
Motivation
En examinant des articles académiques récents de l’année écoulée dans le domaine de la sparsité KV (H2O, SnapKV, PyramidKV), nous appliquons la sparsité KV à différentes couches du modèle. En utilisant une stratégie d’élagage, nous éliminons les paires KV avec des scores faibles tout en conservant celles avec des scores élevés et une proximité plus grande. Cette approche réduit l’utilisation de la mémoire, ainsi que les surcharges de calcul et d’E/S, conduisant finalement à une inférence accélérée.
Expériences
Références et paramètres : Nous exécutons toutes les expériences KV-Compress en utilisant notre intégration vLLM dérivée de v0.6.2, en mode cuda graph avec une taille de bloc de 16. Pour toutes les expériences avec RTX 4090/Llama-3.1-8B-Instruct, nous utilisons une utilisation par défaut de la mémoire GPU de 0,9 et définissons maxmodel-length à 32k. Nous évaluons notre compression sur Llama-3.1-8B-Instruct, en comparant les performances par rapport aux méthodes de référence suivantes introduites dans des travaux antérieurs :
- vLLM-0.6.2
- Novita AI, compression Pyramid KV Cache basée sur le framework vLLM
MMLU Pro et LongBench : Nous contrôlons différents taux de compression du cache KV en définissant différentes longueurs de fenêtre glissante sur différentes couches. Dans l’expérience, nous avons principalement défini trois longueurs de fenêtre glissante différentes : 1024, 1280 et 1536, et avons effectué des tests croisés sur différents nombres de couches. Test MMLU Pro : Dans le test MMLU Pro, différentes couches de sparsité KV et différentes longueurs de fenêtre glissante montrent des performances différentes. En tenant compte du taux d’accélération, la précision globale peut être garantie supérieure à 98 %.
| vllm-0.6.2 | Novita AI | |
| Couches de sparsité KV | full | sliding window=1536 |
| 22 | 0.4517 | 0.4496 |
| 26 | 0.4517 | 0.4476 |
| 31 | 0.4517 | 0.4476 |
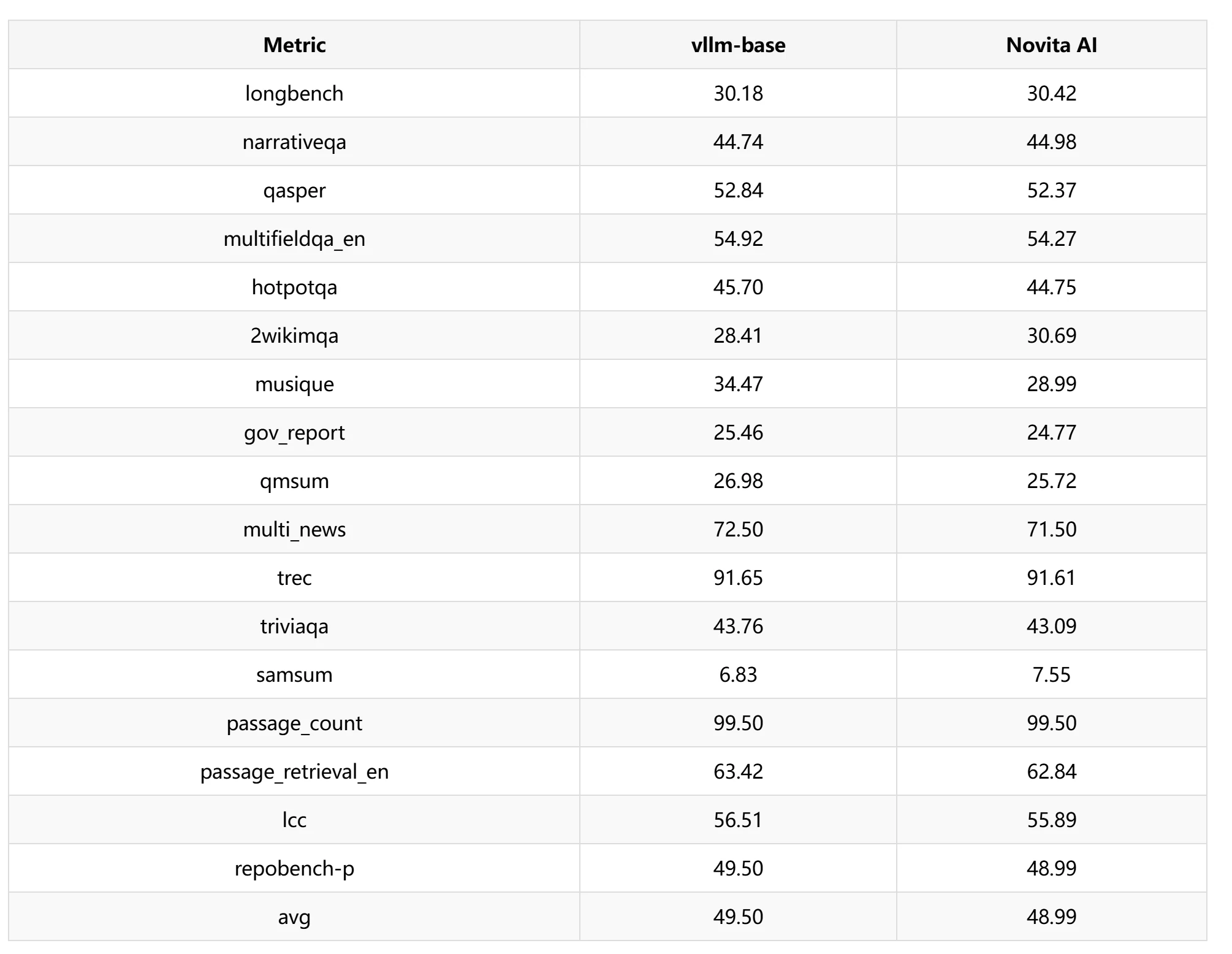
LongBench
Dans le test LongBench, nous avons sélectionné une fenêtre glissante de 1024 pour les tests de performance et avons constaté que la perte de précision était d’environ 1,03 %.
Benchmarks de débit : Dans les applications réelles de LLM, une longueur d’entrée/sortie de 5000/500 est la configuration la plus couramment observée, et l’indice TTFT doit être inférieur à 2 s. Sur la base de ces conditions, nous avons effectué des tests de comparaison de performances par lots, ce qui a donné une accélération de l’inférence de 1,5x pour vLLM.
| Débit | vllm-0.6.2 | Novita AI |
| Couches de sparsité KV | full | sliding window=1536 |
| 22 | 1 | 1.26 |
| 26 | 1 | 1.34 |
| 31 | 1 | 1.44 |
Changements majeurs
Les fichiers modifiés incluent principalement :
- Flash attention, scoring sparse basé sur Flash attention tout en garantissant que la perte de performance du noyau est inférieure à 1 %.
- Paged attention et reshape_and_cache, scoring sparse basé sur Paged attention et synchronisation du scoring sparse dans les étapes de prefill et decode.
- Block_manager et autres fonctions liées à la gestion de la mémoire et à la préparation des tenseurs.
Conclusion
Novita AI prend également en charge le parallélisme tensoriel pour permettre à des modèles tels que Llama3-70B de s’exécuter sur plusieurs GPU. Actuellement, il ne supporte pas le code ouvert pour certaines raisons, mais nous espérons contribuer à la communauté avec quelques technologies et idées, et nous accueillons favorablement les échanges techniques avec tout le monde.Petit avertissement : Les fonctionnalités suivantes ne sont pas encore prises en charge dans vLLM-0.6.2 :
- Chunked-prefill
- Prefix caching
- FlashInfer et autres backends non FlashAttention
- Decoding spéculatif
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA en utilisant notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et le passage à l’échelle.
Lectures recommandées



