

TL;DR
Novita AI разработала набор протестированных в продакшене высокоэффективных оптимизаций для развертывания моделей GLM4-MoE на основе SGLANG. Мы представляем сквозную стратегию оптимизации производительности, которая устраняет узкие места во всем конвейере вывода — от эффективности выполнения ядер до планирования передачи данных между узлами. Благодаря интеграции Fusion общих экспертов (Shared Experts Fusion) и декодирования суффиксов (Suffix Decoding) мы наблюдаем значительный прирост ключевых метрик продакшена, в том числе:
- снижение времени до первого токена (TTFT) до 65%
- улучшение времени на выходной токен (TPOT) на 22% при рабочих нагрузках агентного программирования.
Все результаты были валидированы на кластерах H200 в конфигурациях TP8 и FP8, что дает проверенный на практике план достижения оптимальной пропускной способности и низкой задержки в требовательных продакшен-средах.
Как мы реализовали основные продакшен-оптимизации для GLM-MoE
1. Fusion общих экспертов (Shared Experts Fusion)
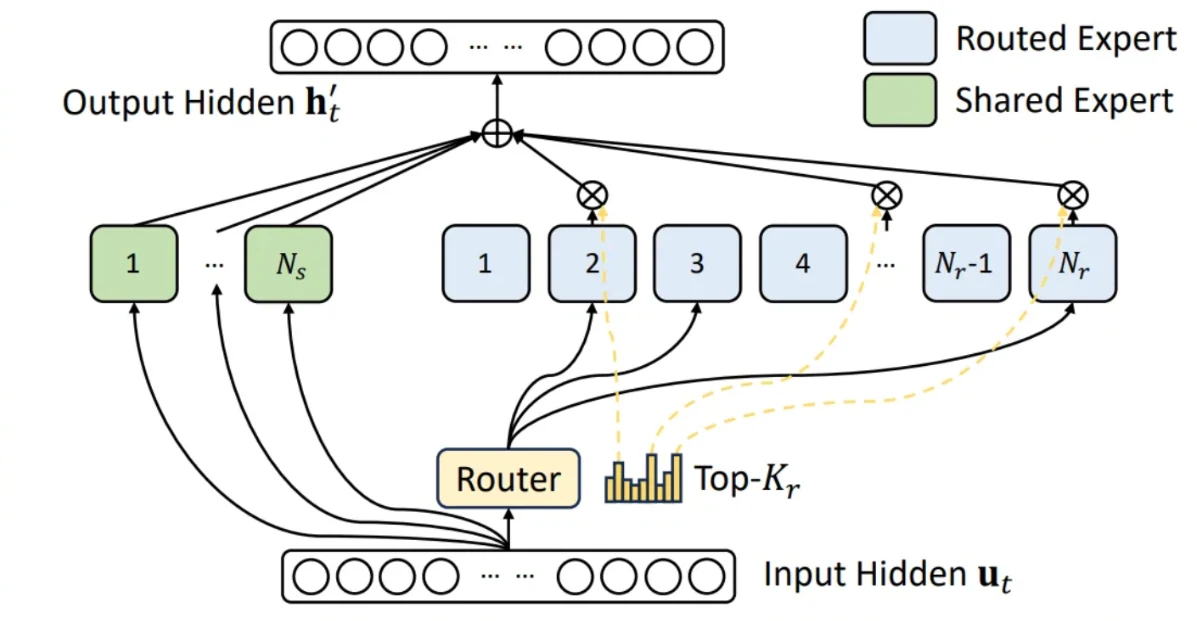
Полная заслуга этой оптимизации принадлежит исходной работе над моделью Deepseek. Как показано на рисунке выше, модели MoE, такие как GLM4.7, пропускают все входные токены через общего эксперта, при этом каждый токен также индивидуально маршрутизируется в свой набор топ-k маршрутизируемых экспертов, выбранных маршрутизатором модели. Выходы всех экспертов затем взвешиваются и агрегируются. Например, GLM4.7 использует 160 маршрутизируемых экспертов вместе с одним общим экспертом, выбирая топ-8 маршрутизируемых экспертов для каждого токена. В ранних реализациях эти два компонента обрабатывались раздельно. Учитывая, что они имеют идентичные формы тензоров и вычислительные процедуры, естественно объединить их, включив общего эксперта в структуру маршрутизируемого MoE: выбирается топ-9 из общего числа 161 эксперта, при этом общий эксперт стабильно занимает 9-ю позицию.
Как указано в PR, эта оптимизация дает прирост производительности до 23.7% по TTFT и 20.8% по ITL. Этот прирост ожидаем, поскольку в конфигурациях TP8 и FP8, где промежуточный размер составляет всего 192, что относительно мало для оборудования H200, операция fusion значительно повышает утилизацию мультипроцессорных потоков (Streaming Multiprocessor, SM) и существенно снижает накладные расходы на ввод-вывод памяти.
2. Слияние QK-нормы (Qknorm Fusion)
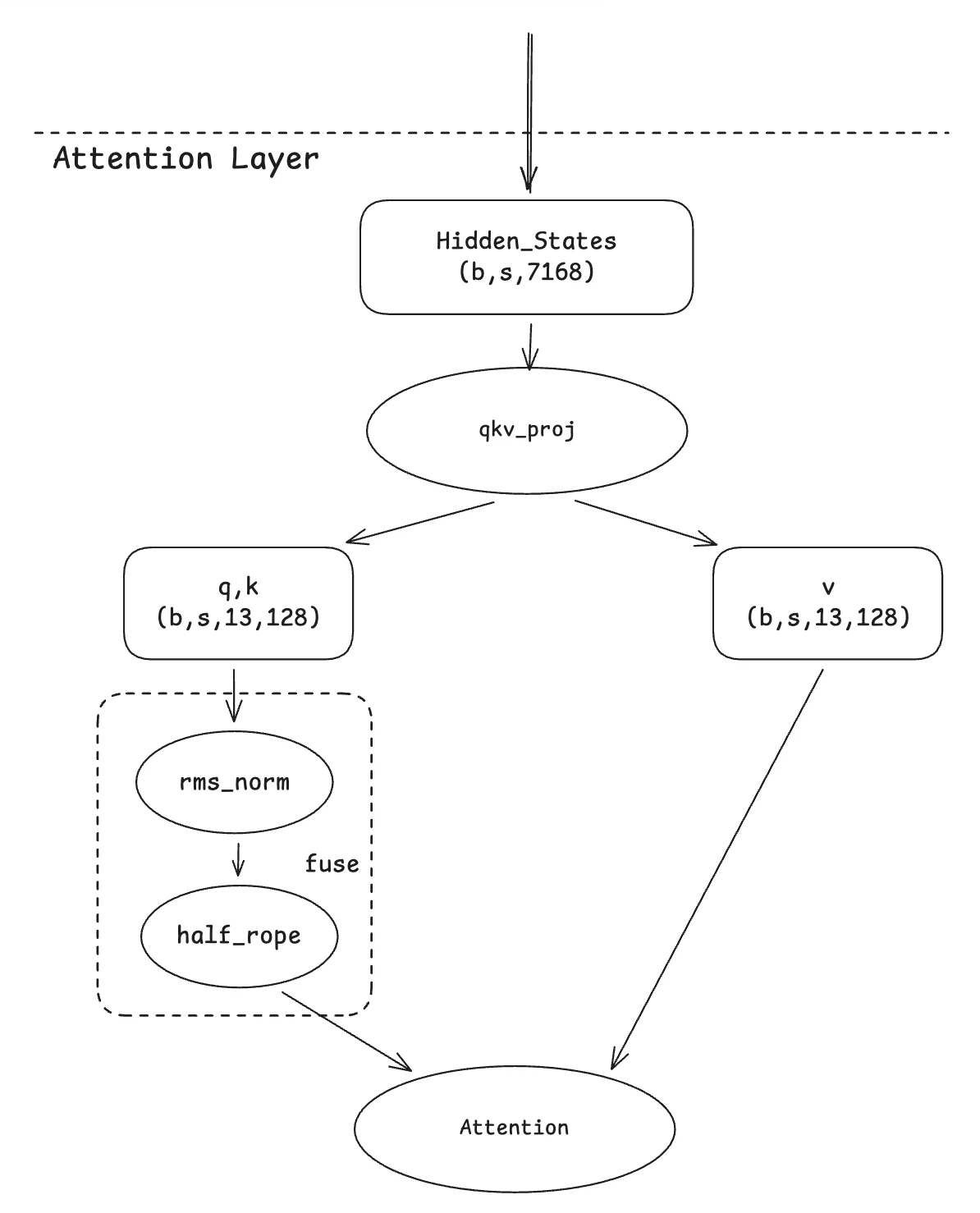
Эта миграция основана на оптимизации из Qwen-MOE. Основная идея проста: поскольку оба оператора выполняют вычисления отдельно для каждой головы внимания, естественным решением является их объединение в одно ядро. Наш вклад заключается в адаптации этого объединенного ядра под специфику варианта GLM4-MoE, в котором только половина измерений внутри головы подвергается вращению.
3. Асинхронная передача (Async Transfer)
https://github.com/sgl-project/sglang/pull/14782
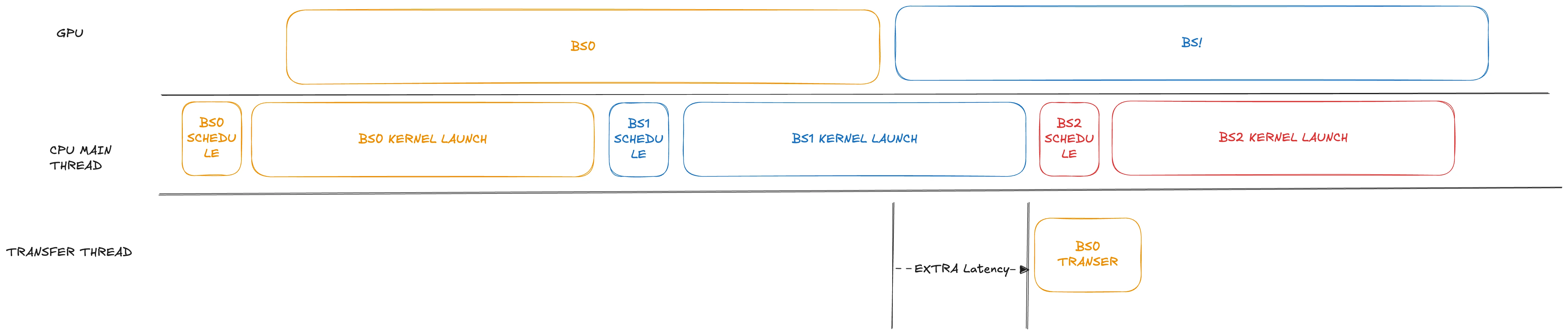
В сценариях, где применяется PD-дизагрегация с накладывающимися расписаниями, хотя пропускная способность может вырасти примерно на 10%, TTFT значительно падает. Мы обнаружили, что в текущей реализации prefill процесс передачи данных откладывается до после запуска ядра для следующей партии токенов. Для такой модели, как GLM4.7, состоящей из 92 слоев, запуск ядра без CUDA Graph может быть очень затратным по времени (часто занимает сотни миллисекунд, а иногда и более 1 секунды).
Чтобы решить эту проблему, в нашей модификации мы немного сдвигаем этап передачи вперед, планируя его сразу после завершения соответствующих операций на GPU. Кроме того, передача выполняется в отдельном потоке. При аккуратной обработке потенциальных структур гонки данных она может выполняться без блокировки основного потока.
Прирост производительности огромен для моделей с большим количеством запусков ядер. При тяжелых рабочих нагрузках эта оптимизация может сэкономить до 1 секунды по метрике TTFT, как показано ниже.
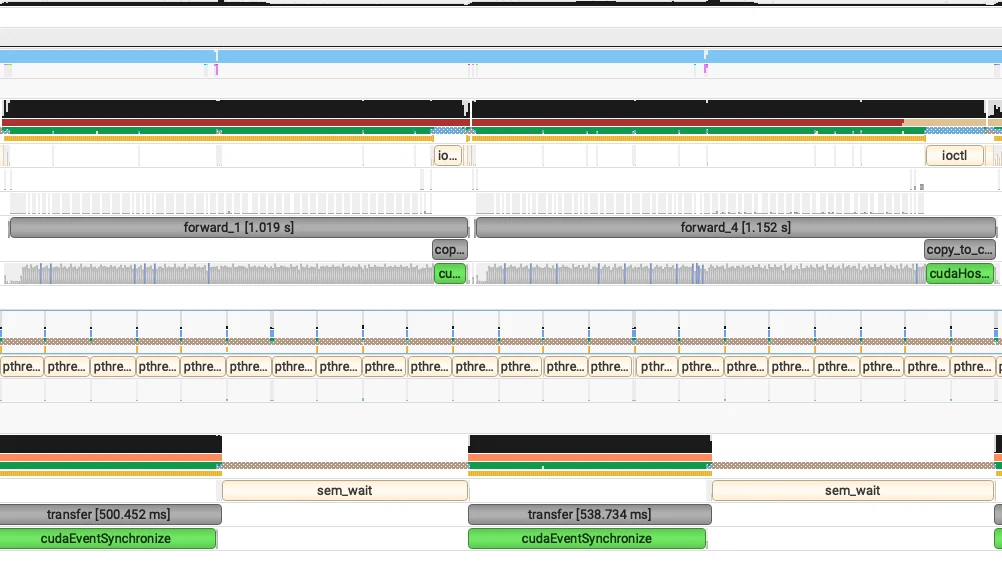
Результаты продакшен-бенчмарков
После реализации описанных выше подходов мы наблюдали значительный прирост производительности для моделей GLM-MoE, что наглядно демонстрируют результаты бенчмарка ниже.
Конфигурация бенчмарка
- Длина входных данных: 4096
- Длина выходных данных: 1000
- Частота запросов: 14 запросов/с
- Модель: GLM-4.7 FP8 (TP8)
Результаты
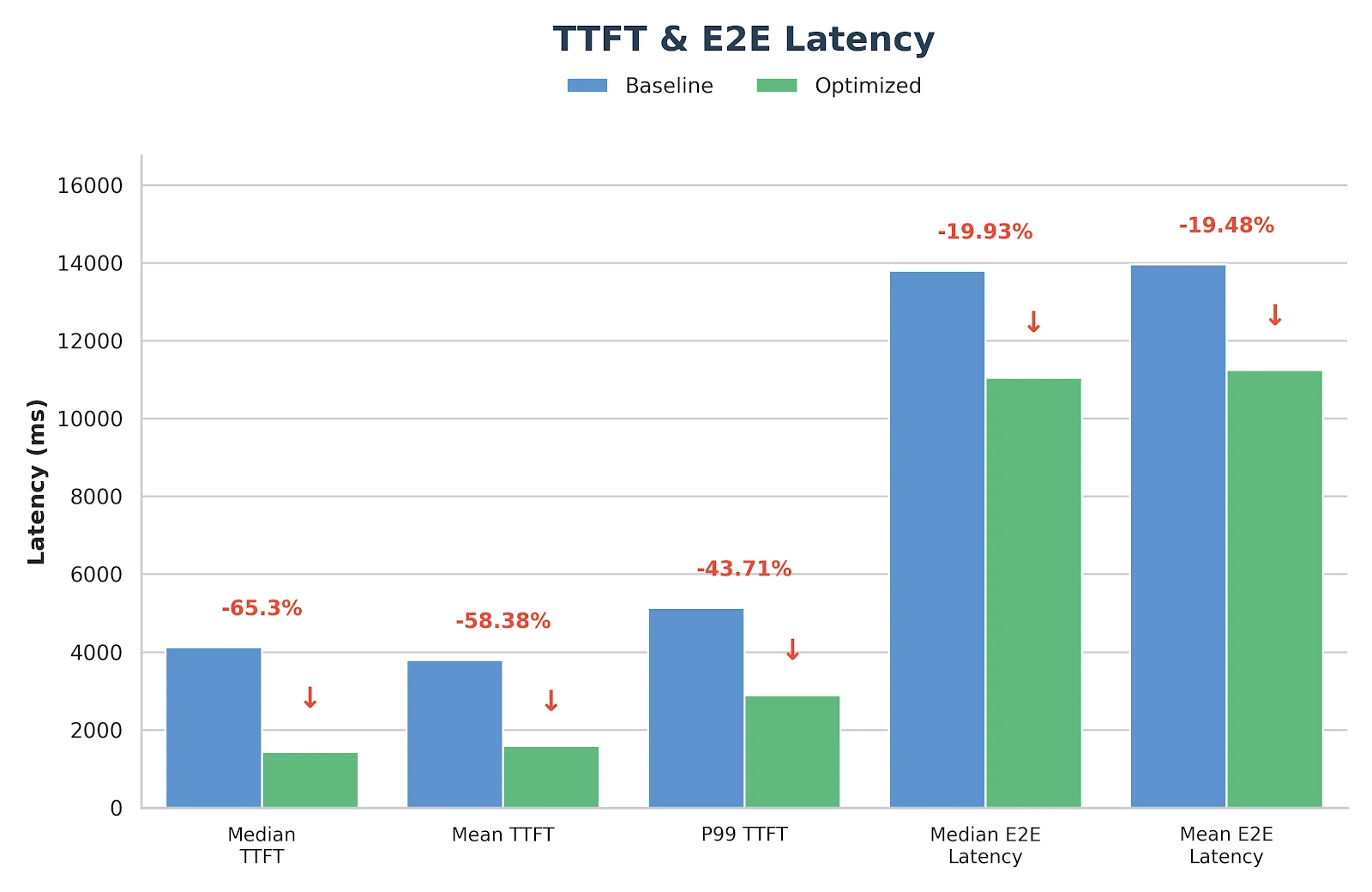
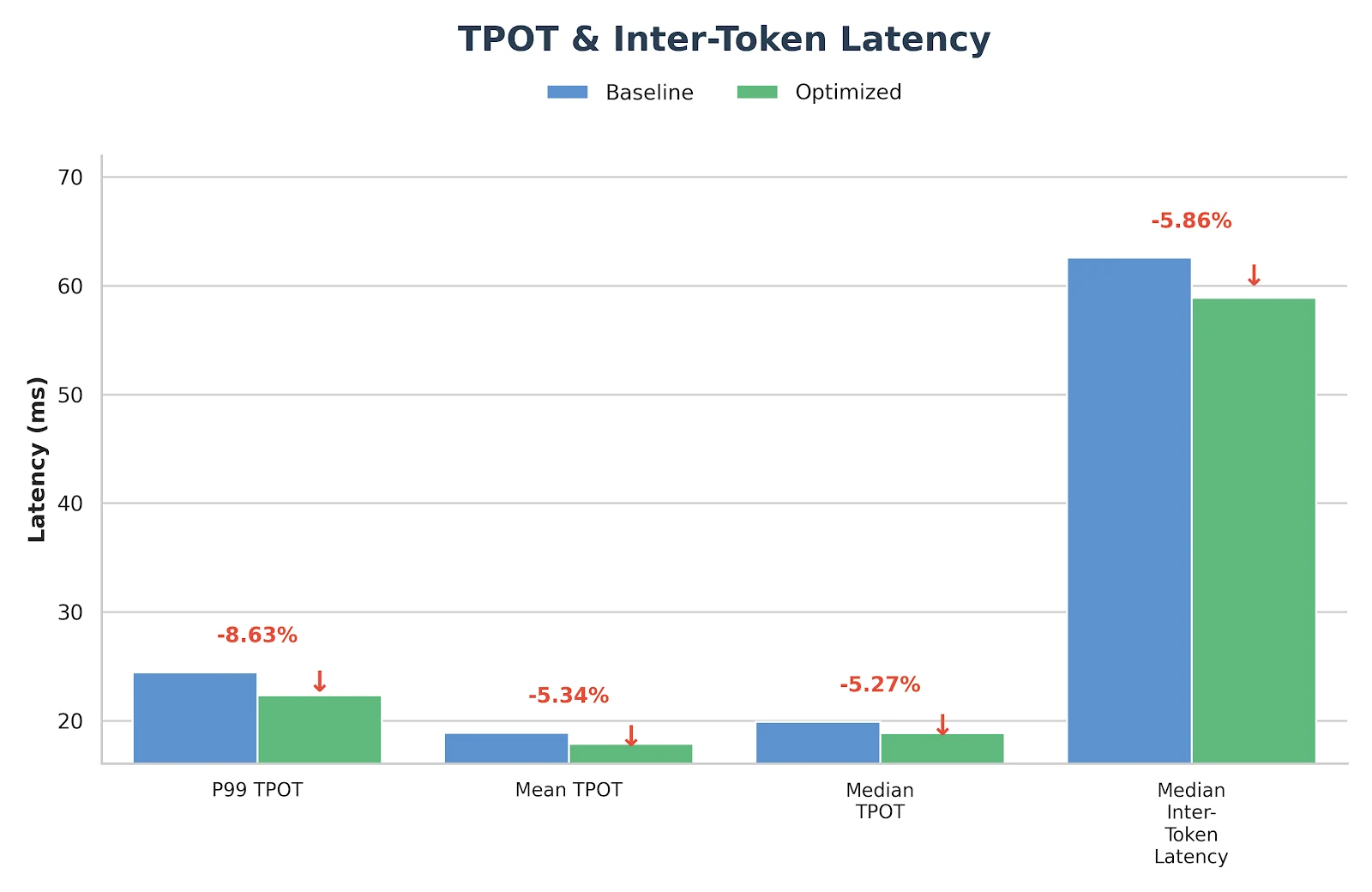
Эти оптимизации не являются чисто экспериментальными — они уже развернуты и валидированы в продакшен-сервисе вывода Novita.ai. Если вы ищете надежный бэкенд GLM-MoE с низкой задержкой для реальных рабочих нагрузок, вы можете попробовать его напрямую на novita.ai.
Декодирование суффиксов (Suffix Decoding)
Сценарии агентного программирования (такие как Cursor и Claude Code) характеризуются большим объемом повторно используемых шаблонов кода, что позволяет применять целевые производительные оптимизации, такие как декодирование суффиксов (Suffix Decoding).
Предыстория: Узкое место вывода в сценариях агентного программирования
Агенты LLM превосходно справляются с задачами генерации кода, но задержка остается серьезной проблемой. Традиционное спекулятивное декодирование (Speculative Decoding) ускоряет вывод, предсказывая несколько токенов заранее, но распространенные подходы требуют обучения дополнительных моделей-черновиков, что добавляет инженерной сложности.
Как работает декодирование суффиксов
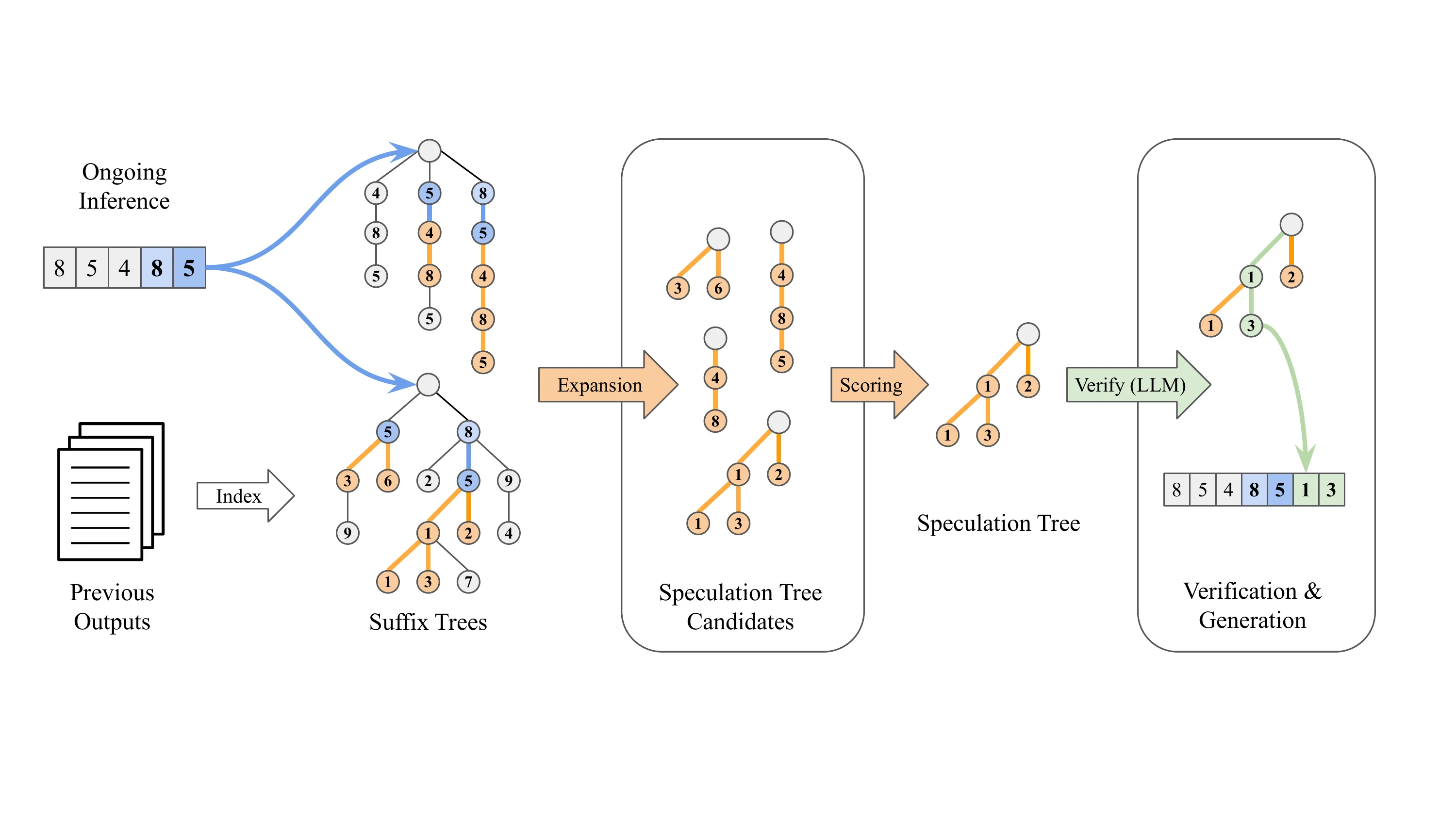
Декодирование суффиксов использует принципиально иной подход — оно полностью не требует наличия дополнительных моделей:
- Не зависит от дополнительных весов моделей
- Использует шаблоны из ранее сгенерированных выходных последовательностей для предсказания предстоящих токенов
- Если суффикс текущего запроса совпадает с историческим шаблоном, оно продолжает следовать этой исторической последовательности для спекуляции
Валидация данных: Анализ повторения шаблонов выходных данных
При анализе 22 сессий Claude Code (17 487 оборотов диалога) мы обнаружили:
- Повторение шаблонов выходных данных в 39,3% случаев: Высокая частота похожих вызовов инструментов и шаблонов ответов
- Высокоструктурированное поведение агентов: Часто появляются фиксированные фразы вида «Let me…», «Now let me…»
Для поддержки дальнейших исследований мы открыли датасет для оценки на Hugging Face: https://huggingface.co/datasets/novita/agentic_code_dataset_22
Сравнение производительности
При встроенном ускорении MTP декодирование суффиксов дополнительно снижает TPOT на 22% (с 25,13 мс до 19,63 мс):
| Метрика | MTP | Декодирование суффиксов | Изменение |
| Средний TPOT | 25,13 мс | 19,63 мс | -21,90% |
| Медианный TPOT | 25,95 мс | 20,05 мс | -22,70% |
Заключение
Комбинация этих оптимизаций обеспечивает комплексный прирост производительности для развертываний SGLANG:
- Fusion общих экспертов (Shared Experts Fusion) решает проблему вычислительной эффективности в моделях MoE
- Fusion QK-Norm-RoPE снижает накладные расходы на запуск ядер
- Асинхронная передача (Async Transfer) оптимизирует перемещение данных в дизагрегированных развертываниях
- Декодирование суффиксов (Suffix Decoding) использует повторение шаблонов для спекулятивного декодирования в сценариях агентного программирования.
Большинство компонентов уже объединены в основную ветку (upstream) или находятся в процессе интеграции; не стесняйтесь ознакомиться с ними в репозитории SGLang.
Как воспроизвести результаты
Здесь показаны только ключевые параметры, влияющие на производительность.
Полные скрипты запуска (базовый вариант против оптимизированного), инфраструктура для бенчмарков и трассировки профилирования опубликованы в нашем GitHub:https://github.com/novitalabs/sglang/tree/glm\_suffix.
- Ключевые флаги оптимизации (среда выполнения SGLang)
--tp-size 8
--kv-cache-dtype fp8_e4m3
--attention-backend fa3
--chunked-prefill-size 16384
--enable-flashinfer-allreduce-fusion
--enable-fused-qk-norm-rope
--enable-shared-experts-fusion
--disaggregation-async-transfer
- Конфигурация спекулятивного декодирования (рабочая нагрузка агентного программирования)
--speculative-algorithm NEXTN
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 4
- Конфигурация декодирования суффиксов (опционально)
--speculative-algorithm SUFFIX
--speculative-suffix-cache-max-depth 64
--speculative-suffix-max-spec-factor 1.0
--speculative-suffix-min-token-prob 0.1
Ссылки
- PR SGLANG #13873: Оптимизация общих экспертов
- Инженерный блог Snowflake: Декодирование суффиксов в промышленном масштабе
- Статья NeurIPS: Декодирование суффиксов
- Репозиторий Arctic Inference
Novita AI — ведущая AI-облачная платформа, которая предоставляет разработчикам простые в использовании API и доступную, надежную GPU-инфраструктуру для создания и масштабирования AI-приложений.


