

النقاط الرئيسية
- تكاليف استدلال عالية: لا يزال استدلال النماذج واسعة النطاق مكلفًا، مما يحد من قابلية التوسع على الرغم من انخفاض التكاليف الإجمالية.
- تحديات اختيار GPU: تنوع وحدات GPU المتاحة يعقد عملية الاختيار، مما يؤدي غالبًا إلى اختيارات دون المستوى الأمثل بناءً على مقاييس سطحية.
- إطار تقييم موضوعي: تساعد طريقة التقييم الموحدة في تحديد حلول GPU الفعالة من حيث التكلفة والمصممة خصيصًا لاحتياجات الأعمال المحددة.
- مقاييس الأداء: ركز على زمن الاستجابة (Time To First Token) والإنتاجية (Tokens Per Second) لتحسين تجربة المستخدم.
- تحليل فعالية التكلفة: يسمح تقييم التكلفة لكل مليون رمز إلى جانب مقاييس الأداء بتصنيف الحلول بوضوح إلى أرباع فعالة.
- اختبار واقعي: اختبار النماذج الشائعة (سلسلة Llama 3.1) على وحدات GPU الرئيسية (H100, A100, RTX 4090) ينتج رؤى قابلة للتنفيذ.
- أفضل الممارسات: توصيات لاختيار أجهزة الاستدلال وتحسين المحركات تعزز الكفاءة وتقلل التكاليف.
- اكتشف Novita AI: لمزيد من المعلومات حول خدمات استدلال النماذج الكبيرة، تفضل بزيارة Novita AI.
مقدمة
تكلفة استدلال النماذج واسعة النطاق، على الرغم من انخفاضها المستمر، لا تزال مرتفعة بشكل ملحوظ، حيث تحد سرعة الاستدلال وتكاليف الاستخدام بشدة من قابلية توسع العمليات. كمزود لخدمات استدلال النماذج الكبيرة، نستثمر باستمرار في تحسين سرعة الاستدلال وخفض تكاليفه.
نحن نتعمق في استكشاف اختيار أجهزة الاستدلال وتحسين محركات الاستدلال لتقديم أكثر حلول الاستدلال فعالية من حيث التكلفة لعملائنا. تركز هذه المقالة على تقديم الطرق النظرية وأفضل الممارسات لاختيار أجهزة الاستدلال وتعرض استنتاجاتنا الأولية.
هناك مجموعة واسعة من وحدات GPU المتاحة لاستدلال النماذج الكبيرة، مما يجعل من الصعب العثور على ما يناسب متطلبات العمل المحددة. عند نشر العمليات، غالبًا ما تتركنا كثرة وحدات GPU في حيرة، مما يؤدي إلى مقارنة ثابتة تعتمد فقط على مقاييس مثل قوة حوسبة GPU وسعة الذاكرة وعرض النطاق الترددي والسعر. هذا النهج لاختيار GPU بناءً على تصور شخصي بأنه يبدو جذابًا يمكن أن يكون مضللاً بشكل كبير ويؤثر سلبًا على نتائج الأعمال.
لقد واجهنا هذه المشكلة أيضًا في مراحلنا المبكرة. ومع ذلك، مع نمو الأعمال وتوسعها، قمنا تدريجيًا بتطوير معيار تقييم GPU موضوعي ونزيه إلى جانب طرق التقييم المقابلة. باستخدام هذا النهج الموحد من خلال العديد من التقييمات، يمكننا تحديد الحلول الأكثر فعالية من حيث التكلفة والمصممة لاحتياجات الأعمال المختلفة من بين مجموعة كبيرة من وحدات GPU. إلى جانب محركات الاستدلال المحسنة، نقدم في النهاية للعملاء خدمات استدلال نماذج كبيرة سريعة وفعالة من حيث التكلفة.
نهج التقييم
ببساطة، يجب أن يستوفي “أفضل GPU من حيث التكلفة” معيارين: أقل سعر وأعلى أداء. قبل بدء التقييمات، نحدد هذه المعايير بدقة.
تعريف أقل سعر
أقل سعر ليس تكلفة أجهزة GPU أو استئجار الخادم السحابي في مراكز البيانات، بل تكلفة خدمة الاستدلال. إنه السعر الذي نراه على الموقع الرسمي لاستخدام واجهة برمجة تطبيقات النموذج، ويُعرّف بأنه التكلفة لكل مليون رمز مستهلك (دولار لكل 1 مليون رمز). القيمة الأقل تعني سعرًا أقل.
فهم أعلى أداء
يشير أعلى أداء إلى سرعة استدلال النموذج الكبير، حيث كلما زاد كان أفضل. من الضروري التمييز بين هذا وأداء النموذج، والذي يتضمن عادةً مقياسين فرعيين: زمن الاستجابة والإنتاجية.
مقاييس زمن الاستجابة والإنتاجية
- زمن الاستجابة (Latency): يقيس الوقت حتى الرمز الأول (TTFT)، أي الوقت الذي ينتظره المستخدم من بدء الطلب إلى استلام الرمز الأول.
- الإنتاجية (Throughput): تشير إلى متوسط عدد الرموز المستلمة في الثانية (TPS) من الرمز الأول فصاعدًا.
منهجية التقييم
لمواءمة التقييمات مع احتياجات الأعمال، نتعامل مع نظام الاستدلال كصندوق أسود أثناء التقييمات، ونحسب زمن الاستجابة والإنتاجية بناءً على مدخلات ومخرجات النظام. يوضح الرسم البياني أدناه كيفية حساب زمن الاستجابة والإنتاجية.
اعتبارات رئيسية
- انخفاض زمن الاستجابة وارتفاع الإنتاجية يشير إلى أداء استدلال أفضل.
- الإنتاجية أكثر أهمية بشكل ملحوظ من زمن الاستجابة في السيناريوهات الحقيقية.

إدارة الطلبات
بشكل عام، انخفاض زمن الاستجابة وارتفاع الإنتاجية يشير إلى أداء استدلال أفضل. ومع ذلك، في السيناريوهات الحقيقية، الإنتاجية أكثر أهمية بشكل ملحوظ من زمن الاستجابة.
طالما ظل زمن الاستجابة أقل من ثانيتين، فإن المستخدمين ليسوا حساسين جدًا تجاهه. حتى الانتظار بضع ملي ثانية لرؤية الرمز الأول لن يؤثر بشكل ملحوظ على التجربة.
من ناحية أخرى، تؤثر التغييرات في الإنتاجية بشكل كبير على تجربة المستخدم، مما يجعل المستخدمين يفضلون الأنظمة ذات الإنتاجية الأعلى. لذلك، عند تقييم مقاييس أداء حلول الاستدلال، نركز على مقارنة الاختلافات في الإنتاجية، مع الحفاظ على زمن الاستجابة ضمن نطاق مقبول.
في العمليات الحقيقية، يتعامل نظام الاستدلال مع طلبات مستخدمين متعددة بشكل متزامن لتعزيز الحمل الإجمالي للنظام. ومع ذلك، يجب ألا يكون مستوى التزامن مفرطًا، حيث أن التزامن العالي جدًا يمكن أن يقلل فعليًا من أداء الاستدلال. بالإضافة إلى ذلك، يؤثر طول طلبات المستخدمين وعدد الرموز المرتجعة أيضًا على مقاييس الأداء.
أنماط تقييم مبسطة
لاستخراج الأنماط من سيناريوهات الأعمال المعقدة، تعمل طريقتنا في التقييم على تبسيط الأمور بشكل مناسب مع الاقتراب من إعدادات الأعمال.
نسب وأطوال ثابتة
نحدد نسبًا وأطوالًا ثابتة لمدخلات ومخرجات الطلب، مثل (1000,100)، (3000,300)، (5000,500)، ونتحكم بدقة في أطوال الإدخال والإخراج عند إرسال الطلبات.
جولات الاختبار وحساب المقاييس
بعد إعداد عشرات الآلاف من الطلبات، نرسل الطلبات إلى خادم الاستدلال بأحجام دفعات ثابتة لجولات الاختبار، محاكاة العديد من المستخدمين الذين يرسلون الطلبات باستمرار والحفاظ على مستوى ثابت من التزامن في نظام الاستدلال.
مقاييس الأداء
بناءً على البيانات من كل جولة اختبار، نحسب مقاييس زمن الاستجابة والإنتاجية لجميع الطلبات ونحسب إحصائيات حول مؤشرات النسب المئوية المختلفة مثل P50 وP90 وP99 لتعكس أداء أكثر واقعية.
بالإضافة إلى ذلك، نحسب إجمالي إنتاجية جميع رموز الإدخال والإخراج في جولة اختبار، ونجمعها مع تكاليف الأجهزة، ونشتق سعر كل مليون رمز لنظام الاستدلال.
تحليل فعالية التكلفة
باتباع نهج التقييم هذا، ننتج عدة مجموعات من بيانات الاختبار بناءً على أطوال الإدخال والإخراج وأحجام الدفعات المختلفة، ونرسلها إلى خدمة الاستدلال، ونحسب مقياسين رئيسيين: السعر لكل مليون رمز ومعدل رمز الإخراج في الثانية (TPS) لكل طلب.
ثم نرسم هذه المقاييس على رسم بياني مع السعر على المحور السيني و TPS على المحور الصادي. من خلال تقييم المزيد من مواصفات الأجهزة باستخدام نفس الطريقة ورسم النتائج على الرسم البياني، نقوم بإنشاء نظرة عامة على فعالية التكلفة.
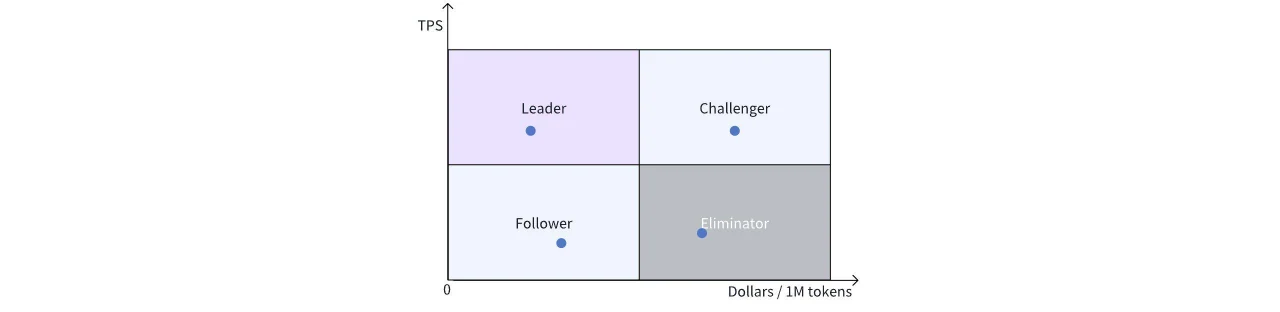
لتسهيل المقارنة بين الحلول المختلفة، نقسم الرسم البياني إلى أربعة أرباع:
الجزء العلوي الأيسر: رباعي القادة، بأعلى أداء وأقل سعر.
الجزء السفلي الأيسر: رباعي التابعين، بسعر جذاب ولكنه يحتاج إلى تحسينات في الأداء.
الجزء العلوي الأيمن: رباعي المتحدين، متقدم في الأداء ولكن بسعر أعلى، ربما من حلول أجهزة متطورة وباهظة الثمن، والتي قد تتحدى القادة إذا انخفضت الأسعار.
الجزء السفلي الأيمن: حلول قديمة تفتقر إلى مزايا في السعر والأداء.
طريقة التنفيذ
هدفنا من التقييم هو تحديد أجهزة GPU الأكثر فعالية من حيث التكلفة. لضمان مقارنات ذات معنى، سنثبت النموذج ومحرك الاستدلال وبيانات الطلب، ونغير فقط أجهزة GPU تحت نفس ظروف الاختبار. أثناء التقييم، سنختار النماذج مفتوحة المصدر ومجموعات البيانات ومحركات الاستدلال السائدة، باستخدام أجهزة GPU من سلسلة NVIDIA بشكل أساسي.
اختيار النموذج
سنستخدم نماذج سلسلة Llama 3.1، وتحديدًا نموذج Llama 3.1–70B (رابط Hugging Face). يتطلب حجم النموذج هذا عادةً استدلالًا متعدد GPU، مما يجعله مناسبًا لتقييم أداء الاتصال بين وحدات GPU.
محرك الاستدلال
سيكون محرك الاستدلال vLLM v0.6.3. بالنسبة لمجموعة البيانات، سنركز على أزواج الأسئلة والأجوبة، ونختار ShareGPT-v3-unfiltered كخيار الأنسب. عند بناء بيانات الطلب، سنكرر عبر مجموعة بيانات ShareGPT، ونقوم بتصفية أزواج الأسئلة والأجوبة بناءً على طول الإدخال للاحتفاظ فقط بتلك التي تساوي أو تتجاوز قيمة محددة، مع الاحتفاظ فقط بالأسئلة (مع التقليم المناسب إذا كانت طويلة جدًا) كموجه الطلب.
اختيار مواصفات GPU
عند اختيار مواصفات GPU، سنقوم بتقييم وحدات GPU السائدة، وتحديدًا H100 وA100 وRTX 4090، عبر الفئات المنخفضة والمتوسطة والعليا. النهج الشائع هو استئجار خوادم GPU بتكوين 8 بطاقات على منصات سحابية، مثل موقعنا Novita AI، الذي يقدم خيارات دفع حسب الاستخدام مريحة. بالإضافة إلى ذلك، قد ندرج المزيد من مواصفات GPU لتوسيع نطاق التقييم، بهدف ملء الأرباع الأربعة بمجموعة متنوعة من وحدات GPU واستراتيجيات الاستدلال.
بدء التقييم
بمجرد اكتمال الاستعدادات، يمكن بدء التقييم باتباع هذه الخطوات:
الخطوة 1: بدء محرك الاستدلال
لبدء محرك استدلال vLLM على خادم GPU المستهدف، يمكنك إنشاء مثيل حاوية Docker بسرعة. بالنسبة لخادم GPU 8 بطاقات 4090، استخدم الأمر التالي:
docker run -d --gpus all --net=host vllm/vllm-openai:v0.6.3 --port 8080 --model meta-llama/Llama-3.1-70B-Instruct --tensor-parallel-size 8 --swap-space 16 --gpu-memory-utilization 0.9 --dtype auto --served-model-name llama31-70b --max-num-seqs 32 --max-model-len 32768 --enable-prefix-caching --enable-chunked-prefill --disable-log-requests
الخطوة 2: بناء وإرسال الطلبات
على جانب العميل، قم ببناء الطلبات بناءً على أطوال الإدخال/الإخراج وأحجام الدُفعات، وإرسالها بكميات كبيرة إلى الخادم. يمكننا أيضًا الرجوع إلى حالات الاختبار المضمنة التي يوفرها vLLM لكتابة نصوص اختبار تلبي متطلبات التقييم الخاصة بنا
فيما يلي النقاط الرئيسية التي يجب مراعاتها عند بناء الطلبات:
- تصفية البيانات من ShareGPT
أثناء التكرار عبر جميع إدخالات المحادثة في مجموعة بيانات ShareGPT، لاحظ أن العنصر الأول من كل محادثة هو السؤال، والعنصر الثاني هو الإجابة المقابلة. تحتاج فقط إلى السؤال كموجه لطلباتك.
لضمان أن عدد الرموز في السؤال يلبي متطلبات طول الإدخال، قد تحتاج إلى تقليم السؤال بشكل مناسب. بالإضافة إلى ذلك، في قائمة المعلمات لكل طلب، قم بتعيين max_tokens إلى طول الإخراج المحدد و ignore_eos إلى true لإجبار محرك الاستدلال على إخراج العدد المحدد من الرموز.
- حجم دفعة ثابت
في كل جولة اختبار، حافظ دائمًا على نفس حجم الدفعة. لتحقيق ذلك، يجب على العميل إرسال عدد ثابت من الطلبات بشكل متوازٍ وإعادة إرسال طلب فور اكتمال أحدها. هذا يضمن بقاء ظروف الاختبار متسقة ويسمح بقياسات أداء دقيقة.
يمكن تكوين معلمات كل طلب على النحو التالي:
{
"model": "llama31-70b",
"prompt": prompt_content,
"temperature": 0.8,
"top_p": 1.0,
"best_of": 1,
"max_tokens": output_len,
"ignore_eos": true
}
الخطوة 3: جمع بيانات المقاييس
بعد اكتمال جميع الطلبات، يجب جمع المقاييس الرئيسية التالية:
- لكل طلب: زمن الاستجابة للرمز الأول (TTFT) = وقت_الرمز_الأول — وقت_إرسال_الطلب
- لكل طلب: الرموز في الثانية (TPS) = إجمالي_رموز_الإخراج / (وقت_إنهاء_الطلب — وقت_الرمز_الأول)
- لجولة اختبار: إجمالي إنتاجية النظام = مجموع (رموز_الإدخال_لكل_طلب + رموز_الإخراج_لكل_طلب) / إجمالي_الثواني
حيث يشير TTFT و TPS إلى كل طلب، وللتيسير في الحسابات، يمكنك استخدام النسبة المئوية P90 لجميع الطلبات في جولة اختبار.
يشير إجمالي إنتاجية النظام إلى إجمالي عدد الرموز (بما في ذلك رموز الإدخال والإخراج) التي يمكن لخدمة الاستدلال معالجتها في الثانية. قسمة سعر خادم GPU المقابل على إجمالي الإنتاجية تسمح لك باشتقاق التكلفة لكل مليون رمز.
في السيناريوهات العملية، قد يؤثر استخدام الخادم وتقلبات الطلب أيضًا على الإنتاجية، ويمكن تطبيق عامل لمراعاة هذه التأثيرات، على الرغم من أن هذا لا يؤثر بشكل عام على استنتاجات التقييم.
النتائج الرئيسية حول أداء GPU وفعالية التكلفة
أجرينا تقييمًا متعمقًا لوحدات GPU الرئيسية (H100، A100، RTX 4090) باستخدام طرق الاختبار المذكورة أعلاه. لكل GPU، قمنا بحساب مقاييس الأداء (TTFT، TPS) بأطوال إدخال/إخراج وأحجام دفعات مختلفة، واستخرجنا النسب المئوية P50 وP90 وP99. كما أشرنا إلى أسعار استئجار منصات GPU السحابية السائدة (المتاحة في Novita AI) لحساب التكلفة لكل مليون رمز. ستكون هذه البيانات بمثابة الأساس لمزيد من تقييمات فعالية التكلفة وتوجيهنا إلى استنتاجاتنا التقييمية النهائية.
مقارنة أداء الاستدلال الفردي
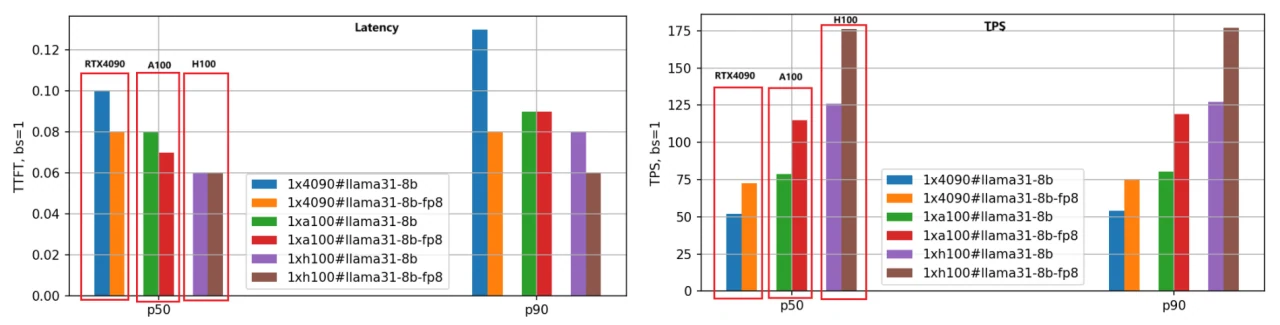
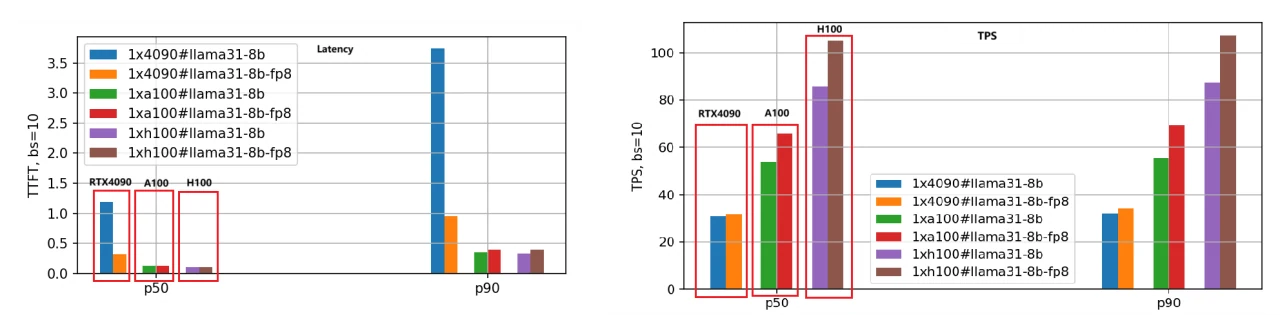
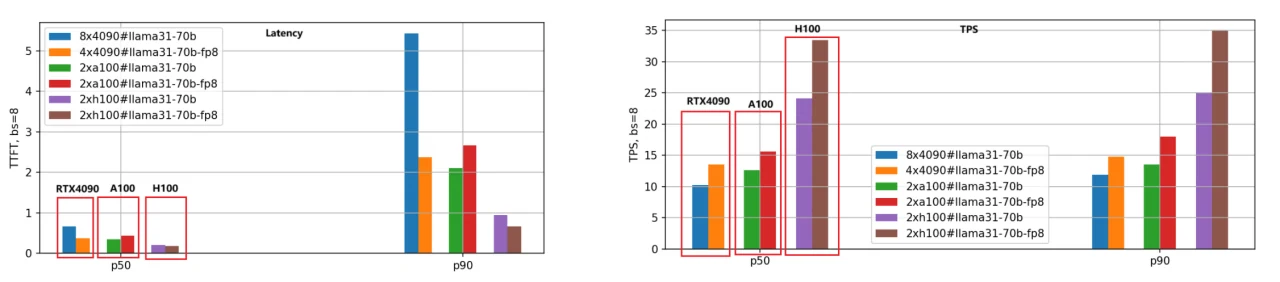
التركيز الأساسي هو على زمن الاستجابة (زمن الاستجابة للرمز الأول) والإنتاجية (الرموز في الثانية). زمن استجابة أقل هو الأفضل، بينما TPS أعلى هو المرغوب. قمنا بتقييم كل من إصدارات BF16 و FP8 لنماذج Llama-3.1–8B و Llama-3.1–70B عبر وحدات GPU الثلاث، مع ضبط طول الإدخال/الإخراج لكل طلب على 5000/500 واختبار أحجام دفعات مختلفة. فيما يلي نتائج مقارنة الأداء لنموذج Llama-3.1–8B، باستخدام بيانات P50 للتحليل.
- زمن الاستجابة للرمز الأول:
ترتيب السرعة من الأسرع إلى الأبطأ هو H100 وA100 وRTX 4090. عندما يكون حجم الدفعة 1، تكون سرعة A100 1.25 مرة من RTX 4090، و H100 أسرع بـ 1.66 مرة.
مع زيادة حجم الدفعة، تتسع الفجوة بين RTX 4090 والاثنين الآخرين بشكل ملحوظ. عندما يصل حجم الدفعة إلى 10، يتجاوز زمن الاستجابة لـ RTX 4090 3.5 ثوانٍ (النسبة المئوية P90)، وهو أمر غير مقبول للعديد من تطبيقات الأعمال. في المقابل، يحافظ A100 و H100 على زمن استجابة أقل من 0.5 ثانية، مما يظهر أداءً مستقرًا.
2. الرموز في الثانية (TPS):
يعكس هذا المقياس سرعة توليد المحرك، مع نفس ترتيب السرعة: H100، A100، RTX 4090. مع حجم دفعة 1، يكون TPS لـ A100 حوالي 1.48 ضعف TPS لـ RTX 4090، و TPS لـ H100 هو 2.44 ضعف TPS لـ RTX 4090، مما يشير إلى أعلى كفاءة توليد لـ H100.
مع زيادة حجم الدفعة، ينخفض TPS للطلبات الفردية تدريجيًا بسبب زيادة حمل النظام وانخفاض الموارد لكل طلب. عندما يكون حجم الدفعة 10، ينخفض TPS إلى حوالي 70٪ من TPS مع حجم دفعة 1.
3. تكميم النموذج FP8:
إصدار FP8، مع ملفات وزن مخفضة بمقدار النصف مقارنة بـ BF16، يقلل بشكل كبير من الحمل الزائد لموارد النظام، مما يؤدي إلى تحسين زمن الاستجابة والإنتاجية. توضح المجموعة الثانية من الرسوم البيانية الشريطية هذا الاستنتاج بوضوح، خاصة في مقياس TPS، حيث يبلغ أداء إصدار FP8 حوالي 1.4 ضعف أداء إصدار BF16 لنفس GPU.
4. حساسية RTX 4090 لحجم الدفعة:
بسبب قيود الذاكرة والاتصال، فإن RTX 4090 حساس جدًا لحجم الدفعة. يمكن أن تؤدي أحجام الدفعات الكبيرة بشكل مفرط إلى طابور داخلي، مما يؤدي إلى زمن استجابة أعلى وإنتاجية أقل. يجب إيلاء اهتمام خاص لإعدادات حجم الدفعة عند نشر أعباء العمل على RTX 4090.
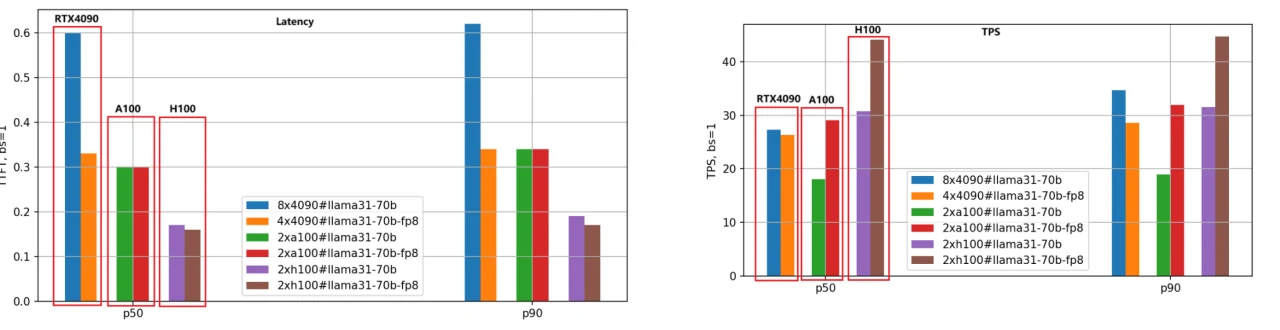
طبقنا نفس طريقة التقييم لنموذج Llama-3.1–70B، وتظهر مقارنة الأداء في الشكل التالي.
نظرًا للحجم الكبير لنموذج 70B، استخدمنا 8 وحدات GPU RTX 4090 لإصدار BF16 و 4 وحدات GPU RTX 4090 لإصدار FP8. في المقابل، تطلبت كل من وحدات GPU A100 و H100، بسعة ذاكرة 80 جيجابايت، وحدتين فقط لتشغيل فعال.
من الشكل، يمكننا استخلاص استنتاجات مماثلة لتلك الخاصة بنموذج Llama-3.1–8B: يظل H100 هو GPU الأعلى أداءً، وإصدار تكميم FP8 أسرع بحوالي 1.4 مرة من إصدار BF16.
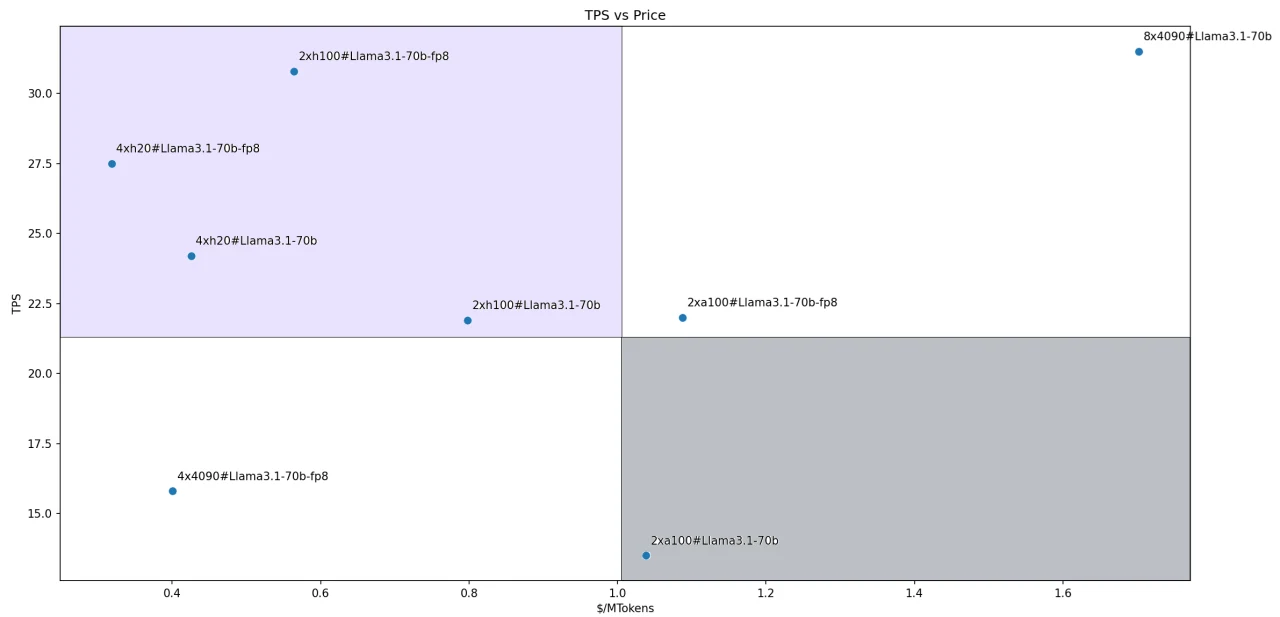
تقييم شامل للأداء مقابل التكلفة
في النشر العملي، من الضروري مراعاة ليس فقط مقاييس الأداء ولكن أيضًا التكلفة الإجمالية للحلول لتحديد أفضل نسبة أداء إلى تكلفة.
على سبيل المثال، قد يكون RTX 4090 أبطأ من حيث الأداء، لكن سعره المنخفض جدًا قد يجعل فعالية التكلفة الإجمالية تنافسية. لتحقيق ذلك، نحتاج إلى طرق تقييم أكثر علمية واحترافية لتحديد أي GPU وأي حل استدلال يقدم أفضل قيمة بدقة.
في “نهج التقييم” الخاص بنا، نقترح رسم تكاليف ومقاييس أداء حلول الاستدلال المختلفة على نظام إحداثيات ثنائي الأبعاد، وتقسيم المساحة إلى أربعة أرباع: القادة، والتابعون، والمتحدون، والمستبعدون. باتباع هذا النهج، ركزنا على اختبار نماذج Llama-3.1–70B و Llama-3.1–8B وإصدارات التكميم FP8 الخاصة بهم.
اخترنا أربع وحدات GPU: RTX 4090، A100، H100، و H200، مع ضبط طول الإدخال/الإخراج على 5000/500 وأحجام دفعات من 1 إلى 10. اختبرنا مجموعات مختلفة للحصول على بيانات الأداء والتسعير، والتي تم رسمها في النهاية في الشكلين أدناه.
بالنسبة لنموذج Llama-3.1–70B، تظهر نسب الأداء إلى التكلفة لكل حل في الشكل. أربعة حلول تقع في رباعي القادة الذي حددناه:
- Llama3.1–70B-FP8@2xH100
- Llama3.1–70B-FP8@4xH200
- Llama3.1–70B@4xH200
- Llama3.1–70B@2xH100
في الشكل، يمثل ميل الخط الذي يربط نقطة إحداثيات كل حل بالأصل نسبة الأداء إلى السعر. يشير المنحدر الأكثر حدة إلى نسبة أداء إلى تكلفة أعلى.
لذلك، يبرز الحل Llama3.1–70B-FP8@4xH200 كأكثر الخيارات فعالية من حيث التكلفة بين جميع حلول الاستدلال التي تم تقييمها.
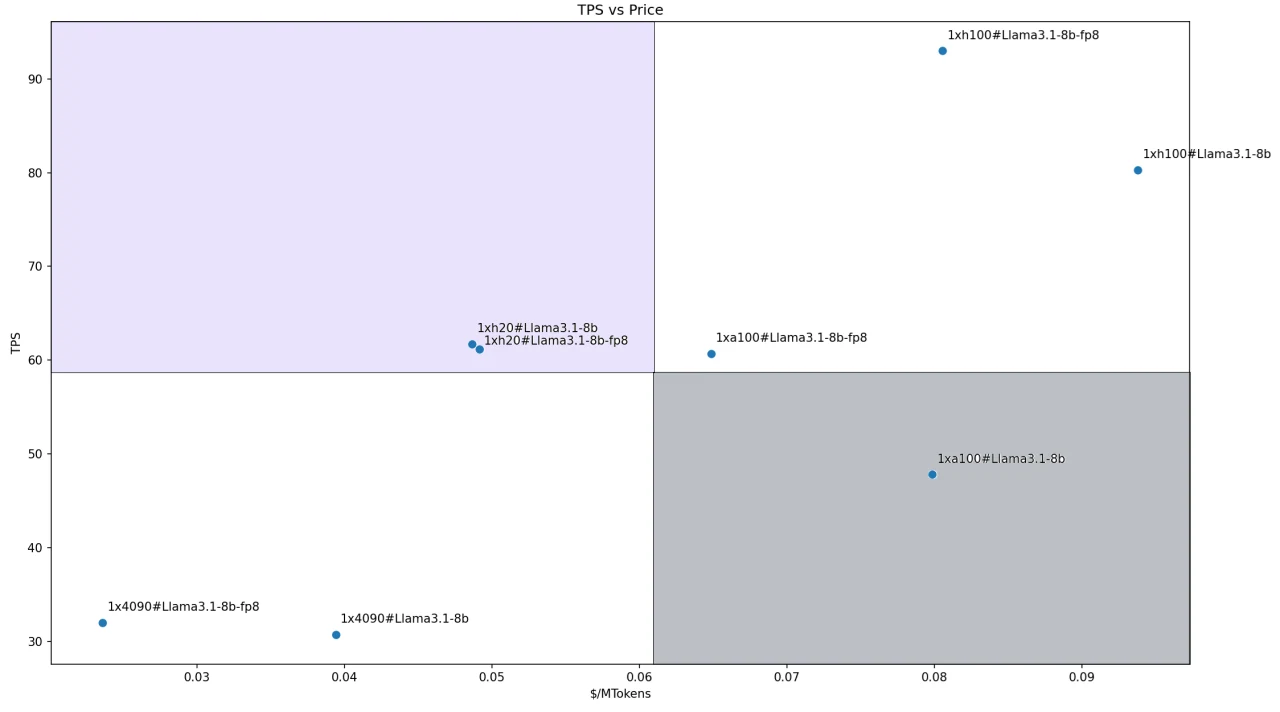
بالنسبة لنموذج Llama3.1–8B، نظرًا لحجمه الأصغر، قمنا بنشر جميع النماذج باستخدام تكوين GPU واحد. تظهر نسب الأداء إلى التكلفة للحلول المختلفة في الشكل أدناه. يقع كلا التكوينين مع H200 في رباعي القادة الذي حددناه.
يرجع هذا بشكل أساسي إلى الأداء الجيد لـ H200 (خاصة سعة الذاكرة وعرض النطاق الترددي الرائدين) والتسعير التنافسي. تكوينات RTX 4090 هي الأكثر فعالية من حيث التكلفة، ولكن نظرًا لأدائها الأضعف، فإنها تقع في رباعي التابعين.
الخاتمة
تمثل تكاليف GPU جزءًا كبيرًا من خدمات استدلال النماذج الكبيرة، ومع تعدد خيارات أجهزة GPU المتاحة في السوق، قد يكون اختيار الأنسب أمرًا صعبًا. يعد تحديد أفضل GPU وحل استدلال من حيث الأداء والتكلفة والمصمم خصيصًا لاحتياجات العمل المحددة أمرًا بالغ الأهمية، حيث يمكن أن يحدد نجاح أو فشل العمل.
من خلال تجربتنا في تقديم خدمات استدلال النماذج الكبيرة، اكتسبنا معرفة نشر واسعة وطورنا إطارًا فعالًا لتقييم GPU يوجه تطوير الأعمال باستمرار، ويقدم للعملاء أفضل خدمات الاستدلال من حيث الأداء والتكلفة.
تستخلص هذه المقالة أفضل الممارسات من التطبيقات العملية وتجري اختبارات واقعية على النماذج الكبيرة ومواصفات GPU السائدة، وتوفر مقارنات أداء لتحديد أفضل حلول الاستدلال من حيث الأداء والتكلفة.
يتجاوز نهج التقييم لدينا مقاييس الأجهزة المعقدة، مع التركيز على التطبيقات العملية للأعمال، مما يجعله قابلاً للتعميم وقابلاً للتنفيذ - خاصة مناسبًا للاختبار المقارن عبر نماذج GPU المختلفة أو محركات الاستدلال.
اطلع على Novita AI لمزيد من المعلومات حول خدمات وحلول استدلال النماذج الكبيرة من الدرجة الأولى!
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.
قراءات موصى بها
1.كيف يحقق KV Sparsity تسريعًا بنسبة 1.5x لـ vLLM
2.التخصيص الديناميكي لموارد GPU لأحمال عمل Kubernetes
3.إضافة تعيينات المنافذ ديناميكيًا إلى حاويات Docker قيد التشغيل


