

تستكشف هذه المقالة بشكل أساسي الاتجاهات القابلة للتطبيق لتسريع استدلال التكميم بناءً على أحدث الأوراق البحثية حول أجهزة GPU السائدة وخوارزميات التكميم. على خلفية مخططات التكميم الحالية، دعنا نتعمق في الموضوع. مقدمة موجزة عن التكميم تكميم النموذج هو تقنية ضغط للنموذج تهدف إلى تقليل حجم النموذج عن طريق ضبط عرض البت للأوزان والتنشيطات. يساعد هذا التخفيض في خفض الأعباء الحسابية، وإدخال/إخراج ذاكرة GPU، والإشغال، مما يقلل في النهاية من زمن الاستجابة ويعزز الإنتاجية. يوضح الرسم البياني التالي كيف يعمل التكميم على تسريع التعلم العميق:
- الخطوة 1: يتم تحميل تخزين الأوزان والتنشيطات من الذاكرة إلى وحدات الحساب MatMul. يؤثر عرض البت للأوزان والتنشيطات بشكل كبير على زمن نقل البيانات.
- الخطوة 2: تقوم وحدات الحساب MatMul بإجراء ضرب المصفوفات، حيث يؤثر عرض البت والتنسيق أيضًا على زمن الاستجابة.
- الخطوة 3: عادةً ما تحتوي المراكمات على عرض بت أعلى للجمع عالي الدقة. بعد الجمع، قد تخضع القيم في المراكمات لإعادة التكميم (يحدد عرض بت الإخراج عدد البتات المنقولة والمخزنة مرة أخرى في الذاكرة لخطوة المعالجة التالية).

نظرة عامة تخطيطية على مسرع التعلم العميق بناءً على مخططات التكميم المختلفة، هناك طريقتان رئيسيتان: التدريب الواعي بالتكميم (QAT) والتكميم بعد التدريب (PTQ).
- QAT (التدريب الواعي بالتكميم)، المعروف أيضًا باسم التكميم عبر الإنترنت، يتطلب جهدًا حسابيًا إضافيًا أثناء التدريب. فهو يجمع بين التكميم والانتشار العكسي لضبط أوزان النموذج، مما يضمن أن النموذج المكمم يحافظ على الدقة.
- PTQ (التكميم بعد التدريب)، المعروف أيضًا باسم التكميم دون اتصال، يتضمن تكميم نموذج مُدرّب مسبقًا باستخدام الحد الأدنى من البيانات الإضافية أو بدونها. تتضمن هذه العملية معايرة، قد تتضمن قياس أوزان النموذج. هناك نوعان من طرق PTQ:
- التكميم الديناميكي اللاحق (PDQ) لا يعتمد على مجموعات بيانات المعايرة. بدلاً من ذلك، يقوم بتحويل كل طبقة مباشرة باستخدام صيغ التكميم. يستخدم QLoRA (التكيف منخفض الرتبة الواعي بالتكميم) هذه الطريقة.
- التكميم اللاحق بالمعايرة (PCQ) يتطلب مجموعات بيانات تمثيلية لضبط أوزان التكميم بناءً على إدخال وإخراج كل طبقة في النموذج. يتبنى GPTQ (تحويل المولد التوليدي السابق للتدريب للتكميم) هذا النهج.
دعم الأجهزة
سلسلة NVIDIA حافظت بطاقات سلسلة NV، بسبب نظام CUDA البيئي، باستمرار على موقع ريادي في دعم الدقة وأنواع البيانات المختلفة.
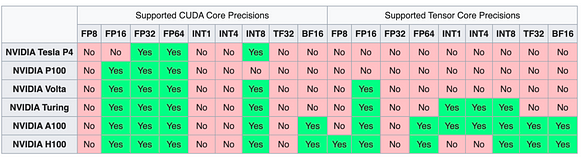

التحديات في تكميم LLM
لنبدأ بمقارنة بسيطة. قمنا بإجراء تكميم INT أساسي على كل من نموذجي ResNet18 و OPT-13B. وجدنا أن أداء ResNet18 لم يتأثر تقريبًا، بينما عانى OPT-13B من خسائر كبيرة.
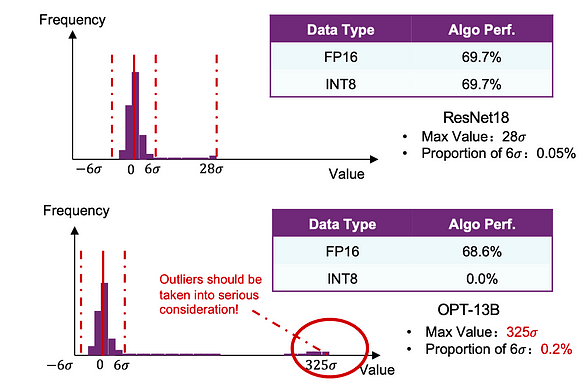


رسم تخطيطي لـ LLM.int8() وفقًا للرسم البياني أعلاه، يمثل X تنشيطات كل طبقة، مع عدد صفوف يساوي طول التسلسل وعدد أعمدة يساوي الحجم المخفي. تمثل الأشرطة الصفراء في الرسم البياني القيم الشاذة، موضحة بشكل واضح نمط توزيعها (الاستنتاج الثاني). معنى التكميم على مستوى المتجه هو أنه بالنسبة للأعمدة التي ليست قيمًا شاذة، يتم تكميمها بشكل متماثل باستخدام int8. نظرًا لأننا نتعامل مع الأعمدة، في ضرب المصفوفات، يجب استخراج الأوزان المقابلة W من الصفوف المقابلة لعمليات int8. بالنسبة للأعمدة الصفراء الشاذة، يتم استخدام كل من الصفوف والأعمدة لعمليات fp16. أخيرًا، يتم جمع نتائج الجزأين معًا، وهو ما يعادل ضرب المصفوفات مباشرة. من خلال طريقة التكميم المختلط لـ LLM.int8()، تكون الدقة تقريبًا مماثلة لـ fp32، ولا يتم لصق بيانات النتيجة التجريبية هنا.
FP8 و INT8
لماذا نذكر FP8 و INT8 على وجه التحديد؟ يرجع ذلك أساسًا إلى أحدث بنى GPU، مثل بنية hopper ونوى الموتر، التي تدعم الحساب بدقة FP8. لذلك، من الجدير استكشاف تكميم FP8.



- وفقًا لمبادئ التراكم ذي النقطة الثابتة والنقطة العائمة في تصميم الدوائر، تكون وحدات FP8 MAC أقل كفاءة بنسبة 50٪ إلى 180٪ من وحدات INT8. إذا كان عبء العمل محدودًا بالحساب، فإن هذا يبطئ سرعة معالجة الرقاقات المخصصة.
- بالنسبة لمعظم الشبكات، يكون أداء FP8 أسوأ من INT8، حتى بالنسبة للهياكل مثل المحولات التي تحتوي على عدد كبير من القيم الشاذة، والتي يمكن معالجتها من خلال الدقة المختلطة أو طرق التدريب الواعي بالتكميم. بشكل عام، في سياق التكميم الخالص، لا يمكن لتنسيقات النقطة العائمة مثل FP8-E4 و FP8-E5 أن تحل محل INT8 من حيث الأداء والدقة في استدلال التعلم العميق. إذن، أين تكمن ميزة وموقع تنسيق FP8؟ أولاً، دعنا نلخص مزايا تنسيق FP8:
- نوى FP8 Tensor أسرع من نوى Tensor 16 بت.
- يقلل من حركة الذاكرة.
- إذا تم تدريب النموذج بالفعل باستخدام FP8، يكون النشر أكثر ملاءمة.
- يتمتع FP8 بنطاق ديناميكي أوسع.
- يمكن تصميم دائرة التحويل من FP8 إلى FP16/FP32/BF16 بشكل أبسط وأكثر مباشرة، دون الحمل الإضافي للضرب والجمع المطلوب للتحويل من INT8/UINT8 إلى FP. بناءً على هذه المزايا، من الواضح أن FP8 في الواقع أكثر ملاءمة للتدريب. بالإشارة إلى [5]، دون تعديل أي معلمات مفرطة مثل معدل التعلم وتسوس الوزن، في كل من مهام ما قبل التدريب والمهام النهائية، تكون أداء النماذج المدربة باستخدام FP8 مشابهة لأداء النماذج المدربة باستخدام التدريب عالي الدقة BF16. يجدر بالذكر أنه أثناء تدريب نموذج GPT-175B، مقارنة بطريقة TE، يمكن لإطار FP8 المختلط الدقة المقترح حديثًا على منصة GPU H100 تقليل وقت التدريب بنسبة 17٪ واستخدام الذاكرة بنسبة 21٪.
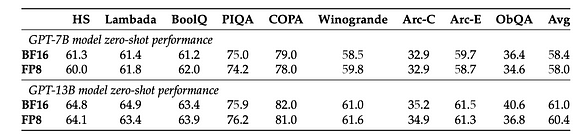

- بالنسبة لأداء صفر-shot معين، توفر دقة 4 بت أفضل تحجيم لجميع سلاسل وأحجام النماذج تقريبًا (دقة 4 بت لا تؤدي إلى انخفاضات كبيرة في الأداء لأداء النموذج). الاستثناء الوحيد هو BLOOM-176B، حيث يكون أداء 3 بت أفضل قليلاً، ولكن ليس بشكل ملحوظ.
- دقة 4 بت هي حاليًا الدقة الأكثر فعالية من حيث كل بت، مع الإشارة أيضًا إلى أنه يمكن تحسين أداء دقة 3 بت. لذلك، فإن البحث في الدقة المنخفضة البت أقل من 4 بت هو اتجاه جدير بالاهتمام.
- يكشف البحث في التكميم على مستوى البت أن أنواع البيانات وحجم الكتلة هما العاملان الرئيسيان المؤثران على فعالية التكميم على مستوى البت. بناءً على ما سبق، يمكننا أن نستنتج أن تكميم الدقة 4 بت هو حاليًا الحل الأكثر فعالية من حيث التكلفة. ومع ذلك، بين بيانات 4 بت، أي نوع بيانات يعطي نتائج تكميم أفضل؟ بالإشارة إلى [7]، تقترح طريقة LLM-FP4 تكميم FP4 لنماذج اللغة الكبيرة (LLMs) بطريقة ما بعد التدريب، وتكميم الأوزان والتنشيطات إلى قيم نقطة عائمة 4 بت. تعتمد حلول PTQ الحالية بشكل أساسي على الأعداد الصحيحة وتواجه صعوبات مع عرض بت أقل من 8 بت. مقارنة بتكميم الأعداد الصحيحة، فإن تكميم النقطة العائمة (FP) أكثر مرونة، ويتعامل بشكل أفضل مع التوزيعات طويلة الذيل أو على شكل جرس، وأصبح الخيار الافتراضي للعديد من منصات الأجهزة. مرجع المشروع: https://github.com/nbasyl/LLM-FP4 تتمثل إحدى خصائص تكميم FP في أن أداءه يعتمد إلى حد كبير على اختيار بتات الأس ونطاق الاقتطاع. تقوم LLM-FP4 ببناء خط أساس FP-PTQ قوي من خلال البحث عن معلمات التكميم المثلى. بالإضافة إلى ذلك، هناك تباينات أعلى بين القنوات وتباينات أقل داخل القنوات في توزيع التنشيط، مما يزيد من صعوبة تكميم التنشيط. لمعالجة هذه المشكلة، تقترح LLM-FP4 تكميم التنشيط لكل قناة وتوضح أنه يمكن إعادة تمثيل عوامل القياس الإضافية هذه في تحيزات الأس للأوزان، مما يؤدي إلى تكاليف ضئيلة. تقوم LLM-FP4 بتكميم الأوزان والتنشيطات في LLaMA-13B إلى 4 بتات فقط لأول مرة، محققة متوسط درجة 63.1 في مهام التفكير صفر-shot المنطقية، وهو أقل بمقدار 5.8 فقط من العينة الكاملة ويتفوق بشكل كبير على النموذج الأحدث السابق بنسبة 12.7 نقطة مئوية. يمكن العثور على البيانات المحددة في الشكل التالي:
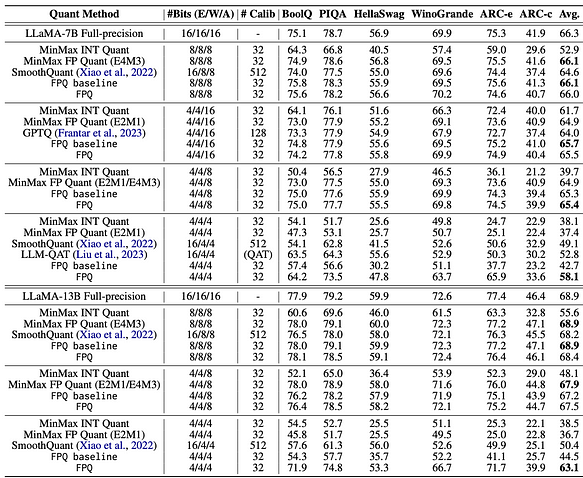
- عندما لا يتم تكميم التنشيطات ويتم تكميم تضمينات الكلمات والأوزان إلى 4 بتات، يكون لـ LLM-FP4 (نوع FP) ميزة طفيفة على خوارزميات مثل GPTQ (نوع INT).
- عندما يتم تكميم التنشيطات إلى 8 بت ويتم تكميم تضمينات الكلمات والأوزان إما إلى 4 أو 8 بتات، يكون أداء LLM-FP4 (نوع FP) مشابهًا للخوارزميات الأخرى (نوع INT)، دون اختلاف كبير في الأداء.
- عندما يتم تكميم التنشيطات إلى 4 بتات، يُظهر LLM-FP4 (نوع FP) تحسنًا ملحوظًا مقارنة بالخوارزميات الأخرى (نوع INT). في الختام، إذا لم يتم تكميم التنشيطات إلى 4 بتات، فلا توجد حاليًا ميزة كبيرة لـ FP4 على INT4.
بعض مشاريع التكميم الجديرة بالملاحظة تشمل
GPTQ-for-LLaMa
-
توفر النماذج المكممة باستخدام GPTQ مزايا سرعة كبيرة. ببساطة، يقوم GPTQ بتكميم كل معلمة داخل كتلة على حدة، وبعد تكميم كل معلمة، يتم إجراء تعديلات على المعلمات الأخرى داخل الكتلة للتعويض عن فقدان الدقة الناتج عن التكميم.
-
يتطلب تكميم GPTQ مجموعة بيانات معايرة لإجراء التكميم بعد التدريب على النموذج للحصول على أوزان مكممة. ينشأ مفهوم GPTQ من خوارزمية OBD التي اقترحها Yann LeCun في عام 1990، والتي تم تحسينها باستمرار بطرق مثل OBS و OBC (OBQ)، و GPTQ هي نسخة مسرعة من طريقة OBQ.
-
يوفر مستودع GPTQ-for-LLaMa حلاً لتكميم GPTQ مخصصًا لـ LLaMa. يوصى به لنشر نماذج LLaMa على وحدات GPU.
-
رابط المشروع: GPTQ-for-LLaMa ExLlama
-
يأتي ExLlama في إصدارين، ExLlama و ExLlamaV2، وهو بمثابة مكتبة استدلال لتشغيل LLM المحلي على وحدات GPU الاستهلاكية الحديثة.
-
يدعم ExLlamaV2 نماذج GPTQ رباعية البت المشابهة لـ V1 ولكنه يقدم أيضًا تنسيق “EXL2” الجديد. يعتمد EXL2 على نفس طرق التحسين مثل GPTQ، ويدعم التكميم 2 و 3 و 4 و 5 و 6 و 8 بت، مما يسمح بمزج مستويات التكميم داخل النموذج لتحقيق أي متوسط معدل بت بين 2 إلى 8 بت لكل وزن.
-
يمكن لـ ExLlamaV2 تطبيق مستويات تكميم متعددة على كل طبقة خطية، مما ينتج شيئًا مشابهًا للتكميم المتناثر، حيث يتم تكميم الأوزان الأكثر أهمية (الأعمدة) بعدد أكبر من البتات. تمكن تقنيات إعادة التعيين نفسها التي تسمح لـ ExLlama بالعمل بكفاءة مع النماذج المتسلسلة من تمكين هذا التنسيق المختلط مع عدم وجود تأثير تقريبًا على الأداء.
-
بشكل عام، يقدم ExLlama سرعة استدلال أسرع قليلاً مقارنة بأساليب التكميم الأخرى.
-
رابط المشروع: ExLlama GGML
-
GGML هي مكتبة C تركز على التعلم الآلي، أنشأها Georgi Gerganov، ومن هنا جاء الاختصار “GG”. لا توفر المكتبة العناصر الأساسية للتعلم الآلي مثل الموترات فحسب، بل توفر أيضًا تنسيقًا ثنائيًا فريدًا لتوزيع LLM.
-
GGML مكتوب بلغة C، ويدعم التكميم الصحيح (4 بت، 5 بت، 8 بت)، و float 16 بت.
-
يتعاون GGML بسلاسة مع مكتبة llama.cpp، مما يضمن للممارسين القدرة على تسخير قوة LLM بشكل فعال. الهدف الرئيسي لمكتبة llama.cpp هو السماح باستخدام نماذج LLaMA المكممة بـ INT4 على MacBook.
-
رابط المشروع: GGML Transformer Engine Transformer Engine (TE) هي مكتبة مصممة لتسريع نماذج المحولات على وحدات NVIDIA GPU، بما في ذلك استخدام دقة النقطة العائمة 8 بت (FP8) على وحدات Hopper GPU، مما يوفر أداءً أفضل مع استخدام ذاكرة أقل في كل من التدريب والاستدلال. تقدم TE مجموعة من اللبنات الأساسية عالية التحسين لهياكل المحولات الشائعة، إلى جانب واجهة برمجة تطبيقات لفئة الدقة المختلطة التلقائية التي تتكامل بسلاسة مع الكود الخاص بالإطار. بالإضافة إلى ذلك، تتضمن TE واجهة برمجة تطبيقات C ++ مستقلة عن الإطار لدعم FP8 في المحولات، والتي يمكن دمجها مع مكتبات التعلم العميق الأخرى. تشمل الميزات الرئيسية ما يلي:
-
وحدات سهلة الاستخدام لبناء طبقات المحولات التي تدعم FP8.
-
التحسين لنماذج المحولات، بما في ذلك دمج النواة.
-
دعم FP8 على NVIDIA Hopper و NVIDIA Ada GPUs.
-
التحسين لجميع الدقات (FP16، BF16) على بنية NVIDIA Ampere GPU والإصدارات الأحدث. رابط المشروع: Transformer Engine لاختبار الانتباه، يمكنك استيراد
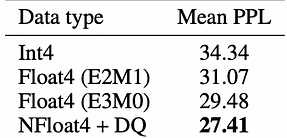
te.LayerNormLinearوقياس متوسط الوقت لحساب الانتباه. هيكل نموذج المرحلةنوع البياناتRTX 4090RTX 3090الانتباه الأساسيالانتباه الأساسي PyTorch الأصليFP1692 مللي ثانية183 مللي ثانيةالانتباه الأساسي + TEاستبدال Linear و LayerNorm txFP1696 مللي ثانيةغير مدعومالانتباه الأساسي + تحسين LayerNorm من TETe.LayerNormLinearFP1696 مللي ثانيةغير مدعومTE الكاملخوارزمية الانتباه الكامل من TEFP1674 مللي ثانيةغير مدعومTE الكامل + FP8استبدال الانتشار الأمامي FP8FP842 مللي ثانيةغير مدعوم خلاصة الاختبارات: في حالة Transformer Engine، هناك تحسن بنسبة 20٪ تقريبًا بالنسبة لخوارزمية الانتباه الأساسية عند استخدام fp16. بالإضافة إلى ذلك، هناك تحسن كبير بنسبة 54.5٪ عند استخدام fp8، مما يشير إلى أنه من الجدير استثمار الوقت في تحسين أداء الاستدلال. Bitsandbytes: Bitsandbytes هي غلاف خفيف الوزن لوظائف CUDA المخصصة، تم تحسينها خصيصًا للعمليات 8 بت، وضرب المصفوفات (LLM.int8())، ووظائف التكميم، وتدعم بشكل أساسي خوارزمية تكميم LLM.int8(). تدعم مكتبة bitsandbytes طرق تكميم مثل الكميات، والخطي، والتكميم الديناميكي. إنها واحدة من أبسط الطرق المتاحة ولا تتطلب بيانات معايرة التكميم أو عمليات معايرة. يمكن استخدامها بسهولة مع أي نموذج يحتوي على وحدات torch.nn.Linear. يشير التحليل الحالي إلى أن NF4 (نوع البيانات NormalFloat) و FP4 هما تقنيتا تكميم 4 بت متساويتان في الفعالية، وتظهران سمات متشابهة مثل سرعة الاستدلال واستهلاك الذاكرة وجودة المحتوى الذي يتم إنشاؤه. نوع البيانات NormalFloat هو شكل محسّن من تقنية التكميم، ويمثل التمثيل الأمثل للأوزان في توزيع طبيعي من حيث نظرية المعلومات. يستخدم بشكل أساسي بواسطة طريقة QLoRA لضبط النماذج بدقة 4 بت. فيما يلي بعض البيانات من QLoRA:
في الختام
يعد التكميم 4 بت حاليًا مخطط التكميم الأكثر فعالية من حيث التكلفة. ومع ذلك، يختلف التحسين بناءً على مستوى تكميم تضمينات الكلمات والأوزان والتنشيطات. في معظم السيناريوهات، باستثناء التنشيطات المكممة إلى 4 بتات، يوفر التكميم الصحيح (Int) فعالية أفضل من حيث التكلفة، بما في ذلك سيناريوهات عدم التكميم. وبالتالي، فإن التكميم منخفض البت، مع التركيز بشكل خاص على التنشيطات من خلال التكميم بعد التدريب (PTQ)، هو اتجاه واعد لتسريع التكميم. INT8 هو مخطط التكميم الأكثر استخدامًا حاليًا. مقارنة بـ INT8، لا يمكن لـ FP8 استبداله بالكامل في سيناريوهات التكميم ولكنه مناسب لتدريب النموذج، مما يوفر حلاً لمشكلات أداء الاستدلال دون الحاجة إلى التكميم. يعد دمج التقنيات المتعلقة بـ FP8 مع نوى الموتر للأجهزة لتعظيم سرعة الاستدلال اتجاهًا جديدًا يستحق الاستكشاف. تهيمن المشاريع القائمة على خوارزمية GPTQ على مشهد نماذج اللغة الكبيرة (LLM). ومع ذلك، فإن أنواع البيانات الجديدة (مثل FP4 و NF4)، والدقة المنخفضة للبت، والتكميم الديناميكي توفر فرصًا للابتكار والبحث. إلى جانب وحدات NVIDIA GPU، تقدم وحدات GPU و CPUs الجديدة (مثل AMD ووحدات GPU المحلية و Qualcomm) فرصًا جديدة. يعد تكييف خوارزميات التكميم مع منصات الأجهزة المختلفة بسرعة وزيادة أداء الأجهزة إلى أقصى حد اتجاهًا جديدًا للاستكشاف.
الأوراق المرجعية
[1]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale [2]Outliers Dimensions that Disrupt Transformers Are Driven by Frequency [3]Smoothquant: Accurate and efficient post-training quantization for large language models [4]FP8 versus INT8 for efficient deep learning inference [5]FP8-LM: Training FP8 Large Language Models [6]The case for 4-bit precision: k-bit Inference Scaling Laws [7]LLM-FP4: 4-Bit Floating-Point Quantized Transformers [8]GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers [9]Understanding the Impact of Post-Training Quantization on Large Language Models [10]QLoRA: Efficient Finetuning of Quantized LLMs
novita.ai يقدم واجهة برمجة تطبيقات Stable Diffusion ومئات من واجهات برمجة التطبيقات السريعة والأرخص لتوليد الصور بالذكاء الاصطناعي لعشرة آلاف نموذج. 🎯 أسرع توليد في 2 ثانية فقط، الدفع حسب الاستخدام، بحد أدنى 0.0015 دولار لكل صورة قياسية، يمكنك إضافة نماذجك الخاصة وتجنب صيانة GPU. مجاني لمشاركة الامتدادات مفتوحة المصدر.
قراءة موصى بها



