

TL;DR
Novita AI a développé une suite d’optimisations à fort impact, testées en production, pour le déploiement de modèles GLM4-MoE basés sur SGLang. Nous présentons une stratégie d’optimisation des performances de bout en bout qui résout les goulots d’étranglement sur l’ensemble de la pipeline d’inférence — de l’efficacité d’exécution des kernels à l’ordonnancement des transferts de données inter-nœuds. Grâce à l’intégration de la Fusion des experts partagés et du Décodage de suffixe, nous observons des gains substantiels sur les indicateurs clés de production, notamment :
- jusqu’à 65 % de réduction du Time-to-First-Token (TTFT)
- amélioration de 22 % du Time-Per-Output-Token (TPOT)
dans des charges de travail de codage agentique.
Tous les résultats ont été validés sur des clusters H200 dans des configurations TP8 et FP8, fournissant un plan d’action ayant fait ses preuves pour atteindre à la fois un débit optimal et une faible latence dans des environnements de production exigeants.
Comment nous avons implémenté les optimisations de production cœur pour GLM-MoE
1. Fusion des experts partagés
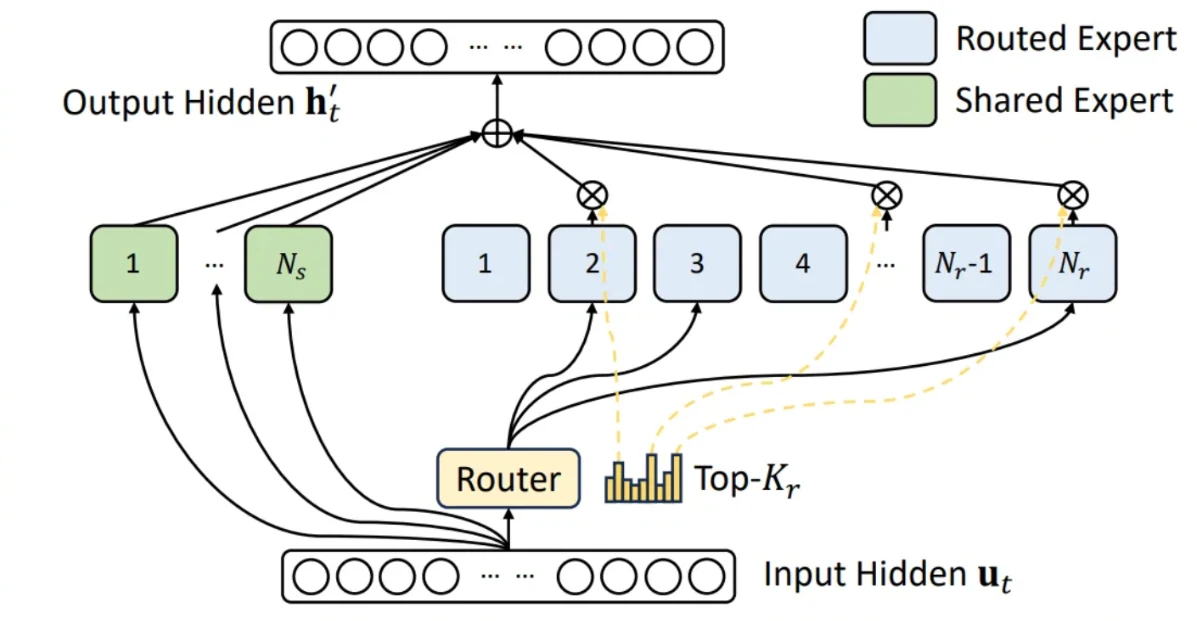
L’entière paternité de cette optimisation revient au travail original sur le modèle Deepseek. Comme illustré sur la figure ci-dessus, les modèles MoE tels que GLM4.7 acheminent tous les jetons d’entrée via un expert partagé, tandis que chaque jeton est également acheminé individuellement vers son propre ensemble d’experts acheminés de premier rang (top-k) sélectionnés par le routeur du modèle. Les sorties de tous les experts sont ensuite pondérées et agrégées. GLM4.7, par exemple, utilise 160 experts acheminés ainsi qu’un seul expert partagé, en sélectionnant les 8 experts acheminés de premier rang par jeton. Dans les implémentations précédentes, ces deux composants étaient traités séparément. Étant donné qu’ils partagent des formes de tenseur et des procédures de calcul identiques, il est naturel de les unifier en fusionnant l’expert partagé dans la structure MoE acheminée : on sélectionne les 9 premiers experts parmi les 161 au total, l’expert partagé étant systématiquement assigné à la 9e position.
Comme documenté dans la PR, cette optimisation permet des gains de performance allant jusqu’à 23,7 % sur le TTFT et 20,8 % sur l’ITL. Ces gains sont attendus car, dans des configurations TP8 et FP8 — où la taille intermédiaire n’est que de 192, ce qui est relativement faible pour le matériel H200 — l’opération de fusion augmente considérablement l’utilisation des multiprocesseurs de streaming (SM) et réduit significativement la surcharge d’E/S mémoire.
2. Fusion QKnorm
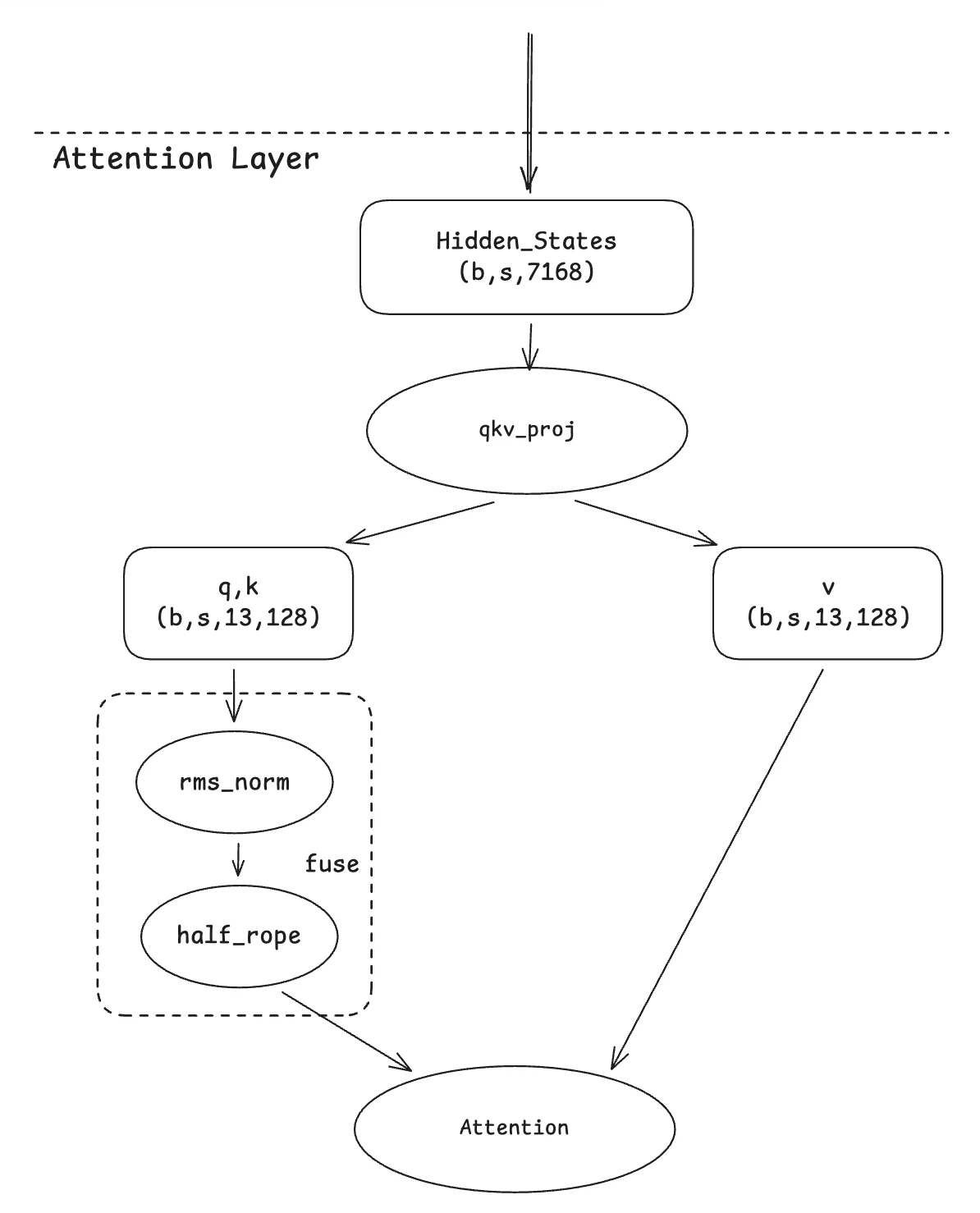
Cette migration s’appuie sur l’optimisation issue de Qwen-MoE. L’idée sous-jacente est simple. Comme les deux opérateurs effectuent des calculs par tête, il est naturel de les fusionner en un seul kernel. Notre contribution réside dans l’adaptation de ce kernel fusionné pour prendre en charge le cas spécifique de la variante GLM4-MoE, où seule la moitié des dimensions d’une tête sont rotationnées.
3. Transfert asynchrone
https://github.com/sgl-project/sglang/pull/14782
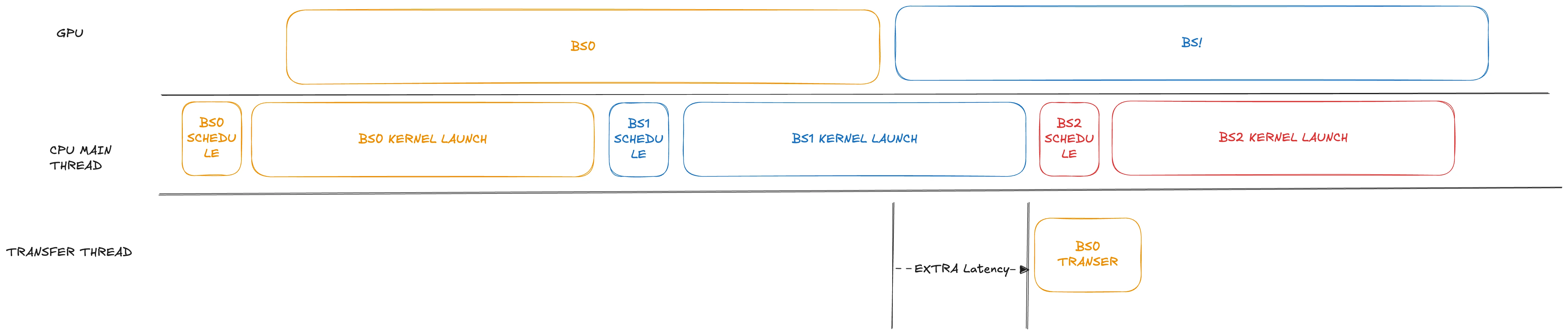
Dans les scénarios où la désagrégation PD avec des ordonnancements chevauchants est appliquée, bien que le débit puisse gagner environ 10 %, le TTFT chute de manière significative. Nous avons observé que dans l’implémentation actuelle du prefill, le processus de transfert de données est retardé jusqu’après le lancement du kernel pour le prochain lot. Pour un modèle comme GLM4.7, qui comporte 92 couches, le lancement de kernel sans CUDA Graph peut être long (prenant souvent des centaines de millisecondes, voire plus d’une seconde).
Pour résoudre ce problème, dans notre modification nous avançons légèrement l’étape de transfert, en l’ordonnançant juste après la fin des opérations GPU correspondantes. De plus, le transfert est placé dans un thread séparé. En gérant soigneusement les structures de compétition de données potentielles, il peut s’exécuter sans bloquer le thread principal.
Les gains de performance sont énormes pour les modèles avec de nombreux lancements de kernel. Dans des charges de travail élevées, cette optimisation peut économiser jusqu’à 1 seconde sur le TTFT, comme illustré ci-dessous.
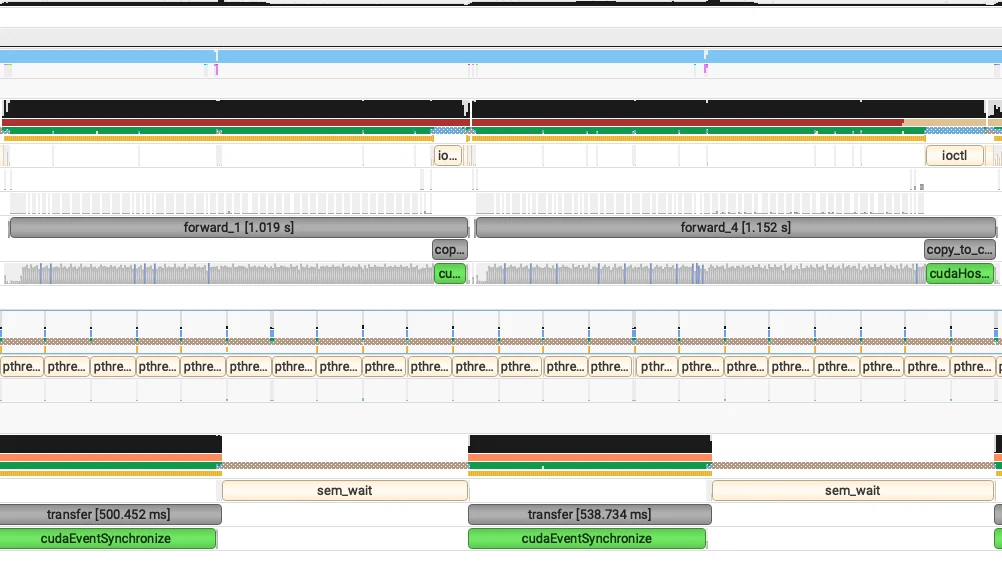
Résultats des benchmarks en production
Après avoir implémenté les approches décrites ci-dessus, nous avons observé des améliorations de performance significatives pour les modèles GLM-MoE, comme le démontrent clairement les résultats de benchmark ci-dessous.
Configuration du benchmark
- Longueur d’entrée : 4096
- Longueur de sortie : 1000
- Taux de requêtes : 14 req/s
- Modèle : GLM-4.7 FP8 (TP8)
Résultats
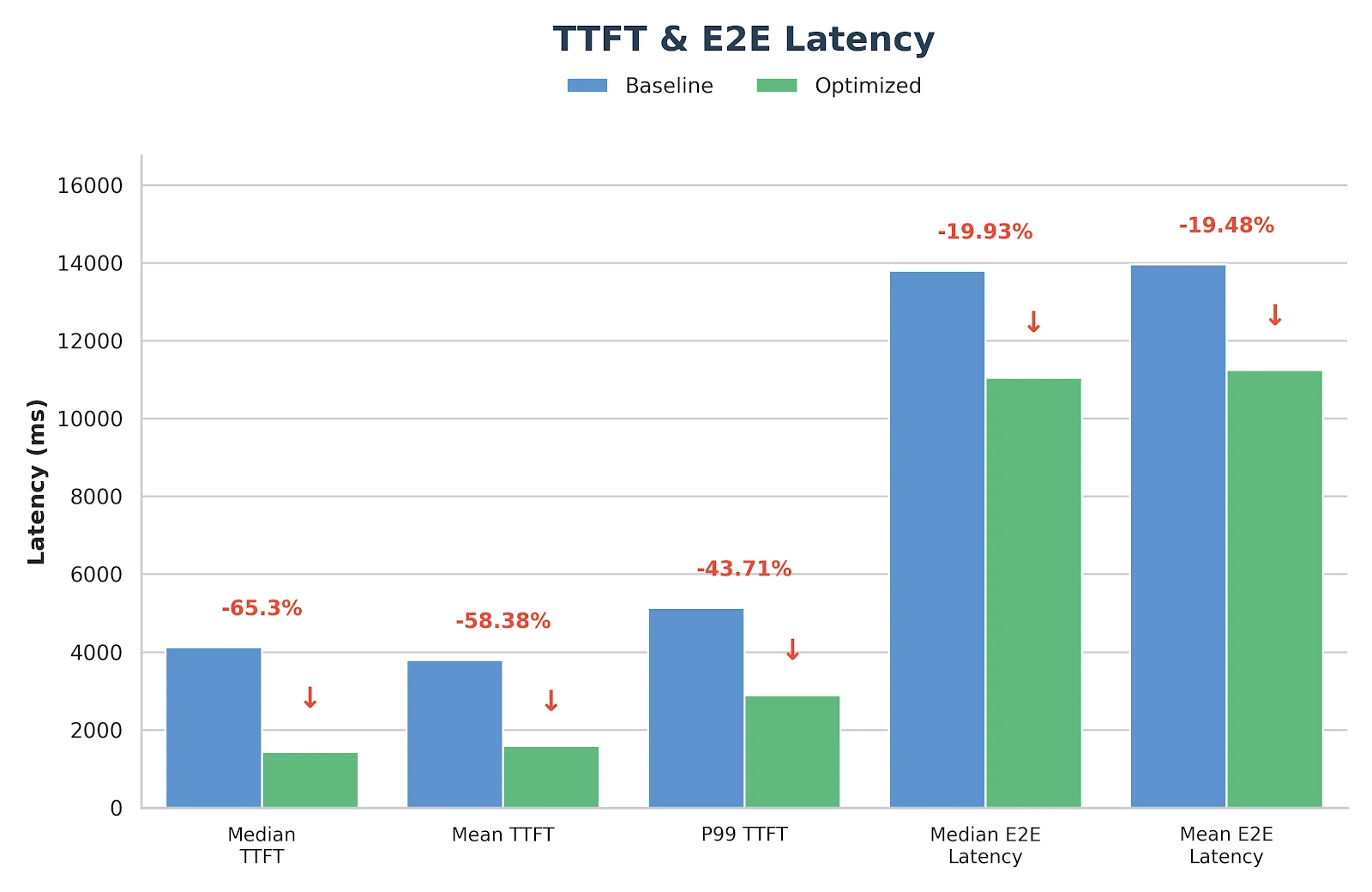
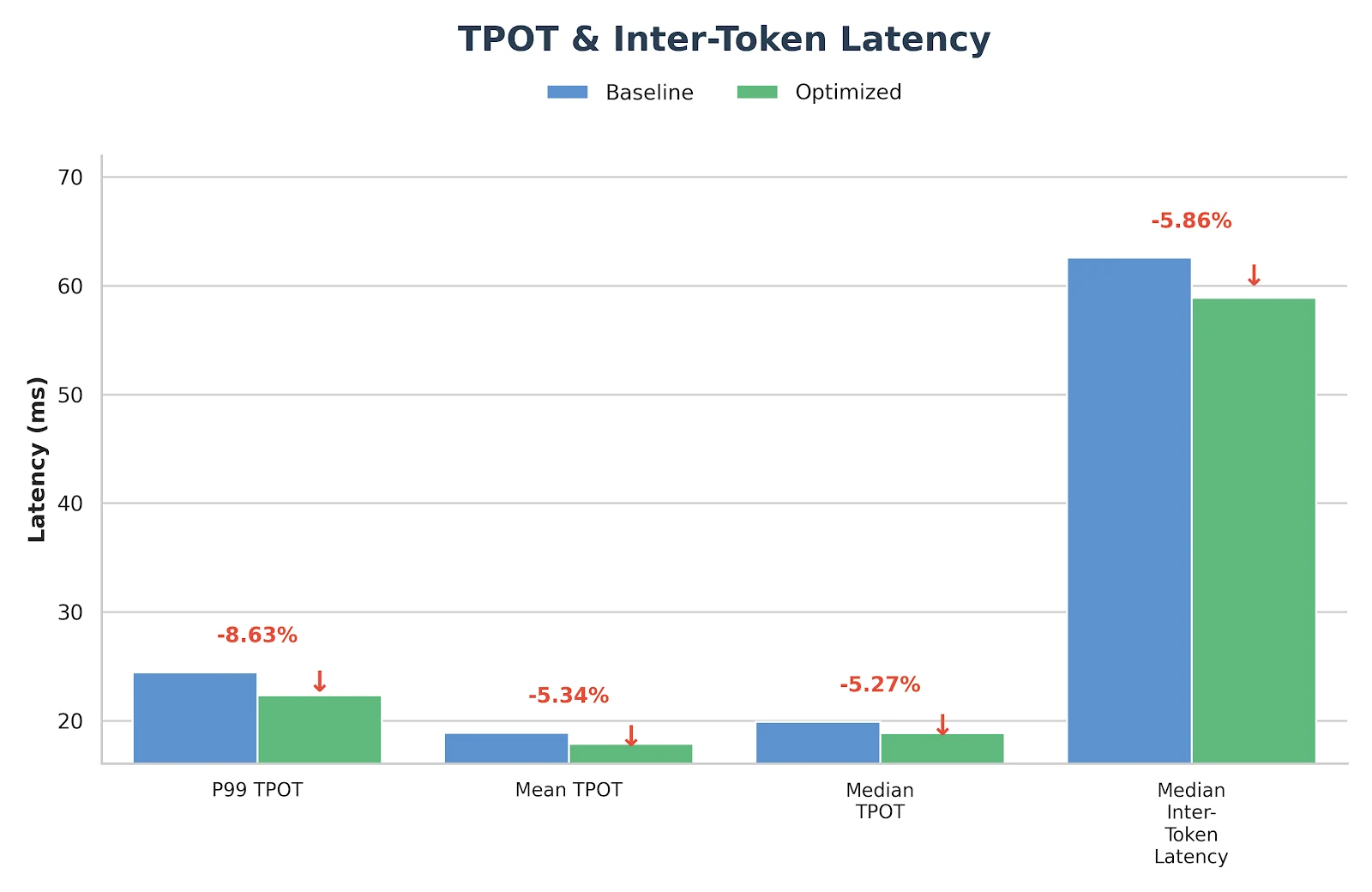
Ces optimisations ne sont pas seulement expérimentales : elles ont déjà été déployées et validées dans le service d’inférence en production de Novita.ai. Si vous recherchez un backend GLM-MoE fiable et à faible latence pour des charges de travail réelles, vous pouvez l’essayer directement sur novita.ai.
Décodage de suffixe
Les scénarios de codage agentique (comme Cursor et Claude Code) présentent un volume élevé de motifs de code réutilisables, permettant des optimisations de performance ciblées comme le décodage de suffixe.
Contexte : le goulot d’étranglement de l’inférence dans le codage agentique
Les agents LLM excellent dans les tâches de génération de code, mais la latence reste un défi majeur. Le décodage spéculatif traditionnel accélère l’inférence en prédisant plusieurs jetons à l’avance, mais les approches courantes nécessitent l’entraînement de modèles de brouillon supplémentaires, ce qui introduit une complexité d’ingénierie.
Fonctionnement du décodage de suffixe
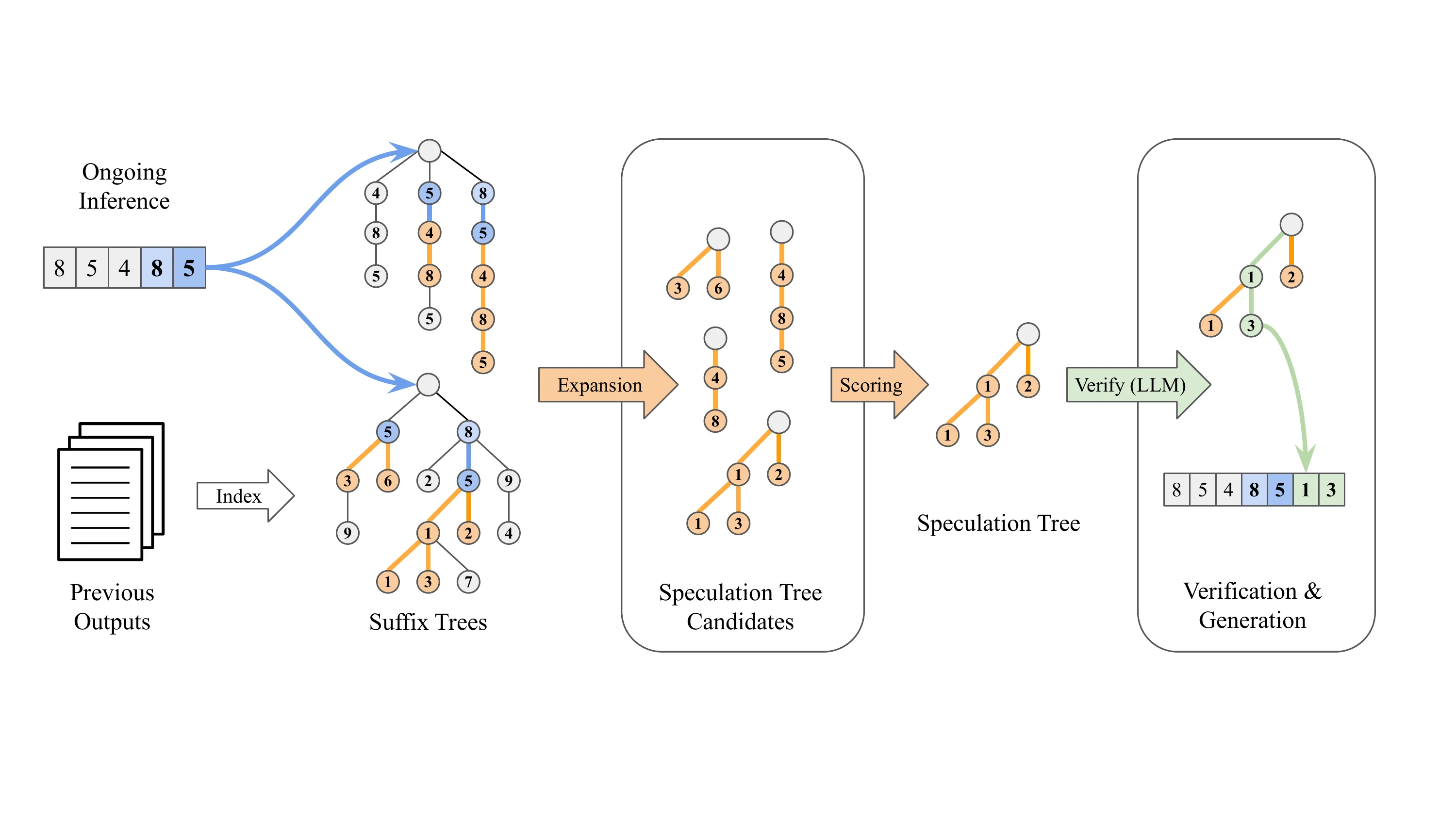
Le décodage de suffixe adopte une approche fondamentalement différente : il est totalement sans modèle :
- Aucune dépendance à des poids de modèle supplémentaires
- Exploite les motifs des séquences de sortie générées précédemment pour prédire les jetons à venir
- Lorsque le suffixe de la requête actuelle correspond à un motif historique, il poursuit le long de cette séquence historique pour la spéculation
Validation des données : analyse de la répétition des motifs de sortie
En analysant 22 sessions Claude Code (17 487 tours de conversation), nous avons découvert :
- Répétition de 39,3 % des motifs de sortie : fréquence élevée d’appels d’outils et de motifs de réponse similaires
- Comportements agentiques très structurés : des phrases fixes comme « Laissez-moi… », « Maintenant, laissez-moi… » apparaissent fréquemment
Pour soutenir la recherche future, nous avons rendu open source le jeu de données d’évaluation sur Hugging Face : https://huggingface.co/datasets/novita/agentic_code_dataset_22
Comparaison des performances
Avec l’accélération MTP intégrée, le décodage de suffixe réduit en outre le TPOT de 22 % (de 25,13 ms à 19,63 ms) :
| Indicateur | MTP | Décodage de suffixe | Variation |
|---|---|---|---|
| TPOT moyen | 25,13 ms | 19,63 ms | -21,90 % |
| TPOT médian | 25,95 ms | 20,05 ms | -22,70 % |
Conclusion
La combinaison de ces optimisations apporte des améliorations de performance complètes pour les déploiements SGLang :
- La Fusion des experts partagés résout les problèmes d’efficacité de calcul dans les modèles MoE
- La Fusion QK-Norm-RoPE réduit la surcharge de lancement de kernel
- Le Transfert asynchrone optimise le déplacement des données dans les déploiements désagrégés
- Le Décodage de suffixe exploite la répétition de motifs pour le décodage spéculatif dans le codage agentique.
La plupart des composants sont déjà fusionnés en amont ou en cours d’intégration ; n’hésitez pas à les consulter sur le dépôt SGLang.
Comment reproduire
Seuls les paramètres clés pertinents pour les performances sont présentés ici.
Les scripts de lancement complets (baseline vs optimisé), le harnais de benchmark et les traces de profilage sont publiés sur notre GitHub : https://github.com/novitalabs/sglang/tree/glm\_suffix.
- Indicateurs d’optimisation cœur (runtime SGLang)
--tp-size 8
--kv-cache-dtype fp8_e4m3
--attention-backend fa3
--chunked-prefill-size 16384
--enable-flashinfer-allreduce-fusion
--enable-fused-qk-norm-rope
--enable-shared-experts-fusion
--disaggregation-async-transfer
- Configuration du décodage spéculatif (charge de travail de codage agentique)
--speculative-algorithm NEXTN
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 4
- Configuration du décodage de suffixe (optionnel)
--speculative-algorithm SUFFIX
--speculative-suffix-cache-max-depth 64
--speculative-suffix-max-spec-factor 1.0
--speculative-suffix-min-token-prob 0.1
Références
- PR SGLang #13873 : Optimisation des experts partagés
- Blog d’ingénierie Snowflake : SuffixDecoding à l’échelle de la production
- Article NeurIPS : SuffixDecoding
- Dépôt Arctic Inference
Novita AI est une plateforme cloud IA leader qui fournit aux développeurs des API faciles à utiliser et une infrastructure GPU abordable et fiable pour construire et mettre à l’échelle des applications IA.


