

TL;DR
طورت Novita AI مجموعة من التحسينات عالية التأثير المختبرة في الإنتاج لنشر نماذج GLM4-MOE المعتمدة على SGLANG. نقدم استراتيجية تحسين الأداء من البداية إلى النهاية تعالج الاختناقات في خط أنابيب الاستدلال بأكمله - من كفاءة تنفيذ النواة إلى جدولة نقل البيانات بين العقد. من خلال دمج دمج الخبراء المشتركين و فك تشفير اللاحقة، لاحظنا مكاسب كبيرة في المقاييس الإنتاجية الرئيسية، بما في ذلك:
- تقليل يصل إلى 65% في زمن الوصول لأول رمز (TTFT)
- تحسين بنسبة 22% في زمن الرمز لكل مخرج (TPOT)
في أحمال عمل البرمجة بالوكلاء.
تم التحقق من جميع النتائج على مجموعات H200 بتكوينات TP8 و FP8، مما يوفر خطة عمل مجربة لتحقيق أفضل إنتاجية وزمن استجابة منخفض في البيئات الإنتاجية الصعبة.
كيف قمنا بتنفيذ التحسينات الإنتاجية الأساسية لنموذج GLM-MoE
1. دمج الخبراء المشتركين
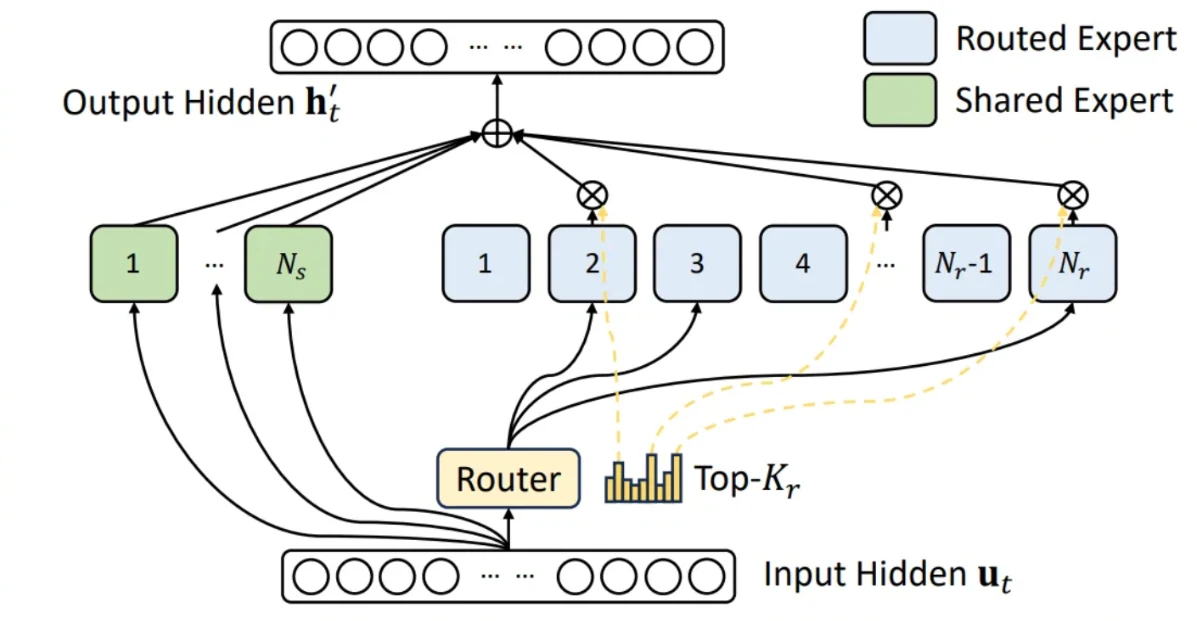
نسبة الفضل الكامل لهذا التحسين يعود إلى العمل الأصلي على نموذج Deepseek. كما هو موضح في الشكل أعلاه، تقوم نماذج MoE مثل GLM4.7 بتوجيه جميع الرموز المدخلة عبر خبير مشترك واحد، بينما يتم توجيه كل رمز بشكل فردي إلى مجموعته الخاصة من الخبراء الموجهين من أعلى k حسبما يحدد موجه النموذج. ثم يتم ترجيح مخرجات جميع الخبراء وتجميعها. على سبيل المثال، يستخدم GLM4.7 160 خبيرًا موجهًا بالإضافة إلى خبير مشترك واحد، ويختار أفضل 8 خبراء موجهين لكل رمز. في التنفيذات السابقة، تم التعامل مع هذين المكونين بشكل منفصل. نظرًا لأنهما يشتركان في نفس أشكال الموترات وإجراءات الحساب، فمن الطبيعي توحيدهما عن طريق دمج الخبير المشترك في بنية MoE الموجهة - باختيار أفضل 9 من أصل 161 خبيرًا إجمالاً، مع تعيين الخبير المشترك دائمًا في المركز التاسع.
كما هو موثق في طلب السحب (PR)، يحقق هذا التحسين مكاسب في الأداء تصل إلى 23.7% في TTFT و 20.8% في زمن الرمز بين الرموز (ITL). هذه المكاسب متوقعة لأنه تحت تكوينات TP8 و FP8 - حيث يكون الحجم الوسيط 192 فقط، وهو حجم صغير نسبيًا لعتاد H200 - تعمل عملية الدمج على تعزيز استخدام معالج الدفق المتعدد (SM) بشكل كبير وتقلل بشكل كبير من عبء إدخال/إخراج الذاكرة.
2. دمج Qknorm
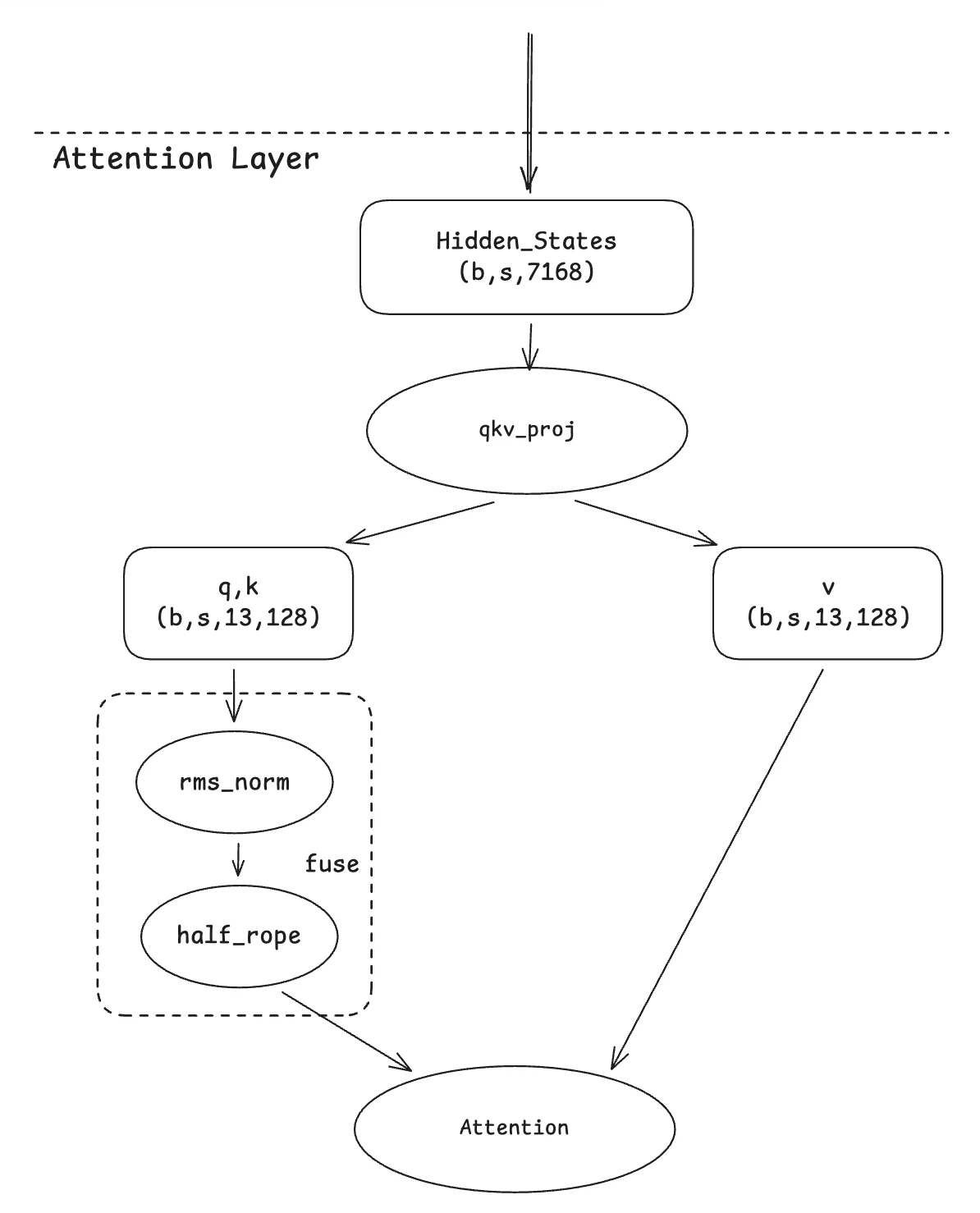
يعتمد هذا الترحيل على التحسين من نموذج Qwen-MOE. الفكرة الأساسية بسيطة. نظرًا لأن كلا المشغلين يقومان بحسابات على مستوى الرأس، فمن الطبيعي دمجهما في نواة واحدة. تكمن مساهمتنا في تكييف هذه النواة المدمجة لتناسب الحالة المحددة لنموذج GLM4-MOE، حيث يتم تدوير نصف الأبعاد فقط داخل الرأس.
3. النقل غير المتزامن
https://github.com/sgl-project/sglang/pull/14782
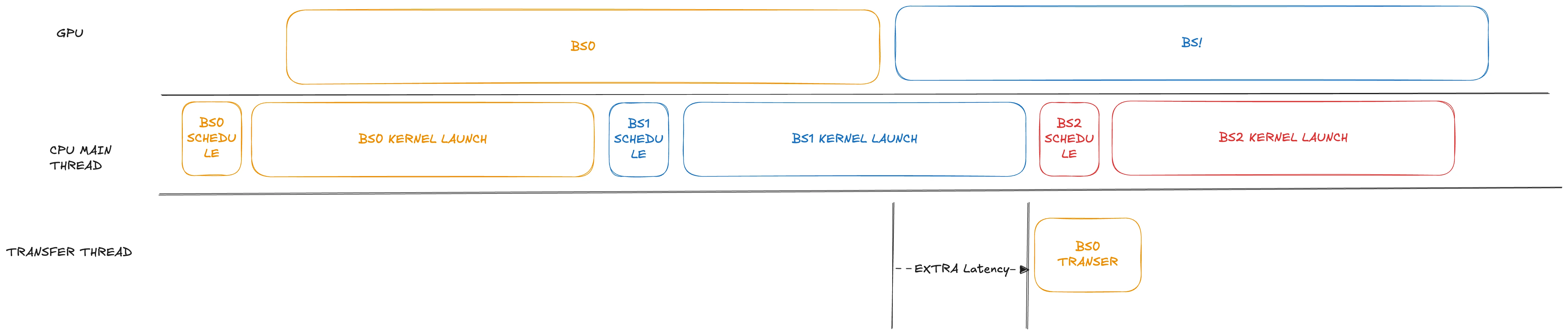
في السيناريوهات التي يتم فيها تطبيق تفكيك PD مع جداول متداخلة، على الرغم من أن الإنتاجية يمكن أن تزيد بنسبة 10% تقريبًا، ينخفض TTFT بشكل كبير. لاحظنا أنه في التنفيذ الحالي للتعبئة المسبقة (prefill)، يتم تأخير عملية نقل البيانات حتى بعد إطلاق النواة للدفعة التالية. بالنسبة لنموذج مثل GLM4.7 الذي يتكون من 92 طبقة، يمكن أن يكون إطلاق النواة بدون رسم بياني CUDA مستهلكًا للوقت (يستغرق غالبًا مئات من المللي ثانية甚至 أكثر من ثانية واحدة).
لمعالجة هذه المشكلة، قمنا في تعديلنا بتقديم خطوة النقل قليلاً، وجدولتها مباشرة بعد اكتمال عمليات GPU المقابلة لها. بالإضافة إلى ذلك، يتم وضع النقل في خيط منفصل. من خلال التعامل بعناية مع هياكل تعارض البيانات المحتملة، يمكن أن يستمر دون حظر الخيط الرئيسي.
الأداء ضخم للنماذج التي تحتوي على العديد من عمليات إطلاق النواة. في حالات الأحمال الثقيلة، يمكن أن يوفر هذا التحسين ما يصل إلى ثانية واحدة في TTFT كما هو موضح أدناه.
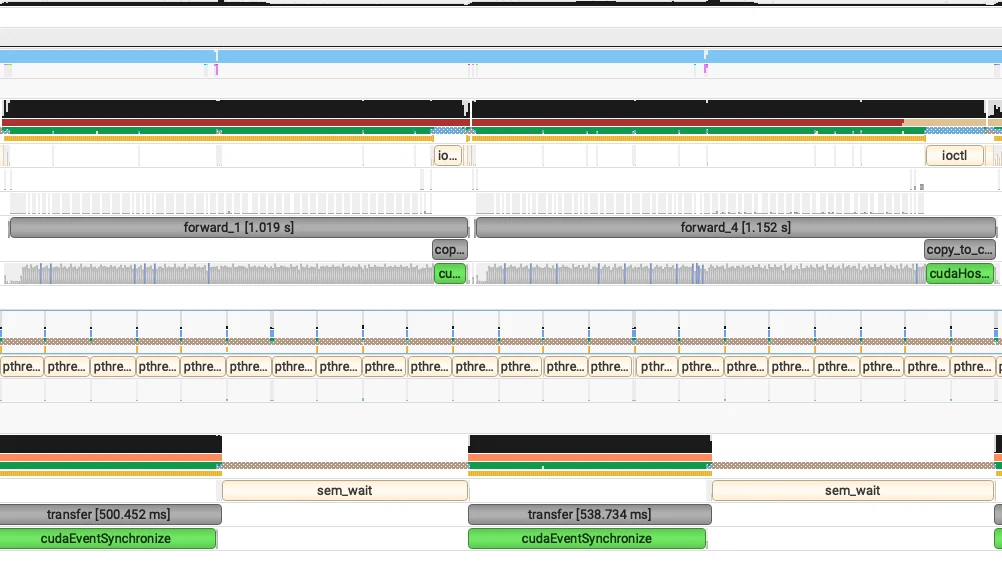
نتائج معايير الأداء الإنتاجية
بعد تنفيذ الأساليب المذكورة أعلاه، لاحظنا تحسينات كبيرة في الأداء لنماذج GLM-MOE، كما هو موضح بوضوح في نتائج المعايير أدناه.
تكوين المعيار
- طول الإدخال: 4096
- طول المخرج: 1000
- معدل الطلبات: 14 طلب/ثانية
- النموذج: GLM-4.7 FP8 (TP8)
النتائج
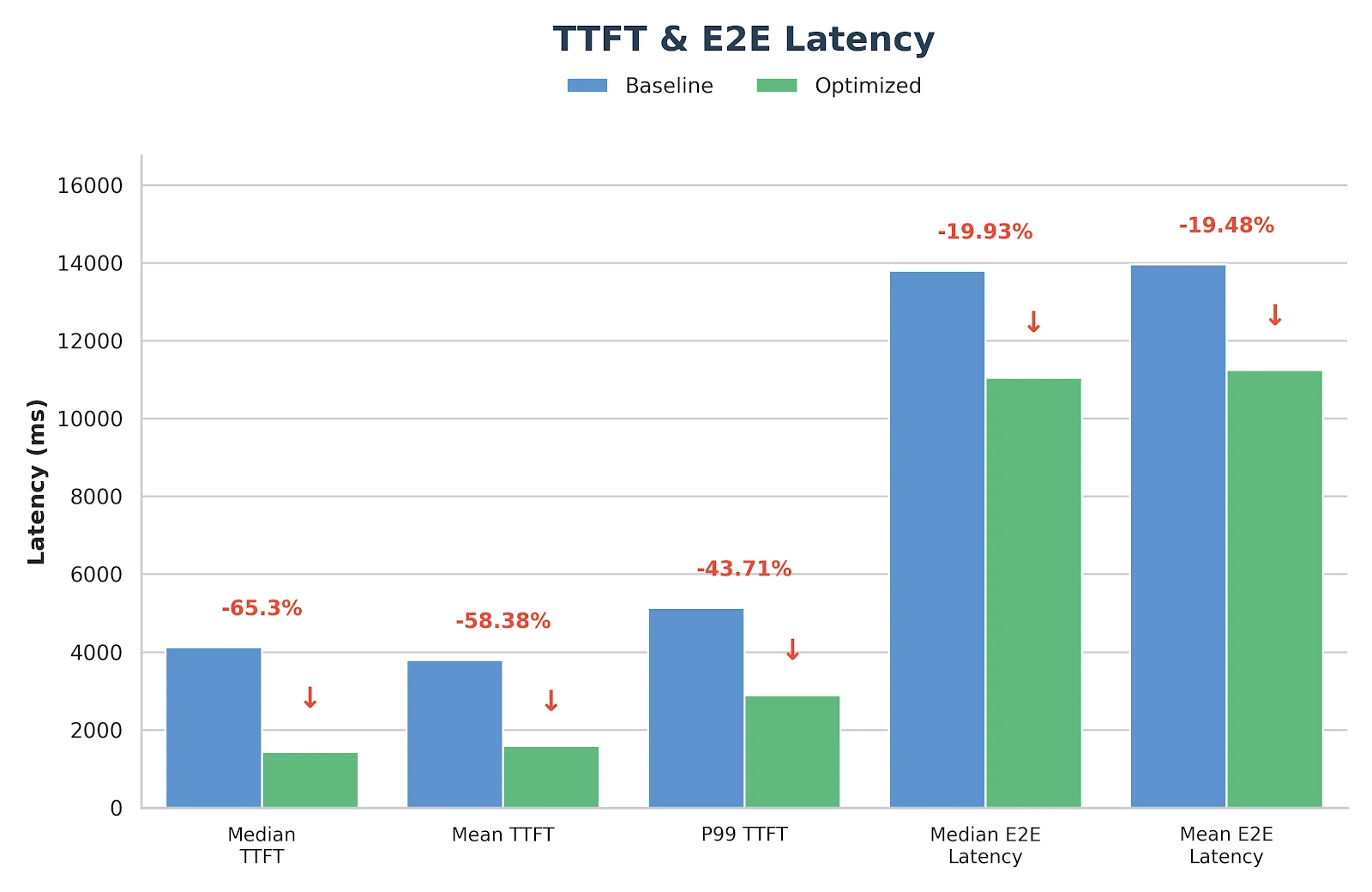
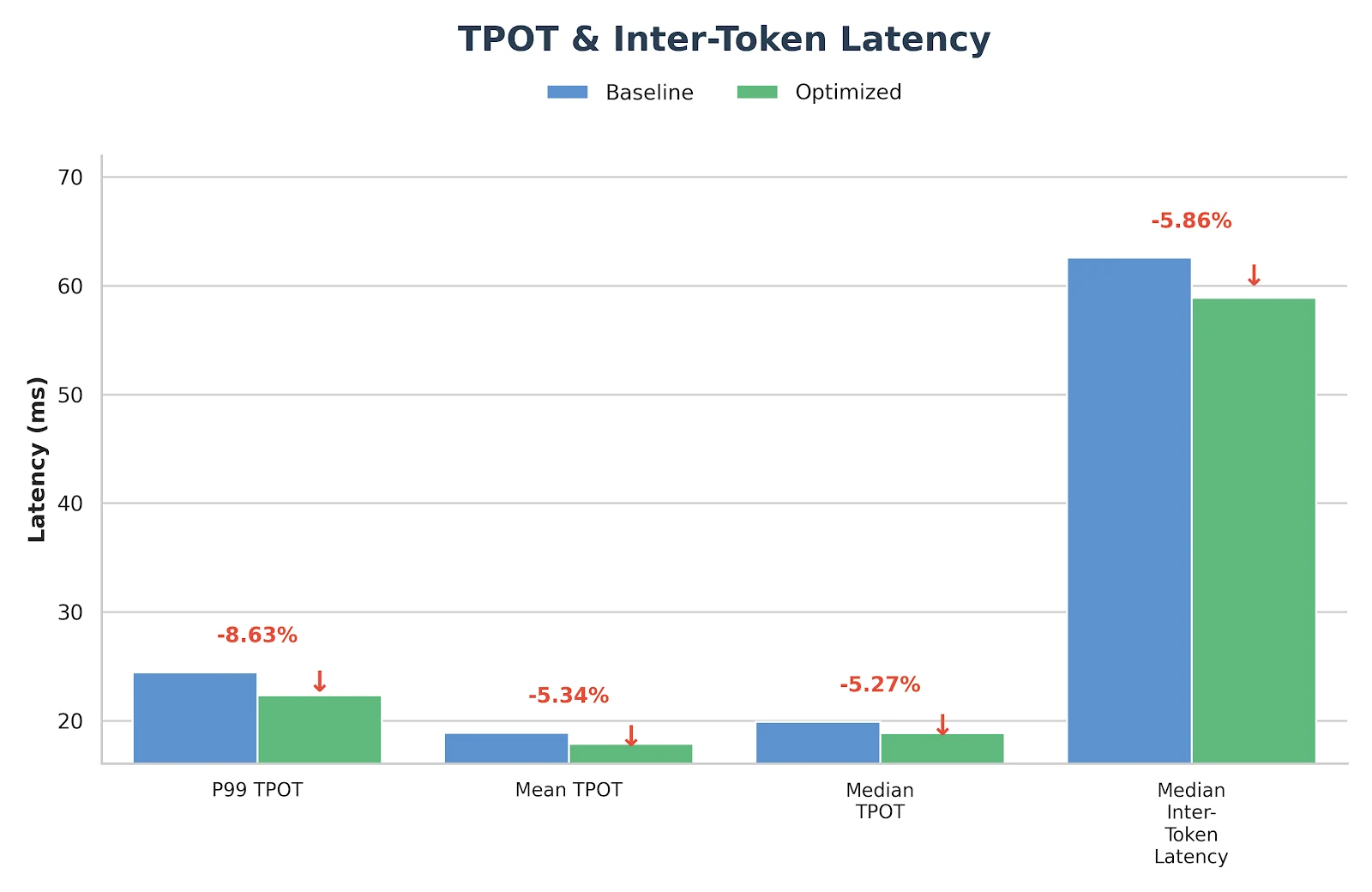
هذه التحسينات ليست تجريبية فقط - بل تم نشرها والتحقق منها بالفعل في خدمة الاستدلال الإنتاجيات لـ Novita.ai. إذا كنت تبحث عن خلفية GLM-MoE موثوقة ذات زمن استجابة منخفض لأحمال العمل الواقعية، فنرحب بك لتجربتها مباشرة على novita.ai.
فك تشفير اللاحقة
تظهر سيناريوهات البرمجة بالوكلاء (مثل Cursor و Claude Code) حجمًا كبيرًا من أنماط الأكواد القابلة لإعادة الاستخدام، مما يسمح بإجراء تحسينات أداء موجهة مثل فك تشفير اللاحقة.
الخلفية: اختناق الاستدلال في البرمجة بالوكلاء
تتفوق وكلاء نماذج اللغة الكبيرة (LLM) في مهام توليد الأكواد، لكن زمن الاستجابة يظل تحديًا كبيرًا. يعمل فك التشفير التخميني التقليدي على تسريع عملية الاستدلال عن طريق التنبؤ بعدة رموز مسبقًا، لكن الأساليب الشائعة تتطلب تدريب نماذج مسودة إضافية، مما يضيف تعقيدات هندسية.
كيف يعمل فك تشفير اللاحقة
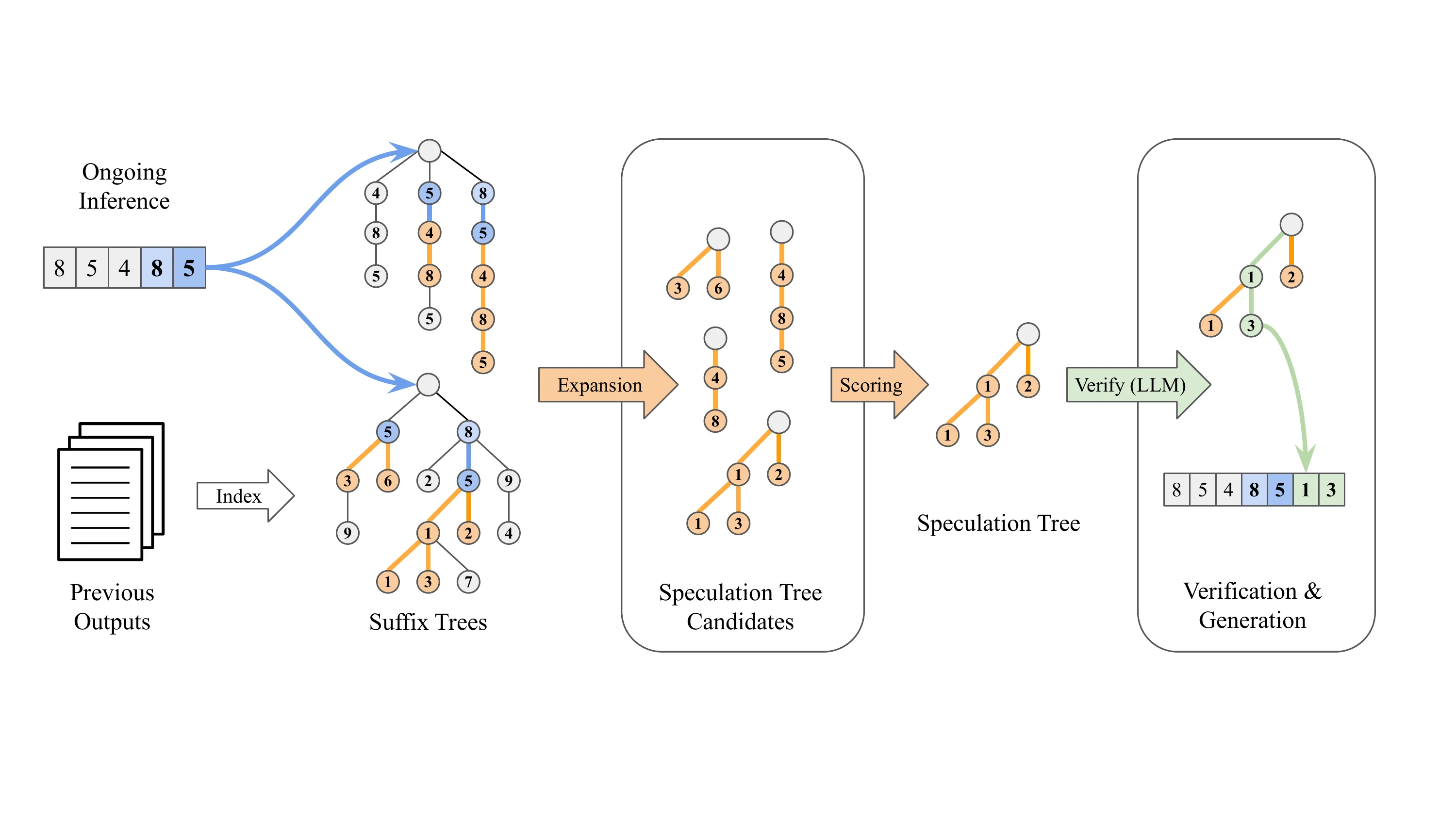
يتبع فك تشفير اللاحقة نهجًا مختلفًا جذريًا - إنه خالٍ تمامًا من النماذج:
- لا يعتمد على أوزان نماذج إضافية
- يستفيد من الأنماط في تسلسلات المخرجات التي تم توليدها مسبقًا للتنبؤ بالرموز القادمة
- عندما تتطابق لاحقة الطلب الحالي مع نمط تاريخي، يستمر في ذلك التسلسل التاريخي للتخمين
التحقق من البيانات: تحليل تكرار أنماط المخرجات
من خلال تحليل 22 جلسة لـ Claude Code (17487 دورة محادثة)، اكتشفنا:
- تكرار أنماط المخرجات بنسبة 39.3%: تكرار عالٍ لاستدعاءات الأدوات المماثلة وأنماط الاستجابة
- سلوكيات الوكلاء شديدة الهيكلة: عبارات ثابتة مثل “دعني…” و “الآن دعني…” تظهر بشكل متكرر
لدعم المزيد من الأبحاث، قمنا بفتح مصدر مجموعة بيانات التقييم على منصة Hugging Face: https://huggingface.co/datasets/novita/agentic_code_dataset_22
مقارنة الأداء
مع تسريع MTP المدمج، يقلل فك تشفير اللاحقة TPOT بنسبة 22% (من 25.13 مللي ثانية إلى 19.63 مللي ثانية):
| المقياس | MTP | فك تشفير اللاحقة | التغيير |
| متوسط TPOT | 25.13 مللي ثانية | 19.63 مللي ثانية | -21.90% |
| وسيط TPOT | 25.95 مللي ثانية | 20.05 مللي ثانية | -22.70% |
الخلاصة
يوفر الجمع بين هذه التحسينات تحسينات شاملة في الأداء لنشرات SGLANG:
- دمج الخبراء المشتركين يعالج كفاءة الحساب في نماذج MoE
- دمج QK-Norm-RoPE يقلل من عبء إطلاق النواة
- النقل غير المتزامن يحسن حركة البيانات في عمليات النشر المفككة
- فك تشفير اللاحقة يستفيد من تكرار الأنماط لفك التشفير التخميني للبرمجة بالوكلاء.
تم دمج معظم المكونات بالفعل في الفرع الرئيسي أو تخضع حاليًا للتكامل؛ لا تتردد في الاطلاع عليها في مستودع SGLang.
كيفية إعادة الإنتاج
يتم عرض المعلمات الرئيسية المتعلقة بالأداء فقط هنا.
تم نشر نصوص إطلاق كاملة (الأساسي مقابل المحسن)، وأدوات معايير الأداء، وتسجيلات التحليل في مستودع GitHub الخاص بنا:https://github.com/novitalabs/sglang/tree/glm\_suffix.
- معلمات التحسين الأساسية (محرك وقت تشغيل SGLang)
--tp-size 8
--kv-cache-dtype fp8_e4m3
--attention-backend fa3
--chunked-prefill-size 16384
--enable-flashinfer-allreduce-fusion
--enable-fused-qk-norm-rope
--enable-shared-experts-fusion
--disaggregation-async-transfer
- تكوين فك التشفير التخميني (أحمال عمل البرمجة بالوكلاء)
--speculative-algorithm NEXTN
--speculative-num-steps 3
--speculative-eagle-topk 1
--speculative-num-draft-tokens 4
- تكوين فك تشفير اللاحقة (اختياري)
--speculative-algorithm SUFFIX
--speculative-suffix-cache-max-depth 64
--speculative-suffix-max-spec-factor 1.0
--speculative-suffix-min-token-prob 0.1
المراجع
- SGLANG PR #13873: تحسين دمج الخبراء المشتركين
- مدونة Snowflake الهندسية: فك تشفير اللاحقة على نطاق الإنتاج
- ورقة NeurIPS: فك تشفير اللاحقة
- مستودع Arctic Inference
Novita AI هي منصة سحابية رائدة للذكاء الاصطناعي توفر للمطورين واجهات برمجة تطبيقات سهلة الاستخدام وبنية تحتية لـ GPU بأسعار معقولة وموثوقة لبناء وتوسيع نطاق تطبيقات الذكاء الاصطناعي.


