
Motivação
Revisando artigos acadêmicos recentes do último ano na área de esparsidade KV (H2O, SnapKV, PyramidKV), aplicamos a esparsidade KV a diferentes camadas do modelo. Empregando uma estratégia de poda, eliminamos pares KV com pontuações mais baixas, mantendo aqueles com pontuações mais altas e maior proximidade. Essa abordagem reduz o uso de memória, bem como a sobrecarga computacional e de E/S, resultando em inferência acelerada.
Experimentos
Linhas de base e configurações: Executamos todos os experimentos de KV-Compress usando nossa integração vLLM, bifurcada da v0.6.2, em modo de grafo CUDA com tamanho de bloco 16. Para todos os experimentos com RTX 4090/Llama-3.1-8B-Instruct, usamos utilização padrão de memória GPU de 0,9 e definimos maxmodel-length para 32k. Avaliamos nossa compressão no Llama-3.1-8B-Instruct, comparando o desempenho com os seguintes métodos de linha de base introduzidos em trabalhos anteriores:
- vLLM-0.6.2
- Novita AI, compressão de Cache KV Pyramid baseada no framework vLLM
MMLU Pro e LongBench: Controlamos diferentes taxas de compressão do Cache KV definindo diferentes comprimentos de janela deslizante em diferentes camadas. No experimento, definimos principalmente três comprimentos de janela deslizante: 1024, 1280 e 1536, e realizamos testes cruzados em diferentes números de camadas.
No teste MMLU Pro, diferentes camadas de esparsidade KV e diferentes comprimentos de janela deslizante apresentam desempenhos variados. Considerando a taxa de aceleração, a precisão geral pode ser garantida acima de 98%.
| vllm-0.6.2 | Novita AI | |
| Camadas de esparsidade KV | completa | janela deslizante=1536 |
| 22 | 0.4517 | 0.4496 |
| 26 | 0.4517 | 0.4476 |
| 31 | 0.4517 | 0.4476 |
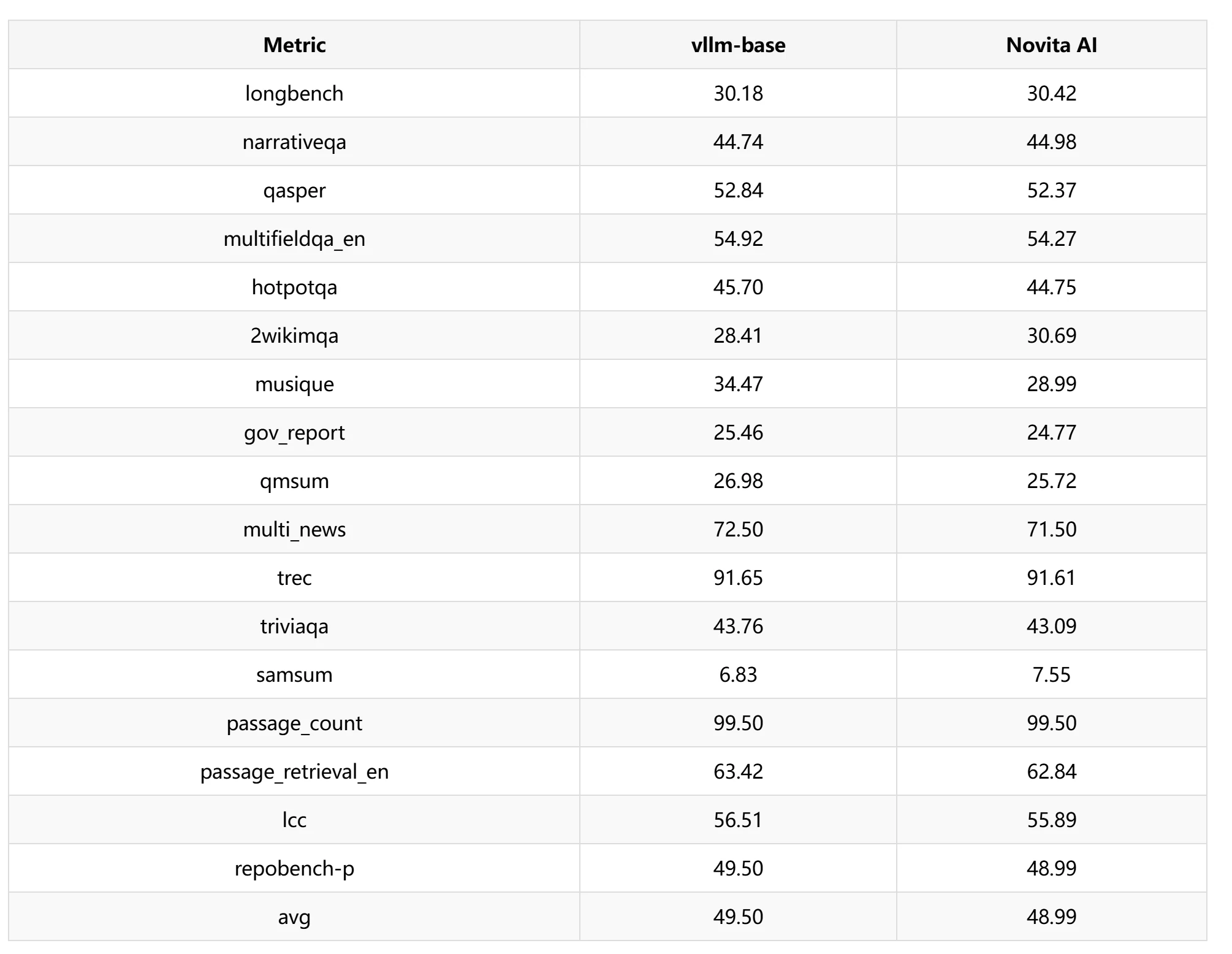
No teste LongBench, selecionamos uma janela deslizante de 1024 para teste de desempenho e constatamos que a perda de precisão foi de cerca de 1,03%.
Benchmarks de throughput: Em aplicações reais de LLM, uma configuração de comprimento de entrada/saída de 5000/500 é a mais comum, e o índice TTFT deve ser inferior a 2s. Com base nessas condições, realizamos testes comparativos de desempenho em lote, que resultaram em uma aceleração de inferência de 1,5x para vLLM.
| Throughput | vllm-0.6.2 | Novita AI |
| Camadas de esparsidade KV | completa | janela deslizante=1536 |
| 22 | 1 | 1.26 |
| 26 | 1 | 1.34 |
| 31 | 1 | 1.44 |
Principais alterações
Os arquivos modificados incluem principalmente:
- Flash attention, pontuação esparsa baseada em Flash attention, garantindo que a perda de desempenho do kernel seja inferior a 1%.
- Paged attention e reshape_and_cache, pontuação esparsa baseada em Paged attention e sincronização da pontuação esparsa nas fases de preenchimento e decodificação.
- Block_manager e outras funções relacionadas ao gerenciamento de memória e preparação de tensores.
Conclusão
A Novita AI também suporta paralelismo de tensores para permitir que modelos como Llama3-70B sejam executados em múltiplas GPUs. Atualmente, não suporta código aberto por algumas razões, mas esperamos contribuir com tecnologia e ideias para a comunidade e recebemos com satisfação intercâmbios técnicos com todos. Apenas um aviso: Os seguintes recursos ainda não são suportados no vLLM-0.6.2:
- Chunked-prefill
- Prefix caching
- FlashInfer e outros backends que não sejam FlashAttention
- Decodificação especulativa
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma GPU em nuvem acessível e confiável para construção e escalonamento.
Leitura recomendada



