

Zachary, expert en algorithmes chez Novita AI
Focus de recherche : Accélération de l’inférence
Introduction
Depuis l’émergence de H2O il y a un an, les articles de recherche sur la sparsité KV se sont multipliés. Cependant, un défi majeur dans les applications réelles est l’écart important entre la recherche académique et la mise en œuvre pratique. Par exemple, des frameworks comme vLLM adoptent PagedAttention, une technique mémoire basée sur la pagination, incompatible avec la plupart des algorithmes de sparsité, ou bien ces algorithmes performent moins bien que PagedAttention. Ces problèmes empêchent les algorithmes de sparsité d’être utilisés efficacement dans des environnements de production.
En examinant les articles académiques récents de l’année passée sur la sparsité KV, nous avons modifié le framework vLLM en nous basant sur la sparsité KV. Ces modifications étaient alignées avec les fonctionnalités d’optimisation inhérentes à vLLM, telles que Continuous Batching, FlashAttention et PagedAttention. Finalement, en comparant le framework modifié aux frameworks d’inférence SOTA, en utilisant les modèles, paramètres et matériels les plus couramment déployés en production, nous avons obtenu une accélération de 1,5x des performances d’inférence.
Avant d’aborder la sparsité KV, il est essentiel de mentionner la caractéristique des Activations Massives dans les LLM. Dans les LLM, un petit nombre de valeurs d’activation sont significativement plus actives que les autres, parfois jusqu’à 100 000 fois plus. En d’autres termes, un petit sous-ensemble de tokens joue un rôle critique. Cette observation constitue la base pour appliquer les techniques de sparsité KV, où ne conserver que les tokens importants peut améliorer les performances d’inférence.
Des analyses spécifiques sur Llama2 et Llama3 soutiennent cette observation, comme le montrent la Fig. 1 et la Fig. 2.
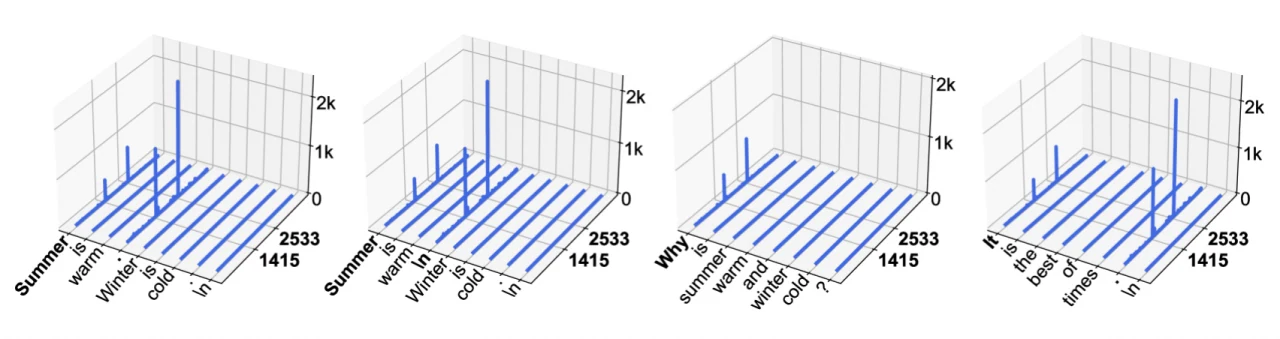
Fig. 1. Amplitudes d’activation (axe z) dans LLaMA2-7B. Les axes x et y correspondent aux dimensions de séquence et de caractéristiques. Pour ce modèle spécifique, nous observons que les activations de grande amplitude apparaissent dans deux dimensions de caractéristiques fixes (1415, 2533), et deux types de tokens : le token de début et le premier point (.) ou le token de nouvelle ligne (\ ).
Contrairement à Llama2, Llama3 ne présente pas la caractéristique d’activations massives dans toutes les couches. Dans les couches inférieures, les activations sont plus uniformément réparties, tandis que les couches intermédiaires affichent des motifs d’attention localisés. Ce n’est que dans les couches supérieures que le phénomène d’activations massives devient important. Cette observation explique pourquoi des modèles comme Llama3 adoptent des techniques de sparsité hiérarchique, adaptant la sparsité à différentes couches selon leurs motifs d’activation spécifiques.
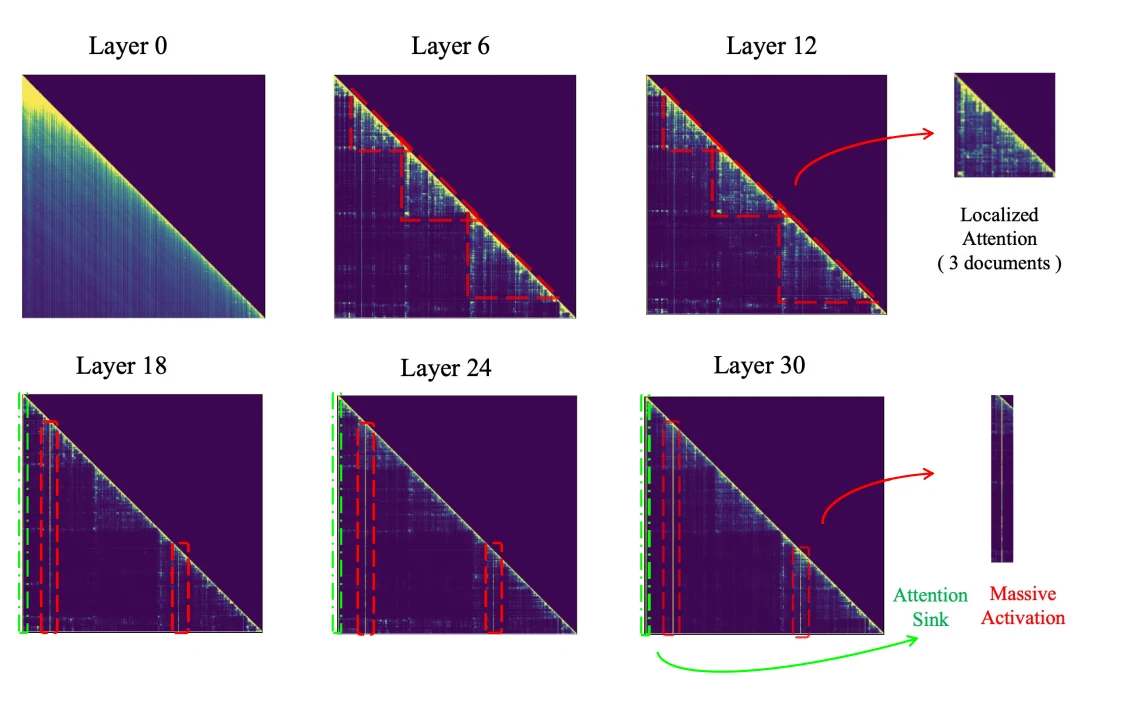
Fig. 2. Les motifs d’attention de la génération augmentée par récupération à travers les couches dans LLaMa (Touvron et al., 2023a;b) révèlent que dans les couches inférieures, le modèle adopte un mode d’attention large, distribuant les scores d’attention uniformément sur tout le contenu. Dans les couches intermédiaires, l’attention devient plus localisée dans chaque document, indiquant un affinement de l’agrégation d’informations (formes triangulaires rouges en pointillés dans les couches 6 et 10). Cela culmine dans les couches supérieures, où « l’attention massive » se concentre sur quelques tokens clés (barres d’attention concentrées après la couche 18), extrayant efficacement les informations essentielles pour les réponses.
Modèle système
Après avoir présenté la caractéristique des activations massives dans les LLM, nous avons une compréhension de base des principes de la sparsité KV. Ensuite, nous verrons comment la sparsité KV est mise en œuvre. Dans le processus d’inférence des grands modèles, trois goulots d’étranglement majeurs sont courants : la capacité mémoire GPU, la puissance de calcul et la bande passante d’E/S. Pour éviter des calculs redondants, le KV est souvent mis en cache pendant l’inférence, ce qui entraîne une consommation importante de mémoire GPU. Parallèlement, la charge de calcul et le débit d’E/S deviennent des goulots d’étranglement critiques dans les étapes de préremplissage (Prefill) et de décodage (Decode), respectivement.
Notre modification du framework vLLM repose sur la caractéristique des activations massives des LLM, implémentant une sparsité par couche (c’est-à-dire différents niveaux de sparsité pour différentes couches). Cette approche réduit considérablement la surcharge associée à la mise en cache KV, accélérant ainsi le processus d’inférence des modèles LLM.
Comme illustré dans la Fig. 3, pendant le processus d’inférence, nous appliquons la sparsité KV à différentes couches du modèle. En utilisant une stratégie d’élagage, nous éliminons les paires KV avec des scores faibles tout en conservant celles avec des scores élevés et une proximité plus grande. Cette approche réduit l’utilisation de la mémoire, ainsi que la charge de calcul et d’E/S, conduisant finalement à une inférence accélérée.
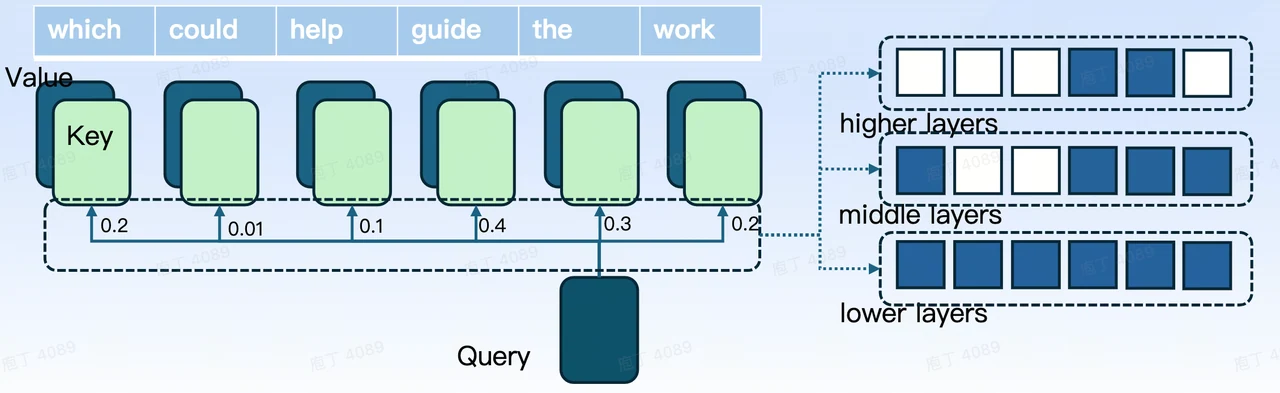
Fig. 3. Impact de la sparsité KV sur le modèle
Résultats d’accélération de l’inférence
La principale préoccupation de la plupart des chercheurs est l’impact réel de la sparsité KV dans le framework vLLM. Avant d’entrer dans les détails, nous présentons d’abord les résultats d’évaluation des performances.
1. Performances d’inférence
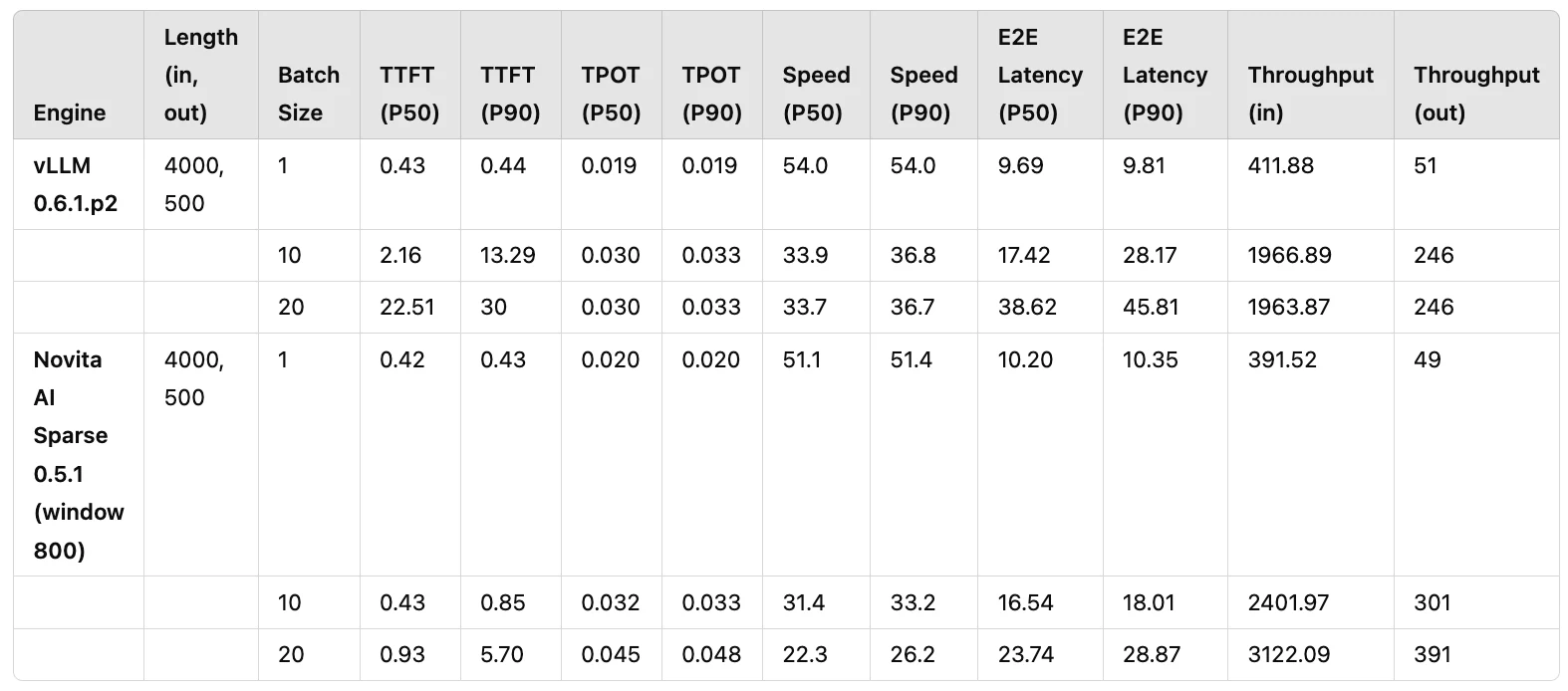
Dans les applications réelles de LLM, une longueur d’entrée/sortie de 4000/500 est la configuration la plus courante. De plus, la carte RTX 4090 est l’un des GPU les plus utilisés dans l’industrie. Sur la base de ces conditions, nous avons mené des tests de performance par lots. Le groupe témoin est vLLM 0.6.1.p2, tandis que le groupe expérimental est Novita AI Sparse 0.5.1 (une version modifiée de vLLM 0.5.1 avec sparsité KV). Plusieurs séries de tests de performance comparatifs ont été réalisées entre les deux, avec des métriques clés incluant TTFT (temps jusqu’au premier token, crucial pour l’expérience utilisateur) et Throughput (vitesse d’inférence réelle).
Les résultats finaux des tests sont présentés dans le Tableau 1. En appliquant la sparsité KV, nous avons pu augmenter le débit de vLLM d’environ 1,58x, tout en maintenant un TTFT utilisable (P50 sous 1 seconde). De plus, dans des scénarios avec des tailles de lots plus grandes, vLLM 0.6.1.p2 atteignait sa limite de performance à un niveau de concurrence de 10, tandis que Novita AI Sparse 0.5.1 pouvait maintenir des performances TTFT stables même à un niveau de concurrence de 20. Cela démontre la robustesse de la sparsité KV pour garantir la stabilité des performances dans des environnements de production.
Tableau 1 : Comparaison des performances entre vLLM 0.6.1.p2 et Novita AI Sparse 0.5.1
2. Précision du modèle
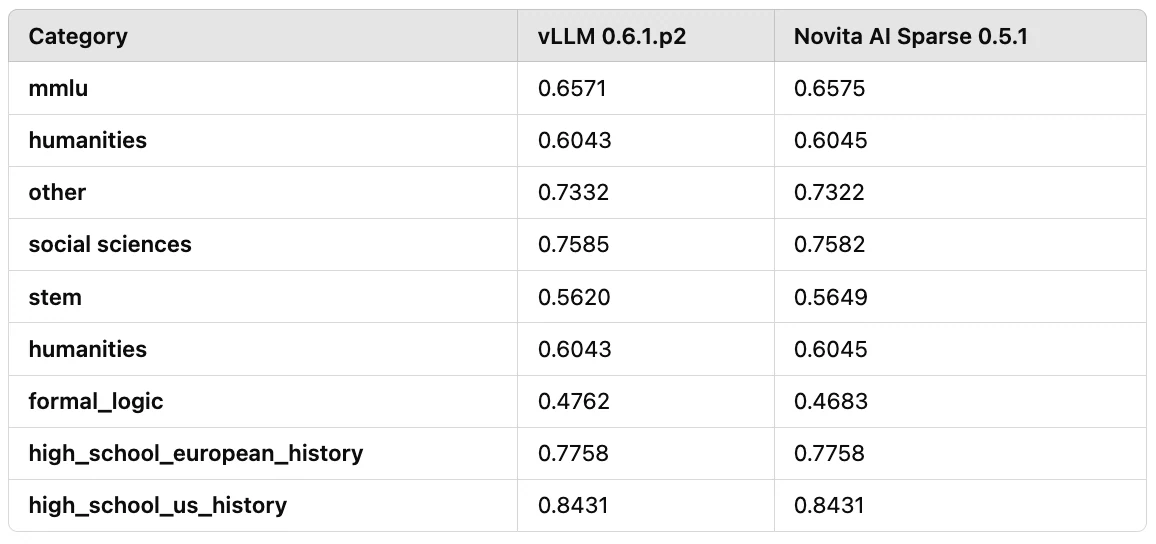
Puisque la sparsité KV est un algorithme de compression avec perte, il est également important d’évaluer les performances du modèle. Nous avons effectué des évaluations basées sur Llama3–8B, y compris des évaluations utilisant MMLU et d’autres benchmarks. Les résultats indiquent que la perte de précision reste inférieure à environ 3%.
Comme le montre le Tableau 2, nous avons testé les performances du modèle en utilisant MMLU et des benchmarks humanités :
Tableau 2 : Résultats d’évaluation des performances de Llama3–8B avec MMLU et benchmarks Humanités
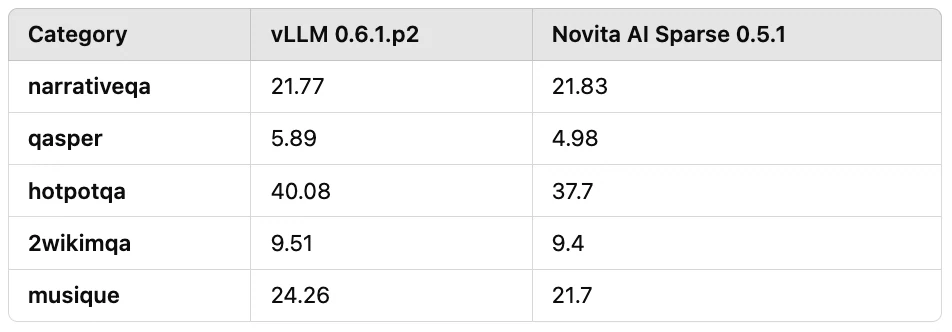
Deuxièmement, nous avons évalué les tâches de QA dans des scénarios de longs textes courants dans les applications pratiques, avec des longueurs d’entrée de 7k à 30k. Le taux de compression a été maintenu à plus de 10 fois, comme indiqué dans le Tableau 3. Les résultats ont montré une perte de précision globale d’environ 10 %.
Tableau 3 : Résultats d’évaluation des tâches de QA sur longs textes avec des longueurs d’entrée de 7k à 30k
Techniques clés
1. Sparsité par couche et parallélisme de tenseurs
Le framework vLLM utilise une stratégie d’ordonnancement par itération, communément appelée Continuous Batching. Cette approche d’ordonnancement ne consiste pas à attendre que chaque séquence d’un batch termine sa génération ; elle facilite l’ordonnancement par itération, ce qui se traduit par une utilisation GPU plus élevée par rapport au batching statique. Comme mentionné au début de cet article, des modèles comme Llama3–8B possèdent naturellement des caractéristiques telles que la sparsité hiérarchique. Par conséquent, nos modifications basées sur Continuous Batching ont rencontré une série de défis, comme illustré dans la Fig. 4.
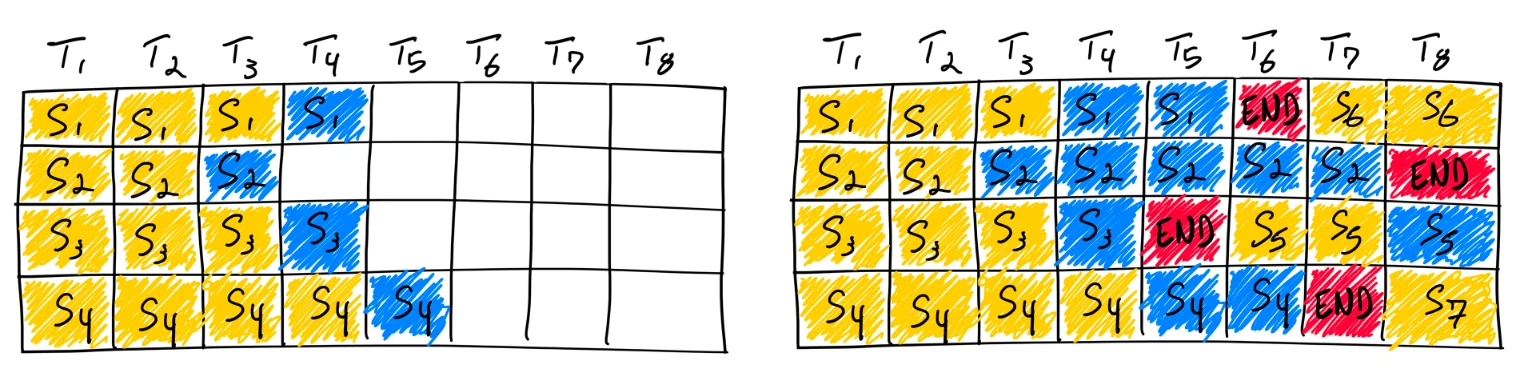
Fig. 4. Complétion de sept séquences à l’aide du batching continu. À gauche, vous voyez le lot après une seule itération, tandis qu’à droite, le lot après plusieurs itérations. Dès qu’une séquence émet un token de fin de séquence, nous introduisons une nouvelle séquence à sa place (par exemple, les séquences S5, S6 et S7). Cette méthode augmente l’utilisation du GPU en évitant qu’il attende la fin de toutes les séquences avant d’en initier une nouvelle.
Le principal défi que nous avons relevé était la gestion de la mémoire entre différentes couches. Étant donné que vLLM utilise un modèle de gestion mémoire paginée unifié et que la stratégie de file d’attente ne peut supporter que le mode Full Cache ou Sliding Window, nous avons modifié la structure centrale de vLLM pour permettre le support des deux options.
Cet ajustement donne à chaque couche la flexibilité de choisir entre Full Cache ou Sliding Window, permettant différents niveaux de sparsité entre les couches, comme illustré dans le diagramme ci-dessous.
Le premier défi à relever est le problème de gestion mémoire entre différentes couches. Puisque vLLM utilise un modèle de gestion mémoire paginée unifié pour toutes les couches, et que la stratégie de file d’attente permet soit Full Cache, soit Sliding Window, nous devons ajuster la structure sous-jacente de vLLM. Concrètement, cela implique de permettre le support à la fois de Full Cache et de Sliding Window, afin que différentes couches puissent choisir indépendamment leur stratégie de gestion mémoire préférée. Cet ajustement permet finalement différents degrés de sparsité entre les couches. Le diagramme structurel correspondant est présenté dans la Figure 5.
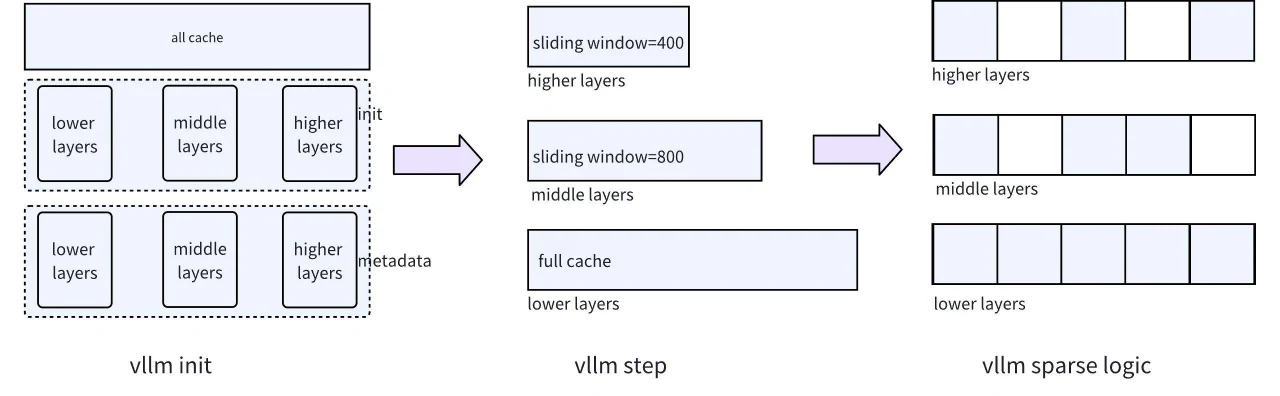
Fig. 5. Structure de gestion mémoire par couche dans vLLM
Dans l’ensemble, les ajustements peuvent être classés en trois phases distinctes :
Phase d’initialisation du service : Pendant le démarrage du service, la mémoire allouée pour les trois couches est initialisée principalement par le calcul de l’espace restant, ainsi qu’une initialisation hiérarchique de la structure Metadata. En revanche, le vLLM original fonctionne comme un Full Cache complet, sans prendre en compte la logique d’allocation mémoire pour différentes couches.
Phase de préparation des étapes : Pendant l’initialisation des étapes dans vLLM, en particulier dans les phases impliquant les méthodes du gestionnaire de blocs et du modèle runner, différentes stratégies de gestion de tables de blocs sont utilisées pour différentes couches, afin de contrôler le mécanisme de mise à jour du KV. Comme illustré dans la figure précédente, nous utilisons le mécanisme Full Cache pour les trois premières couches, stockant tous les KV, tandis que les couches au-delà de la troisième utilisent la stratégie Sliding Window pour remplacer automatiquement les KV avec les scores les plus bas. Cette approche permet une allocation flexible de l’espace mémoire adaptée aux besoins de chaque couche, économisant ainsi de l’espace tout en maximisant l’efficacité de l’algorithme de sparsité.
Phase de calcul de la sparsification : Cette phase a généralement lieu après l’exécution du modèle, où les opérations de sparsité sont effectuées en fonction des scores de sparsité calculés. Une considération clé à cette étape est la compatibilité avec des technologies telles que le parallélisme de tenseurs, les graphes CUDA et GQA. Dans les implémentations pratiques, le parallélisme de tenseurs nécessite une attention particulière. Comme illustré dans la figure ci-dessous, dans un scénario multi-GPU sur une seule machine, il est essentiel d’utiliser un mécanisme de partitionnement approprié pour confiner les opérations de sparsification KV à chaque GPU, évitant ainsi les communications entre GPU. Heureusement, l’unité d’Attention utilise une approche de partitionnement basée sur ColumnLinear, ce qui rend son implémentation relativement simple.
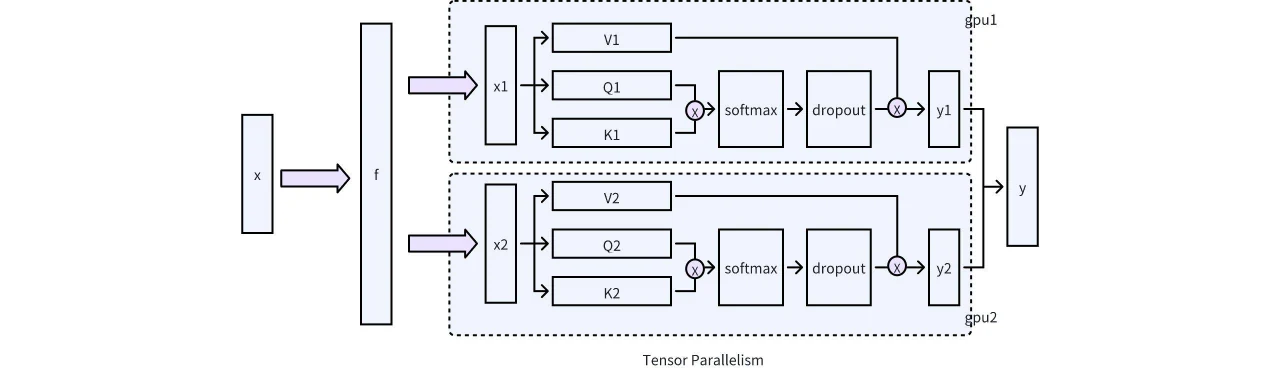
Fig. 6. Processus en trois étapes pour la gestion mémoire et la sparsification dans vLLM
La discussion ci-dessus porte principalement sur les modifications apportées au niveau du framework pour supporter la sparsité hiérarchique dans vLLM. Ensuite, nous nous concentrerons sur les optimisations implémentées au niveau CUDA.
2. Modification de l’Attention
Les modifications au niveau CUDA concernent principalement les améliorations apportées à l’unité de calcul Attention, en particulier FlashAttention et PagedAttention. Bien que PagedAttention soit relativement simple, nous insisterons sur les modifications liées à FlashAttention.
Tout d’abord, présentons la formule de calcul de l’Attention :
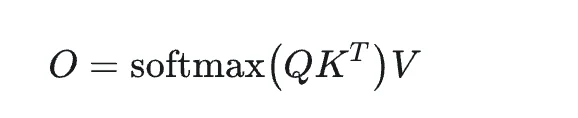
Comme le montre la formule, le calcul softmax implique le produit QK, et c’est un algorithme en 2 passes (nécessitant deux passages). Cependant, le résultat final O peut être obtenu en une seule passe (un passage) avec l’algorithme FlashAttention. La logique d’implémentation de FlashAttention peut être illustrée par la Fig. 7 de l’article FlashAttention2. En bref, il s’agit de parcourir Q par blocs pour effectuer des calculs par blocs sur KV, tout en mettant à jour progressivement les données O, P et rowmax jusqu’à la fin de la boucle. Enfin, diviser O par ℓ permet le calcul en une passe de FlashAttention.

Fig .7. Logique d’implémentation de FlashAttention2
Pour notre implémentation de la sparsité KV, il est important de noter que pendant le calcul de FlashAttention, les valeurs nécessaires pour softmax (rowmax/ℓ, le maximum global et les valeurs cumulées) sont déjà calculées. Cependant, FlashAttention ne retourne pas les résultats de ces deux valeurs.
Avec une compréhension de base de FlashAttention, nous pouvons maintenant discuter des formules de score pour la sparsification présentées dans des articles tels que PYRAMIDKV :
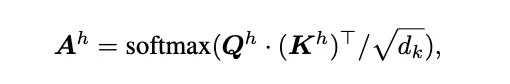
où [n − α, n] est la plage des tokens d’instruction. Dans chaque couche l et pour chaque tête h, les top k l tokens avec les scores les plus élevés sont sélectionnés, et leurs caches KV respectifs sont conservés. Tous les autres caches KV sont rejetés et ne seront utilisés dans aucun calcul ultérieur pendant le processus de génération.
Plus précisément, nous calculons le score de sélection du i-ième token à conserver dans le cache KV comme S dans chaque tête d’attention h par :
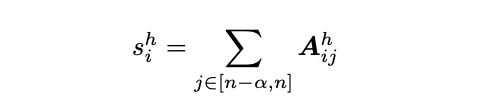
Dans la formule ci-dessus, A représente le score softmax, tandis que S désigne la somme des scores des a valeurs softmax les plus proches. Comme indiqué, softmax lui-même est un algorithme en 2 passes, ce qui ne peut pas être intégré directement dans FlashAttention. Cela implique également que le score de sparsification ne peut pas être implémenté en une passe.
Comme mentionné précédemment, bien que FlashAttention ne produise pas les scores softmax, il calcule des valeurs intermédiaires telles que rowmax/ℓ. Par conséquent, en se référant à Online Softmax : algorithme en 2 passes, nous pouvons utiliser les sorties de rowmax/ℓ pour obtenir le score spécifique S pour la sparsité KV. En pratique, nous devons seulement apporter des améliorations à FlashAttention illustrées dans la Fig. 7 pour répondre à cette exigence.
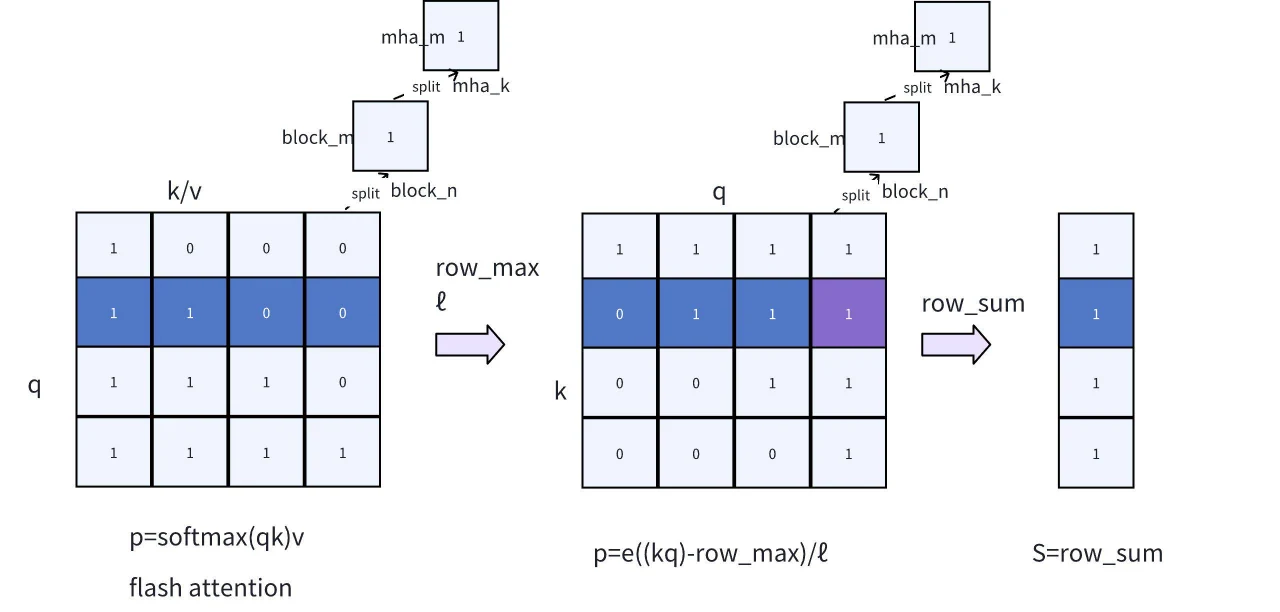
Fig .7. Modification de FlashAttention pour le score de sparsité KV
- Sortie de rowmax/ℓ dans FlashAttention : FlashAttention intègre les sorties de rowmax/ℓ. Comme ces valeurs représentent le maximum et les totaux cumulés, leur taille de données est minime, n’ayant qu’un impact négligeable sur les performances globales de FlashAttention. En réutilisant rowmax/ℓ, nous pouvons éviter un second passage, améliorant ainsi l’efficacité globale du calcul.
- Ajout de l’étape Online Softmax : Nous introduisons l’étape Online Softmax, qui s’appuie sur FlashAttention en calculant les scores softmax à l’aide de la formule p=e((kq)−row_max)/ℓ (logique en une passe). Ensuite, en effectuant une sommation par ligne, nous pouvons calculer le score de sparsification S.
Dans l’implémentation d’Online Softmax, deux détails critiques nécessitent une attention particulière :
- Ajustement de l’ordre des boucles : Puisque S est la somme des scores basés sur la dimension k, il est nécessaire d’ajuster le calcul dans Online Softmax de q*k à *k**q, par rapport à l’attention. Cet ajustement évite des communications inutiles entre différents blocs en transformant la somme de colonnes en somme de lignes, permettant à tous les calculs d’être effectués dans les registres.
- Positions de début et de fin de q : En raison de la présence de l’encodage causal et de la logique de sommation pour les a plus proches, il n’est pas nécessaire de parcourir tous les q avec k. En se référant aux indicateurs de masque marqués 0/1 dans la Fig. .7, nous pouvons déterminer si un bloc correspondant nécessite un calcul en fonction des positions de début et de fin de q, ce qui économise considérablement les ressources de calcul. Par exemple, si la longueur de l’invite d’entrée est de 5000 et la longueur du a le plus proche est de 256, le calcul conventionnel nécessiterait 5000*5000 opérations. Cependant, en enregistrant les positions de début et de fin, seules *5000**256 opérations sont nécessaires, améliorant ainsi l’efficacité du calcul.
PagedAttention effectue un travail similaire à celui de FlashAttention, avec l’objectif commun de calculer le score final S. Une explication détaillée de PagedAttention n’est pas fournie ici.
Conclusion
Notre version modifiée, Novita AI Sparse 0.5.1, basée sur vLLM 0.5.1, supporte actuellement principalement des modèles comme Llama3–8B et Llama3–70B. Elle fonctionne en mode d’inférence utilisant les graphes CUDA et est principalement déployée sur des GPU grand public comme la RTX 4090. Il reste une marge d’optimisation significative tant sur le plan technique que algorithmique.
Petite précision : Les fonctionnalités suivantes ne sont pas encore supportées dans vLLM-0.6.2 :
- Chunked-prefill
- Prefix caching
- Backends autres que FlashAttention, comme FlashInfer
Pour ceux qui sont intéressés par Novita AI Sparse 0.5.1, vous pouvez visiter Novita AI pour l’expérimenter avant les autres.
Références :
[1] H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
[2] Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
[3] SnapKV: LLM Knows What You are Looking for Before Generation
[4] PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
[5] PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
[6] MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
[7] Layer-Condensed KV Cache for Efficient Inference of Large Language Models
[8] TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
[9] CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
[10] KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation


