

TL;DR
Novita AI ha desarrollado un conjunto de optimizaciones probadas en producción y de alto impacto para desplegar modelos GLM4-MOE basados en SGLANG. Presentamos una estrategia de optimización de rendimiento integral que aborda los cuellos de botella en toda la tubería de inferencia, desde la eficiencia de ejecución del kernel hasta la programación de transferencia de datos entre nodos. Mediante la integración de Fusión de Expertos Compartidos y Decodificación de Sufijo, observamos mejoras sustanciales en métricas clave de producción, que incluyen:
- hasta un 65% de reducción en el Tiempo hasta el Primer Token (TTFT)
- un 22% de mejora en el Tiempo por Token de Salida (TPOT)
bajo cargas de trabajo de codificación agentiva.
Todos los resultados se validaron en clústeres H200 bajo configuraciones TP8 y FP8, proporcionando un plan probado en batalla para lograr tanto un rendimiento óptimo como una baja latencia en entornos de producción exigentes.
Cómo Implementamos Optimizaciones Clave de Producción para GLM-MoE
1. Fusión de Expertos Compartidos
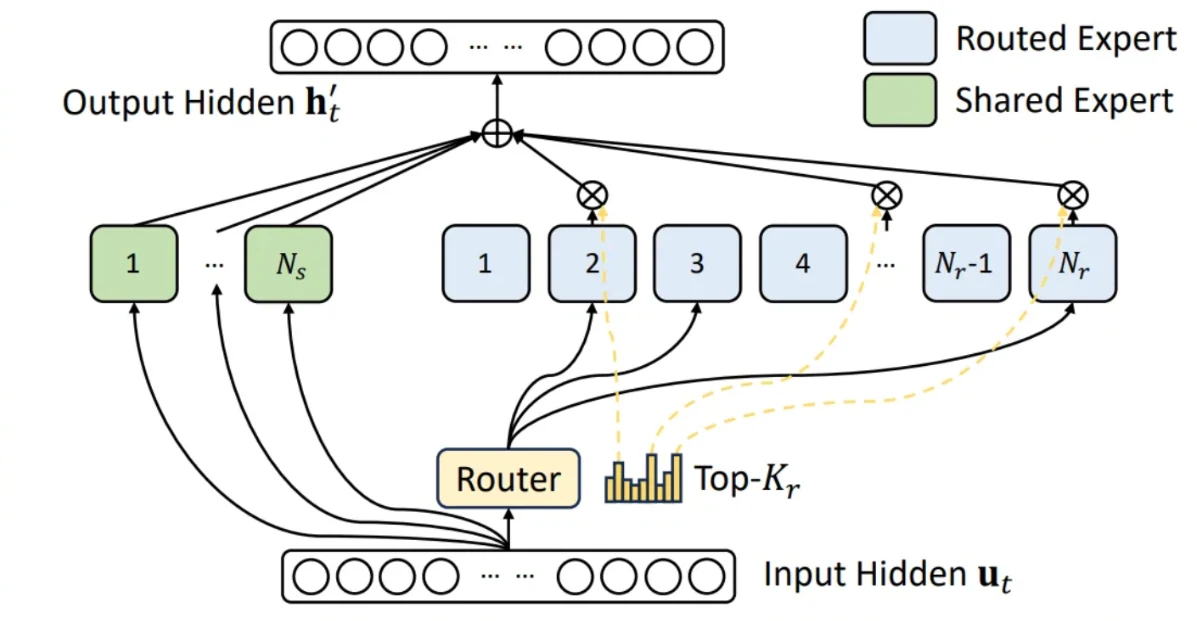
El crédito completo de esta optimización pertenece al trabajo original sobre el modelo Deepseek. Como se ilustra en la figura anterior, los modelos MoE como GLM4.7 enrutan todos los tokens de entrada a través de un experto compartido, mientras que cada token también se enruta individualmente a su propio conjunto de expertos enrutados top‑k seleccionados por el enrutador del modelo. Las salidas de todos los expertos luego se ponderan y agregan. GLM4.7, por ejemplo, emplea 160 expertos enrutados junto con un solo experto compartido, seleccionando los 8 expertos enrutados superiores por token. En implementaciones anteriores, estos dos componentes se manejaban por separado. Dado que comparten formas de tensor y procedimientos computacionales idénticos, es natural unificarlos fusionando el experto compartido en la estructura MoE enrutada, seleccionando los 9 mejores de un total de 161 expertos, con el experto compartido asignado consistentemente a la novena posición.
Como se documenta en el PR, esta optimización logra ganancias de rendimiento de hasta un 23.7% en TTFT y un 20.8% en ITL. Estas ganancias son esperadas porque, bajo configuraciones TP8 y FP8, donde el tamaño intermedio es solo 192, que es relativamente pequeño para hardware H200, la operación de fusión aumenta sustancialmente la utilización del Multiprocesador de Flujo (SM) y reduce significativamente la sobrecarga de E/S de memoria.
2. Fusión Qknorm
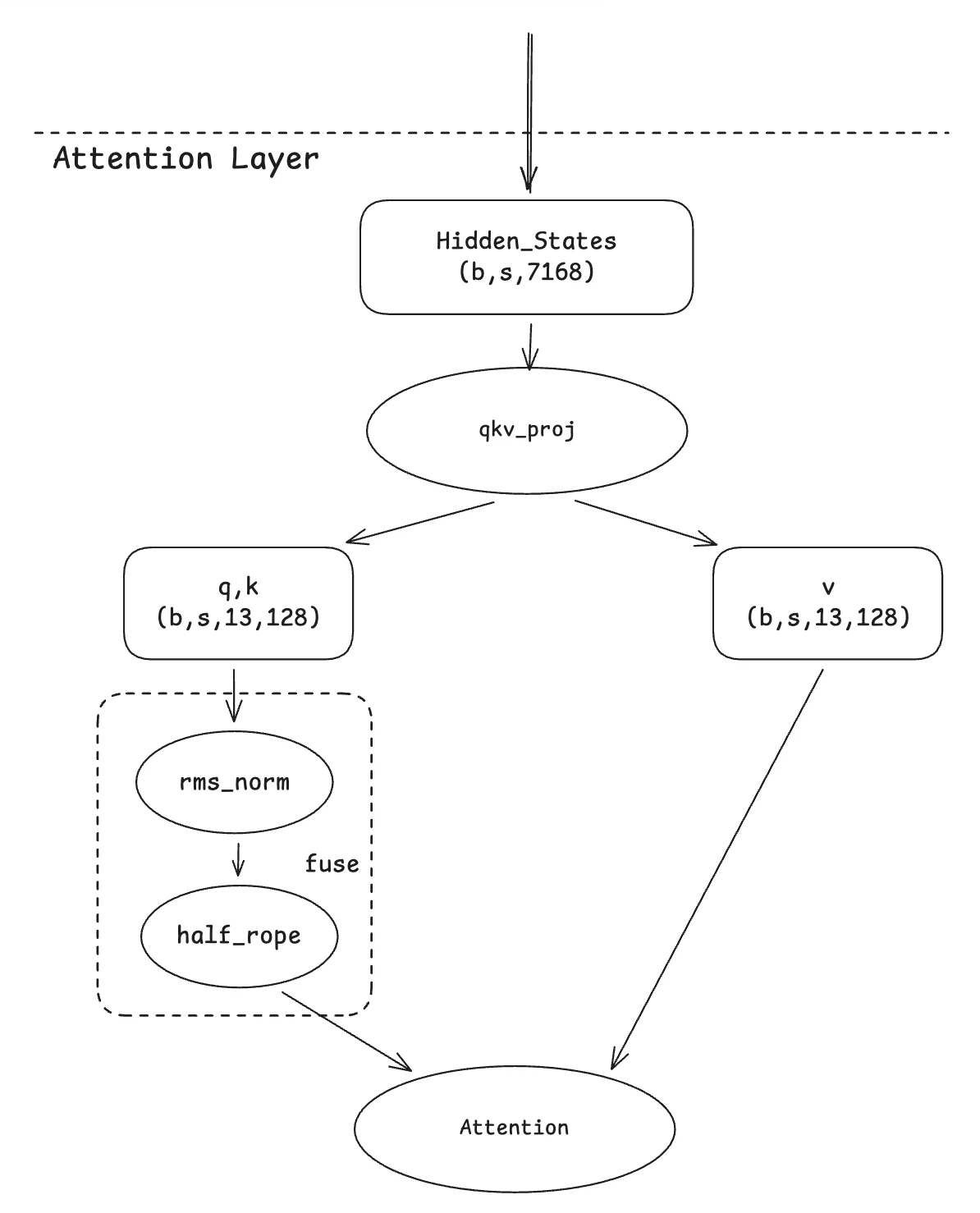
Esta migración se basa en la optimización de Qwen-MOE. La idea subyacente es sencilla. Dado que ambos operadores realizan cálculos por cabeza, es un enfoque natural fusionarlos en un solo kernel. Nuestra contribución radica en adaptar este kernel fusionado para acomodar el caso específico de la variante GLM4-MOE, donde solo la mitad de las dimensiones dentro de una cabeza se rotan.
3. Transferencia Asíncrona
https://github.com/sgl-project/sglang/pull/14782
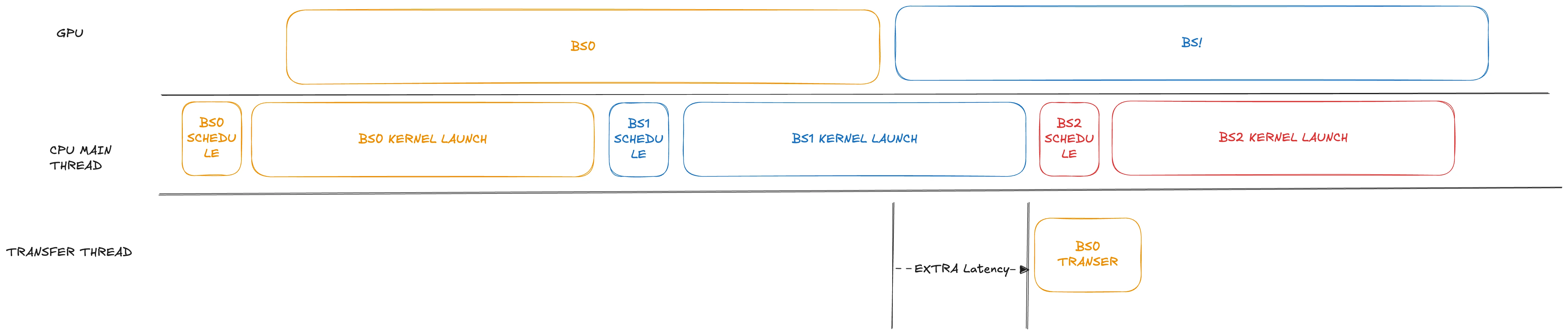
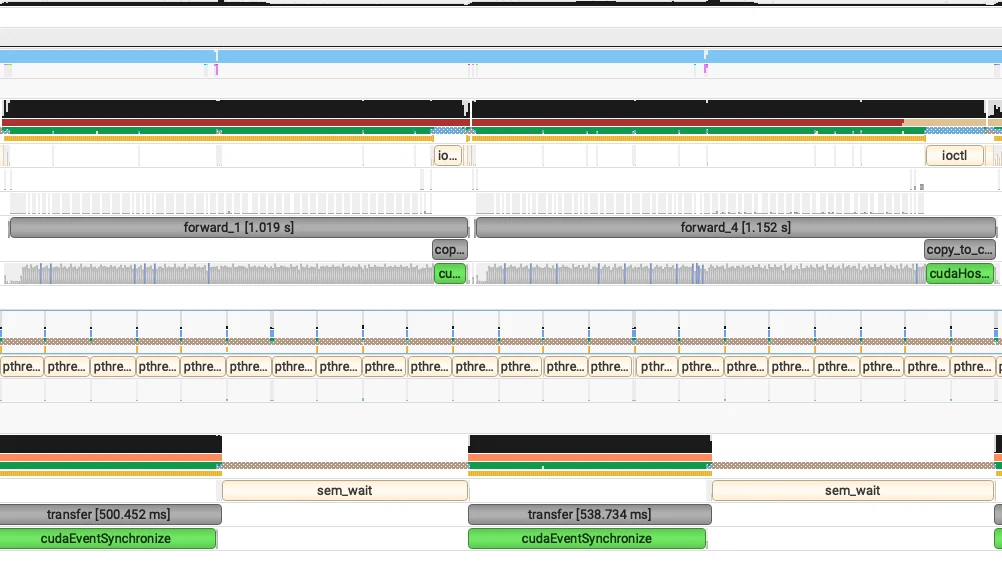
En escenarios donde se aplica la desagregación PD con programación superpuesta, aunque el rendimiento puede aumentar aproximadamente un 10%, el TTFT disminuye significativamente. Observamos que en la implementación actual de prefill, el proceso de transferencia de datos se retrasa hasta después del lanzamiento del kernel para el siguiente lote. Para un modelo como GLM4.7, que consta de 92 capas, el lanzamiento del kernel sin CUDA Graph puede consumir mucho tiempo (a menudo tomando cientos de milisegundos, incluso más de 1 segundo).
Para abordar esto, en nuestra modificación adelantamos ligeramente el paso de transferencia, programándolo justo después de que se completen sus operaciones de GPU correspondientes. Además, la transferencia se coloca en un hilo separado. Al manejar cuidadosamente las posibles estructuras de riesgo de carrera de datos, puede proceder sin bloquear el hilo principal.
El rendimiento es enorme para modelos con muchos lanzamientos de kernel. Cuando está bajo cargas de trabajo pesadas, esta optimización puede ahorrar hasta 1 segundo en términos de TTFT como se muestra a continuación.
Resultados de Benchmark en Producción
Después de implementar los enfoques descritos anteriormente, observamos mejoras significativas en el rendimiento de los modelos GLM-MOE, como se demuestra claramente en los resultados de benchmark a continuación.
Configuración del benchmark
- Longitud de entrada: 4096
- Longitud de salida: 1000
- Tasa de solicitudes: 14 req/s
- Modelo: GLM-4.7 FP8 (TP8)
Resultados
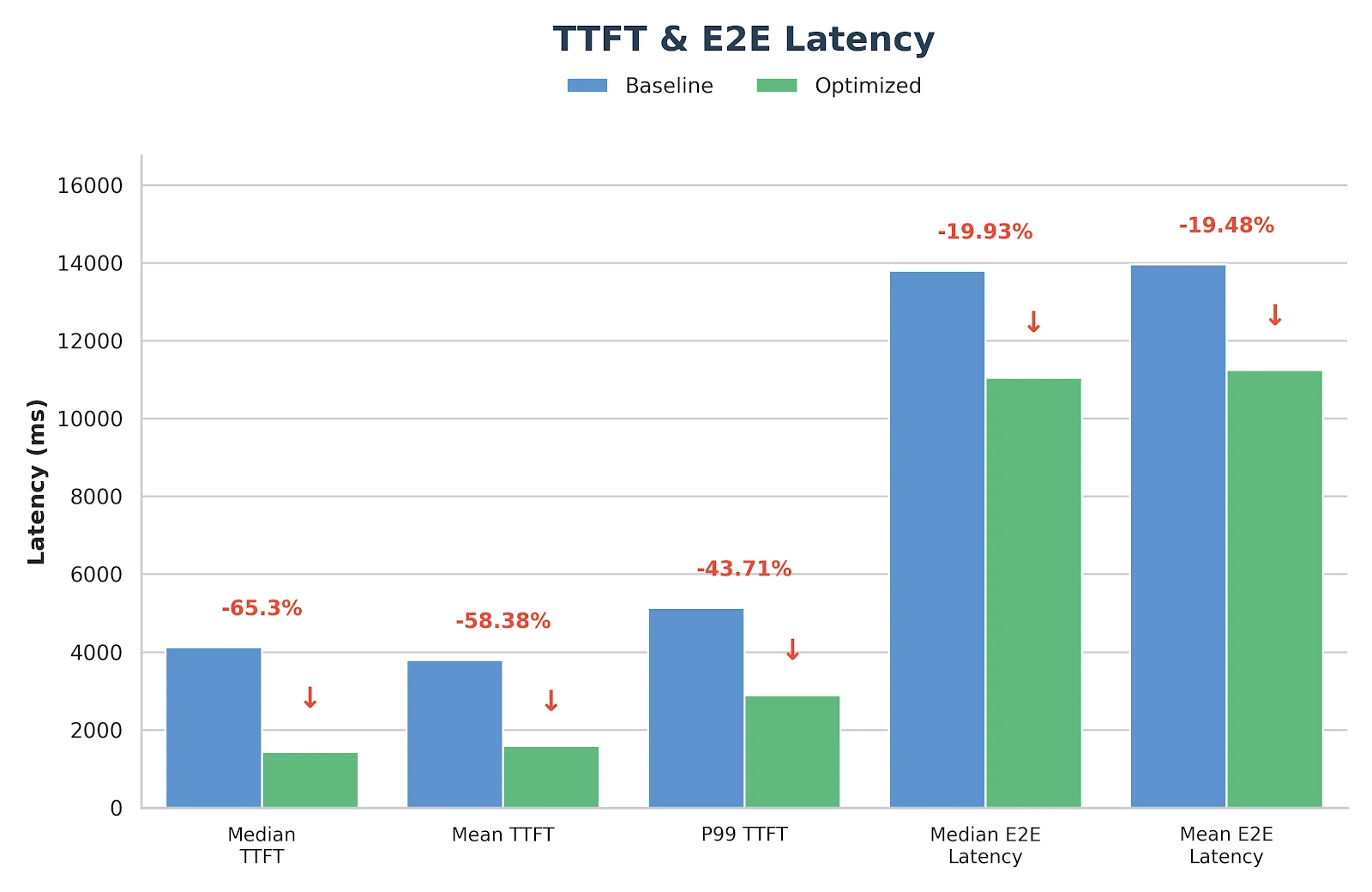
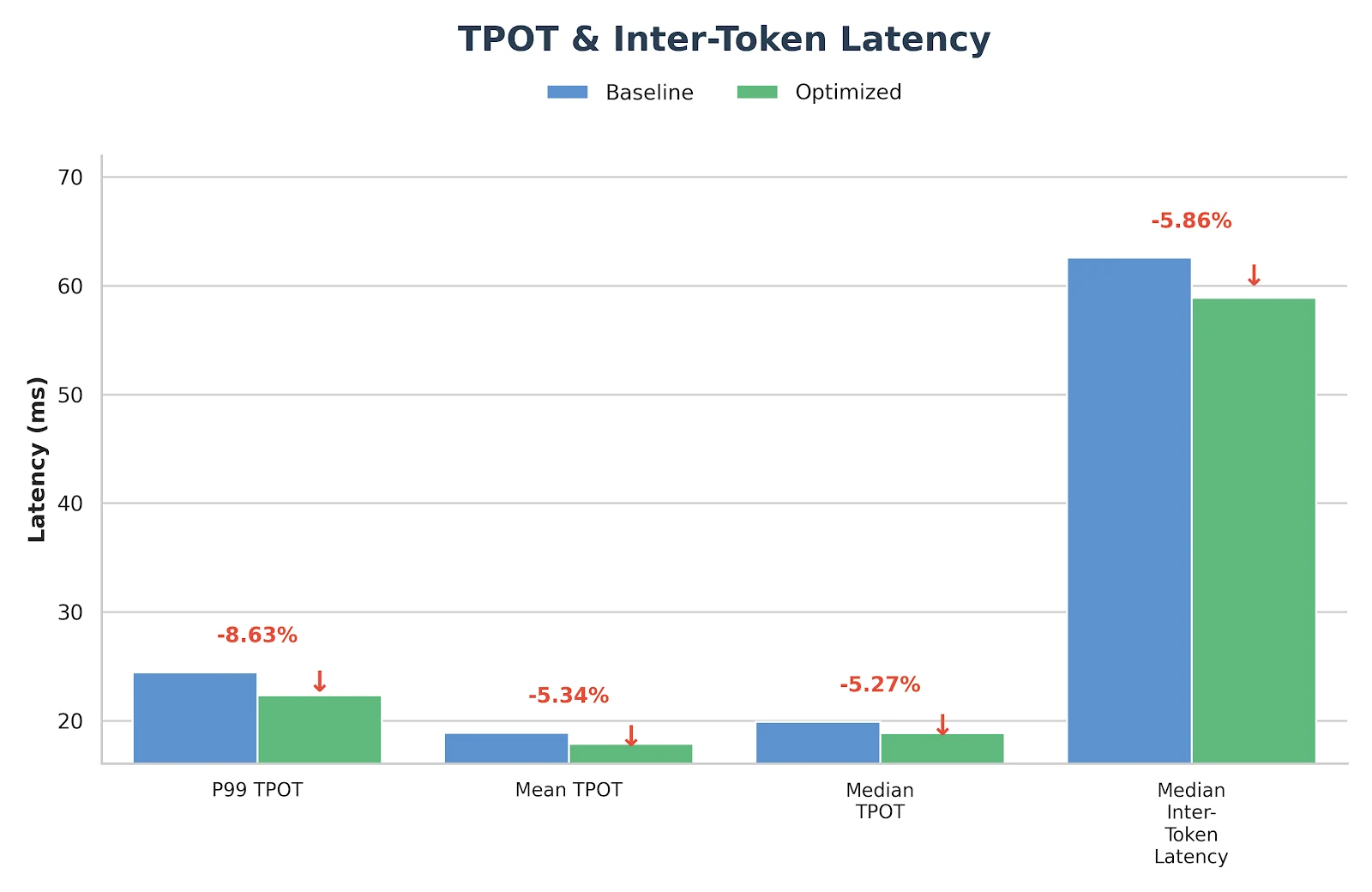
Estas optimizaciones no son solo experimentales, ya se han desplegado y validado en el servicio de inferencia de producción de Novita.ai. Si buscas un backend GLM-MoE fiable y de baja latencia para cargas de trabajo del mundo real, eres bienvenido a probarlo directamente en novita.ai.
Decodificación por Sufijo
Los escenarios de codificación agentiva (como Cursor y Claude Code) exhiben un alto volumen de patrones de código reutilizables, lo que permite optimizaciones de rendimiento específicas como la Decodificación por Sufijo.
Antecedentes: El cuello de botella de inferencia en la codificación agentiva
Los Agentes LLM sobresalen en tareas de generación de código, pero la latencia sigue siendo un desafío significativo. La Decodificación Especulativa tradicional acelera la inferencia prediciendo múltiples tokens por adelantado, pero los enfoques comunes requieren entrenar modelos borrador adicionales, lo que introduce complejidad de ingeniería.
Cómo funciona la Decodificación por Sufijo
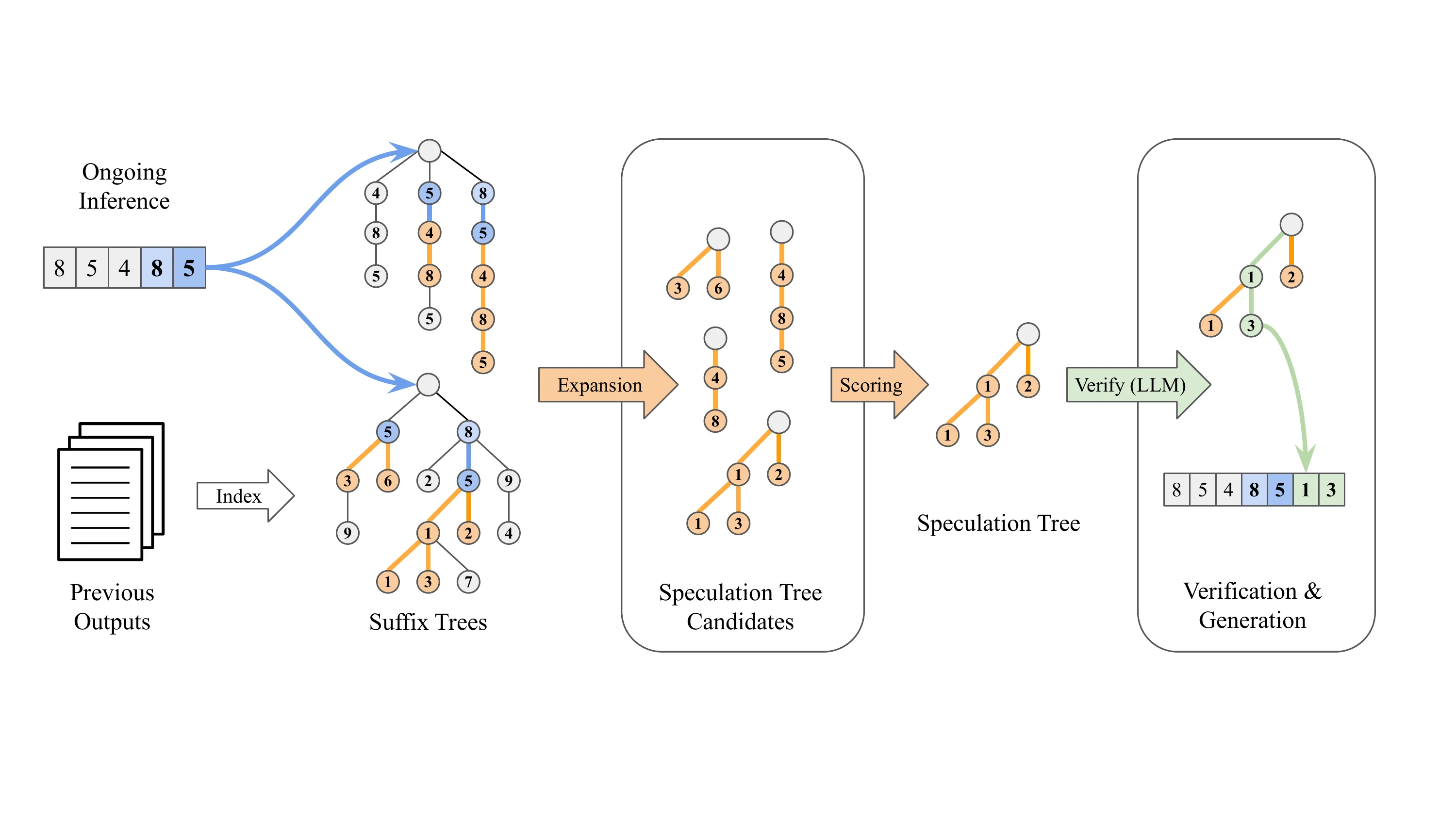
La Decodificación por Sufijo adopta un enfoque fundamentalmente diferente: es completamente libre de modelos:
- Sin dependencia de pesos de modelos adicionales
- Aprovecha patrones de secuencias de salida generadas previamente para predecir tokens futuros
- Cuando el sufijo de la solicitud actual coincide con un patrón histórico, continúa a lo largo de esa secuencia histórica para la especulación
Validación de datos: Análisis de repetición de patrones de salida
Al analizar 22 sesiones de Claude Code (17,487 turnos de conversación), descubrimos:
- 39.3% de repetición de patrón de salida: Alta frecuencia de llamadas a herramientas y patrones de respuesta similares
- Comportamientos agentivos altamente estructurados: Frases fijas como “Déjame…”, “Ahora déjame…” aparecen con frecuencia
Para apoyar más investigación, hemos publicado el conjunto de datos de evaluación en Hugging Face: https://huggingface.co/datasets/novita/agentic_code_dataset_22
Comparación de rendimiento
Con la aceleración MTP integrada, la Decodificación por Sufijo reduce aún más el TPOT en un 22% (de 25.13 ms a 19.63 ms):
| Métrica | MTP | Decodificación por Sufijo | Cambio |
| TPOT medio | 25.13 ms | 19.63 ms | -21.90% |
| TPOT mediano | 25.95 ms | 20.05 ms | -22.70% |
Conclusión
La combinación de estas optimizaciones proporciona mejoras integrales de rendimiento para despliegues de SGLANG:
- Fusión de Expertos Compartidos aborda la eficiencia computacional en modelos MoE
- Fusión QK-Norm-RoPE reduce la sobrecarga de lanzamiento del kernel
- Transferencia Asíncrona optimiza el movimiento de datos en despliegues desagregados
- Decodificación por Sufijo aprovecha la repetición de patrones para decodificación especulativa en codificación agentiva.
La mayoría de los componentes ya se han fusionado en la rama principal o están en proceso de integración; no dudes en echarles un vistazo en el repositorio de SGLang.
Cómo Reproducir
Aquí solo se muestran los parámetros clave relevantes para el rendimiento.
Los scripts de lanzamiento completos (línea base frente a optimizado), el arnés de benchmark y los trazados de perfil se publican en nuestro GitHub: https://github.com/novitalabs/sglang/tree/glm_suffix.
- Indicadores de optimización clave (tiempo de ejecución de SGLang)
--tp-size 8
--kv-cache-dtype fp8_e4m3
--attention-backend fa3
--chunked-prefill-size 16384
--enable-flashinfer-allreduce-fusion
--enable-fused-qk-norm-rope
--enable-shared-experts-fusion
--disaggregation-async-transfer
- Configuración de decodificación especulativa (carga de trabajo de codificación agentiva)
--speculative-algorithm NEXTN
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 4
- Configuración de Decodificación por Sufijo (opcional)
--speculative-algorithm SUFFIX
--speculative-suffix-cache-max-depth 64
--speculative-suffix-max-spec-factor 1.0
--speculative-suffix-min-token-prob 0.1
Referencias
- PR #13873 de SGLANG: Optimización de Expertos Compartidos
- Blog de Ingeniería de Snowflake: SuffixDecoding a Escala de Producción
- Artículo de NeurIPS: SuffixDecoding
- Repositorio de Arctic Inference
Novita AI es una plataforma líder en la nube de IA que proporciona a los desarrolladores APIs fáciles de usar e infraestructura de GPU asequible y fiable para construir y escalar aplicaciones de IA.



