
Мотивация
Изучив недавние академические статьи за последний год в области разреженности KV (H2O, SnapKV, PyramidKV), мы применяем разреженность KV к разным слоям модели. Используя стратегию сокращения, мы удаляем KV-пары с низкими оценками, сохраняя при этом те, которые имеют более высокие оценки и расположены ближе. Такой подход снижает использование памяти, а также вычислительные и I/O накладные расходы, что в конечном итоге приводит к ускорению вывода.
Эксперименты
Базовые модели и настройки: Все эксперименты с KV-Compress мы проводили с использованием нашей интеграции vLLM, ответвлённой от версии v0.6.2, работающей в режиме cuda graph с размером блоков 16. Для всех экспериментов на RTX 4090/Llama-3.1-8B-Instruct мы использовали загрузку GPU по умолчанию 0.9 и установили maxmodel-length равным 32k. Мы оценивали наше сжатие на Llama-3.1-8B-Instruct, сравнивая производительность со следующими базовыми методами, представленными в предыдущих работах:
- vLLM-0.6.2
- Novita AI, сжатие Pyramid KV Cache на основе фреймворка vLLM
MMLU Pro и LongBench: Мы контролируем разные коэффициенты сжатия KV-кэша, устанавливая разные длины скользящего окна на разных слоях. В эксперименте мы в основном устанавливали три разные длины скользящего окна: 1024, 1280 и 1536, и проводили перекрёстные тесты на разном количестве слоёв.
MMLU Pro
В тесте MMLU Pro разные слои разреженности KV и разная длина скользящего окна показывают разную производительность. С учётом коэффициента ускорения общая точность может быть гарантирована на уровне выше 98%.
| vllm-0.6.2 | Novita AI | |
| Слои разреженности KV | полный | скользящее окно=1536 |
| 22 | 0.4517 | 0.4496 |
| 26 | 0.4517 | 0.4476 |
| 31 | 0.4517 | 0.4476 |
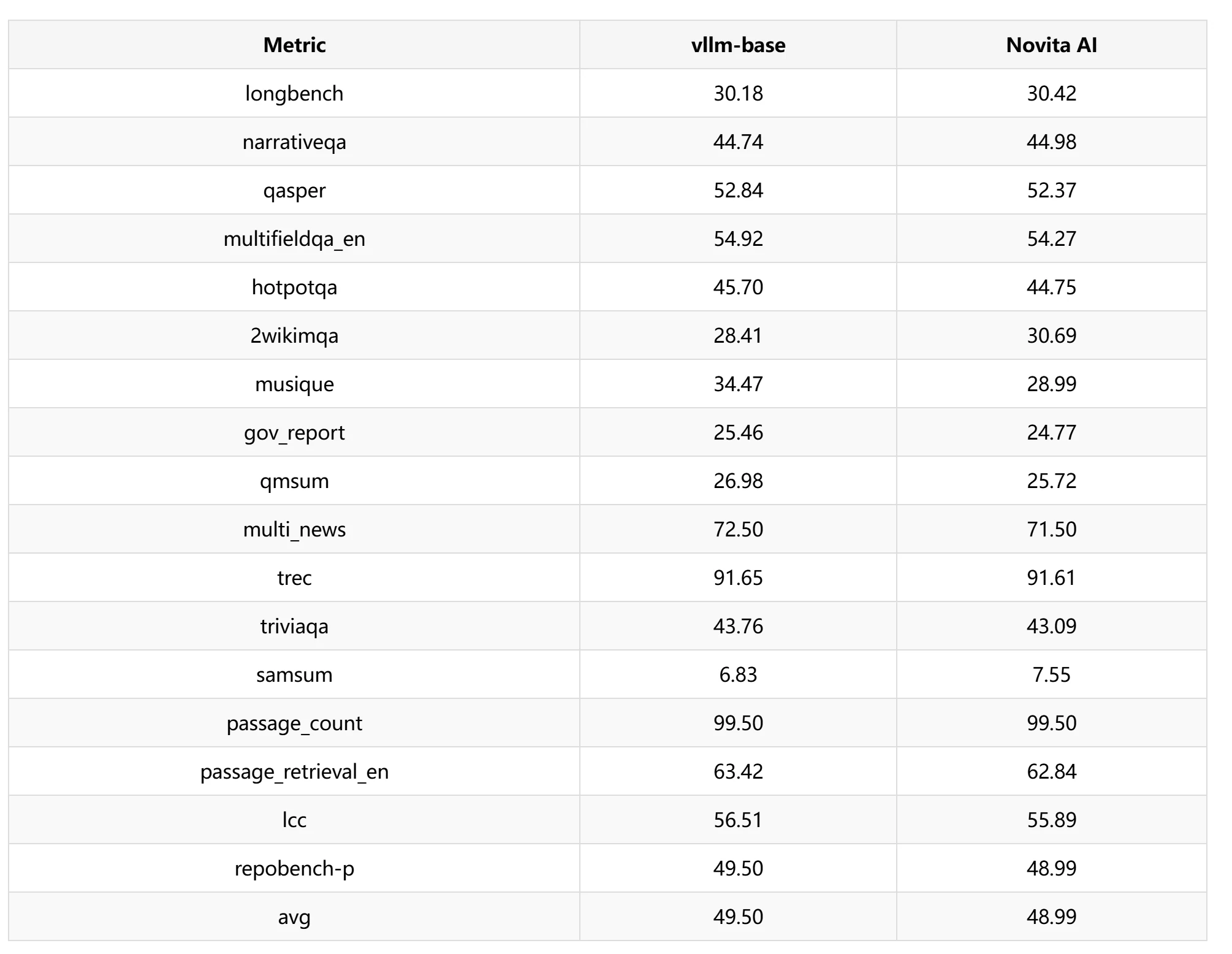
LongBench
В тесте LongBench мы выбрали скользящее окно 1024 для тестирования производительности и обнаружили, что потеря точности составила около 1.03%.
Бенчмарки пропускной способности: В реальных LLM-приложениях длина ввода/вывода 5000/500 является наиболее часто встречающейся конфигурацией, и показатель TTFT должен быть менее 2 с. На основе этих условий мы провели сравнительное тестирование производительности пакетной обработки, которое показало ускорение вывода в 1.5 раза для vLLM.
| Пропускная способность | vllm-0.6.2 | Novita AI |
| Слои разреженности KV | полный | скользящее окно=1536 |
| 22 | 1 | 1.26 |
| 26 | 1 | 1.34 |
| 31 | 1 | 1.44 |
Основные изменения
Изменённые файлы в основном включают:
- Flash attention — разреженная оценка на основе Flash attention с обеспечением потери производительности ядра менее 1%.
- Paged attention и reshape_and_cache — разреженная оценка на основе Paged attention и синхронизация разреженной оценки на этапах prefill и decode.
- Block_manager и другие функции, связанные с управлением памятью и подготовкой тензоров.
Заключение
Novita AI также поддерживает тензорный параллелизм, позволяющий запускать такие модели, как Llama3-70B, на нескольких GPU. В настоящее время по ряду причин мы не открываем код, но надеемся внести свой вклад в сообщество технологиями и идеями и приветствуем технический обмен со всеми. Обратите внимание: следующие функции пока не поддерживаются в vLLM-0.6.2:
- Chunked-prefill
- Prefix caching
- FlashInfer и другие бэкенды, не основанные на FlashAttention
- Спрекативное декодирование
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей через наш простой API, а также предлагает доступные и надёжные GPU-облака для создания и масштабирования.
Рекомендуемое чтение



