

Zachary,Novita AI 演算法專家
研究重點:推論加速
引言
在過去一年中,自從 H2O 出現以來,關於 KV 稀疏性的研究論文層出不窮。然而,在實際應用中一個重大的挑戰是學術研究與實際實作之間的巨大鴻溝。舉例來說,像 vLLM 這樣的框架採用了 PagedAttention,這是一種基於分頁的記憶體技術,而它與大多數稀疏演算法不相容,或者這些演算法的表現不如 PagedAttention。這類問題使得稀疏演算法無法在生產環境中得到有效利用。
透過回顧過去一年在 KV 稀疏性領域的近期學術論文,我們基於 KV 稀疏性對 vLLM 框架進行了修改。這些修改與 vLLM 框架的內建最佳化特性保持一致,例如 Continuous Batching、FlashAttention 和 PagedAttention。最終,透過將修改後的框架與當前最先進的推論框架進行比較,使用在生產環境中最常部署的模型、參數和硬體,我們實現了 1.5 倍的推論效能提升。
在討論 KV 稀疏性之前,有必要先了解 LLM 中的 Massive Activations 特性。在 LLM 中,少數活化值比其他值活躍得多,有時甚至超過不活躍值 10 萬倍以上。換句話說,一小部分的 token 扮演了關鍵角色。這個觀察結果是應用 KV 稀疏性技術的基礎,即只保留重要的 token 就能提升推論效能。
來自 Llama2 和 Llama3 的具體分析資料進一步支持了這個觀察結果,如圖 1 和圖 2 所示。
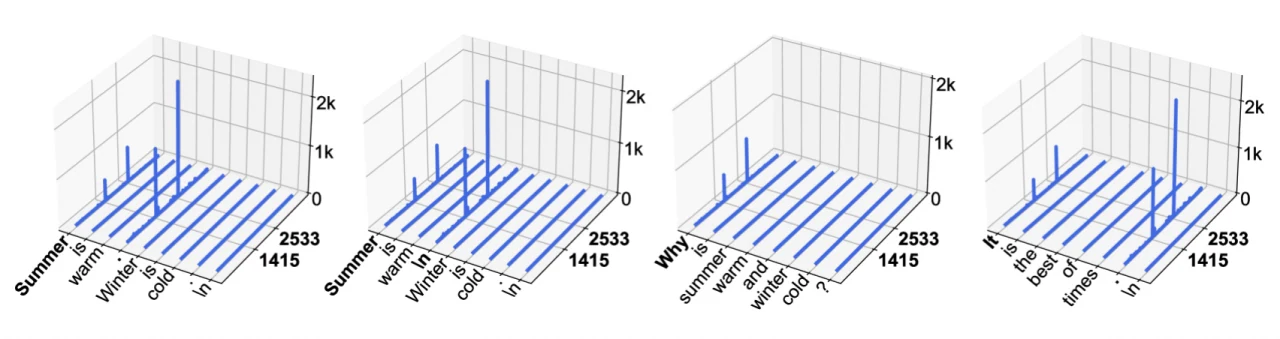
圖 1. LLaMA2-7B 中的活化幅度(𝐳 軸)。𝐱 和 𝐲 軸分別為序列和特徵維度。對於這個特定模型,我們觀察到具有巨大幅度的活化出現在兩個固定的特徵維度(1415, 2533),以及兩種類型的 token——起始 token,以及第一個句號(.)或換行 token(\)。
與 Llama2 不同,Llama3 並非在所有層都表現出 Massive Activations 特性。在較低層,活化分佈更均勻,而中間層則呈現局部化的注意力模式。只有在較高層,Massive Activations 現象才變得顯著。這個觀察結果解釋了為什麼像 Llama3 這樣的模型採用分層稀疏性技術,該技術根據各層特定的活化模式來客製化稀疏性。
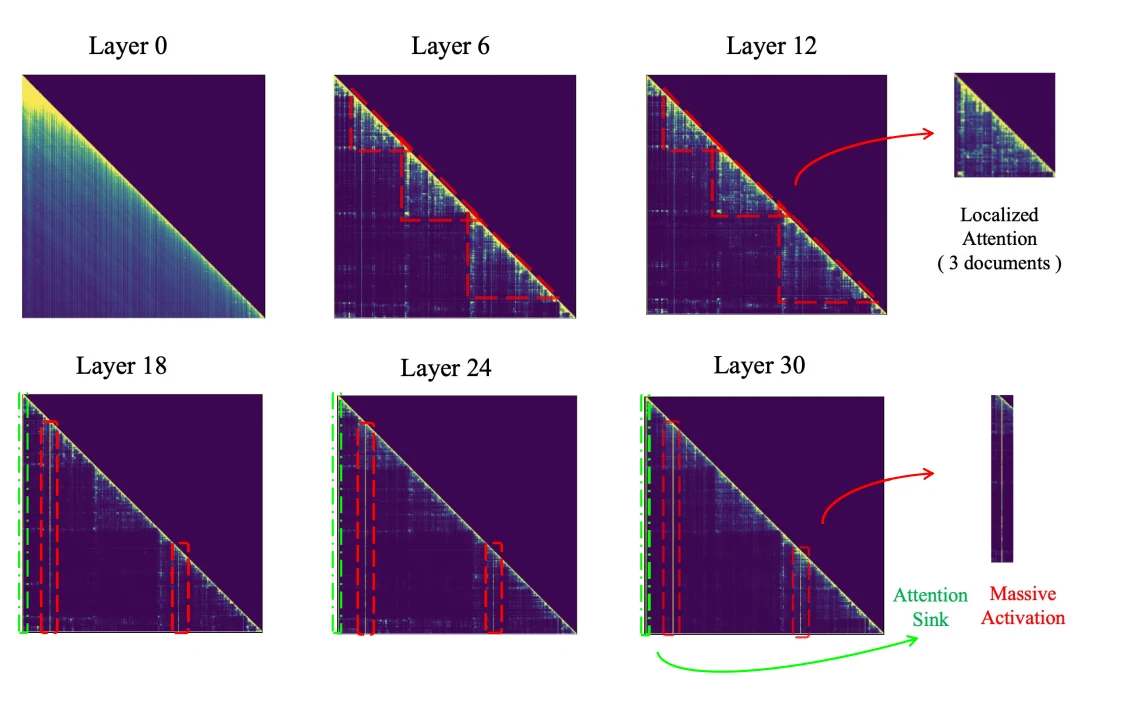
圖 2. LlaMa (Touvron et al., 2023a;b) 中檢索增強生成在跨層的注意力模式顯示,在較低層,模型呈現廣譜注意力模式,將注意力分數均勻分佈在所有內容上。在中間層,注意力在每個文件內變得更加局部化,表示資訊聚合的精細化(第 6 層和第 10 層的紅色虛線三角形形狀)。最終在較高層,「巨大注意力」集中在少數關鍵 token 上(第 18 層之後的集中注意力條),有效地提取答案所需的基本資訊。
系統模型
在介紹完 LLM 中的 Massive Activations 特性後,我們現在對 KV 稀疏性的原理有了基本了解。接下來,我們將討論如何實作 KV 稀疏性。在大型模型的推論過程中,通常會遇到三個主要瓶頸:GPU 記憶體容量、計算能力和 I/O 頻寬。為了避免重複計算,推論時經常會快取 KV,導致 GPU 記憶體的大量消耗。同時,計算負載和 I/O 吞吐量分別成為 Prefill 和 Decode 階段的關鍵瓶頸。
我們對 vLLM 框架的修改基於 LLM 的 Massive Activations 特性,實作了逐層稀疏性(即不同層採用不同的稀疏程度)。這種方法顯著減少了 KV 快取相關的開銷,從而加速了 LLM 模型的推論過程。
如圖 3 所示,在推論過程中,我們對模型的不同層應用 KV 稀疏性。透過採用剪枝策略,我們移除分數較低的 KV 對,同時保留分數較高且距離較近的 KV 對。這種方法減少了記憶體使用量,以及計算和 I/O 開銷,最終實現了加速推論。
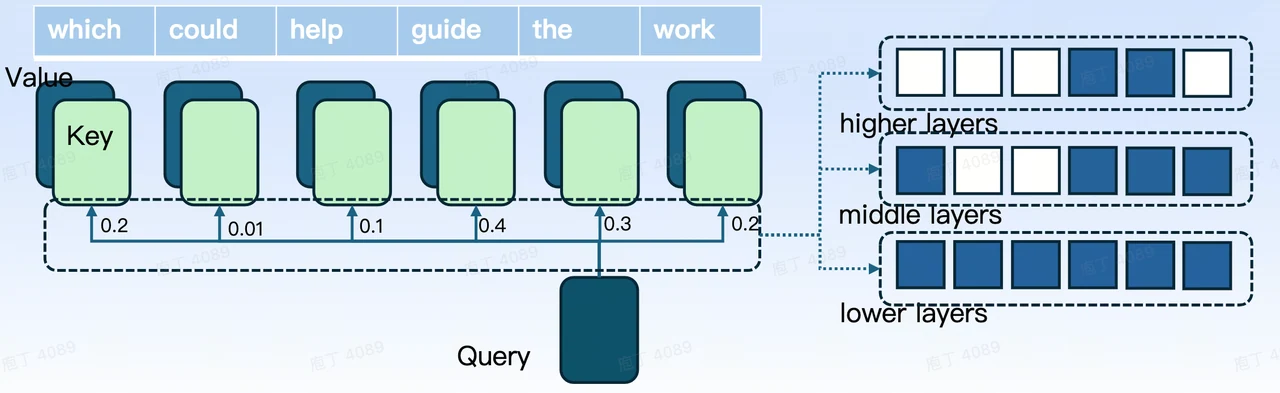
圖 3. KV 稀疏性對模型的影響
推論加速結果
大多數研究人員最關心的是 KV 稀疏性在 vLLM 框架中的實際影響。在深入探討細節之前,我們先呈現效能評估的結果。
1. 推論效能
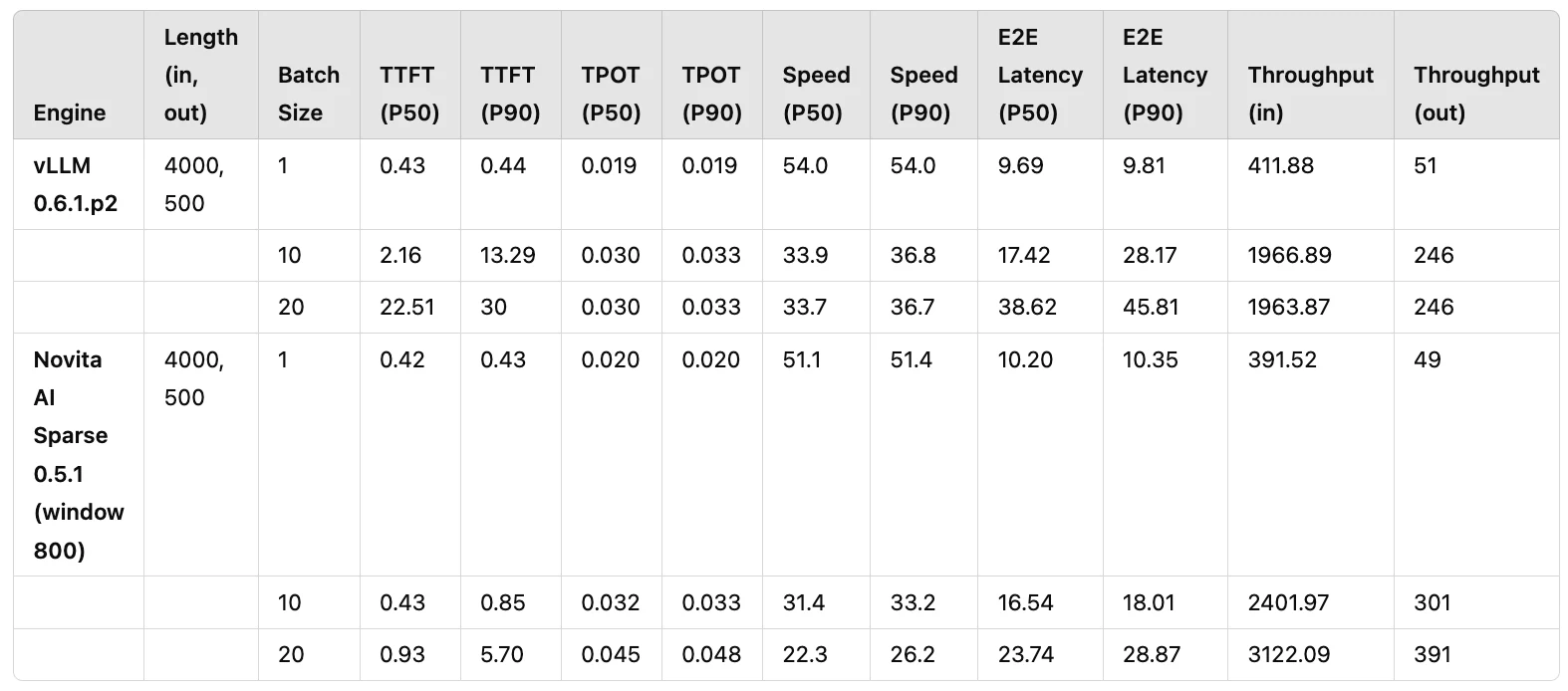
在實際的 LLM 應用中,輸入/輸出長度為 4000/500 是最常見的配置。此外,RTX 4090 GPU 是業界最廣泛使用的 GPU 之一。基於這些條件,我們進行了批次效能比較測試。對照組是 vLLM 0.6.1.p2,實驗組是 Novita AI Sparse 0.5.1(基於 KV 稀疏性修改的 vLLM 0.5.1 版本)。兩者之間進行了多輪效能比較測試,關鍵指標包括 TTFT(首個 token 生成時間,對使用者體驗至關重要)和 Throughput(實際推論速度)。
最終測試結果如表 1 所示。透過應用 KV 稀疏性,我們能夠將 vLLM 的吞吐量提升約 1.58 倍,同時保持可用的 TTFT(P50 低於 1 秒)。此外,在較大批次大小的情況下,vLLM 0.6.1.p2 在並發數為 10 時達到效能極限,而 Novita AI Sparse 0.5.1 即使在並發數為 20 時也能維持穩定的 TTFT 效能。這證明了 KV 稀疏性在生產環境中確保效能穩定性的穩健性。
表 1:vLLM 0.6.1.p2 與 Novita AI Sparse 0.5.1 的效能比較
2. 模型準確度
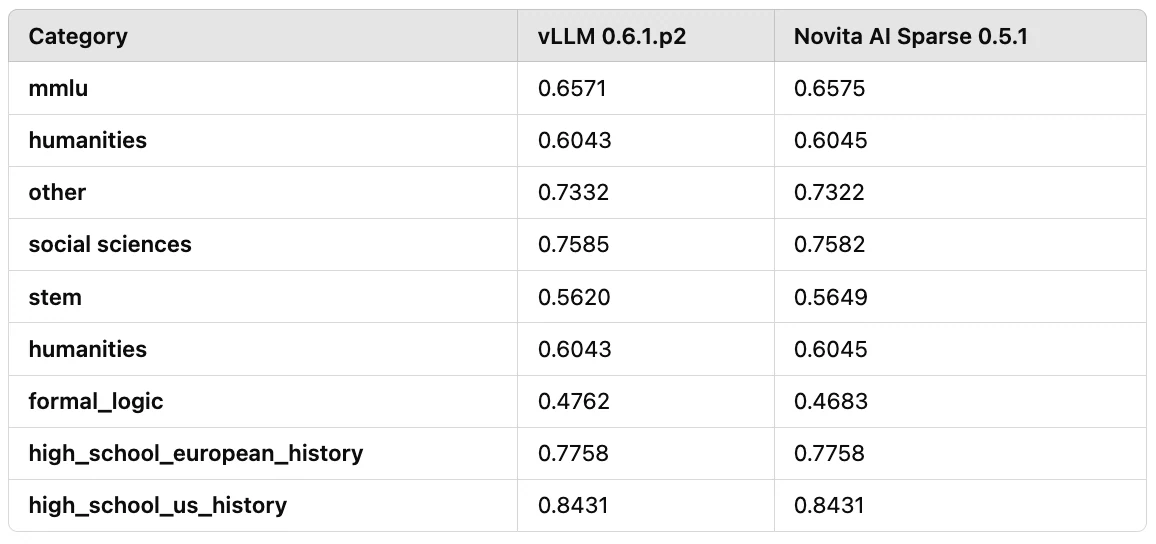
由於 KV 稀疏性是一種有損壓縮演算法,因此評估模型效能同樣重要。我們基於 Llama3-8B 進行了效能評估,包括使用 MMLU 和其他基準測試。結果表明,準確度損失約在 3% 以內。
如表 2 所示,我們使用 MMLU 和人文基準測試了模型效能:
表 2:使用 MMLU 和人文基準對 Llama3-8B 進行的效能評估結果
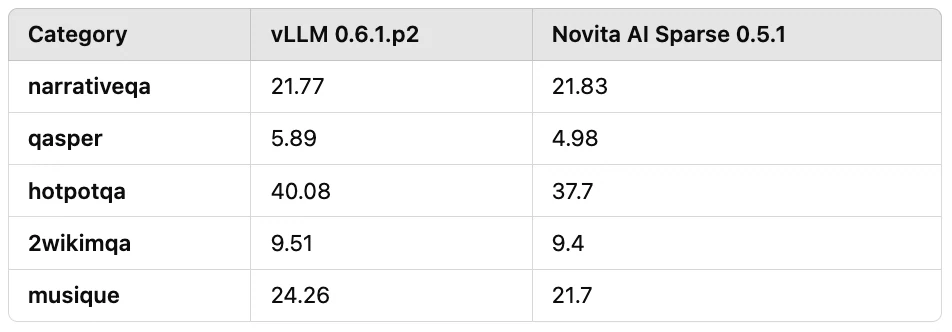
其次,我們對實際應用中常見的長文本場景(輸入長度範圍為 7k 至 30k)進行了問答任務評估。壓縮比維持在 10 倍以上,如表 3 所示。結果顯示整體準確度損失約為 10%。
表 3:輸入長度為 7k 至 30k 的長文本問答任務評估結果
關鍵技術
1. 逐層稀疏性與張量平行
vLLM 框架採用了一種迭代層級排程策略,通常稱為 Continuous Batching。這種排程方式的特點是不等待批次中的每個序列都完成生成,而是進行迭代層級的排程,與靜態批次相比能實現更高的 GPU 利用率。正如本文開頭所述,像 Llama3-8B 這樣的模型本身具有分層稀疏性等特性。因此,我們基於 Continuous Batching 的修改遇到了一系列挑戰,如圖 4 所示。
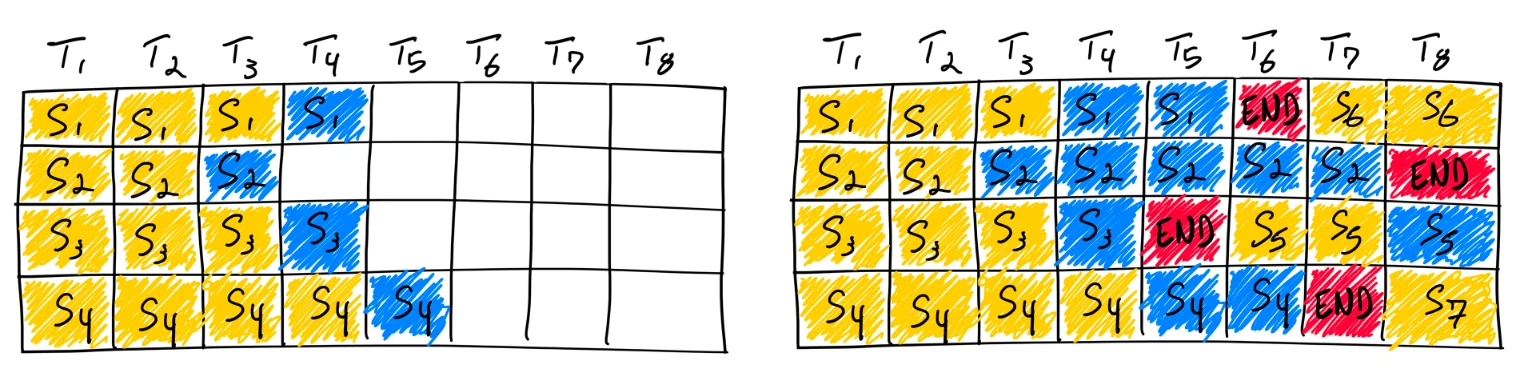
圖 4. 使用 Continuous Batching 完成七個序列。左側顯示單次迭代後的批次,右側顯示多次迭代後的批次。一旦某個序列發出序列結束 token,我們就在其位置引入一個新序列(例如序列 S5、S6 和 S7)。這種方法透過避免 GPU 等待所有序列完成後才啟動新序列,從而提高了 GPU 利用率。
我們處理的主要挑戰是跨不同層的記憶體管理。由於 vLLM 對所有層使用統一分頁記憶體管理模型,且佇列策略僅能支援 Full Cache 或 Sliding Window,我們修改了 vLLM 的核心結構,使其能夠同時支援這兩種選項。
這項調整賦予了每一層靈活性,可以選擇 Full Cache 或 Sliding Window,從而在不同層實現不同的稀疏程度,如下圖所示。
首先需要解決的是跨不同層的記憶體管理問題。由於 vLLM 對所有層使用統一分頁記憶體管理模型,且佇列策略允許 Full Cache 或 Sliding Window,我們需要調整 vLLM 的底層結構。具體來說,這涉及啟用對 Full Cache 和 Sliding Window 的支援,以便不同的層可以獨立選擇其偏好的記憶體管理策略。這項調整最終促成了不同層之間不同程度的稀疏性。對應的結構圖如圖 5 所示。
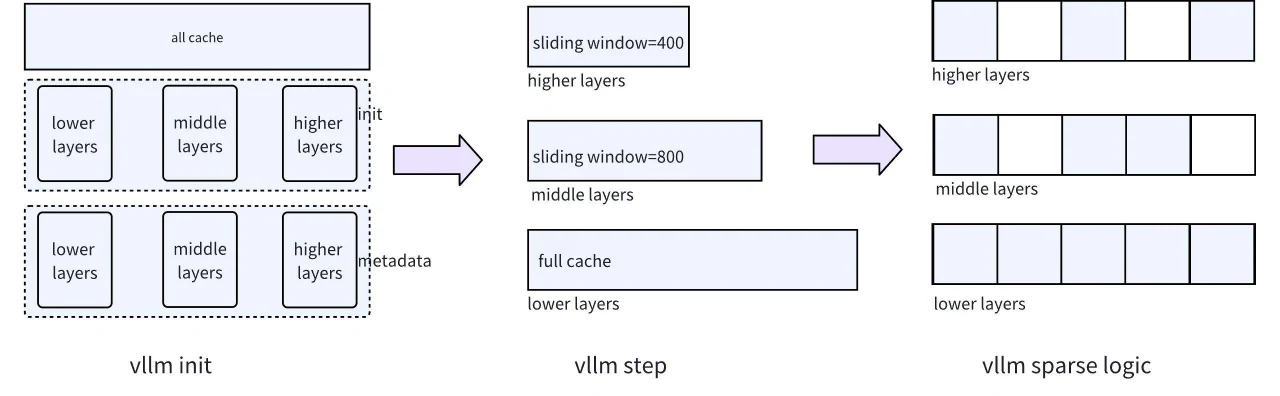
圖 5. vLLM 中的逐層記憶體管理結構
總體而言,這些調整可以分為三個不同的階段:
服務初始化階段: 在服務啟動過程中,主要透過計算剩餘空間以及 Metadata 結構的分層初始化,來初始化分配給三層的記憶體。相比之下,原始的 vLLM 作為一個完整的 Full Cache 運行,沒有考慮不同層的記憶體分配邏輯。
步驟準備階段: 在 vLLM 步驟的初始化過程中,特別是在涉及 block manager 和 model runner 方法的階段,對不同的層採用不同的 block table 管理策略來控制 KV 更新機制。如上圖所示,我們對前三層使用 Full Cache 機制,儲存所有 KV,而第三層之後的層則採用 Sliding Window 策略,自動替換分數最低的 KV。這種方法允許根據每層的需求靈活分配記憶體空間,從而節省空間,同時最大化稀疏演算法的效果。
稀疏化計算階段: 此階段通常發生在模型執行之後,根據計算出的稀疏分數執行稀疏化操作。這一步需要特別注意的是與 Tensor Parallelism、CUDA graphs 和 GQA 等技術的相容性。在實際工程實作中,Tensor Parallelism 需要特別關注。如下圖所示,在單機多 GPU 場景中,必須採用適當的分割機制,將 KV 稀疏化操作限制在每個 GPU 內,以避免 GPU 之間的通訊。幸運的是,Attention 單元採用基於 ColumnLinear 的分割方式,使其實作相對簡單。
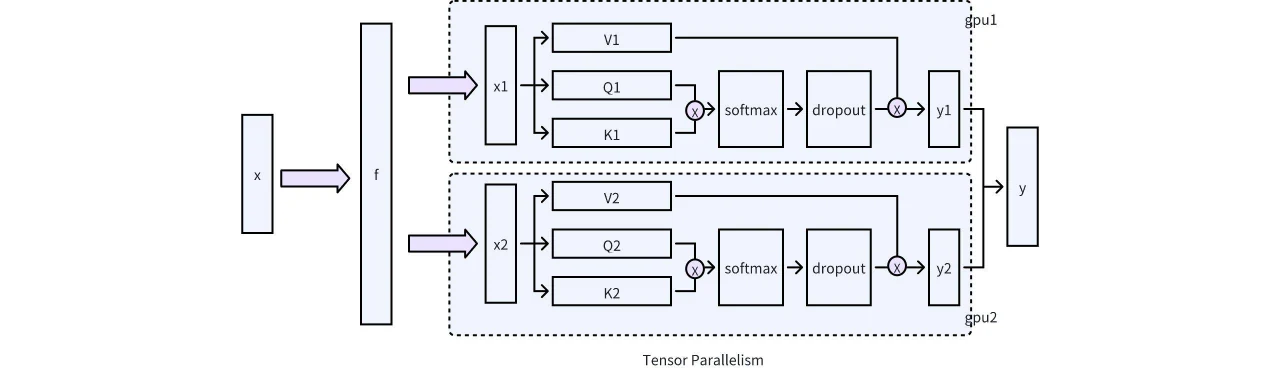
圖 6. vLLM 中記憶體管理與稀疏化的三階段流程
以上討論主要集中於在框架層級對 vLLM 進行修改以支援分層稀疏性。接下來,我們將把注意力轉向在 CUDA 層級實作的最佳化。
2. Attention 修改
CUDA 層級的修改主要集中於對 Attention 計算單元的增強,特別是 FlashAttention 和 PagedAttention。雖然 PagedAttention 相對直接,我們將重點關注與 FlashAttention 相關的修改。
首先,我們呈現 Attention 的計算公式:
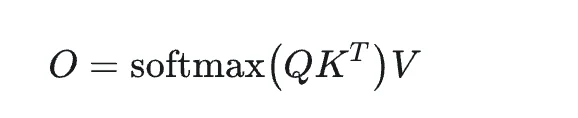
如公式所示,softmax 計算過程涉及 QK 乘積的計算,並且是一個 2-pass 演算法(需要兩次遍歷)。然而,最終的計算目標 O 可以使用 FlashAttention 演算法透過單次遍歷(1-pass)來實現。FlashAttention 的實作邏輯可以透過 FlashAttention2 論文的圖 7 來說明。簡而言之,它涉及對 Q 進行分塊遍歷,對 KV 進行區塊計算,同時逐步更新 O、P 和 rowmax 資料,直到迴圈結束。最後,將 O 除以 ℓ 即可實現 FlashAttention 的 1-pass 計算。

圖 7. FlashAttention2 的實作邏輯
對於我們實作的 KV 稀疏性,需要注意的是,在 FlashAttention 的計算過程中,softmax 所需的值——即 rowmax/ℓ(全域最大值和累積值)已經被計算出來。然而,FlashAttention 並不會回傳這兩個值的結果。
在對 FlashAttention 有了基本了解後,我們現在可以討論如 PYRAMIDKV 等論文中提出的稀疏化評分公式:
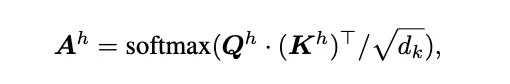
其中 [n − α, n] 是指令 token 的範圍。在每一層 l 和每個注意力頭 h 中,選擇得分最高的 top k l 個 token,並保留它們各自的 KV 快取。所有其他 KV 快取將被丟棄,並且在生成過程中的任何後續計算中都不會使用。
具體來說,我們計算在每個注意力頭 h 中選擇第 i 個 token 保留在 KV 快取中的分數 S,公式如下:
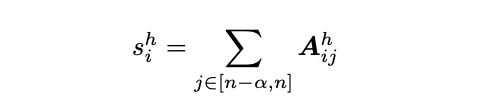
在上述公式中,A 代表 softmax 分數,而 S 表示最近 a 個 softmax 值的分數總和。如所述,softmax 本身是一個 2-pass 演算法,無法直接整合到 FlashAttention 中。這也意味著稀疏化評分無法以 1-pass 的方式實作。
如前所述,雖然 FlashAttention 不輸出 softmax 分數,但它確實計算了 rowmax/ℓ 等中間值。因此,透過參考 Online Softmax:2-pass 演算法,我們可以利用 rowmax/ℓ 的輸出來實現 KV 稀疏性的特定評分 S。在實踐中,我們只需要對圖 7 中所示的 FlashAttention 進行改進以滿足此需求。
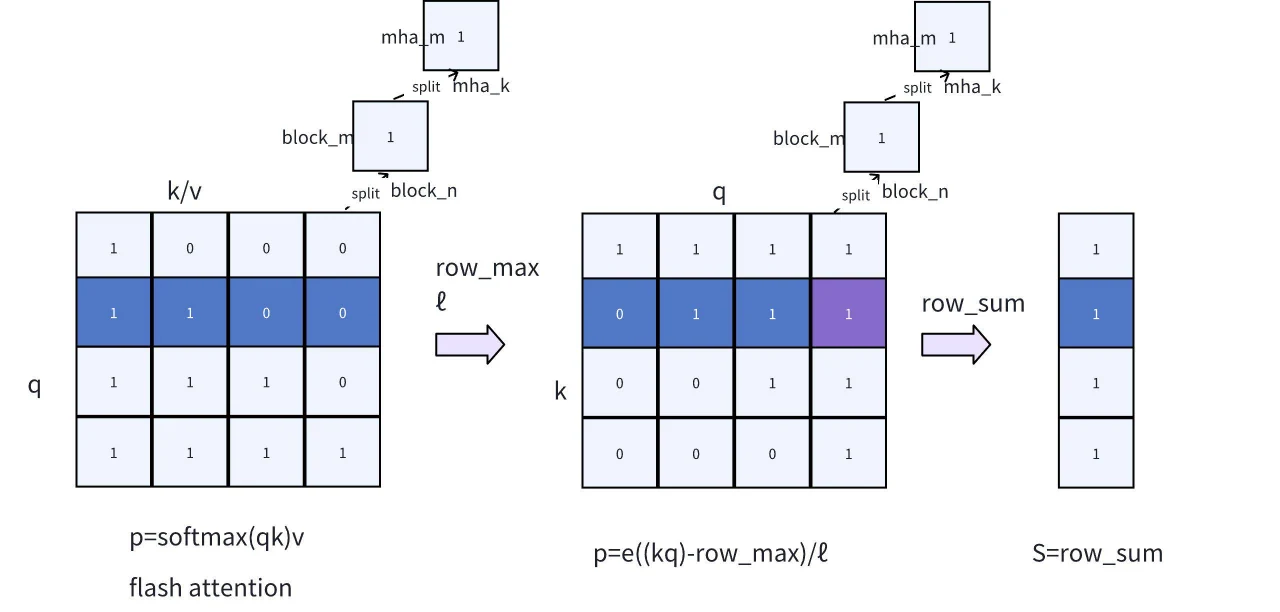
圖 7. 為 KV 稀疏性評分修改 FlashAttention
- FlashAttention 中 rowmax/ℓ 的輸出:FlashAttention 包含了 rowmax/ℓ 的輸出。由於這些值代表最大值和累積總和,其資料大小非常小,對 FlashAttention 的整體效能影響微乎其微。透過重用 rowmax/ℓ,我們可以避免第二次 1-pass,從而提高整體計算效率。
- 加入 Online Softmax 步驟:我們引入了 Online Softmax 步驟,該步驟建立在 FlashAttention 之上,使用公式 p=e((kq)−row_max)/ℓ(1-pass 邏輯)計算 softmax 分數。隨後,透過對行進行求和,我們可以計算出稀疏化分數 S。
在 Online Softmax 的實作中,有兩個關鍵細節需要特別注意:
- **調整迴圈順序 **:由於 S 是基於 k 維度的分數總和,因此與注意力機制相比,需要將 Online Softmax 中的計算從 q*k 調整為 *k**q。這種調整透過將列求和轉換為行求和,避免了不同區塊之間不必要的通訊,使所有計算都能在暫存器內完成。
- **q 的起始和結束位置 **:由於因果編碼的存在以及最近 a 個的求和邏輯,沒有必要用 k 遍歷所有 q 值。透過參考圖 7 中標記為 0/1 的 mask 指標,我們可以根據 q 的起始和結束位置來確定對應的區塊是否需要計算,這大大節省了計算資源。例如,如果輸入 prompt 的長度為 5000,最近 a 個的長度為 256,傳統計算需要 5000*5000 次操作。然而,透過記錄起始和結束位置,只需要 *5000**256 次操作,從而提高了計算效率。
PagedAttention 執行與 FlashAttention 類似的工作,共同目標是計算最終的分數 SSS。此處不提供 PagedAttention 的詳細說明。
結論
我們基於 vLLM 0.5.1 修改的版本 Novita AI Sparse 0.5.1,目前主要支援 Llama3-8B 和 Llama3-70B 等模型。它使用 CUDA graphs 的推論模式運行,主要部署在 RTX 4090 等消費級 GPU 上。在工程和演算法方面仍有很大的最佳化空間。
請注意: 以下功能在 vLLM-0.6.2 中尚未支援:
- Chunked-prefill
- Prefix caching
- FlashInfer 及其他非 FlashAttention 後端
對 Novita AI Sparse 0.5.1 感興趣的人,可以訪問 Novita AI 搶先體驗。
參考文獻:
[1] H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
[2] Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
[3] SnapKV: LLM Knows What You are Looking for Before Generation
[4] PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
[5] PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
[6] MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
[7] Layer-Condensed KV Cache for Efficient Inference of Large Language Models
[8] TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
[9] CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
[10] KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation



