

요약
Novita AI는 SGLANG 기반 GLM4-MOE 모델 배포를 위해 프로덕션에서 검증된 고영향 최적화 제품군을 개발했습니다. 추론 파이프라인 전반의 병목 현상(커널 실행 효율성부터 노드 간 데이터 전송 스케줄링까지)을 해결하는 엔드투엔드 성능 최적화 전략을 소개합니다. 공유 전문가 융합(Shared Experts Fusion) 및 접미사 디코딩(Suffix Decoding) 을 통합하여 에이전트 코딩 워크로드에서 다음과 같은 주요 프로덕션 지표의 실질적인 개선을 확인했습니다:
- 최대 65%의 TTFT(첫 토큰까지의 시간) 감소
- 22%의 TPOT(출력 토큰당 시간) 개선
모든 결과는 H200 클러스터에서 TP8 및 FP8 구성으로 검증되었으며, 까다로운 프로덕션 환경에서 최적의 처리량과 낮은 지연 시간을 모두 달성하기 위한 실전 검증된 청사진을 제공합니다.
GLM-MoE를 위한 핵심 프로덕션 최적화 구현 방법
1. 공유 전문가 융합
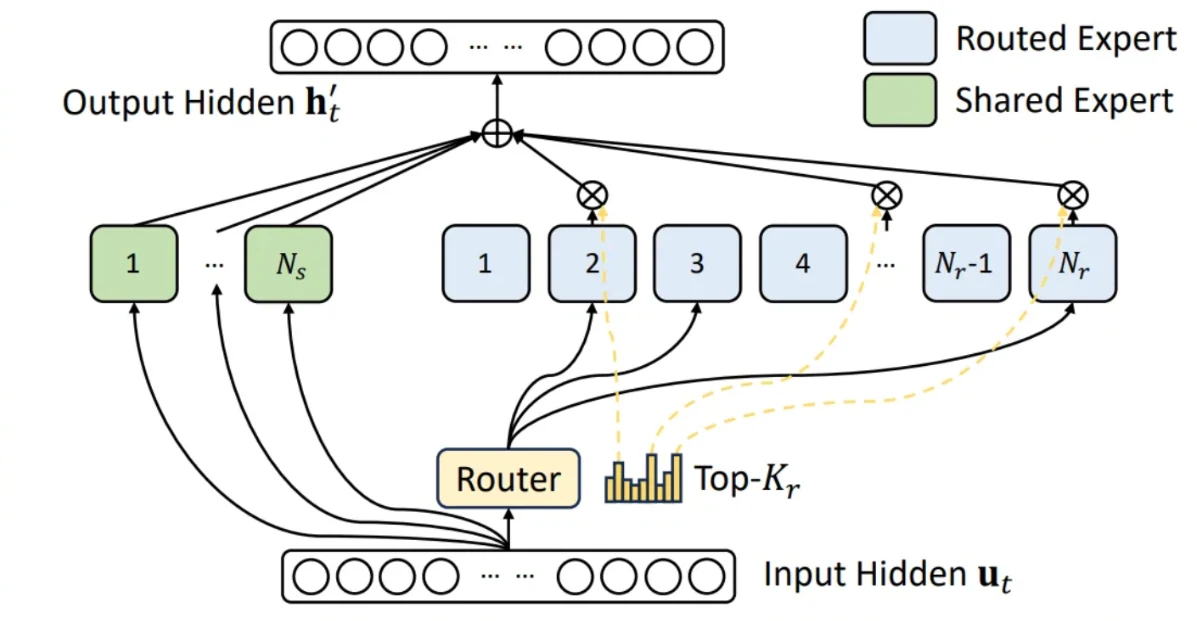
이 최적화는 Deepseek 모델의 원작업에 완전히 기인합니다. 위 그림과 같이 GLM4.7과 같은 MoE 모델은 모든 입력 토큰을 공유 전문가(shared expert)로 라우팅하는 동시에 각 토큰을 모델 라우터가 선택한 자체 top-k 라우팅 전문가 집합으로 개별 라우팅합니다. 모든 전문가의 출력은 가중치가 적용되어 집계됩니다. 예를 들어 GLM4.7은 단일 공유 전문가와 함께 160개의 라우팅 전문가를 사용하며, 토큰당 상위 8개의 라우팅 전문가를 선택합니다. 이전 구현에서는 이 두 구성 요소가 별도로 처리되었습니다. 두 구성 요소가 동일한 텐서 모양과 계산 절차를 공유하므로, 공유 전문가를 라우팅 MoE 구조에 병합하여 통합하는 것이 자연스럽습니다. 이렇게 하면 총 161개의 전문가 중 상위 9개를 선택하며, 공유 전문가는 항상 9번째 위치에 할당됩니다.
PR에 문서화된 바와 같이, 이 최적화는 TTFT에서 최대 23.7%, ITL에서 20.8%의 성능 향상을 달성합니다. 이러한 이점은 예상된 결과입니다. TP8 및 FP8 구성에서 중간 크기가 192에 불과하여 H200 하드웨어에서 상대적으로 작기 때문에, 융합 연산은 SM(스트리밍 멀티프로세서) 활용도를 크게 높이고 메모리 I/O 오버헤드를 현저히 줄여줍니다.
2. QKNorm 융합
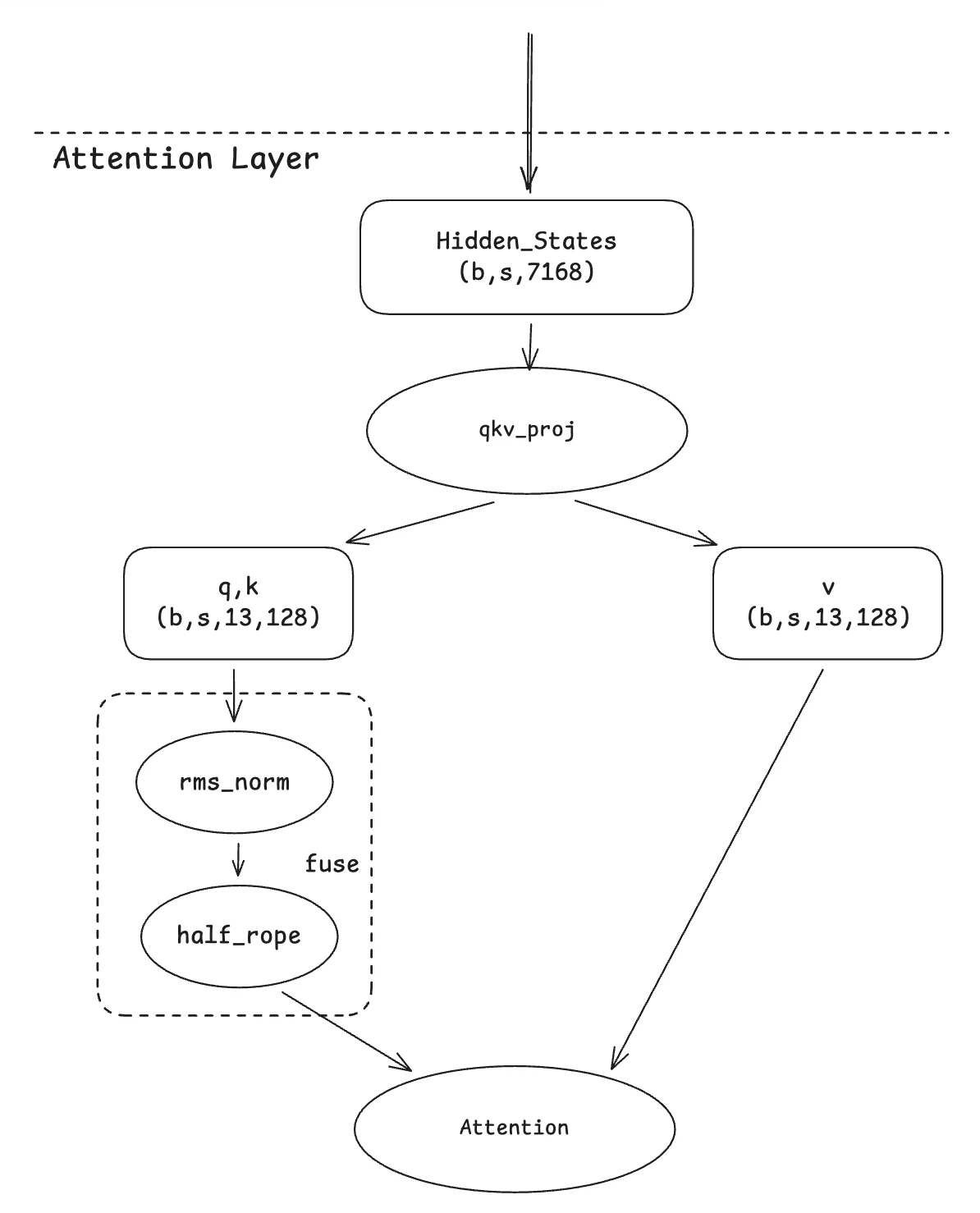
이 마이그레이션은 Qwen-MOE의 최적화를 기반으로 합니다. 기본 아이디어는 간단합니다. 두 연산자가 헤드별(head-wise) 계산을 수행하므로, 이를 단일 커널로 융합하는 것이 자연스러운 접근 방식입니다. 우리의 기여는 이 융합 커널을 GLM4-MOE 변형의 특정 사례에 맞게 조정한 것으로, 여기서는 헤드 내 차원의 절반만 회전됩니다.
3. 비동기 전송
https://github.com/sgl-project/sglang/pull/14782
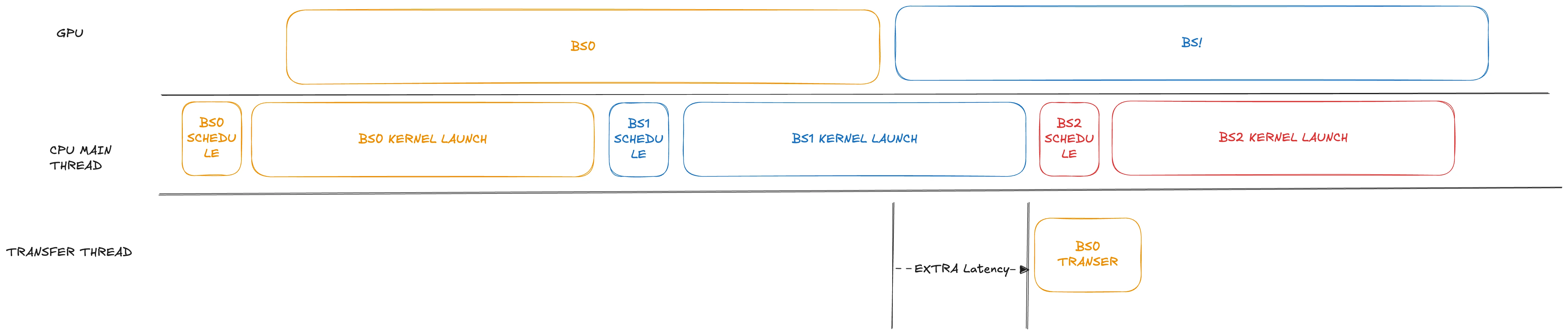
중첩 스케줄이 있는 PD 분리 시나리오에서는 처리량이 약 10% 향상될 수 있지만 TTFT가 크게 저하됩니다. 현재 프리필(prefill) 구현에서는 데이터 전송 프로세스가 다음 배치의 커널 실행 이후까지 지연되는 것을 관찰했습니다. GLM4.7과 같이 92개의 레이어로 구성된 모델의 경우, CUDA Graph 없이 커널을 실행하는 데 시간이 많이 걸릴 수 있습니다(수백 밀리초에서 1초 이상 소요되는 경우도 많습니다).
이를 해결하기 위해 수정에서는 전송 단계를 약간 앞당겨 해당 GPU 연산이 완료된 직후에 스케줄링했습니다. 또한 전송을 별도의 스레드에 배치했습니다. 잠재적인 데이터 경합 구조를 신중하게 처리함으로써 메인 스레드를 차단하지 않고 진행할 수 있습니다.
이 최적화는 커널 실행이 많은 모델에서 성능 효과가 큽니다. 아래와 같이 워크로드가 많을 때 이 최적화는 TTFT 측면에서 최대 1초를 절약할 수 있습니다.
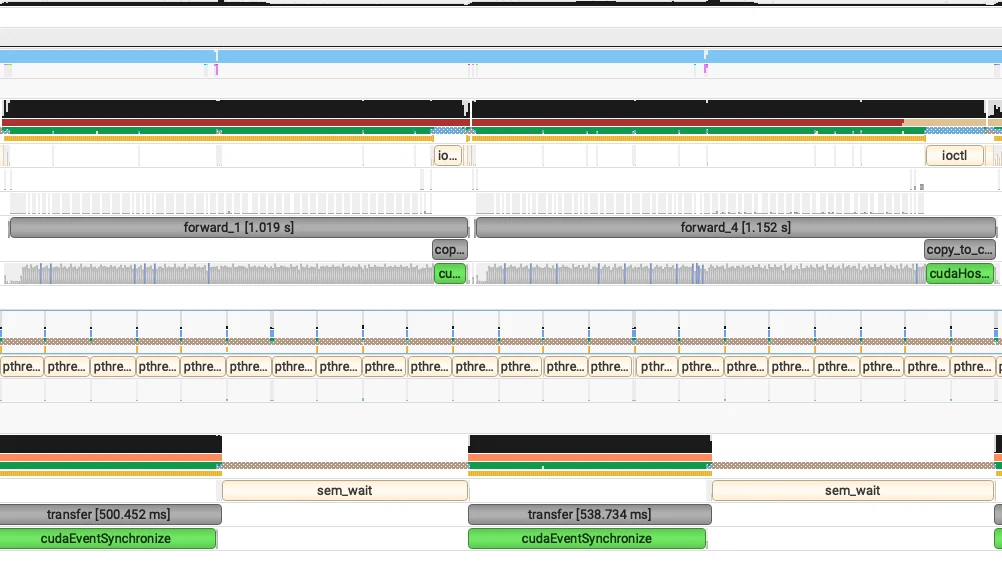
프로덕션 벤치마크 결과
위에서 설명한 접근 방식을 구현한 후 GLM-MOE 모델에서 상당한 성능 향상을 관찰했으며, 아래 벤치마크 결과에서 명확히 확인할 수 있습니다.
벤치마크 구성
- 입력 길이: 4096
- 출력 길이: 1000
- 요청 속도: 14 req/s
- 모델: GLM-4.7 FP8 (TP8)
결과
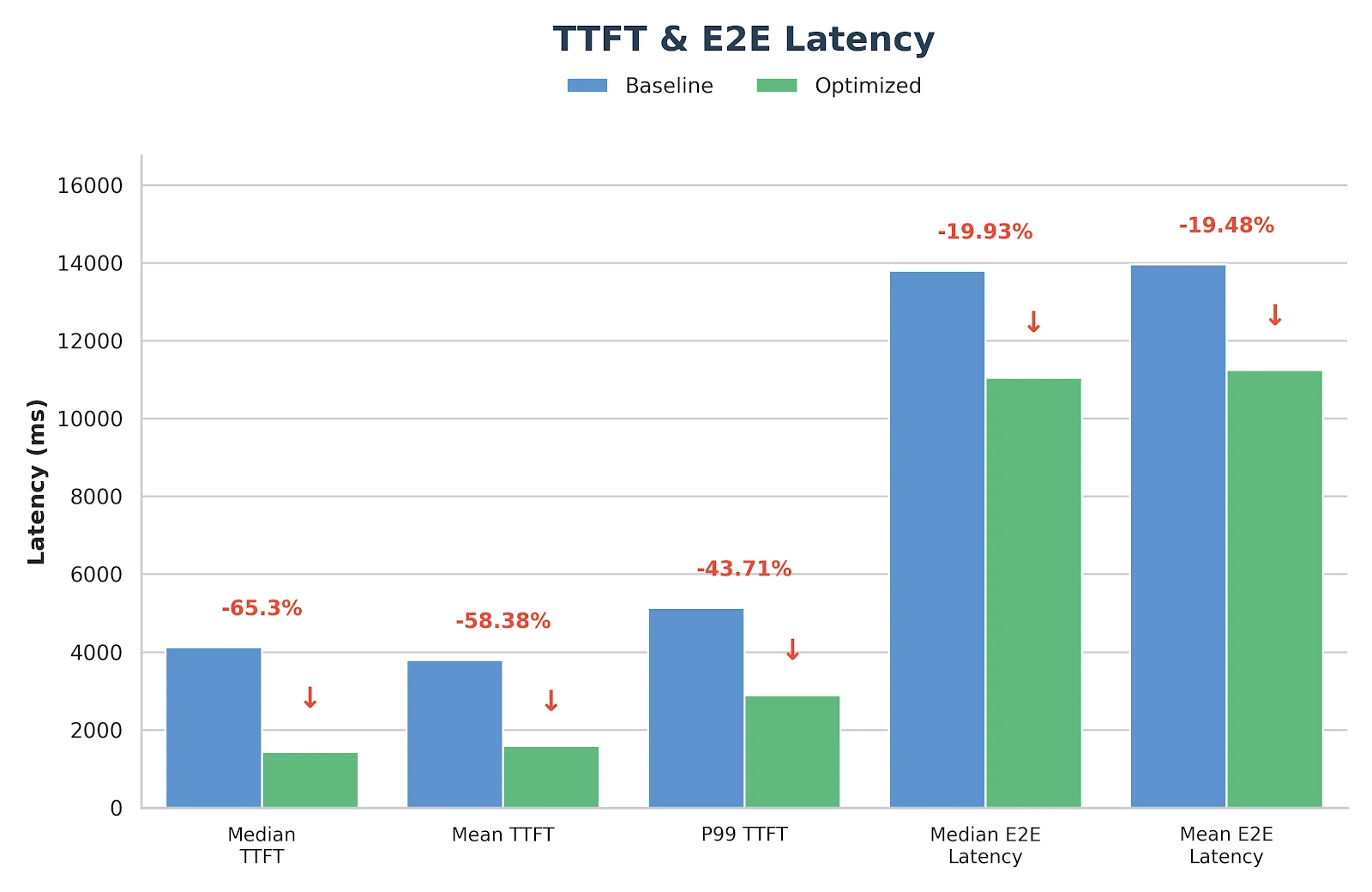
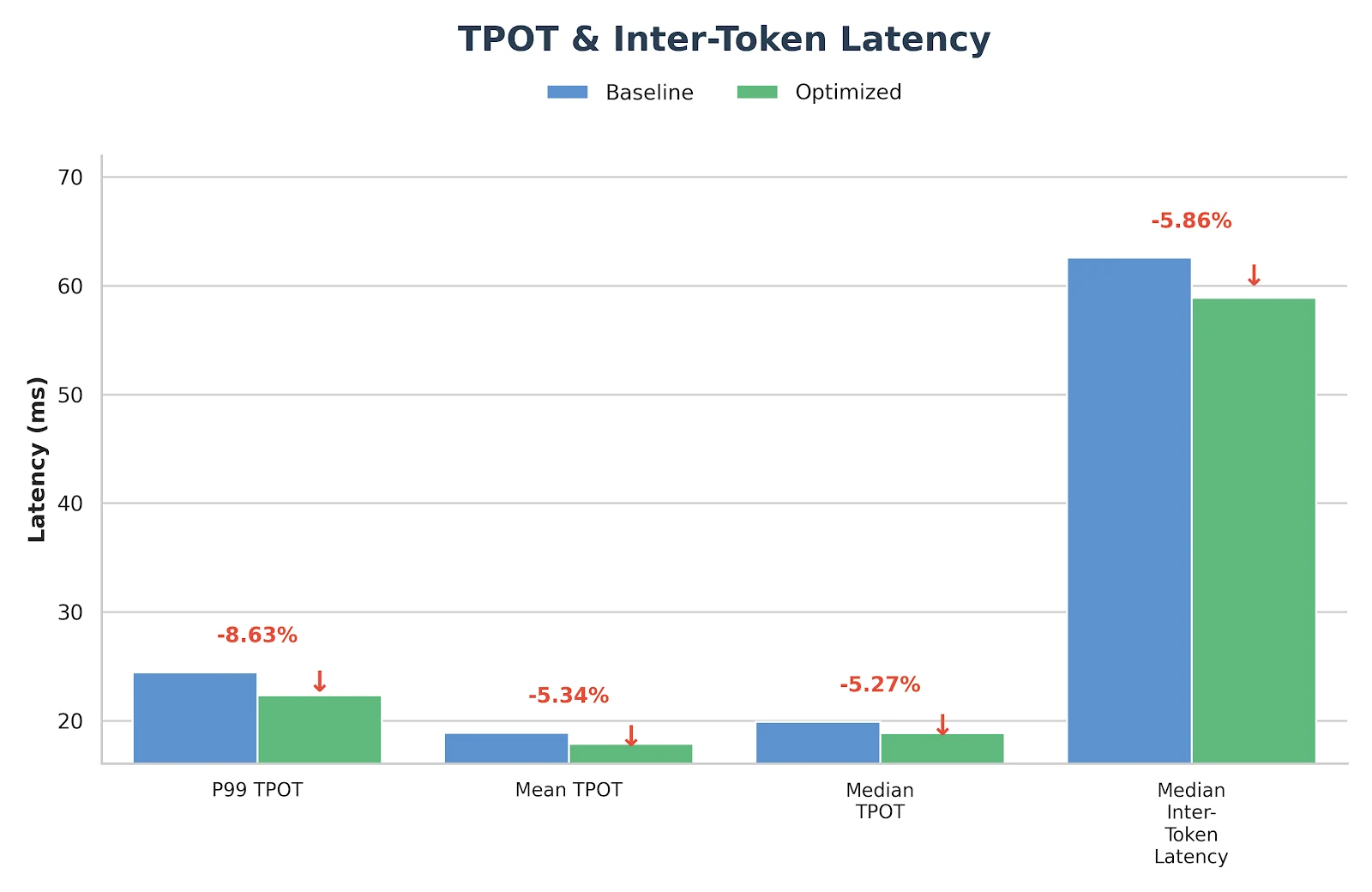
이러한 최적화는 실험 수준에 그치지 않고 이미 Novita.ai의 프로덕션 추론 서비스에 배포 및 검증되었습니다. 실제 워크로드를 위한 안정적이고 지연 시간이 짧은 GLM-MoE 백엔드를 찾고 계시다면 novita.ai 에서 직접 체험해 보세요.
접미사 디코딩
에이전트 코딩 시나리오(Cursor 및 Claude Code 등)는 재사용 가능한 코드 패턴이 많아 접미사 디코딩과 같은 목표 성능 최적화를 활용할 수 있습니다.
배경: 에이전트 코딩의 추론 병목 현상
LLM 에이전트는 코드 생성 작업에 탁월하지만 지연 시간은 여전히 주요 과제입니다. 기존의 추측 디코딩(Speculative Decoding)은 여러 토큰을 미리 예측하여 추론을 가속화하지만, 일반적인 접근 방식은 추가 드래프트 모델을 학습해야 하므로 엔지니어링 복잡성이 증가합니다.
접미사 디코딩 작동 방식
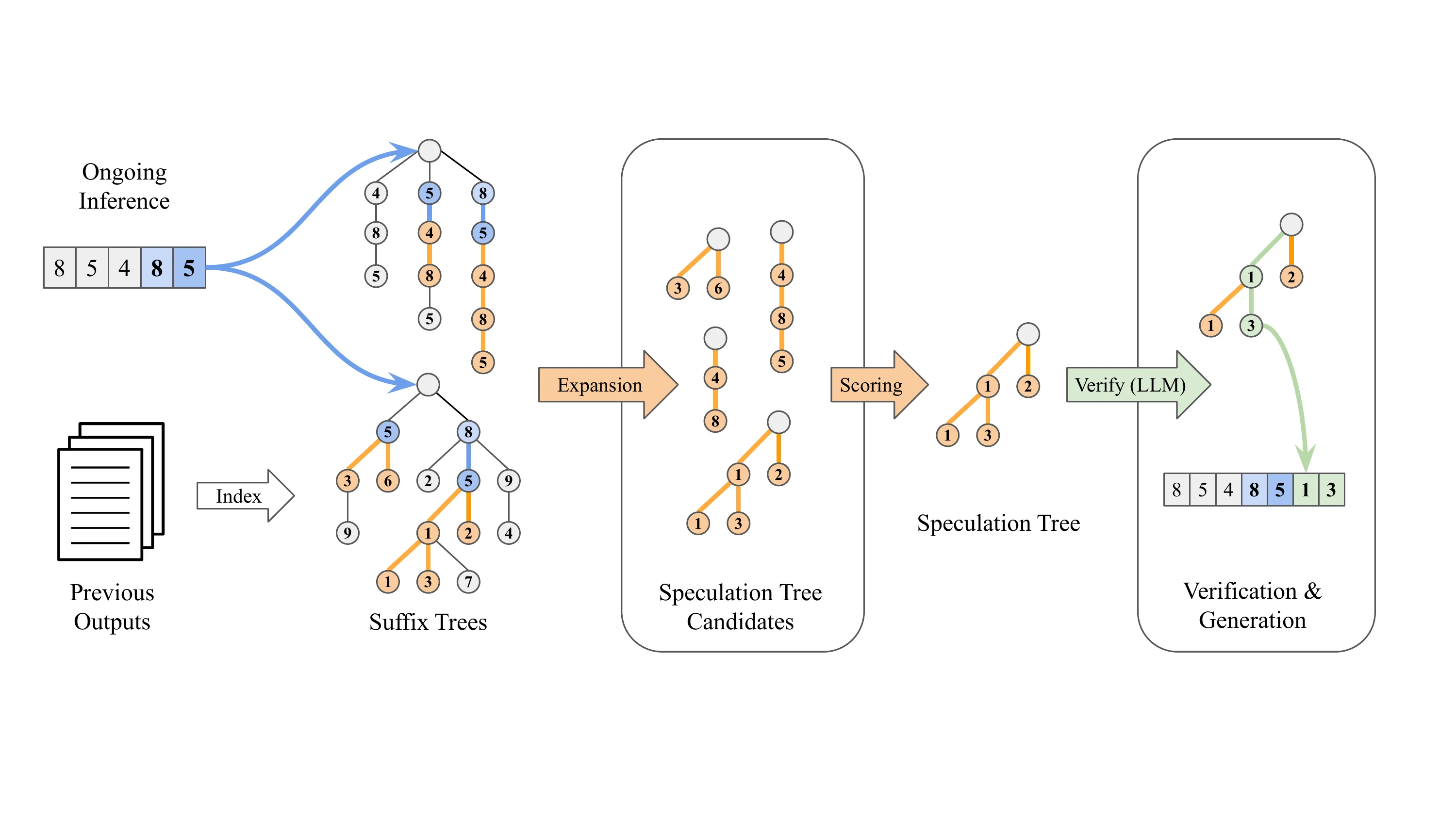
접미사 디코딩은 근본적으로 다른 접근 방식을 취합니다. 완전히 모델이 필요 없습니다:
- 추가 모델 가중치에 의존하지 않음
- 이전에 생성된 출력 시퀀스의 패턴을 활용하여 다가오는 토큰을 예측
- 현재 요청의 접미사가 과거 패턴과 일치하면, 해당 과거 시퀀스를 따라 추측을 계속 진행
데이터 검증: 출력 패턴 반복 분석
22개의 Claude Code 세션(17,487회의 대화 턴)을 분석하여 다음을 발견했습니다:
- 39.3% 출력 패턴 반복: 유사한 도구 호출 및 응답 패턴의 빈도가 높음
- 구조화된 에이전트 행동: “Let me…”, "Now let me…"와 같은 고정 표현이 자주 나타남
추가 연구를 지원하기 위해 평가 데이터셋을 Hugging Face에 오픈소스로 공개했습니다: https://huggingface.co/datasets/novita/agentic_code_dataset_22
성능 비교
내장 MTP 가속과 함께 접미사 디코딩은 TPOT을 22% 추가 감소시킵니다(25.13ms에서 19.63ms로):
| 지표 | MTP | 접미사 디코딩 | 변화 |
| 평균 TPOT | 25.13 ms | 19.63 ms | -21.90% |
| 중간 TPOT | 25.95 ms | 20.05 ms | -22.70% |
결론
이러한 최적화의 조합은 SGLANG 배포에 포괄적인 성능 개선을 제공합니다:
- 공유 전문가 융합은 MoE 모델의 계산 효율성을 해결합니다.
- QK-Norm-RoPE 융합은 커널 실행 오버헤드를 줄입니다.
- 비동기 전송은 분리 배포에서 데이터 이동을 최적화합니다.
- 접미사 디코딩은 에이전트 코딩을 위해 패턴 반복을 활용한 추측 디코딩을 제공합니다.
대부분의 구성 요소는 이미 업스트림에 병합되었거나 통합 중입니다. SGLang 저장소에서 직접 확인해 보세요.
재현 방법
여기서는 주요 성능 관련 매개변수만 표시합니다.
전체 실행 스크립트(기준 vs 최적화), 벤치마크 도구 및 프로파일링 추적은 GitHub에 게시되어 있습니다: https://github.com/novitalabs/sglang/tree/glm\_suffix
- 핵심 최적화 플래그 (SGLang 런타임)
--tp-size 8
--kv-cache-dtype fp8_e4m3
--attention-backend fa3
--chunked-prefill-size 16384
--enable-flashinfer-allreduce-fusion
--enable-fused-qk-norm-rope
--enable-shared-experts-fusion
--disaggregation-async-transfer
- 추측 디코딩 구성 (에이전트 코딩 워크로드)
--speculative-algorithm NEXTN
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 4
- 접미사 디코딩 구성 (선택 사항)
--speculative-algorithm SUFFIX
--speculative-suffix-cache-max-depth 64
--speculative-suffix-max-spec-factor 1.0
--speculative-suffix-min-token-prob 0.1
참고 문헌
- SGLANG PR #13873: 공유 전문가 최적화
- Snowflake 엔지니어링 블로그: 프로덕션 규모의 접미사 디코딩
- NeurIPS 논문: 접미사 디코딩
- Arctic 추론 저장소
Novita AI 는 개발자에게 사용하기 쉬운 API와 합리적인 가격의 안정적인 GPU 인프라를 제공하여 AI 애플리케이션 구축 및 확장을 지원하는 선도적인 AI 클라우드 플랫폼입니다.


