

Cet article explore principalement les directions réalisables pour accélérer l’inférence quantifiée, sur la base des dernières recherches sur le matériel GPU grand public et les algorithmes de quantification. Dans le contexte des schémas de quantification actuels, plongeons dans le sujet.
Brève introduction à la quantification
La quantification de modèle est une technique de compression de modèle visant à réduire la taille du modèle en ajustant la largeur de bits des poids et des activations. Cette réduction aide à diminuer les charges de calcul, les entrées/sorties mémoire GPU et l’occupation, réduisant finalement la latence et améliorant le débit. Le diagramme suivant illustre comment la quantification accélère l’apprentissage profond :
- Étape 1 : Le stockage des poids et des activations est chargé de la mémoire vers les unités de calcul MatMul. La largeur de bits des poids et des activations impacte significativement la latence de transfert de données.
- Étape 2 : Les unités de calcul MatMul effectuent la multiplication matricielle, où la largeur de bits et le format influencent également la latence.
- Étape 3 : Les accumulateurs ont généralement des largeurs de bits plus élevées pour une somme de haute précision. Après la somme, les valeurs dans les accumulateurs peuvent subir une requantification (la largeur de bits de sortie détermine le nombre de bits transmis et stockés en mémoire pour l’étape de traitement suivante).

Un aperçu schématique d’un accélérateur d’apprentissage profond
Selon les différents schémas de quantification, il existe deux approches principales : l’entraînement conscient de la quantification (QAT) et la quantification post-entraînement (PTQ).
- QAT (Quantization-Aware Training), également appelé quantification en ligne, nécessite un effort de calcul supplémentaire pendant l’entraînement. Il combine la quantification avec la rétropropagation pour ajuster les poids du modèle, garantissant que le modèle quantifié conserve sa précision.
- PTQ (Post-Training Quantification), également appelé quantification hors ligne, consiste à quantifier un modèle pré-entraîné en utilisant un minimum ou aucune donnée supplémentaire. Ce processus comprend un calibrage, qui peut impliquer la mise à l’échelle des poids du modèle. Il existe deux types de méthodes PTQ :
- La quantification dynamique post-entraînement (PDQ) ne repose pas sur des jeux de données de calibrage. Au lieu de cela, elle convertit directement chaque couche à l’aide de formules de quantification. QLoRA (Quantization-aware Low-Rank Adaptation) utilise cette méthode.
- La quantification par calibrage post-entraînement (PCQ) nécessite des jeux de données représentatifs pour ajuster les poids de quantification en fonction des entrées-sorties de chaque couche du modèle. GPTQ (Generative Pre-training Transformer for Quantization) adopte cette approche.
Support matériel
Série NVIDIA Les cartes de la série NV, grâce à l’écosystème CUDA, ont toujours maintenu une position de leader en matière de support pour différentes précisions et types de données.
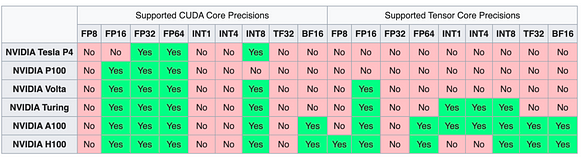
Série AMD Les cartes de la série MI300 d’AMD ont montré des performances supérieures à celles du H100 dans certains tests, ce qui en fait un choix prometteur. Elles offrent également un support pour les types FP8.

Outre les séries NVIDIA et AMD, les cartes produites localement offrent également un bon support pour des types de données tels que FP16 et INT8 (actuellement moins de support pour FP8 et autres formats). Nous ne les listons pas toutes ici.
Défis de la quantification des LLM
Commençons par une simple comparaison. Nous avons effectué une quantification INT de base sur les modèles ResNet18 et OPT-13B. Nous avons constaté que les performances de ResNet18 étaient à peine affectées, tandis que OPT-13B subissait des pertes significatives.
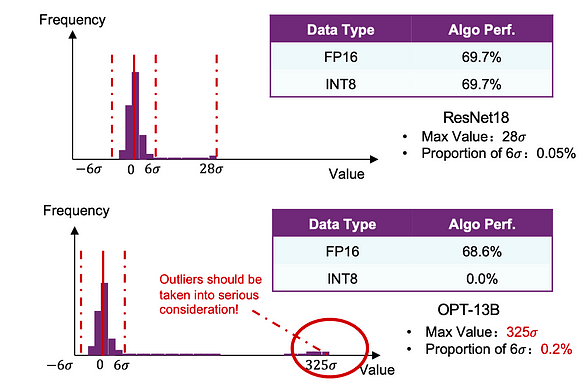
Pourquoi des réseaux neuronaux, tous deux suivant des distributions gaussiennes, présentent-ils de telles différences ? Cela est principalement dû aux valeurs aberrantes (outliers) dans les LLM.

Un seul bloc transformer, composé du module d’auto-attention et du module linéaire. La connexion en rouge est la connexion problématique dans les transformers avec des valeurs aberrantes. Comme indiqué par les marqueurs rouges dans la structure du transformer ci-dessus, le problème de quantification dans les transformers se produit dans une partie très spécifique du réseau. Dans certains modules entièrement connectés, en particulier dans les dernières couches du réseau, il existe des valeurs aberrantes significatives dans la somme des normalisations de couche. Supprimer simplement ces valeurs aberrantes réduirait considérablement la précision du réseau car elles remplissent un but spécifique. Ces valeurs aberrantes forcent le mécanisme d’attention de la couche suivante à se concentrer sur certains tokens insignifiants dans le texte, tels que les séparateurs de phrase, les points ou les virgules, ce qui empêche ces tokens spécifiques d’être mis à jour de manière significative. Selon l’article LLM.int8(), il est révélé qu’il y a des valeurs aberrantes dans les activations, dont les valeurs absolues sont significativement plus grandes. De plus, ces valeurs aberrantes sont distribuées dans un petit nombre de caractéristiques, appelées caractéristiques émergentes. On sait que les valeurs aberrantes ont un impact significatif sur les performances du modèle, et les jeter directement n’est pas une solution réalisable. La présence de valeurs aberrantes rend la plage de fp16 très large. Par conséquent, lorsqu’on les représente avec int8, chaque nombre doit représenter une large plage de fp16, ce qui entraîne des erreurs naturelles. Les CNN traditionnels ont également résolu ce problème en proposant des méthodes de calibrage. Plus précisément, les valeurs fp16 sont analysées statistiquement, puis des algorithmes tels que la divergence KL sont utilisés pour jeter les grandes valeurs, réduisant ainsi la plage que int8 doit représenter pour fp16, améliorant la précision. La quantité spécifique de valeurs à jeter est déterminée en itérant continuellement l’algorithme KL pour trouver la plage optimale. Heureusement, ces valeurs aberrantes sont très spécifiques. Elles n’apparaissent que dans certains blocs d’attention, et dans ces blocs, elles n’apparaissent que dans une seule couche, et dans ces couches, elles n’apparaissent que dans quelques canaux de sortie. Ces valeurs aberrantes se produisent même dans le même canal pour chaque point de données ([1,3]). Sur la base des conclusions ci-dessus, LLM.int8() [1] propose un algorithme de précision mixte.

Schéma de LLM.int8()
Selon le diagramme ci-dessus, X représente les activations de chaque couche, avec autant de lignes que la longueur de séquence et autant de colonnes que la taille cachée. Les barres jaunes dans le diagramme représentent les valeurs aberrantes, illustrant clairement leur schéma de distribution (la deuxième conclusion). La signification de la quantification vector-wise est que pour les colonnes qui ne sont pas aberrantes, elles sont quantifiées symétriquement en int8. Comme nous traitons avec des colonnes, dans la multiplication matricielle, les poids W correspondants doivent être extraits des lignes correspondantes pour les opérations int8. Pour les colonnes aberrantes jaunes, les lignes et les colonnes sont utilisées pour les opérations fp16. Enfin, les résultats des deux parties sont additionnés, équivalant à une multiplication matricielle directe. Grâce à la méthode de quantification mixte de LLM.int8(), la précision est presque la même que fp32, et les données des résultats expérimentaux ne sont pas collées ici.
FP8 et INT8
Pourquoi parler spécifiquement de FP8 et INT8 ? Cela est principalement dû aux dernières architectures GPU, telles que l’architecture hopper et les tensor cores, qui prennent en charge le calcul en précision FP8. Par conséquent, il vaut la peine d’explorer la quantification FP8.

Tensor Core (Hopper) (a) Allouer 1 bit à la plage ou à la précision (b) Support pour plusieurs types d’accumulateur et de sortie.
Int8 diffère de fp8 en ce qu’il manque un exposant intermédiaire et ne comprend qu’une mantisse. Cette structure de représentation des données, comme le montre le diagramme ci-dessous, est plus adaptée pour exprimer une distribution uniforme.

Selon [4], si la distribution présente des valeurs aberrantes très prononcées, alors le format FP8-E4/FP8-E5 serait plus précis. Cependant, si la distribution se comporte bien et ressemble davantage à une forme gaussienne, alors INT8 ou FP8-E2/FP8-E3 devraient mieux fonctionner.

Ici, nous traçons, pour plusieurs distributions, « bits de précision » : RMSE inversé et normalisé
Comme le montre la figure ci-dessus, pour une distribution uniforme, INT8 est le meilleur. Pour une distribution normale, FP8-E2 est optimal, suivi de près par INT8. De nombreuses distributions dans les réseaux neuronaux sont gaussiennes, ce qui indique que le résultat de la distribution est une mesure de performance très pertinente. Ce n’est que lorsque des valeurs aberrantes se produisent qu’un format avec plus de bits d’exposant commence à fournir de meilleurs résultats. Le quantificateur optimal est basé sur le quantificateur Lloyd-Max et peut être obtenu pour ces distributions. Pour des réseaux comme ResNet18, MobileNetV2, etc., où les couches sont principalement de forme gaussienne, les performances sont meilleures avec des formats comme FP8-E2 et INT, tandis que les formats FP8-E4 et FP8-E5 fonctionnent nettement moins bien. Nous constatons également que les modèles transformer comme ViT et BERT fonctionnent mieux sur FP8-E4, précisément parce que certaines couches du transformer ont de très grandes valeurs aberrantes. Plus précisément, certaines couches ont de nombreuses valeurs aberrantes dans les activations avant la normalisation de couche. Parce que ces valeurs aberrantes affectent significativement les performances, conduisant à des erreurs nulles lors de l’écrêtage, le format FP8-E4 fonctionne le mieux, tandis que les formats FP8-E2/INT8 fonctionnent nettement moins bien.
Alors, FP8 a-t-il un avantage absolu sur INT8 dans le domaine des LLM ? La conclusion pourrait être tout le contraire, principalement pour les raisons suivantes :
- Selon les principes de l’accumulation en virgule fixe et flottante dans la conception de circuits, les unités MAC FP8 sont 50 % à 180 % moins efficaces que les unités INT8. Si la charge de travail est liée au calcul, cela ralentit la vitesse de traitement des puces dédiées.
- Pour la plupart des réseaux, FP8 fonctionne moins bien que INT8, même pour des structures comme les transformers avec un grand nombre de valeurs aberrantes, qui peuvent être traitées par des méthodes de précision mixte ou d’entraînement conscient de la quantification.
Globalement, dans le contexte de la quantification pure, les formats à virgule flottante comme FP8-E4 et FP8-E5 ne peuvent pas remplacer INT8 en termes de performances et de précision dans l’inférence d’apprentissage profond. Alors, où se situe l’avantage et le positionnement du format FP8 ? Tout d’abord, résumons les avantages du format FP8 :
- Les Tensor Cores FP8 sont plus rapides que les Tensor Cores 16 bits.
- Réduit les mouvements de mémoire.
- Si le modèle a déjà été entraîné en FP8, le déploiement est plus pratique.
- FP8 a une plage dynamique plus large.
- Le circuit de conversion de FP8 vers FP16/FP32/BF16 peut être conçu plus simplement et directement, sans la surcharge de multiplication et d’addition nécessaire pour la conversion de INT8/UINT8 vers FP.
En se basant sur ces avantages, il est évident que FP8 est en fait plus adapté à l’entraînement. Se référant à [5], sans modifier aucun hyperparamètre tel que le taux d’apprentissage et la décroissance du poids, à la fois dans les tâches de pré-entraînement et les tâches en aval, les modèles entraînés en FP8 se comportent de manière similaire aux modèles entraînés avec l’entraînement haute précision BF16. Il est à noter que lors de l’entraînement du modèle GPT-175B, par rapport à la méthode TE, le nouveau cadre de précision mixte FP8 sur la plateforme GPU H100 peut réduire le temps d’entraînement de 17 % et l’utilisation de la mémoire de 21 %.
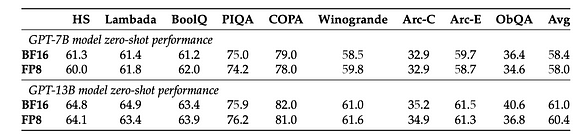
Performance zero-shot sur des tâches en aval. Les modèles sont entraînés soit avec le schéma standard de précision mixte BF16, soit avec le schéma proposé de faible précision FP8.
Quantifier les modèles en utilisant le format FP8 pour l’inférence peut éviter le besoin de processus QAT ou PTQ (pour éviter la réduction de précision), tout en bénéficiant d’une efficacité de conversion plus élevée de FP8 à FP16 et autres formats, améliorant ainsi significativement les performances d’inférence.
Meilleur rapport qualité-prix de la quantification
Semblable au projet exllamav2, qui prend en charge la quantification en 2, 3, 4, 5, 6 et 8 bits basée sur l’algorithme GPTQ, mais pour les LLM, quelle longueur et quel format offrent le meilleur rapport qualité-prix en matière de quantification ? Se référant à [6], des expériences approfondies ont été menées sur diverses architectures LLM pour déterminer l’impact de différentes allocations de bits sur les performances du modèle :

Lois d’échelle au niveau des bits pour la performance moyenne zero-shot sur quatre jeux de données pour les modèles OPT de 125M à 176B paramètres. La performance zero-shot augmente régulièrement pour des bits de modèle fixes à mesure que nous réduisons la précision de quantification de 16 à 4 bits. À 3 bits, cette relation s’inverse, rendant la précision 4 bits optimale.
- Pour une performance zero-shot donnée, la précision 4 bits offre la meilleure échelle pour presque toutes les séries de modèles et tailles (la précision 4 bits n’entraîne pas de baisse significative des performances du modèle). La seule exception est BLOOM-176B, où 3 bits fonctionnent légèrement mieux, mais pas de manière significative.
- La précision 4 bits est actuellement la précision la plus efficace en termes de par bit, tout en indiquant que les performances de la précision 3 bits pourraient être améliorées. Par conséquent, la recherche sur la faible précision en dessous de 4 bits est une direction prometteuse.
- La recherche sur la quantification au niveau des bits révèle que les types de données et la taille de bloc sont des facteurs clés affectant l’efficacité de la quantification au niveau des bits.
Sur la base de ce qui précède, nous pouvons conclure que la quantification en précision 4 bits est actuellement la solution la plus rentable. Cependant, parmi les données 4 bits, quel type de données donne de meilleurs résultats de quantification ? Se référant à [7], la méthode LLM-FP4 propose une quantification FP4 pour les grands modèles de langage (LLM) de manière post-entraînement, quantifiant les poids et les activations en valeurs flottantes 4 bits. Les solutions PTQ existantes sont principalement basées sur des entiers et peinent avec des largeurs de bits inférieures à 8 bits. Par rapport à la quantification entière, la quantification à virgule flottante (FP) est plus flexible, gère mieux les distributions à longue traîne ou en forme de cloche, et est devenue le choix par défaut pour de nombreuses plateformes matérielles.
Référence du projet : https://github.com/nbasyl/LLM-FP4
L’une des caractéristiques de la quantification FP est que ses performances dépendent largement du choix des bits d’exposant et de la plage d’écrêtage. LLM-FP4 construit une base de référence FP-PTQ robuste en recherchant les paramètres de quantification optimaux. De plus, il existe des variances inter-canaux plus élevées et des variances intra-canaux plus faibles dans la distribution des activations, ce qui augmente la difficulté de la quantification des activations. Pour résoudre ce problème, LLM-FP4 propose une quantification des activations par canal et démontre que ces facteurs d’échelle supplémentaires peuvent être reparamétrés en biais d’exposant des poids, entraînant des coûts négligeables. LLM-FP4 quantifie les poids et les activations dans LLaMA-13B en seulement 4 bits pour la première fois, atteignant un score moyen de 63,1 sur les tâches de raisonnement zéro-shot de bon sens, ce qui n’est que 5,8 de moins que l’échantillon complet et surpasse significativement le modèle de pointe précédent de 12,7 points de pourcentage. Les données spécifiques peuvent être trouvées dans la figure suivante :
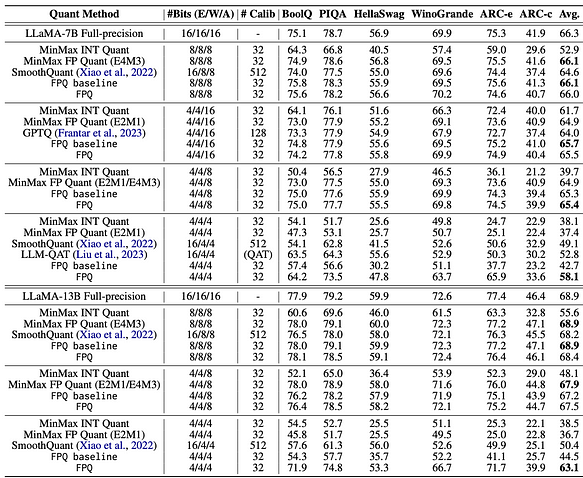
Performance zero-shot sur des tâches de raisonnement de bon sens avec les modèles LLaMA. Nous notons E/W/A comme la largeur de bits des embeddings de mots, des poids du modèle et des activations, respectivement.
D’après la figure ci-dessus, on peut tirer les principales conclusions suivantes :
- Lorsque les activations ne sont pas quantifiées et que les embeddings de mots ainsi que les poids sont quantifiés à 4 bits, LLM-FP4 (type FP) a un léger avantage sur des algorithmes comme GPTQ (type INT).
- Lorsque les activations sont quantifiées à 8 bits et que les embeddings de mots ainsi que les poids sont quantifiés à 4 ou 8 bits, LLM-FP4 (type FP) se comporte de manière similaire aux autres algorithmes (type INT), sans différence significative de performance.
- Lorsque les activations sont quantifiées à 4 bits, LLM-FP4 (type FP) montre une amélioration notable par rapport aux autres algorithmes (type INT).
En conclusion, si les activations ne sont pas quantifiées à 4 bits, il n’y a actuellement aucun avantage significatif de FP4 par rapport à INT4.
Quelques projets de quantification notables
GPTQ-for-LLaMa
- Les modèles quantifiés avec GPTQ offrent des avantages de vitesse significatifs. En termes simples, GPTQ quantifie chaque paramètre dans un bloc individuellement, et après chaque quantification de paramètre, des ajustements sont apportés aux autres paramètres du bloc pour compenser la perte de précision causée par la quantification.
- La quantification GPTQ nécessite un jeu de données de calibrage pour effectuer une quantification post-entraînement sur le modèle afin d’obtenir des poids quantifiés. Le concept de GPTQ provient de l’algorithme OBD de Yann LeCun proposé en 1990, qui a été continuellement amélioré avec des méthodes comme OBS, OBC (OBQ), et GPTQ est une version accélérée de la méthode OBQ.
- Le dépôt GPTQ-for-LLaMa fournit une solution de quantification GPTQ spécifiquement pour LLaMa. Il est recommandé pour déployer des modèles LLaMa sur GPU.
- Lien du projet : GPTQ-for-LLaMa
ExLlama
- ExLlama existe en deux versions, ExLlama et ExLlamaV2, servant de bibliothèque d’inférence pour exécuter des LLM locaux sur des GPU grand public modernes.
- ExLlamaV2 prend en charge les modèles GPTQ 4 bits similaires à V1 mais introduit également le nouveau format « EXL2 ». EXL2, basé sur les mêmes méthodes d’optimisation que GPTQ, prend en charge la quantification en 2, 3, 4, 5, 6 et 8 bits, permettant de mélanger les niveaux de quantification au sein du modèle pour atteindre n’importe quel débit binaire moyen entre 2 et 8 bits par poids.
- ExLlamaV2 peut appliquer plusieurs niveaux de quantification à chaque couche linéaire, produisant quelque chose qui ressemble à une quantification clairsemée, où les poids (colonnes) les plus importants sont quantifiés avec plus de bits. Les mêmes techniques de remappage qui permettent à ExLlama de fonctionner efficacement avec des modèles séquentiels permettent ce format mixte avec presque aucun impact sur les performances.
- En général, ExLlama offre une vitesse d’inférence légèrement plus rapide par rapport aux autres approches de quantification.
- Lien du projet : ExLlama
GGML
- GGML est une bibliothèque C axée sur l’apprentissage automatique, créée par Georgi Gerganov, d’où l’abréviation « GG ». La bibliothèque fournit non seulement des éléments fondamentaux de l’apprentissage automatique tels que les tenseurs, mais aussi un format binaire unique pour distribuer les LLM.
- GGML, écrit en C, prend en charge la quantification entière (4 bits, 5 bits, 8 bits) et le flottant 16 bits.
- GGML coopère de manière transparente avec la bibliothèque llama.cpp, garantissant que les praticiens peuvent exploiter efficacement la puissance des LLM. L’objectif principal de la bibliothèque llama.cpp est de permettre l’utilisation de modèles LLaMA quantifiés en INT4 sur MacBook.
- Lien du projet : GGML
Transformer Engine
Transformer Engine (TE) est une bibliothèque conçue pour accélérer les modèles Transformer sur les GPU NVIDIA, y compris l’utilisation de la précision à virgule flottante 8 bits (FP8) sur les GPU Hopper, offrant ainsi de meilleures performances avec une utilisation mémoire plus faible à la fois en entraînement et en inférence. TE fournit un ensemble de blocs de construction hautement optimisés pour les architectures Transformer populaires, ainsi qu’une API de classe de précision mixte automatique qui s’intègre de manière transparente au code spécifique au framework. De plus, TE inclut une API C++ indépendante du framework pour le support FP8 dans les Transformers, qui peut être intégrée à d’autres bibliothèques d’apprentissage profond. Les fonctionnalités clés incluent :
- Des modules faciles à utiliser pour construire des couches Transformer prenant en charge FP8.
- Optimisation pour les modèles Transformer, y compris la fusion de noyaux.
- Support pour FP8 sur les GPU NVIDIA Hopper et NVIDIA Ada.
- Optimisation pour toutes les précisions (FP16, BF16) sur l’architecture GPU NVIDIA Ampere et versions supérieures.
Lien du projet : Transformer Engine
Pour les tests d’attention, vous pouvez importer te.LayerNormLinear et mesurer le temps moyen pour le calcul de l’attention.
| Stage | Model Structure | Data Format | RTX 4090 | RTX 3090 |
|---|---|---|---|---|
| Basic Attention | PyTorch Native Attention | FP16 | 92ms | 183ms |
| Basic Attention + TE | Linear and LayerNorm tx replacement | FP16 | 96ms | Not supported |
| Basic Attention + TE’s LayerNorm Optimization | TE.LayerNormLinear | FP16 | 96ms | Not supported |
| TE Full | TE Full Attention Algorithm | FP16 | 74ms | Not supported |
| TE Full + FP8 | FP Forward Propagation Replacement | FP8 | 42ms | Not supported |
Conclusion des tests : Dans le cas de Transformer Engine, il y a environ 20 % d’amélioration par rapport à l’algorithme d’attention de base lors de l’utilisation de fp16. De plus, il y a une amélioration significative de 54,5 % lors de l’utilisation de fp8, indiquant qu’il vaut la peine d’investir du temps pour améliorer les performances d’inférence.
Bitsandbytes
Bitsandbytes est une surcouche légère pour des fonctions CUDA personnalisées, spécialement optimisée pour les opérations 8 bits, la multiplication matricielle (LLM.int8()) et les fonctions de quantification, prenant principalement en charge l’algorithme de quantification LLM.int8(). La bibliothèque bitsandbytes prend en charge des méthodes de quantification telles que les quantiles, linéaire et dynamique. C’est l’une des méthodes les plus simples disponibles et ne nécessite pas de données de calibrage de quantification ni de processus de calibrage. Elle peut être utilisée immédiatement avec tout modèle contenant des modules torch.nn.Linear. L’analyse actuelle suggère que NF4 (type de données NormalFloat) et FP4 sont des techniques de quantification 4 bits également efficaces, présentant des attributs similaires tels que la vitesse d’inférence, la consommation mémoire et la qualité du contenu généré. Le type de données NormalFloat est une forme améliorée de technique de quantification, représentant la représentation optimale des poids dans une distribution normale en termes de théorie de l’information. Il est principalement utilisé par la méthode QLoRA pour affiner les modèles avec une précision 4 bits. Voici quelques données de QLoRA :
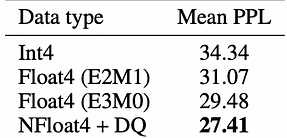
Perplexité moyenne sur Pile Common Crawl pour différents types de données pour les modèles OPT, BLOOM, LLaMA et Pythia de 125M à 13B.
AIMET
AIMET est une bibliothèque fournie par Qualcomm pour les techniques avancées de quantification et de compression de modèles pour les réseaux neuronaux. Elle vise à améliorer la vitesse d’inférence tout en réduisant les besoins en calcul et en mémoire, avec un impact minimal sur la précision. Par exemple, les modèles fonctionnant sur le Qualcomm Hexagon DSP peuvent atteindre des vitesses 5 à 15 fois plus rapides que sur le Qualcomm Kyro CPU. AIMET sert de reflet de l’implémentation de la quantification sur du matériel non NVIDIA. Généralement, il représente les capacités de quantification de base fournies par les fabricants de matériel, et actuellement, il n’existe pas de projet unique offrant des capacités de quantification universelles pour différentes plates-formes matérielles.
En conclusion
La quantification 4 bits est actuellement le schéma de quantification le plus rentable. Cependant, l’optimisation varie en fonction du niveau de quantification des embeddings de mots, des poids et des activations. Dans la plupart des scénarios, à l’exception des activations quantifiées à 4 bits, la quantification entière (Int) offre un meilleur rapport qualité-prix, y compris dans les scénarios sans quantification. Ainsi, la quantification à faible nombre de bits, en particulier en se concentrant sur les activations via la quantification post-entraînement (PTQ), est une direction prometteuse pour accélérer la quantification. INT8 est le schéma de quantification le plus couramment utilisé actuellement. Par rapport à INT8, FP8 ne peut pas le remplacer complètement dans les scénarios de quantification mais est adapté à l’entraînement de modèles, offrant une solution aux problèmes de performances d’inférence sans nécessiter de quantification. Intégrer les techniques liées à FP8 avec les cœurs tensoriels matériels pour maximiser la vitesse d’inférence est une nouvelle direction à explorer. Les projets basés sur l’algorithme GPTQ dominent le paysage des grands modèles de langage (LLM). Cependant, les nouveaux types de données (tels que FP4 et NF4), la précision binaire plus faible et la quantification dynamique offrent des opportunités d’innovation et de recherche. Outre les GPU NVIDIA, les nouveaux GPU et CPU (tels que AMD, les GPU domestiques et Qualcomm) présentent de nouvelles opportunités. Adapter rapidement les algorithmes de quantification à différentes plates-formes matérielles et maximiser les performances matérielles est une nouvelle direction à explorer.
Références
[1] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
[2] Outliers Dimensions that Disrupt Transformers Are Driven by Frequency
[3] Smoothquant: Accurate and efficient post-training quantization for large language models
[4] FP8 versus INT8 for efficient deep learning inference
[5] FP8-LM: Training FP8 Large Language Models
[6] The case for 4-bit precision: k-bit Inference Scaling Laws
[7] LLM-FP4: 4-Bit Floating-Point Quantized Transformers
[8] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
[9] Understanding the Impact of Post-Training Quantization on Large Language Models
[10] QLoRA: Efficient Finetuning of Quantized LLMs
novita.ai fournit une API Stable Diffusion et des centaines d’API de génération d’images IA rapides et les moins chères pour 10 000 modèles. 🎯 Génération la plus rapide en seulement 2s, paiement à l’utilisation, à partir de 0,0015 $ par image standard, vous pouvez ajouter vos propres modèles et éviter la maintenance GPU. Partage libre de ressources open source.
Lecture recommandée


