

Este artigo explora principalmente direções viáveis para acelerar a inferência quantizada com base nos artigos de pesquisa mais recentes sobre hardware mainstream de GPU e algoritmos de quantização. No contexto dos esquemas atuais de quantização, vamos nos aprofundar no tema. Uma Breve Introdução à Quantização A quantização de modelos é uma técnica de compressão de modelos que visa reduzir o tamanho do modelo ajustando a largura de bits (bit-width) dos pesos e ativações. Essa redução ajuda a diminuir as cargas computacionais, a E/S de memória da GPU e a ocupação, reduzindo, em última análise, a latência e aumentando a taxa de transferência. O diagrama a seguir ilustra como a quantização acelera o aprendizado profundo:
- Passo 1: O armazenamento de pesos e ativações é carregado da memória para as unidades de computação MatMul. A largura de bits dos pesos e ativações impacta significativamente a latência da transferência de dados.
- Passo 2: As unidades de computação MatMul realizam a multiplicação de matrizes, onde a largura de bits e o formato também influenciam a latência.
- Passo 3: Os acumuladores geralmente têm larguras de bits mais altas para soma de alta precisão. Após a soma, os valores nos acumuladores podem passar por requantização (a largura de bits de saída determina o número de bits transmitidos e armazenados de volta na memória para a próxima etapa de processamento).

Uma visão geral esquemática de um acelerador de aprendizado profundo Com base em diferentes esquemas de quantização, existem duas abordagens principais: Treinamento Ciente da Quantização (QAT) e Quantização Pós-Treinamento (PTQ).
- QAT (Quantization-Aware Training), também conhecido como Quantização Online, requer esforço computacional adicional durante o treinamento. Ele combina a quantização com a retropropagação para ajustar os pesos do modelo, garantindo que o modelo quantizado mantenha a precisão.
- PTQ (Post-Training Quantization), também conhecida como Quantização Offline, envolve a quantização de um modelo pré-treinado usando o mínimo ou nenhum dado adicional. Este processo inclui calibração, que pode envolver o escalonamento dos pesos do modelo. Existem dois tipos de métodos PTQ:
- Quantização Dinâmica Pós-Treinamento (PDQ) não depende de conjuntos de dados de calibração. Em vez disso, converte diretamente cada camada usando fórmulas de quantização. QLoRA (Quantization-aware Low-Rank Adaptation) emprega este método.
- Quantização Pós-Calibração (PCQ) requer conjuntos de dados representativos para ajustar os pesos de quantização com base na entrada e saída de cada camada do modelo. GPTQ (Generative Pre-training Transformer for Quantization) adota esta abordagem.
Suporte de Hardware
Série NVIDIA As placas da série NV, devido ao ecossistema CUDA, sempre mantiveram uma posição de liderança no suporte a diferentes precisões e tipos de dados.
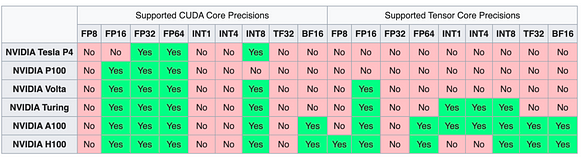

Desafios na Quantização de LLMs
Vamos começar com uma comparação simples. Realizamos quantização INT básica em ambos os modelos ResNet18 e OPT-13B. Descobrimos que o desempenho do ResNet18 foi quase inalterado, enquanto o OPT-13B sofreu perdas significativas.
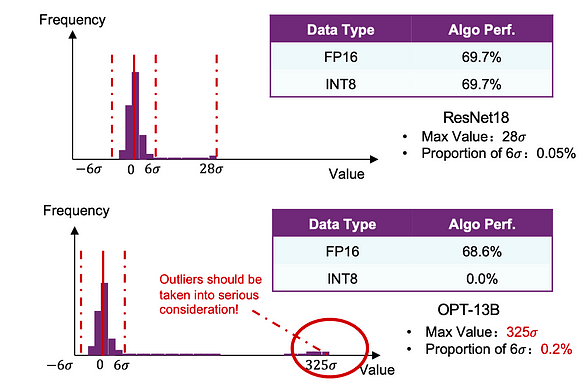


Esquema do LLM.int8() De acordo com o diagrama acima, X representa as ativações de cada camada, com tantas linhas quanto o comprimento da sequência e tantas colunas quanto o tamanho oculto (hidden size). As barras amarelas no diagrama representam outliers, ilustrando vividamente seu padrão de distribuição (a segunda conclusão). O significado da quantização vetorial (vector-wise quantization) é que, para colunas que não são outliers, elas são quantizadas simetricamente usando int8. Como estamos lidando com colunas, na multiplicação de matrizes, os pesos W correspondentes precisam ser extraídos das linhas correspondentes para operações int8. Para as colunas outliers amarelas, tanto linhas quanto colunas são usadas para operações fp16. Finalmente, os resultados das duas partes são somados, o que equivale à multiplicação direta de matrizes. Através do método de quantização mista do LLM.int8(), a precisão é quase a mesma do fp32, e os dados experimentais não são colados aqui.
FP8 e INT8
Por que mencionar especificamente FP8 e INT8? Isso se deve principalmente às arquiteturas de GPU mais recentes, como a arquitetura Hopper e os Tensor Cores, que suportam computação de precisão FP8. Portanto, vale a pena explorar a quantização FP8.



- De acordo com os princípios de acumulação de ponto fixo e ponto flutuante no design de circuitos, as unidades MAC FP8 são 50% a 180% menos eficientes que as unidades INT8. Se a carga de trabalho for limitada computacionalmente, isso diminui a velocidade de processamento dos chips dedicados.
- Para a maioria das redes, o FP8 tem desempenho pior que o INT8, mesmo para estruturas como transformers com um grande número de outliers, que podem ser tratados por meio de métodos de precisão mista ou treinamento ciente da quantização. No geral, no contexto da quantização pura, formatos de ponto flutuante como FP8-E4 e FP8-E5 não podem substituir o INT8 em termos de desempenho e precisão na inferência de aprendizado profundo. Então, onde reside a vantagem e o posicionamento do formato FP8? Primeiro, vamos resumir as vantagens do formato FP8:
- Tensor Cores FP8 são mais rápidos que Tensor Cores de 16 bits.
- Reduz a movimentação de memória.
- Se o modelo já foi treinado em FP8, a implantação é mais conveniente.
- FP8 tem uma faixa dinâmica mais ampla.
- O circuito de conversão de FP8 para FP16/FP32/BF16 pode ser projetado de forma mais simples e direta, sem a sobrecarga de multiplicação e adição necessária para a conversão de INT8/UINT8 para FP. Com base nessas vantagens, é evidente que o FP8 é, na verdade, mais adequado para treinamento. Referindo-se a [5], sem modificar nenhum hiperparâmetro, como taxa de aprendizado e decadência de peso, tanto em tarefas de pré-treinamento quanto em tarefas downstream, os modelos treinados usando FP8 apresentam desempenho semelhante aos modelos treinados usando treinamento de alta precisão BF16. Vale a pena notar que, durante o treinamento do modelo GPT-175B, em comparação com o método TE, o novo framework de precisão mista FP8 na plataforma GPU H100 pode reduzir o tempo de treinamento em 17% e o uso de memória em 21%.
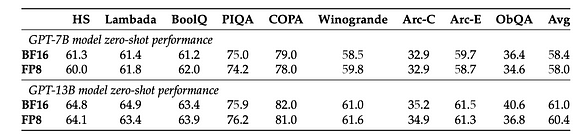

- Para um determinado desempenho zero-shot, a precisão de 4 bits fornece a melhor escala para quase todas as séries e tamanhos de modelo (a precisão de 4 bits não resulta em quedas significativas de desempenho para o desempenho do modelo). A única exceção é o BLOOM-176B, onde 3 bits têm desempenho ligeiramente melhor, mas não significativamente.
- A precisão de 4 bits é atualmente a precisão mais eficaz em termos de bits, indicando também que o desempenho da precisão de 3 bits pode ser melhorado. Portanto, a pesquisa sobre precisão de baixo bit abaixo de 4 bits é uma direção que vale a pena.
- A pesquisa sobre quantização em nível de bit revela que os tipos de dados e o tamanho do bloco são fatores-chave que afetam a eficácia da quantização em nível de bit. Com base no exposto, podemos concluir que a quantização de precisão de 4 bits é atualmente a solução mais econômica. No entanto, entre os dados de 4 bits, qual tipo de dados produz melhores resultados de quantização? Referindo-se a [7], o método LLM-FP4 propõe quantização FP4 para grandes modelos de linguagem (LLMs) de forma pós-treinamento, quantizando pesos e ativações em valores de ponto flutuante de 4 bits. As soluções PTQ existentes são baseadas principalmente em inteiros e têm dificuldades com larguras de bits abaixo de 8 bits. Em comparação com a quantização inteira, a quantização de ponto flutuante (FP) é mais flexível, lidando melhor com distribuições de cauda longa ou em forma de sino, e tornou-se a escolha padrão para muitas plataformas de hardware. Referência do projeto: https://github.com/nbasyl/LLM-FP4 Uma das características da quantização FP é que seu desempenho depende em grande parte da seleção dos bits de expoente e do intervalo de corte. O LLM-FP4 constrói uma linha de base FP-PTQ robusta buscando os parâmetros de quantização ideais. Além disso, existem variações inter-canal mais altas e variações intra-canal mais baixas na distribuição de ativação, o que aumenta a dificuldade da quantização de ativação. Para resolver esse problema, o LLM-FP4 propõe quantização de ativação por canal (per-channel activation quantization) e demonstra que esses fatores de escala adicionais podem ser reparametrizados em biases de expoente dos pesos, incorrendo em custos insignificantes. O LLM-FP4 quantifica pesos e ativações no LLaMA-13B em apenas 4 bits pela primeira vez, alcançando uma pontuação média de 63,1 em tarefas de raciocínio zero-shot de senso comum, que é apenas 5,8 menor que a amostra completa e supera significativamente o modelo de última geração anterior em 12,7 pontos percentuais. Os dados específicos podem ser encontrados na figura a seguir:
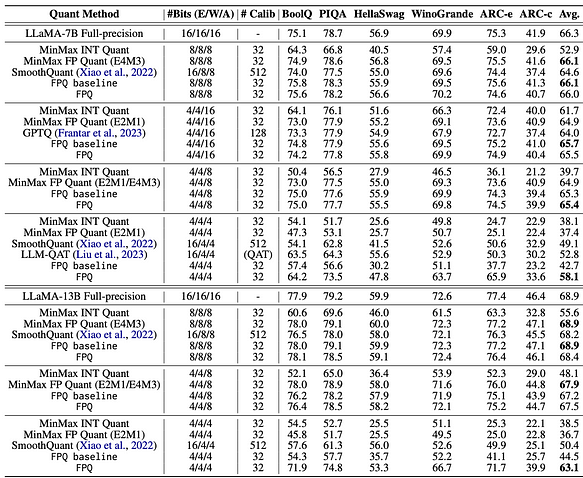
- Quando as ativações não são quantizadas e os embeddings de palavras juntamente com os pesos são quantizados em 4 bits, o LLM-FP4 (tipo FP) tem uma ligeira vantagem sobre algoritmos como GPTQ (tipo INT).
- Quando as ativações são quantizadas em 8 bits e os embeddings de palavras juntamente com os pesos são quantizados em 4 ou 8 bits, o LLM-FP4 (tipo FP) tem desempenho semelhante a outros algoritmos (tipo INT), sem diferença significativa no desempenho.
- Quando as ativações são quantizadas em 4 bits, o LLM-FP4 (tipo FP) mostra uma melhoria notável em comparação com outros algoritmos (tipo INT). Em conclusão, se as ativações não forem quantizadas em 4 bits, atualmente não há vantagem significativa do FP4 sobre o INT4.
Alguns projetos de quantização notáveis incluem
GPTQ-for-LLaMa
-
Modelos quantizados usando GPTQ oferecem vantagens significativas de velocidade. Em termos simples, o GPTQ quantiza cada parâmetro dentro de um bloco individualmente e, após cada quantização de parâmetro, ajustes são feitos nos outros parâmetros dentro do bloco para compensar a perda de precisão causada pela quantização.
-
A quantização GPTQ requer um conjunto de dados de calibração para realizar a quantização pós-treinamento no modelo, a fim de obter pesos quantizados. O conceito do GPTQ se origina do algoritmo OBD de Yann LeCun proposto em 1990, que foi continuamente melhorado com métodos como OBS, OBC (OBQ), e o GPTQ é uma versão acelerada do método OBQ.
-
O repositório GPTQ-for-LLaMa fornece uma solução de quantização GPTQ especificamente para LLaMa. É recomendado para implantar modelos LLaMa em GPUs.
-
Link do Projeto: GPTQ-for-LLaMa ExLlama
-
ExLlama vem em duas versões, ExLlama e ExLlamaV2, servindo como uma biblioteca de inferência para executar LLM local em GPUs modernas de consumo.
-
ExLlamaV2 suporta modelos GPTQ de 4 bits, similar ao V1, mas também introduz o novo formato “EXL2”. O EXL2, baseado nos mesmos métodos de otimização do GPTQ, suporta quantização de 2, 3, 4, 5, 6 e 8 bits, permitindo misturar níveis de quantização dentro do modelo para alcançar qualquer taxa de bits média entre 2 e 8 bits por peso.
-
ExLlamaV2 pode aplicar múltiplos níveis de quantização a cada camada linear, produzindo algo semelhante a uma quantização esparsa, onde pesos mais importantes (colunas) são quantizados com mais bits. As mesmas técnicas de remapeamento que permitem que o ExLlama funcione de forma eficiente com modelos sequenciais possibilitam esse formato misto com quase nenhum impacto no desempenho.
-
Geralmente, o ExLlama oferece velocidade de inferência ligeiramente mais rápida em comparação com outras abordagens de quantização.
-
Link do Projeto: ExLlama GGML
-
GGML é uma biblioteca C focada em aprendizado de máquina, criada por Georgi Gerganov, daí a abreviatura “GG”. A biblioteca não apenas fornece elementos fundamentais de aprendizado de máquina, como tensores, mas também oferece um formato binário único para distribuição de LLM.
-
GGML, escrito em C, suporta quantização inteira (4 bits, 5 bits, 8 bits) e float de 16 bits.
-
GGML coopera perfeitamente com a biblioteca llama.cpp, garantindo que os profissionais possam aproveitar efetivamente o poder do LLM. O principal objetivo da biblioteca llama.cpp é permitir o uso de modelos LLaMA quantizados em INT4 no MacBook.
-
Link do Projeto: GGML Transformer Engine O Transformer Engine (TE) é uma biblioteca projetada para acelerar modelos Transformer em GPUs NVIDIA, incluindo o uso de precisão de ponto flutuante de 8 bits (FP8) em GPUs Hopper, proporcionando assim melhor desempenho com menor utilização de memória tanto no treinamento quanto na inferência. O TE oferece um conjunto de blocos de construção altamente otimizados para arquiteturas Transformer populares, juntamente com uma API de classe de precisão mista automática que se integra perfeitamente ao código específico do framework. Além disso, o TE inclui uma API C++ independente de framework para suporte FP8 em Transformers, que pode ser integrada com outras bibliotecas de aprendizado profundo. As principais características incluem:
-
Módulos fáceis de usar para construir camadas Transformer que suportam FP8.
-
Otimização para modelos Transformer, incluindo fusão de kernels.
-
Suporte para FP8 em GPUs NVIDIA Hopper e NVIDIA Ada.
-
Otimização para todas as precisões (FP16, BF16) na arquitetura NVIDIA Ampere e versões superiores. Link do Projeto: Transformer Engine Para testes de atenção, você pode importar
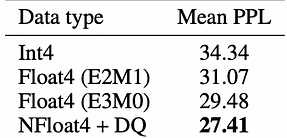
te.LayerNormLineare medir o tempo médio para o cálculo da atenção. Resultados dos testes:Estrutura do ModeloFormato de DadosRTX 4090RTX 3090Atenção BásicaAtenção Nativa PyTorchFP1692ms183msAtenção Básica + TESubstituição de Linear e LayerNorm txFP1696msNão suportadoAtenção Básica + Otimização LayerNorm do TETE.LayerNormLinearFP1696msNão suportadoTE CompletoAlgoritmo de Atenção Total TEFP1674msNão suportadoTE Completo + FP8Substituição da Propagação Direta FP8FP842msNão suportado Conclusão dos testes: No caso do Transformer Engine, há uma melhoria de aproximadamente 20% em relação ao algoritmo de atenção básica ao usar fp16. Além disso, há uma melhoria significativa de 54,5% ao usar fp8, indicando que vale a pena investir tempo para melhorar o desempenho da inferência. Bitsandbytes: Bitsandbytes é um wrapper leve para funções CUDA personalizadas, especificamente otimizado para operações de 8 bits, multiplicação de matrizes (LLM.int8()) e funções de quantização, suportando principalmente o algoritmo de quantização LLM.int8(). A biblioteca bitsandbytes suporta métodos de quantização como quantiles, linear e dinâmico. É um dos métodos mais simples disponíveis e não requer dados de calibração de quantização ou processos de calibração. Pode ser prontamente usado com qualquer modelo que contenha módulos torch.nn.Linear. A análise atual sugere que NF4 (tipo de dados NormalFloat) e FP4 são técnicas de quantização de 4 bits igualmente eficazes, exibindo atributos semelhantes, como velocidade de inferência, consumo de memória e qualidade do conteúdo gerado. O tipo de dados NormalFloat é uma forma aprimorada da técnica de quantização, representando a representação ideal de pesos em uma distribuição normal em termos de teoria da informação. É usado principalmente pelo método QLoRA para ajuste fino de modelos com precisão de 4 bits. Abaixo estão alguns dados do QLoRA:
Conclusão
A quantização de 4 bits é atualmente o esquema de quantização mais econômico. No entanto, a otimização varia com base no nível de quantização dos embeddings de palavras, pesos e ativações. Na maioria dos cenários, exceto para ativações quantizadas em 4 bits, a quantização inteira (Int) oferece melhor relação custo-benefício, incluindo cenários sem quantização. Assim, a quantização de baixo bit, particularmente focando em ativações através de quantização pós-treinamento (PTQ), é uma direção promissora para acelerar a quantização. INT8 é o esquema de quantização mais comumente usado atualmente. Em comparação com INT8, o FP8 não pode substituí-lo completamente em cenários de quantização, mas é adequado para treinamento de modelos, oferecendo uma solução para problemas de desempenho de inferência sem a necessidade de quantização. Integrar técnicas relacionadas ao FP8 com Tensor Cores de hardware para maximizar a velocidade de inferência é uma nova direção que vale a pena explorar. Projetos baseados no algoritmo GPTQ dominam o cenário de Grandes Modelos de Linguagem (LLM). No entanto, novos tipos de dados (como FP4 e NF4), precisão de bits mais baixa e quantização dinâmica apresentam oportunidades para inovação e pesquisa. Além das GPUs NVIDIA, novas GPUs e CPUs (como AMD, GPUs domésticas e Qualcomm) apresentam novas oportunidades. Adaptar rapidamente algoritmos de quantização a diferentes plataformas de hardware e maximizar o desempenho do hardware é uma nova direção para exploração.
Artigos de Referência
[1]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale [2]Outliers Dimensions that Disrupt Transformers Are Driven by Frequency [3]Smoothquant: Accurate and efficient post-training quantization for large language models [4]FP8 versus INT8 for efficient deep learning inference [5]FP8-LM: Training FP8 Large Language Models [6]The case for 4-bit precision: k-bit Inference Scaling Laws [7]LLM-FP4: 4-Bit Floating-Point Quantized Transformers [8]GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers [9]Understanding the Impact of Post-Training Quantization on Large Language Models [10]QLoRA: Efficient Finetuning of Quantized LLMs
novita.ai fornece API Stable Diffusion e centenas de APIs de geração de imagens AI rápidas e mais baratas para 10.000 modelos. 🎯 Geração mais rápida em apenas 2s, pague conforme o uso, a partir de US$0,0015 por imagem padrão, você pode adicionar seus próprios modelos e evitar manutenção de GPU. Livre para compartilhar extensões de código aberto.
Leitura recomendada


