

Points clés
- Coûts d’inférence élevés : L’inférence à grande échelle reste coûteuse, limitant la scalabilité malgré la baisse globale des coûts.
- Défis de sélection des GPU : La variété des GPU disponibles complique le processus de sélection, conduisant souvent à des choix sous-optimaux basés sur des métriques superficielles.
- Cadre d’évaluation objectif : Une méthode d’évaluation standardisée permet d’identifier des solutions GPU rentables adaptées aux besoins spécifiques de l’entreprise.
- Métriques de performance : Concentrez-vous sur la latence (Time To First Token) et le débit (Tokens Per Second) pour optimiser l’expérience utilisateur.
- Analyse du rapport coût-efficacité : L’évaluation du coût par million de tokens combinée aux métriques de performance permet de classer clairement les solutions en quadrants efficaces.
- Tests réels : Des tests de modèles populaires (série Llama 3.1) sur des GPU majeurs (H100, A100, RTX 4090) fournissent des informations exploitables.
- Bonnes pratiques : Des recommandations pour sélectionner le matériel d’inférence et optimiser les moteurs améliorent l’efficacité et réduisent les coûts.
- Explorez Novita AI : Pour en savoir plus sur les services d’inférence de grands modèles, visitez Novita AI.
Introduction
Le coût de l’inférence à grande échelle, bien qu’en constante diminution, reste considérablement élevé, la vitesse d’inférence et les coûts d’utilisation limitant fortement la scalabilité des opérations. En tant que fournisseur de services d’inférence de grands modèles, nous investissons continuellement pour améliorer la vitesse d’inférence et réduire les coûts d’inférence.
Nous explorons en profondeur la sélection du matériel d’inférence et l’optimisation des moteurs d’inférence afin de fournir à nos clients les solutions d’inférence les plus rentables. Cet article se concentre sur la présentation des méthodes théoriques et des bonnes pratiques pour choisir le matériel d’inférence, et expose nos conclusions préliminaires.
Il existe une grande variété de GPU disponibles pour l’inférence de grands modèles, ce qui rend difficile la recherche d’un GPU adapté aux exigences spécifiques de l’entreprise. Lors du déploiement des opérations, la multitude de GPU nous laisse souvent perplexes, conduisant à une simple comparaison statique basée sur des métriques comme la puissance de calcul du GPU, la capacité mémoire, la bande passante et le prix. Cette approche consistant à sélectionner un GPU sur la base d’une perception subjective de son attrait peut considérablement induire en erreur et avoir un impact négatif sur les résultats commerciaux.
Nous avons également rencontré ce problème à nos débuts. Cependant, avec la croissance et l’expansion de l’entreprise, nous avons progressivement développé un standard d’évaluation objectif et impartial des GPU ainsi que des méthodes d’évaluation correspondantes. En utilisant cette approche standardisée à travers de nombreuses évaluations, nous pouvons identifier les solutions les plus rentables adaptées à différents besoins commerciaux parmi une multitude de GPU. Associée à des moteurs d’inférence optimisés, nous fournissons finalement à nos clients des services d’inférence de grands modèles à la fois rapides et rentables.
Approche d’évaluation
En termes simples, un « meilleur GPU rentable » doit répondre à deux critères : le prix le plus bas et les performances les plus élevées. Avant de commencer les évaluations, nous définissons précisément ces standards.
Définir le prix le plus bas
Le prix le plus bas n’est pas le coût matériel du GPU ou la location de serveur cloud dans les centres de données, mais le coût du service d’inférence. C’est le prix que nous voyons sur le site officiel pour utiliser l’API du modèle, défini comme le coût par million de tokens consommés (Dollars Per 1M tokens). Une valeur plus faible signifie un prix plus bas.
Comprendre les performances les plus élevées
Les performances les plus élevées font référence à la vitesse d’inférence du grand modèle, où plus c’est élevé, mieux c’est. Il est essentiel de distinguer cela des performances du modèle, qui incluent généralement deux sous-métriques : la latence et le débit.
Métriques de latence et de débit
- Latence : Mesure le Time To First Token (TTFT), le temps qu’un utilisateur attend depuis l’initiation de la requête jusqu’à la réception du premier token.
- Débit : Indique le nombre moyen de tokens reçus par seconde (TPS) à partir du premier token.
Méthodologie d’évaluation
Pour aligner les évaluations sur les besoins métier, nous traitons le système d’inférence comme une boîte noire lors des évaluations, calculant la latence et le débit en fonction des entrées et sorties du système. Le diagramme ci-dessous illustre comment la latence et le débit sont calculés.
Considérations clés
- Une latence plus faible et un débit plus élevé indiquent de meilleures performances d’inférence.
- Le débit est nettement plus crucial que la latence dans les scénarios réels.

Gestion des requêtes
En général, une latence plus faible et un débit plus élevé indiquent de meilleures performances d’inférence. Cependant, dans les scénarios réels, le débit est nettement plus crucial que la latence.
Tant que la latence reste inférieure à 2 secondes, les utilisateurs n’y sont pas très sensibles. Même attendre quelques millisecondes pour voir le premier token n’affecte pas sensiblement l’expérience.
En revanche, les variations de débit ont un impact considérable sur l’expérience utilisateur, rendant les utilisateurs plus enclins à préférer les systèmes avec un débit plus élevé. Par conséquent, lors de l’évaluation des métriques de performance des solutions d’inférence, nous nous concentrons sur la comparaison des différences de débit, tout en maintenant la latence dans une plage acceptable.
Dans les opérations réelles, un système d’inférence traite simultanément plusieurs requêtes utilisateurs pour améliorer la charge globale du système. Cependant, le niveau de concurrence ne doit pas être excessif, car une trop forte concurrence peut en réalité dégrader les performances d’inférence. De plus, la longueur des requêtes utilisateurs et le nombre de tokens retournés influencent également les métriques de performance.
Schémas d’évaluation simplifiés
Pour extraire des schémas de scénarios métier complexes, notre méthode d’évaluation simplifie de manière appropriée tout en restant proche des paramètres métier.
Ratios et longueurs fixes
Nous définissons des ratios et longueurs fixes pour les entrées et sorties des requêtes, par exemple (1000,100), (3000,300), (5000,500), et nous contrôlons précisément les longueurs d’entrée et de sortie lors de l’envoi des requêtes.
Tours de test et calcul des métriques
Après avoir préparé des dizaines de milliers de requêtes, nous envoyons les requêtes au serveur d’inférence par lots de taille fixe pour des tours de test, simulant de nombreux utilisateurs envoyant continuellement des requêtes et maintenant un niveau de concurrence stable dans le système d’inférence.
Métriques de performance
Sur la base des données de chaque tour de test, nous calculons les métriques de latence et de débit pour toutes les requêtes et compilons des statistiques sur différents indicateurs de percentile comme P50, P90, P99 pour refléter des performances plus réalistes.
De plus, nous calculons le débit total de tous les tokens d’entrée et de sortie dans un tour de test, le combinons avec les coûts matériels, et en dérivons le prix par million de tokens pour le système d’inférence.
Analyse du rapport coût-efficacité
En suivant cette approche d’évaluation, nous générons plusieurs ensembles de données de test basés sur différentes longueurs d’entrée-sortie et tailles de lots, les envoyons au service d’inférence, et calculons deux métriques clés : le prix par million de tokens et le taux de tokens de sortie par seconde (TPS) par requête.
Nous traçons ensuite ces métriques sur un graphique avec le prix en abscisse et le TPS en ordonnée. En évaluant davantage de spécifications matérielles avec la même méthode et en traçant les résultats sur le graphique, nous créons une vue d’ensemble du rapport coût-efficacité.
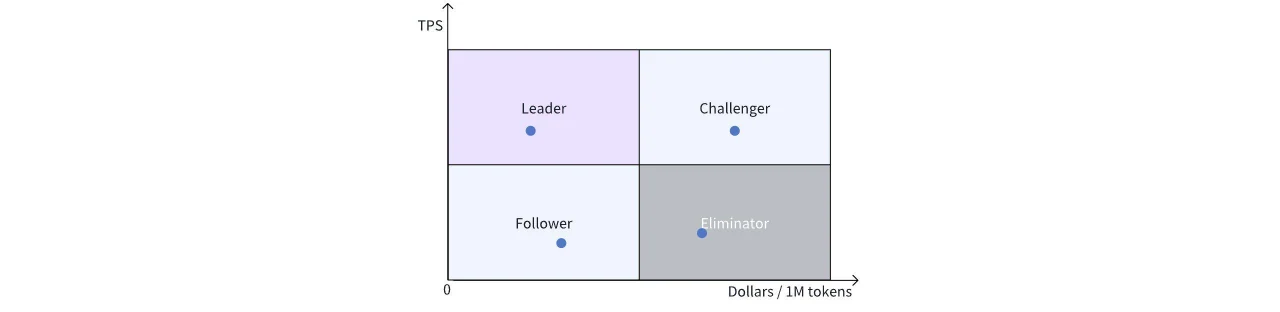
Pour faciliter la comparaison entre différentes solutions, nous divisons le graphique en quatre quadrants :
Haut gauche : Quadrant Leader, avec les performances les plus élevées et le prix le plus bas.
Bas gauche : Quadrant Suiveur, avec un prix attractif mais nécessitant des améliorations de performances.
Haut droit : Quadrant Challenger, leader en performances mais avec un prix plus élevé, pouvant provenir de solutions matérielles de pointe et coûteuses, qui pourraient défier les leaders si les prix baissent.
Bas droit : Solutions obsolètes sans avantages ni en prix ni en performances.
Méthode de mise en œuvre
Notre objectif d’évaluation est d’identifier le matériel GPU le plus rentable. Pour garantir des comparaisons significatives, nous fixerons le modèle, le moteur d’inférence et les données de requête, en ne modifiant que le matériel GPU dans les mêmes conditions de test. Lors de l’évaluation, nous sélectionnerons des modèles open-source, des ensembles de données et des moteurs d’inférence grand public, en utilisant principalement du matériel GPU de la série NVIDIA.
Sélection du modèle
Nous utiliserons les modèles de la série Llama 3.1, en particulier le modèle Llama 3.1–70B (lien Hugging Face). Cette taille de modèle nécessite généralement une inférence multi-GPU, ce qui la rend adaptée pour évaluer les performances de communication inter-GPU.
Moteur d’inférence
Le moteur d’inférence sera vLLM v0.6.3. Pour l’ensemble de données, nous nous concentrerons sur les paires QA, en choisissant ShareGPT-v3-unfiltered comme option la plus appropriée. Lors de la construction des données de requête, nous parcourrons l’ensemble de données ShareGPT, en filtrant les paires QA en fonction de la longueur d’entrée pour ne conserver que celles qui sont égales ou supérieures à une valeur spécifiée, en ne gardant que les questions (avec un écrêtage approprié si trop long) comme prompt de la requête.
Sélection des spécifications GPU
Lors de la sélection des spécifications GPU, nous évaluerons les GPU grand public, en particulier le H100, l’A100 et le RTX 4090, dans les catégories bas de gamme, milieu de gamme et haut de gamme. Une approche courante consiste à louer des serveurs GPU avec une configuration 8 cartes sur des plateformes cloud, comme notre site Web, Novita AI, qui propose des options de paiement à l’usage pratiques. De plus, nous pourrions inclure davantage de spécifications GPU pour élargir le champ de l’évaluation, visant finalement à remplir les quatre quadrants avec une variété de GPU et de stratégies d’inférence.
Lancement de l’évaluation
Une fois les préparations terminées, l’évaluation peut être lancée en suivant ces étapes :
Étape 1 : Démarrer le moteur d’inférence
Pour démarrer le moteur d’inférence vLLM sur votre serveur GPU cible, vous pouvez rapidement créer une instance de conteneur Docker. Pour un serveur GPU 8 cartes 4090, utilisez la commande suivante :
docker run -d --gpus all --net=host vllm/vllm-openai:v0.6.3 --port 8080 --model meta-llama/Llama-3.1-70B-Instruct --tensor-parallel-size 8 --swap-space 16 --gpu-memory-utilization 0.9 --dtype auto --served-model-name llama31-70b --max-num-seqs 32 --max-model-len 32768 --enable-prefix-caching --enable-chunked-prefill --disable-log-requests
Étape 2 : Construire et envoyer les requêtes
Du côté client, construisez les requêtes en fonction des longueurs d’entrée/sortie et des tailles de lots, et envoyez-les en masse au serveur. Nous pouvons également nous référer aux cas de test intégrés fournis par vLLM pour écrire des scripts de test répondant à nos exigences d’évaluation.
Voici les points clés à prendre en compte lors de la construction des requêtes :
- Filtrage des données depuis ShareGPT
Lors du parcours de toutes les entrées de conversation dans l’ensemble de données ShareGPT, notez que le premier élément de chaque conversation est la question et le second élément est la réponse correspondante. Vous n’avez besoin que de la question comme prompt pour vos requêtes.
Pour garantir que le nombre de tokens dans la question répond aux exigences de longueur d’entrée, vous devrez peut-être écrêter la question de manière appropriée. De plus, dans la liste des paramètres de chaque requête, définissez max_tokens sur la longueur de sortie spécifiée et ignore_eos sur true pour forcer le moteur d’inférence à générer le nombre spécifié de tokens.
- Taille de lot constante
Dans chaque tour de test, maintenez toujours la même taille de lot. Pour y parvenir, le client doit envoyer un nombre fixe de requêtes en parallèle et renvoyer immédiatement une requête dès qu’une est terminée. Cela garantit que les conditions de test restent cohérentes et permet des mesures de performance précises.
Les paramètres de chaque requête peuvent être configurés comme suit :
{
"model": "llama31-70b",
"prompt": prompt_content,
"temperature": 0.8,
"top_p": 1.0,
"best_of": 1,
"max_tokens": output_len,
"ignore_eos": true
}
Étape 3 : Collecte des données de métriques
Une fois toutes les requêtes terminées, les métriques clés suivantes doivent être collectées :
- Pour chaque requête : Première latence du token (TTFT) = First_Token_Time — Send_Req_Time
- Pour chaque requête : Tokens par seconde (TPS) = Total_Output_Tokens / (Finish_Req_Time — First_Token_Time)
- Pour un tour de test : Débit total du système = Somme(Input_Tokens_Per_Req + Output_Tokens_Per_Req) / Total_Seconds
Où TTFT et TPS se réfèrent à chaque requête, et pour faciliter les calculs, vous pouvez utiliser le percentile P90 de toutes les requêtes dans un tour de test.
Le débit total du système indique le nombre total de tokens (y compris les tokens d’entrée et de sortie) que le service d’inférence peut traiter par seconde. En divisant le prix du serveur GPU correspondant par le débit total, vous pouvez obtenir le coût par million de tokens.
Dans les scénarios pratiques, l’utilisation du serveur et les fluctuations des requêtes peuvent également affecter le débit, et un facteur peut être appliqué pour tenir compte de ces influences, mais cela n’affecte généralement pas les conclusions de l’évaluation.
Principaux résultats sur les performances des GPU et le rapport coût-efficacité
Nous avons réalisé une évaluation approfondie des principaux GPU (H100, A100, RTX 4090) en utilisant les méthodes de test susmentionnées. Pour chaque GPU, nous avons calculé les métriques de performance (TTFT, TPS) à différentes longueurs d’entrée/sortie et tailles de lots, en dérivant les percentiles P50, P90 et P99. Nous avons également référencé les prix de location des principales plateformes cloud GPU (disponibles sur Novita AI) pour calculer le coût par million de tokens. Ces données serviront de base pour des évaluations ultérieures du rapport coût-performance et nous guideront vers nos conclusions finales d’évaluation.
Comparaison des performances d’inférence unique
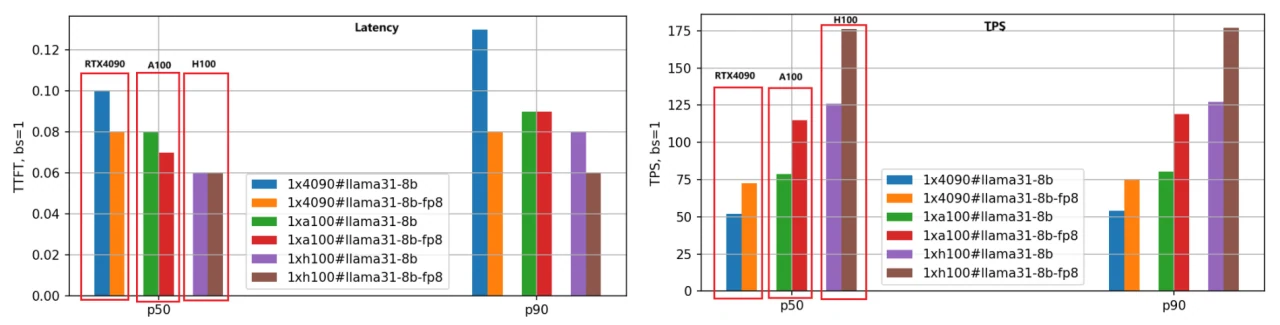
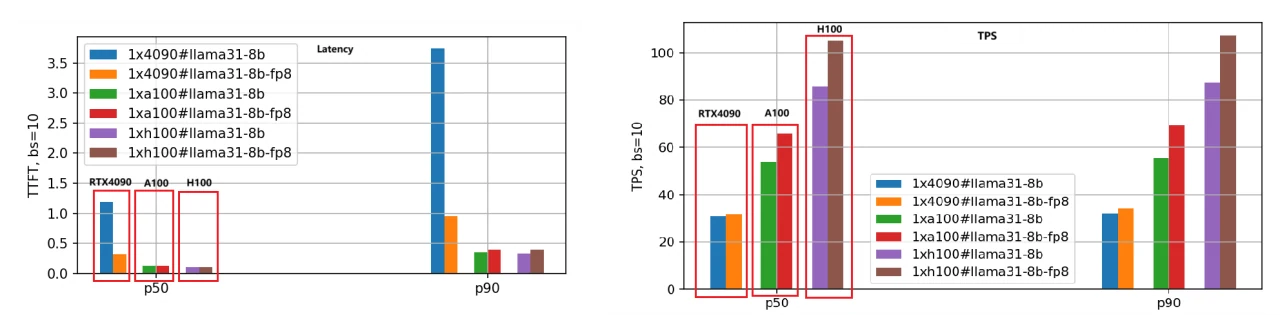
L’accent est mis principalement sur la latence (First Token Latency) et le débit (Tokens Per Second). Une latence plus faible est préférable, tandis qu’un TPS plus élevé est souhaité. Nous avons évalué les versions BF16 et FP8 des modèles Llama-3.1–8B et Llama-3.1–70B sur les trois GPU, en définissant la longueur d’entrée/sortie de chaque requête à 5000/500 et en testant différentes tailles de lots. Voici les résultats de comparaison des performances pour le modèle Llama-3.1–8B, en utilisant les données P50 pour l’analyse.
- Première latence du token :
Le classement de rapidité, du plus rapide au plus lent, est H100, A100, puis RTX 4090. Lorsque la taille de lot est fixée à 1, la vitesse de l’A100 est 1,25 fois celle du RTX 4090, et celle du H100 est 1,66 fois plus rapide.
À mesure que la taille de lot augmente, l’écart entre le RTX 4090 et les deux autres GPU se creuse considérablement. Lorsque la taille de lot atteint 10, la latence du RTX 4090 dépasse 3,5 secondes (percentile P90), ce qui est inacceptable pour de nombreuses applications métier. En revanche, l’A100 et le H100 maintiennent des latences inférieures à 0,5 seconde, montrant des performances stables.
2. Tokens par seconde (TPS) :
Cette métrique reflète la vitesse de génération du moteur, avec le même classement de rapidité : H100, A100, RTX 4090. Avec une taille de lot de 1, le TPS de l’A100 est environ 1,48 fois celui du RTX 4090, et le TPS du H100 est 2,44 fois celui du RTX 4090, indiquant la plus grande efficacité de génération du H100.
À mesure que la taille de lot augmente, le TPS pour les requêtes individuelles diminue progressivement en raison de l’augmentation de la charge du système et de la réduction des ressources par requête. Lorsque la taille de lot est de 10, le TPS chute à environ 70 % du TPS avec une taille de lot de 1.
3. Quantification du modèle FP8 :
La version FP8, avec des fichiers de poids réduits de moitié par rapport à BF16, réduit considérablement la surcharge des ressources système, ce qui améliore la latence et le débit. Le deuxième ensemble de graphiques à barres illustre clairement cette conclusion, en particulier dans la métrique TPS, où les performances de la version FP8 sont environ 1,4 fois supérieures à celles de la version BF16 pour le même GPU.
4. Sensibilité du RTX 4090 à la taille de lot :
En raison des limitations de mémoire et de communication, le RTX 4090 est très sensible à la taille de lot. Des tailles de lot excessivement grandes peuvent entraîner une mise en file d’attente interne, résultant en une latence plus élevée et un débit plus faible. Une attention particulière doit être portée aux réglages de la taille de lot lors du déploiement de charges de travail sur du RTX 4090.
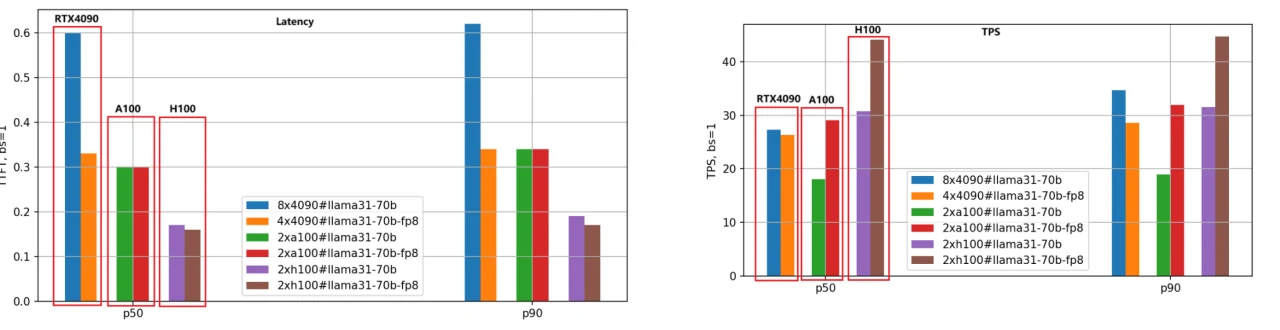
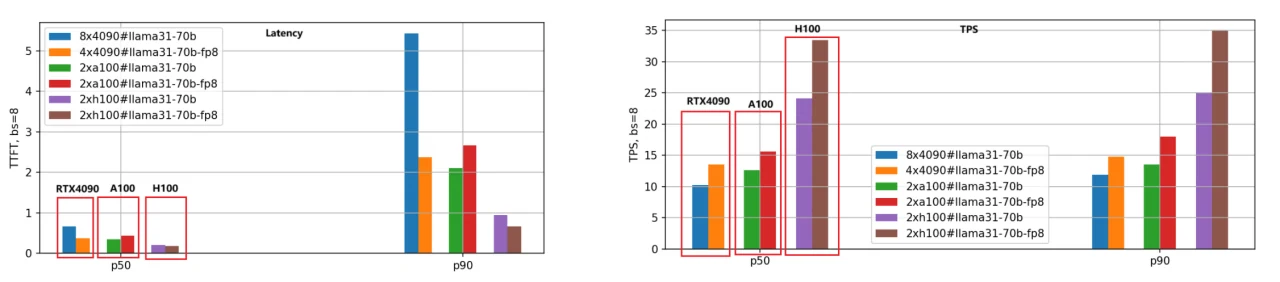
Nous avons appliqué la même méthode d’évaluation au modèle Llama-3.1–70B, et la comparaison des performances est illustrée dans la figure suivante.
Compte tenu de la grande taille du modèle 70B, nous avons utilisé 8 GPU RTX 4090 pour la version BF16 et 4 GPU RTX 4090 pour la version FP8. En revanche, les GPU A100 et H100, avec leurs 80 Go de mémoire, n’ont nécessité que 2 unités pour fonctionner efficacement.
D’après la figure, nous pouvons tirer des conclusions similaires à celles du modèle Llama-3.1–8B : le H100 reste le GPU le plus performant, et la version de quantification FP8 est environ 1,4 fois plus rapide que la version BF16.
Évaluation complète du rapport coût-performance
Dans le déploiement pratique, il est essentiel de considérer non seulement les métriques de performance, mais aussi le coût global des solutions pour identifier le meilleur rapport qualité-prix.
Par exemple, bien que le RTX 4090 puisse être plus lent en termes de performances, son prix très bas pourrait rendre son rapport coût-efficacité global compétitif. Pour y parvenir, nous avons besoin de méthodes d’évaluation plus scientifiques et professionnelles pour déterminer avec précision quel GPU et quelle solution d’inférence offrent le meilleur rapport qualité-prix.
Dans notre « Approche d’évaluation », nous proposons de tracer les coûts et les métriques de performance de différentes solutions d’inférence sur un système de coordonnées bidimensionnel, en divisant l’espace en quatre quadrants : Leaders, Suiveurs, Challengers et Éliminés. En suivant cette approche, nous nous sommes concentrés sur le test des modèles Llama-3.1–70B, Llama-3.1–8B et de leurs versions de quantification FP8.
Nous avons sélectionné quatre GPU : RTX 4090, A100, H100 et H200, en fixant la longueur d’entrée/sortie à 5000/500 et les tailles de lot de 1 à 10. Nous avons testé diverses combinaisons pour obtenir des données de performance et de prix, qui ont finalement été tracées dans les deux figures ci-dessous.
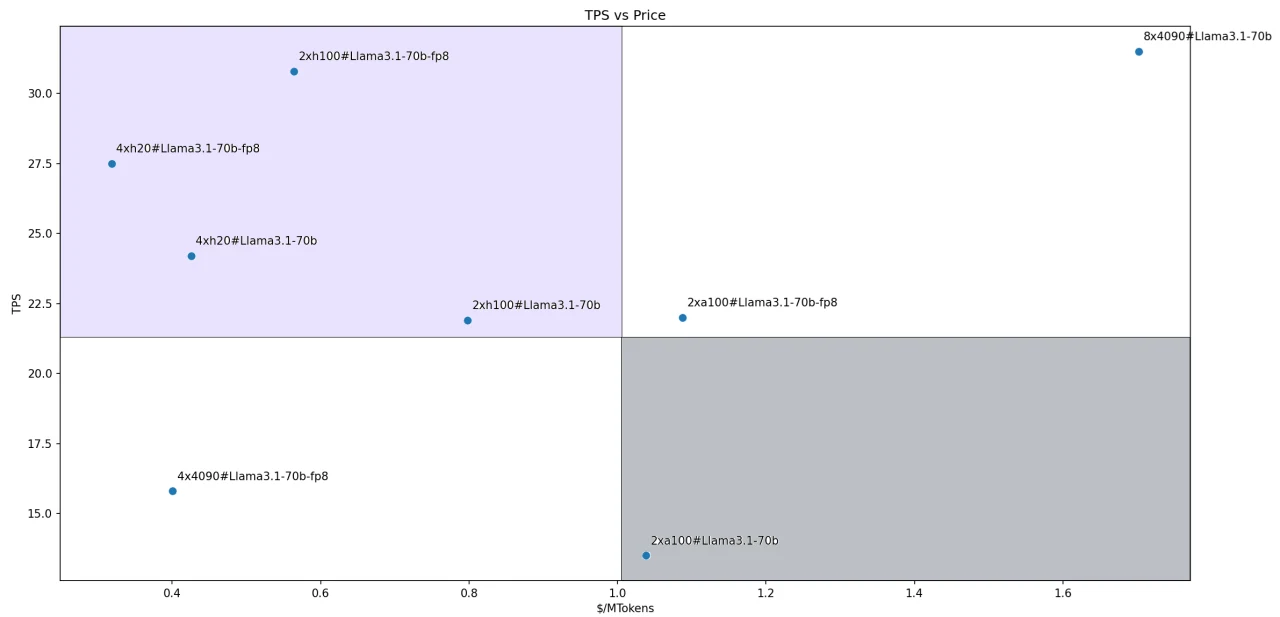
Pour le modèle Llama-3.1–70B, les rapports coût-performance de chaque solution sont illustrés dans la figure. Quatre solutions se trouvent dans notre quadrant Leader défini :
- Llama3.1–70B-FP8@2xH100
- Llama3.1–70B-FP8@4xH200
- Llama3.1–70B@4xH200
- Llama3.1–70B@2xH100
Dans la figure, la pente de la ligne reliant le point de coordonnées de chaque solution à l’origine représente le rapport performance/prix. Une pente plus raide indique un meilleur rapport coût-performance.
Par conséquent, la solution Llama3.1–70B-FP8@4xH200 se démarque comme l’option la plus rentable parmi toutes les solutions d’inférence évaluées.
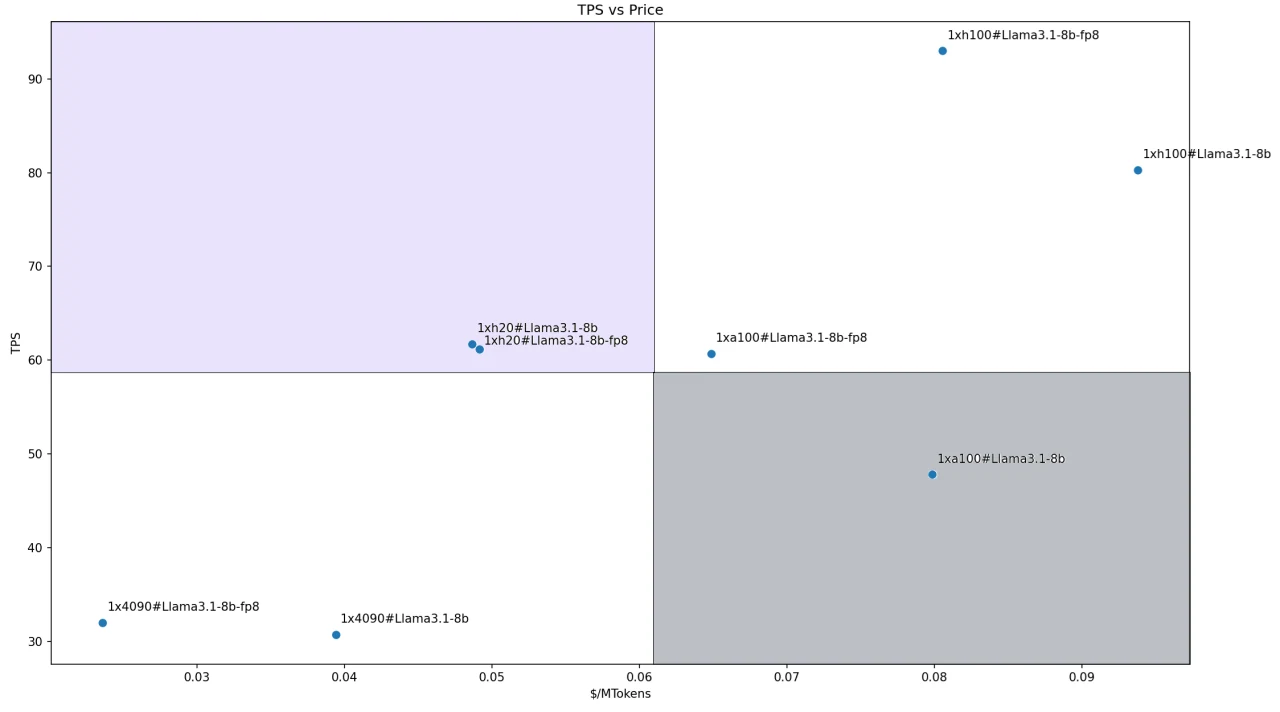
Pour le modèle Llama3.1–8B, en raison de sa taille plus petite, nous avons déployé tous les modèles en utilisant une configuration à un seul GPU. Les rapports coût-performance des différentes solutions sont illustrés dans la figure ci-dessous. Les deux configurations avec H200 se trouvent dans notre quadrant Leader défini.
Cela est principalement dû aux bonnes performances du H200 (notamment sa capacité mémoire et sa bande passante de pointe) et à son prix compétitif. Les deux configurations RTX 4090 sont les plus rentables, mais en raison de leurs performances inférieures, elles se trouvent dans le quadrant Suiveur.
Conclusion
Les coûts des GPU représentent une part importante des services d’inférence de grands modèles, et avec la multitude d’options matérielles GPU disponibles sur le marché, choisir le plus adapté peut être difficile. Identifier le meilleur GPU et la meilleure solution d’inférence en termes de rapport coût-performance, adaptés aux besoins spécifiques de l’entreprise, est crucial car cela peut déterminer le succès ou l’échec de l’activité.
Grâce à notre expérience dans la fourniture de services d’inférence de grands modèles, nous avons accumulé une connaissance substantielle du déploiement et développé un cadre efficace d’évaluation des GPU qui guide en continu le développement de l’entreprise, offrant aux clients les services d’inférence au meilleur rapport qualité-prix.
Cet article distille les bonnes pratiques issues d’applications pratiques et effectue des tests réels sur des modèles grand public et des spécifications GPU, fournissant des comparaisons de performances pour identifier les meilleures solutions d’inférence rentables.
Notre approche d’évaluation transcende les métriques matérielles complexes, se concentrant sur les applications métier pratiques, ce qui la rend hautement généralisable et actionnable — particulièrement adaptée aux tests comparatifs entre différents modèles de GPU ou moteurs d’inférence.
Consultez Novita AI pour plus d’informations sur les services et solutions d’inférence de grands modèles de premier ordre !
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Lectures recommandées
1.Comment la parcimonie KV atteint une accélération de 1,5x pour vLLM
2.Allocation dynamique de ressources GPU pour les charges de travail Kubernetes
3.Ajout dynamique de mappages de ports aux conteneurs Docker en cours d’exécution


