
Motivation
Durch die Analyse aktueller wissenschaftlicher Arbeiten aus dem vergangenen Jahr im Bereich der KV-Sparsity (H2O, SnapKV, PyramidKV) wenden wir KV-Sparsity auf verschiedene Ebenen des Modells an. Mit einer Pruning-Strategie entfernen wir KV-Paare mit niedrigeren Bewertungen und behalten diejenigen mit höheren Bewertungen und größerer Nähe bei. Dieser Ansatz reduziert den Speicherverbrauch sowie den Rechen- und I/O-Overhead und führt letztlich zu einer beschleunigten Inferenz.
Experimente
Baselines und Einstellungen: Wir führen alle KV-Compress-Experimente mit unserer vLLM-Integration durch, die von v0.6.2 abgeleitet ist, im Cuda-Graph-Modus mit einer Blockgröße von 16. Für alle RTX 4090/Llama-3.1-8B-Instruct-Experimente verwenden wir eine standardmäßige GPU-Speicherauslastung von 0,9 und setzen die maximale Modelllänge auf 32k. Wir bewerten unsere Kompression auf Llama-3.1-8B-Instruct und vergleichen die Leistung mit den folgenden Basislinienmethoden aus früheren Arbeiten:
- vLLM-0.6.2
- Novita AI, Pyramid-KV-Cache-Kompression basierend auf dem vLLM-Framework
MMLU Pro und LongBench: Wir steuern verschiedene KV-Cache-Kompressionsverhältnisse, indem wir auf verschiedenen Ebenen unterschiedliche Längen gleitender Fenster festlegen. Im Experiment haben wir hauptsächlich drei verschiedene Längen gleitender Fenster von 1024, 1280 und 1536 eingestellt und Quertests mit unterschiedlicher Anzahl von Ebenen durchgeführt.MMLU ProIm MMLU-Pro-Test zeigen verschiedene KV-Sparsity-Ebenen und unterschiedliche Längen gleitender Fenster unterschiedliche Leistungen. Unter Berücksichtigung des Beschleunigungsverhältnisses kann die Gesamtgenauigkeit über 98% garantiert werden.
| vllm-0.6.2 | Novita AI | |
| KV-Sparsity-Ebenen | voll | gleitendes Fenster=1536 |
| 22 | 0.4517 | 0.4496 |
| 26 | 0.4517 | 0.4476 |
| 31 | 0.4517 | 0.4476 |
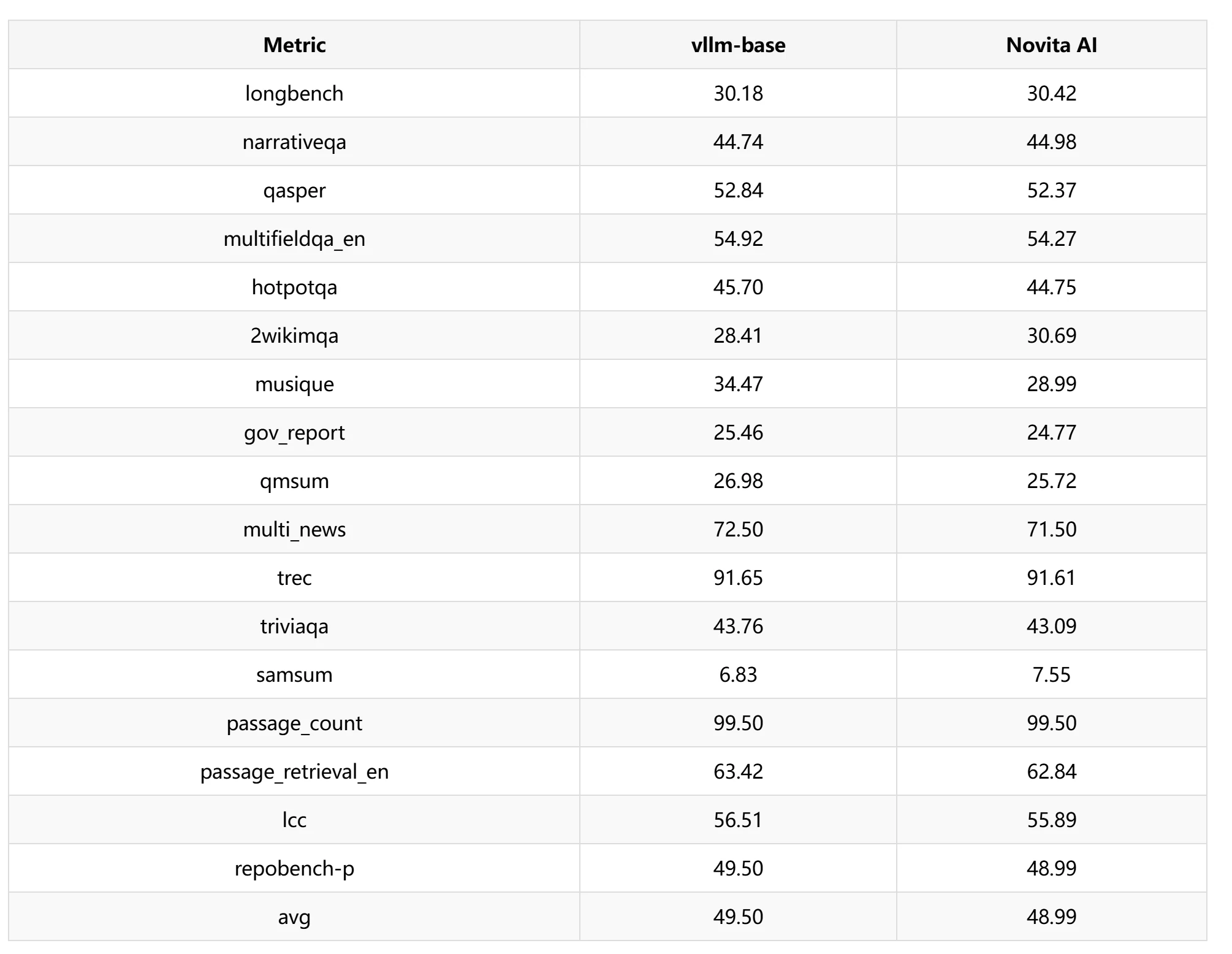
LongBenchIm LongBench-Test haben wir ein gleitendes Fenster von 1024 für den Leistungstest ausgewählt und festgestellt, dass der Genauigkeitsverlust etwa 1,03 % beträgt.
Durchsatz-Benchmarks: In realen LLM-Anwendungen ist eine Eingabe-/Ausgabelänge von 5000/500 die am häufigsten beobachtete Konfiguration, und der TTFT-Index muss unter 2s liegen. Basierend auf diesen Bedingungen haben wir Batch-Leistungsvergleichstests durchgeführt, die eine 1,5-fache Inferenzbeschleunigung für vLLM ergaben.
| Durchsatz | vllm-0.6.2 | Novita AI |
| KV-Sparsity-Ebenen | voll | gleitendes Fenster=1536 |
| 22 | 1 | 1.26 |
| 26 | 1 | 1.34 |
| 31 | 1 | 1.44 |
Wesentliche Änderungen
Geänderte Dateien umfassen hauptsächlich:
- Flash Attention, sparsity-basierte Bewertung basierend auf Flash Attention, während der Kernel-Leistungsverlust unter 1% gehalten wird.
- Paged Attention und reshape_and_cache, sparsity-basierte Bewertung basierend auf Paged Attention und Synchronisierung der sparsity-basierten Bewertung in den Prefill- und Decode-Phasen.
- Block_manager und andere Funktionen im Zusammenhang mit Speicherverwaltung und Tensor-Vorbereitung.
Fazit
Novita AI unterstützt auch Tensor-Parallelismus, um Modelle wie Llama3-70B auf mehreren GPUs auszuführen. Derzeit wird der Code aus bestimmten Gründen nicht offen unterstützt, aber wir hoffen, der Community einige Technologien und Ideen beizutragen, und freuen uns über technischen Austausch mit allen.Ein Hinweis: Die folgenden Funktionen werden in vLLM-0.6.2 noch nicht unterstützt:
- Chunked-prefill
- Prefix caching
- FlashInfer und andere Nicht-FlashAttention-Backends
- Spekulative Dekodierung
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.
Empfohlene Lektüre



