
Motivación
Tras revisar artículos académicos recientes del último año en el campo de la dispersión KV (H2O, SnapKV, PyramidKV), aplicamos la dispersión KV a diferentes capas del modelo. Empleando una estrategia de poda, eliminamos pares KV con puntuaciones bajas mientras conservamos aquellos con puntuaciones altas y mayor proximidad. Este enfoque reduce el uso de memoria, así como la sobrecarga computacional y de E/S, lo que finalmente acelera la inferencia.
Experimentos
Líneas base y configuraciones: Ejecutamos todos los experimentos de KV-Compress utilizando nuestra integración con vLLM bifurcada de v0.6.2, en modo cuda graph con un tamaño de bloque de 16. Para todos los experimentos con RTX 4090 / Llama-3.1-8B-Instruct, usamos una utilización de memoria GPU predeterminada de 0.9 y establecemos maxmodel-length en 32k. Evaluamos nuestra compresión en Llama-3.1-8B-Instruct, comparando el rendimiento con los siguientes métodos de línea base presentados en trabajos anteriores:
- vLLM-0.6.2
- Novita AI, compresión de Pyramid KV Cache basada en el framework vLLM
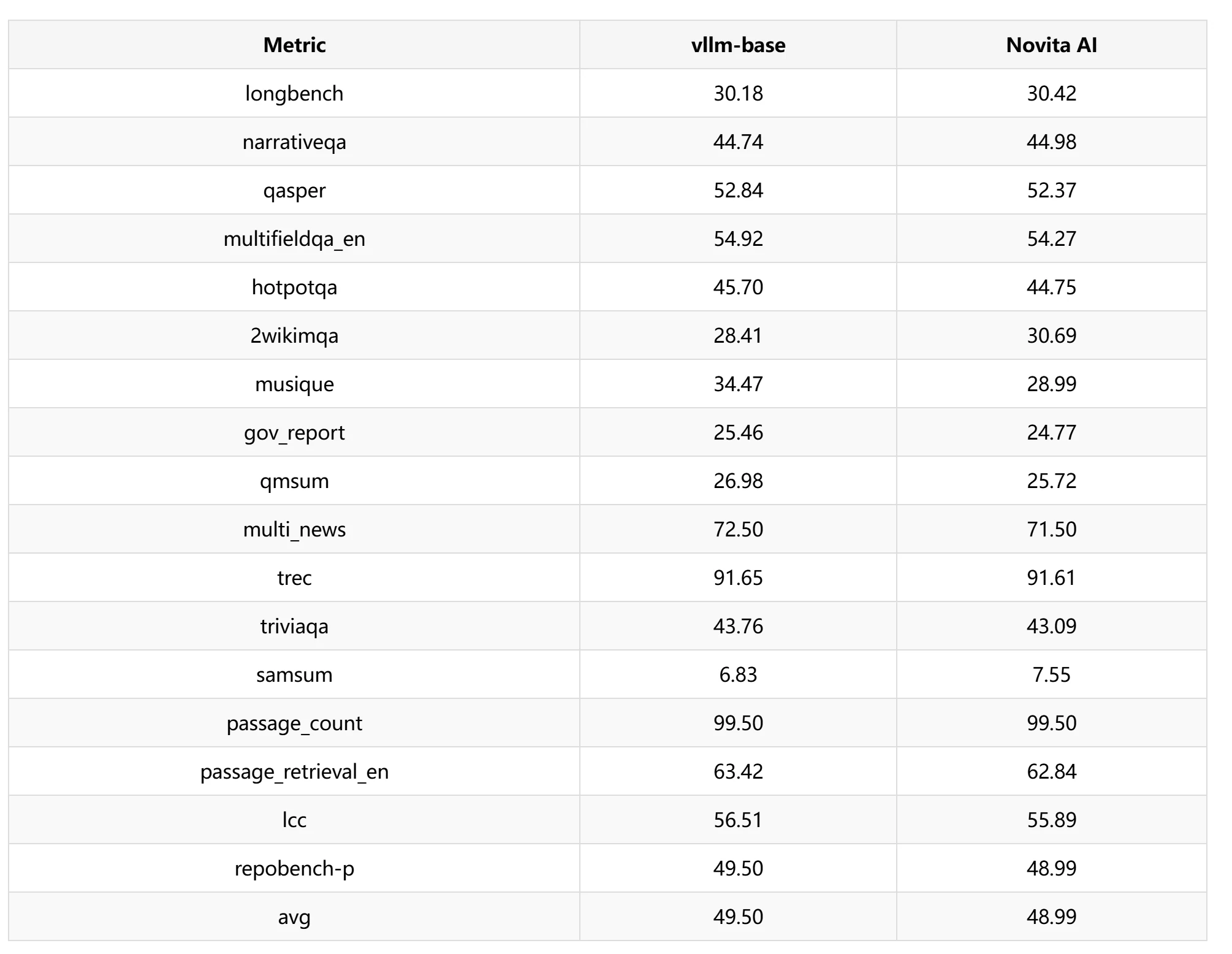
MMLU Pro y LongBench: Controlamos diferentes ratios de compresión de KV Cache configurando diferentes longitudes de ventana deslizante en distintas capas. En el experimento, establecimos principalmente tres longitudes de ventana deslizante: 1024, 1280 y 1536, y realizamos pruebas cruzadas en diferentes números de capas. En la prueba MMLU Pro, diferentes capas de dispersión KV y diferentes longitudes de ventana deslizante muestran rendimientos distintos. Considerando la relación de aceleración, se puede garantizar una precisión general superior al 98%.
| vllm-0.6.2 | Novita AI | |
| Capas de dispersión KV | completo | ventana deslizante=1536 |
| 22 | 0.4517 | 0.4496 |
| 26 | 0.4517 | 0.4476 |
| 31 | 0.4517 | 0.4476 |
En la prueba LongBench, seleccionamos una ventana deslizante de 1024 para las pruebas de rendimiento y encontramos que la pérdida de precisión fue de aproximadamente 1.03%.
Pruebas de rendimiento (Throughput): En aplicaciones reales de LLM, una longitud de entrada/salida de 5000/500 es la configuración más comúnmente observada, y el índice TTFT debe ser inferior a 2 s. Basándonos en estas condiciones, realizamos pruebas comparativas de rendimiento por lotes, obteniendo una aceleración de inferencia de 1.5× para vLLM.
| Throughput | vllm-0.6.2 | Novita AI |
| Capas de dispersión KV | completo | ventana deslizante=1536 |
| 22 | 1 | 1.26 |
| 26 | 1 | 1.34 |
| 31 | 1 | 1.44 |
Cambios principales
Los archivos modificados incluyen principalmente:
- Flash attention, puntuación dispersa basada en Flash attention garantizando que la pérdida de rendimiento del kernel sea inferior al 1%.
- Paged attention y reshape_and_cache, puntuación dispersa basada en Paged attention y sincronización de la puntuación dispersa en las etapas de prefill y decode.
- Block_manager y otras funciones relacionadas con la gestión de memoria y la preparación de tensores.
Conclusión
Novita AI también soporta paralelismo de tensores para permitir que modelos como Llama3-70B se ejecuten en múltiples GPUs. Actualmente, no respaldamos código abierto por ciertas razones, pero esperamos contribuir con algo de tecnología e ideas a la comunidad, y agradecemos los intercambios técnicos con todos. Solo un aviso: Las siguientes características aún no están soportadas en vLLM-0.6.2:
- Chunked-prefill
- Prefix caching
- Backends que no sean FlashAttention, como FlashInfer
- Decodificación especulativa (Speculative Decoding)
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.
Lectura recomendada



