

Este artículo explora principalmente direcciones viables para acelerar la inferencia cuantizada, basándose en los trabajos de investigación más recientes sobre hardware GPU convencional y algoritmos de cuantización. En el contexto de los esquemas de cuantización actuales, profundicemos en el tema. Breve introducción a la cuantización La cuantización de modelos es una técnica de compresión de modelos que tiene como objetivo reducir el tamaño del modelo ajustando el ancho de bits de los pesos y las activaciones. Esta reducción ayuda a disminuir las cargas computacionales, la E/S de memoria GPU y la ocupación, reduciendo en última instancia la latencia y mejorando el rendimiento. El siguiente diagrama ilustra cómo la cuantización acelera el aprendizaje profundo:
- Paso 1: El almacenamiento de pesos y activaciones se carga desde la memoria a las unidades de cálculo MatMul. El ancho de bits de los pesos y las activaciones impacta significativamente en la latencia de transferencia de datos.
- Paso 2: Las unidades de cálculo MatMul realizan la multiplicación de matrices, donde el ancho de bits y el formato también influyen en la latencia.
- Paso 3: Los acumuladores suelen tener anchos de bits más altos para una suma de alta precisión. Después de la suma, los valores en los acumuladores pueden someterse a una recuantización (el ancho de bits de salida determina la cantidad de bits transmitidos y almacenados en memoria para el siguiente paso de procesamiento).

Una vista esquemática de un acelerador de aprendizaje profundo Según los diferentes esquemas de cuantización, existen dos enfoques principales: Entrenamiento Consciente de Cuantización (QAT) y Cuantización Posterior al Entrenamiento (PTQ).
- QAT (Quantization-Aware Training), también conocido como Cuantización en Línea, requiere un esfuerzo computacional adicional durante el entrenamiento. Combina la cuantización con la retropropagación para ajustar los pesos del modelo, asegurando que el modelo cuantizado mantenga la precisión.
- PTQ (Post-Training Quantization), también conocido como Cuantización Fuera de Línea, implica cuantizar un modelo preentrenado utilizando datos mínimos o ninguno. Este proceso incluye calibración, que puede implicar escalar los pesos del modelo. Existen dos tipos de métodos PTQ:
- Cuantización Dinámica Posterior (PDQ) no depende de conjuntos de datos de calibración. En su lugar, convierte directamente cada capa utilizando fórmulas de cuantización. QLoRA (Quantization-aware Low-Rank Adaptation) emplea este método.
- Cuantización Posterior con Calibración (PCQ) requiere conjuntos de datos representativos para ajustar los pesos de cuantización según la entrada y salida de cada capa del modelo. GPTQ (Generative Pre-training Transformer for Quantization) adopta este enfoque.
Soporte de Hardware
Serie NVIDIA Las tarjetas de la serie NV, debido al ecosistema CUDA, han mantenido consistentemente una posición de liderazgo en el soporte de diferentes precisiones y tipos de datos.
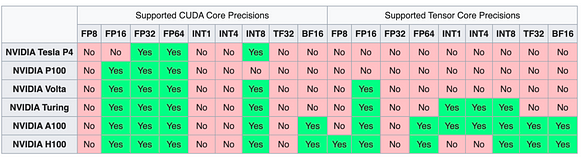

Desafíos en la Cuantización de LLM
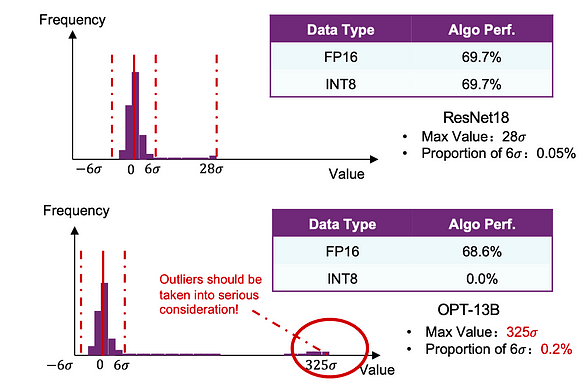
Comencemos con una comparación simple. Realizamos una cuantización INT básica tanto en los modelos ResNet18 como OPT-13B. Descubrimos que el rendimiento de ResNet18 apenas se vio afectado, mientras que OPT-13B experimentó pérdidas significativas.


Esquema de LLM.int8() Según el diagrama anterior, X representa las activaciones de cada capa, con tantas filas como longitud de secuencia y tantas columnas como tamaño oculto. Las barras amarillas en el diagrama representan los valores atípicos, ilustrando vívidamente su patrón de distribución (la segunda conclusión). El significado de la cuantización por vectores es que para las columnas que no son valores atípicos, se cuantizan simétricamente usando int8. Dado que estamos tratando con columnas, en la multiplicación de matrices, los pesos W correspondientes deben extraerse de las filas correspondientes para las operaciones int8. Para las columnas atípicas amarillas, tanto las filas como las columnas se utilizan para operaciones fp16. Finalmente, los resultados de las dos partes se suman, lo que equivale a la multiplicación de matrices directa. Mediante el método de cuantización mixta de LLM.int8(), la precisión es casi la misma que fp32, y los datos de los resultados experimentales no se pegan aquí.
FP8 e INT8
¿Por qué mencionar específicamente FP8 e INT8? Esto se debe principalmente a las arquitecturas de GPU más recientes, como la arquitectura hopper y los núcleos tensor, que admiten el cálculo de precisión FP8. Por lo tanto, vale la pena explorar la cuantización FP8.



- Según los principios de acumulación de punto fijo y punto flotante en el diseño de circuitos, las unidades MAC FP8 son entre un 50% y un 180% menos eficientes que las unidades INT8. Si la carga de trabajo está limitada por el cómputo, esto ralentiza la velocidad de procesamiento de los chips dedicados.
- Para la mayoría de las redes, FP8 tiene un rendimiento peor que INT8, incluso para estructuras como los transformadores con una gran cantidad de valores atípicos, que se pueden abordar mediante métodos de precisión mixta o entrenamiento consciente de cuantización. En general, en el contexto de la cuantización pura, los formatos de punto flotante como FP8-E4 y FP8-E5 no pueden reemplazar a INT8 en términos de rendimiento y precisión en la inferencia de aprendizaje profundo. Entonces, ¿dónde radica la ventaja y el posicionamiento del formato FP8? Primero, resumamos las ventajas del formato FP8:
- Los Tensor Cores FP8 son más rápidos que los Tensor Cores de 16 bits.
- Reduce el movimiento de memoria.
- Si el modelo ya ha sido entrenado en FP8, la implementación es más conveniente.
- FP8 tiene un rango dinámico más amplio.
- El circuito de conversión de FP8 a FP16/FP32/BF16 se puede diseñar de manera más simple y directa, sin la sobrecarga de multiplicación y suma requerida para la conversión de INT8/UINT8 a FP. Basándonos en estas ventajas, es evidente que FP8 es en realidad más adecuado para el entrenamiento. Refiriéndose a [5], sin modificar ningún hiperparámetro como la tasa de aprendizaje y la reducción de peso, tanto en tareas de preentrenamiento como en tareas posteriores, los modelos entrenados usando FP8 tienen un rendimiento similar a los modelos entrenados usando entrenamiento de alta precisión BF16. Vale la pena señalar que durante el entrenamiento del modelo GPT-175B, en comparación con el método TE, el nuevo marco de precisión mixta FP8 propuesto en la plataforma GPU H100 puede reducir el tiempo de entrenamiento en un 17% y el uso de memoria en un 21%.
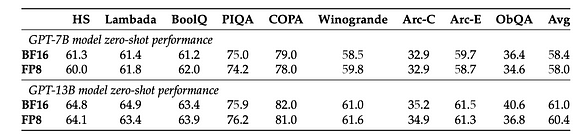

- Para un rendimiento de zero-shot dado, la precisión de 4 bits proporciona el mejor escalado para casi todas las series y tamaños de modelo (la precisión de 4 bits no resulta en caídas significativas de rendimiento para el rendimiento del modelo). La única excepción es BLOOM-176B, donde 3 bits funcionan ligeramente mejor, pero no de manera significativa.
- La precisión de 4 bits es actualmente la precisión más efectiva en términos de costo por bit, al mismo tiempo que indica que el rendimiento de la precisión de 3 bits podría mejorarse. Por lo tanto, la investigación sobre precisión de bits baja por debajo de 4 bits es una dirección que vale la pena.
- La investigación sobre cuantización a nivel de bits revela que los tipos de datos y el tamaño del bloque son factores clave que afectan la efectividad de la cuantización a nivel de bits. Basado en lo anterior, podemos concluir que la cuantización de precisión de 4 bits es actualmente la solución más rentable. Sin embargo, entre los datos de 4 bits, ¿qué tipo de datos produce mejores resultados de cuantización? Refiriéndose a [7], el método LLM-FP4 propone la cuantización FP4 para modelos de lenguaje grande (LLM) de manera posterior al entrenamiento, cuantizando pesos y activaciones en valores de punto flotante de 4 bits. Las soluciones PTQ existentes se basan principalmente en enteros y tienen dificultades con anchos de bits inferiores a 8 bits. En comparación con la cuantización de enteros, la cuantización de punto flotante (FP) es más flexible, maneja mejor distribuciones de cola larga o en forma de campana, y se ha convertido en la opción predeterminada para muchas plataformas de hardware. Referencia del proyecto: https://github.com/nbasyl/LLM-FP4 Una de las características de la cuantización FP es que su rendimiento depende en gran medida de la selección de los bits de exponente y el rango de recorte. LLM-FP4 construye una línea base FP-PTQ robusta buscando los parámetros de cuantización óptimos. Además, hay varianzas entre canales más altas y varianzas dentro de canales más bajas en la distribución de activaciones, lo que aumenta la dificultad de la cuantización de activaciones. Para abordar este problema, LLM-FP4 propone la cuantización de activaciones por canal y demuestra que estos factores de escala adicionales se pueden reparametrizar en los sesgos de exponente de los pesos, con costos insignificantes. LLM-FP4 cuantifica pesos y activaciones en LLaMA-13B a solo 4 bits por primera vez, logrando una puntuación promedio de 63.1 en tareas de razonamiento de zero-shot de sentido común, que es solo 5.8 menos que la muestra completa y supera significativamente al modelo anterior de última generación en 12.7 puntos porcentuales. Los datos específicos se pueden encontrar en la siguiente figura:
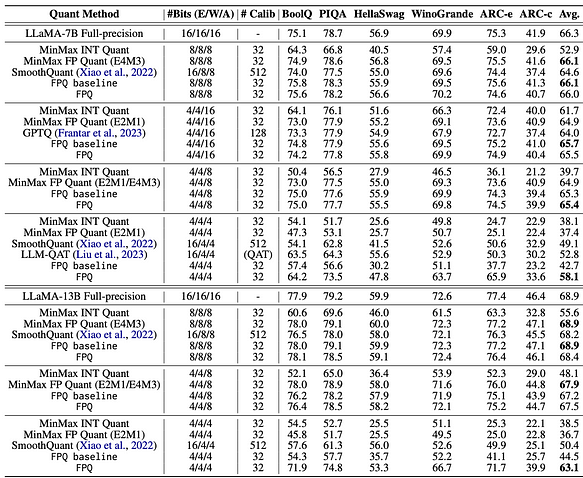
- Cuando las activaciones no se cuantizan y las incrustaciones de palabras junto con los pesos se cuantizan a 4 bits, LLM-FP4 (tipo FP) tiene una ligera ventaja sobre algoritmos como GPTQ (tipo INT).
- Cuando las activaciones se cuantizan a 8 bits y las incrustaciones de palabras junto con los pesos se cuantizan a 4 u 8 bits, LLM-FP4 (tipo FP) tiene un rendimiento similar a otros algoritmos (tipo INT), sin diferencias significativas en el rendimiento.
- Cuando las activaciones se cuantizan a 4 bits, LLM-FP4 (tipo FP) muestra una mejora notable en comparación con otros algoritmos (tipo INT). En conclusión, si las activaciones no se cuantizan a 4 bits, actualmente no hay una ventaja significativa de FP4 sobre INT4.
Algunos proyectos de cuantización destacados incluyen
GPTQ-for-LLaMa
-
Los modelos cuantizados usando GPTQ ofrecen ventajas significativas de velocidad. En términos simples, GPTQ cuantiza cada parámetro dentro de un bloque individualmente, y después de la cuantización de cada parámetro, se realizan ajustes en los otros parámetros dentro del bloque para compensar la pérdida de precisión causada por la cuantización.
-
La cuantización GPTQ requiere un conjunto de datos de calibración para realizar la cuantización posterior al entrenamiento en el modelo y obtener pesos cuantizados. El concepto de GPTQ se origina en el algoritmo OBD de Yann LeCun propuesto en 1990, que se ha mejorado continuamente con métodos como OBS, OBC (OBQ), y GPTQ es una versión acelerada del método OBQ.
-
El repositorio GPTQ-for-LLaMa proporciona una solución de cuantización GPTQ específica para LLaMa. Se recomienda para implementar modelos LLaMa en GPU.
-
Enlace del proyecto: GPTQ-for-LLaMa ExLlama
-
ExLlama viene en dos versiones, ExLlama y ExLlamaV2, y sirve como una biblioteca de inferencia para ejecutar LLM local en GPU de consumo modernas.
-
ExLlamaV2 admite modelos GPTQ de 4 bits de manera similar a V1, pero también introduce el nuevo formato “EXL2”. EXL2, basado en los mismos métodos de optimización que GPTQ, admite cuantización de 2, 3, 4, 5, 6 y 8 bits, lo que permite mezclar niveles de cuantización dentro del modelo para lograr cualquier tasa de bits promedio entre 2 y 8 bits por peso.
-
ExLlamaV2 puede aplicar múltiples niveles de cuantización a cada capa lineal, produciendo algo similar a una cuantización dispersa, donde los pesos más importantes (columnas) se cuantizan con más bits. Las mismas técnicas de reasignación que permiten que ExLlama funcione de manera eficiente con modelos secuenciales permiten este formato mixto con un impacto casi nulo en el rendimiento.
-
En general, ExLlama ofrece una velocidad de inferencia ligeramente más rápida en comparación con otros enfoques de cuantización.
-
Enlace del proyecto: ExLlama GGML
-
GGML es una biblioteca C enfocada en el aprendizaje automático, creada por Georgi Gerganov, de ahí la abreviatura “GG”. La biblioteca no solo proporciona elementos fundamentales del aprendizaje automático, como tensores, sino que también ofrece un formato binario único para distribuir LLM.
-
GGML, escrito en C, admite cuantización de enteros (4 bits, 5 bits, 8 bits) y flotante de 16 bits.
-
GGML coopera perfectamente con la biblioteca llama.cpp, lo que garantiza que los profesionales puedan aprovechar eficazmente el poder de LLM. El objetivo principal de la biblioteca llama.cpp es permitir el uso de modelos LLaMA cuantizados con INT4 en MacBook.
-
Enlace del proyecto: GGML Transformer Engine Transformer Engine (TE) es una biblioteca diseñada para acelerar modelos Transformer en GPU NVIDIA, incluido el uso de precisión de punto flotante de 8 bits (FP8) en GPU Hopper, proporcionando así un mejor rendimiento con una menor utilización de memoria tanto en entrenamiento como en inferencia. TE ofrece un conjunto de bloques de construcción altamente optimizados para arquitecturas Transformer populares, junto con una API de clase de precisión mixta automática que se integra perfectamente con el código específico del framework. Además, TE incluye una API C++ independiente del framework para soporte FP8 en Transformers, que se puede integrar con otras bibliotecas de aprendizaje profundo. Las características clave incluyen:
-
Módulos fáciles de usar para construir capas Transformer que admiten FP8.
-
Optimización para modelos Transformer, incluida la fusión de kernels.
-
Soporte para FP8 en NVIDIA Hopper y NVIDIA Ada GPU.
-
Optimización para todas las precisiones (FP16, BF16) en la arquitectura NVIDIA Ampere GPU y versiones superiores. Enlace del proyecto: Transformer Engine Para las pruebas de atención, puede importar
te.LayerNormLineary medir el tiempo promedio para el cálculo de la atención. EtapaEstructura del ModeloFormato de DatosRTX 4090RTX 3090Atención BásicaAtención Nativa de PyTorchFP1692ms183msAtención Básica + TEReemplazo de tx de Linear y LayerNormFP1696msNo compatibleAtención Básica + Optimización LayerNorm de TETE.LayerNormLinearFP1696msNo compatibleTE CompletoAlgoritmo de Atención Completo TEFP1674msNo compatibleTE Completo + FP8Reemplazo de Propagación Directa FP8FP842msNo compatible Conclusión de las pruebas: En el caso de Transformer Engine, hay una mejora de aproximadamente el 20% en relación con el algoritmo de atención básica cuando se usa fp16. Además, hay una mejora significativa del 54.5% cuando se usa fp8, lo que indica que vale la pena invertir tiempo en mejorar el rendimiento de la inferencia. Bitsandbytes: Bitsandbytes es un envoltorio liviano para funciones CUDA personalizadas, optimizado específicamente para operaciones de 8 bits, multiplicación de matrices (LLM.int8()) y funciones de cuantización, y admite principalmente el algoritmo de cuantización LLM.int8(). La biblioteca bitsandbytes admite métodos de cuantización como cuantiles, lineales y dinámicos. Es uno de los métodos más simples disponibles y no requiere datos de calibración de cuantización ni procesos de calibración. Se puede usar fácilmente con cualquier modelo que contenga módulos torch.nn.Linear. El análisis actual sugiere que NF4 (tipo de datos NormalFloat) y FP4 son técnicas de cuantización de 4 bits igualmente efectivas, que exhiben atributos similares como velocidad de inferencia, consumo de memoria y calidad del contenido generado. El tipo de datos NormalFloat es una forma mejorada de técnica de cuantización, que representa la representación óptima de los pesos en una distribución normal en términos de teoría de la información. Es utilizado principalmente por el método QLoRA para ajustar modelos con precisión de 4 bits. A continuación, se muestran algunos datos de QLoRA:
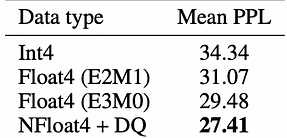
En Conclusión
La cuantización de 4 bits es actualmente el esquema de cuantización más rentable. Sin embargo, la optimización varía según el nivel de cuantización de las incrustaciones de palabras, los pesos y las activaciones. En la mayoría de los escenarios, excepto cuando las activaciones se cuantizan a 4 bits, la cuantización de enteros (Int) ofrece una mejor relación costo-efectividad, incluidos los escenarios sin cuantización. Por lo tanto, la cuantización de bits bajos, centrándose particularmente en las activaciones a través de la cuantización posterior al entrenamiento (PTQ), es una dirección prometedora para acelerar la cuantización. INT8 es el esquema de cuantización más utilizado en la actualidad. En comparación con INT8, FP8 no puede reemplazarlo por completo en escenarios de cuantización, pero es adecuado para el entrenamiento de modelos, ofreciendo una solución a los problemas de rendimiento de inferencia sin necesidad de cuantización. Integrar las técnicas relacionadas con FP8 con los núcleos tensor de hardware para maximizar la velocidad de inferencia es una nueva dirección que vale la pena explorar. Los proyectos basados en el algoritmo GPTQ dominan el panorama de los Modelos de Lenguaje Grande (LLM). Sin embargo, los nuevos tipos de datos (como FP4 y NF4), la precisión de bits más baja y la cuantización dinámica presentan oportunidades para la innovación y la investigación. Además de las GPU NVIDIA, las nuevas GPU y CPU (como AMD, GPU nacionales y Qualcomm) presentan nuevas oportunidades. Adaptar los algoritmos de cuantización a diferentes plataformas de hardware rápidamente y maximizar el rendimiento del hardware es una nueva dirección para explorar.
Artículos de Referencia
[1]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale [2]Outliers Dimensions that Disrupt Transformers Are Driven by Frequency [3]Smoothquant: Accurate and efficient post-training quantization for large language models [4]FP8 versus INT8 for efficient deep learning inference [5]FP8-LM: Training FP8 Large Language Models [6]The case for 4-bit precision: k-bit Inference Scaling Laws [7]LLM-FP4: 4-Bit Floating-Point Quantized Transformers [8]GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers [9]Understanding the Impact of Post-Training Quantization on Large Language Models [10]QLoRA: Efficient Finetuning of Quantized LLMs
novita.ai proporciona API de Stable Diffusion y cientos de API de generación de imágenes AI rápidas y económicas para 10,000 modelos.🎯 Generación más rápida en solo 2s, pago por uso, un mínimo de $0.0015 por imagen estándar, puede agregar sus propios modelos y evitar el mantenimiento de GPU. Gratis para compartir extensiones de código abierto.
Lectura recomendada


