73.10)에서 앞서며 약 7배 적은 출력 토큰을 사용합니다. Nemotron은 수학에서 앞섭니다. 에이전트 워크로드의 경우 Ling-2.6-flash가 더 경제적인 선택입니다.
컨텍스트 윈도우는 어떻게 되나요?
256K 토큰(262,144)이며, 하이브리드 선형 어텐션 덕분에 선형 비용 프리필이 가능합니다. 긴 RAG 및 다중 턴 세션이 효율적으로 확장됩니다.
Ling-2.6-flash는 오픈소스인가요?
BF16, FP8, INT4 변형과 Linghe 커널은 오픈소스 릴리스로 계획되어 있습니다. 일정은 미정입니다. 업데이트는 Ling 공식 사이트를 확인하세요.
함께 보면 좋은 글
- Kimi K2.6: 13시간 코딩 세션을 위한 오픈소스 에이전트 — 1T MoE 모델, 256K 컨텍스트, 58.6% SWE-Bench Pro
- Novita AI의 GLM-5.1 API: 장기 지평 에이전트 모델 — SWE-Bench Pro 58.4% 최고, 8시간 자율 코딩 작업 실행
- 2026년 오픈소스 모델을 위한 최고 추론 API 제공업체 — Novita AI, Together AI, Fireworks, DeepInfra, Groq 비교



