

Ключевые моменты
- Высокие затраты на инференс: Инференс крупномасштабных моделей остаётся дорогим, что ограничивает масштабируемость, несмотря на общее снижение стоимости.
- Сложность выбора GPU: Многообразие доступных GPU усложняет процесс выбора, часто приводя к неоптимальным решениям на основе поверхностных метрик.
- Объективная система оценки: Стандартизированный метод оценки помогает выявить экономичные решения GPU, адаптированные к конкретным бизнес‑задачам.
- Показатели производительности: Ориентируйтесь на задержку (время до первого токена) и пропускную способность (токенов в секунду) для оптимизации пользовательского опыта.
- Анализ экономической эффективности: Оценка стоимости за миллион токенов вместе с показателями производительности позволяет чётко разделить решения на эффективные квадранты.
- Реальное тестирование: Тестирование популярных моделей (серия Llama 3.1) на основных GPU (H100, A100, RTX 4090) даёт практические результаты.
- Лучшие практики: Рекомендации по выбору аппаратного обеспечения для инференса и оптимизации движков повышают эффективность и снижают затраты.
- Узнайте больше о Novita AI: Чтобы узнать больше об услугах инференса больших моделей, посетите Novita AI.
Введение
Стоимость инференса крупномасштабных моделей, хотя и постоянно снижается, остаётся весьма высокой, при этом скорость инференса и стоимость использования серьёзно ограничивают масштабируемость операций. Как поставщик услуг инференса больших моделей, мы постоянно вкладываем средства в повышение скорости и снижение затрат.
Мы углублённо изучаем выбор аппаратного обеспечения для инференса и оптимизацию движков, чтобы предлагать клиентам самые экономичные решения. Эта статья посвящена теоретическим методам и лучшим практикам выбора аппаратного обеспечения, а также представляет наши предварительные выводы.
Существует большое разнообразие GPU, доступных для инференса больших моделей, и найти подходящий для конкретных бизнес‑требований непросто. При развёртывании множество GPU часто ставит нас в тупик, и мы прибегаем к статическому сравнению на основе вычислительной мощности, объёма памяти, пропускной способности и цены. Такой подход, основанный на субъективном впечатлении, может ввести в заблуждение и негативно сказаться на бизнесе.
Мы тоже столкнулись с этой проблемой на ранних этапах. Однако по мере роста и расширения бизнеса мы постепенно разработали объективный и беспристрастный стандарт оценки GPU и соответствующие методы оценки. Используя этот стандартизированный подход в многочисленных оценках, мы можем выявить наиболее экономичные решения для разных бизнес‑задач из множества GPU. В сочетании с оптимизированными движками инференса мы в итоге предоставляем клиентам услуги инференса больших моделей, которые являются одновременно быстрыми и экономически эффективными.
Подход к оценке
Проще говоря, «самый экономичный GPU» должен удовлетворять двум критериям: самая низкая цена и самая высокая производительность. Перед началом оценки мы точно определяем эти стандарты.
Определение самой низкой цены
Самая низкая цена — это не стоимость аппаратного обеспечения GPU или аренда облачного сервера в дата-центре, а стоимость услуги инференса. Это цена, которую мы видим на официальном сайте при использовании API модели, определяемая как стоимость за миллион потреблённых токенов (Dollars Per 1M tokens). Чем меньше значение, тем ниже цена.
Понимание самой высокой производительности
Самая высокая производительность относится к скорости инференса больших моделей, где выше — значит лучше. Важно отличать это от производительности модели, которая обычно включает две метрики: задержку и пропускную способность.
Метрики задержки и пропускной способности
- Задержка: Измеряет время до первого токена (TTFT) — время, которое пользователь ждёт от отправки запроса до получения первого токена.
- Пропускная способность: Указывает среднее количество токенов, получаемых в секунду (TPS) после первого токена.
Методология оценки
Чтобы согласовать оценку с бизнес‑требованиями, мы рассматриваем систему инференса как чёрный ящик и рассчитываем задержку и пропускную способность на основе входных и выходных данных системы. Диаграмма ниже иллюстрирует, как рассчитываются задержка и пропускная способность.
Ключевые соображения
- Меньшая задержка и более высокая пропускная способность указывают на лучшую производительность инференса.
- В реальных сценариях пропускная способность значительно важнее задержки.

Управление запросами
В целом, меньшая задержка и более высокая пропускная способность означают лучшую производительность инференса. Однако в реальных сценариях пропускная способность значительно важнее задержки.
Пока задержка остаётся меньше 2 секунд, пользователи не очень чувствительны к ней. Даже ожидание в несколько миллисекунд до появления первого токена не заметно влияет на впечатление.
С другой стороны, изменения пропускной способности сильно влияют на пользовательский опыт, и пользователи предпочитают системы с более высокой пропускной способностью. Поэтому при оценке производительности решений для инференса мы концентрируемся на сравнении пропускной способности, удерживая задержку в приемлемых пределах.
В реальной работе система инференса обрабатывает несколько пользовательских запросов одновременно, чтобы повысить общую нагрузку. Однако уровень параллелизма не должен быть чрезмерным, так как слишком высокая параллельность может ухудшить производительность инференса. Кроме того, длина запросов пользователей и количество возвращаемых токенов также влияют на показатели производительности.
Упрощённые шаблоны оценки
Чтобы извлечь закономерности из сложных бизнес‑сценариев, наш метод оценки соответствующим образом упрощается, оставаясь при этом близким к бизнес‑условиям.
Фиксированные соотношения и длины
Мы устанавливаем фиксированные соотношения и длины для входных и выходных данных запроса, например (1000,100), (3000,300), (5000,500), и точно контролируем длины ввода и вывода при отправке запросов.
Раунды тестирования и расчёт метрик
После подготовки десятков тысяч запросов мы отправляем их на сервер инференса фиксированными пакетами (batch sizes) в раундах тестирования, имитируя множество пользователей, непрерывно отправляющих запросы, и поддерживая стабильный уровень параллелизма в системе инференса.
Метрики производительности
На основе данных каждого раунда тестирования мы вычисляем задержку и пропускную способность для всех запросов и собираем статистику по различным процентильным показателям, таким как P50, P90, P99, чтобы отразить более реалистичную производительность.
Кроме того, мы рассчитываем общую пропускную способность всех входных и выходных токенов в раунде тестирования, объединяем её с затратами на оборудование и получаем цену за миллион токенов для системы инференса.
Анализ экономической эффективности
Следуя этому подходу, мы генерируем несколько наборов тестовых данных с разными длинами ввода‑вывода и размерами пакетов, отправляем их в сервис инференса и вычисляем две ключевые метрики: цену за миллион токенов и количество выходных токенов в секунду (TPS) на один запрос.
Затем мы наносим эти метрики на график, где цена — ось X, а TPS — ось Y. Оценивая больше спецификаций оборудования тем же методом и нанося результаты на график, мы получаем обзор экономической эффективности.
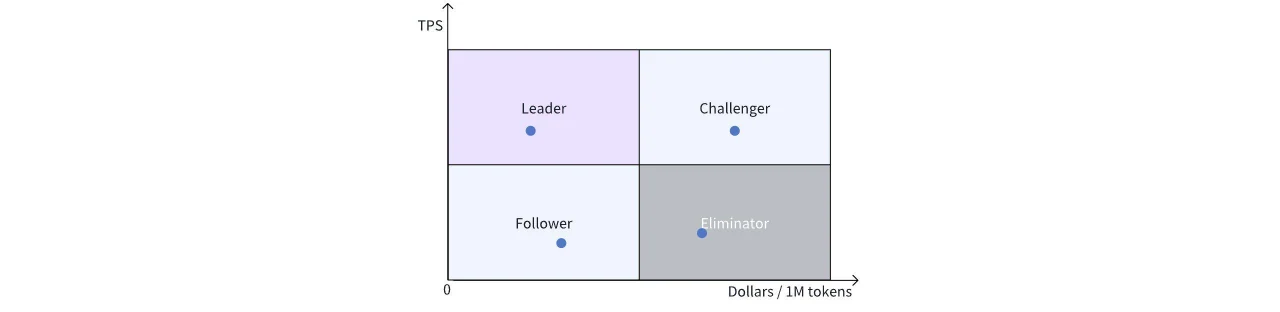
Чтобы облегчить сравнение различных решений, мы делим график на четыре квадранта:
Верхний левый: Квадрант лидеров — самая высокая производительность и самая низкая цена.
Нижний левый: Квадрант последователей — привлекательная цена, но требуется улучшение производительности.
Верхний правый: Квадрант претендентов — лидерство по производительности, но более высокая цена, возможно, из-за передовых и дорогих аппаратных решений; они могут бросить вызов лидерам, если цены снизятся.
Нижний правый: Устаревшие решения, не имеющие преимуществ ни по цене, ни по производительности.
Метод реализации
Наша цель оценки — выявить наиболее экономичное аппаратное обеспечение GPU. Чтобы обеспечить значимость сравнения, мы фиксируем модель, движок инференса и данные запроса, изменяя только аппаратное обеспечение GPU в одинаковых условиях тестирования. Для оценки мы выбираем основные open‑source модели, наборы данных и движки инференса, в основном используя оборудование GPU серии NVIDIA.
Выбор модели
Мы используем модели серии Llama 3.1, конкретно модель Llama 3.1–70B (ссылка на Hugging Face). Этот размер модели обычно требует многопоточного инференса на нескольких GPU, что позволяет оценить производительность меж‑GPU взаимодействия.
Движок инференса
В качестве движка инференса используется vLLM v0.6.3. Для набора данных мы фокусируемся на парах вопрос‑ответ, выбирая ShareGPT-v3-unfiltered как наиболее подходящий вариант. При формировании данных запроса мы проходим по набору данных ShareGPT, фильтруя пары вопрос‑ответ по длине ввода, оставляя только те, которые равны или превышают заданное значение; сохраняем только вопросы (при необходимости обрезая, если слишком длинные) в качестве промпта запроса.
Выбор спецификаций GPU
При выборе спецификаций GPU мы оцениваем основные модели: H100, A100 и RTX 4090, охватывая низкий, средний и высокий сегменты. Распространённый подход — арендовать серверы GPU с конфигурацией из 8 карт в облачных платформах, например на нашем сайте Novita AI, который предлагает удобную оплату по мере использования. Кроме того, мы можем включить больше спецификаций GPU, чтобы расширить область оценки, и в конечном итоге заполнить четыре квадранта разнообразными GPU и стратегиями инференса.
Запуск оценки
После завершения подготовки оценку можно запустить, выполнив следующие шаги:
Шаг 1: Запуск движка инференса
Чтобы запустить движок инференса vLLM на целевом GPU‑сервере, можно быстро создать экземпляр Docker‑контейнера. Для сервера с 8 картами 4090 используйте следующую команду:
docker run -d --gpus all --net=host vllm/vllm-openai:v0.6.3 --port 8080 --model meta-llama/Llama-3.1-70B-Instruct --tensor-parallel-size 8 --swap-space 16 --gpu-memory-utilization 0.9 --dtype auto --served-model-name llama31-70b --max-num-seqs 32 --max-model-len 32768 --enable-prefix-caching --enable-chunked-prefill --disable-log-requests
Шаг 2: Формирование и отправка запросов
На стороне клиента сформируйте запросы на основе длин ввода/вывода и размеров пакетов и отправляйте их массово на сервер. Мы также можем обратиться к встроенным тестовым случаям, предоставленным vLLM, чтобы написать тестовые скрипты, соответствующие нашим требованиям оценки.
Вот ключевые моменты, которые следует учитывать при формировании запросов:
- Фильтрация данных из ShareGPT
При проходе по всем записям разговоров в наборе данных ShareGPT обратите внимание, что первый элемент каждого разговора — это вопрос, а второй — соответствующий ответ. Вам нужен только вопрос в качестве промпта для запросов.
Чтобы количество токенов в вопросе соответствовало требованиям по длине ввода, возможно, потребуется обрезать вопрос. Кроме того, в списке параметров каждого запроса установите max_tokens равным указанной длине вывода и ignore_eos в true, чтобы принудить движок инференса вывести указанное количество токенов.
- Постоянный размер пакета
В каждом раунде тестирования всегда поддерживайте один и тот же размер пакета. Для этого клиент должен отправлять фиксированное количество запросов параллельно и немедленно отправлять новый запрос, как только один завершается. Это обеспечивает постоянство условий тестирования и позволяет точно измерить производительность.
Параметры каждого запроса можно настроить следующим образом:
{
"model": "llama31-70b",
"prompt": prompt_content,
"temperature": 0.8,
"top_p": 1.0,
"best_of": 1,
"max_tokens": output_len,
"ignore_eos": true
}
Шаг 3: Сбор данных метрик
После завершения всех запросов необходимо собрать следующие ключевые метрики:
- Для каждого запроса: Задержка первого токена (TTFT) = First_Token_Time — Send_Req_Time
- Для каждого запроса: Токенов в секунду (TPS) = Total_Output_Tokens / (Finish_Req_Time — First_Token_Time)
- Для раунда тестирования: Общая пропускная способность системы = Sum(Input_Tokens_Per_Req + Output_Tokens_Per_Req) / Total_Seconds
Где TTFT и TPS относятся к каждому запросу; для удобства расчётов можно использовать P90 процентиль всех запросов в раунде тестирования.
Общая пропускная способность системы указывает общее количество токенов (включая как входные, так и выходные токены), которое сервис инференса может обработать в секунду. Разделив цену соответствующего GPU‑сервера на общую пропускную способность, можно получить стоимость за миллион токенов.
В реальных сценариях утилизация сервера и колебания запросов также могут влиять на пропускную способность; можно применить коэффициент для учёта этих влияний, хотя это обычно не влияет на выводы оценки.
Ключевые результаты по производительности GPU и экономической эффективности
Мы провели углублённую оценку основных GPU (H100, A100, RTX 4090), используя описанные выше методы тестирования. Для каждого GPU мы рассчитали показатели производительности (TTFT, TPS) при различных длинах ввода/вывода и размерах пакетов, получив процентили P50, P90 и P99. Мы также учли цены аренды популярных облачных платформ GPU (доступны на Novita AI), чтобы рассчитать стоимость за миллион токенов. Эти данные послужат основой для дальнейшей оценки стоимости и производительности и приведут нас к окончательным выводам.
Сравнение производительности одиночного инференса
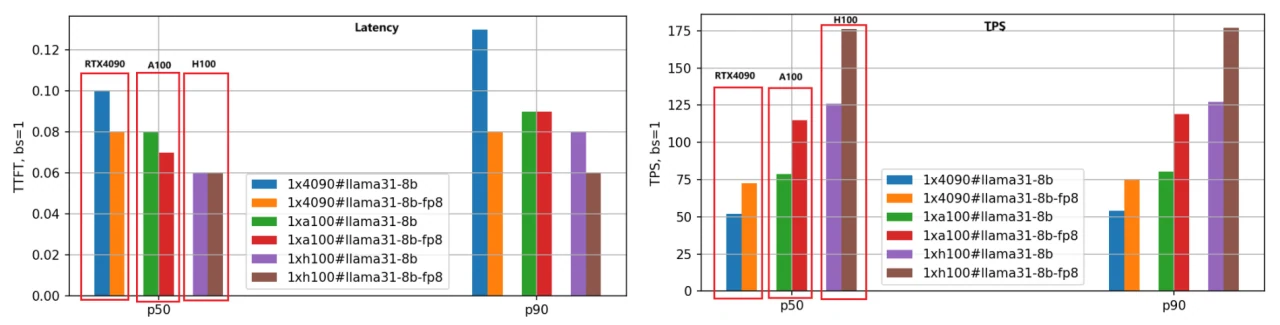
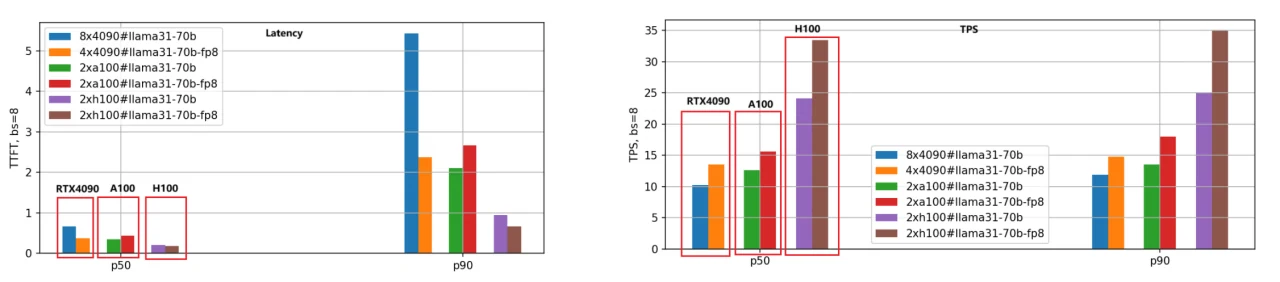
Основное внимание уделяется задержке (время до первого токена) и пропускной способности (токенов в секунду). Меньшая задержка — лучше, более высокий TPS — желателен. Мы оценили как версии BF16, так и FP8 моделей Llama-3.1–8B и Llama-3.1–70B на трёх GPU, установив длину ввода/вывода каждого запроса равной 5000/500 и тестируя разные размеры пакетов. Ниже приведены результаты сравнения производительности для модели Llama-3.1–8B с использованием данных P50.
- Задержка первого токена:
Рейтинг скорости от самого быстрого к самому медленному: H100, A100, RTX 4090. При размере пакета, равном 1, скорость A100 в 1,25 раза выше, чем у RTX 4090, а H100 — в 1,66 раза быстрее.
С увеличением размера пакета разрыв между RTX 4090 и двумя другими GPU значительно увеличивается. При размере пакета 10 задержка RTX 4090 превышает 3,5 секунды (P90 процентиль), что неприемлемо для многих бизнес‑приложений. Напротив, A100 и H100 сохраняют задержку ниже 0,5 секунды, демонстрируя стабильную производительность.
2. Токенов в секунду (TPS):
Эта метрика отражает скорость генерации движка; рейтинг скорости тот же: H100, A100, RTX 4090. При размере пакета 1 TPS A100 примерно в 1,48 раза выше, чем у RTX 4090, а TPS H100 в 2,44 раза выше, чем у RTX 4090, что указывает на самую высокую эффективность генерации у H100.
При увеличении размера пакета TPS для отдельных запросов постепенно снижается из-за возросшей нагрузки на систему и уменьшения ресурсов на запрос. При размере пакета 10 TPS падает примерно до 70% от TPS при размере пакета 1.
3. Квантование модели FP8:
Версия FP8, где файлы весов вдвое меньше по сравнению с BF16, значительно снижает нагрузку на системные ресурсы, что приводит к улучшению задержки и пропускной способности. Вторая группа столбчатых диаграмм наглядно иллюстрирует этот вывод, особенно по метрике TPS, где производительность версии FP8 примерно в 1,4 раза выше, чем у версии BF16 на том же GPU.
4. Чувствительность RTX 4090 к размеру пакета:
Из-за ограничений памяти и коммуникации RTX 4090 очень чувствителен к размеру пакета. Чрезмерно большие размеры пакетов могут привести к внутренним очередям, что вызовет более высокую задержку и снижение пропускной способности. При развёртывании рабочих нагрузок на RTX 4090 необходимо уделять особое внимание настройке размера пакета.
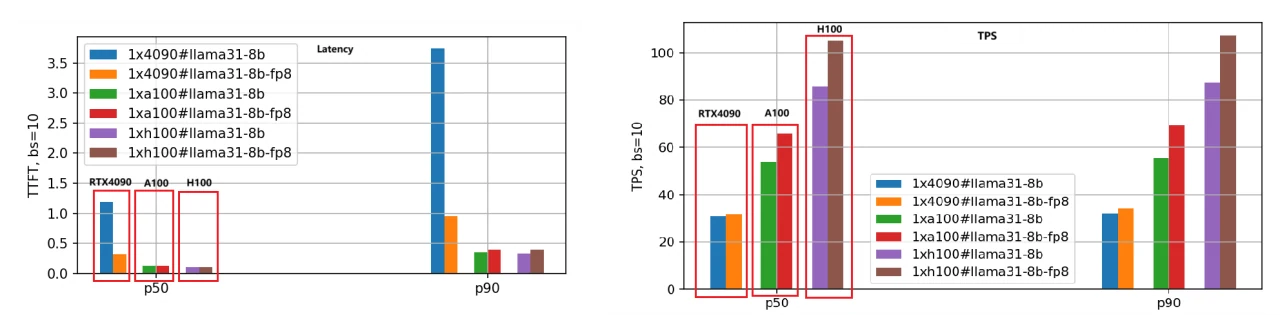
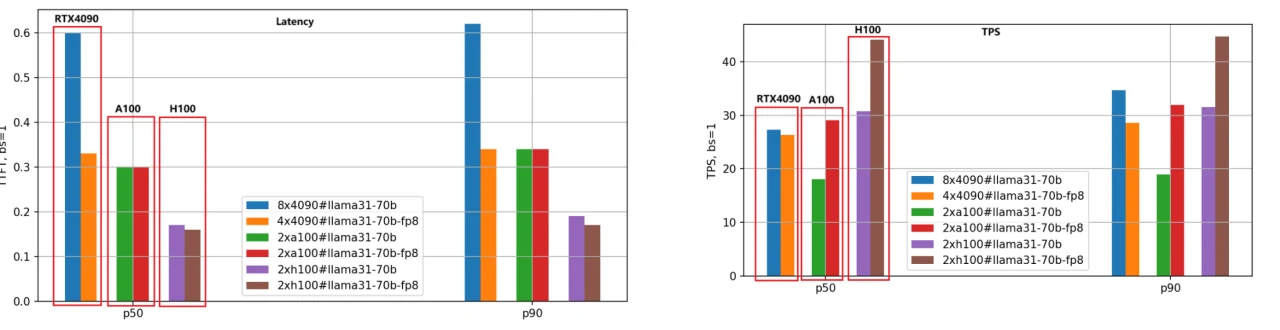
Мы применили тот же метод оценки для модели Llama-3.1–70B; сравнение производительности показано на следующем рисунке.
Учитывая большой размер модели 70B, мы использовали 8 GPU RTX 4090 для версии BF16 и 4 GPU RTX 4090 для версии FP8. Напротив, GPU A100 и H100, обладающие 80 ГБ памяти, требовали всего 2 единицы для эффективной работы.
Из рисунка мы можем сделать выводы, аналогичные выводам для модели Llama-3.1–8B: H100 остаётся самым производительным GPU, а версия с квантованием FP8 примерно в 1,4 раза быстрее версии BF16.
Комплексная оценка стоимости и производительности
При практическом развёртывании необходимо учитывать не только показатели производительности, но и общую стоимость решений, чтобы выявить наилучшее соотношение цены и производительности.
Например, хотя RTX 4090 может быть медленнее по производительности, его очень низкая цена может сделать общую экономическую эффективность конкурентоспособной. Для этого необходимы более научные и профессиональные методы оценки, чтобы точно определить, какой GPU и какое решение для инференса обеспечивают наилучшее соотношение цены и качества.
В нашем «Подходе к оценке» мы предлагаем наносить затраты и показатели производительности различных решений на двумерную систему координат, разделяя пространство на четыре квадранта: лидеры, последователи, претенденты и устаревшие. Следуя этому подходу, мы сосредоточились на тестировании моделей Llama-3.1–70B, Llama-3.1–8B и их версий с квантованием FP8.
Мы выбрали четыре GPU: RTX 4090, A100, H100 и H200, установив длину ввода/вывода 5000/500 и размеры пакетов от 1 до 10. Мы протестировали различные комбинации, получили данные о производительности и цене, которые в итоге были нанесены на два рисунка ниже.
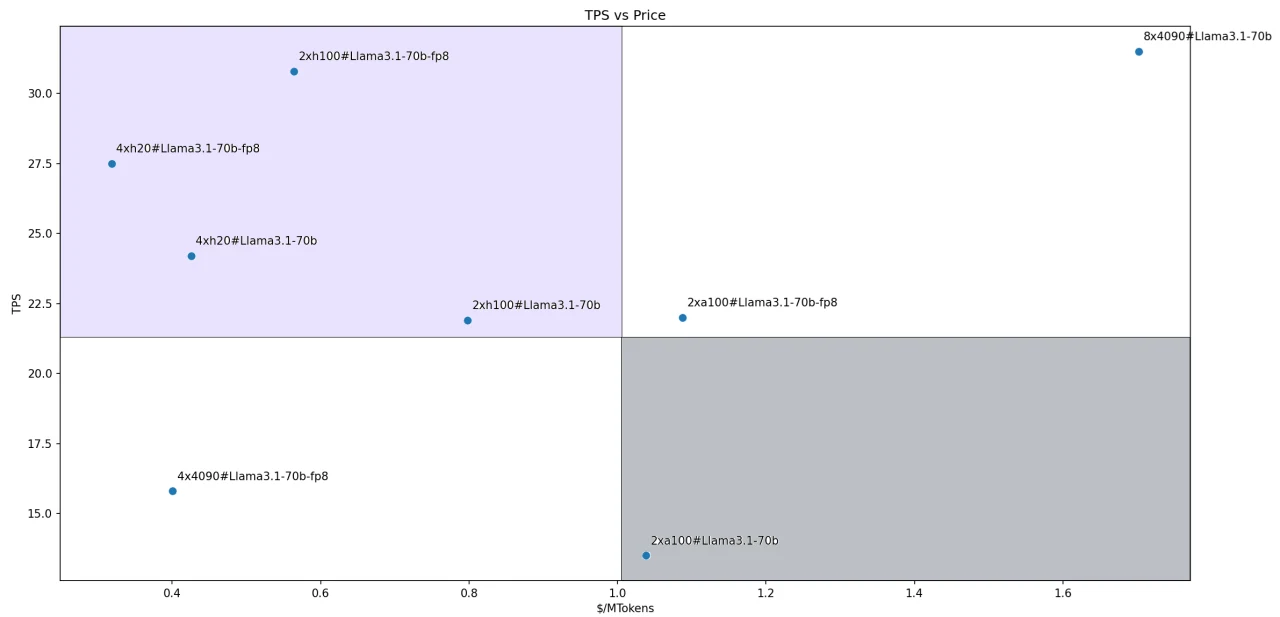
Для модели Llama-3.1–70B соотношение цены и производительности каждого решения показано на рисунке. Четыре решения попадают в определённый нами квадрант лидеров:
- Llama3.1–70B-FP8@2xH100
- Llama3.1–70B-FP8@4xH200
- Llama3.1–70B@4xH200
- Llama3.1–70B@2xH100
На рисунке наклон линии, соединяющей координатную точку каждого решения с началом координат, представляет отношение производительности к цене. Чем круче наклон, тем выше соотношение цены и производительности.
Следовательно, решение Llama3.1–70B-FP8@4xH200 оказывается наиболее экономически эффективным вариантом среди всех оценённых решений для инференса.
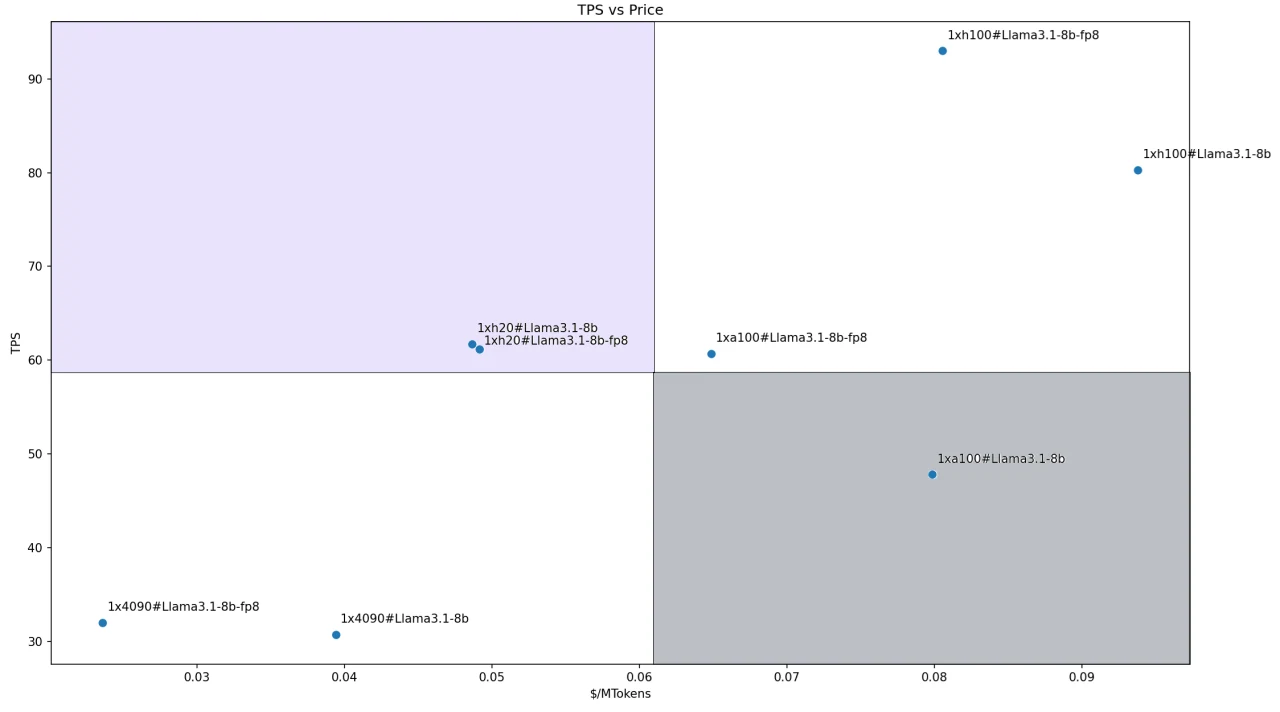
Для модели Llama3.1–8B из-за её меньшего размера мы развернули все модели, используя конфигурацию с одним GPU. Соотношение цены и производительности различных решений показано на рисунке ниже. Обе конфигурации с H200 попадают в определённый нами квадрант лидеров.
Это в основном связано с хорошей производительностью H200 (особенно его ведущим объёмом памяти и пропускной способностью) и конкурентоспособной ценой. Две конфигурации с RTX 4090 являются наиболее экономически эффективными, но из-за их худшей производительности они попадают в квадрант последователей.
Заключение
Затраты на GPU составляют значительную часть услуг инференса больших моделей, а из-за множества доступных на рынке аппаратных решений GPU выбор наиболее подходящего может быть сложной задачей. Выявление наилучшего соотношения цены и производительности GPU и решения для инференса, адаптированного к конкретным бизнес-задачам, имеет решающее значение, поскольку это может определить успех или неудачу бизнеса.
Благодаря нашему опыту предоставления услуг инференса больших моделей мы накопили значительные знания в области развёртывания и разработали эффективную систему оценки GPU, которая постоянно направляет развитие бизнеса, предлагая клиентам услуги инференса с наилучшим соотношением цены и производительности.
Эта статья обобщает лучшие практики, полученные из практического применения, проводит реальные тесты на основных больших моделях и спецификациях GPU, предоставляя сравнение производительности для выявления наилучших решений для инференса с точки зрения цены и производительности.
Наш подход к оценке выходит за рамки сложных аппаратных метрик, фокусируясь на практическом применении в бизнесе, что делает его высоко обобщаемым и применимым — особенно подходит для сравнительного тестирования различных моделей GPU или движков инференса.
Посетите Novita AI для получения дополнительной информации о первоклассных услугах и решениях для инференса больших моделей!
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей с помощью нашего простого API, а также предлагает доступные и надёжные GPU-облака для создания и масштабирования.
Рекомендуемое чтение
1.Как KV Sparsity обеспечивает ускорение в 1,5 раза для vLLM
2.Динамическое выделение GPU-ресурсов для рабочих нагрузок Kubernetes
3.Динамическое добавление сопоставлений портов в работающие Docker-контейнеры


