

Puntos clave
- Altos costos de inferencia: La inferencia de modelos a gran escala sigue siendo costosa, lo que limita la escalabilidad a pesar de la disminución de los costos generales.
- Desafíos en la selección de GPU: La variedad de GPU disponibles complica el proceso de selección, a menudo llevando a elecciones subóptimas basadas en métricas superficiales.
- Marco de evaluación objetivo: Un método de evaluación estandarizado ayuda a identificar soluciones GPU rentables adaptadas a necesidades comerciales específicas.
- Métricas de rendimiento: Céntrate en la latencia (Tiempo hasta el primer token) y el rendimiento (Tokens por segundo) para optimizar la experiencia del usuario.
- Análisis de rentabilidad: Evaluar el costo por millón de tokens junto con las métricas de rendimiento permite clasificar claramente las soluciones en cuadrantes efectivos.
- Pruebas en el mundo real: Las pruebas de modelos populares (serie Llama 3.1) en GPU principales (H100, A100, RTX 4090) brindan información procesable.
- Mejores prácticas: Las recomendaciones para seleccionar hardware de inferencia y optimizar motores mejoran la eficiencia y reducen costos.
- Explora Novita AI: Para más información sobre servicios de inferencia de modelos grandes, visita Novita AI.
Introducción
El costo de la inferencia de modelos a gran escala, aunque sigue disminuyendo, sigue siendo considerablemente alto, y la velocidad de inferencia y los costos de uso limitan severamente la escalabilidad de las operaciones. Como proveedor de servicios de inferencia de modelos grandes, invertimos continuamente en mejorar la velocidad de inferencia y reducir los costos de inferencia.
Profundizamos en explorar la selección del hardware de inferencia y la optimización de los motores de inferencia para ofrecer a nuestros clientes las soluciones de inferencia más rentables. Este artículo se centra en presentar los métodos teóricos y las mejores prácticas para elegir hardware de inferencia y expone nuestras conclusiones preliminares.
Existe una gran variedad de GPU disponibles para la inferencia de modelos grandes, lo que dificulta encontrar una que se adapte a los requisitos comerciales específicos. Al implementar operaciones, la multitud de GPU a menudo nos deja perplejos, lo que nos lleva a una comparación estática basada en métricas como la potencia de cómputo de la GPU, la capacidad de memoria, el ancho de banda y el precio. Este enfoque de seleccionar una GPU basándose en una percepción subjetiva de que se ve atractiva puede desorientar significativamente y afectar negativamente los resultados comerciales.
Nosotros también nos encontramos con este problema en nuestras etapas iniciales. Sin embargo, con el crecimiento y la expansión del negocio, hemos desarrollado gradualmente un estándar de evaluación de GPU objetivo e imparcial junto con los métodos de evaluación correspondientes. Al emplear este enfoque estandarizado a través de numerosas evaluaciones, podemos identificar las soluciones más rentables adaptadas a diferentes necesidades comerciales entre una gran cantidad de GPU. Combinado con motores de inferencia optimizados, finalmente proporcionamos a los clientes servicios de inferencia de modelos grandes que son rápidos y rentables.
Enfoque de evaluación
En pocas palabras, una “GPU con mejor relación costo-beneficio” debe cumplir dos criterios: el precio más bajo y el rendimiento más alto. Antes de comenzar las evaluaciones, definimos con precisión estos estándares.
Definición del precio más bajo
El precio más bajo no es el costo del hardware de la GPU ni el arrendamiento del servidor en la nube en los centros de datos, sino el costo del servicio de inferencia. Es el precio que vemos en el sitio web oficial por usar la API del modelo, definido como el costo por millón de tokens consumidos (Dólares por 1M de tokens). Un valor más bajo significa un precio más bajo.
Comprender el rendimiento más alto
El rendimiento más alto se refiere a la velocidad de inferencia del modelo grande, donde cuanto más alto, mejor. Es esencial distinguir esto del rendimiento del modelo, que generalmente incluye dos submétricas: latencia y rendimiento.
Métricas de latencia y rendimiento
- Latencia: Mide el Tiempo hasta el primer token (TTFT), el tiempo que un usuario espera desde que inicia una solicitud hasta que recibe el primer token.
- Rendimiento: Indica el número promedio de tokens recibidos por segundo (TPS) desde el primer token en adelante.
Metodología de evaluación
Para alinear las evaluaciones con las necesidades comerciales, tratamos el sistema de inferencia como una caja negra durante las evaluaciones, calculando la latencia y el rendimiento en función de las entradas y salidas del sistema. El siguiente diagrama ilustra cómo se calculan la latencia y el rendimiento.
Consideraciones clave
- Una latencia más baja y un rendimiento más alto indican un mejor rendimiento de inferencia.
- El rendimiento es significativamente más crucial que la latencia en escenarios reales.

Gestión de solicitudes
En general, una latencia más baja y un rendimiento más alto indican un mejor rendimiento de inferencia. Sin embargo, en escenarios reales, el rendimiento es significativamente más crucial que la latencia.
Siempre que la latencia sea inferior a 2 segundos, los usuarios no son muy sensibles a ella. Incluso esperar unos milisegundos para ver el primer token no afectará notablemente la experiencia.
Por otro lado, los cambios en el rendimiento afectan en gran medida la experiencia del usuario, lo que hace que los usuarios prefieran sistemas con mayor rendimiento. Por lo tanto, al evaluar las métricas de rendimiento de las soluciones de inferencia, nos enfocamos en comparar las diferencias de rendimiento, mientras mantenemos la latencia dentro de un rango aceptable.
En las operaciones del mundo real, un sistema de inferencia maneja simultáneamente múltiples solicitudes de usuarios para mejorar la carga general del sistema. Sin embargo, el nivel de concurrencia no debe ser excesivo, ya que una concurrencia demasiado alta puede degradar el rendimiento de la inferencia. Además, la longitud de las solicitudes de los usuarios y la cantidad de tokens devueltos también influyen en las métricas de rendimiento.
Patrones de evaluación simplificados
Para extraer patrones de escenarios comerciales complejos, nuestro método de evaluación simplifica adecuadamente mientras se alinea estrechamente con los entornos comerciales.
Relaciones y longitudes fijas
Establecemos relaciones y longitudes fijas para las entradas y salidas de las solicitudes, como (1000,100), (3000,300), (5000,500), y controlamos con precisión las longitudes de entrada y salida al enviar solicitudes.
Rondas de prueba y cálculo de métricas
Después de preparar decenas de miles de solicitudes, enviamos las solicitudes al servidor de inferencia en lotes de tamaño fijo para rondas de prueba, simulando que numerosos usuarios envían solicitudes continuamente y manteniendo un nivel estable de concurrencia en el sistema de inferencia.
Métricas de rendimiento
Basándonos en los datos de cada ronda de prueba, calculamos las métricas de latencia y rendimiento para todas las solicitudes y recopilamos estadísticas sobre diferentes indicadores de percentiles como P50, P90, P99 para reflejar un rendimiento más realista.
Además, calculamos el rendimiento total de todos los tokens de entrada y salida en una ronda de prueba, lo combinamos con los costos de hardware y derivamos el precio por millón de tokens para el sistema de inferencia.
Análisis de rentabilidad
Siguiendo este enfoque de evaluación, generamos varios conjuntos de datos de prueba basados en diferentes longitudes de entrada-salida y tamaños de lote, los enviamos al servicio de inferencia y calculamos dos métricas clave: el precio por millón de tokens y la tasa de tokens de salida por segundo (TPS) por solicitud.
Luego, trazamos estas métricas en un gráfico con el precio en el eje x y el TPS en el eje y. Al evaluar más especificaciones de hardware usando el mismo método y trazar los resultados en el gráfico, creamos una visión general de la rentabilidad.
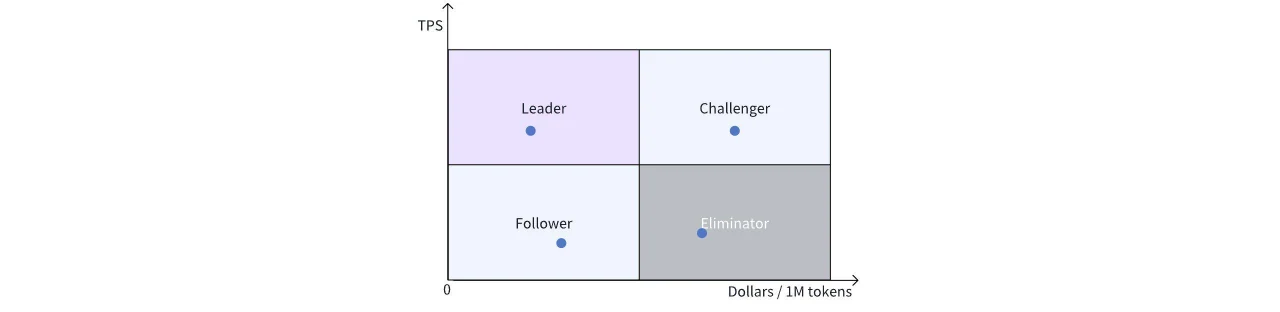
Para facilitar la comparación entre diferentes soluciones, dividimos el gráfico en cuatro cuadrantes:
Superior izquierdo: Cuadrante Líder, con el mayor rendimiento y el precio más bajo.
Inferior izquierdo: Cuadrante Seguidor, con un precio atractivo pero que necesita mejoras de rendimiento.
Superior derecho: Cuadrante Desafiante, líder en rendimiento pero con un precio más alto, posiblemente de soluciones de hardware costosas y de vanguardia, que podrían desafiar a los líderes si los precios disminuyen.
Inferior derecho: Soluciones obsoletas que carecen de ventajas tanto en precio como en rendimiento.
Método de implementación
Nuestro objetivo de evaluación es identificar el hardware de GPU más rentable. Para garantizar comparaciones significativas, fijaremos el modelo, el motor de inferencia y los datos de solicitud, cambiando solo el hardware de la GPU bajo las mismas condiciones de prueba. Durante la evaluación, seleccionaremos modelos open source populares, conjuntos de datos y motores de inferencia, utilizando principalmente hardware de GPU de la serie NVIDIA.
Selección del modelo
Usaremos los modelos de la serie Llama 3.1, específicamente el modelo Llama 3.1-70B (enlace a Hugging Face). Este tamaño de modelo generalmente requiere inferencia con múltiples GPU, lo que lo hace adecuado para evaluar el rendimiento de la comunicación entre GPU.
Motor de inferencia
El motor de inferencia será vLLM v0.6.3. Para el conjunto de datos, nos centraremos en pares de preguntas y respuestas, eligiendo ShareGPT-v3-unfiltered como la opción más adecuada. Al construir los datos de solicitud, recorreremos el conjunto de datos ShareGPT, filtrando pares de preguntas y respuestas según la longitud de entrada para conservar solo aquellos que sean iguales o superen un valor especificado, manteniendo solo las preguntas (recortando adecuadamente si son demasiado largas) como el prompt de la solicitud.
Selección de especificaciones de GPU
Al seleccionar las especificaciones de GPU, evaluaremos GPU principales, específicamente H100, A100 y RTX 4090, en categorías baja, media y alta. Un enfoque común es alquilar servidores GPU con configuración de 8 tarjetas en plataformas en la nube, como nuestro sitio web, Novita AI, que ofrece opciones convenientes de pago por uso. Además, podemos incluir más especificaciones de GPU para ampliar el alcance de la evaluación, con el objetivo final de poblar los cuatro cuadrantes con una variedad de GPU y estrategias de inferencia.
Inicio de la evaluación
Una vez que las preparaciones estén completas, se puede iniciar la evaluación siguiendo estos pasos:
Paso 1: Iniciar el motor de inferencia
Para iniciar el motor de inferencia vLLM en tu servidor GPU objetivo, puedes crear rápidamente una instancia de contenedor Docker. Para un servidor GPU con 8 tarjetas 4090, usa el siguiente comando:
docker run -d --gpus all --net=host vllm/vllm-openai:v0.6.3 --port 8080 --model meta-llama/Llama-3.1-70B-Instruct --tensor-parallel-size 8 --swap-space 16 --gpu-memory-utilization 0.9 --dtype auto --served-model-name llama31-70b --max-num-seqs 32 --max-model-len 32768 --enable-prefix-caching --enable-chunked-prefill --disable-log-requests
Paso 2: Construir y enviar solicitudes
En el lado del cliente, construye solicitudes basadas en longitudes de entrada/salida y tamaños de lote, y envíalas en lote al servidor. También podemos consultar los casos de prueba integrados proporcionados por vLLM para escribir scripts de prueba que cumplan con nuestros requisitos de evaluación.
Aquí hay puntos clave a considerar al construir solicitudes:
- Filtrado de datos de ShareGPT
Al recorrer todas las entradas de conversación en el conjunto de datos ShareGPT, ten en cuenta que el primer elemento de cada conversación es la pregunta y el segundo elemento es la respuesta correspondiente. Solo necesitas la pregunta como prompt para tus solicitudes.
Para asegurarte de que la cantidad de tokens en la pregunta cumpla con los requisitos de longitud de entrada, es posible que debas recortar la pregunta adecuadamente. Además, en la lista de parámetros para cada solicitud, establece max_tokens en la longitud de salida especificada y ignore_eos en true para forzar al motor de inferencia a generar la cantidad especificada de tokens.
- Tamaño de lote consistente
En cada ronda de prueba, mantén siempre el mismo tamaño de lote. Para lograr esto, el cliente debe enviar una cantidad fija de solicitudes en paralelo y reenviar una solicitud inmediatamente después de que se complete una. Esto asegura que las condiciones de prueba se mantengan consistentes y permite mediciones de rendimiento precisas.
Los parámetros de cada solicitud se pueden configurar de la siguiente manera:
{
"model": "llama31-70b",
"prompt": prompt_content,
"temperature": 0.8,
"top_p": 1.0,
"best_of": 1,
"max_tokens": output_len,
"ignore_eos": true
}
Paso 3: Recopilación de datos de métricas
Después de que se completen todas las solicitudes, se deben recopilar las siguientes métricas clave:
- Para cada solicitud: Latencia del primer token (TTFT) = First_Token_Time — Send_Req_Time
- Para cada solicitud: Tokens por segundo (TPS) = Total_Output_Tokens / (Finish_Req_Time — First_Token_Time)
- Para una ronda de prueba: Rendimiento total del sistema = Suma(Input_Tokens_Per_Req + Output_Tokens_Per_Req) / Total_Seconds
Donde TTFT y TPS se refieren a cada solicitud, y por conveniencia en los cálculos, puedes usar el percentil P90 de todas las solicitudes en una ronda de prueba.
El rendimiento total del sistema indica la cantidad total de tokens (incluyendo tanto tokens de entrada como de salida) que el servicio de inferencia puede manejar por segundo. Dividir el precio del servidor GPU correspondiente por el rendimiento total permite obtener el costo por millón de tokens.
En escenarios prácticos, la utilización del servidor y las fluctuaciones de las solicitudes también pueden afectar el rendimiento, y se puede aplicar un factor para tener en cuenta estas influencias, aunque esto generalmente no afecta las conclusiones de la evaluación.
Conclusiones clave sobre el rendimiento y la rentabilidad de las GPU
Realizamos una evaluación en profundidad de las GPU principales (H100, A100, RTX 4090) utilizando los métodos de prueba mencionados anteriormente. Para cada GPU, calculamos las métricas de rendimiento (TTFT, TPS) en varias longitudes de entrada/salida y tamaños de lote, obteniendo los percentiles P50, P90 y P99. También consultamos los precios de alquiler de las principales plataformas de GPU en la nube (disponibles en Novita AI) para calcular el costo por millón de tokens. Estos datos servirán como base para evaluaciones adicionales de costo-rendimiento y nos guiarán hacia nuestras conclusiones finales de evaluación.
Comparación de rendimiento de inferencia única
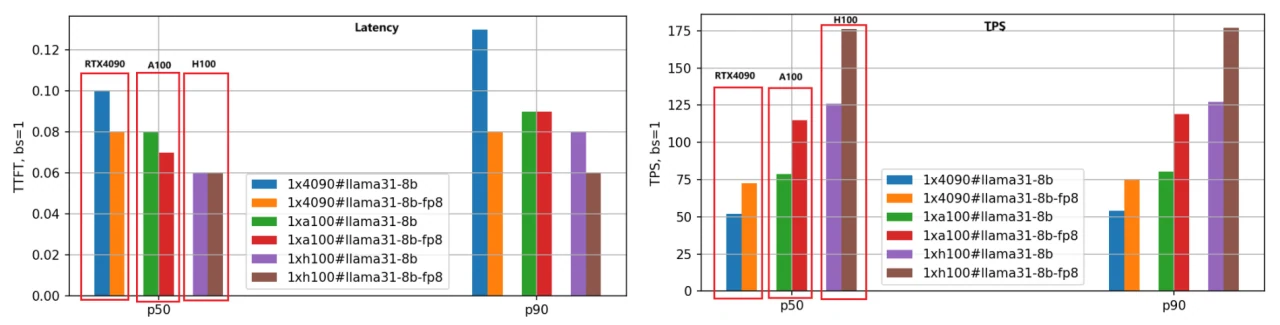
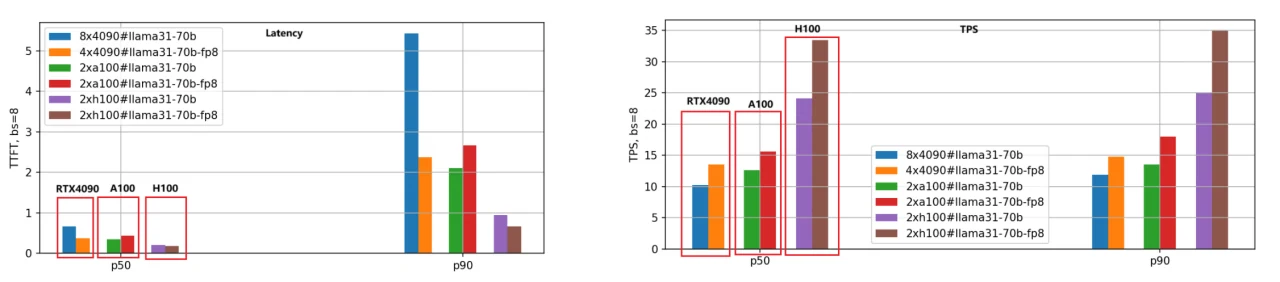
El enfoque principal está en la latencia (Latencia del primer token) y el rendimiento (Tokens por segundo). Se prefiere una latencia más baja, mientras que se desea un TPS más alto. Evaluamos las versiones BF16 y FP8 de los modelos Llama-3.1-8B y Llama-3.1-70B en las tres GPU, estableciendo la longitud de entrada/salida de cada solicitud en 5000/500 y probando diferentes tamaños de lote. A continuación se muestran los resultados de comparación de rendimiento para el modelo Llama-3.1-8B, utilizando datos P50 para el análisis.
-
Latencia del primer token:
La clasificación de velocidad de más rápida a más lenta es H100, A100 y RTX 4090. Cuando el tamaño de lote se establece en 1, la velocidad de A100 es 1,25 veces la de RTX 4090, y H100 es 1,66 veces más rápida.
A medida que aumenta el tamaño del lote, la brecha entre RTX 4090 y las otras dos GPU se amplía significativamente. Cuando el tamaño de lote alcanza 10, la latencia de RTX 4090 supera los 3,5 segundos (percentil P90), lo que no es aceptable para muchas aplicaciones comerciales. En contraste, A100 y H100 mantienen latencias por debajo de 0,5 segundos, mostrando un rendimiento estable.
2. Tokens por segundo (TPS):
Esta métrica refleja la velocidad de generación del motor, con la misma clasificación de velocidad: H100, A100 y RTX 4090. Con un tamaño de lote de 1, el TPS de A100 es aproximadamente 1,48 veces el de RTX 4090, y el TPS de H100 es 2,44 veces el de RTX 4090, lo que indica la mayor eficiencia de generación de H100.
A medida que aumenta el tamaño del lote, el TPS para solicitudes individuales disminuye gradualmente debido al aumento de la carga del sistema y la reducción de recursos por solicitud. Cuando el tamaño de lote es 10, el TPS cae a aproximadamente el 70% del TPS con tamaño de lote 1.
3. Cuantización del modelo FP8:
La versión FP8, con archivos de pesos reducidos a la mitad en comparación con BF16, reduce significativamente la sobrecarga de recursos del sistema, lo que resulta en una mejora de la latencia y el rendimiento. El segundo conjunto de gráficos de barras ilustra claramente esta conclusión, particularmente en la métrica TPS, donde el rendimiento de la versión FP8 es aproximadamente 1,4 veces el de la versión BF16 para la misma GPU.
4. Sensibilidad de RTX 4090 al tamaño de lote:
Debido a limitaciones de memoria y comunicación, RTX 4090 es muy sensible al tamaño de lote. Tamaños de lote excesivamente grandes pueden provocar colas internas, lo que resulta en una latencia más alta y un rendimiento más bajo. Se debe prestar especial atención a la configuración del tamaño de lote al implementar cargas de trabajo en RTX 4090.
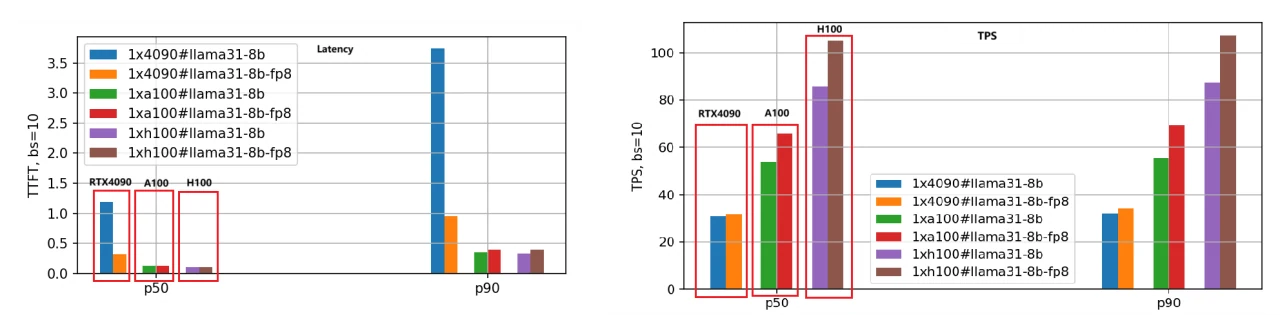
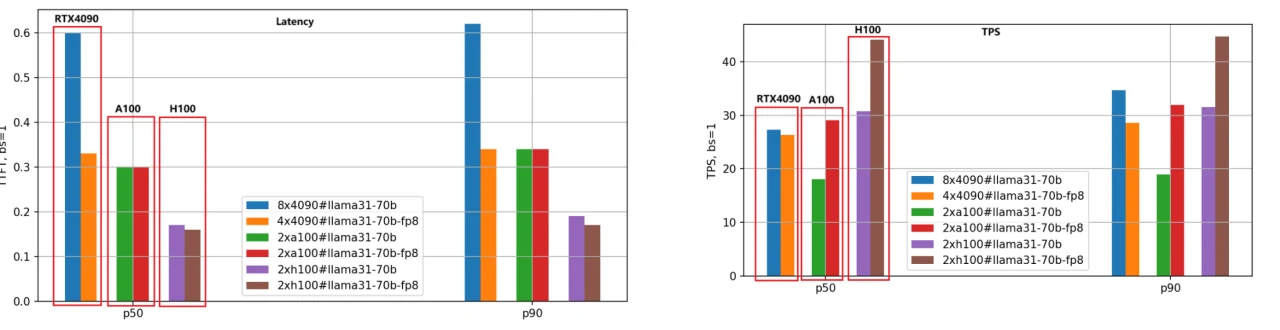
Empleamos el mismo método de evaluación para el modelo Llama-3.1-70B, y la comparación de rendimiento se ilustra en la siguiente figura.
Dado el gran tamaño del modelo 70B, utilizamos 8 GPU RTX 4090 para la versión BF16 y 4 GPU RTX 4090 para la versión FP8. En contraste, las GPU A100 y H100, con sus 80 GB de memoria, solo requirieron 2 unidades para funcionar de manera efectiva.
En la figura, podemos extraer conclusiones similares a las del modelo Llama-3.1-8B: H100 sigue siendo la GPU de mayor rendimiento y la versión de cuantización FP8 es aproximadamente 1,4 veces más rápida que la versión BF16.
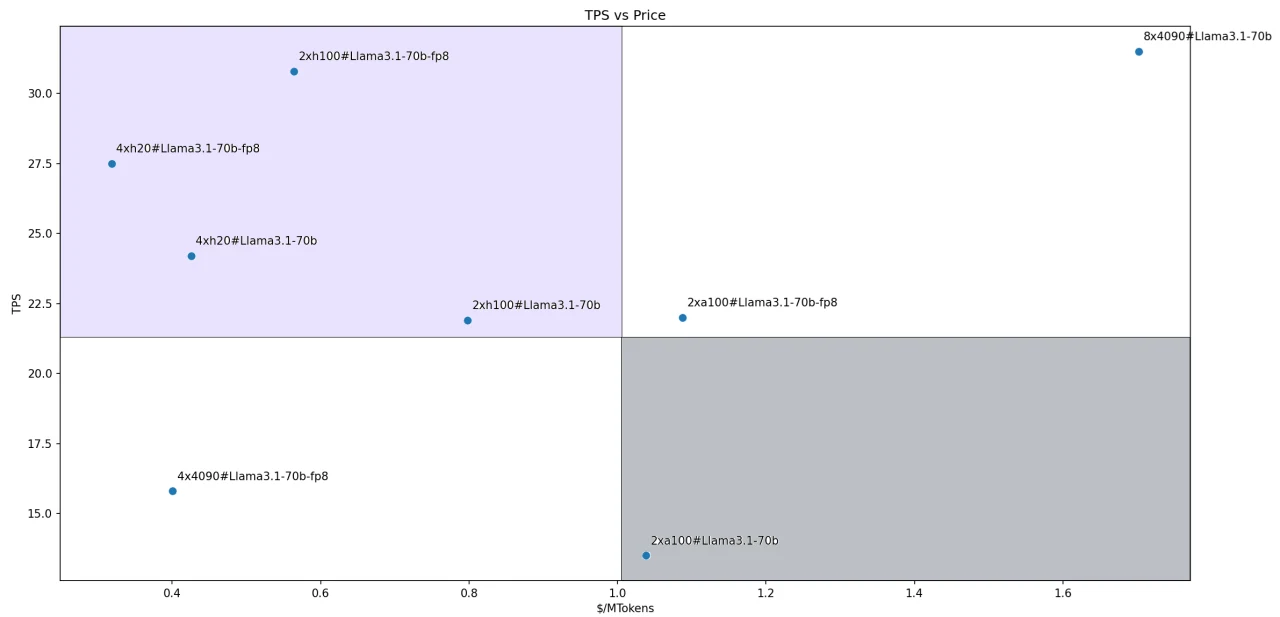
Evaluación integral de costo-rendimiento
En la implementación práctica, es esencial considerar no solo las métricas de rendimiento, sino también el costo total de las soluciones para identificar la mejor relación costo-beneficio.
Por ejemplo, aunque la RTX 4090 puede ser más lenta en términos de rendimiento, su precio muy bajo podría hacer que su rentabilidad general sea competitiva. Para lograr esto, necesitamos métodos de evaluación más científicos y profesionales para determinar con precisión qué GPU y solución de inferencia ofrecen el mejor valor.
En nuestro “Enfoque de evaluación”, proponemos trazar los costos y las métricas de rendimiento de diferentes soluciones de inferencia en un sistema de coordenadas bidimensional, dividiendo el espacio en cuatro cuadrantes: Líderes, Seguidores, Desafiantes y Eliminados. Siguiendo este enfoque, nos centramos en probar los modelos Llama-3.1-70B, Llama-3.1-8B y sus versiones de cuantización FP8.
Seleccionamos cuatro GPU: RTX 4090, A100, H100 y H200, estableciendo la longitud de entrada/salida en 5000/500 y tamaños de lote de 1 a 10. Probamos varias combinaciones para obtener datos de rendimiento y precios, que finalmente se representaron en las dos figuras siguientes.
Para el modelo Llama-3.1-70B, las relaciones costo-rendimiento de cada solución se ilustran en la figura. Cuatro soluciones caen en nuestro cuadrante Líder definido:
- Llama3.1-70B-FP8@2xH100
- Llama3.1-70B-FP8@4xH200
- Llama3.1-70B@4xH200
- Llama3.1-70B@2xH100
En la figura, la pendiente de la línea que conecta el punto de coordenadas de cada solución con el origen representa la relación rendimiento/precio. Una pendiente más pronunciada indica una relación costo-beneficio más alta.
Por lo tanto, la solución Llama3.1-70B-FP8@4xH200 se destaca como la opción más rentable entre todas las soluciones de inferencia evaluadas.
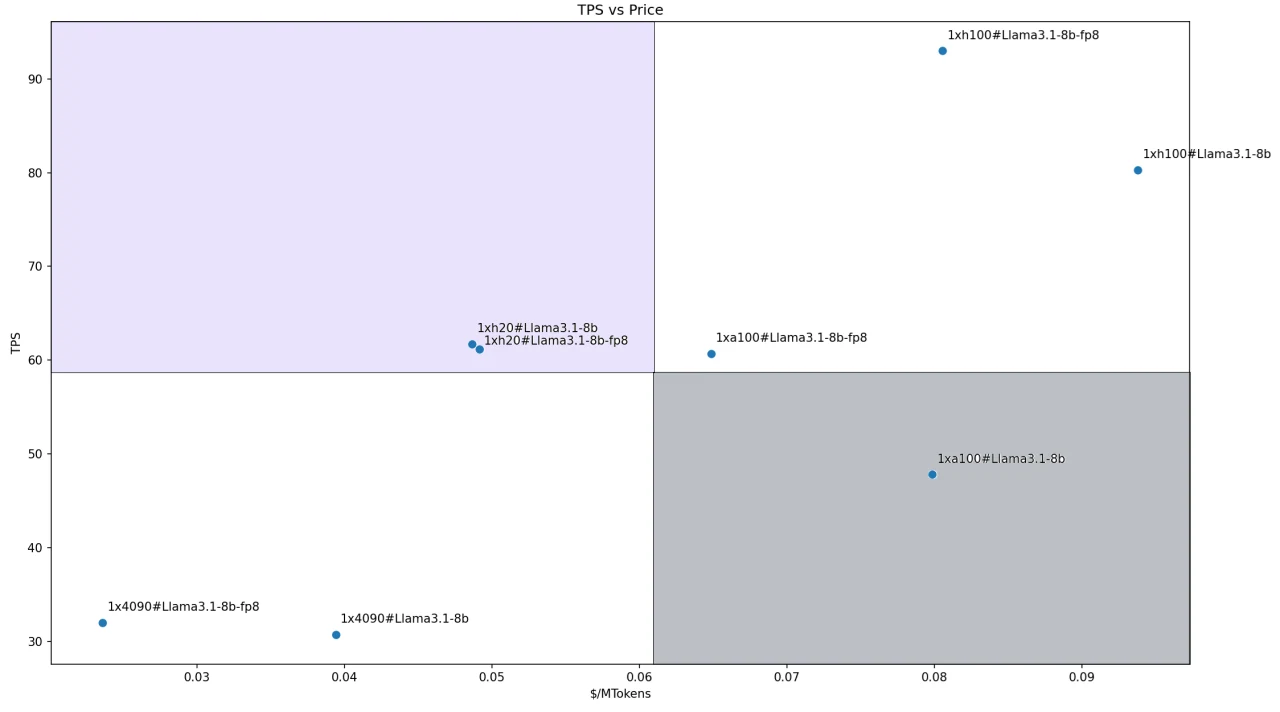
Para el modelo Llama3.1-8B, debido a su menor tamaño, implementamos todos los modelos utilizando una configuración de una sola GPU. Las relaciones costo-rendimiento de las diversas soluciones se ilustran en la figura siguiente. Ambas configuraciones con H200 caen en nuestro cuadrante Líder definido.
Esto se debe principalmente al buen rendimiento de H200 (especialmente su capacidad de memoria y ancho de banda líderes) y su precio competitivo. Las dos configuraciones de RTX 4090 son las más rentables, pero debido a su rendimiento inferior, caen en el cuadrante Seguidor.
Conclusión
Los costos de GPU representan una parte significativa de los servicios de inferencia de modelos grandes, y con la multitud de opciones de hardware de GPU disponibles en el mercado, seleccionar la más adecuada puede ser un desafío. Identificar la GPU y la solución de inferencia con la mejor relación costo-beneficio adaptada a las necesidades comerciales específicas es crucial, ya que puede determinar el éxito o el fracaso del negocio.
A través de nuestra experiencia en la prestación de servicios de inferencia de modelos grandes, hemos acumulado un conocimiento sustancial sobre implementación y hemos desarrollado un marco de evaluación de GPU efectivo que guía continuamente el desarrollo del negocio, ofreciendo a los clientes los servicios de inferencia con la mejor relación costo-beneficio.
Este artículo destila las mejores prácticas de aplicaciones prácticas y realiza pruebas del mundo real en modelos grandes y especificaciones de GPU populares, proporcionando comparaciones de rendimiento para identificar las soluciones de inferencia más rentables.
Nuestro enfoque de evaluación trasciende las métricas complejas de hardware, centrándose en aplicaciones comerciales prácticas, lo que lo hace altamente generalizable y procesable, especialmente adecuado para pruebas comparativas entre varios modelos de GPU o motores de inferencia.
¡Consulta Novita AI para obtener más información sobre los servicios y soluciones de inferencia de modelos grandes de primer nivel!
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona la GPU en la nube asequible y confiable para construir y escalar.
Lectura recomendada



