

重點摘要
Novita AI 針對基於 SGLANG 部署 GLM4-MoE 模型,開發了一套經過生產環境驗證、影響力顯著的優化方案。我們提出一套端到端效能優化策略,從核心函式執行效率到跨節點資料傳輸排程,全面解決推論管線的瓶頸。透過整合**共享專家融合(Shared Experts Fusion)與後綴解碼(Suffix Decoding)**技術,我們在關鍵生產指標上取得了顯著提升,包括:
- Time-to-First-Token(TTFT,首字元延遲)最多降低 65%
- Time-Per-Output-Token(TPOT,單字元輸出延遲)提升 22%
在 AI 代理程式碼生成工作負載下達成上述成果。
所有結果皆在 TP8 與 FP8 配置的 H200 叢集上驗證,為高要求生產環境中實現最佳吞吐量與低延遲提供了實戰驗證的藍圖。
我們如何實現 GLM-MoE 的核心生產環境優化
1. 共享專家融合(Shared Experts Fusion)
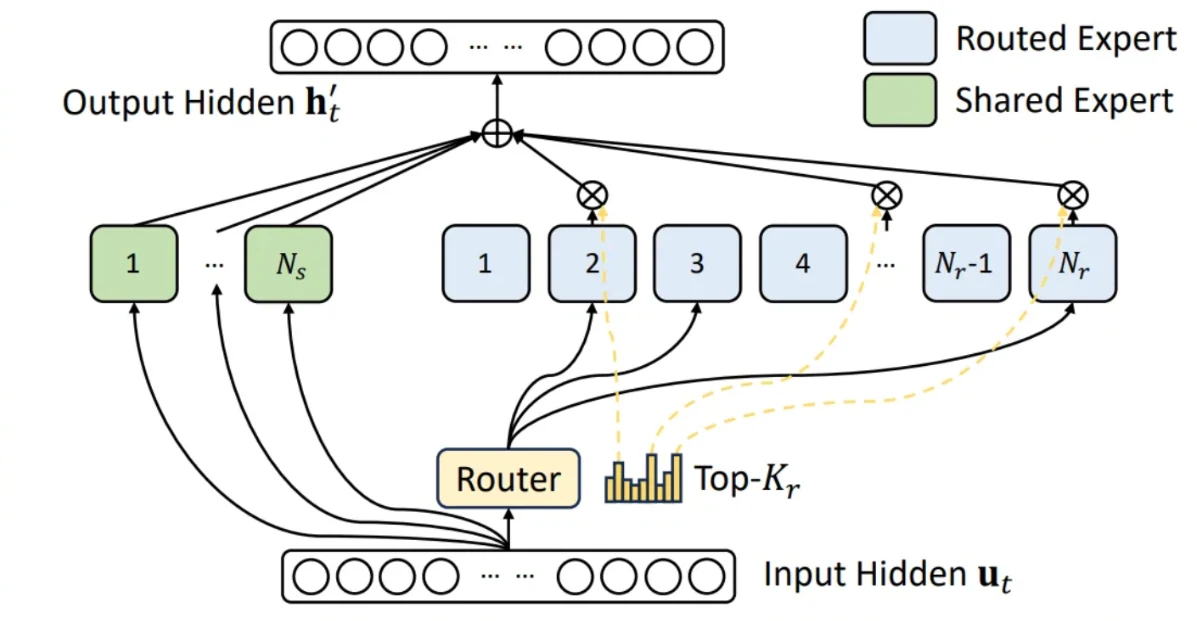
此優化的完整版權屬於 DeepSeek 模型的原始研究成果。如上圖所示,GLM4.7 這類 MoE 模型會將所有輸入權杖(token)傳遞給單一共享專家,同時每個權杖也會根據模型路由器的選擇,個別路由到各自的前 k 個路由專家。所有專家的輸出會經過加權聚合。例如 GLM4.7 採用 160 個路由專家搭配 1 個共享專家,每個權杖會選擇前 8 個路由專家。在先前的實作中,這兩個元件是分開處理的。由於兩者擁有相同的張量形狀與計算流程,最自然的優化方式就是將共享專家合併到路由 MoE 結構中——從總共 161 個專家中选择前 9 個,其中共享專家固定排在第九位。
如 PR 文件所述,此優化可讓 TTFT 提升最多 23.7%,詞元間延遲(ITL)提升 20.8%。這項增益符合預期,因為在 TP8 與 FP8 配置下,中間層大小僅有 192,對 H200 硬體來說相對較小,融合操作能大幅提升串流多處理器(SM)的利用率,同時顯著降低記憶體 I/O 開銷。
2. QK-Norm 融合(Qknorm Fusion)
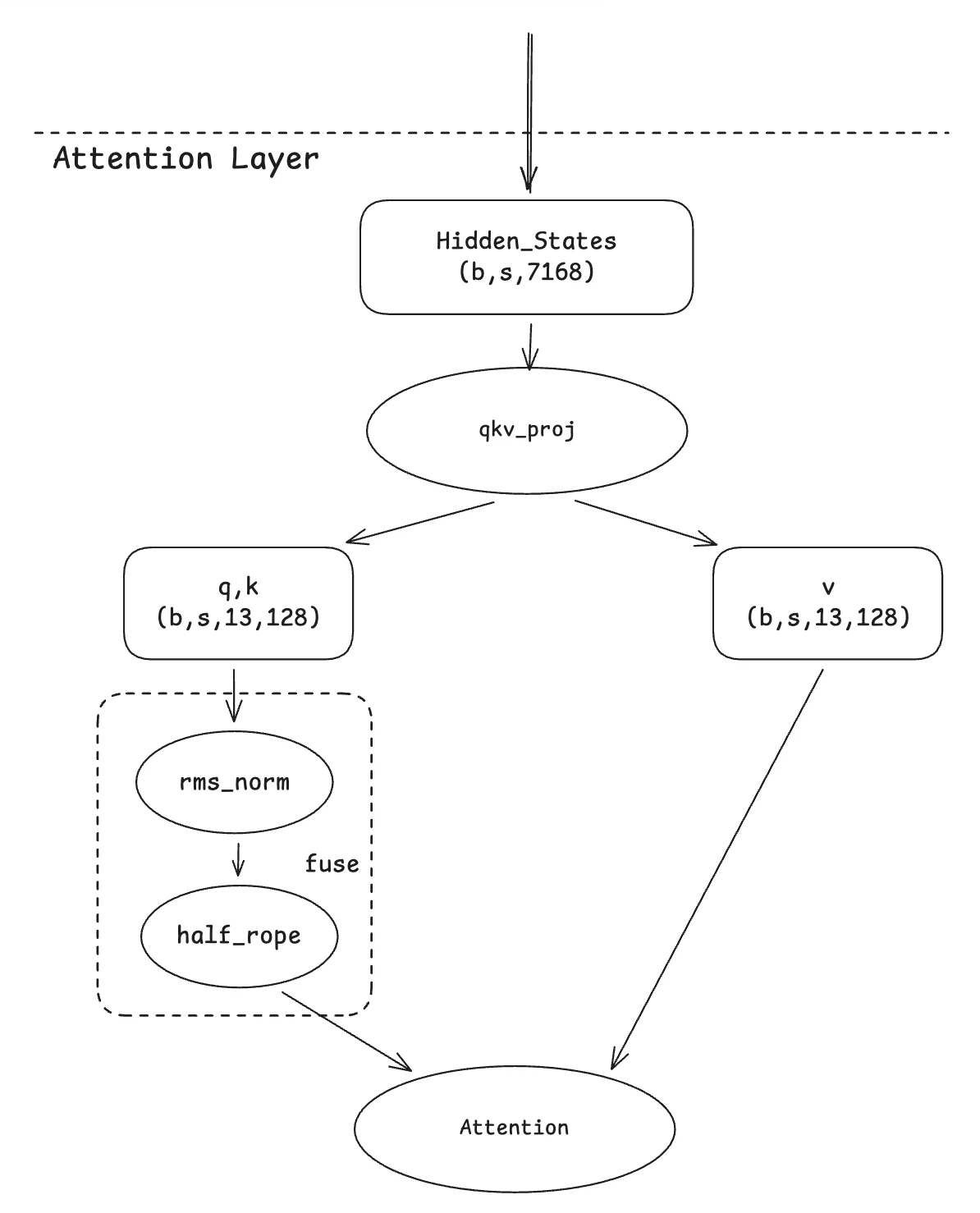
這項移植優化基於 Qwen-MoE 的優化方案。其核心思路非常簡單:由於兩個運算元都是針對每個注意力頭(head)進行計算,因此很自然地可以將它們融合為單一核心。我們的貢獻在於調整這組融合核心,以適配 GLM4-MoE 變體的特定場景——該場景中每個注意力頭只有一半的維度會進行旋轉。
3. 非同步傳輸(Async Transfer)
https://github.com/sgl-project/sglang/pull/14782
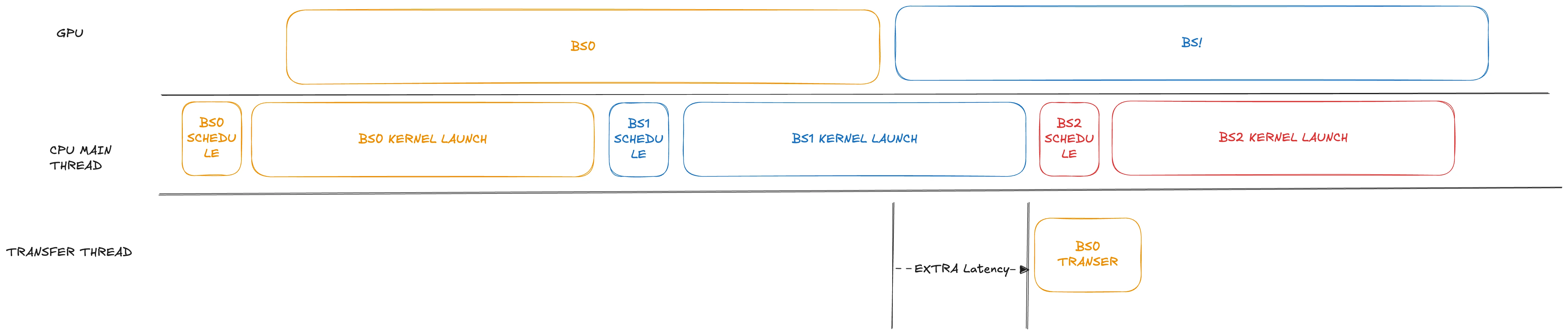
在採用重疊排程的 PD disaggregation 場景中,雖然吞吐量可提升約 10%,但 TTFT 會顯著下降。我們觀察到,在當前的預填充(prefill)實作中,資料傳輸流程會被延遲到下一批次的核心啟動之後才執行。對於擁有 92 層的 GLM4.7 這類模型,未使用 CUDA Graph 的核心啟動會非常耗時(通常需要數百毫秒,甚至超過 1 秒)。
為了解決這個問題,我們在修改版中稍微提前了傳輸步驟的排程,將其安排在對應的 GPU 運算完成後立即執行。此外,我們將傳輸流程放在獨立的執行緒中執行,透過妥善處理潛在的資料競爭結構,傳輸流程不會阻塞主執行緒。
對於需要大量核心啟動的模型,這項優化的效能提升非常顯著。在重負載場景下,這項優化最多可節省 1 秒的 TTFT,如下圖所示:
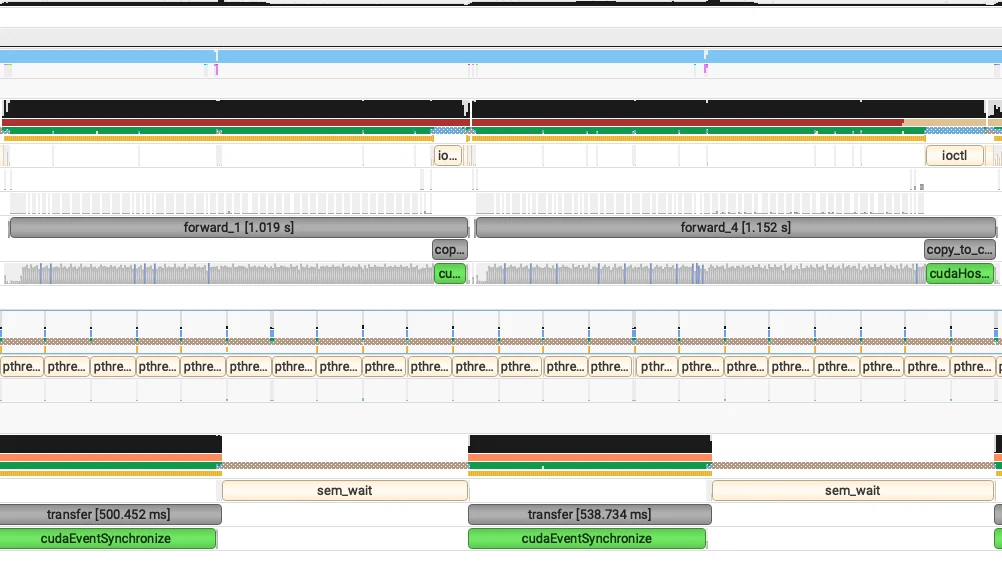
生產環境基準測試結果
在實施上述所有優化方案後,GLM-MoE 模型的效能取得了顯著提升,如下方的基準測試結果所示:
基準測試配置
- 輸入長度:4096
- 輸出長度:1000
- 請求速率:14 req/s
- 模型:GLM-4.7 FP8(TP8)
測試結果
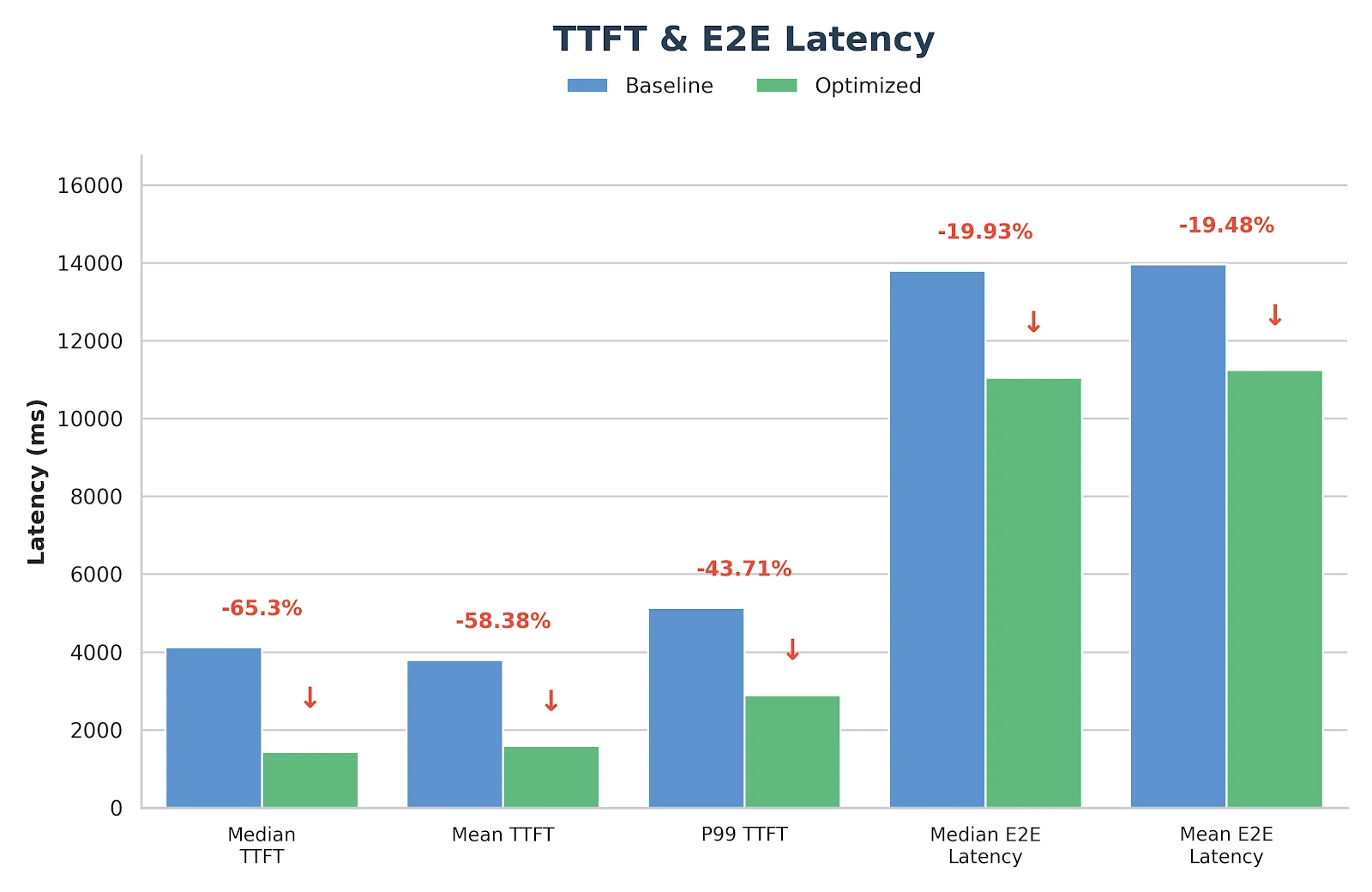
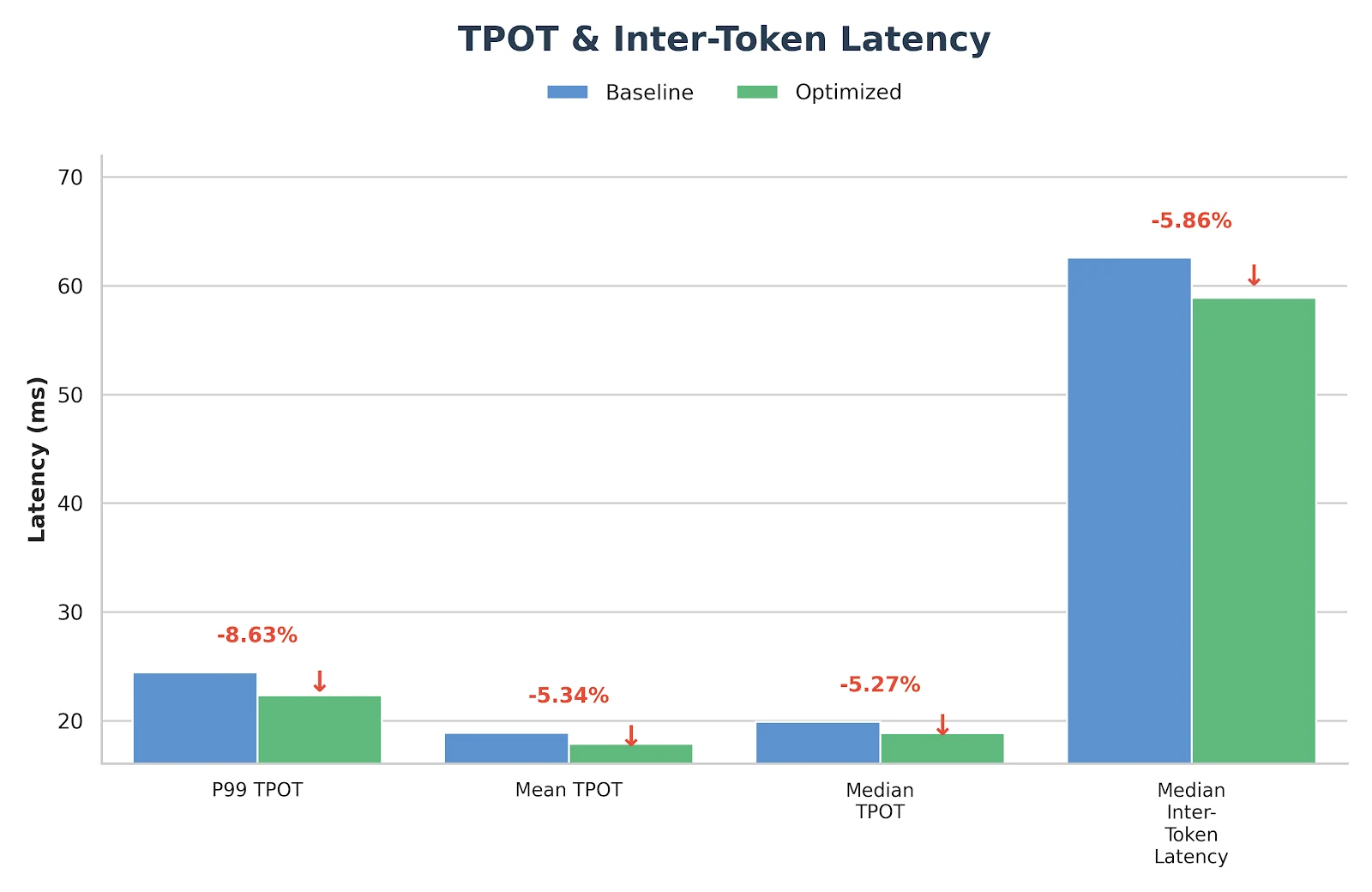
這些優化並非僅停留在實驗階段——它們已經在 Novita.ai 的生產環境推論服務中完成部署與驗證。如果您正在尋找適合真實工作負載的可靠、低延遲 GLM-MoE 後端,歡迎直接前往 novita.ai 體驗。
後綴解碼(Suffix Decoding)
AI 代理程式碼生成場景(如 Cursor、Claude Code)存在大量可重複使用的程式碼模式,因此可以針對這類場景實施後綴解碼這類定向效能優化。
背景:AI 代理程式碼生成的推論瓶頸
LLM 代理在程式碼生成任務上表現優異,但延遲仍是重大挑戰。傳統的推測解碼(Speculative Decoding)透過提前預測多個權杖(token)來加速推論,但常見的方案需要訓練額外的草稿模型,會引入額外的工程複雜度。
後綴解碼的運作原理
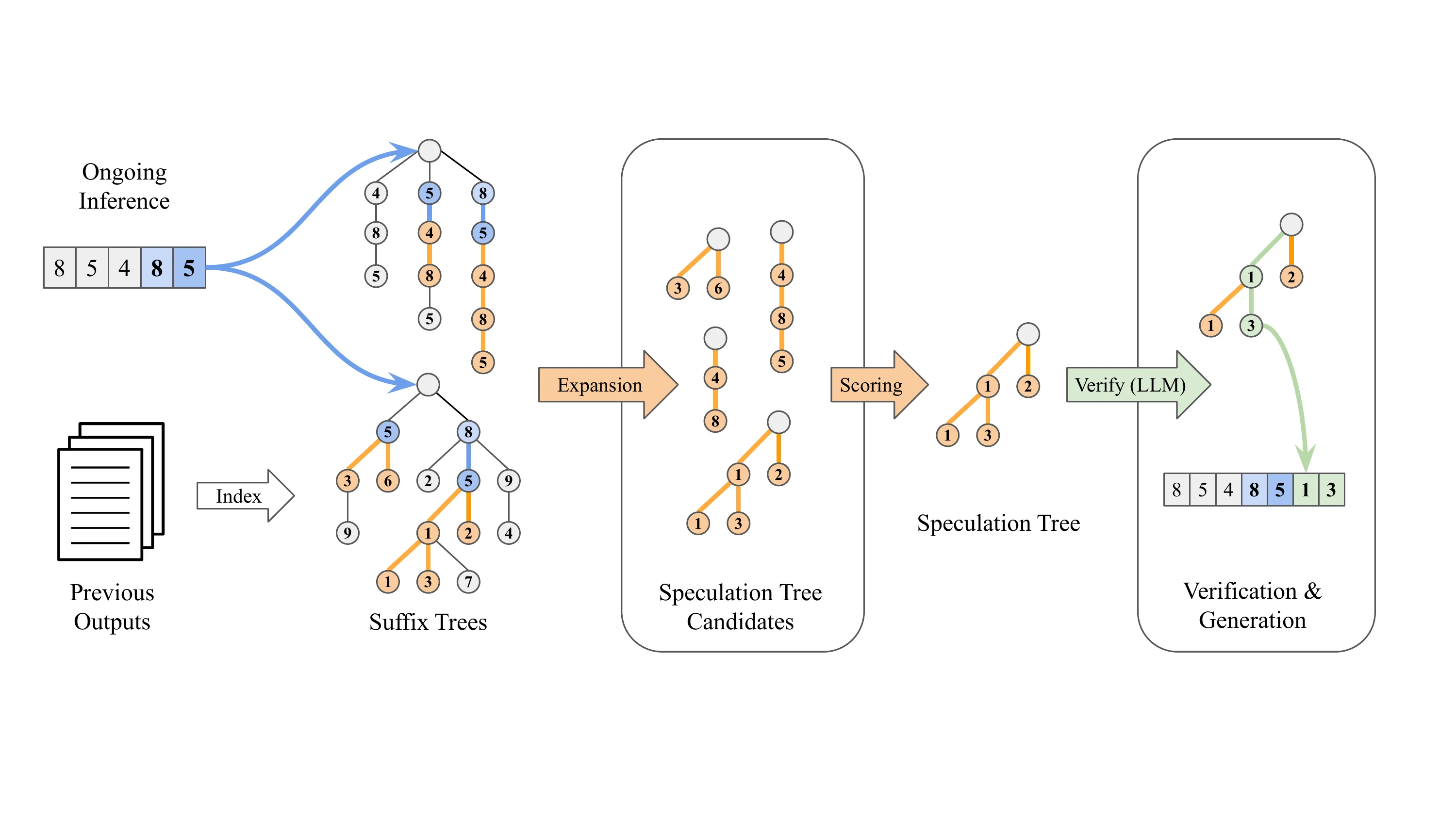
後綴解碼採用了完全不同的思路——它是完全不依賴模型的方案:
- 無需依賴額外的模型權重
- 利用先前生成的輸出序列中的模式來預測接下來的權杖(token)
- 當目前請求的後綴與歷史模式匹配時,會沿著該歷史序列繼續進行推測
資料驗證:輸出模式重複性分析
透過分析 22 個 Claude Code 使用時段(共 17,487 輪對話),我們發現:
- 39.3% 的輸出模式重複:相似的工具呼叫與回應模式出現頻率極高
- 高度結構化的代理行為:「讓我來…」「現在讓我…」這類固定用語出現頻率很高
為支持後續研究,我們已在 Hugging Face 開源評估資料集:https://huggingface.co/datasets/novita/agentic_code_dataset_22
效能比較
在內建多權杖預測(MTP)加速的基礎上,後綴解碼可進一步將 TPOT 降低 22%(從 25.13ms 降至 19.63ms):
| 指標 | MTP | 後綴解碼 | 變化 |
|---|---|---|---|
| 平均 TPOT | 25.13 ms | 19.63 ms | -21.90% |
| 中位數 TPOT | 25.95 ms | 20.05 ms | -22.70% |
結論
這些優化方案的組合,為 SGLANG 部署提供了全面的效能提升:
- 共享專家融合(Shared Experts Fusion) 解決 MoE 模型的計算效率問題
- QK-Norm-RoPE 融合 降低核心啟動開銷
- 非同步傳輸(Async Transfer) 優化 disaggregated 部署中的資料傳輸效率
- 後綴解碼(Suffix Decoding) 利用模式重複性,為 AI 代理程式碼生成場景提供推測解碼加速。
大部分元件已經合併至上游版本,或正在進行整合流程,歡迎前往 SGLang 倉庫查看詳情。
如何重現結果
此處僅列出與效能相關的關鍵參數。
完整的啟動腳本(基線版本 vs 優化版本)、基準測試框架與效能分析追蹤記錄已發佈至我們的 GitHub:https://github.com/novitalabs/sglang/tree/glm\_suffix
- 核心優化參數(SGLang 執行階段)
--tp-size 8
--kv-cache-dtype fp8_e4m3
--attention-backend fa3
--chunked-prefill-size 16384
--enable-flashinfer-allreduce-fusion
--enable-fused-qk-norm-rope
--enable-shared-experts-fusion
--disaggregation-async-transfer
- 推測解碼配置(AI 代理程式碼生成工作負載)
--speculative-algorithm NEXTN
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 4
- 後綴解碼配置(可選)
--speculative-algorithm SUFFIX
--speculative-suffix-cache-max-depth 64
--speculative-suffix-max-spec-factor 1.0
--speculative-suffix-min-token-prob 0.1
參考資料
- SGLANG PR #13873:共享專家優化
- Snowflake 工程部落格:生產規模的 SuffixDecoding 實踐
- NeurIPS 論文:SuffixDecoding
- Arctic Inference 倉庫
Novita AI 是領先的 AI 雲端平台,為開發者提供易於使用的 API,以及可負擔、可靠的 GPU 基礎設施,用於構建與擴展 AI 應用程式。



