

В этой статье рассматриваются возможные направления ускорения квантизованного вывода на основе последних научных работ по основным GPU и алгоритмам квантизации. В контексте современных схем квантизации давайте углубимся в тему. Краткое введение в квантизацию Квантизация модели — это техника сжатия модели, направленная на уменьшение размера модели за счёт изменения разрядности весов и активаций. Это снижение помогает уменьшить вычислительную нагрузку, ввод-вывод и занятость памяти GPU, что в итоге сокращает задержку и увеличивает пропускную способность. На следующей диаграмме показано, как квантизация ускоряет глубокое обучение:
- Шаг 1: Веса и активации загружаются из памяти в вычислительные блоки MatMul. Разрядность весов и активаций существенно влияет на задержку передачи данных.
- Шаг 2: Вычислительные блоки MatMul выполняют матричное умножение, где разрядность и формат также влияют на задержку.
- Шаг 3: Аккумуляторы обычно имеют более высокую разрядность для высокоточного суммирования. После суммирования значения в аккумуляторах могут подвергаться повторной квантизации (выходная разрядность определяет количество бит, передаваемых и сохраняемых обратно в память для следующего шага обработки).

Схематический обзор ускорителя глубокого обучения В зависимости от схемы квантизации существуют два основных подхода: тренировка с учётом квантизации (QAT) и пост-тренировочная квантизация (PTQ).
- QAT (Quantization-Aware Training), также известная как онлайн-квантизация, требует дополнительных вычислительных затрат во время обучения. Она сочетает квантизацию с обратным распространением для корректировки весов модели, гарантируя, что квантизованная модель сохраняет точность.
- PTQ (Post-Training Quantization), также известная как офлайн-квантизация, включает квантизацию предварительно обученной модели с использованием минимального количества дополнительных данных или вообще без них. Этот процесс включает калибровку, которая может включать масштабирование весов модели. Существует два типа методов PTQ:
- Пост-динамическая квантизация (PDQ) не relies on calibration datasets. Вместо этого она напрямую преобразует каждый слой с помощью формул квантизации. QLoRA (Quantization-aware Low-Rank Adaptation) использует этот метод.
- Пост-калибровочная квантизация (PCQ) требует репрезентативных наборов данных для корректировки весов квантизации на основе входных и выходных данных каждого слоя модели. GPTQ (Generative Pre-training Transformer for Quantization) применяет этот подход.
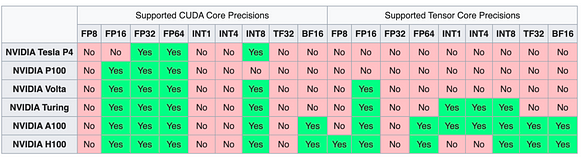
Поддержка оборудования
Серия NVIDIA Карты серии NV благодаря экосистеме CUDA всегда занимали лидирующие позиции в поддержке различной точности и типов данных.

Проблемы квантизации LLM
Начнём с простого сравнения. Мы провели базовую INT-квантизацию моделей ResNet18 и OPT-13B. Мы обнаружили, что производительность ResNet18 почти не пострадала, в то время как OPT-13B испытала значительные потери.
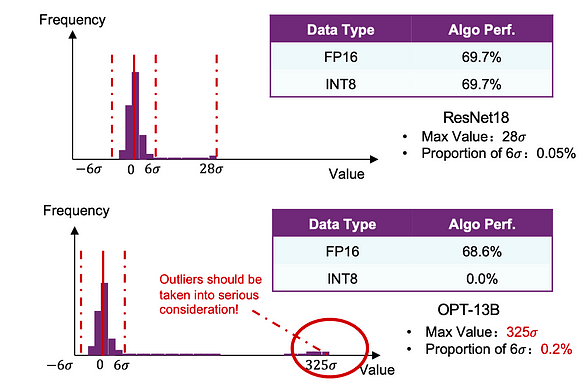


Схема LLM.int8() Согласно диаграмме выше, X представляет активации каждого слоя, количество строк равно длине последовательности, количество столбцов — скрытому размеру. Жёлтые столбцы на диаграмме представляют выбросы, наглядно иллюстрируя их распределение (второй вывод). Смысл векторной квантизации в том, что для столбцов, не являющихся выбросами, используется симметричная квантизация int8. Поскольку мы работаем со столбцами, при матричном умножении соответствующие веса W необходимо извлечь из соответствующих строк для операций int8. Для жёлтых столбцов-выбросов и строки, и столбцы используются для операций fp16. Наконец, результаты двух частей складываются, что эквивалентно прямому матричному умножению. Благодаря смешанному методу квантизации LLM.int8() точность почти такая же, как у fp32, и экспериментальные данные здесь не приводятся.
FP8 и INT8
Почему стоит отдельно упомянуть FP8 и INT8? Это связано с новейшими архитектурами GPU, такими как архитектура hopper и тензорные ядра, которые поддерживают вычисления с точностью FP8. Поэтому стоит изучить квантизацию FP8.



- Согласно принципам сложения с фиксированной и плавающей точкой при проектировании схем, FP8 MAC-блоки на 50–180% менее эффективны, чем INT8-блоки. Если нагрузка ограничена вычислениями, это замедляет скорость обработки специализированных чипов.
- Для большинства сетей FP8 работает хуже, чем INT8, даже для структур типа трансформеров с большим количеством выбросов, которые можно обрабатывать с помощью методов смешанной точности или тренировки с учётом квантизации. В целом, в контексте чистой квантизации форматы с плавающей точкой, такие как FP8-E4 и FP8-E5, не могут заменить INT8 по производительности и точности в выводе глубокого обучения. В чём же тогда преимущество и позиционирование формата FP8? Сначала подведём итоги преимуществ формата FP8:
- FP8 Tensor Cores быстрее, чем 16-битные Tensor Cores.
- Уменьшает перемещение данных.
- Если модель уже обучена в FP8, развёртывание более удобно.
- FP8 имеет более широкий динамический диапазон.
- Схема преобразования из FP8 в FP16/FP32/BF16 может быть спроектирована проще и прямее, без накладных расходов на умножение и сложение, необходимых для преобразования из INT8/UINT8 в FP. Основываясь на этих преимуществах, очевидно, что FP8 на самом деле больше подходит для обучения. Согласно [5], без изменения каких-либо гиперпараметров, таких как скорость обучения и затухание весов, как в задачах предобучения, так и в последующих задачах, модели, обученные с использованием FP8, показывают результаты, аналогичные моделям, обученным с использованием высокоточной тренировки BF16. Стоит отметить, что при обучении модели GPT-175B по сравнению с методом TE, недавно предложенная структура смешанной точности FP8 на платформе H100 GPU может сократить время обучения на 17% и использование памяти на 21%.
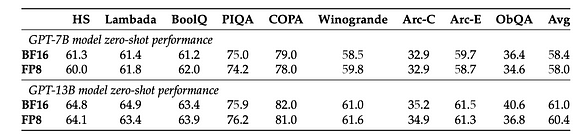

- Для данной нуль-шотовой производительности 4-битная точность обеспечивает наилучшее масштабирование почти для всех серий и размеров моделей (4-битная точность не приводит к значительному падению производительности модели). Единственное исключение — BLOOM-176B, где 3 бита показывают немного лучший результат, но не существенно.
- 4-битная точность в настоящее время является наиболее эффективной точностью в расчете на бит, а также указывает на то, что производительность 3-битной точности может быть улучшена. Таким образом, исследования низкой битовой точности ниже 4 бит являются перспективным направлением.
- Исследование квантизации на уровне битов показывает, что типы данных и размер блока являются ключевыми факторами, влияющими на эффективность квантизации на уровне битов. Основываясь на вышеизложенном, можно сделать вывод, что 4-битная квантизация в настоящее время является наиболее экономически эффективным решением. Однако среди 4-битных данных, какой тип данных даёт лучшие результаты квантизации? Согласно [7], метод LLM-FP4 предлагает FP4-квантизацию для больших языковых моделей (LLM) в пост-тренировочном режиме, квантизуя веса и активации в 4-битные значения с плавающей точкой. Существующие решения PTQ в основном основаны на целых числах и испытывают трудности с разрядностью менее 8 бит. По сравнению с целочисленной квантизацией, квантизация с плавающей точкой (FP) более гибкая, лучше обрабатывает длиннохвостые или колоколообразные распределения и стала выбором по умолчанию для многих аппаратных платформ. Ссылка на проект: https://github.com/nbasyl/LLM-FP4 Одна из характеристик FP-квантизации заключается в том, что её производительность во многом зависит от выбора бит экспоненты и диапазона отсечения. LLM-FP4 создаёт надёжный базовый уровень FP-PTQ путём поиска оптимальных параметров квантизации. Кроме того, в распределении активаций наблюдается более высокая межканальная вариативность и более низкая внутриканальная вариативность, что увеличивает сложность квантизации активаций. Для решения этой проблемы LLM-FP4 предлагает поканальную квантизацию активаций и демонстрирует, что эти дополнительные коэффициенты масштабирования могут быть перепараметризованы в смещения экспоненты весов, неся незначительные затраты. LLM-FP4 впервые квантизует веса и активации в LLaMA-13B всего до 4 бит, достигая среднего балла 63.1 в задачах нуль-шотового здравого смысла, что всего на 5.8 ниже, чем у полной выборки, и значительно превосходит предыдущую самую современную модель на 12.7 процентных пунктов. Конкретные данные можно найти на следующем рисунке:
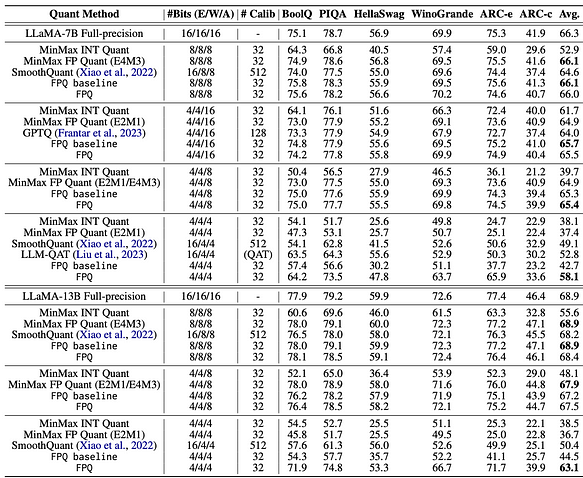
- Когда активации не квантизованы, а встраивания слов и веса квантизованы до 4 бит, LLM-FP4 (тип FP) имеет небольшое преимущество перед алгоритмами типа GPTQ (тип INT).
- Когда активации квантизованы до 8 бит, а встраивания слов и веса квантизованы до 4 или 8 бит, LLM-FP4 (тип FP) показывает результаты, аналогичные другим алгоритмам (тип INT), без существенных различий в производительности.
- Когда активации квантизованы до 4 бит, LLM-FP4 (тип FP) демонстрирует заметное улучшение по сравнению с другими алгоритмами (тип INT). В заключение, если активации не квантизованы до 4 бит, в настоящее время нет существенного преимущества FP4 перед INT4.
Некоторые заслуживающие внимания проекты квантизации включают
GPTQ-for-LLaMa
-
Модели, квантизованные с помощью GPTQ, обеспечивают значительное преимущество в скорости. Проще говоря, GPTQ квантизует каждый параметр внутри блока отдельно, и после квантизации каждого параметра вносятся корректировки в другие параметры внутри блока для компенсации потери точности, вызванной квантизацией.
-
Квантизация GPTQ требует калибровочного набора данных для выполнения пост-тренировочной квантизации модели и получения квантизованных весов. Концепция GPTQ берёт начало от алгоритма OBD Янна Лекуна, предложенного в 1990 году, который постоянно улучшался с помощью методов OBS, OBC (OBQ), и GPTQ является ускоренной версией метода OBQ.
-
Репозиторий GPTQ-for-LLaMa предоставляет решение квантизации GPTQ специально для LLaMa. Рекомендуется для развёртывания моделей LLaMa на GPU.
-
Ссылка на проект: GPTQ-for-LLaMa ExLlama
-
ExLlama существует в двух версиях: ExLlama и ExLlamaV2. Это библиотека вывода для запуска локальных LLM на современных потребительских GPU.
-
ExLlamaV2 поддерживает 4-битные модели GPTQ, как и V1, но также вводит новый формат «EXL2». EXL2, основанный на тех же методах оптимизации, что и GPTQ, поддерживает квантизацию на 2, 3, 4, 5, 6 и 8 бит, позволяя смешивать уровни квантизации внутри модели для достижения любого среднего битрейта от 2 до 8 бит на вес.
-
ExLlamaV2 может применять несколько уровней квантизации к каждому линейному слою, создавая нечто вроде разреженной квантизации, где более важные веса (столбцы) квантизуются с большим количеством бит. Те же методы ремаппинга, которые позволяют ExLlama эффективно работать с последовательными моделями, позволяют использовать этот смешанный формат практически без влияния на производительность.
-
В целом ExLlama обеспечивает немного более высокую скорость вывода по сравнению с другими подходами к квантизации.
-
Ссылка на проект: ExLlama GGML
-
GGML — это библиотека на C, ориентированная на машинное обучение, созданная Георгием Гергановым, отсюда аббревиатура «GG». Библиотека предоставляет не только фундаментальные элементы машинного обучения, такие как тензоры, но также предлагает уникальный бинарный формат для распространения LLM.
-
GGML написана на C, поддерживает целочисленную квантизацию (4-бит, 5-бит, 8-бит) и 16-битные числа с плавающей точкой.
-
GGML бесшовно взаимодействует с библиотекой llama.cpp, позволяя практикам эффективно использовать возможности LLM. Основная цель библиотеки llama.cpp — обеспечить использование INT4 квантизованных моделей LLaMA на MacBook.
-
Ссылка на проект: GGML Transformer Engine Transformer Engine (TE) — это библиотека, предназначенная для ускорения моделей-трансформеров на GPU NVIDIA, включая использование 8-битной точности с плавающей точкой (FP8) на GPU Hopper, что обеспечивает лучшую производительность с меньшим использованием памяти как при обучении, так и при выводе. TE предлагает набор высокооптимизированных строительных блоков для популярных архитектур трансформеров, а также API автоматической смешанной точности, который бесшовно интегрируется с кодом, специфичным для фреймворка. Кроме того, TE включает в себя не зависящий от фреймворка C++ API для поддержки FP8 в трансформерах, который можно интегрировать с другими библиотеками глубокого обучения. Ключевые особенности включают:
-
Простые в использовании модули для построения слоёв трансформера с поддержкой FP8.
-
Оптимизация для моделей-трансформеров, включая слияние ядер.
-
Поддержка FP8 на NVIDIA Hopper и NVIDIA Ada GPU.
-
Оптимизация для всех точностей (FP16, BF16) на архитектуре NVIDIA Ampere и выше. Ссылка на проект: Transformer Engine Для тестирования внимания можно импортировать
te.LayerNormLinearи измерить среднее время вычисления внимания. StageModel StructureData FormatRTX 4090RTX 3090Basic AttentionPyTorch Native AttentionFP1692ms183msBasic Attention + TELinear and LayerNorm tx replacementFP1696msNot supportedBasic Attention + TE’s LayerNorm OptimizationTE.LayerNormLinearFP1696msNot supportedTE FullTE Full Attention AlgorithmFP1674msNot supportedTE Full + FP8FP Forward Propagation ReplacementFP842msNot supported Вывод тестов: В случае Transformer Engine наблюдается примерно 20% улучшение относительно базового алгоритма внимания при использовании fp16. Кроме того, наблюдается значительное улучшение на 54.5% при использовании fp8, что указывает на то, что стоит потратить время на улучшение производительности вывода. Bitsandbytes: Bitsandbytes — это лёгкая обёртка для пользовательских функций CUDA, специально оптимизированная для 8-битных операций, матричного умножения (LLM.int8()) и функций квантизации, в основном поддерживающая алгоритм квантизации LLM.int8(). Библиотека bitsandbytes поддерживает такие методы квантизации, как квантили, линейная и динамическая квантизация. Это один из самых простых доступных методов, не требующий калибровочных данных или процесса калибровки. Его можно легко использовать с любой моделью, содержащей модули torch.nn.Linear. Текущий анализ показывает, что NF4 (тип данных NormalFloat) и FP4 являются одинаково эффективными методами 4-битной квантизации, демонстрируя схожие атрибуты, такие как скорость вывода, потребление памяти и качество генерируемого контента. Тип данных NormalFloat — это улучшенная форма техники квантизации, представляющая оптимальное представление весов в нормальном распределении с точки зрения теории информации. В основном он используется методом QLoRA для тонкой настройки моделей с 4-битной точностью. Ниже приведены некоторые данные из QLoRA:
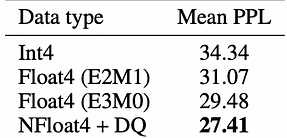
В заключение
4-битная квантизация в настоящее время является наиболее экономически эффективной схемой квантизации. Однако оптимизация варьируется в зависимости от уровня квантизации встраиваний слов, весов и активаций. В большинстве сценариев, за исключением случаев, когда активации квантизованы до 4 бит, целочисленная (Int) квантизация обеспечивает лучшую экономическую эффективность, включая сценарии без квантизации. Таким образом, низкобитовая квантизация, особенно с акцентом на активации с помощью пост-тренировочной квантизации (PTQ), является перспективным направлением для ускорения квантизации. INT8 — это наиболее часто используемая схема квантизации в настоящее время. По сравнению с INT8, FP8 не может полностью заменить его в сценариях квантизации, но подходит для обучения моделей, предлагая решение проблем производительности вывода без необходимости квантизации. Интеграция методов, связанных с FP8, с аппаратными тензорными ядрами для максимального увеличения скорости вывода — это новое направление, которое стоит изучить. Проекты, основанные на алгоритме GPTQ, доминируют в ландшафте больших языковых моделей (LLM). Однако новые типы данных (такие как FP4 и NF4), более низкая битовая точность и динамическая квантизация открывают возможности для инноваций и исследований. Помимо GPU NVIDIA, новые GPU и CPU (такие как AMD, отечественные GPU и Qualcomm) предоставляют новые возможности. Быстрая адаптация алгоритмов квантизации к различным аппаратным платформам и максимальное использование производительности оборудования — это новое направление для исследований.
Ссылочные статьи
[1]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale [2]Outliers Dimensions that Disrupt Transformers Are Driven by Frequency [3]Smoothquant: Accurate and efficient post-training quantization for large language models [4]FP8 versus INT8 for efficient deep learning inference [5]FP8-LM: Training FP8 Large Language Models [6]The case for 4-bit precision: k-bit Inference Scaling Laws [7]LLM-FP4: 4-Bit Floating-Point Quantized Transformers [8]GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers [9]Understanding the Impact of Post-Training Quantization on Large Language Models [10]QLoRA: Efficient Finetuning of Quantized LLMs
novita.ai предоставляет API Stable Diffusion и сотни быстрых и самых дешевых AI-генерации изображений для 10 000 моделей. 🎯 Самая быстрая генерация всего за 2 секунды, оплата по мере использования, минимум $0.0015 за стандартное изображение; вы можете добавлять свои собственные модели и избежать обслуживания GPU. Бесплатно делитесь расширениями с открытым исходным кодом.
Рекомендуемое чтение


