
動機
透過回顧過去一年在 KV 稀疏性領域的近期學術論文(H2O、SnapKV、PyramidKV),我們將 KV 稀疏性應用於模型的不同層。採用剪枝策略,我們移除分數較低的 KV 對,同時保留分數較高且距離較近的 KV 對。這種方法減少了記憶體使用量,以及運算與 I/O 開銷,最終實現加速推理。
實驗
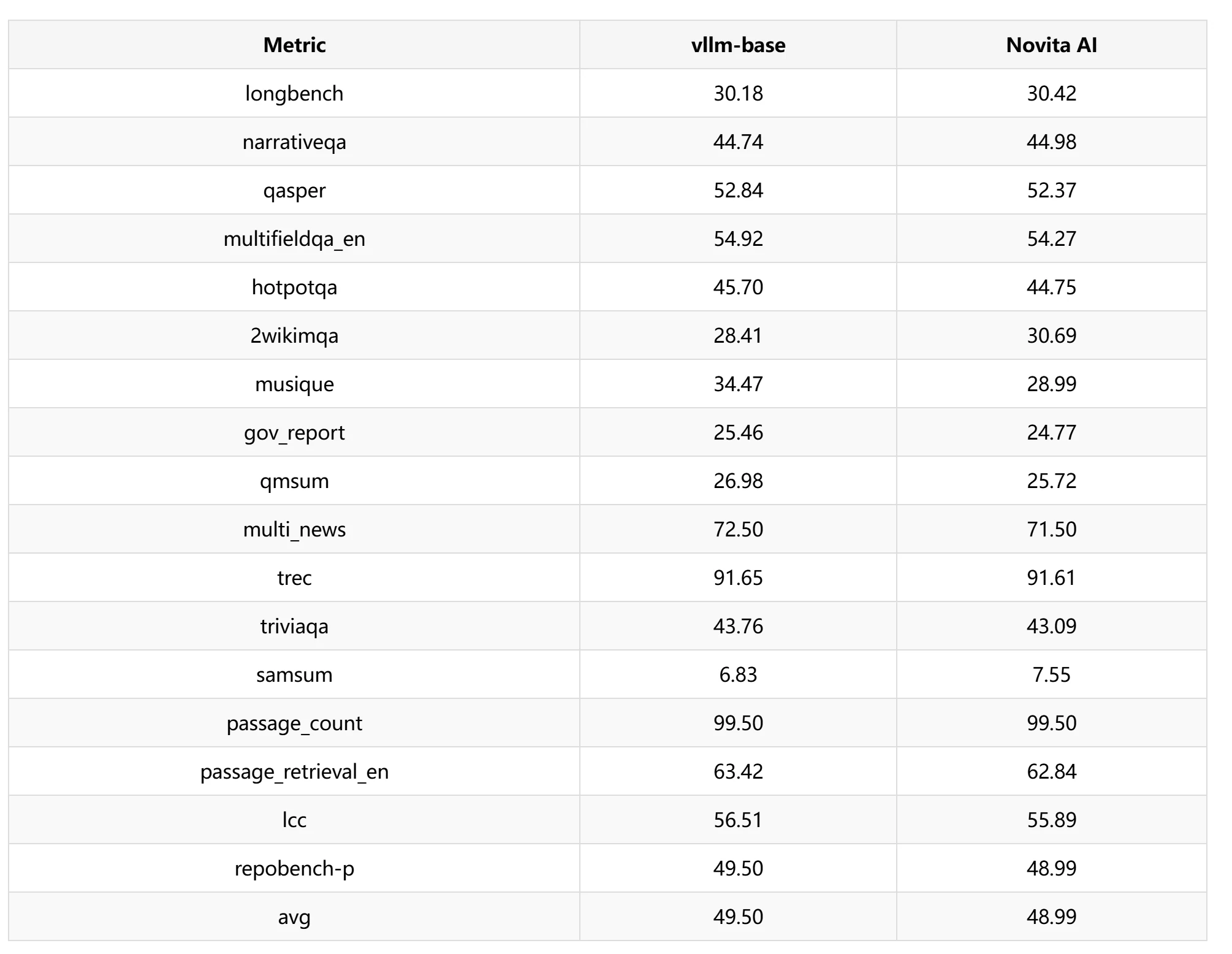
基準方法與設定: 我們使用基於 vLLM 0.6.2 分支的整合版本進行所有 KV-Compress 實驗,並在 cuda graph 模式下以區塊大小 16 執行。所有 RTX 4090 / Llama-3.1-8B-Instruct 實驗均使用預設 GPU 記憶體利用率 0.9,並將 maxmodel-length 設為 32k。我們在 Llama-3.1-8B-Instruct 上評估壓縮效果,並與先前研究中提出的以下基準方法進行比較:
- vLLM-0.6.2
- Novita AI,基於 vLLM 框架的金字塔 KV 快取壓縮
MMLU Pro 與 LongBench: 我們透過在不同層設定不同的滑動視窗長度,來控制不同的 KV 快取壓縮比例。實驗中主要設定了三種滑動視窗長度:1024、1280 與 1536,並在不同層數上進行交叉測試。MMLU Pro 測試中,不同的 KV 稀疏層與不同的滑動視窗長度表現出不同的效能。考量加速比後,整體準確率可確保維持在 98% 以上。
| vllm-0.6.2 | Novita AI | |
| KV 稀疏層數 | 完整 | 滑動視窗=1536 |
| 22 | 0.4517 | 0.4496 |
| 26 | 0.4517 | 0.4476 |
| 31 | 0.4517 | 0.4476 |
LongBench 測試中,我們選用滑動視窗 1024 進行效能測試,發現準確度損失約為 1.03%。
吞吐量基準測試: 在實際的 LLM 應用中,輸入/輸出長度 5000/500 是最常見的配置,且 TTFT 指標必須小於 2 秒。基於這些條件,我們進行了批次效能比較測試,vLLM 獲得了 1.5 倍的推理加速。
| 吞吐量 | vllm-0.6.2 | Novita AI |
| KV 稀疏層數 | 完整 | 滑動視窗=1536 |
| 22 | 1 | 1.26 |
| 26 | 1 | 1.34 |
| 31 | 1 | 1.44 |
主要變更
修改的檔案主要包括:
- Flash attention:基於 Flash attention 實現稀疏評分,同時確保核心效能損失低於 1%。
- Paged attention 與 reshape_and_cache:基於 Paged attention 進行稀疏評分,並在 prefill 與 decode 階段同步稀疏評分。
- Block_manager 及其他與記憶體管理及 tensor 準備相關的功能。
結論
Novita AI 也支援張量並行,讓 Llama3-70B 等模型能夠在多個 GPU 上執行。目前因某些原因未開放程式碼,但我們希望為社群貢獻一些技術與思路,並歡迎與大家進行技術交流。請注意: 以下功能在 vLLM-0.6.2 中尚未支援:
- Chunked-prefill
- Prefix caching
- FlashInfer 及其他非 FlashAttention 的後端
- Speculative Decoding
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來部署 AI 模型,同時提供平價且可靠的 GPU 雲端服務用於建置與擴展。
推薦閱讀



