

Wichtige Erkenntnisse
- Hohe Inferenzkosten: Die Inferenz großer Modelle bleibt teuer und schränkt die Skalierbarkeit trotz sinkender Gesamtkosten ein.
- Herausforderungen bei der GPU-Auswahl: Die Vielzahl verfügbarer GPUs erschwert den Auswahlprozess und führt oft zu suboptimalen Entscheidungen basierend auf oberflächlichen Metriken.
- Objektiver Bewertungsrahmen: Eine standardisierte Bewertungsmethode hilft, kosteneffiziente GPU-Lösungen zu identifizieren, die auf spezifische Geschäftsanforderungen zugeschnitten sind.
- Leistungskennzahlen: Konzentrieren Sie sich auf Latenz (Time To First Token) und Durchsatz (Tokens Per Second), um die Benutzererfahrung zu optimieren.
- Kosteneffizienzanalyse: Die Bewertung der Kosten pro Million Tokens zusammen mit Leistungskennzahlen ermöglicht eine klare Kategorisierung von Lösungen in effektive Quadranten.
- Praxistests: Tests gängiger Modelle (Llama 3.1-Serie) auf wichtigen GPUs (H100, A100, RTX 4090) liefern umsetzbare Erkenntnisse.
- Best Practices: Empfehlungen zur Auswahl von Inferenzhardware und zur Optimierung von Engines steigern die Effizienz und senken die Kosten.
- Novita AI entdecken: Für weitere Informationen zu großen Modell-Inferenzdiensten besuchen Sie Novita AI.
Einleitung
Die Kosten für die Inferenz großer Modelle sinken zwar kontinuierlich, bleiben aber dennoch beträchtlich. Dabei schränken die Inferenzgeschwindigkeit und die Nutzungskosten die Skalierbarkeit des Betriebs stark ein. Als Anbieter von Inferenzdiensten für große Modelle investieren wir kontinuierlich in die Verbesserung der Inferenzgeschwindigkeit und die Senkung der Inferenzkosten.
Wir untersuchen eingehend die Auswahl von Inferenzhardware und die Optimierung von Inferenzengines, um unseren Kunden die kosteneffizientesten Inferenzlösungen zu bieten. Dieser Artikel konzentriert sich auf die Einführung der theoretischen Methoden und Best Practices für die Auswahl von Inferenzhardware und präsentiert unsere vorläufigen Schlussfolgerungen.
Für die Inferenz großer Modelle steht eine breite Palette von GPUs zur Verfügung, was die Auswahl einer geeigneten GPU für die spezifischen Geschäftsanforderungen erschwert. Bei der Bereitstellung des Betriebs sind wir oft von der Vielzahl der GPUs überfordert, was zu einem statischen Vergleich führt, der lediglich auf Metriken wie GPU-Rechenleistung, Speicherkapazität, Bandbreite und Preis basiert. Dieser Ansatz, eine GPU aufgrund eines subjektiven Eindrucks auszuwählen, kann erheblich in die Irre führen und negative Auswirkungen auf das Geschäft haben.
Auch wir sind in der Anfangsphase auf dieses Problem gestoßen. Mit dem Wachstum und der Expansion des Geschäfts haben wir jedoch nach und nach einen objektiven und unparteiischen GPU-Bewertungsstandard sowie entsprechende Bewertungsmethoden entwickelt. Durch die Anwendung dieses standardisierten Ansatzes in zahlreichen Bewertungen können wir aus einer Vielzahl von GPUs die kosteneffizientesten Lösungen für unterschiedliche Geschäftsanforderungen identifizieren. In Kombination mit optimierten Inferenzengines bieten wir unseren Kunden letztendlich schnelle und kosteneffiziente Inferenzdienste für große Modelle.
Bewertungsansatz
Einfach ausgedrückt muss eine „kosteneffizienteste GPU“ zwei Kriterien erfüllen: niedrigster Preis und höchste Leistung. Bevor wir mit den Bewertungen beginnen, definieren wir diese Standards genau.
Niedrigsten Preis definieren
Der niedrigste Preis sind nicht die GPU-Hardwarekosten oder die Miete von Cloud-Servern in Rechenzentren, sondern die Kosten des Inferenzdienstes. Es ist der Preis, den wir auf der offiziellen Website für die Nutzung der Modell-API sehen, definiert als Kosten pro Million verbrauchter Tokens (Dollars Per 1M tokens). Ein niedrigerer Wert bedeutet einen niedrigeren Preis.
Höchste Leistung verstehen
Die höchste Leistung bezieht sich auf die Geschwindigkeit der großen Modellinferenz, wobei höhere Werte besser sind. Es ist wichtig, dies von der Modellleistung zu unterscheiden, die typischerweise zwei Untermetriken umfasst: Latenz und Durchsatz.
Latenz- und Durchsatzmetriken
- Latenz: Misst die Time To First Token (TTFT), die Zeit, die ein Benutzer vom Initiieren einer Anfrage bis zum Erhalt des ersten Tokens wartet.
- Durchsatz: Gibt die durchschnittliche Anzahl der pro Sekunde empfangenen Tokens (TPS) ab dem ersten Token an.
Bewertungsmethodik
Um die Bewertungen an die Geschäftsanforderungen anzupassen, behandeln wir das Inferenzsystem während der Bewertungen als Blackbox und berechnen Latenz und Durchsatz basierend auf den Systemeingaben und -ausgaben. Das folgende Diagramm zeigt, wie Latenz und Durchsatz berechnet werden.
Wichtige Überlegungen
- Niedrigere Latenz und höherer Durchsatz deuten auf eine bessere Inferenzleistung hin.
- In realen Szenarien ist der Durchsatz wesentlich wichtiger als die Latenz.

Anfragenverwaltung
Im Allgemeinen bedeuten niedrigere Latenz und höherer Durchsatz eine bessere Inferenzleistung. In realen Szenarien ist der Durchsatz jedoch wesentlich wichtiger als die Latenz.
Solange die Latenz unter 2 Sekunden bleibt, sind Benutzer nicht sehr empfindlich darauf. Selbst ein Warten von einigen Millisekunden, um das erste Token zu sehen, wird die Erfahrung nicht merklich beeinträchtigen.
Andererseits wirken sich Änderungen des Durchsatzes stark auf die Benutzererfahrung aus, sodass Benutzer Systeme mit höherem Durchsatz bevorzugen. Daher konzentrieren wir uns bei der Bewertung der Leistungsmetriken von Inferenzlösungen auf den Vergleich der Durchsatzunterschiede, während die Latenz innerhalb eines akzeptablen Bereichs gehalten wird.
Im realen Betrieb verarbeitet ein Inferenzsystem gleichzeitig mehrere Benutzeranfragen, um die Gesamtsystemlast zu erhöhen. Der Parallelitätsgrad sollte jedoch nicht übermäßig hoch sein, da eine zu hohe Parallelität die Inferenzleistung tatsächlich verschlechtern kann. Darüber hinaus beeinflussen die Länge der Benutzeranfragen und die Anzahl der zurückgegebenen Tokens die Leistungsmetriken.
Vereinfachte Bewertungsmuster
Um aus komplexen Geschäftsszenarien Muster zu extrahieren, vereinfacht unsere Bewertungsmethode angemessen, während sie eng an den Geschäftseinstellungen bleibt.
Feste Verhältnisse und Längen
Wir legen feste Verhältnisse und Längen für Anfrageeingaben und -ausgaben fest, z. B. (1000,100), (3000,300), (5000,500), und steuern die Eingabe- und Ausgabelängen beim Senden von Anfragen genau.
Testdurchläufe und Metrikenberechnung
Nach der Vorbereitung von Zehntausenden von Anfragen senden wir die Anfragen in festen Batch-Größen für Testdurchläufe an den Inferenzserver, simulieren zahlreiche Benutzer, die kontinuierlich Anfragen senden, und halten ein stabiles Parallelitätsniveau im Inferenzsystem aufrecht.
Leistungsmetriken
Basierend auf den Daten jedes Testdurchlaufs berechnen wir Latenz- und Durchsatzmetriken für alle Anfragen und erstellen Statistiken zu verschiedenen Perzentilindikatoren wie P50, P90, P99, um eine realistischere Leistung widerzuspiegeln.
Zusätzlich berechnen wir den Gesamtdurchsatz aller Eingabe- und Ausgabetokens in einem Testdurchlauf, kombinieren ihn mit den Hardwarekosten und leiten den Preis pro Million Tokens für das Inferenzsystem ab.
Kosteneffizienzanalyse
Nach diesem Bewertungsansatz generieren wir mehrere Datensätze basierend auf unterschiedlichen Eingabe-/Ausgabelängen und Batch-Größen, senden sie an den Inferenzdienst und berechnen zwei Schlüsselmetriken: den Preis pro Million Tokens und die Ausgabetokenrate pro Sekunde (TPS) pro Anfrage.
Wir zeichnen diese Metriken dann in einem Diagramm mit dem Preis auf der x-Achse und TPS auf der y-Achse auf. Durch die Bewertung weiterer Hardwarespezifikationen mit derselben Methode und das Einzeichnen der Ergebnisse in das Diagramm erstellen wir einen Überblick über die Kosteneffizienz.
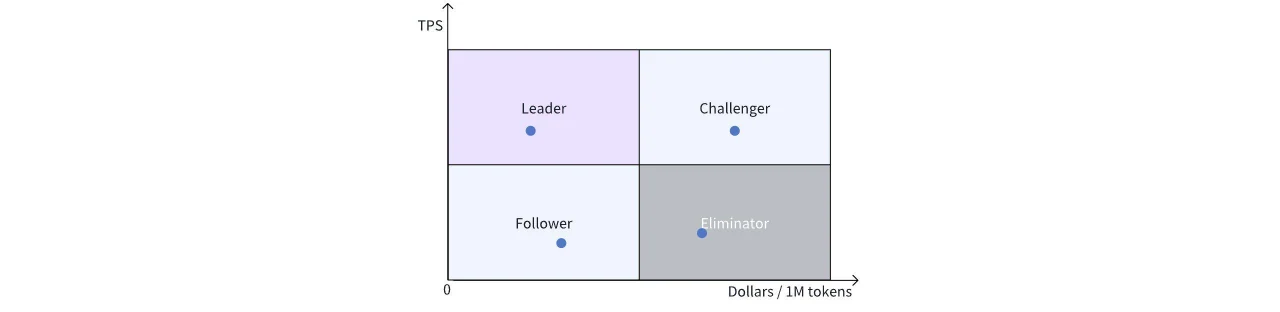
Um den Vergleich zwischen verschiedenen Lösungen zu erleichtern, teilen wir das Diagramm in vier Quadranten auf:
Oben links: Leader-Quadrant, mit der höchsten Leistung und dem niedrigsten Preis.
Unten links: Follower-Quadrant, mit attraktivem Preis, aber Verbesserungsbedarf bei der Leistung.
Oben rechts: Herausforderer-Quadrant, führend in der Leistung, aber mit einem höheren Preis, möglicherweise von hochmodernen und teuren Hardwarelösungen, die die Leader herausfordern könnten, wenn die Preise sinken.
Unten rechts: Veraltete Lösungen, denen es sowohl an Preis- als auch Leistungsvorteilen mangelt.
Implementierungsmethode
Unser Bewertungsziel ist es, die kosteneffizienteste GPU-Hardware zu identifizieren. Um aussagekräftige Vergleiche zu gewährleisten, fixieren wir das Modell, den Inferenzengine und die Anfragedaten und ändern nur die GPU-Hardware unter denselben Testbedingungen. Während der Bewertung wählen wir gängige Open-Source-Modelle, Datensätze und Inferenzengines aus und verwenden hauptsächlich NVIDIA-GPU-Hardware.
Modellauswahl
Wir verwenden die Llama 3.1-Serienmodelle, insbesondere das Llama 3.1–70B-Modell (Hugging Face Link). Diese Modellgröße erfordert typischerweise Multi-GPU-Inferenz, wodurch es sich zur Bewertung der Inter-GPU-Kommunikationsleistung eignet.
Inferenzengine
Der Inferenzengine ist vLLM v0.6.3. Für den Datensatz konzentrieren wir uns auf QA-Paare und wählen ShareGPT-v3-unfiltered als am besten geeignete Option. Beim Erstellen von Anfragedaten durchlaufen wir den ShareGPT-Datensatz, filtern QA-Paare basierend auf der Eingabelänge, um nur solche zu behalten, die einen bestimmten Wert erreichen oder überschreiten, und behalten nur die Fragen (bei Bedarf entsprechend kürzen) als Anfrage-Prompt.
Auswahl der GPU-Spezifikationen
Bei der Auswahl der GPU-Spezifikationen bewerten wir gängige GPUs, insbesondere die H100, A100 und RTX 4090, über Low-, Mid- und High-End-Kategorien hinweg. Ein üblicher Ansatz ist es, GPU-Server mit einer 8-Karten-Konfiguration auf Cloud-Plattformen zu mieten, wie z. B. auf unserer Website Novita AI, die bequeme Pay-as-you-go-Optionen bietet. Darüber hinaus können wir weitere GPU-Spezifikationen einbeziehen, um den Bewertungsumfang zu erweitern, mit dem Ziel, die vier Quadranten mit einer Vielzahl von GPUs und Inferenzstrategien zu füllen.
Starten der Bewertung
Sobald die Vorbereitungen abgeschlossen sind, kann die Bewertung durch Befolgen dieser Schritte gestartet werden:
Schritt 1: Inferenzengine starten
Um den vLLM-Inferenzengine auf Ihrem Ziel-GPU-Server zu starten, können Sie schnell eine Docker-Container-Instanz erstellen. Für einen 8-Karten-4090-GPU-Server verwenden Sie den folgenden Befehl:
docker run -d --gpus all --net=host vllm/vllm-openai:v0.6.3 --port 8080 --model meta-llama/Llama-3.1-70B-Instruct --tensor-parallel-size 8 --swap-space 16 --gpu-memory-utilization 0.9 --dtype auto --served-model-name llama31-70b --max-num-seqs 32 --max-model-len 32768 --enable-prefix-caching --enable-chunked-prefill --disable-log-requests
Schritt 2: Anfragen erstellen und senden
Erstellen Sie auf der Client-Seite Anfragen basierend auf Eingabe-/Ausgabelängen und Batch-Größen und senden Sie sie in großen Mengen an den Server. Wir können auch auf die integrierten Testfälle von vLLM zurückgreifen, um Testskripte zu schreiben, die unseren Bewertungsanforderungen entsprechen.
Hier sind wichtige Punkte, die beim Erstellen von Anfragen zu beachten sind:
- Datenfilterung aus ShareGPT
Beim Durchlaufen aller Gesprächseinträge im ShareGPT-Datensatz ist zu beachten, dass das erste Element jedes Gesprächs die Frage und das zweite Element die entsprechende Antwort ist. Sie benötigen nur die Frage als Prompt für Ihre Anfragen.
Um sicherzustellen, dass die Anzahl der Tokens in der Frage den Eingabelängenanforderungen entspricht, müssen Sie die Frage möglicherweise entsprechend kürzen. Setzen Sie außerdem in der Parameterliste für jede Anfrage max_tokens auf die angegebene Ausgabelänge und ignore_eos auf true, um den Inferenzengine zu zwingen, die angegebene Anzahl von Tokens auszugeben.
- Konsistente Batch-Größe
Halten Sie in jedem Testdurchlauf stets dieselbe Batch-Größe ein. Um dies zu erreichen, sollte der Client eine feste Anzahl von Anfragen parallel senden und sofort eine neue Anfrage senden, sobald eine abgeschlossen ist. Dadurch wird sichergestellt, dass die Testbedingungen konsistent bleiben und genaue Leistungsmessungen ermöglicht werden.
Die Parameter jeder Anfrage können wie folgt konfiguriert werden:
{
"model": "llama31-70b",
"prompt": prompt_content,
"temperature": 0.8,
"top_p": 1.0,
"best_of": 1,
"max_tokens": output_len,
"ignore_eos": true
}
Schritt 3: Erfassen von Metrikdaten
Nachdem alle Anfragen abgeschlossen sind, sollten die folgenden Schlüsselmetriken erfasst werden:
- Für jede Anfrage: First Token Latency (TTFT) = First_Token_Time — Send_Req_Time
- Für jede Anfrage: Tokens Per Second (TPS) = Total_Output_Tokens / (Finish_Req_Time — First_Token_Time)
- Für einen Testdurchlauf: Gesamtsystemdurchsatz = Sum(Input_Tokens_Per_Req + Output_Tokens_Per_Req) / Total_Seconds
Dabei beziehen sich TTFT und TPS auf jede Anfrage, und der Einfachheit halber können Sie das P90-Perzentil aller Anfragen in einem Testdurchlauf verwenden.
Der Gesamtsystemdurchsatz gibt die Gesamtzahl der Tokens (einschließlich Eingabe- und Ausgabetokens) an, die der Inferenzdienst pro Sekunde verarbeiten kann. Durch Teilen des Preises des entsprechenden GPU-Servers durch den Gesamtdurchsatz erhalten Sie die Kosten pro Million Tokens.
In der Praxis können sich die Serverauslastung und Anforderungsschwankungen ebenfalls auf den Durchsatz auswirken. Ein Faktor kann angewendet werden, um diese Einflüsse zu berücksichtigen, was die Bewertungsergebnisse jedoch in der Regel nicht beeinflusst.
Wichtige Erkenntnisse zur GPU-Leistung und Kosteneffizienz
Wir haben eine eingehende Bewertung der wichtigsten GPUs (H100, A100, RTX 4090) unter Verwendung der oben genannten Testmethoden durchgeführt. Für jede GPU haben wir Leistungskennzahlen (TTFT, TPS) bei verschiedenen Eingabe-/Ausgabelängen und Batch-Größen sowie die P50-, P90- und P99-Perzentile berechnet. Wir haben auch die Mietpreise gängiger GPU-Cloud-Plattformen (verfügbar unter Novita AI) herangezogen, um die Kosten pro Million Tokens zu berechnen. Diese Daten dienen als Grundlage für weitere Kosten-Leistungs-Bewertungen und führen uns zu unseren endgültigen Bewertungsschlussfolgerungen.
Einzelinferenz-Leistungsvergleich
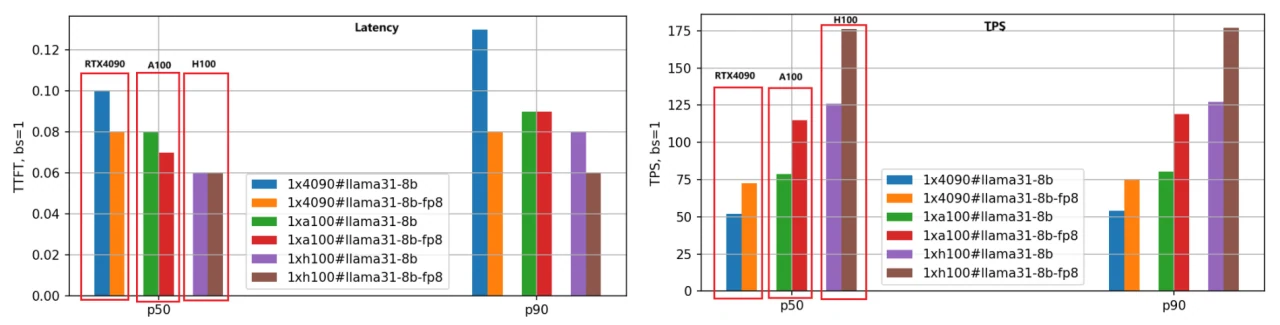
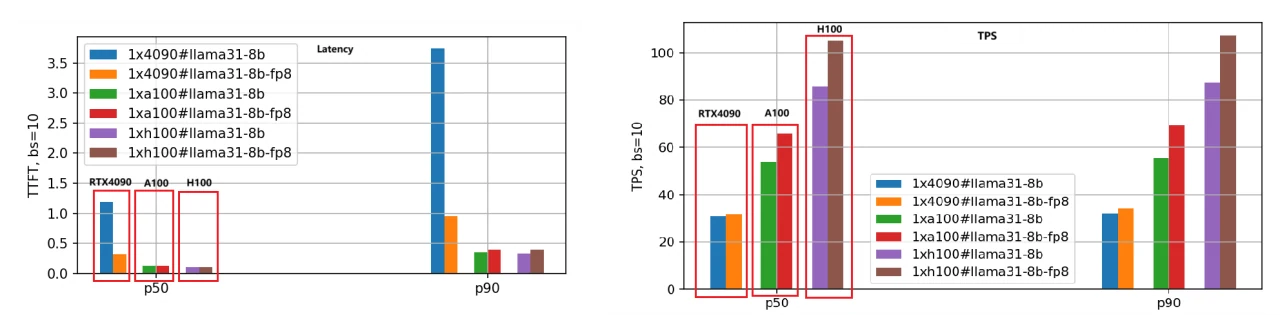
Der primäre Fokus liegt auf Latenz (First Token Latency) und Durchsatz (Tokens Per Second). Eine niedrigere Latenz ist bevorzugt, während ein höherer TPS gewünscht wird. Wir haben sowohl die BF16- als auch die FP8-Versionen der Modelle Llama-3.1–8B und Llama-3.1–70B auf den drei GPUs bewertet, die Eingabe-/Ausgabelänge jeder Anfrage auf 5000/500 gesetzt und verschiedene Batch-Größen getestet. Nachfolgend sind die Leistungsvergleichsergebnisse für das Llama-3.1–8B-Modell unter Verwendung der P50-Daten für die Analyse aufgeführt.
- First Token Latency:
Die Geschwindigkeitsrangfolge von schnell nach langsam ist H100, A100 und RTX 4090. Bei einer Batch-Größe von 1 ist die Geschwindigkeit der A100 1,25-mal so hoch wie die der RTX 4090, und die H100 ist 1,66-mal schneller.
Mit zunehmender Batch-Größe vergrößert sich der Abstand zwischen der RTX 4090 und den anderen beiden GPUs deutlich. Bei einer Batch-Größe von 10 überschreitet die Latenz der RTX 4090 3,5 Sekunden (P90-Perzentil), was für viele Geschäftsanwendungen inakzeptabel ist. Im Gegensatz dazu bleiben die Latenzen von A100 und H100 unter 0,5 Sekunden und zeigen eine stabile Leistung.
2. Tokens Per Second (TPS):
Diese Metrik spiegelt die Generierungsgeschwindigkeit des Engines wider, mit derselben Geschwindigkeitsrangfolge: H100, A100, RTX 4090. Bei einer Batch-Größe von 1 beträgt der TPS der A100 etwa das 1,48-Fache des TPS der RTX 4090, und der TPS der H100 beträgt das 2,44-Fache des TPS der RTX 4090, was auf die höchste Generierungseffizienz der H100 hinweist.
Mit zunehmender Batch-Größe sinkt der TPS für einzelne Anfragen allmählich aufgrund der erhöhten Systemlast und der reduzierten Ressourcen pro Anfrage. Bei einer Batch-Größe von 10 sinkt der TPS auf etwa 70 % des TPS bei Batch-Größe 1.
3. FP8-Modellquantisierung:
Die FP8-Version, deren Gewichtsdateien im Vergleich zu BF16 halbiert sind, reduziert den Systemressourcen-Overhead erheblich, was zu verbesserter Latenz und Durchsatz führt. Das zweite Balkendiagramm veranschaulicht diese Schlussfolgerung deutlich, insbesondere bei der TPS-Metrik, bei der die Leistung der FP8-Version etwa das 1,4-Fache der BF16-Version für dieselbe GPU beträgt.
4. Empfindlichkeit der RTX 4090 gegenüber der Batch-Größe:
Aufgrund von Speicher- und Kommunikationseinschränkungen ist die RTX 4090 sehr empfindlich gegenüber der Batch-Größe. Übermäßig große Batch-Größen können zu internen Warteschlangen führen, was zu höherer Latenz und geringerem Durchsatz führt. Bei der Bereitstellung von Arbeitslasten auf der RTX 4090 muss besonders auf die Einstellung der Batch-Größe geachtet werden.
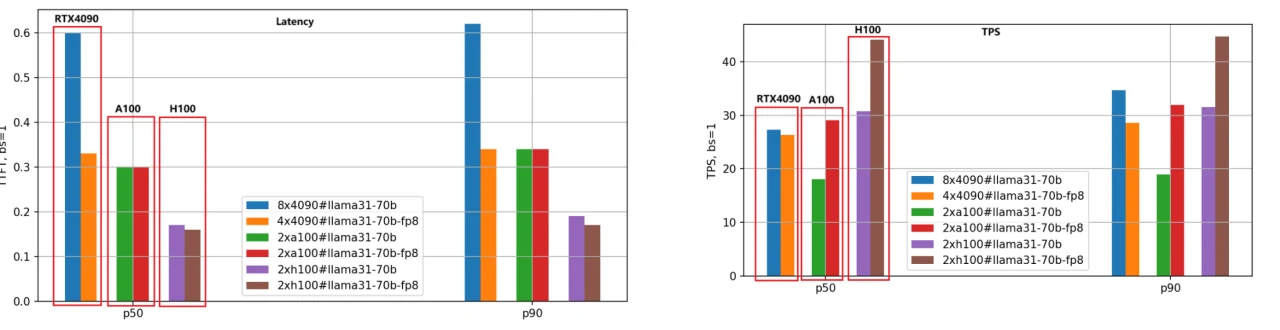
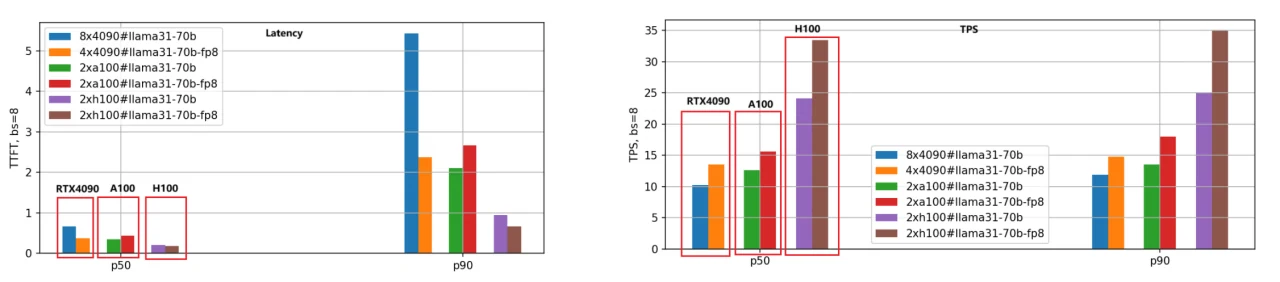
Wir haben dieselbe Bewertungsmethode für das Llama-3.1–70B-Modell angewendet, und der Leistungsvergleich ist in der folgenden Abbildung dargestellt.
Aufgrund der Größe des 70B-Modells haben wir 8 RTX 4090 GPUs für die BF16-Version und 4 RTX 4090 GPUs für die FP8-Version verwendet. Im Gegensatz dazu benötigten die GPUs A100 und H100 mit 80 GB Speicher nur 2 Einheiten für einen effektiven Betrieb.
Aus der Abbildung können wir ähnliche Schlussfolgerungen wie für das Llama-3.1–8B-Modell ziehen: Die H100 bleibt die leistungsstärkste GPU, und die FP8-Quantisierungsversion ist etwa 1,4-mal schneller als die BF16-Version.
Umfassende Kosten-Leistungs-Bewertung
Im praktischen Einsatz ist es wichtig, nicht nur Leistungskennzahlen, sondern auch die Gesamtkosten der Lösungen zu berücksichtigen, um das beste Preis-Leistungs-Verhältnis zu ermitteln.
Beispielsweise mag die RTX 4090 in Bezug auf die Leistung langsamer sein, aber ihr sehr niedriger Preis könnte ihre Gesamtkosteneffizienz wettbewerbsfähig machen. Um dies zu erreichen, benötigen wir wissenschaftlichere und professionellere Bewertungsmethoden, um genau zu bestimmen, welche GPU und Inferenzlösung den besten Wert bieten.
In unserem „Bewertungsansatz“ schlagen wir vor, die Kosten und Leistungskennzahlen verschiedener Inferenzlösungen in einem zweidimensionalen Koordinatensystem aufzutragen und den Raum in vier Quadranten zu unterteilen: Leader, Follower, Herausforderer und Eliminatoren. Nach diesem Ansatz haben wir uns auf die Tests der Modelle Llama-3.1–70B, Llama-3.1–8B und ihrer FP8-Quantisierungsversionen konzentriert.
Wir haben vier GPUs ausgewählt: RTX 4090, A100, H100 und H200, die Eingabe-/Ausgabelänge auf 5000/500 und Batch-Größen von 1 bis 10 gesetzt. Wir haben verschiedene Kombinationen getestet, um Leistungs- und Preisdaten zu erhalten, die schließlich in den beiden folgenden Abbildungen aufgetragen wurden.
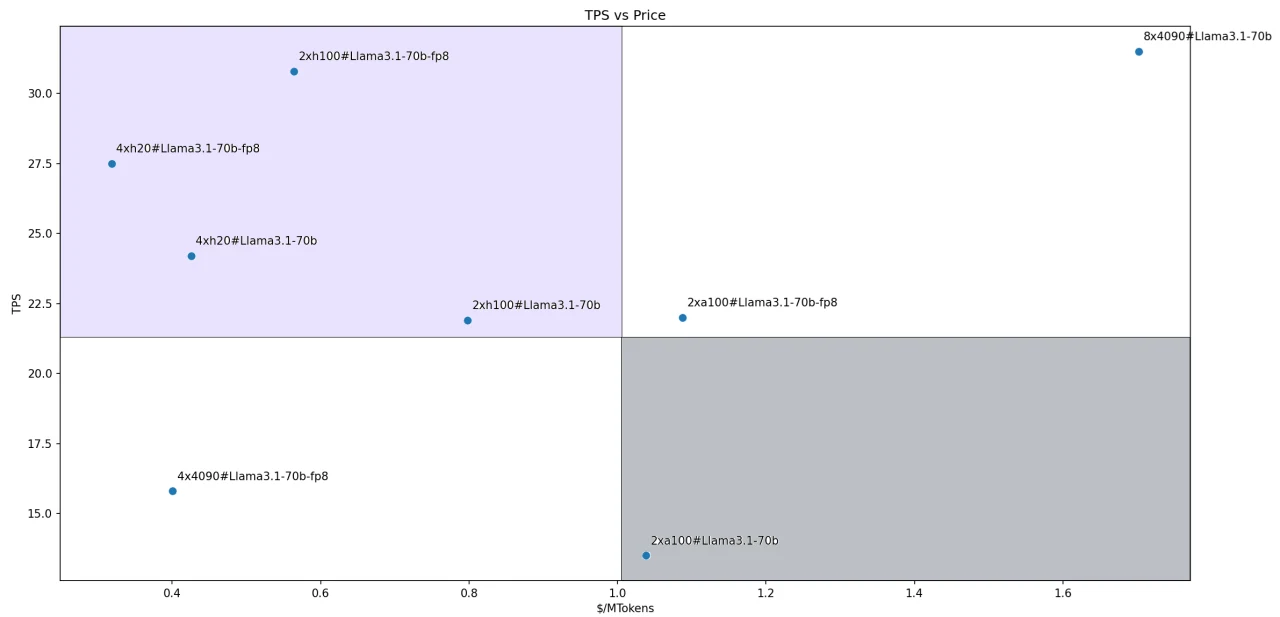
Für das Llama-3.1–70B-Modell sind die Kosten-Leistungs-Verhältnisse jeder Lösung in der Abbildung dargestellt. Vier Lösungen fallen in unseren definierten Leader-Quadranten:
- Llama3.1–70B-FP8@2xH100
- Llama3.1–70B-FP8@4xH200
- Llama3.1–70B@4xH200
- Llama3.1–70B@2xH100
In der Abbildung repräsentiert die Steigung der Linie, die den Koordinatenpunkt jeder Lösung mit dem Ursprung verbindet, das Verhältnis von Leistung zu Preis. Eine steilere Steigung zeigt ein höheres Kosten-Leistungs-Verhältnis an.
Daher sticht die Lösung Llama3.1–70B-FP8@4xH200 als die kosteneffizienteste Option unter allen bewerteten Inferenzlösungen hervor.
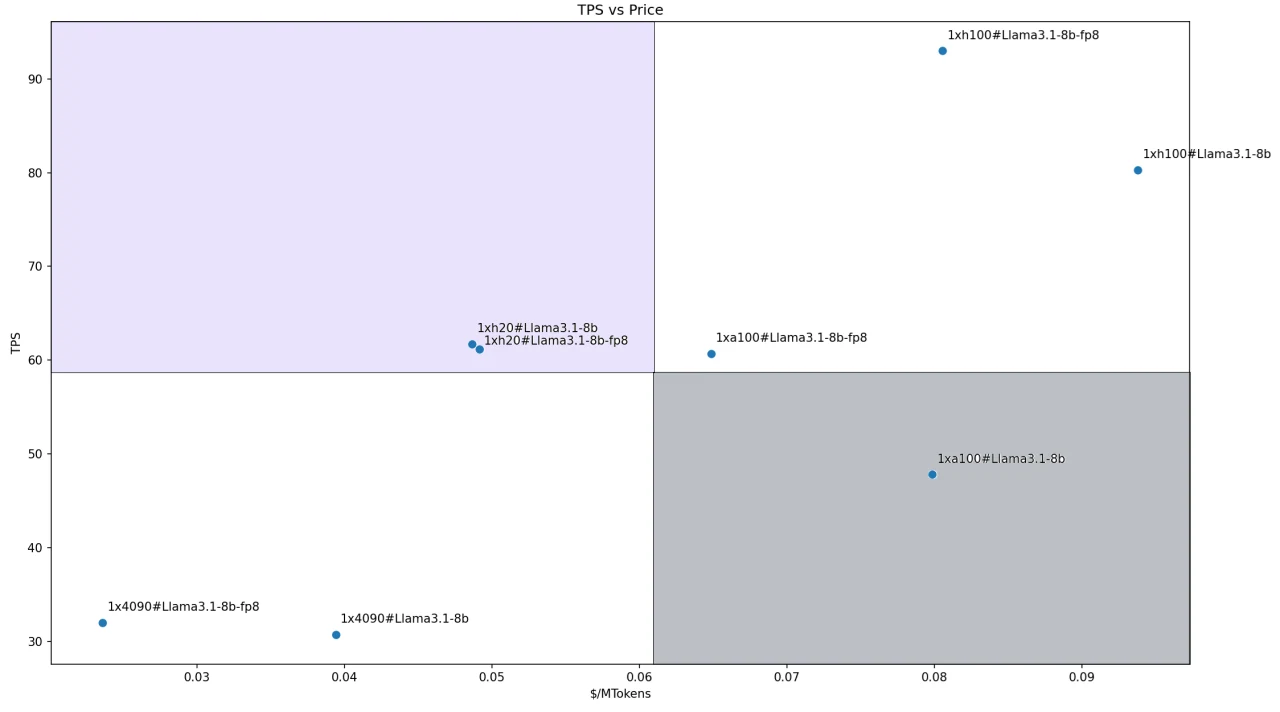
Für das Llama3.1–8B-Modell haben wir aufgrund seiner geringeren Größe alle Modelle mit einer einzelnen GPU-Konfiguration bereitgestellt. Die Kosten-Leistungs-Verhältnisse der verschiedenen Lösungen sind in der folgenden Abbildung dargestellt. Beide Konfigurationen mit H200 fallen in unseren definierten Leader-Quadranten.
Dies ist hauptsächlich auf die gute Leistung der H200 (insbesondere ihre führende Speicherkapazität und Bandbreite) und ihre wettbewerbsfähige Preisgestaltung zurückzuführen. Die beiden RTX 4090-Konfigurationen sind am kosteneffizientesten, fallen aber aufgrund ihrer geringeren Leistung in den Follower-Quadranten.
Fazit
GPU-Kosten stellen einen erheblichen Anteil an den Kosten für Inferenzdienste großer Modelle dar, und angesichts der Vielzahl der auf dem Markt erhältlichen GPU-Hardwareoptionen kann die Auswahl der am besten geeigneten eine Herausforderung sein. Die Identifizierung der besten Kosten-Leistungs-GPU und Inferenzlösung, die auf die spezifischen Geschäftsanforderungen zugeschnitten ist, ist entscheidend, da sie über Erfolg oder Misserfolg des Geschäfts entscheiden kann.
Durch unsere Erfahrung in der Bereitstellung von Inferenzdiensten für große Modelle haben wir umfangreiches Deployment-Wissen gesammelt und einen effektiven GPU-Bewertungsrahmen entwickelt, der die Geschäftsentwicklung kontinuierlich lenkt und Kunden die besten Kosten-Leistungs-Inferenzdienste bietet.
Dieser Artikel destilliert Best Practices aus praktischen Anwendungen und führt Echtzeittests an gängigen großen Modellen und GPU-Spezifikationen durch, um Leistungsvergleiche zu liefern und die besten Kosten-Leistungs-Inferenzlösungen zu identifizieren.
Unser Bewertungsansatz geht über komplexe Hardware-Metriken hinaus und konzentriert sich auf praktische Geschäftsanwendungen, was ihn hochgradig verallgemeinerbar und umsetzbar macht – besonders geeignet für Vergleichstests über verschiedene GPU-Modelle oder Inferenzengines hinweg.
Besuchen Sie Novita AI für weitere Informationen über erstklassige große Modell-Inferenzdienste und -Lösungen!
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Empfohlene Lektüre


