

本文主要基于主流 GPU 硬件和量化算法的最新研究论文,探讨加速量化推理的可行方向。在当前量化方案的背景下,让我们深入探讨这个话题。
量化简介
模型量化是一种模型压缩技术,旨在通过调整权重和激活值的位宽来减小模型大小。这种减小有助于降低计算负载、GPU 内存 I/O 和占用,最终减少延迟并提高吞吐量。下图说明了量化如何加速深度学习:
- 第1步:权重和激活存储从内存加载到 MatMul 计算单元。权重和激活值的位宽显著影响数据传输延迟。
- 第2步:MatMul 计算单元执行矩阵乘法,位宽和格式也会影响延迟。
- 第3步:累加器通常具有更高的位宽以实现高精度求和。求和后,累加器中的值可能会进行重新量化(输出位宽决定了传输并存储回内存以供下一步处理的位数)。

深度学习加速器示意概览
根据不同的量化方案,主要有两种方法:量化感知训练(QAT)和训练后量化(PTQ)。
- QAT(量化感知训练),也称为在线量化,需要在训练过程中进行额外的计算。它将量化与反向传播相结合,调整模型权重,确保量化后的模型保持精度。
- PTQ(训练后量化),也称为离线量化,使用最少或无需额外数据对预训练模型进行量化。此过程包括校准,可能涉及缩放模型权重。PTQ 方法有两种类型:
- Post-Dynamic Quantization (PDQ) 不依赖校准数据集。相反,它直接使用量化公式转换每一层。QLoRA(量化感知低秩自适应)采用了这种方法。
- Post-Calibration Quantization (PCQ) 需要具有代表性的数据集,根据模型中每个层的输入输出来调整量化权重。GPTQ(生成式预训练变压器量化)采用了这种方法。
硬件支持
英伟达系列 英伟达系列显卡凭借 CUDA 生态系统,一直保持在支持不同精度和数据类型方面的领先地位。
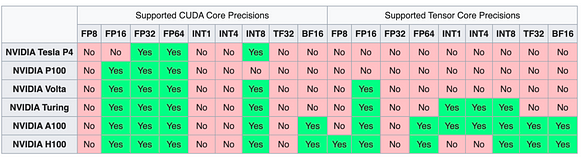
AMD 系列 AMD 的 MI300 系列显卡在一些测试中显示出超越 H100 的性能指标,使其成为一个有前途的后续选择。它们也支持 FP8 类型。

除了英伟达和 AMD 系列显卡外,国产显卡也对 FP16 和 INT8 等数据类型提供了良好支持(目前相对缺乏对 FP8 和其他数据格式的支持)。这里不一一列举。
LLM 量化的挑战
让我们从一个简单的比较开始。我们对 ResNet18 和 OPT-13B 模型都进行了基本的 INT 量化。我们发现 ResNet18 的性能几乎没有受到影响,而 OPT-13B 则经历了显著的损失。
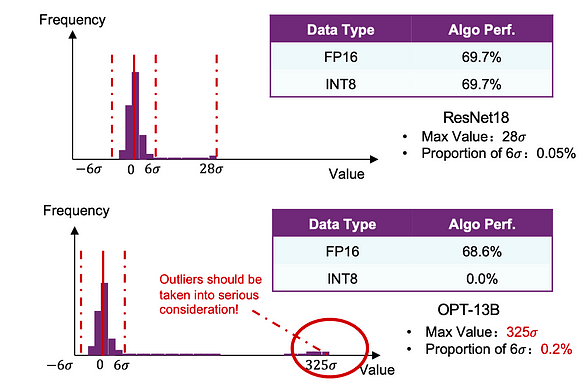
为什么都遵循高斯分布的神经网络会表现出如此差异?这主要归因于 LLM 中的异常值或离群点。

单个 Transformer 块,由自注意模块和线性模块组成。红色连接表示 Transformer 中存在异常值的问题连接。如上图 Transformer 结构中的红色标记所示,Transformer 中的量化问题发生在网络的一个非常特定的部分。在一些全连接模块中,特别是网络的最后几层,层归一化求和后存在显著的异常值。简单移除这些异常值会显著降低网络精度,因为它们有特定的用途。这些异常值迫使下一层的注意力机制关注文本中一些无意义的标记,如句子分隔符、句点或逗号,导致这些特定标记不会得到显著更新。根据论文 LLM.int8(),研究发现激活中存在异常值,其绝对值显著更大。此外,这些异常值分布在少数特征中,称为涌现特征。已知异常值对模型性能有显著影响,直接丢弃它们不是可行的解决方案。异常值的存在使得 fp16 的范围非常大。因此,当用 int8 表示它们时,每个数需要表示一个很宽的 fp16 范围,从而产生自然误差。传统的 CNN 也解决了这个问题,提出了校准方法。具体来说,对 fp16 值进行统计分析,然后使用 KL 散度等算法丢弃较大的值,从而减少 int8 需要表示 fp16 的范围,提高精度。丢弃的具体数量通过不断迭代 KL 算法以找到最优范围来确定。幸运的是,这些异常值非常特殊。它们只出现在某些注意力块中,在这些块中只出现在一层,并且在层内只出现在少数输出通道中。这些异常值甚至在每个数据点的相同通道中出现([1,3])。基于上述结论,LLM.int8()[1]提出了一种混合精度算法。

LLM.int8() 示意图
根据上图,X 表示每层的激活值,行数等于序列长度,列数等于隐藏大小。图中的黄色条表示异常值,生动地说明了它们的分布模式(第二个结论)。向量级量化的含义是,对于不是异常值的列,它们使用 int8 进行对称量化。由于我们处理的是列,在矩阵乘法中,相应的权重 W 需要从相应的行中提取出来进行 int8 运算。对于黄色的异常值列,行和列都用于 fp16 运算。最后,两部分的结果相加,等效于直接矩阵乘法。通过 LLM.int8() 的混合量化方法,精度几乎与 fp32 相同,此处不粘贴实验结果数据。
FP8 和 INT8
为什么专门提 FP8 和 INT8?这主要是因为最新的 GPU 架构,例如 hopper 架构和 Tensor Core,支持 FP8 精度计算。因此,探索 FP8 量化是值得的。

Tensor Core (Hopper) (a) 将 1 位分配给范围或精度 (b) 支持多种累加器和输出类型。
Int8 与 fp8 的不同之处在于它缺少中间的指数,只包含尾数。这种数据表示结构如下图所示,更适合表达均匀分布。

根据[4],如果分布表现出非常突出的异常值,那么 FP8-E4/FP8-E5 格式会更精确。但是,如果分布表现良好,更像高斯形状,那么预计 INT8 或 FP8-E2/FP8-E3 会表现更好。

这里我们针对几种分布绘制了 “精度位数”:反转和归一化的 RMSE
如上图所示,对于均匀分布,INT8 表现最佳。对于正态分布,FP8-E2 是最优的,紧随其后的是 INT8。神经网络中的许多分布是高斯分布,表明分布结果是高度相关的性能指标。只有当出现异常值时,具有更多指数位的格式才开始提供更好的结果。最优量化器基于 Lloyd-Max 量化器,并且可以针对这些分布获得。对于像 ResNet18、MobileNetV2 等网络,其中层大多是高斯形状,FP8-E2 和 INT 等格式表现最佳,而 FP8-E4 和 FP8-E5 等格式表现显著更差。我们还发现,像 ViT 和 BERT 这样的 Transformer 模型在 FP8-E4 上表现最佳,正是因为 Transformer 中的某些层具有非常大的异常值。具体来说,一些层在层归一化之前的激活中有许多异常值。因为这些异常值显著影响性能,导致裁剪时出现零误差,FP8-E4 格式表现最好,而 FP8-E2/INT8 格式表现显著更差。
那么,在 LLM 领域,FP8 是否具有绝对优势?结论可能恰恰相反,主要原因如下:
- 根据电路设计中定点数和浮点数的累加原理,FP8 MAC 单元的效率比 INT8 单元低 50% 到 180%。如果工作负载是计算密集型,这会减慢专用芯片的处理速度。
- 对于大多数网络,FP8 表现比 INT8 差,即使对于像 Transformer 这样有大量异常值的结构,也可以通过混合精度或量化感知训练方法来解决。
总体而言,在纯量化背景下,像 FP8-E4 和 FP8-E5 这样的浮点格式在深度学习的推理性能和精度方面无法取代 INT8。那么,FP8 格式的优势和定位在哪里?首先,总结一下 FP8 格式的优势:
- FP8 Tensor Core 比 16 位 Tensor Core 更快。
- 减少内存移动。
- 如果模型已经在 FP8 中训练,部署更方便。
- FP8 具有更宽的动态范围。
- 从 FP8 到 FP16/FP32/BF16 的转换电路可以设计得更简单直接,无需从 INT8/UINT8 到 FP 的转换所需的乘法和加法开销。
基于这些优势,显然 FP8 实际上更适合训练。参考[5],在无需修改任何超参数(如学习率和权重衰减)的情况下,无论是在预训练任务还是下游任务中,使用 FP8 训练的模型与使用 BF16 高精度训练的模型表现相似。值得注意的是,在 GPT-175B 模型的训练过程中,与 TE 方法相比,新提出的 FP8 混合精度框架在 H100 GPU 平台上可将训练时间减少 17%,内存使用量减少 21%。
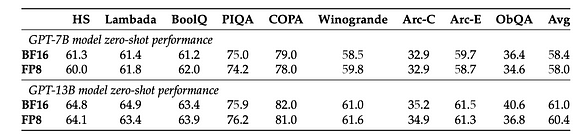
下游任务上的零样本性能。模型使用标准的 BF16 混合精度方案或提出的 FP8 低精度方案进行训练
使用 FP8 格式量化模型进行推理可以避免 QAT 或 PTQ 过程(以避免精度降低),同时得益于 FP8 到 FP16 等格式的更高转换效率,从而显著提高推理性能。
关于量化的最佳成本效益: 类似于 exllamav2 项目,它支持基于 GPTQ 算法的 2、3、4、5、6 和 8 位量化,但对于 LLM,哪种长度和格式在量化中提供最佳成本效益?参考[6],在各种 LLM 架构上进行了大量实验,以确定不同比特分配对模型性能的影响:

125M 到 176B 参数 OPT 模型在四个数据集上的平均零样本性能的比特级缩放规律。当量化精度从 16 位降低到 4 位时,固定模型比特数的零样本性能稳步提升。在 3 位时,这种关系逆转,使得 4 位精度成为最优。
- 对于给定的零样本性能,4 位精度几乎为所有模型系列和大小提供了最佳缩放(4 位精度不会导致模型性能显著下降)。唯一的例外是 BLOOM-176B,其中 3 位表现稍好,但并不显著。
- 4 位精度目前是每比特最高效的精度,同时也表明 3 位精度的性能还有提升空间。因此,研究低于 4 位的低位精度是一个有价值的方向。
- 对比特级量化的研究表明,数据类型和块大小是影响比特级量化效果的关键因素。
基于以上,我们可以得出结论:4 位精度量化是目前最具成本效益的方案。然而,在 4 位数据中,哪种数据类型能产生更好的量化结果?参考[7],LLM-FP4 方法提出以训练后方式对大语言模型(LLM)进行 FP4 量化,将权重和激活值量化为 4 位浮点值。现有的 PTQ 解决方案主要基于整数,在处理低于 8 位的位宽时存在困难。与整数量化相比,浮点(FP)量化更灵活,能更好地处理长尾或钟形分布,并已成为许多硬件平台的默认选择。
项目参考:https://github.com/nbasyl/LLM-FP4
FP 量化的一个特点是其性能在很大程度上取决于指数位和裁剪范围的选择。LLM-FP4 通过搜索最优量化参数,构建了一个强大的 FP-PTQ 基线。此外,激活分布中存在较高的通道间方差和较低的通道内方差,这增加了激活量化的难度。为了解决这个问题,LLM-FP4 提出了逐通道激活量化,并证明了这些额外的缩放因子可以重新参数化为权重的指数偏置,从而产生可忽略不计的成本。LLM-FP4 首次将 LLaMA-13B 中的权重和激活值量化为仅 4 位,在常识零样本推理任务上取得了 63.1 的平均得分,仅比全精度低 5.8 分,并显著超过了之前最先进的模型 12.7 个百分点。具体数据见下图:
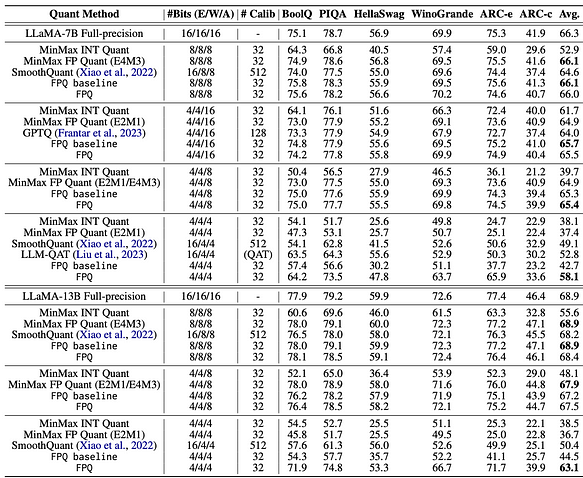
LLaMA 模型在常识推理任务上的零样本性能。我们用 E/W/A 分别表示词嵌入、模型权重和激活值的位宽
从上图可以得出以下主要结论:
- 当激活值不量化,词嵌入和权重量化为 4 位时,LLM-FP4(FP 类型)比 GPTQ(INT 类型)等算法略有优势。
- 当激活值量化为 8 位,词嵌入和权重量化为 4 或 8 位时,LLM-FP4(FP 类型)与其他算法(INT 类型)表现相似,性能没有显著差异。
- 当激活值量化为 4 位时,LLM-FP4(FP 类型)与其他算法(INT 类型)相比显示出明显改进。
总之,如果激活值不量化为 4 位,目前 FP4 相对于 INT4 没有显著优势。
一些值得关注的量化项目
GPTQ-for-LLaMa
- 使用 GPTQ 量化的模型具有显著的速度优势。简单来说,GPTQ 逐个量化块内的每个参数,每次参数量化后,都会调整块内的其他参数以补偿量化引起的精度损失。
- GPTQ 量化需要一个校准数据集,对模型进行训练后量化以获得量化权重。GPTQ 的概念源自 Yann LeCun 在 1990 年提出的 OBD 算法,该算法通过 OBS、OBC (OBQ) 等方法不断改进,而 GPTQ 是 OBQ 方法的加速版本。
GPTQ-for-LLaMa仓库专门为 LLaMa 提供了 GPTQ 量化解决方案。建议在 GPU 上部署 LLaMa 模型时使用。- 项目链接:GPTQ-for-LLaMa
ExLlama
- ExLlama 有两个版本:ExLlama 和 ExLlamaV2,是一个在当代消费级 GPU 上运行本地 LLM 的推理库。
- ExLlamaV2 支持与 V1 类似的 4 位 GPTQ 模型,但也引入了新的 “EXL2” 格式。EXL2 基于与 GPTQ 相同的优化方法,支持 2、3、4、5、6 和 8 位量化,允许在模型内混合量化级别,以实现每个权重 2 到 8 位之间的任意平均比特率。
- ExLlamaV2 可以对每个线性层应用多种量化级别,产生类似于稀疏量化的效果,其中更重要的权重(列)用更多比特量化。允许 ExLlama 高效处理顺序模型的相同重映射技术使得这种混合格式几乎不影响性能。
- 通常,ExLlama 的推理速度略快于其他量化方法。
- 项目链接:ExLlama
GGML
- GGML 是一个专注于机器学习的 C 语言库,由 Georgi Gerganov 创建,因此缩写为 “GG”。该库不仅提供张量等机器学习基本元素,还提供了一种用于分发 LLM 的独特二进制格式。
- GGML 用 C 编写,支持整数量化(4 位、5 位、8 位)和 16 位浮点。
- GGML 与
llama.cpp库无缝协作,确保从业者能够有效利用 LLM 的力量。llama.cpp库的主要目标是允许在 MacBook 上使用 INT4 量化的 LLaMA 模型。 - 项目链接:GGML
Transformer Engine
Transformer Engine (TE) 是一个旨在加速英伟达 GPU 上 Transformer 模型的库,包括在 Hopper GPU 上使用 8 位浮点 (FP8) 精度,从而在训练和推理中提供更低的显存利用率和更好的性能。TE 为流行的 Transformer 架构提供了一组高度优化的构建块,并带有一个自动混合精度类 API,可与特定框架的代码无缝集成。此外,TE 包含一个用于 Transformer 中 FP8 支持的框架无关 C++ API,可以与其他深度学习库集成。主要特性包括:
- 易于使用的模块,用于构建支持 FP8 的 Transformer 层。
- 针对 Transformer 模型的优化,包括内核融合。
- 支持英伟达 Hopper 和英伟达 Ada GPU 上的 FP8。
- 针对英伟达 Ampere GPU 架构及更高版本上所有精度(FP16, BF16)的优化。
项目链接:Transformer Engine
对于注意力测试,可以导入 te.LayerNormLinear 并测量注意力计算的平均时间。
| 阶段 | 模型结构 | 数据格式 | RTX 4090 | RTX 3090 |
|---|---|---|---|---|
| 基础注意力 | PyTorch 原生注意力 | FP16 | 92ms | 183ms |
| 基础注意力 + TE | Linear 和 LayerNorm tx 替换 | FP16 | 96ms | 不支持 |
| 基础注意力 + TE 的 LayerNorm 优化 | TE.LayerNormLinear | FP16 | 96ms | 不支持 |
| TE 完整 | TE 完整注意力算法 | FP16 | 74ms | 不支持 |
| TE 完整 + FP8 | FP 前向传播替换 | FP8 | 42ms | 不支持 |
测试结论:在使用 Transformer Engine 的情况下,使用 fp16 时相比基础注意力算法大约有 20% 的提升。此外,使用 fp8 时有显著的 54.5% 提升,表明投入时间改进推理性能是值得的。
Bitsandbytes
Bitsandbytes 是一个轻量级的自定义 CUDA 函数包装器,特别针对 8 位运算、矩阵乘法 (LLM.int8()) 和量化函数进行了优化,主要支持 LLM.int8() 量化算法。bitsandbytes 库支持分位数、线性和动态量化等量化方法。它是最简单的方法之一,不需要量化校准数据或校准过程。它可以随时与任何包含 torch.nn.Linear 模块的模型一起使用。当前分析表明,NF4(NormalFloat 数据类型)和 FP4 是同样有效的 4 位量化技术,表现出相似属性,如推理速度、内存消耗和生成内容的质量。NormalFloat 数据类型是一种增强形式的量化技术,代表了从信息论角度来看正态分布中权重的最优表示。它主要由 QLoRA 方法用于以 4 位精度微调模型。以下是 QLoRA 的一些数据:
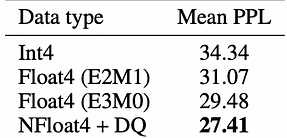
125M 到 13B 的 OPT、BLOOM、LLaMA 和 Pythia 模型在不同数据类型下的 Pile Common Crawl 平均困惑度。
AIMET
AIMET 是高通提供的用于神经网络模型的高级模型量化和压缩技术库。它旨在提高推理速度,同时减少计算和内存需求,对精度影响最小。例如,在高通 Hexagon DSP 上运行的模型可以实现比高通 Kyro CPU 快 5 到 15 倍的速度。AIMET 反映了非英伟达硬件上的量化实现。通常,它代表了硬件供应商提供的基本量化能力,目前没有一个项目能为不同硬件平台提供通用的量化能力。
结论
4 位量化是目前最具成本效益的量化方案。然而,优化取决于词嵌入、权重和激活值的量化级别。在大多数场景中,除了激活值量化为 4 位的情况外,整数(Int)量化提供了更好的成本效益,包括非量化场景。因此,低位量化,特别是通过训练后量化(PTQ)关注激活值的量化,是一个有前途的加速量化方向。
INT8 是目前最常用的量化方案。与 INT8 相比,FP8 在量化场景中无法完全替代它,但适用于模型训练,为解决推理性能问题提供了一条无需量化的途径。将 FP8 相关技术与硬件 Tensor Core 集成以最大化推理速度是一个值得探索的新方向。
基于 GPTQ 算法的项目主导了大语言模型(LLM)的格局。然而,新的数据类型(如 FP4 和 NF4)、更低的比特精度和动态量化为创新和研究提供了机会。
除了英伟达 GPU 之外,新的 GPU 和 CPU(如 AMD、国产 GPU 和高通)带来了新机遇。快速将量化算法适配到不同硬件平台并最大化硬件性能是一个新的探索方向。
参考文献
[1] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
[2] Outliers Dimensions that Disrupt Transformers Are Driven by Frequency
[3] Smoothquant: Accurate and efficient post-training quantization for large language models
[4] FP8 versus INT8 for efficient deep learning inference
[5] FP8-LM: Training FP8 Large Language Models
[6] The case for 4-bit precision: k-bit Inference Scaling Laws
[7] LLM-FP4: 4-Bit Floating-Point Quantized Transformers
[8] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
[9] Understanding the Impact of Post-Training Quantization on Large Language Models
[10] QLoRA: Efficient Finetuning of Quantized LLMs
novita.ai 提供 Stable Diffusion API 以及数百种快速且最便宜的 AI 图像生成 API,涵盖 10,000 个模型。🎯 最快 2 秒生成,按量付费,每张标准图像最低 0.0015 美元,您可以添加自己的模型并避免 GPU 维护。免费分享开源扩展。
推荐阅读


