
동기
지난 1년간 KV 희소성 분야의 최신 학술 논문(H2O, SnapKV, PyramidKV)을 검토한 결과, KV 희소성을 모델의 다양한 레이어에 적용했습니다. 가지치기 전략을 사용하여 낮은 점수의 KV 쌍을 제거하고, 점수가 높고 가까운 위치에 있는 KV 쌍만 유지합니다. 이 접근 방식은 메모리 사용량, 연산 및 I/O 오버헤드를 줄여 궁극적으로 추론을 가속화합니다.
실험
기준 및 설정: 모든 KV-Compress 실험은 v0.6.2에서 포크한 vLLM 통합을 사용하여 cuda graph 모드에서 블록 크기 16으로 실행했습니다. 모든 RTX 4090/Llama-3.1-8B-Instruct 실험에서는 기본 GPU 메모리 사용률 0.9를 사용하고 maxmodel-length를 32k로 설정했습니다. Llama-3.1-8B-Instruct에서 압축을 평가하고, 이전 연구에서 소개된 다음 기준 방법과 성능을 비교했습니다:
- vLLM-0.6.2
- Novita AI, vLLM 프레임워크 기반 Pyramid KV 캐시 압축
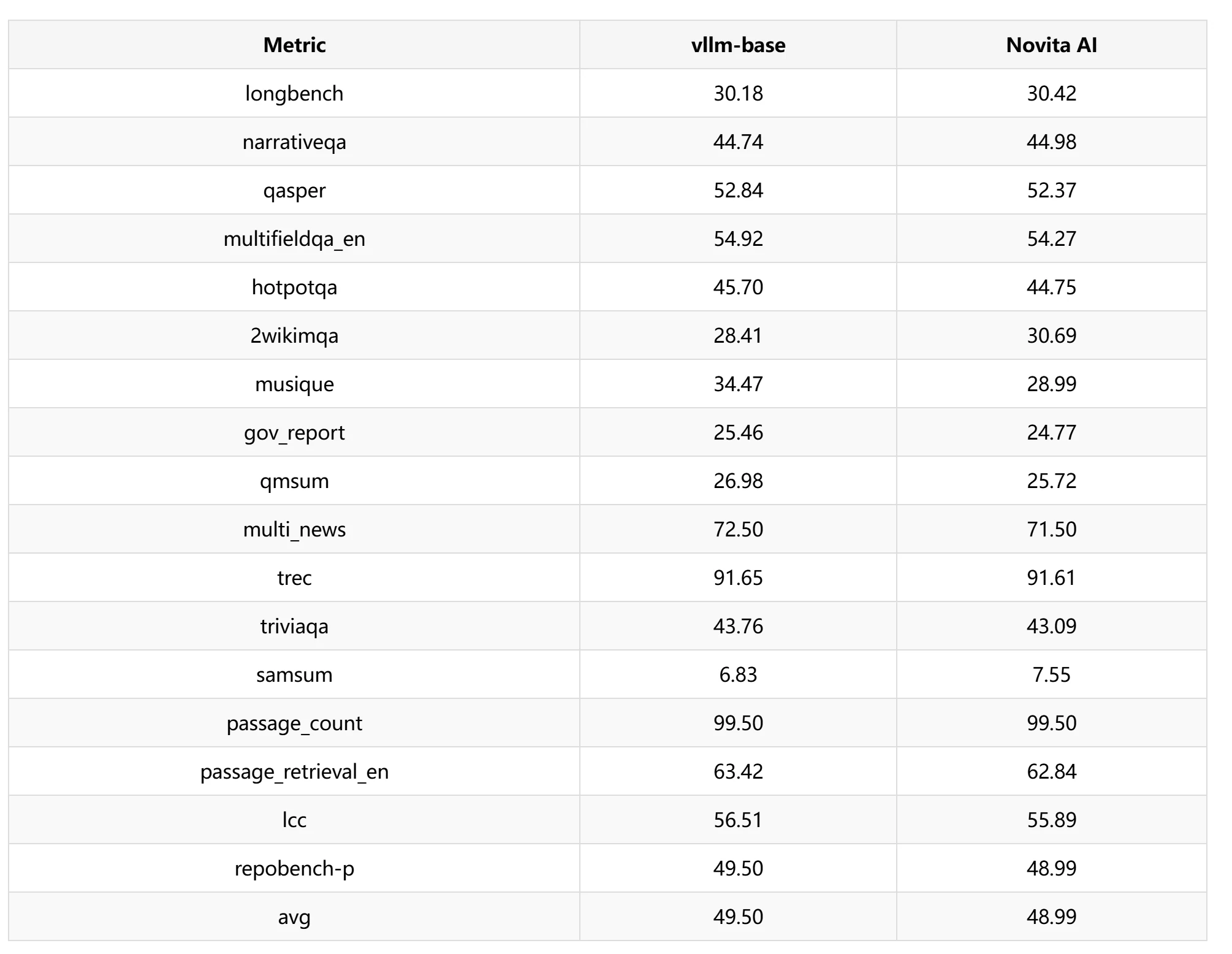
MMLU Pro 및 LongBench: 다양한 레이어에 서로 다른 슬라이딩 윈도우 길이를 설정하여 KV 캐시 압축 비율을 제어했습니다. 실험에서는 주로 1024, 1280, 1536의 세 가지 슬라이딩 윈도우 길이를 설정하고, 다양한 레이어 수에 대해 교차 테스트를 수행했습니다.
MMLU Pro
MMLU Pro 테스트에서 KV 희소성 레이어와 슬라이딩 윈도우 길이에 따라 다른 성능을 보였습니다. 가속 비율을 고려할 때 전체 정확도는 98% 이상으로 유지할 수 있습니다.
| vllm-0.6.2 | Novita AI | |
| KV 희소성 레이어 | 전체 | 슬라이딩 윈도우=1536 |
| 22 | 0.4517 | 0.4496 |
| 26 | 0.4517 | 0.4476 |
| 31 | 0.4517 | 0.4476 |
LongBench
LongBench 테스트에서는 슬라이딩 윈도우 1024를 선택하여 성능 테스트를 진행했으며, 정확도 손실은 약 1.03%임을 확인했습니다.
처리량 벤치마크: 실제 LLM 애플리케이션에서 입력/출력 길이가 5000/500인 구성이 가장 일반적이며, TTFT 지표는 2초 미만이어야 합니다. 이러한 조건에서 배치 성능 비교 테스트를 수행한 결과, vLLM 대비 1.5배의 추론 속도 향상을 얻었습니다.
| 처리량 | vllm-0.6.2 | Novita AI |
| KV 희소성 레이어 | 전체 | 슬라이딩 윈도우=1536 |
| 22 | 1 | 1.26 |
| 26 | 1 | 1.34 |
| 31 | 1 | 1.44 |
주요 변경 사항
수정된 파일은 주로 다음과 같습니다:
- Flash attention: Flash attention 기반 희소성 점수 계산, 커널 성능 손실 1% 미만 보장.
- Paged attention 및
reshape_and_cache: Paged attention 기반 희소성 점수 계산, prefill 및 decode 단계에서 희소성 점수 동기화. Block_manager및 메모리 관리와 텐서 준비 관련 기타 함수.
결론
Novita AI는 텐서 병렬 처리를 지원하므로 Llama3-70B와 같은 모델을 여러 GPU에서 실행할 수 있습니다. 현재 일부 사유로 코드를 공개하지는 않지만, 커뮤니티에 기술과 아이디어를 기여하고 모두와 기술 교류를 환영합니다. 참고사항: vLLM-0.6.2에서는 다음 기능이 아직 지원되지 않습니다:
- Chunked-prefill
- Prefix caching
- FlashInfer 및 FlashAttention 이외의 백엔드
- Speculative Decoding
Novita AI 는 개발자가 간단한 API를 통해 AI 모델을 손쉽게 배포할 수 있도록 지원하고, 저렴하고 신뢰할 수 있는 GPU 클라우드를 제공하여 빌드와 확장을 돕는 AI 클라우드 플랫폼입니다.
추천 읽을거리



