
动机
通过回顾过去一年 KV 稀疏性领域的最新学术论文(H2O、SnapKV、PyramidKV),我们将 KV 稀疏性应用于模型的不同层。采用剪枝策略,剔除得分较低的 KV 对,保留得分较高且距离较近的 KV 对。这种方法减少了内存使用以及计算和 I/O 开销,最终实现了推理加速。
实验
基线与设置: 我们使用基于 v0.6.2 分支的 vLLM 集成来运行所有 KV-Compress 实验,以 CUDA 图模式运行,块大小为 16。所有 RTX 4090/Llama-3.1-8B-Instruct 实验均使用默认 GPU 内存利用率 0.9,并将 maxmodel-length 设置为 32k。我们在 Llama-3.1-8B-Instruct 上评估压缩效果,并与先前工作中引入的以下基线方法进行对比:
- vLLM-0.6.2
- Novita AI,基于 vLLM 框架的 Pyramid KV 缓存压缩
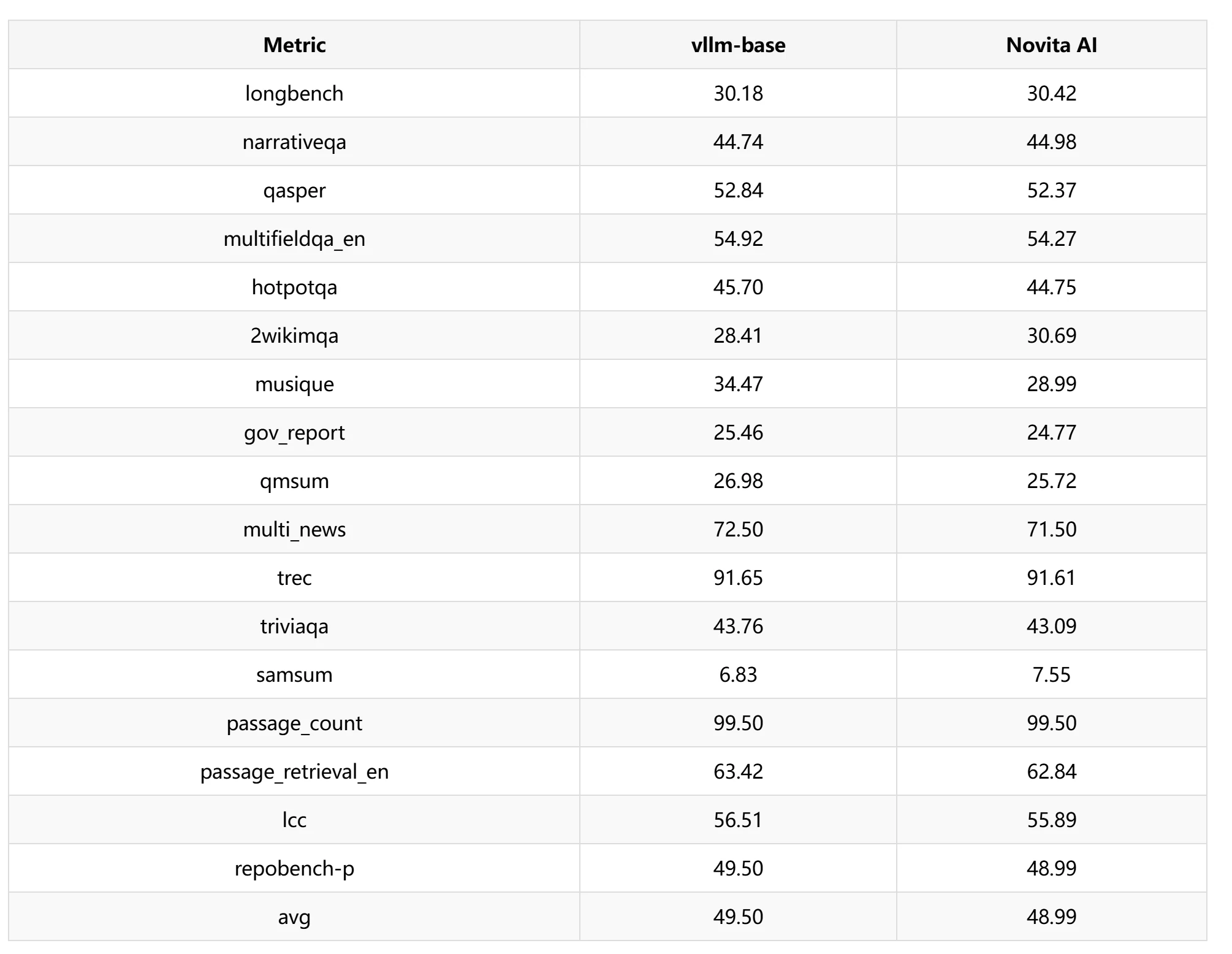
MMLU Pro 与 LongBench: 我们通过在不同层设置不同的滑动窗口长度来控制不同的 KV 缓存压缩比。实验中主要设置了 1024、1280 和 1536 三种滑动窗口长度,并在不同层数下进行了交叉测试。在 MMLU Pro 测试中,不同的 KV 稀疏层和滑动窗口长度表现出不同的性能。综合考虑加速比,整体精度可保持在 98% 以上。
| vllm-0.6.2 | Novita AI | |
| KV 稀疏层 | full | sliding window=1536 |
| 22 | 0.4517 | 0.4496 |
| 26 | 0.4517 | 0.4476 |
| 31 | 0.4517 | 0.4476 |
在 LongBench 测试中,我们选择了滑动窗口为 1024 进行性能测试,发现精度损失约为 1.03%。
吞吐量基准测试: 在真实的大语言模型应用中,输入/输出长度为 5000/500 是最常见的配置,且 TTFT 指标必须小于 2 秒。基于这些条件,我们进行了批量性能对比测试,结果表明 vLLM 的推理速度提升了 1.5 倍。
| 吞吐量 | vllm-0.6.2 | Novita AI |
| KV 稀疏层 | full | sliding window=1536 |
| 22 | 1 | 1.26 |
| 26 | 1 | 1.34 |
| 31 | 1 | 1.44 |
主要改动
修改的文件主要包括:
- Flash attention:基于 Flash attention 进行稀疏评分,同时确保 kernel 性能损失小于 1%。
- Paged attention 和 reshape_and_cache:基于 Paged attention 进行稀疏评分,并在 prefill 和 decode 阶段同步稀疏评分。
- Block_manager 及其他与内存管理和张量准备相关的函数。
结论
Novita AI 还支持张量并行,使 Llama3-70B 等模型能够在多个 GPU 上运行。目前由于某些原因暂未开放代码,但我们希望为社区贡献一些技术和思路,欢迎与大家进行技术交流。温馨提示: vLLM-0.6.2 中暂不支持以下功能:
- Chunked-prefill
- 前缀缓存
- FlashInfer 及其他非 FlashAttention 后端
- 推测解码
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时还提供经济可靠的 GPU 云用于构建和扩展。
推荐阅读



