

TL;DR
Novita AI 基于 SGLANG 开发了一套经过生产验证、影响深远的优化方案,用于部署 GLM4-MOE 模型。我们介绍了一种端到端性能优化策略,该策略解决了整个推理流水线中的瓶颈——从内核执行效率到跨节点数据传输调度。通过集成共享专家融合(Shared Experts Fusion)和后缀解码(Suffix Decoding),我们在代理编码工作负载中观察到关键生产指标的显著提升,包括:
- 首Token延迟(TTFT)降低最高达65%
- 输出每Token时间(TPOT)提升22%
所有结果均在 TP8 和 FP8 配置下的 H200 集群上验证,为在苛刻生产环境中实现最佳吞吐量和低延迟提供了经过实战检验的蓝图。
我们如何实现GLM-MoE的核心生产优化
1. 共享专家融合(Shared Experts Fusion)
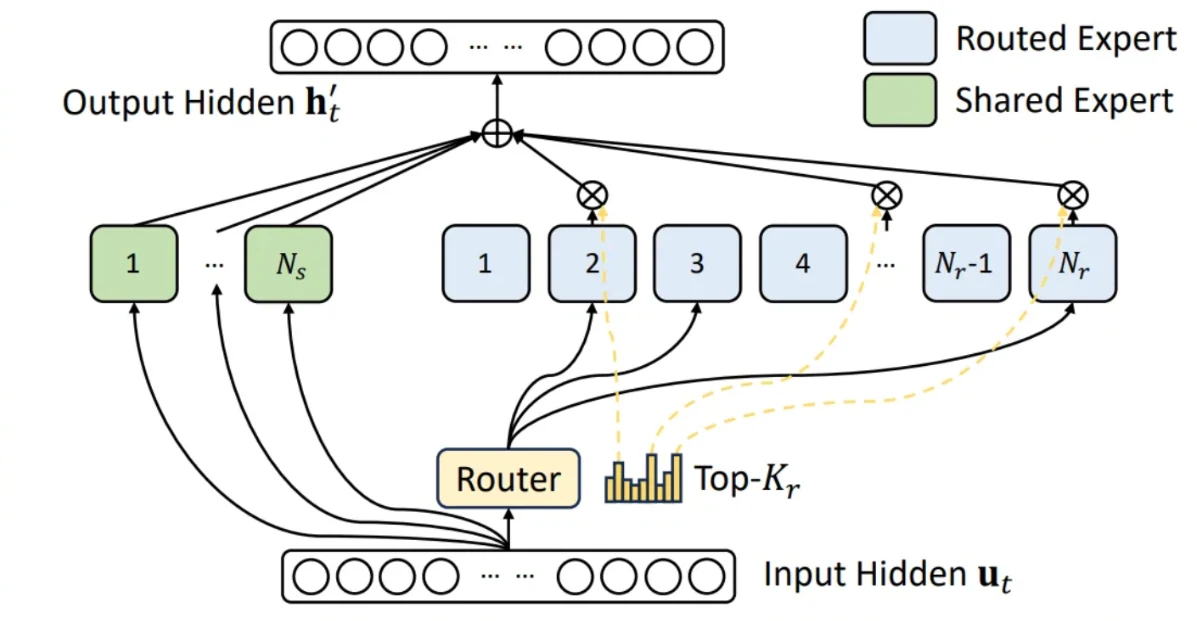
该优化的全部功劳归于 Deepseek 模型的原始工作。如上图所示,GLM4.7 等 MoE 模型将所有输入 Token 路由到一个共享专家,同时每个 Token 也单独路由到由模型路由器选择的各自 top-k 路由专家。所有专家的输出再经过加权聚合。例如,GLM4.7 使用 160 个路由专家加一个共享专家,每个 Token 选择 top-8 路由专家。在早期实现中,这两个组件是分开处理的。由于它们共享相同的张量形状和计算过程,很自然地可以通过将共享专家合并到路由 MoE 结构中来统一两者——从总共 161 个专家中选择 top-9,共享专家始终占据第 9 个位置。
正如 PR 中所记载,该优化在 TTFT 上实现了高达 23.7% 的提升,在 ITL 上实现了 20.8% 的提升。这些提升是预期的,因为在 TP8 和 FP8 配置下,中间大小仅为 192,对于 H200 硬件来说相对较小,融合操作大幅提高了流多处理器(SM)利用率并显著降低了内存 I/O 开销。
2. Q-K 归一化融合(Qknorm Fusion)
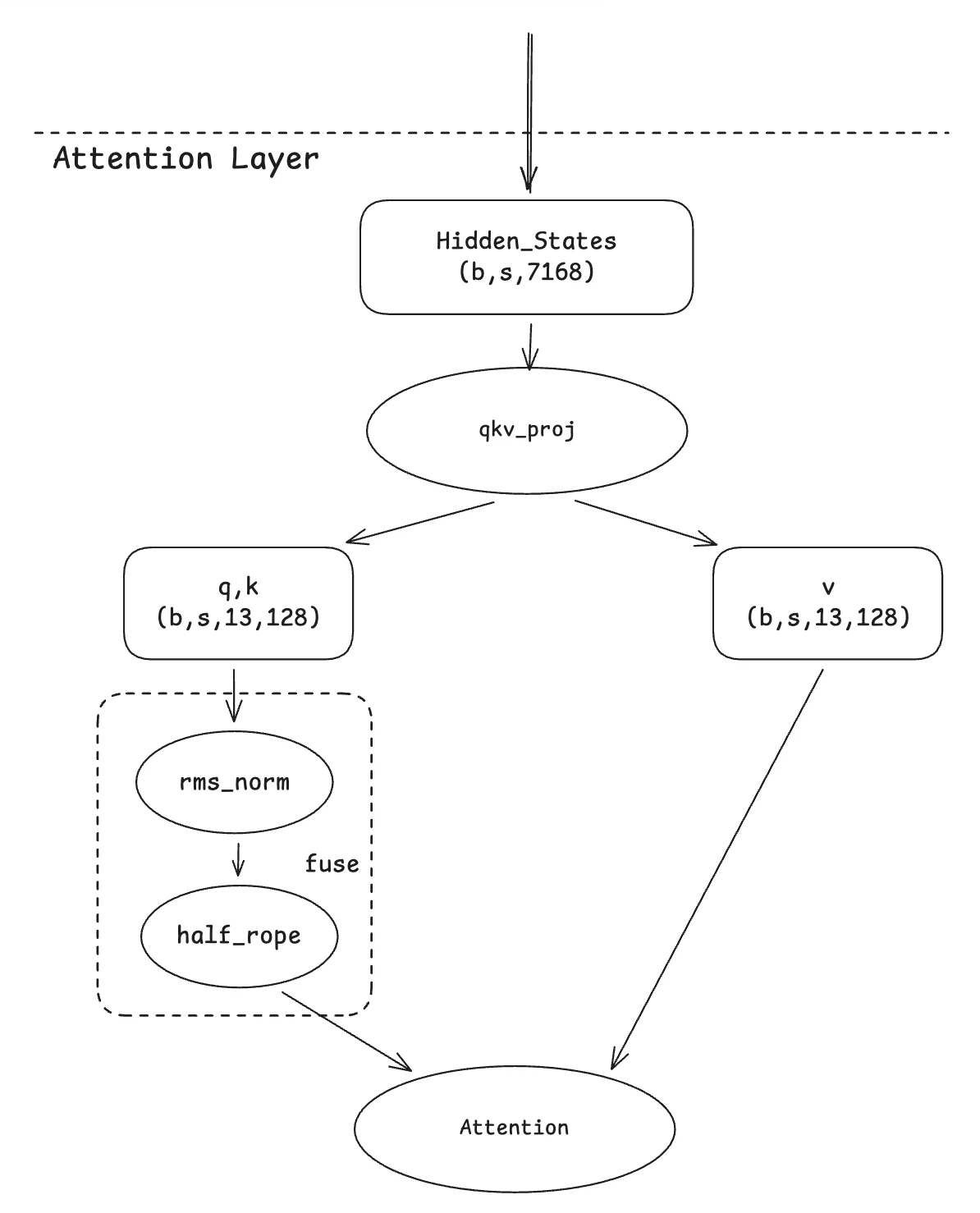
这一迁移建立在 Qwen-MOE 的优化之上。其基本思想很直接:由于两个算子都按 head 进行计算,将它们融合到一个内核中是自然的方法。我们的贡献在于调整这个融合内核,以适应 GLM4-MOE 变体的特定情况——即一个 head 内只有一半维度被旋转。
3. 异步传输(Async Transfer)
https://github.com/sgl-project/sglang/pull/14782
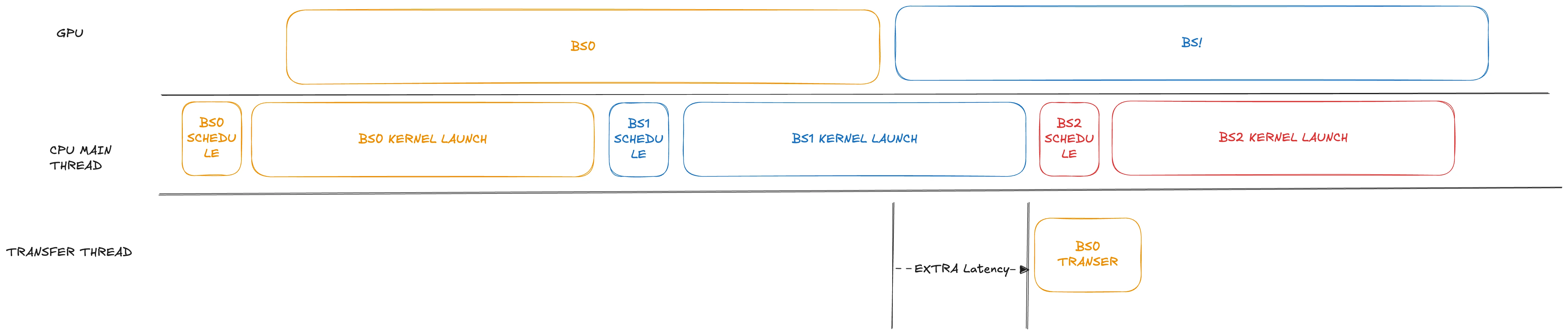
在应用具有重叠调度的 PD 分离(PD disaggregation)场景中,虽然吞吐量可提升约 10%,但 TTFT 明显下降。我们观察到,在当前的 prefill 实现中,数据传输过程会延迟到下一批的内核启动之后才进行。对于像 GLM4.7 这样包含 92 层的模型,在没有 CUDA Graph 的情况下,内核启动可能非常耗时(通常需要数百毫秒,甚至超过 1 秒)。
为了解决这个问题,在我们的修改中,我们将传输步骤稍微提前,安排在相应的 GPU 操作完成后立即进行。此外,传输被放置在一个单独的线程中。通过仔细处理潜在的数据竞争结构,它可以在不阻塞主线程的情况下进行。
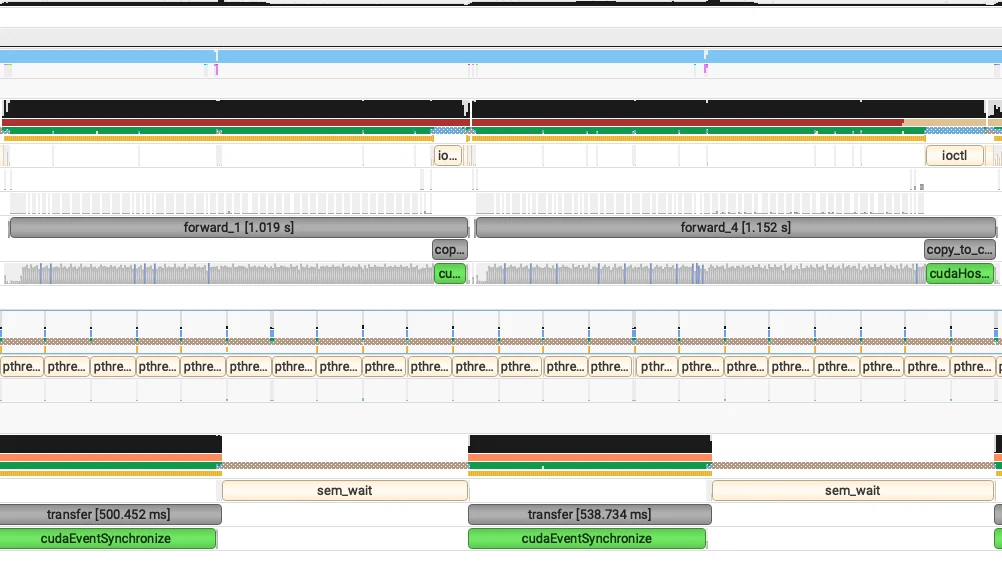
对于内核启动较多的模型,其性能提升非常显著。在负载较重的情况下,该优化可以节省多达 1 秒的 TTFT,如下图所示。
生产基准测试结果
在实施上述方法后,我们观察到 GLM-MOE 模型的性能显著提升,如下面的基准测试结果清晰所示。
基准测试配置
- 输入长度:4096
- 输出长度:1000
- 请求速率:14 req/s
- 模型:GLM-4.7 FP8(TP8)
结果
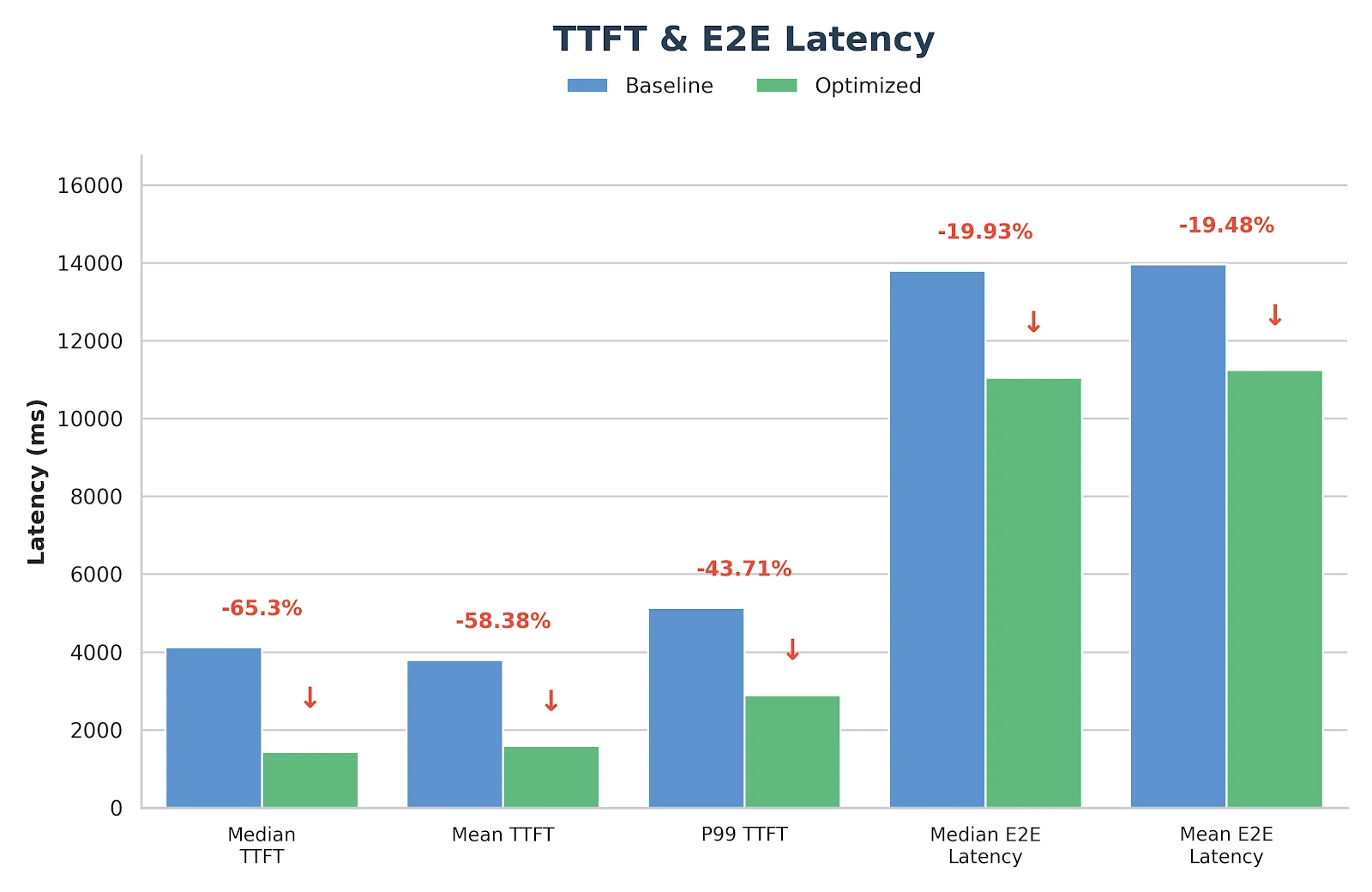
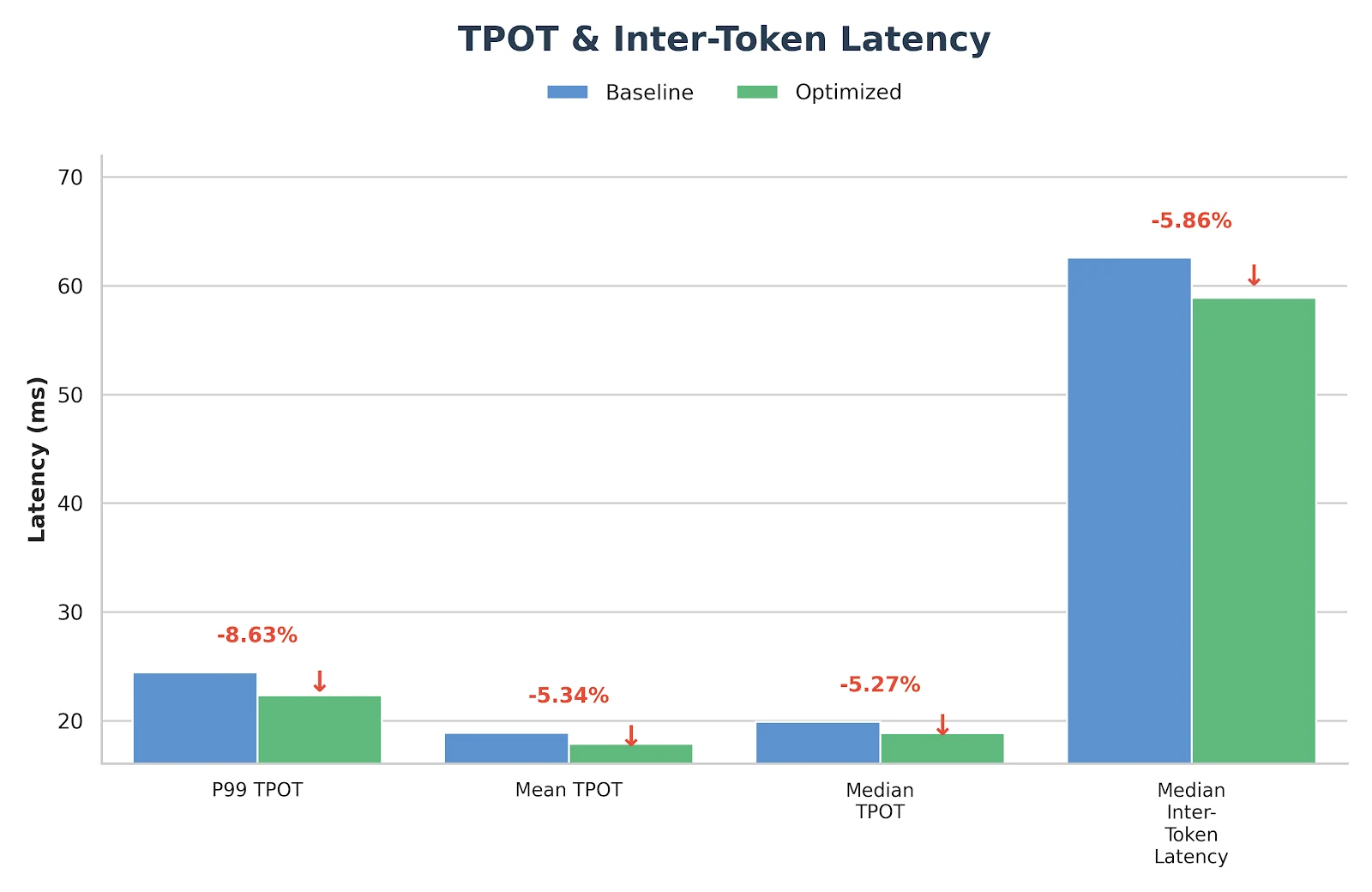
这些优化并非仅仅是实验性的——它们已经在 Novita.ai 的生产推理服务中部署并验证。如果您正在为真实工作负载寻找可靠、低延迟的 GLM-MoE 后端,欢迎直接在 novita.ai 上试用。
后缀解码(Suffix Decoding)
代理编码场景(例如 Cursor 和 Claude Code)中存在大量可复用的代码模式,这使得后缀解码等有针对性的性能优化成为可能。
背景:代理编码中的推理瓶颈
LLM 代理在代码生成任务中表现出色,但延迟仍然是一个重大挑战。传统的推测解码(Speculative Decoding)通过提前预测多个 Token 来加速推理,但常见的方法需要训练额外的草稿模型,从而增加了工程复杂度。
后缀解码的工作原理
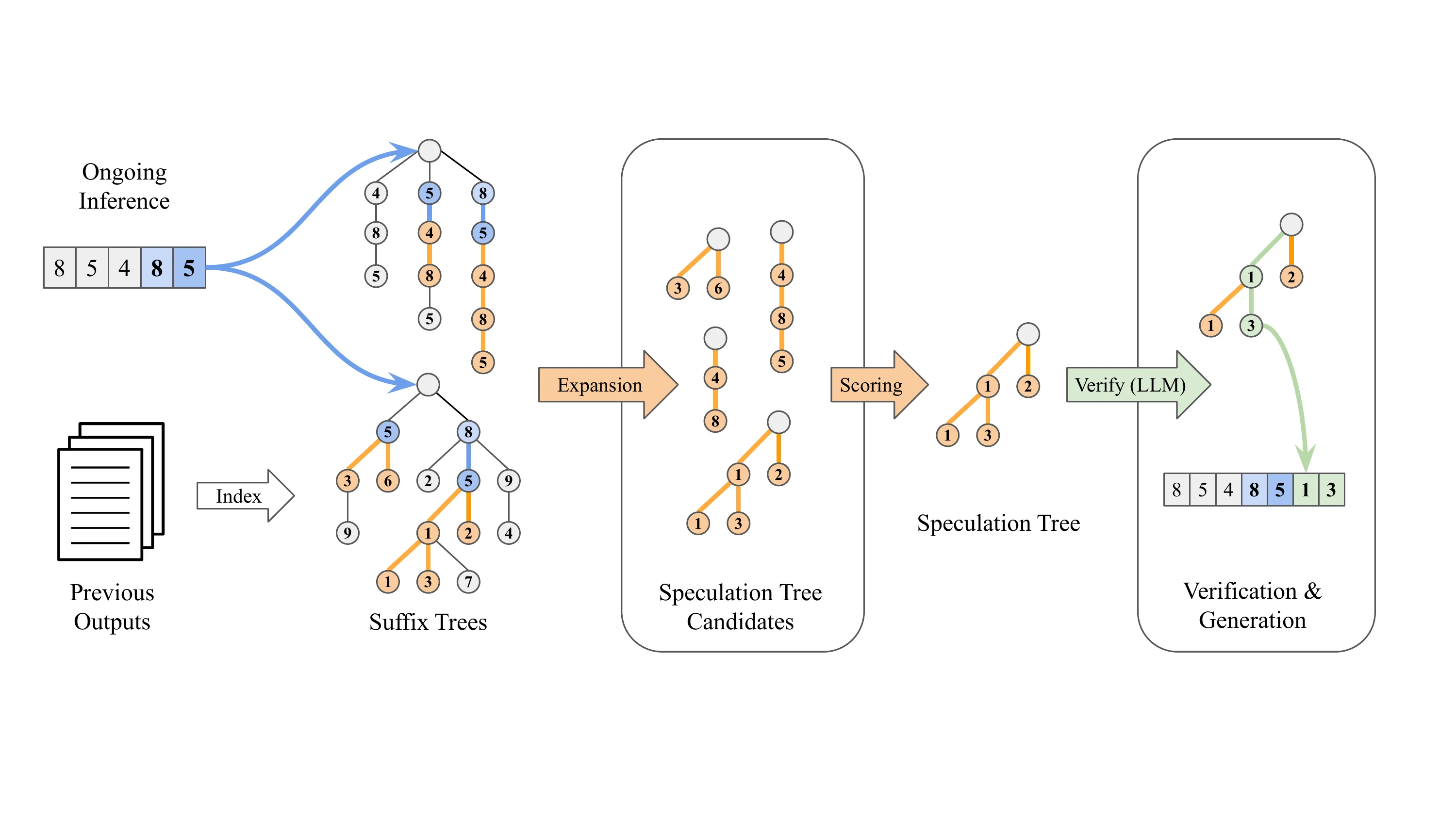
后缀解码采用了一种完全不同的方法——它完全无模型依赖:
- 不依赖额外的模型权重
- 利用先前生成的输出序列中的模式来预测后续 Token
- 当当前请求的后缀与历史模式匹配时,它沿该历史序列继续推测
数据验证:输出模式重复分析
通过分析 22 个 Claude Code 会话(共 17,487 次对话轮次),我们发现:
- 39.3% 的输出模式重复:工具调用和响应模式出现频率高
- 高度结构化的代理行为:固定短语如“Let me…”、“Now let me…”频繁出现
为了支持进一步的研究,我们在 Hugging Face 上开源了评估数据集:https://huggingface.co/datasets/novita/agentic_code_dataset_22
性能对比
在基于 MTP 加速的基础上,后缀解码进一步将 TPOT 降低了 22%(从 25.13ms 降至 19.63ms):
| 指标 | MTP | 后缀解码 | 变化 |
| 平均 TPOT | 25.13 ms | 19.63 ms | -21.90% |
| 中位数 TPOT | 25.95 ms | 20.05 ms | -22.70% |
结论
这些优化的组合为 SGLANG 部署提供了全面的性能提升:
- 共享专家融合:解决 MoE 模型的计算效率问题
- Q-K 归一化与RoPE融合:减少内核启动开销
- 异步传输:优化分离部署中的数据移动
- 后缀解码:利用模式重复实现代理编码场景的推测解码
大多数组件已合并到上游或正在集成中;欢迎前往 SGLang 仓库查看并尝试。
如何复现
此处仅展示关键的性能相关参数。
完整的启动脚本(基线 vs 优化)、基准测试工具和性能分析跟踪已在我们的 GitHub 上发布:https://github.com/novitalabs/sglang/tree/glm_suffix
- 核心优化标志(SGLang 运行时)
--tp-size 8
--kv-cache-dtype fp8_e4m3
--attention-backend fa3
--chunked-prefill-size 16384
--enable-flashinfer-allreduce-fusion
--enable-fused-qk-norm-rope
--enable-shared-experts-fusion
--disaggregation-async-transfer
- 推测解码配置(代理编码工作负载)
--speculative-algorithm NEXTN
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 4
- 后缀解码配置(可选)
--speculative-algorithm SUFFIX
--speculative-suffix-cache-max-depth 64
--speculative-suffix-max-spec-factor 1.0
--speculative-suffix-min-token-prob 0.1
参考文献
- SGLANG PR #13873: 共享专家优化
- Snowflake Engineering Blog: 大规模生产环境下的后缀解码
- NeurIPS 论文: SuffixDecoding
- Arctic Inference 仓库
Novita AI 是领先的 AI 云平台,为开发者提供易于使用的 API 以及经济可靠、生产就绪的 GPU 基础设施,用于构建和扩展 AI 应用。



