

Zachary, Algorithmus-Experte bei Novita AI
Forschungsschwerpunkt: Inferenzbeschleunigung
Einleitung
Im vergangenen Jahr, seit dem Aufkommen von H2O, gab es eine Vielzahl von Forschungsarbeiten zur KV-Sparsity. Eine große Herausforderung in realen Anwendungen ist jedoch die erhebliche Kluft zwischen akademischer Forschung und praktischer Umsetzung. Beispielsweise verwenden Frameworks wie vLLM PagedAttention, eine seitenbasierte Speichertechnik, die mit den meisten Sparsity-Algorithmen nicht kompatibel ist bzw. bei der diese Algorithmen schlechter abschneiden als PagedAttention. Solche Probleme verhindern, dass Sparsity-Algorithmen effektiv in Produktionsumgebungen eingesetzt werden können.
Durch die Durchsicht aktueller akademischer Arbeiten aus dem letzten Jahr im Bereich der KV-Sparsity haben wir Modifikationen am vLLM-Framework basierend auf KV-Sparsity vorgenommen. Diese Modifikationen wurden auf die inhärenten Optimierungsmerkmale des vLLM-Frameworks abgestimmt, wie z. B. Continuous Batching, FlashAttention und PagedAttention. Letztendlich konnten wir durch den Vergleich des modifizierten Frameworks mit den SOTA-Inferenzframeworks unter Verwendung der in der Produktion am häufigsten eingesetzten Modelle, Parameter und Hardware eine 1,5-fache Beschleunigung der Inferenzleistung erzielen.
Bevor wir über KV-Sparsity sprechen, ist es wichtig, das Merkmal der „Massive Activations“ in LLMs zu behandeln. In LLMs sind eine kleine Anzahl von Aktivierungswerten deutlich aktiver als andere, manchmal übertreffen sie die weniger aktiven um den Faktor 100.000 oder mehr. Mit anderen Worten: Eine kleine Teilmenge von Tokens spielt eine entscheidende Rolle. Diese Beobachtung bildet die Grundlage für die Anwendung von KV-Sparsity-Techniken, bei denen das Behalten nur der wichtigen Tokens die Inferenzleistung verbessern kann.
Spezifische Analysedaten von Llama2 und Llama3 stützen diese Beobachtung, wie in Abb. 1 und Abb. 2 dargestellt.
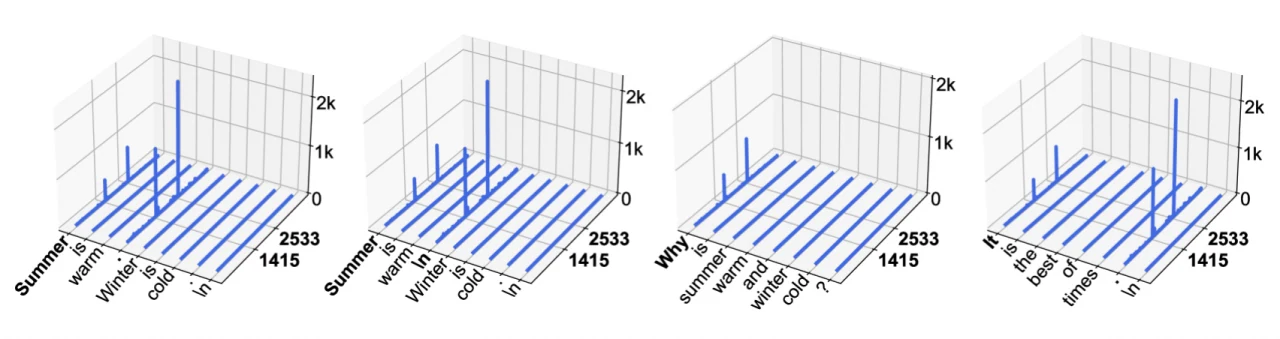
Abb. 1. Aktivierungsstärken (𝐳-Achse) in LLaMA2-7B. Die 𝐱- und 𝐲-Achsen sind Sequenz- und Merkmalsdimensionen. Bei diesem spezifischen Modell beobachten wir, dass Aktivierungen mit massiven Stärken in zwei festen Merkmalsdimensionen (1415, 2533) und bei zwei Token-Arten auftreten – dem Start-Token und dem ersten Punkt (.) oder Zeilenumbruch-Token (\n).
Im Gegensatz zu Llama2 zeigt Llama3 das Merkmal der „Massive Activations“ nicht in allen Schichten. In den unteren Schichten sind die Aktivierungen gleichmäßiger verteilt, während die mittleren Schichten lokalisierte Aufmerksamkeitsmuster aufweisen. Erst in den oberen Schichten tritt das Phänomen der massiven Aktivierungen deutlich hervor. Diese Beobachtung erklärt, warum Modelle wie Llama3 hierarchische Sparsity-Techniken einsetzen, die die Sparsity je nach spezifischem Aktivierungsmuster auf verschiedene Schichten zuschneiden.
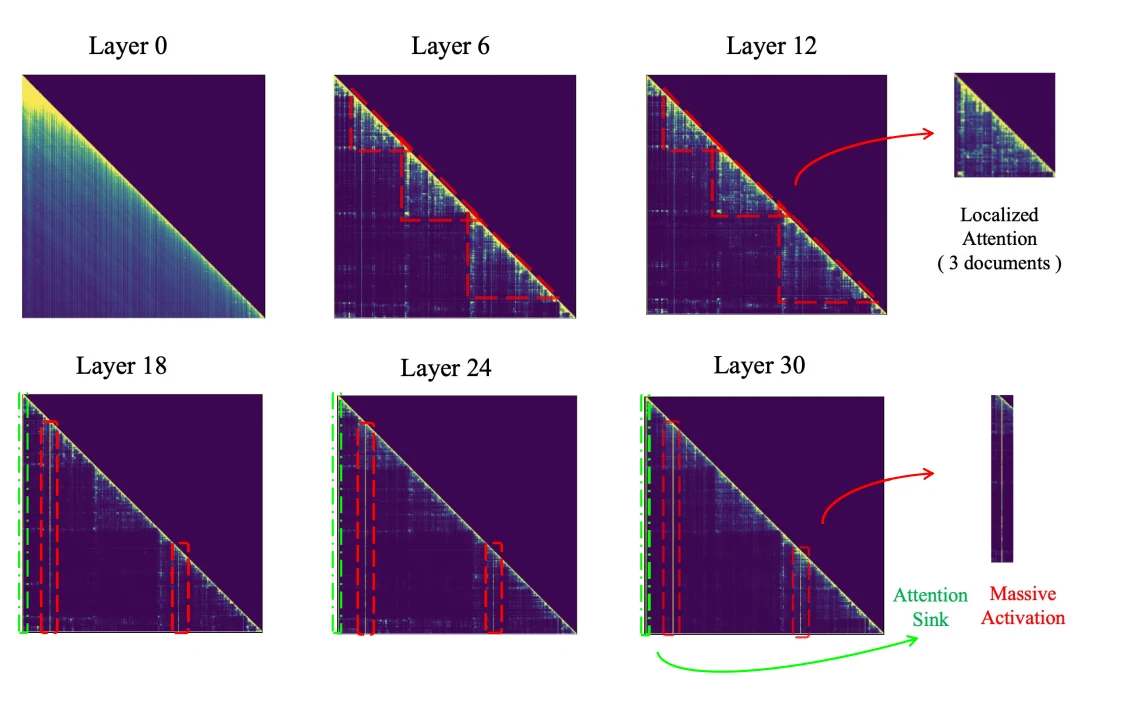
Abb. 2. Aufmerksamkeitsmuster der retrieval-gestützten Generierung über Schichten in LLaMa (Touvron et al., 2023a;b). In den unteren Schichten zeigt das Modell einen breitbandigen Aufmerksamkeitsmodus, der die Aufmerksamkeitswerte gleichmäßig über alle Inhalte verteilt. In den mittleren Schichten wird die Aufmerksamkeit innerhalb jedes Dokuments lokalisierter, was auf eine verfeinerte Informationsaggregation hindeutet (gestrichelte rote Dreiecke in Schicht 6 und 10). Dies gipfelt in den oberen Schichten, wo „massive Aufmerksamkeit“ auf einige wenige Schlüssel-Tokens fokussiert wird (konzentrierte Aufmerksamkeitsbalken nach Schicht 18), um wesentliche Informationen für Antworten effizient zu extrahieren.
Systemmodell
Nach der Einführung des „Massive Activations“-Merkmals in LLMs haben wir nun ein grundlegendes Verständnis der Prinzipien hinter KV-Sparsity. Als Nächstes besprechen wir, wie KV-Sparsity implementiert wird. Im Inferenzprozess großer Modelle treten häufig drei große Engpässe auf: GPU-Speicherkapazität, Rechenleistung und E/A-Bandbreite. Um redundante Berechnungen zu vermeiden, wird KV während der Inferenz oft zwischengespeichert, was zu einem erheblichen Verbrauch von GPU-Speicher führt. Gleichzeitig werden Rechenlast und E/A-Durchsatz zu kritischen Engpässen in der Prefill- bzw. Decode-Phase.
Unsere Modifikation des vLLM-Frameworks basiert auf dem „Massive Activations“-Merkmal von LLMs und implementiert schichtweise Sparsity (d. h. unterschiedliche Sparsity-Level für verschiedene Schichten). Dieser Ansatz reduziert den Overhead der KV-Zwischenspeicherung erheblich und beschleunigt so den Inferenzprozess von LLM-Modellen.
Wie in Abb. 3 gezeigt, wenden wir während der Inferenz KV-Sparsity auf verschiedene Schichten des Modells an. Durch eine Pruning-Strategie entfernen wir KV-Paare mit niedrigeren Bewertungen, während wir die mit höheren Bewertungen und größerer Nähe behalten. Dieser Ansatz reduziert den Speicherverbrauch sowie den Rechen- und E/A-Overhead und führt letztlich zu einer beschleunigten Inferenz.
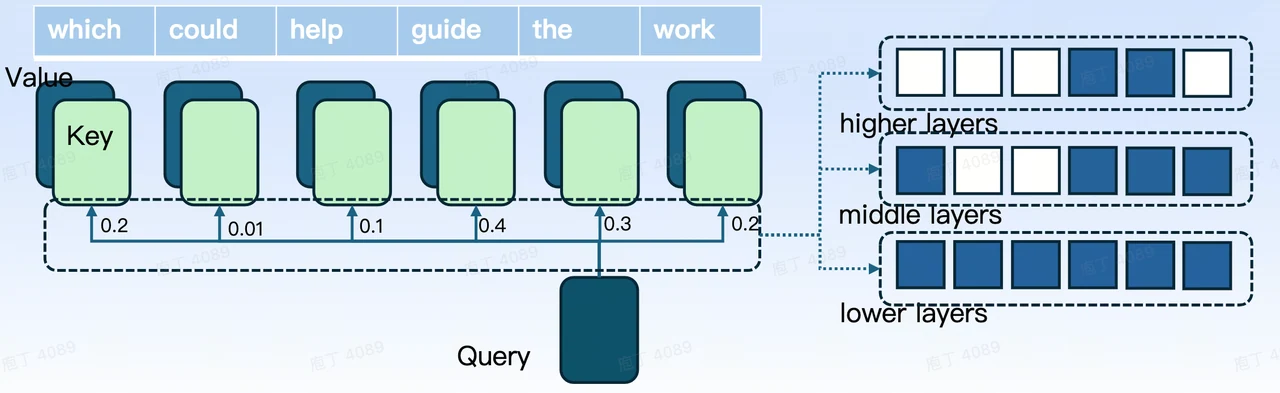
Abb. 3. Auswirkungen der KV-Sparsity auf das Modell
Ergebnisse der Inferenzbeschleunigung
Das Hauptinteresse der meisten Forscher gilt den tatsächlichen Auswirkungen von KV-Sparsity im vLLM-Framework. Bevor wir ins Detail gehen, präsentieren wir zunächst die Leistungsbewertungsergebnisse.
1. Inferenzleistung
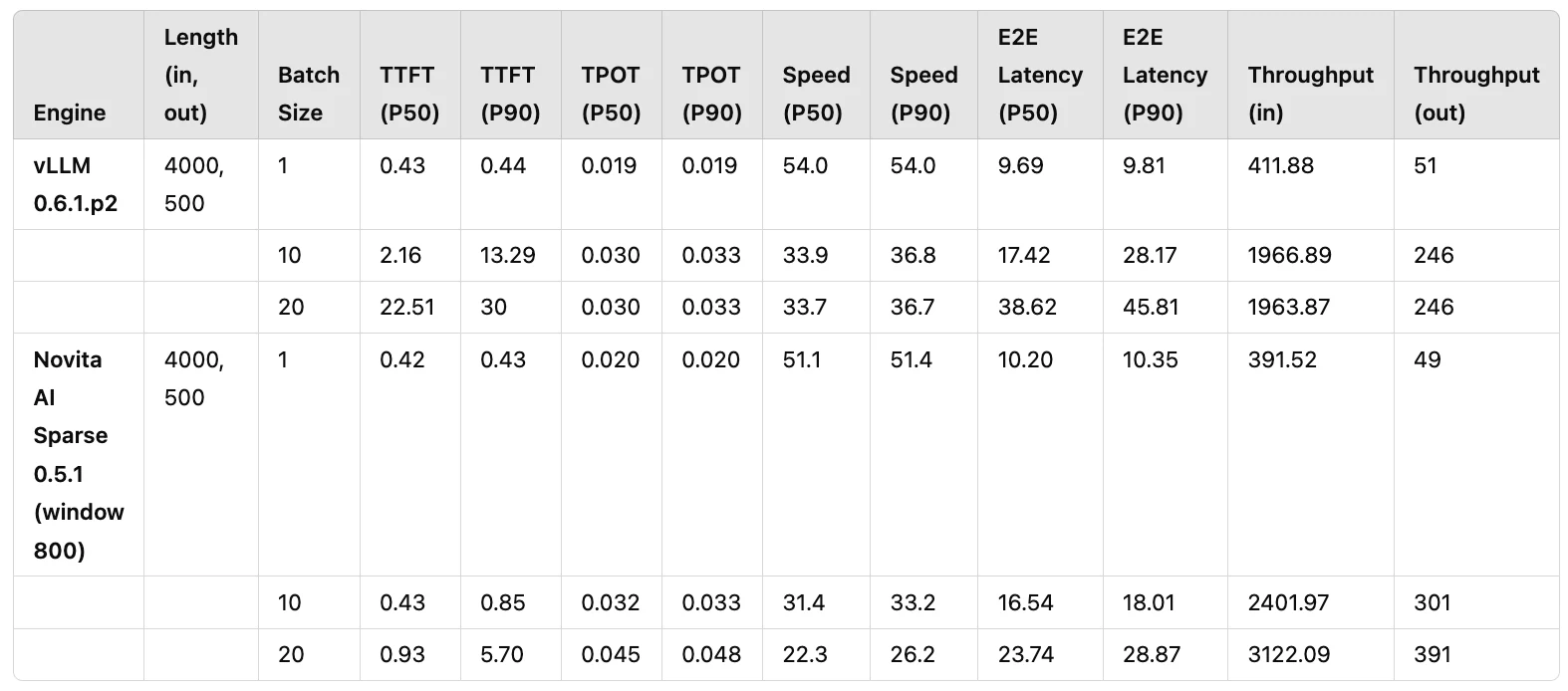
In realen LLM-Anwendungen ist eine Ein-/Ausgabelänge von 4000/500 die am häufigsten beobachtete Konfiguration. Zudem ist die RTX 4090 GPU eine der am weitesten verbreiteten GPUs in der Industrie. Basierend auf diesen Bedingungen führten wir Batch-Leistungsvergleiche durch. Die Kontrollgruppe ist vLLM 0.6.1.p2, die Versuchsgruppe ist Novita AI Sparse 0.5.1 (eine auf KV-Sparsity basierte modifizierte Version von vLLM 0.5.1). Zwischen beiden wurden mehrere Runden von Leistungsvergleichstests durchgeführt, wobei die wichtigsten Metriken TTFT (Time-to-First-Token, entscheidend für die Benutzererfahrung) und Durchsatz (tatsächliche Inferenzgeschwindigkeit) waren.
Die endgültigen Testergebnisse sind in Tabelle 1 dargestellt. Durch Anwendung von KV-Sparsity konnten wir den Durchsatz von vLLM um etwa das 1,58-fache steigern, während die TTFT nutzbar blieb (P50 unter 1 Sekunde). Darüber hinaus erreichte vLLM 0.6.1.p2 bei größeren Batch-Größen sein Leistungslimit bei einer Parallelität von 10, während Novita AI Sparse 0.5.1 auch bei einer Parallelität von 20 stabile TTFT-Werte aufrechterhielt. Dies zeigt die Robustheit von KV-Sparsity zur Gewährleistung der Leistungsstabilität in Produktionsumgebungen.
Tabelle 1: Leistungsvergleich zwischen vLLM 0.6.1.p2 und Novita AI Sparse 0.5.1
2. Modellgenauigkeit
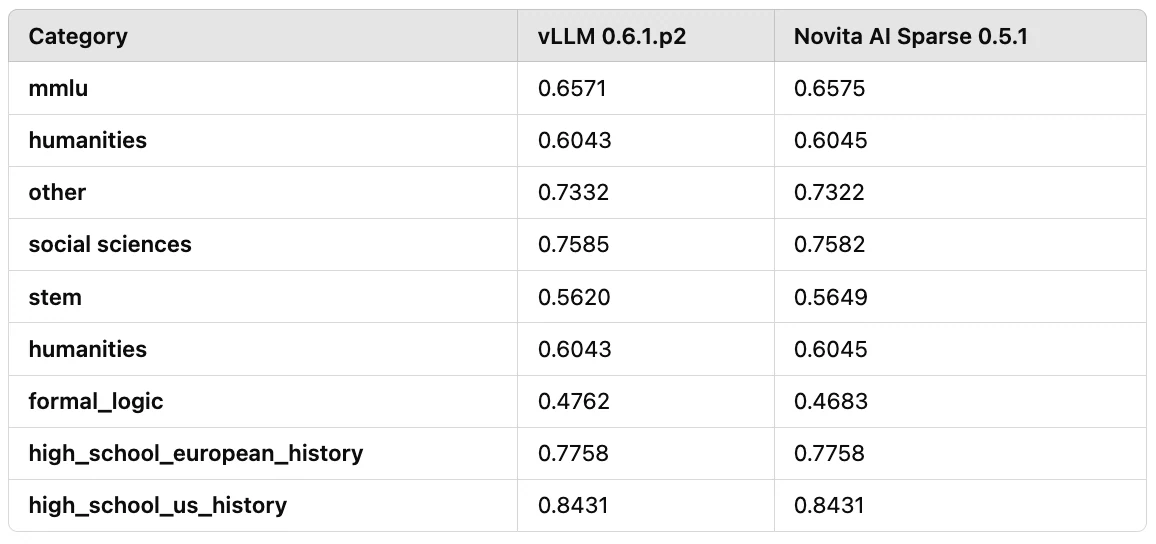
Da KV-Sparsity ein verlustbehafteter Kompressionsalgorithmus ist, ist die Bewertung der Modellleistung gleichermaßen wichtig. Wir führten Leistungsbewertungen basierend auf Llama3–8B durch, einschließlich Evaluierungen mit MMLU und anderen Benchmarks. Die Ergebnisse zeigen, dass der Genauigkeitsverlust bei etwa 3 % liegt.
Wie in Tabelle 2 gezeigt, testeten wir die Modellleistung mit MMLU- und Humanities-Benchmarks:
Tabelle 2: Leistungsbewertungsergebnisse von Llama3–8B mit MMLU- und Humanities-Benchmarks
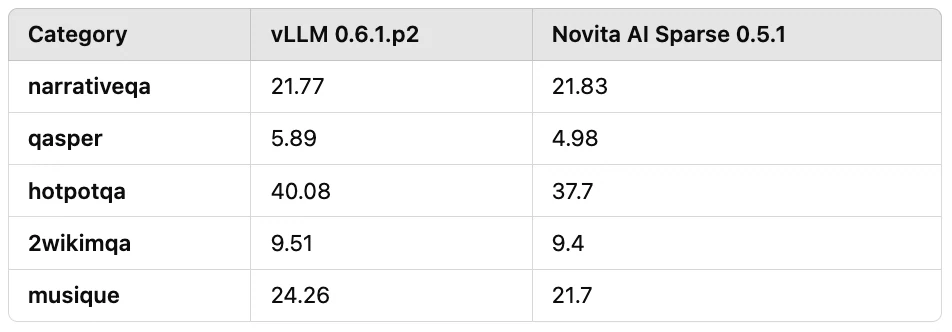
Zweitens führten wir Bewertungen von QA-Aufgaben in langen Textszenarien durch, die in praktischen Anwendungen häufig vorkommen, mit Eingabelängen von 7k bis 30k. Die Kompressionsrate wurde bei über dem 10-fachen gehalten, wie in Tabelle 3 gezeigt. Die Ergebnisse zeigten einen Gesamtgenauigkeitsverlust von etwa 10 %.
Tabelle 3: Bewertungsergebnisse von Langtext-QA-Aufgaben mit Eingabelängen von 7k bis 30k
Wichtige Techniken
1. Schichtspezifische Sparsity und Tensor Parallelism
Das vLLM-Framework verwendet eine „Iteration-Level Scheduling“-Strategie, allgemein als Continuous Batching bekannt. Diese Scheduling-Strategie zeichnet sich dadurch aus, dass sie nicht darauf wartet, dass jede Sequenz in einem Batch die Generierung abgeschlossen hat; stattdessen ermöglicht sie ein Scheduling auf Iterationsebene, was im Vergleich zu statischem Batching zu einer höheren GPU-Auslastung führt. Wie zu Beginn dieses Artikels erwähnt, besitzen Modelle wie Llama3–8B inhärent Merkmale wie hierarchische Sparsity. Folglich traten bei unseren Modifikationen auf Basis von Continuous Batching eine Reihe von Herausforderungen auf, wie in Abb. 4 gezeigt.
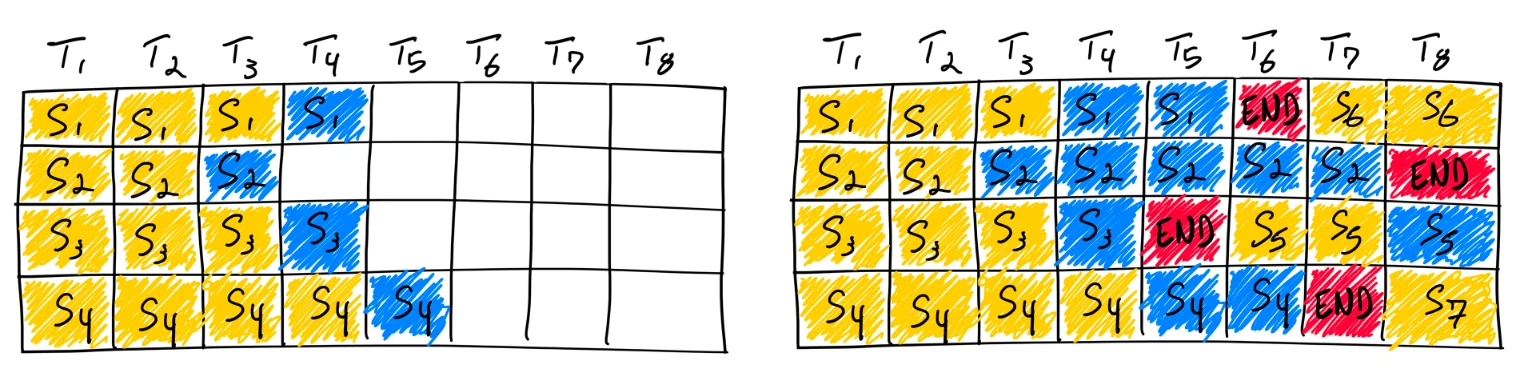
Abb. 4. Abschluss von sieben Sequenzen mittels Continuous Batching. Links sehen Sie den Batch nach einer einzelnen Iteration, rechts den Batch nach mehreren Iterationen. Sobald eine Sequenz ein End-of-Sequence-Token ausgibt, fügen wir eine neue Sequenz an deren Position ein (z. B. Sequenzen S5, S6 und S7). Diese Methode steigert die GPU-Auslastung, da die GPU nicht darauf warten muss, dass alle Sequenzen abgeschlossen sind, bevor eine neue gestartet wird.
Die größte Herausforderung, der wir uns stellten, war die Verwaltung des Speichers über verschiedene Schichten hinweg. Da vLLM ein einheitliches seitenbasiertes Speicherverwaltungsmodell verwendet und die Queue-Strategie nur entweder Full Cache oder Sliding Window unterstützt, haben wir die Kernstruktur von vLLM modifiziert, um beide Optionen zu unterstützen.
Diese Anpassung gibt jeder Schicht die Flexibilität, entweder Full Cache oder Sliding Window zu wählen, sodass unterschiedliche Sparsity-Level über die Schichten hinweg möglich sind, wie im Diagramm dargestellt.
Die erste zu lösende Herausforderung ist das Speicherverwaltungsproblem über verschiedene Schichten hinweg. Da vLLM ein einheitliches seitenbasiertes Speicherverwaltungsmodell für alle Schichten verwendet und die Queue-Strategie entweder Full Cache oder Sliding Window erlaubt, müssen wir die zugrundeliegende Struktur von vLLM anpassen. Konkret bedeutet dies, die Unterstützung sowohl für Full Cache als auch für Sliding Window zu ermöglichen, sodass verschiedene Schichten unabhängig ihre bevorzugte Speicherverwaltungsstrategie wählen können. Diese Anpassung ermöglicht letztlich unterschiedliche Grade der Sparsity in verschiedenen Schichten. Das entsprechende Strukturdiagramm ist in Abbildung 5 dargestellt.
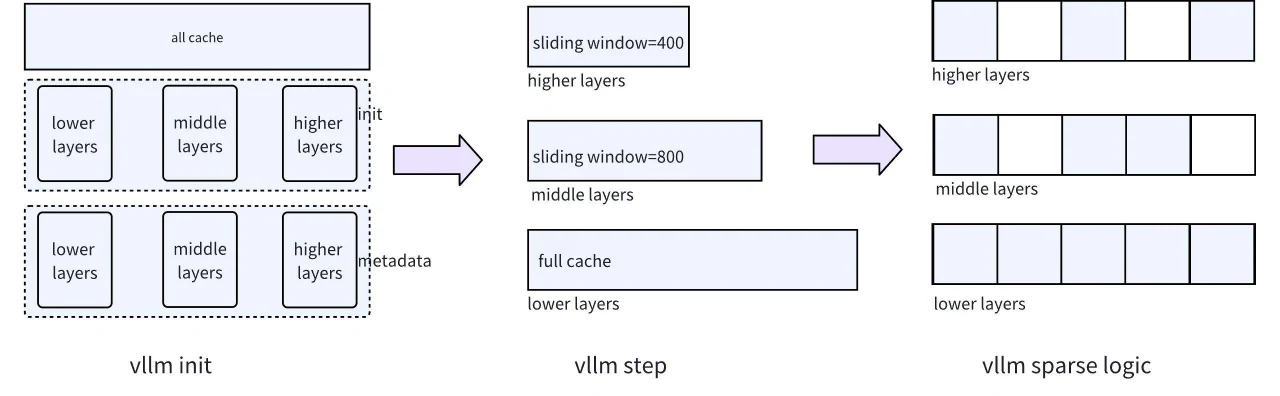
Abb. 5. Schichtweise Speicherverwaltungsstruktur in vLLM
Insgesamt lassen sich die Anpassungen in drei verschiedene Phasen unterteilen:
Dienstinitialisierungsphase: Während des Dienststartvorgangs wird der zugewiesene Speicher für die drei Schichten hauptsächlich durch Berechnung des verbleibenden Speicherplatzes sowie eine hierarchische Initialisierung der Metadatenstruktur initialisiert. Im Gegensatz dazu arbeitet das ursprüngliche vLLM als vollständiger Full Cache, ohne die Speicherzuweisungslogik für verschiedene Schichten zu berücksichtigen.
Schrittvorbereitungsphase: Während der Initialisierungsphase der Schritte in vLLM, insbesondere in den Phasen, die Block-Manager- und Model-Runner-Methoden umfassen, werden für verschiedene Schichten unterschiedliche Blocktabellen-Verwaltungsstrategien verwendet, um den KV-Aktualisierungsmechanismus zu steuern. Wie in der vorhergehenden Abbildung dargestellt, verwenden wir für die ersten drei Schichten den Full Cache-Mechanismus, der alle KVs speichert, während Schichten jenseits der dritten die Sliding-Window-Strategie verwenden, um automatisch die KVs mit den niedrigsten Bewertungen zu ersetzen. Dieser Ansatz ermöglicht eine flexible Zuweisung von Speicherplatz, die auf die Bedürfnisse jeder Schicht zugeschnitten ist, spart so Speicherplatz und maximiert gleichzeitig die Effektivität des Sparsity-Algorithmus.
Sparsifikationsberechnungsphase: Diese Phase tritt typischerweise nach der Modellausführung auf, bei der Sparsity-Operationen basierend auf den berechneten Sparsity-Werten ausgeführt werden. Eine wichtige Überlegung in diesem Schritt ist die Kompatibilität mit Technologien wie Tensor Parallelism, CUDA Graphs und GQA. In praktischen Engineering-Implementierungen erfordert Tensor Parallelism besondere Aufmerksamkeit. Wie in der folgenden Abbildung dargestellt, ist es in einem Szenario mit einer einzelnen Maschine und mehreren GPUs wichtig, einen geeigneten Partitionierungsmechanismus zu verwenden, um die KV-Sparsifikationsoperationen auf jede GPU zu beschränken und so die Kommunikation zwischen GPUs zu vermeiden. Glücklicherweise verwendet die Attention-Einheit einen auf ColumnLinear basierenden Partitionierungsansatz, was die Implementierung relativ einfach macht.
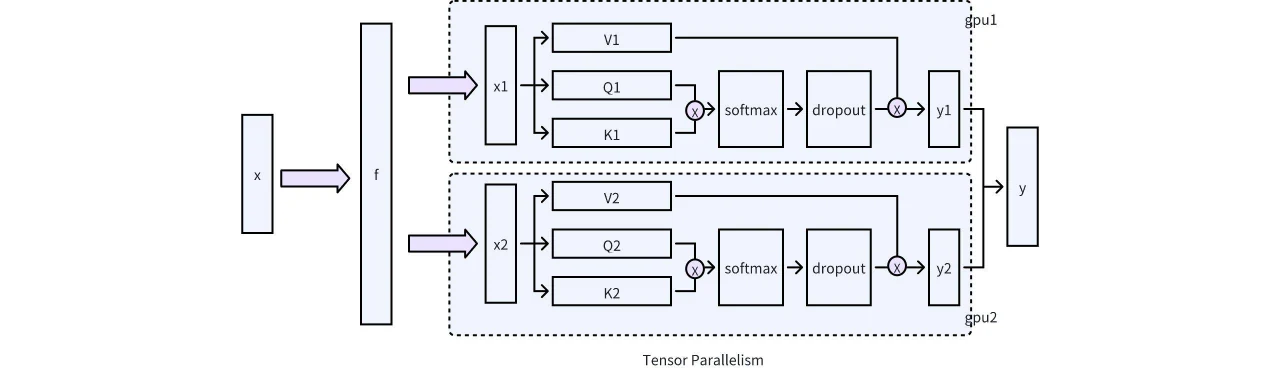
Abb. 6. Dreistufiger Prozess für Speicherverwaltung und Sparsifikation in vLLM
Die obige Diskussion konzentrierte sich hauptsächlich auf die Änderungen auf Framework-Ebene zur Unterstützung hierarchischer Sparsity in vLLM. Als Nächstes werden wir uns den Optimierungen auf CUDA-Ebene zuwenden.
2. Attention-Modifikation
Die Änderungen auf CUDA-Ebene konzentrieren sich hauptsächlich auf die Verbesserungen der Attention-Berechnungseinheit, insbesondere bei FlashAttention und PagedAttention. Während PagedAttention relativ einfach ist, werden wir die Modifikationen im Zusammenhang mit FlashAttention hervorheben.
Zunächst präsentieren wir die Berechnungsformel für Attention:
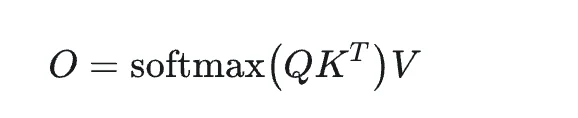
Wie in der Formel gezeigt, beinhaltet der Softmax-Berechnungsprozess die Berechnung des QK-Produkts und ist ein 2-Pass-Algorithmus (erfordert zwei Durchläufe). Das endgültige Berechnungsziel O kann jedoch mit dem FlashAttention-Algorithmus in einem einzigen Durchlauf (1-Pass) erreicht werden. Die Implementierungslogik von FlashAttention kann durch die folgende Abbildung 7 aus dem FlashAttention2-Paper veranschaulicht werden. Kurz gesagt, beinhaltet es eine blockweise Traversierung von Q zur blockweisen Berechnung von KV, während O, P und rowmax-Daten schrittweise aktualisiert werden, bis die Schleife beendet ist. Schließlich ermöglicht die Division von O durch ℓ die 1-Pass-Berechnung von FlashAttention.

Abb. 7. Implementierungslogik von FlashAttention2
Für unsere Implementierung der KV-Sparsity ist es wichtig zu beachten, dass während des Berechnungsprozesses von FlashAttention die für Softmax erforderlichen Werte – nämlich rowmax/ℓ (das globale Maximum und die kumulativen Werte) – bereits berechnet werden. FlashAttention gibt die Ergebnisse dieser beiden Werte jedoch nicht zurück.
Mit einem grundlegenden Verständnis von FlashAttention können wir nun die Bewertungsformeln für die Sparsifikation diskutieren, die in Arbeiten wie PYRAMIDKV vorgestellt werden:
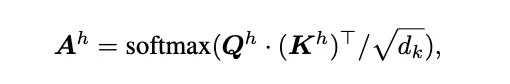
wobei [n − α, n] der Bereich der Instruktions-Tokens ist. In jeder Schicht l und für jeden Kopf h werden die Top-k l Tokens mit den höchsten Bewertungen ausgewählt und ihre jeweiligen KV-Caches behalten. Alle anderen KV-Caches werden verworfen und in keiner nachfolgenden Berechnung während des Generierungsprozesses verwendet.
Konkret berechnen wir die Bewertung für die Beibehaltung des i-ten Tokens im KV-Cache als S in jedem Aufmerksamkeitskopf h durch:
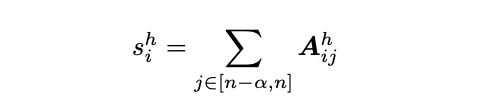
In der obigen Formel repräsentiert A den Softmax-Score, während S die Summe der Scores der a nächsten Softmax-Werte ist. Wie angegeben, ist Softmax selbst ein 2-Pass-Algorithmus, der nicht direkt in FlashAttention integriert werden kann. Dies bedeutet auch, dass die Sparsifikationsbewertung nicht in 1-Pass implementiert werden kann.
Wie bereits erwähnt, gibt FlashAttention zwar keine Softmax-Scores aus, berechnet aber Zwischenwerte wie rowmax/ℓ. Daher können wir unter Bezugnahme auf den Online-Softmax-2-Pass-Algorithmus die Ausgaben von rowmax/ℓ verwenden, um die spezifische Bewertung S für KV-Sparsity zu erreichen. In der Praxis müssen wir lediglich Verbesserungen an FlashAttention vornehmen, wie in Abb. 7 dargestellt, um diese Anforderung zu erfüllen.
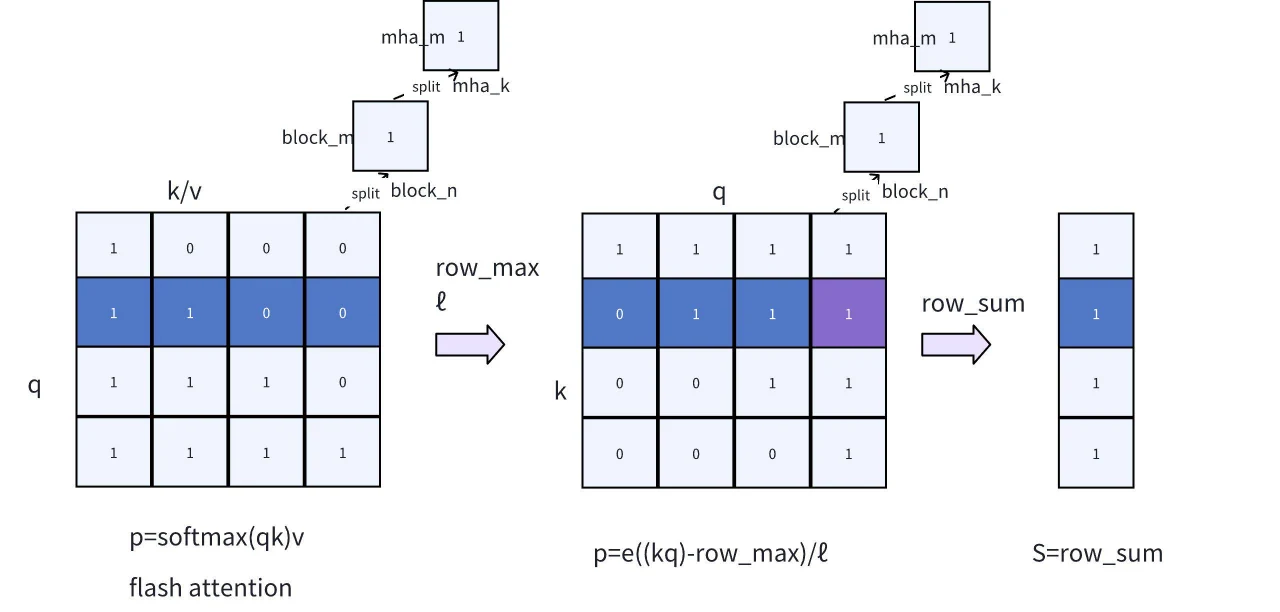
Abb. 7. Modifikation von FlashAttention für KV-Sparsity-Bewertung
- Ausgabe von rowmax/ℓ in FlashAttention: FlashAttention integriert die Ausgaben von rowmax/ℓ. Da diese Werte das Maximum und die kumulativen Summen darstellen, ist ihre Datenmenge minimal und hat einen vernachlässigbaren Einfluss auf die Gesamtleistung von FlashAttention. Durch die Wiederverwendung von rowmax/ℓ können wir einen zweiten 1-Pass vermeiden und so die Gesamtrecheneffizienz steigern.
- Hinzufügen eines Online-Softmax-Schrittes: Wir führen den Online-Softmax-Schritt ein, der auf FlashAttention aufbaut, indem die Softmax-Scores mithilfe der Formel p = e^((kq) − row_max) / ℓ berechnet werden (1-Pass-Logik). Anschließend können wir durch eine zeilenweise Summation die Sparsifikationsbewertung S berechnen.
Bei der Implementierung von Online-Softmax sind zwei kritische Details besonders zu beachten:
- Anpassung der Schleifenreihenfolge: Da S die Summe der Scores basierend auf der k-Dimension ist, muss die Berechnung in Online-Softmax von qk nach kq angepasst werden, verglichen mit der Attention. Diese Anpassung vermeidet unnötige Kommunikation zwischen verschiedenen Blöcken, indem die Spaltensummation in eine Zeilensummation umgewandelt wird, sodass alle Berechnungen in den Registern abgeschlossen werden können.
- Start- und Endpositionen von q: Aufgrund des Vorhandenseins von Causal Encoding und der Summationslogik für die nächsten a ist es nicht notwendig, alle q-Werte mit k zu durchlaufen. Durch Bezugnahme auf die als 0/1 in Abb. 7 markierten Maskenindikatoren können wir basierend auf den Start- und Endpositionen von q bestimmen, ob ein entsprechender Block eine Berechnung erfordert, was die Rechenressourcen erheblich schont. Wenn beispielsweise die Länge des Eingabe-Prompts 5000 beträgt und die Länge der nächsten a 256, würde die konventionelle Berechnung 5000 * 5000 Operationen erfordern. Durch die Aufzeichnung der Start- und Endpositionen sind jedoch nur 5000 * 256 Operationen erforderlich, was die Recheneffizienz verbessert.
PagedAttention führt ähnliche Arbeiten wie FlashAttention durch, mit dem gemeinsamen Ziel, die endgültige Bewertung S zu berechnen. Eine detaillierte Erklärung von PagedAttention wird hier nicht gegeben.
Fazit
Unsere modifizierte Version, Novita AI Sparse 0.5.1, basierend auf vLLM 0.5.1, unterstützt derzeit hauptsächlich Modelle wie Llama3–8B und Llama3–70B. Sie arbeitet im Inferenzmodus mit CUDA-Graphen und wird hauptsächlich auf Consumer-GPUs wie der RTX 4090 eingesetzt. Es besteht weiterhin erheblicher Optimierungsspielraum sowohl in technischer als auch in algorithmischer Hinsicht.
Ein Hinweis: Die folgenden Funktionen werden in vLLM 0.6.2 noch nicht unterstützt:
- Chunked-Prefill
- Prefix Caching
- FlashInfer und andere Nicht-FlashAttention-Backends
Wenn Sie an Novita AI Sparse 0.5.1 interessiert sind, können Sie Novita AI besuchen, um es vor anderen zu erleben.
Referenzen:
[1] H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
[2] Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
[3] SnapKV: LLM Knows What You are Looking for Before Generation
[4] PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
[5] PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
[6] MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
[7] Layer-Condensed KV Cache for Efficient Inference of Large Language Models
[8] TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
[9] CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
[10] KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation


