

TL;DR
Um conjunto de otimizações de alto impacto, testadas em produção, foi desenvolvido pela Novita AI para a implantação de modelos GLM4-MoE baseados no SGLang. Apresentamos uma estratégia de otimização de desempenho ponta a ponta que resolve gargalos em todo o pipeline de inferência — da eficiência de execução de kernels ao agendamento de transferência de dados entre nós. Com a integração da Fusão de Especialistas Compartilhados e da Decodificação de Sufixo, observamos ganhos substanciais nas principais métricas de produção, incluindo:
- redução de até 65% no Tempo até o Primeiro Token (TTFT)
- melhoria de 22% no Tempo por Token de Saída (TPOT)
em cargas de trabalho de codificação agentiva.
Todos os resultados foram validados em clusters H200 em configurações TP8 e FP8, fornecendo um plano testado em cenários reais para alcançar tanto throughput ideal quanto baixa latência em ambientes de produção exigentes.
Como Implementamos as Otimizações Principais de Produção para o GLM-MoE
1. Fusão de Especialistas Compartilhados
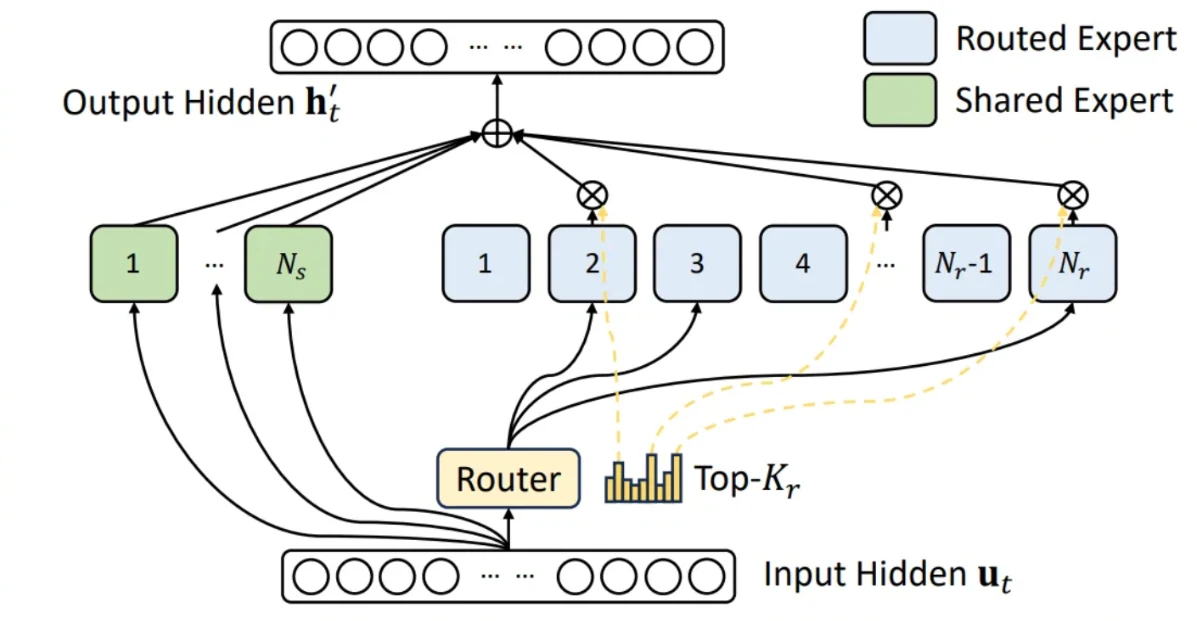
Todo o crédito por essa otimização pertence ao trabalho original no modelo Deepseek. Conforme ilustrado na figura acima, modelos MoE como o GLM4.7 roteiam todos os tokens de entrada por um especialista compartilhado, enquanto cada token também é roteado individualmente para seu próprio conjunto de especialistas roteados top-k, conforme selecionado pelo roteador do modelo. As saídas de todos os especialistas são então ponderadas e agregadas. O GLM4.7, por exemplo, emprega 160 especialistas roteados juntamente com um único especialista compartilhado, selecionando os 8 principais especialistas roteados por token. Em implementações anteriores, esses dois componentes eram tratados separadamente. Dado que eles compartilham formas de tensor e procedimentos computacionais idênticos, é natural unificá-los mesclando o especialista compartilhado na estrutura MoE roteada — selecionando os 9 principais entre o total de 161 especialistas, com o especialista compartilhado sempre atribuído à 9ª posição.
Conforme documentado no PR, essa otimização alcança ganhos de desempenho de até 23,7% no TTFT e 20,8% no ITL. Esses ganhos são esperados porque, em configurações TP8 e FP8 — onde o tamanho intermediário é de apenas 192, que é relativamente pequeno para o hardware H200 — a operação de fusão aumenta substancialmente a utilização do Multiprocessador de Streaming (SM) e reduz significativamente a sobrecarga de E/S de memória.
2. Fusão Qknorm
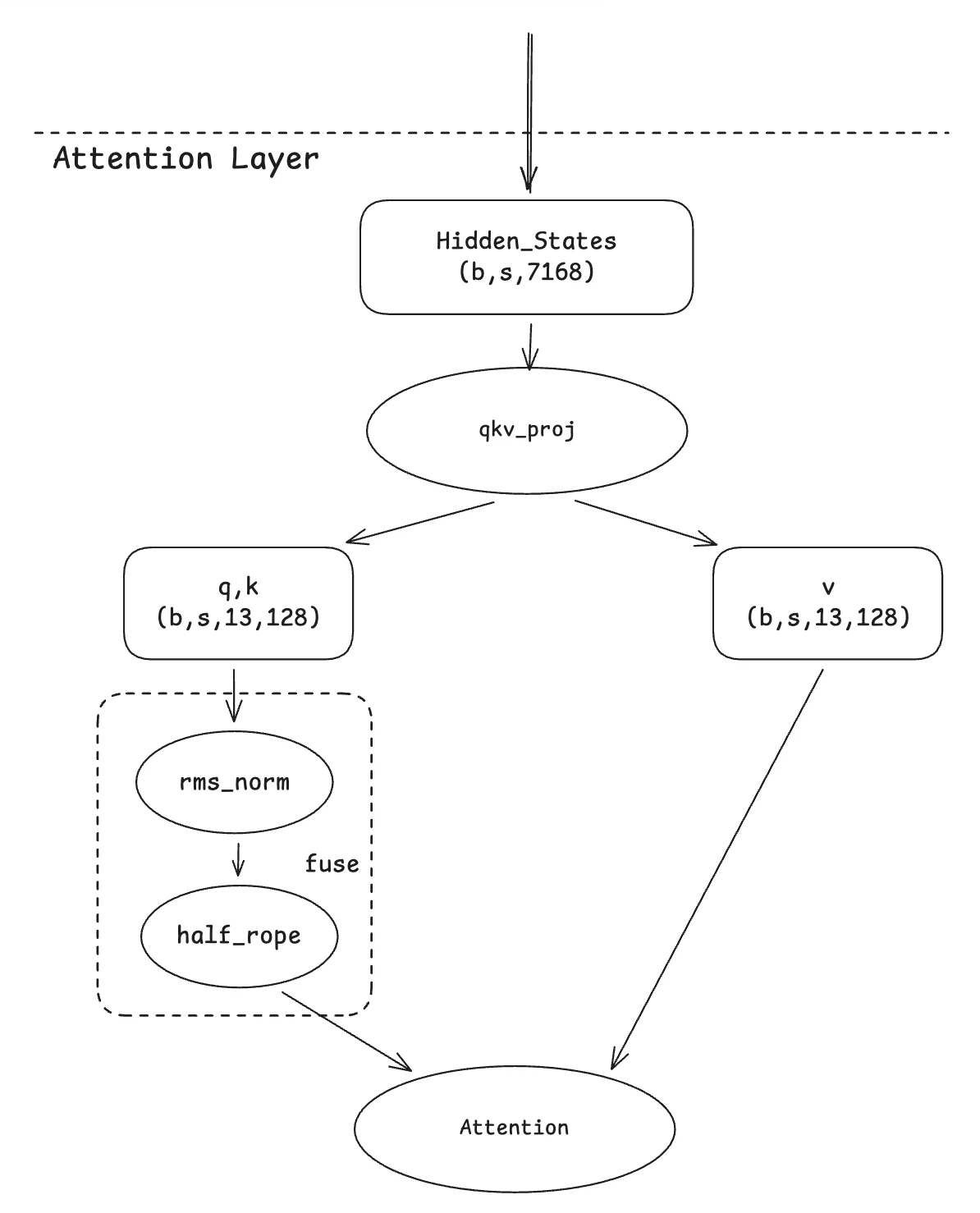
Essa migração se baseia na otimização do Qwen-MoE. A ideia subjacente é simples. Como ambos os operadores realizam computações por cabeça, é uma abordagem natural fundi-los em um único kernel. Nossa contribuição reside em adaptar esse kernel fundido para acomodar o caso específico da variante GLM4-MoE, onde apenas metade das dimensões dentro de uma cabeça são rotacionadas.
3. Transferência Assíncrona
https://github.com/sgl-project/sglang/pull/14782
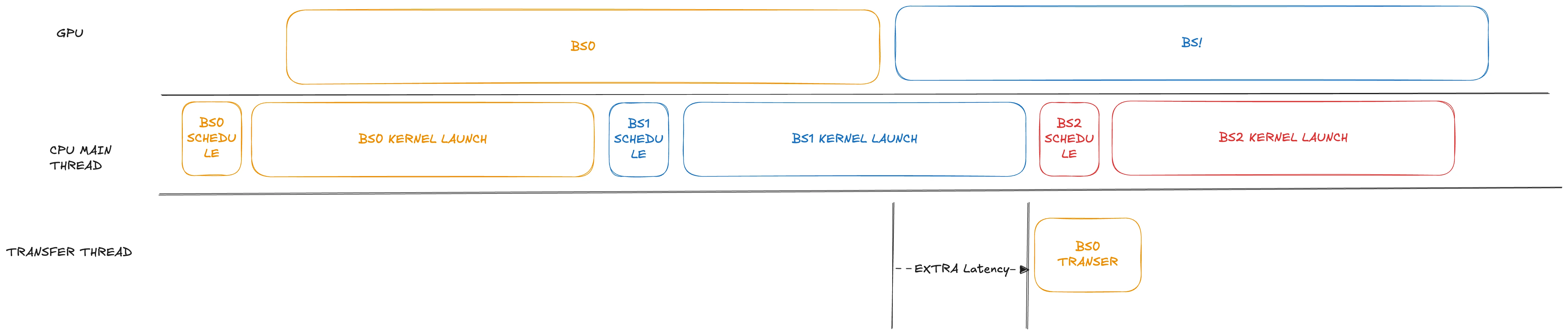
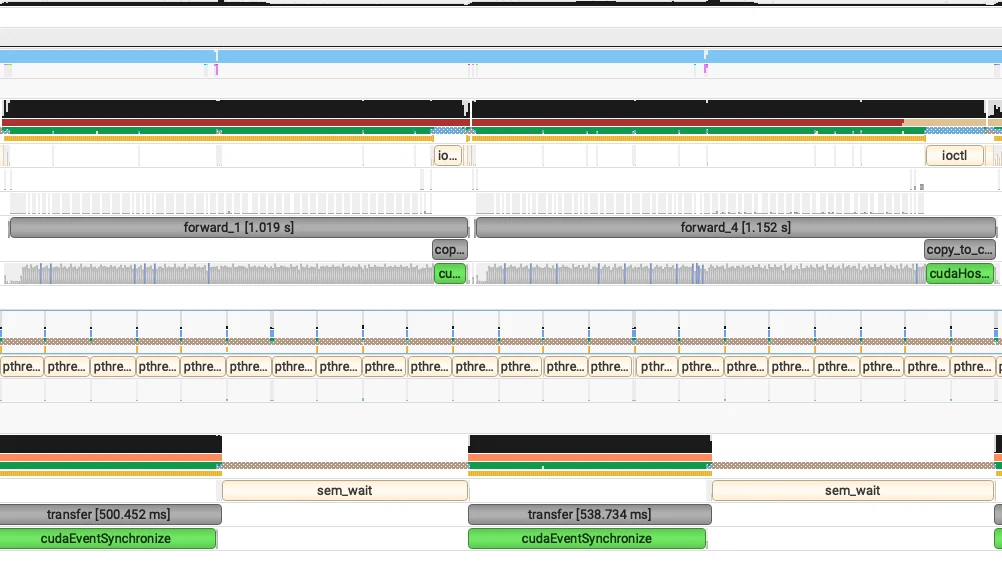
Em cenários onde a desagregação PD com agendamentos sobrepostos é aplicada, embora o throughput possa ganhar cerca de 10%, o TTFT cai significativamente. Observamos que, na implementação atual do preenchimento, o processo de transferência de dados é atrasado até após o lançamento do kernel para o próximo lote. Para um modelo como o GLM4.7, que consiste em 92 camadas, o lançamento de kernel sem CUDA Graph pode ser demorado (geralmente levando centenas de milissegundos, até mais de 1 segundo).
Para resolver isso, em nossa modificação adiantamos o passo de transferência ligeiramente, agendando-o logo após a conclusão das operações de GPU correspondentes. Além disso, a transferência é colocada em uma thread separada. Ao lidar cuidadosamente com possíveis estruturas de corrida de dados, ela pode prosseguir sem bloquear a thread principal.
O desempenho é enorme para modelos com muitos lançamentos de kernel. Em cargas de trabalho pesadas, essa otimização pode economizar até 1 segundo no TTFT, conforme mostrado abaixo.
Resultados de Benchmark em Produção
Depois de implementar as abordagens descritas acima, observamos melhorias de desempenho significativas para os modelos GLM-MoE, conforme demonstrado claramente pelos resultados de benchmark abaixo.
Configuração do benchmark
- Comprimento de entrada: 4096
- Comprimento de saída: 1000
- Taxa de requisição: 14 req/s
- Modelo: GLM-4.7 FP8 (TP8)
Resultados
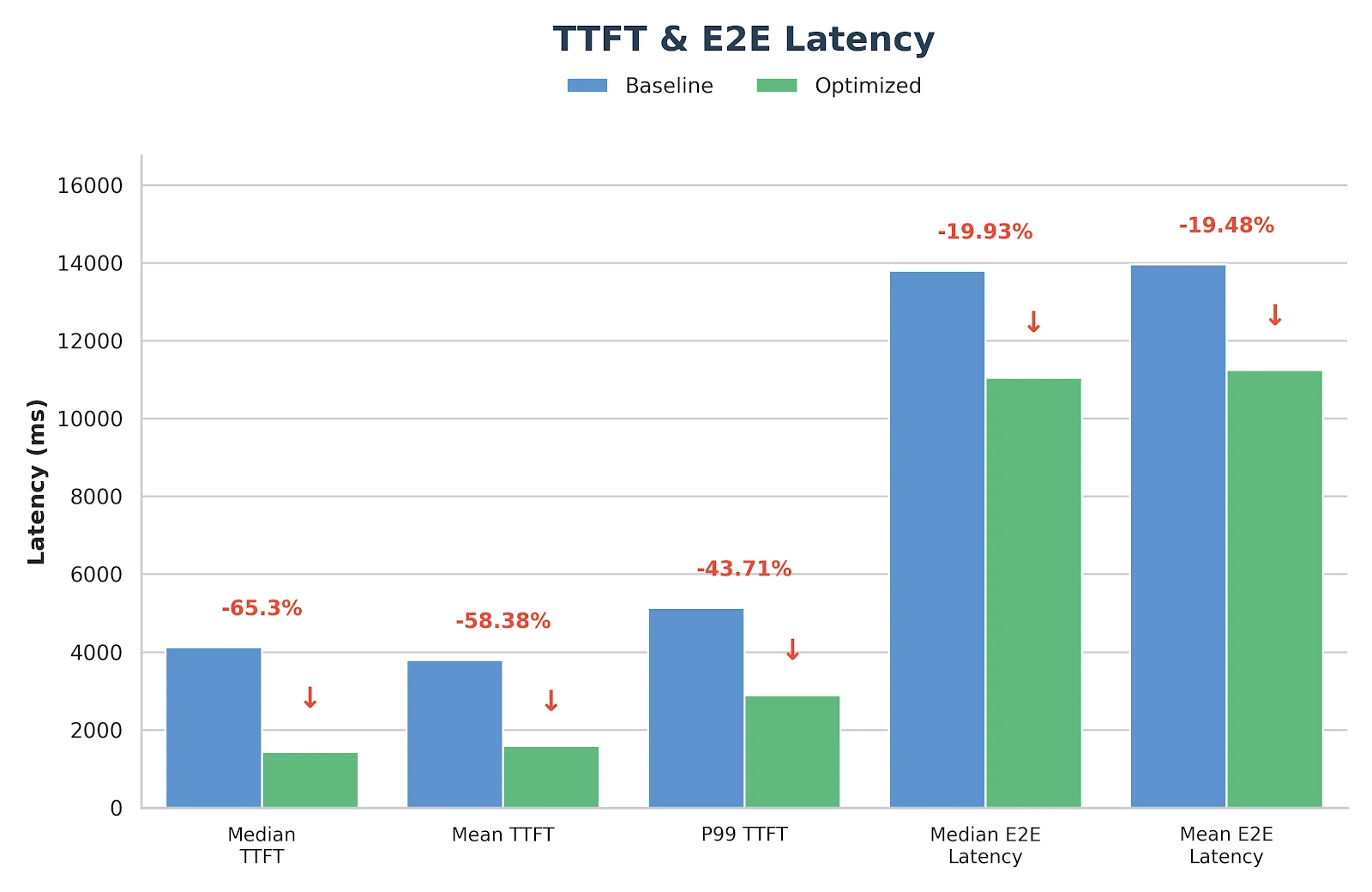
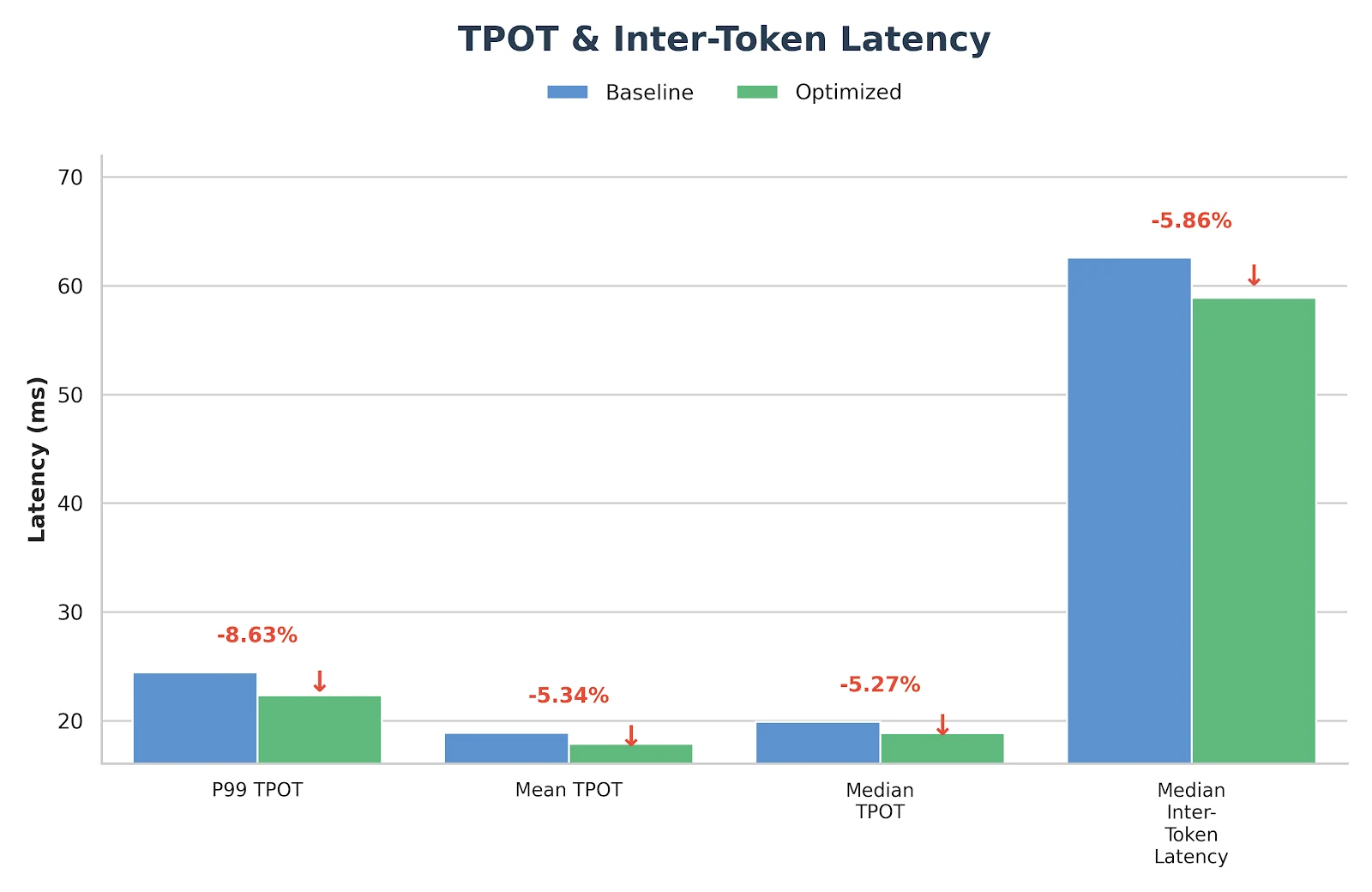
Essas otimizações não são apenas experimentais — elas já foram implantadas e validadas no serviço de inferência de produção da Novita.ai. Se você está procurando um backend GLM-MoE confiável e de baixa latência para cargas de trabalho do mundo real, fique à vontade para experimentá-lo diretamente em novita.ai.
Decodificação de Sufixo
Cenários de codificação agentiva (como Cursor e Claude Code) apresentam um alto volume de padrões de código reutilizáveis, permitindo otimizações de desempenho direcionadas, como a Decodificação de Sufixo.
Contexto: O Gargalo de Inferência na Codificação Agentiva
Agentes LLM se destacam em tarefas de geração de código, mas a latência continua sendo um desafio significativo. A Decodificação Especulativa tradicional acelera a inferência ao prever vários tokens com antecedência, mas as abordagens comuns exigem o treinamento de modelos de rascunho adicionais, introduzindo complexidade de engenharia.
Como a Decodificação de Sufixo Funciona
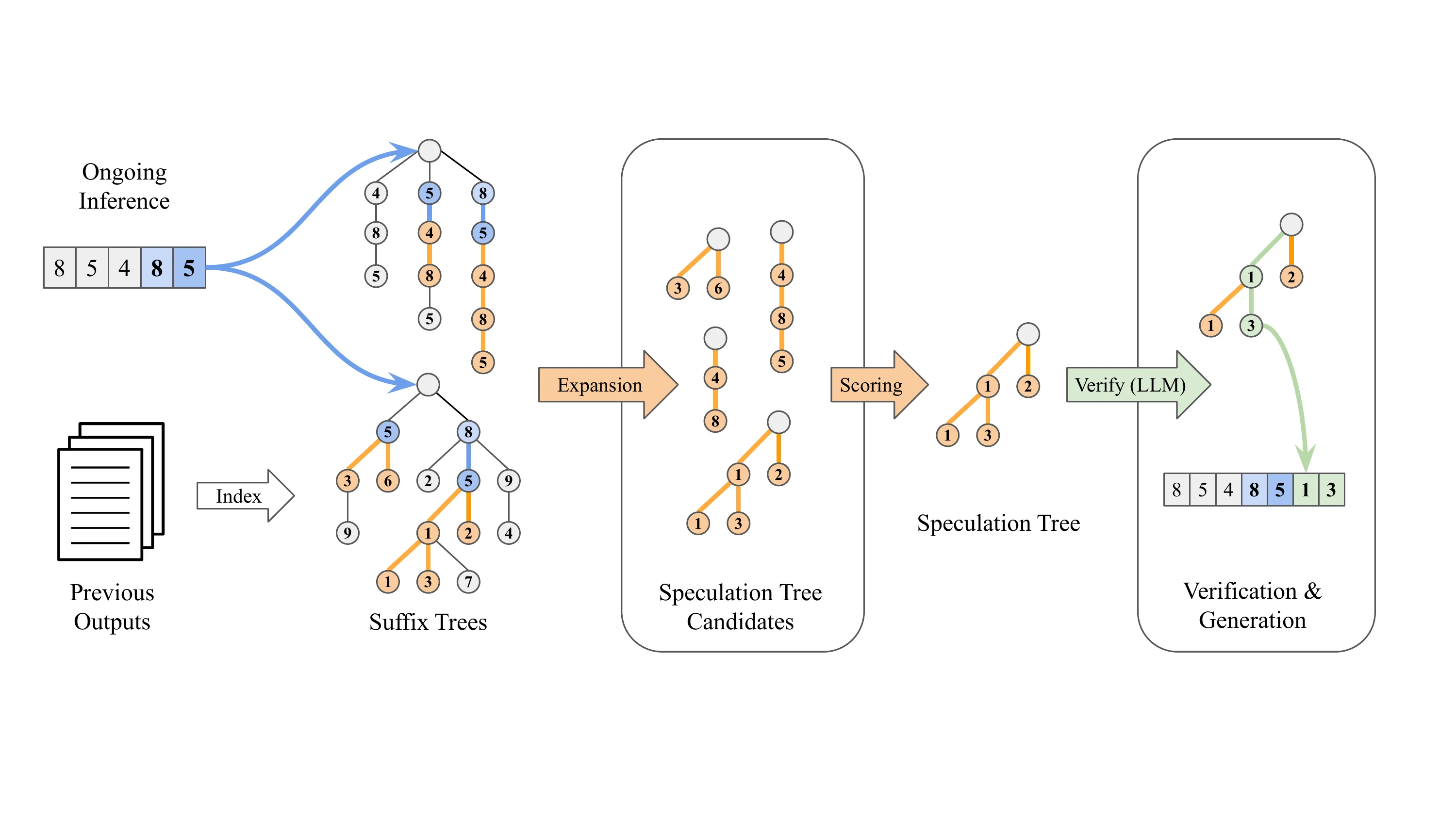
A Decodificação de Sufixo adota uma abordagem fundamentalmente diferente — ela é totalmente independente de modelo:
- Sem dependência de pesos de modelo adicionais
- Aproveita padrões de sequências de saída geradas anteriormente para prever tokens futuros
- Quando o sufixo da requisição atual corresponde a um padrão histórico, ele continua ao longo dessa sequência histórica para especulação
Validação de Dados: Análise de Repetição de Padrões de Saída
Ao analisar 22 sessões do Claude Code (17.487 turnos de conversa), descobrimos:
- 39,3% de repetição de padrões de saída: Alta frequência de chamadas de ferramentas e padrões de resposta semelhantes
- Comportamentos agentivos altamente estruturados: Frases fixas como “Deixe-me…”, “Agora deixe-me…” aparecem com frequência
Para apoiar pesquisas adicionais, disponibilizamos o conjunto de dados de avaliação em código aberto no Hugging Face: https://huggingface.co/datasets/novita/agentic_code_dataset_22
Comparação de Desempenho
Com a aceleração MTP integrada, a Decodificação de Sufixo reduz ainda mais o TPOT em 22% (de 25,13 ms para 19,63 ms):
| Métrica | MTP | Decodificação de Sufixo | Variação |
| TPOT médio | 25,13 ms | 19,63 ms | -21,90% |
| TPOT mediano | 25,95 ms | 20,05 ms | -22,70% |
Conclusão
A combinação dessas otimizações fornece melhorias de desempenho abrangentes para implantações do SGLang:
- A Fusão de Especialistas Compartilhados resolve a eficiência computacional em modelos MoE
- A Fusão QK-Norm-RoPE reduz a sobrecarga de lançamento de kernel
- A Transferência Assíncrona otimiza o movimento de dados em implantações desagregadas
- A Decodificação de Sufixo aproveita a repetição de padrões para decodificação especulativa em codificação agentiva.
A maioria dos componentes já foi mesclada no repositório principal ou está em processo de integração; fique à vontade para conferi-los no repositório do SGLang.
Como Reproduzir
Apenas os principais parâmetros relevantes para o desempenho são mostrados aqui.
Scripts de inicialização completos (linha de base vs otimizado), estrutura de benchmark e traces de profiling são publicados em nosso GitHub: https://github.com/novitalabs/sglang/tree/glm\_suffix
- Flags de Otimização Principais (Runtime do SGLang)
--tp-size 8
--kv-cache-dtype fp8_e4m3
--attention-backend fa3
--chunked-prefill-size 16384
--enable-flashinfer-allreduce-fusion
--enable-fused-qk-norm-rope
--enable-shared-experts-fusion
--disaggregation-async-transfer
- Configuração de decodificação especulativa (carga de trabalho de codificação agentiva)
--speculative-algorithm NEXTN
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 4
- Configuração de Decodificação de Sufixo (opcional)
--speculative-algorithm SUFFIX
--speculative-suffix-cache-max-depth 64
--speculative-suffix-max-spec-factor 1.0
--speculative-suffix-min-token-prob 0.1
Referências
- PR do SGLANG #13873: Otimização de Especialistas Compartilhados
- Blog de Engenharia da Snowflake: SuffixDecoding em Escala de Produção
- Artigo da NeurIPS: SuffixDecoding
- Repositório do Arctic Inference
A Novita AI é uma plataforma de nuvem de IA líder que fornece aos desenvolvedores APIs fáceis de usar e infraestrutura de GPU acessível e confiável para construir e escalar aplicações de IA.



