

This article primarily explores feasible directions for speeding up quantized inference based on the latest research papers on mainstream GPU hardware and quantization algorithms. Against the backdrop of current quantization schemes, let’s delve into the topic. A Brief Introduction to Quantization Model quantization is a model compression technique aimed at reducing model size by adjusting the bit-width of weights and activations. This reduction aids in lowering computational loads, GPU memory I/O, and occupancy, ultimately reducing latency and enhancing throughput. The following diagram illustrates how quantization speeds up deep learning:
- Step 1: Weight and activation storage are loaded from memory into MatMul computing units. The bit-width of weights and activations significantly impacts data transfer latency.
- Step 2: MatMul computing units perform matrix multiplication, where bit-width and format also influence latency.
- Step 3: Accumulators typically have higher bit-widths for high-precision summation. After summation, the values in the accumulators may undergo re-quantization (the output bit-width determines the number of bits transmitted and stored back in memory for the next processing step).

A schematic overview of a deep learning accelerator Based on different quantization schemes, there are two main approaches: Quantization-Aware Training (QAT) and Post-Training Quantization (PTQ).
- QAT (Quantization-Aware Training), also known as Online Quantization, requires additional computational effort during training. It combines quantization with backpropagation to adjust model weights, ensuring that the quantized model maintains accuracy.
- PTQ (Post-Training Quantization), also known as Offline Quantization, involves quantizing a pre-trained model using minimal or no additional data. This process includes calibration, which may involve scaling model weights. There are two types of PTQ methods:
- Post-Dynamic Quantization (PDQ) does not rely on calibration datasets. Instead, it directly converts each layer using quantization formulas. QLoRA (Quantization-aware Low-Rank Adaptation) employs this method.
- Post-Calibration Quantization (PCQ) requires representative datasets to adjust quantization weights based on the input-output of each layer in the model. GPTQ (Generative Pre-training Transformer for Quantization) adopts this approach.
Hardware Support
NVIDIA Series The NV series of cards, due to the CUDA ecosystem, have consistently maintained a leading position in supporting different precision and data types.
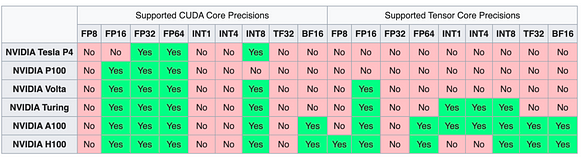

Challenges in LLM Quantization
Let’s start with a simple comparison. We conducted basic INT quantization on both ResNet18 and OPT-13B models. We found that the performance of ResNet18 was hardly affected, while OPT-13B experienced significant losses.
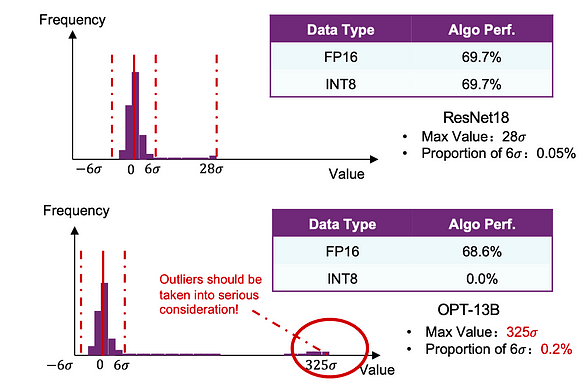


Schematic of LLM.int8() According to the diagram above, X represents the activations of each layer, with as many rows as sequence length and as many columns as hidden size. The yellow bars in the diagram represent outliers, vividly illustrating their distribution pattern (the second conclusion). The meaning of vector-wise quantization is that for columns that are not outliers, they are quantized symmetrically using int8. Since we are dealing with columns, in matrix multiplication, the corresponding weights W need to be extracted from the corresponding rows for int8 operations. For the yellow outlier columns, both rows and columns are used for fp16 operations. Finally, the results of the two parts are added together, equivalent to direct matrix multiplication. Through the mixed quantization method of LLM.int8(), the accuracy is almost the same as fp32, and the experimental result data is not pasted here.
FP8 and INT8
Why specifically mention FP8 and INT8? This is mainly because of the latest GPU architectures, such as the hopper architecture and tensor cores, which support FP8 precision computation. Therefore, it is worthwhile to explore FP8 quantization.



- According to the principles of fixed-point and floating-point accumulation in circuit design, FP8 MAC units are 50% to 180% less efficient than INT8 units. If the workload is computation-bound, this slows down the processing speed of dedicated chips.
- For most networks, FP8 performs worse than INT8, even for structures like transformers with a large number of outliers, which can be addressed through mixed precision or quantization-aware training methods. Overall, in the context of pure quantization, floating-point formats like FP8-E4 and FP8-E5 cannot replace INT8 in terms of performance and accuracy in deep learning inference. So, where does the advantage and positioning of the FP8 format lie? First, let’s summarize the advantages of the FP8 format:
- FP8 Tensor Cores are faster than 16-bit Tensor Cores.
- Reduces memory movement.
- If the model has already been trained in FP8, deployment is more convenient.
- FP8 has a wider dynamic range.
- The conversion circuit from FP8 to FP16/FP32/BF16 can be designed more simply and directly, without the multiplication and addition overhead required for the conversion from INT8/UINT8 to FP. Based on these advantages, it’s evident that FP8 is actually more suitable for training. Referring to [5], without modifying any hyperparameters such as learning rate and weight decay, both in pre-training tasks and downstream tasks, models trained using FP8 perform similarly to models trained using BF16 high-precision training. It’s worth noting that during the training of the GPT-175B model, compared to the TE method, the newly proposed FP8 mixed precision framework on the H100 GPU platform can reduce training time by 17% and memory usage by 21%.
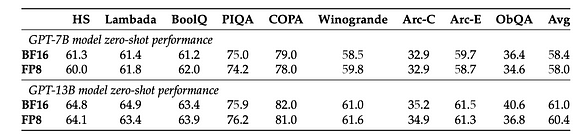

- For a given zero-shot performance, 4-bit precision provides the best scaling for almost all model series and sizes (4-bit precision does not result in significant performance drops for model performance). The only exception is BLOOM-176B, where 3 bits perform slightly better, but not significantly so.
- 4-bit precision is currently the most effective precision in a per-bit manner, while also indicating that the performance of 3-bit precision could be improved. Therefore, research on low-bit precision below 4 bits is a worthwhile direction.
- Research on bit-level quantization reveals that data types and block size are key factors affecting the effectiveness of bit-level quantization. Based on the above, we can conclude that 4-bit precision quantization is currently the most cost-effective solution. However, among the 4-bit data, which data type yields better quantization results? Referring to [7], the LLM-FP4 method proposes FP4 quantization for large language models (LLMs) in a post-training manner, quantizing weights and activations into 4-bit floating-point values. Existing PTQ solutions are mainly based on integers and struggle with bit widths below 8 bits. Compared to integer quantization, floating-point (FP) quantization is more flexible, better handling long-tail or bell-shaped distributions, and has become the default choice for many hardware platforms. Project reference: https://github.com/nbasyl/LLM-FP4 One of the characteristics of FP quantization is that its performance largely depends on the selection of exponent bits and clipping range. LLM-FP4 constructs a robust FP-PTQ baseline by searching for the optimal quantization parameters. Additionally, there are higher inter-channel variances and lower intra-channel variances in the activation distribution, which increases the difficulty of activation quantization. To address this issue, LLM-FP4 proposes per-channel activation quantization and demonstrates that these additional scaling factors can be reparameterized into exponent biases of weights, incurring negligible costs. LLM-FP4 quantifies weights and activations in LLaMA-13B into only 4 bits for the first time, achieving an average score of 63.1 on common-sense zero-shot reasoning tasks, which is only 5.8 lower than the full sample and significantly outperforms the previous state-of-the-art model by 12.7 percentage points. The specific data can be found in the following figure:
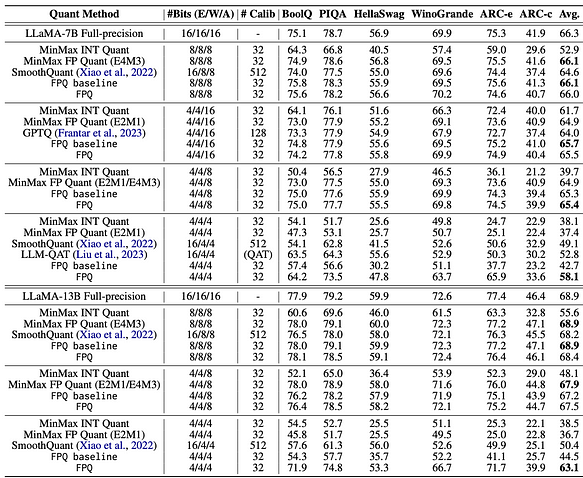
- When activations are not quantized and word embeddings along with weights are quantized to 4 bits, LLM-FP4 (FP type) has a slight advantage over algorithms like GPTQ (INT type).
- When activations are quantized to 8 bits and word embeddings along with weights are quantized to either 4 or 8 bits, LLM-FP4 (FP type) performs similarly to other algorithms (INT type), with no significant difference in performance.
- When activations are quantized to 4 bits, LLM-FP4 (FP type) shows a noticeable improvement compared to other algorithms (INT type). In conclusion, if activations are not quantized to 4 bits, there is currently no significant advantage of FP4 over INT4.
Some noteworthy quantization projects include
GPTQ-for-LLaMa
-
Models quantized using GPTQ offer significant speed advantages. In simple terms, GPTQ quantizes each parameter within a block individually, and after each parameter quantization, adjustments are made to the other parameters within the block to compensate for the precision loss caused by quantization.
-
GPTQ quantization requires a calibration dataset to perform post-training quantization on the model to obtain quantized weights. The concept of GPTQ originates from Yann LeCun’s OBD algorithm proposed in 1990, which has been continuously improved with methods like OBS, OBC (OBQ), and GPTQ is an accelerated version of the OBQ method.
-
The GPTQ-for-LLaMa repository provides a GPTQ quantization solution specifically for LLaMa. It is recommended for deploying LLaMa models on GPUs.
-
Project Link: GPTQ-for-LLaMa ExLlama
-
ExLlama comes in two versions, ExLlama and ExLlamaV2, serving as an inference library for running local LLM on modern consumer-grade GPUs.
-
ExLlamaV2 supports 4-bit GPTQ models similar to V1 but also introduces the new “EXL2” format. EXL2, based on the same optimization methods as GPTQ, supports 2, 3, 4, 5, 6, and 8-bit quantization, allowing mixing of quantization levels within the model to achieve any average bitrate between 2 to 8 bits per weight.
-
ExLlamaV2 can apply multiple quantization levels to each linear layer, producing something akin to sparse quantization, where more important weights (columns) are quantized with more bits. The same remapping techniques that allow ExLlama to work efficiently with sequential models enable this mixed format with almost no impact on performance.
-
Generally, ExLlama offers slightly faster inference speed compared to other quantization approaches.
-
Project Link: ExLlama GGML
-
GGML is a C library focused on machine learning, created by Georgi Gerganov, hence the abbreviation “GG.” The library not only provides fundamental elements of machine learning such as tensors but also offers a unique binary format for distributing LLM.
-
GGML, written in C, supports Integer quantization (4-bit, 5-bit, 8-bit), and 16-bit float.
-
GGML seamlessly cooperates with the llama.cpp library, ensuring practitioners can effectively harness the power of LLM. The main goal of the llama.cpp library is to allow the use of INT4 quantized LLaMA models on MacBook.
-
Project Link: GGML Transformer Engine Transformer Engine (TE) is a library designed to accelerate Transformer models on NVIDIA GPUs, including the use of 8-bit floating-point (FP8) precision on Hopper GPUs, thereby providing better performance with lower memory utilization in both training and inference. TE offers a set of highly optimized building blocks for popular Transformer architectures, along with an auto-mixed-precision class API that seamlessly integrates with framework-specific code. Additionally, TE includes a framework-agnostic C++ API for FP8 support in Transformers, which can be integrated with other deep learning libraries. Key features include:
-
Easy-to-use modules for building Transformer layers that support FP8.
-
Optimization for Transformer models, including kernel fusion.
-
Support for FP8 on NVIDIA Hopper and NVIDIA Ada GPUs.
-
Optimization for all precisions (FP16, BF16) on NVIDIA Ampere GPU architecture and higher versions. Project Link: Transformer Engine For attention testing, you can import
te.LayerNormLinearand measure the average time for attention computation. StageModel StructureData FormatRTX 4090RTX 3090Basic AttentionPyTorch Native AttentionFP1692ms183msBasic Attention + TELinear and LayerNorm tx replacementFP1696msNot supportedBasic Attention + TE’s LayerNorm OptimizationTE.LayerNormLinearFP1696msNot supportedTE FullTE Full Attention AlgorithmFP1674msNot supportedTE Full + FP8FP Forward Propagation ReplacementFP842msNot supported Conclusion of the tests: In the case of Transformer Engine, there is approximately a 20% improvement relative to the basic attention algorithm when using fp16. Additionally, there is a significant 54.5% improvement when using fp8, indicating that it is worthwhile to invest time in improving inference performance. Bitsandbytes: Bitsandbytes is a lightweight wrapper for custom CUDA functions, specifically optimized for 8-bit operations, matrix multiplication (LLM.int8()), and quantization functions, primarily supporting the LLM.int8() quantization algorithm. The bitsandbytes library supports quantization methods such as quantiles, linear, and dynamic quantization. It is one of the simplest methods available and does not require quantization calibration data or calibration processes. It can be readily used with any model containing torch.nn.Linear modules. Current analysis suggests that NF4 (NormalFloat data type) and FP4 are equally effective 4-bit quantization techniques, exhibiting similar attributes such as inference speed, memory consumption, and quality of generated content. The NormalFloat data type is an enhanced form of quantization technique, representing the optimal representation of weights in a normal distribution in terms of information theory. It is primarily used by the QLoRA method for fine-tuning models with 4-bit precision. Below is some data from QLoRA:
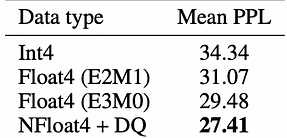
In Conclusion
4-bit quantization is currently the most cost-effective quantization scheme. However, the optimization varies based on the quantization level of word embeddings, weights, and activations. In most scenarios, except for activations quantized to 4 bits, integer (Int) quantization offers better cost-effectiveness, including non-quantization scenarios. Thus, low-bit quantization, particularly focusing on activations through post-training quantization (PTQ), is a promising direction for accelerating quantization. INT8 is the most commonly used quantization scheme at present. Compared to INT8, FP8 cannot fully replace it in quantization scenarios but is suitable for model training, offering a solution to inference performance issues without the need for quantization. Integrating FP8-related techniques with hardware tensor cores to maximize inference speed is a new direction worth exploring. Projects based on the GPTQ algorithm dominate the landscape of Large Language Models (LLM). However, new data types (such as FP4 and NF4), lower bit precision, and dynamic quantization present opportunities for innovation and research. Apart from NVIDIA GPUs, new GPUs and CPUs (such as AMD, domestic GPUs, and Qualcomm) present new opportunities. Adapting quantization algorithms to different hardware platforms quickly and maximizing hardware performance is a new direction for exploration.
Reference Papers
[1]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale [2]Outliers Dimensions that Disrupt Transformers Are Driven by Frequency [3]Smoothquant: Accurate and efficient post-training quantization for large language models [4]FP8 versus INT8 for efficient deep learning inference [5]FP8-LM: Training FP8 Large Language Models [6]The case for 4-bit precision: k-bit Inference Scaling Laws [7]LLM-FP4: 4-Bit Floating-Point Quantized Transformers [8]GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers [9]Understanding the Impact of Post-Training Quantization on Large Language Models [10]QLoRA: Efficient Finetuning of Quantized LLMs
novita.ai provides Stable Diffusion API and hundreds of fast and cheapest AI image generation APIs for 10,000 models.🎯 Fastest generation in just 2s, Pay-As-You-Go, a minimum of $0.0015 for each standard image, you can add your own models and avoid GPU maintenance. Free to share open-source extensions.
Recommended reading


