

Zachary,Novita AI 算法专家
研究方向:推理加速
引言
过去一年里,自 H2O 出现以来,关于 KV 稀疏性的研究论文层出不穷。然而,实际应用中的一个重大挑战是学术研究与实际实施之间存在巨大差距。例如,vLLM 等框架采用了 PagedAttention 这种基于分页的内存技术,它与大多数稀疏性算法不兼容,或者这些算法在 PagedAttention 下的表现更差。此类问题导致稀疏性算法无法在生产环境中有效利用。
通过回顾过去一年 KV 稀疏性领域的最新学术论文,我们基于 KV 稀疏性对 vLLM 框架进行了修改。这些修改与 vLLM 框架的固有优化特性(如 Continuous Batching、FlashAttention 和 PagedAttention)保持一致。最终,通过将修改后的框架与最先进的推理框架进行比较,使用生产环境中最常用的模型、参数和硬件,我们实现了 1.5 倍的推理性能加速。
在讨论 KV 稀疏性之前,有必要先介绍 LLM 中的 大规模激活 特性。在 LLM 中,少数激活值比其他激活值活跃得多,有时甚至超过不活跃激活值的 100,000 倍以上。换句话说,一小部分 token 起着关键作用。这一观察结果是应用 KV 稀疏技术的基础——仅保留重要 token 即可提升推理性能。
来自 Llama2 和 Llama3 的具体分析数据进一步证实了这一观察结果,如图 1 和图 2 所示。
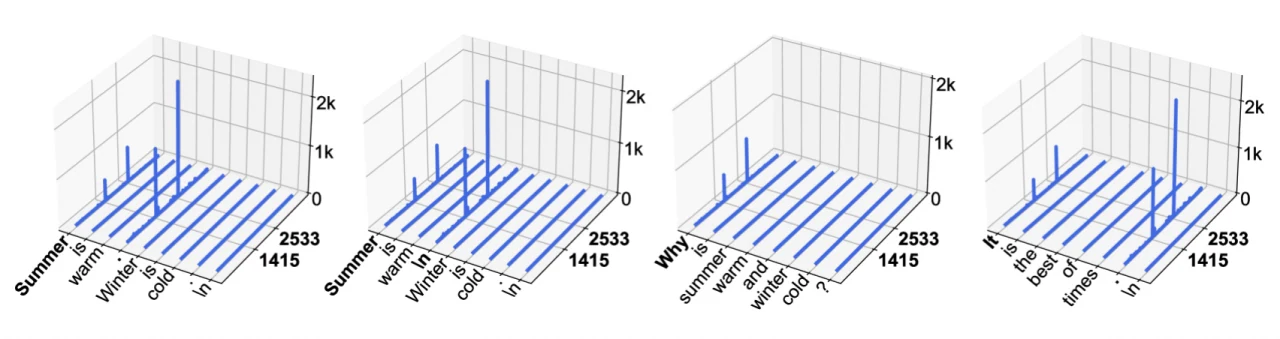
图 1. LLaMA2-7B 中的激活幅度(z 轴)。x 和 y 轴分别表示序列维度和特征维度。对于该特定模型,我们观察到幅度巨大的激活出现在两个固定的特征维度(1415, 2533),以及两类 token——起始 token 和第一个句号 (.) 或换行 token (\n)。
与 Llama2 不同,Llama3 在所有层中并未表现出大规模激活特性。在较低层中,激活分布相对均匀,而中间层则显示出局部注意力模式。只有在上层,大规模激活现象才变得显著。这一观察结果解释了为什么 Llama3 等模型采用分层稀疏技术,根据其特定的激活模式为不同层量身定制稀疏性。
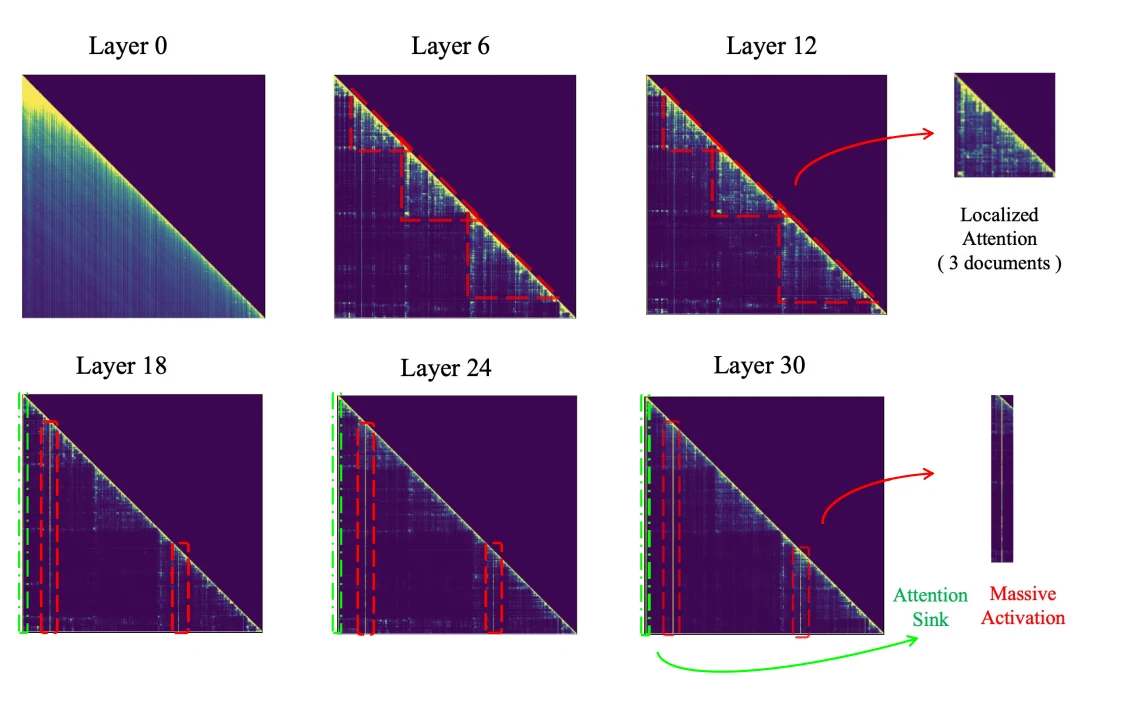
图 2. LlaMa(Touvron 等人,2023a;b)中各层检索增强生成的注意力模式揭示,在较低层中,模型表现出广谱注意力模式,将注意力分数均匀分配给所有内容。在中间层,注意力在每个文档内部变得更加局部化,表明信息聚合更精细(第 6 层和第 10 层中的红色虚线三角形形状)。最终在上层,“大规模注意力”集中在少数关键 token 上(第 18 层之后的集中注意力条),从而高效提取出答案所需的关键信息。
系统模型
在介绍了 LLM 中的大规模激活特性之后,我们现在对 KV 稀疏性的原理有了基本了解。接下来,我们将讨论如何实现 KV 稀疏性。在大模型推理过程中,通常会遇到三个主要瓶颈:GPU 内存容量、计算能力和 I/O 带宽。为了避免重复计算,推理过程中通常会对 KV 进行缓存,这导致 GPU 内存的大量消耗。同时,计算负载和 I/O 吞吐量分别成为 Prefill 和 Decode 阶段的关键瓶颈。
我们对 vLLM 框架的修改基于 LLM 的大规模激活特性,实现了逐层稀疏性(即不同层采用不同的稀疏程度)。这种方法显著降低了与 KV 缓存相关的开销,从而加速了 LLM 模型的推理过程。
如图 3 所示,在推理过程中,我们对模型的不同层应用 KV 稀疏性。通过采用剪枝策略,我们剔除得分较低的 KV 对,同时保留得分较高且距离较近的 KV 对。这种方法减少了内存使用量以及计算和 I/O 开销,最终实现了推理加速。
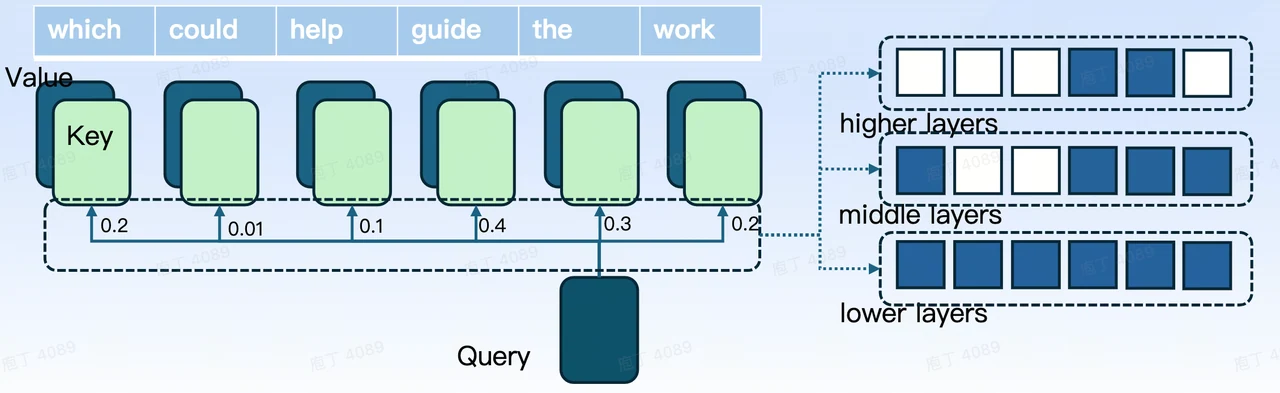
图 3. KV 稀疏性对模型的影响
推理加速结果
大多数研究人员主要关心 KV 稀疏性在 vLLM 框架中的实际效果。在详细介绍细节之前,我们首先展示性能评估结果。
1. 推理性能
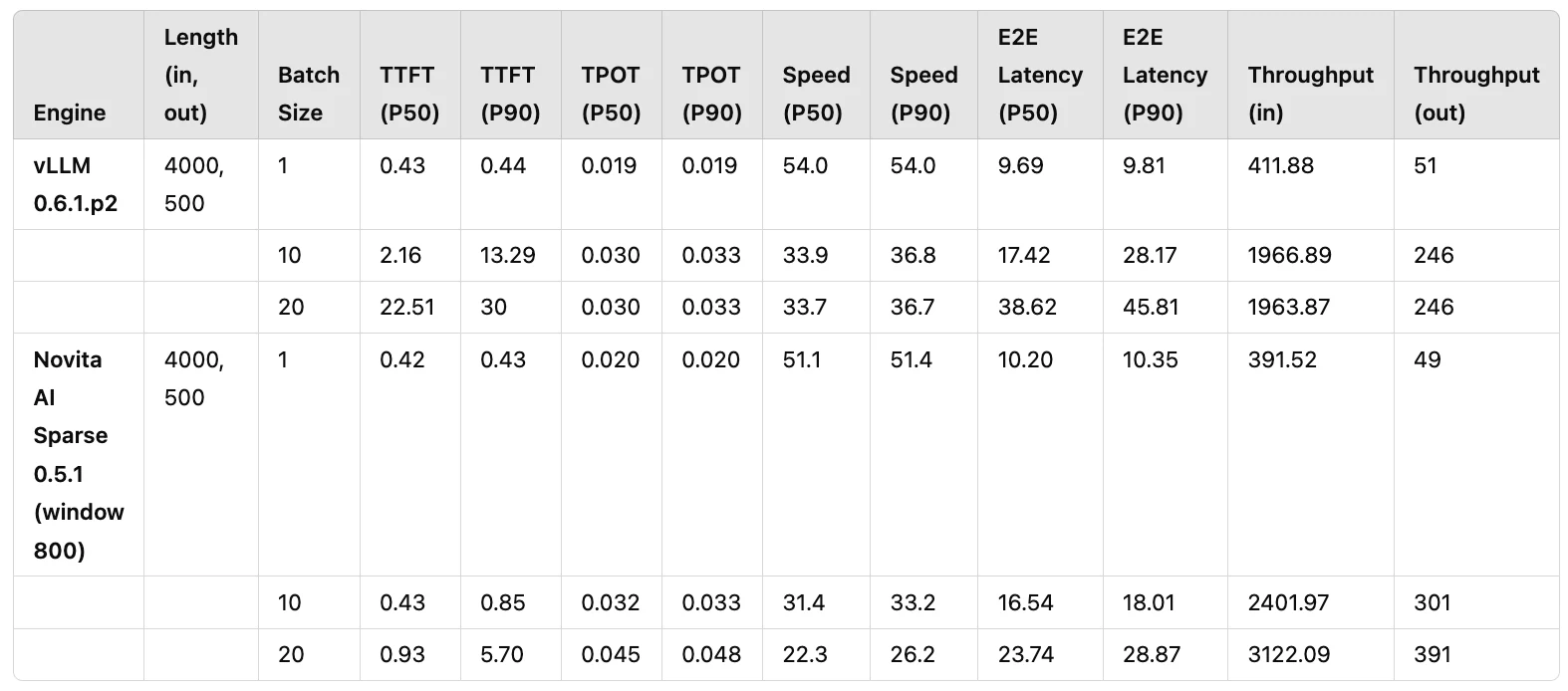
在实际的 LLM 应用中,输入/输出长度为 4000/500 是最常见的配置之一。此外,RTX 4090 GPU 是业界使用最广泛的 GPU 之一。基于这些条件,我们进行了批量性能对比测试。对照组为 vLLM 0.6.1.p2,实验组为 Novita AI Sparse 0.5.1(基于 KV 稀疏性修改的 vLLM 0.5.1 版本)。两者之间进行了多轮性能对比测试,关键指标包括 TTFT(首 token 生成时间,对用户体验至关重要)和吞吐量(实际推理速度)。
最终测试结果如表 1 所示。通过应用 KV 稀疏性,我们能够将 vLLM 的吞吐量提升约 1.58 倍,同时保持可用的 TTFT(P50 低于 1 秒)。此外,在更大的 batch size 场景下,vLLM 0.6.1.p2 在并发数为 10 时达到性能上限,而 Novita AI Sparse 0.5.1 即使在并发数为 20 时也能保持稳定的 TTFT 性能。这表明 KV 稀疏性在生产环境中确保性能稳定性方面具有鲁棒性。
表 1:vLLM 0.6.1.p2 与 Novita AI Sparse 0.5.1 的性能对比
2. 模型精度
由于 KV 稀疏性是一种有损压缩算法,因此评估模型性能同样重要。我们基于 Llama3–8B 进行了性能评估,包括使用 MMLU 等基准测试。结果表明,精度损失大约保持在 3% 以内。
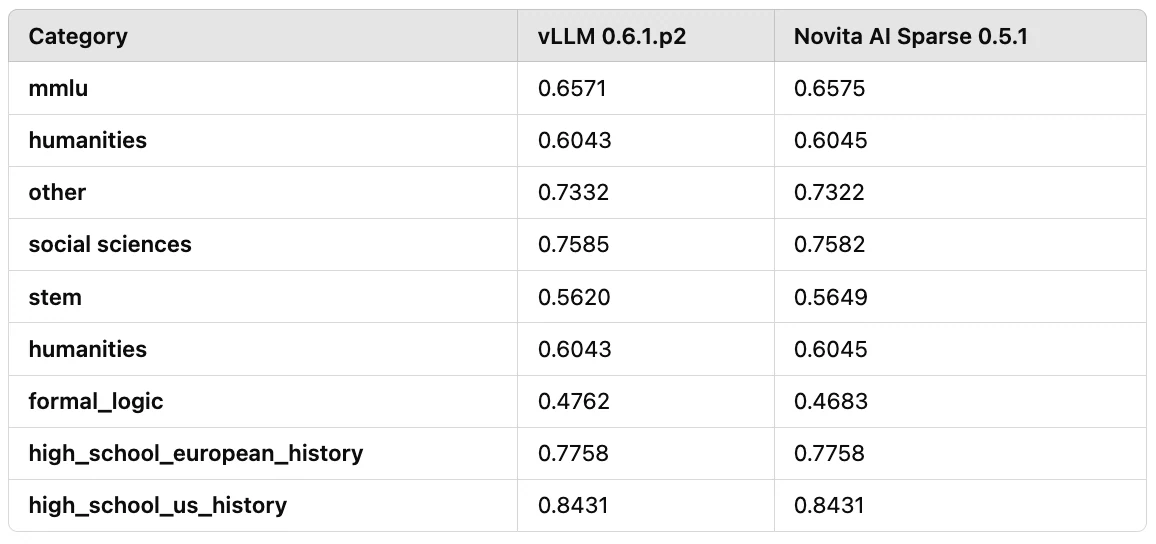
如表 2 所示,我们使用 MMLU 和人文学科基准测试对模型性能进行了测试:
表 2:使用 MMLU 和人文学科基准测试对 Llama3–8B 的性能评估结果
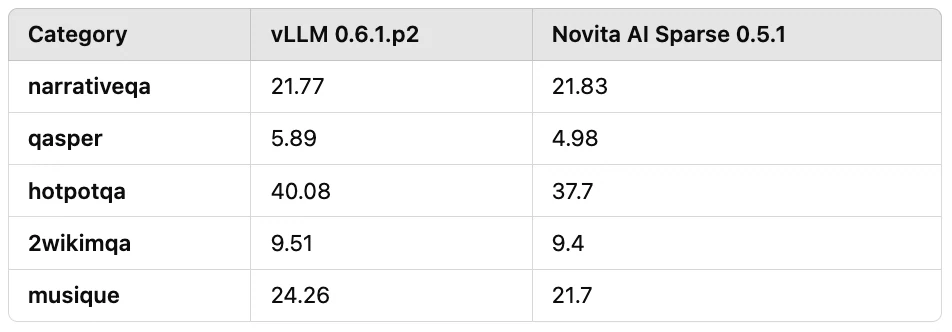
其次,我们对实际应用中常见的输入长度为 7k 到 30k 的长文本场景中的 QA 任务进行了评估。压缩比保持在 10 倍以上,如表 3 所示。结果表明,总体精度损失约为 10%。
表 3:输入长度为 7k 到 30k 的长文本问答任务评估结果
关键技术
1. 逐层稀疏性与张量并行
vLLM 框架采用了迭代级调度策略,通常称为 Continuous Batching。这种调度方式的特点是不等待批次中每个序列都生成完毕;相反,它支持迭代级调度,与静态批处理相比,GPU 利用率更高。正如本文开头所述,Llama3–8B 等模型本身具有分层稀疏性等特性。因此,基于 Continuous Batching 的修改遇到了一系列挑战,如图 4 所示。
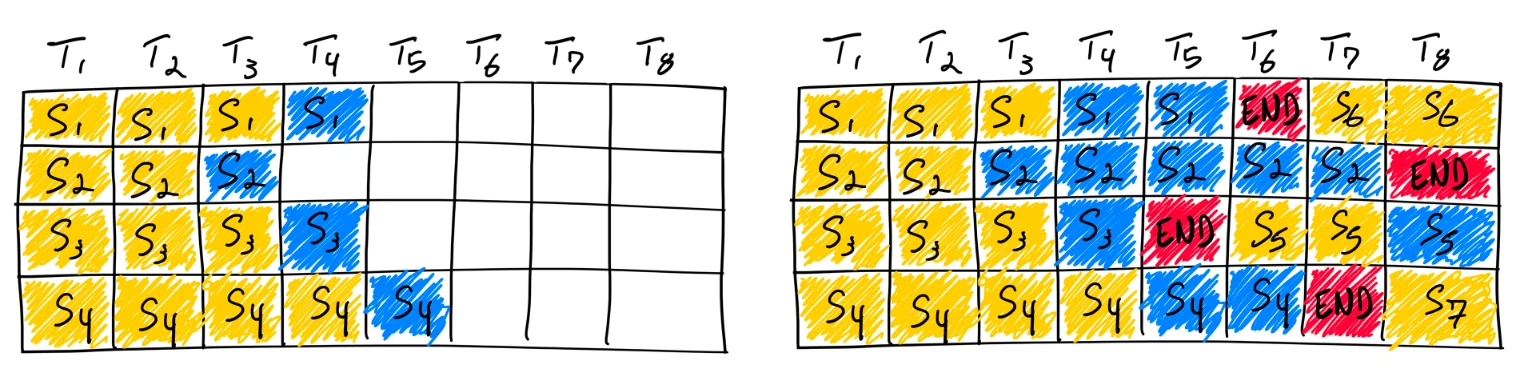
图 4. 使用 Continuous Batching 完成七个序列。左侧显示单次迭代后的批次,右侧显示多次迭代后的批次。一旦某个序列发出 end-of-sequence token,我们就在其位置引入一个新序列(例如序列 S5、S6 和 S7)。这种方法避免了 GPU 等待所有序列完成后再启动新序列的需要,从而提高了 GPU 利用率。
我们解决的主要挑战是跨不同层的内存管理。鉴于 vLLM 使用统一的分页内存管理模型,并且队列策略只能支持 Full Cache 或 Sliding Window,我们对 vLLM 的核心结构进行了修改,以支持同时使用这两种选项。
这一调整使得每一层都能灵活选择 Full Cache 或 Sliding Window,从而允许不同层达到不同的稀疏程度,如图所示的示意图。
需要解决的第一个挑战是不同层之间的内存管理问题。由于 vLLM 对所有层使用统一的分页内存管理模型,并且队列策略只能支持 Full Cache 或 Sliding Window,因此我们需要调整 vLLM 的底层结构。具体来说,需要支持 Full Cache 和 Sliding Window,以便不同的层可以独立选择其首选的内存管理策略。这一调整最终实现了不同层上的不同程度的稀疏性。对应的结构图如图 5 所示。
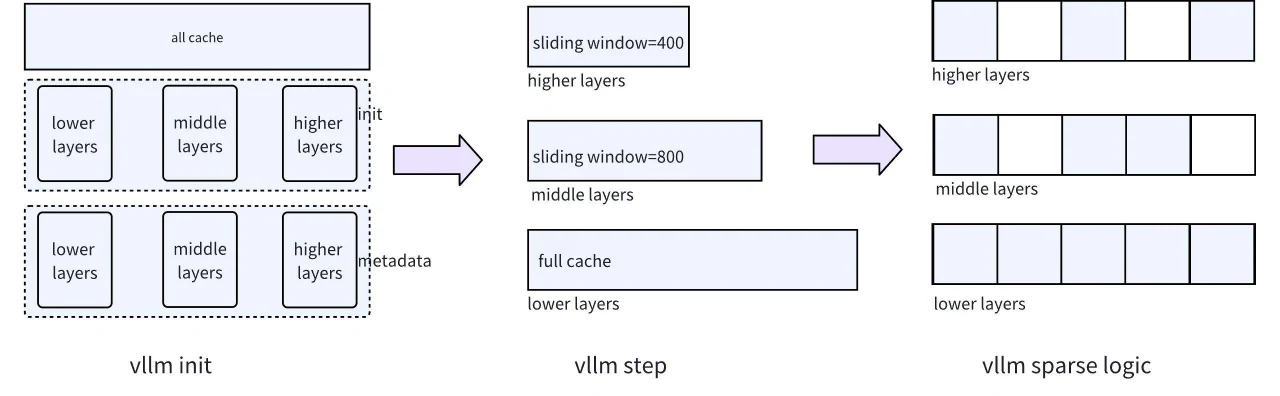
图 5. vLLM 中逐层内存管理结构
总体而言,调整可分为三个不同的阶段:
服务初始化阶段: 在服务启动过程中,主要通过计算剩余空间来初始化三个层分配的内存,同时对 Metadata 结构进行层次初始化。相比之下,原始 vLLM 作为完整的 Full Cache 运行,未考虑不同层的内存分配逻辑。
步骤准备阶段: 在 vLLM 步骤初始化过程中,特别是在涉及 block manager 和 model runner 方法的阶段,对不同层采用不同的块表管理策略来控制 KV 更新机制。如前图所示,我们对前三层使用 Full Cache 机制,存储所有 KV,而第三层之后的层采用 Sliding Window 策略自动替换得分最低的 KV。这种方法允许根据每层的需求灵活分配内存空间,从而节省空间,同时最大化稀疏算法的有效性。
稀疏化计算阶段: 该阶段通常在模型执行后执行,基于计算出的稀疏化分数执行稀疏化操作。此步骤中一个关键的考虑因素是兼容性,例如与 Tensor Parallelism、CUDA graphs 和 GQA 的兼容性。在实际工程实现中,需要特别关注张量并行性。如下图所示,在单机多 GPU 场景下,必须采用适当的分区机制将 KV 稀疏化操作限制在每个 GPU 内部,从而避免 GPU 之间的通信。幸运的是,Attention 单元采用基于 ColumnLinear 的分区方法,因此其实现相对简单。
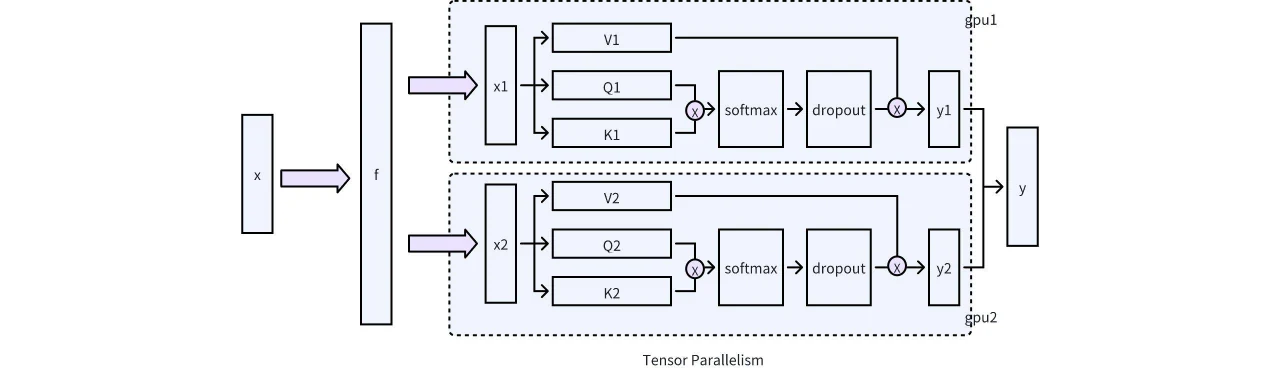
图 6. vLLM 中内存管理和稀疏化的三阶段流程
以上讨论主要集中在框架层面的修改,以支持 vLLM 中的层次稀疏性。接下来,我们将关注在 CUDA 层面实现的优化。
2. 注意力机制修改
CUDA 层面的修改主要集中在 Attention 计算单元的增强上,具体涉及 FlashAttention 和 PagedAttention。由于 PagedAttention 相对简单,我们将重点介绍与 FlashAttention 相关的修改。
首先,我们给出注意力的计算公式:
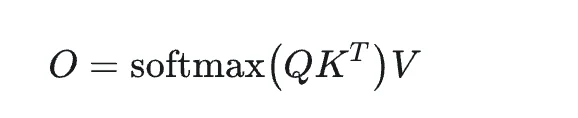
如公式所示,softmax 计算过程涉及计算 QK 的乘积,并且它是一个 2-pass 算法(需要两次遍历)。然而,最终的计算目标 O 可以使用 FlashAttention 算法通过单次遍历(一次传递)实现。FlashAttention 的实现逻辑可以通过 FlashAttention2 论文中的图 7 来说明。简而言之,它涉及对 Q 进行分块遍历以对 KV 执行块计算,同时逐步更新 O、P 和 rowmax 数据,直到循环结束。最后,将 O 除以 ℓ 即可实现 FlashAttention 的单次遍历。

图 7. FlashAttention2 的实现逻辑
对于我们的 KV 稀疏性实现,需要注意,在 FlashAttention 的计算过程中,softmax 所需的值(即 rowmax/ℓ,全局最大值和累积值)已经计算出来。但是,FlashAttention 并不返回这两个值的结果。
在对 FlashAttention 有了基本了解之后,我们现在可以讨论 PYRAMIDKV 等论文中提出的稀疏化评分公式:
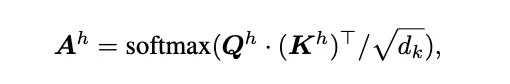
其中 [n − α, n] 是指令 token 的范围。在每个层 l 和每个头 h 中,选择得分最高的前 k_l 个 token,并保留其相应的 KV 缓存。所有其他 KV 缓存将被丢弃,并且在生成过程中的任何后续计算中都不会被使用。
具体来说,我们计算在每个注意力头 h 中选择第 i 个 token 保留在 KV 缓存中的得分 S,计算公式为:
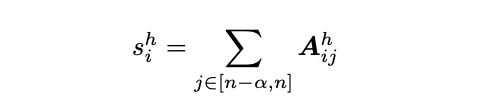
在上述公式中,A 表示 softmax 分数,而 S 表示最近的 a 个 softmax 值分数的总和。如所示,softmax 本身是一个 2-pass 算法,无法直接集成到 FlashAttention 中。这也意味着稀疏化评分无法通过 1-pass 实现。
如前所述,虽然 FlashAttention 不输出 softmax 分数,但它确实会计算中间值,例如 rowmax/ℓ。因此,通过参考 Online Softmax 的 2-pass 算法,我们可以利用 rowmax/ℓ 的输出来实现 KV 稀疏性的特定评分 S。实际上,我们只需要对图 7 中的 FlashAttention 进行改进即可满足这一要求。
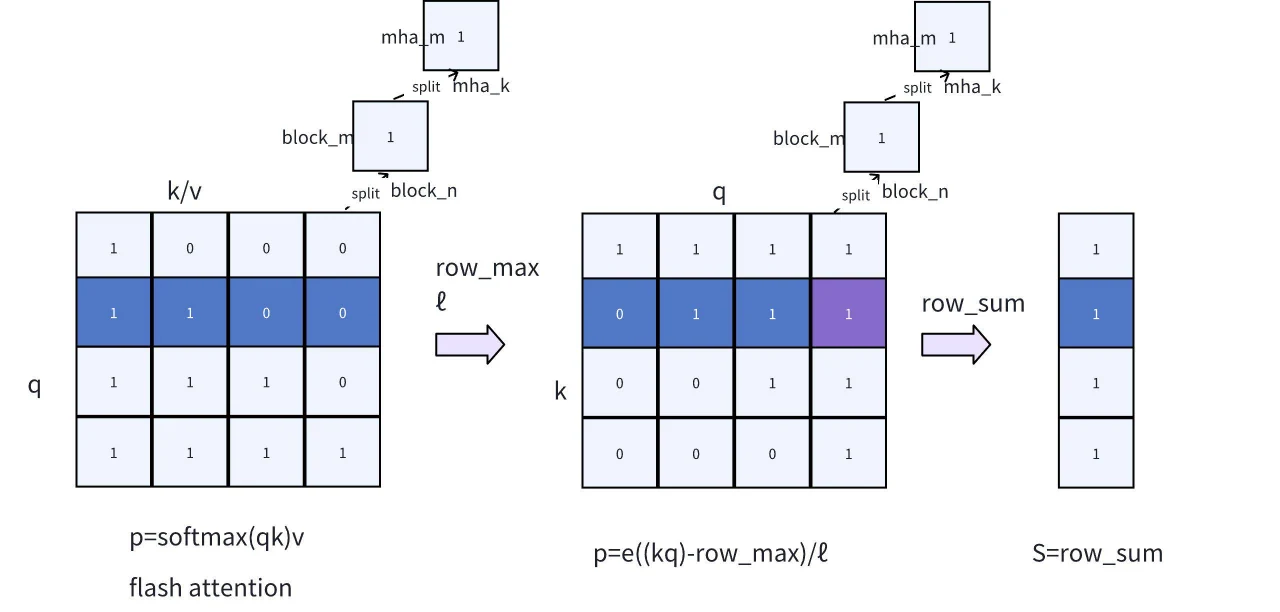
图 7. 针对 KV 稀疏性评分对 FlashAttention 的修改
- FlashAttention 中 rowmax/ℓ 的输出:FlashAttention 包含了 rowmax/ℓ 的输出。由于这些值代表最大值和累计总和,其数据量非常小,对 FlashAttention 的整体性能影响微乎其微。通过重用 rowmax/ℓ,我们可以避免第二次 1-pass,从而提高整体计算效率。
- 添加 Online Softmax 步骤:我们引入了 Online Softmax 步骤,它在 FlashAttention 的基础上,使用公式 p = e^((k·q) - row_max)/ℓ(1-pass 逻辑)计算 softmax 分数。随后,通过对行求和,即可计算出稀疏化分数 S。
在 Online Softmax 的实现中,有两个关键细节需要特别注意:
- **调整循环顺序 **:由于 S 是基于 k 维度的分数求和,因此相对于注意力机制,需要将 Online Softmax 中的计算从 q*k 调整为 k**q。这种调整通过将列求和转换为行求和,避免了不同块之间不必要的通信,使得所有计算都可以在寄存器内完成。
- q 的起始和结束位置:由于因果编码的存在以及对最近 a 个求和的逻辑,没有必要用 k 遍历所有 q 值。通过参考图 7 中标记为 0/1 的 mask 指示符,我们可以根据 q 的起始和结束位置确定是否需要计算相应的块,从而显著节省计算资源。例如,如果输入提示的长度是 5000,而最近 a 的长度是 256,传统计算需要 5000 * 5000 次操作。然而,通过记录起始和结束位置,只需要 5000 * 256 次操作,从而提高了计算效率。
PagedAttention 执行的工作与 FlashAttention 类似,共同目标是计算最终的分数 S。此处不提供 PagedAttention 的详细说明。
结论
我们基于 vLLM 0.5.1 修改的版本 Novita AI Sparse 0.5.1,目前主要支持 Llama3–8B 和 Llama3–70B 等模型。它以使用 CUDA graphs 的推理模式运行,主要部署在 RTX 4090 等消费级 GPU 上。在工程和算法方面仍有很大的优化空间。
温馨提示: 以下功能在 vLLM-0.6.2 中尚不支持:
- Chunked-prefill
- Prefix caching
- FlashInfer 及其他非 FlashAttention 后端
如果您对 Novita AI Sparse 0.5.1 感兴趣,可以访问 Novita AI 抢先体验。
参考文献:
[1] H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
[2] Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
[3] SnapKV: LLM Knows What You are Looking for Before Generation
[4] PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
[5] PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
[6] MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
[7] Layer-Condensed KV Cache for Efficient Inference of Large Language Models
[8] TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
[9] CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
[10] KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation


