

主要なポイント
- 高い推論コスト:大規模モデルの推論は、全体コストが低下傾向にあるにもかかわらず依然として高額であり、スケーラビリティを制限しています。
- GPU選択の課題:利用可能なGPUの多様性により選択プロセスが複雑化し、表面的な指標に基づく最適でない選択につながりがちです。
- 客観的な評価フレームワーク:標準化された評価方法により、特定のビジネスニーズに合わせた費用対効果の高いGPUソリューションを特定できます。
- パフォーマンス指標:レイテンシ(最初のトークンまでの時間)とスループット(1秒あたりのトークン数)に注目し、ユーザー体験を最適化します。
- 費用対効果分析:100万トークンあたりのコストをパフォーマンス指標とともに評価することで、ソリューションを明確な象限に分類できます。
- 実際のテスト:人気モデル(Llama 3.1シリーズ)を主要GPU(H100、A100、RTX 4090)でテストし、実用的な洞察を得ます。
- ベストプラクティス:推論ハードウェアの選択とエンジン最適化に関する推奨事項により、効率を向上させコストを削減します。
- Novita AIを探索:大規模モデル推論サービスの詳細は、Novita AIをご覧ください。
はじめに
大規模モデル推論のコストは継続的に低下しているものの、依然として非常に高く、推論速度と使用コストが運用のスケーラビリティを著しく制限しています。大規模モデル推論サービスのプロバイダーとして、私たちは推論速度の向上と推論コストの削減に継続的に投資しています。
私たちは、推論ハードウェアの選択と推論エンジンの最適化を探求し、クライアントに最も費用対効果の高い推論ソリューションを提供することに注力しています。この記事では、推論ハードウェアを選択するための理論的方法とベストプラクティスを紹介し、予備的な結論を示します。
大規模モデル推論に利用できるGPUは多種多様であり、特定のビジネス要件に適したものを見つけるのは困難です。運用を展開する際、多くのGPUに困惑し、GPUの計算能力、メモリ容量、帯域幅、価格などの指標に基づいた静的な比較に陥りがちです。主観的に「見た目が良い」という理由でGPUを選択するこのアプローチは、大きな誤解を招き、ビジネスに悪影響を及ぼす可能性があります。
私たちも初期の段階でこの問題に直面しました。しかし、ビジネスの成長と拡大に伴い、客観的で公平なGPU評価基準と対応する評価方法を徐々に開発してきました。この標準化されたアプローチを数多くの評価に適用することで、多様なGPUの中からさまざまなビジネスニーズに最適な費用対効果の高いソリューションを特定できます。さらに、最適化された推論エンジンと組み合わせることで、最終的にクライアントに高速かつ費用対効果の高い大規模モデル推論サービスを提供します。
評価アプローチ
簡単に言えば、「最も費用対効果の高いGPU」は、最低価格と最高パフォーマンスの2つの条件を満たす必要があります。評価を開始する前に、これらの基準を正確に定義します。
最低価格の定義
最低価格とは、GPUハードウェアのコストやデータセンターでのクラウドサーバーリースではなく、推論サービスのコストです。これは、Model APIを使用する際に公式ウェブサイトに表示される価格であり、消費された100万トークンあたりのコスト(Dollars Per 1M tokens)として定義されます。値が低いほど価格が低いことを意味します。
最高パフォーマンスの理解
最高パフォーマンスとは、大規模モデル推論の速度を指し、高いほど良いです。これはモデルパフォーマンスとは区別する必要があり、通常、レイテンシとスループットの2つのサブ指標が含まれます。
レイテンシとスループットの指標
- レイテンシ:最初のトークンまでの時間(TTFT)を測定します。ユーザーがリクエストを開始してから最初のトークンを受け取るまでの待ち時間です。
- スループット:最初のトークン以降に1秒あたりに受け取る平均トークン数(TPS)を示します。
評価方法
評価をビジネスニーズに合わせるため、評価中は推論システムをブラックボックスとして扱い、システムの入力と出力に基づいてレイテンシとスループットを計算します。以下の図は、レイテンシとスループットの計算方法を示しています。
重要な考慮事項
- レイテンシが低く、スループットが高いほど、推論パフォーマンスが優れていることを示します。
- 実際のシナリオでは、スループットはレイテンシよりもはるかに重要です。

リクエスト管理
一般的に、レイテンシが低くスループットが高いほど、推論パフォーマンスは優れています。しかし、実際のシナリオでは、スループットはレイテンシよりもはるかに重要です。
レイテンシが2秒未満であれば、ユーザーはそれほど敏感ではありません。最初のトークンを見るまでに数ミリ秒待っても、体験に顕著な影響はありません。
一方、スループットの変化はユーザー体験に大きな影響を与えるため、ユーザーはスループットの高いシステムを好みます。したがって、推論ソリューションのパフォーマンス指標を評価する際には、レイテンシを許容範囲内に保ちつつ、スループットの違いを比較することに焦点を当てます。
実際の運用では、推論システムは複数のユーザーリクエストを同時に処理し、システム全体の負荷を高めます。ただし、同時実行性が高すぎると、実際には推論パフォーマンスが低下する可能性があります。また、ユーザーリクエストの長さや返されるトークン数もパフォーマンス指標に影響を与えます。
簡略化された評価パターン
複雑なビジネスシナリオからパターンを抽出するために、私たちの評価方法はビジネス設定に密接に沿いながら、適切に簡略化します。
固定比率と長さ
リクエストの入力と出力に固定の比率と長さを設定します。例えば、(1000,100)、(3000,300)、(5000,500)などです。リクエスト送信時には、入力と出力の長さを正確に制御します。
テストラウンドと指標の計算
数万のリクエストを準備した後、固定バッチサイズで推論サーバーにリクエストを送信し、テストラウンドを実行します。これにより、多数のユーザーが継続的にリクエストを送信し、推論システムで安定した同時実行レベルを維持するシミュレーションを行います。
パフォーマンス指標
各テストラウンドのデータに基づき、すべてのリクエストのレイテンシとスループット指標を計算し、P50、P90、P99などのパーセンタイル指標の統計を収集して、より現実的なパフォーマンスを反映させます。
また、テストラウンド内のすべての入力トークンと出力トークンの総スループットを計算し、それをハードウェアコストと組み合わせて、推論システムの100万トークンあたりの価格を導き出します。
費用対効果分析
この評価アプローチに従い、さまざまな入出力長とバッチサイズに基づいて複数のテストデータセットを生成し、推論サービスに送信して、100万トークンあたりの価格とリクエストあたりの1秒あたりの出力トークン率(TPS)という2つの主要指標を計算します。
次に、これらの指標を価格をx軸、TPSをy軸としたグラフにプロットします。同じ方法でより多くのハードウェア仕様を評価し、結果をグラフにプロットすることで、費用対効果の全体像を作成します。
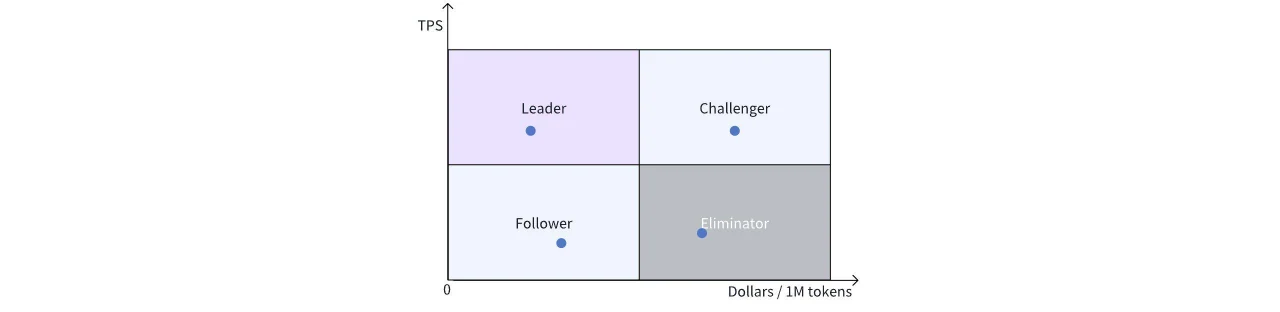
異なるソリューション間の比較を容易にするために、グラフを4つの象限に分割します。
左上:リーダー象限、最高のパフォーマンスと最低の価格。
左下:フォロワー象限、魅力的な価格だがパフォーマンスの向上が必要。
右上:チャレンジャー象限、パフォーマンスでリードするが価格が高い、最先端で高価なハードウェアソリューションが該当し、価格が下がればリーダーに挑戦できる可能性がある。
右下:時代遅れのソリューション、価格とパフォーマンスの両方で優位性がない。
実装方法
私たちの評価目標は、最も費用対効果の高いGPUハードウェアを特定することです。意味のある比較を確実にするために、モデル、推論エンジン、リクエストデータを固定し、同じテスト条件下でGPUハードウェアのみを変更します。評価では、主流のオープンソースモデル、データセット、推論エンジンを選択し、主にNVIDIAシリーズのGPUハードウェアを使用します。
モデル選択
Llama 3.1シリーズモデル、具体的にはLlama 3.1–70Bモデル(Hugging Faceリンク)を使用します。このモデルサイズは通常、複数GPUでの推論を必要とするため、GPU間通信パフォーマンスの評価に適しています。
推論エンジン
推論エンジンはvLLM v0.6.3を使用します。データセットとしては、QAペアに焦点を当て、ShareGPT-v3-unfilteredが最も適切な選択肢です。リクエストデータを構築する際、ShareGPTデータセットを反復処理し、入力長に基づいてQAペアをフィルタリングし、指定された値以上であるもののみを保持します。質問のみを(長すぎる場合は適切にトリミングして)リクエストプロンプトとして使用します。
GPU仕様の選択
GPU仕様を選択する際、低・中・高の各カテゴリからH100、A100、RTX 4090という主流のGPUを評価します。一般的なアプローチは、クラウドプラットフォーム(当社のウェブサイトNovita AIなど)で8枚構成のGPUサーバーをレンタルすることです。Novita AIでは便利な従量課金オプションを提供しています。また、評価範囲を広げるために、より多くのGPU仕様を含めることもあり、最終的にはさまざまなGPUと推論戦略で4つの象限を埋めることを目指します。
評価の開始
準備が整ったら、以下の手順に従って評価を開始できます。
ステップ1:推論エンジンを起動する
対象のGPUサーバーでvLLM推論エンジンを起動するには、Dockerコンテナインスタンスを迅速に作成します。8枚の4090 GPUサーバーの場合、以下のコマンドを使用します。
docker run -d --gpus all --net=host vllm/vllm-openai:v0.6.3 --port 8080 --model meta-llama/Llama-3.1-70B-Instruct --tensor-parallel-size 8 --swap-space 16 --gpu-memory-utilization 0.9 --dtype auto --served-model-name llama31-70b --max-num-seqs 32 --max-model-len 32768 --enable-prefix-caching --enable-chunked-prefill --disable-log-requests
ステップ2:リクエストを構築して送信する
クライアント側で、入出力長とバッチサイズに基づいてリクエストを構築し、一括でサーバーに送信します。また、vLLM が提供する組み込みテストケースを参照して、評価要件を満たすテストスクリプトを作成することもできます。
リクエスト構築時の重要なポイントは以下の通りです。
- ShareGPTからのデータフィルタリング
ShareGPTデータセット内のすべての会話エントリを反復処理する際、各会話の最初の要素が質問、2番目の要素が対応する回答であることに注意してください。リクエストのプロンプトには質問のみが必要です。
質問内のトークン数が入力長要件を満たすようにするために、質問を適切にトリミングする必要がある場合があります。また、各リクエストのパラメータリストで、max_tokens を指定された出力長に設定し、ignore_eos を true に設定して、推論エンジンが指定されたトークン数を強制的に出力するようにします。
- 一貫したバッチサイズ
各テストラウンドでは、常に同じバッチサイズを維持します。これを実現するために、クライアントは固定数のリクエストを並行して送信し、1つのリクエストが完了したらすぐに次のリクエストを再送信します。これにより、テスト条件が一貫して保たれ、正確なパフォーマンス測定が可能になります。
各リクエストのパラメータは次のように設定できます。
{
"model": "llama31-70b",
"prompt": prompt_content,
"temperature": 0.8,
"top_p": 1.0,
"best_of": 1,
"max_tokens": output_len,
"ignore_eos": true
}
ステップ3:指標データを収集する
すべてのリクエストが完了したら、以下の主要な指標を収集します。
- 各リクエストについて:最初のトークンのレイテンシ(TTFT)= First_Token_Time — Send_Req_Time
- 各リクエストについて:1秒あたりのトークン数(TPS)= Total_Output_Tokens / (Finish_Req_Time — First_Token_Time)
- テストラウンドについて:システム全体のスループット = Sum(Input_Tokens_Per_Req + Output_Tokens_Per_Req) / Total_Seconds
TTFTとTPSは各リクエストに関するものであり、計算を容易にするために、1つのテストラウンドにおけるすべてのリクエストのP90パーセンタイルを使用できます。
システム全体のスループットは、推論サービスが1秒あたりに処理できるトークンの総数(入力トークンと出力トークンの両方を含む)を示します。対応するGPUサーバーの価格を総スループットで割ることで、100万トークンあたりのコストを導き出せます。
実際のシナリオでは、サーバーの利用率やリクエストの変動もスループットに影響を与える可能性があり、これらの影響を考慮するための係数を適用できますが、通常は評価の結論に影響しません。
GPUのパフォーマンスと費用対効果に関する主な発見
前述のテスト方法を用いて、主要なGPU(H100、A100、RTX 4090)の詳細な評価を実施しました。各GPUについて、さまざまな入出力長とバッチサイズでのパフォーマンス指標(TTFT、TPS)を計算し、P50、P90、P99パーセンタイルを導き出しました。また、主要なGPUクラウドプラットフォームのレンタル価格(Novita AI で入手可能)を参照し、100万トークンあたりのコストを計算しました。このデータは、さらなる費用対効果評価の基礎となり、最終的な評価結論へと導きます。
単一推論パフォーマンス比較
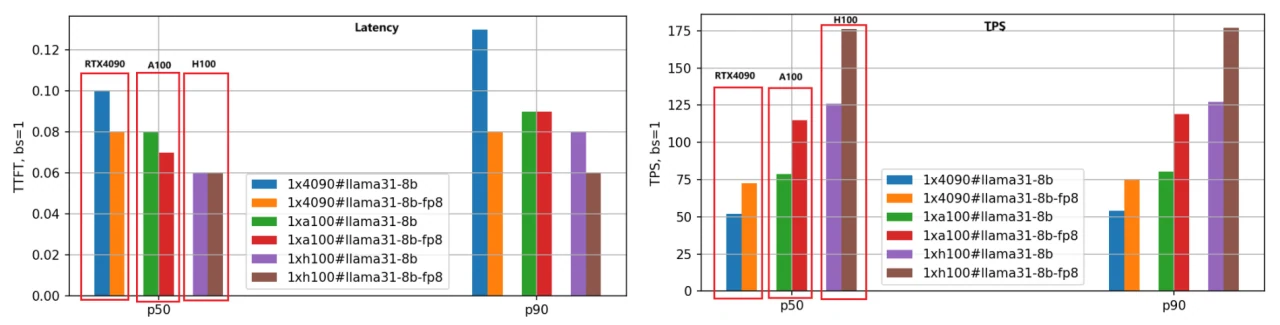
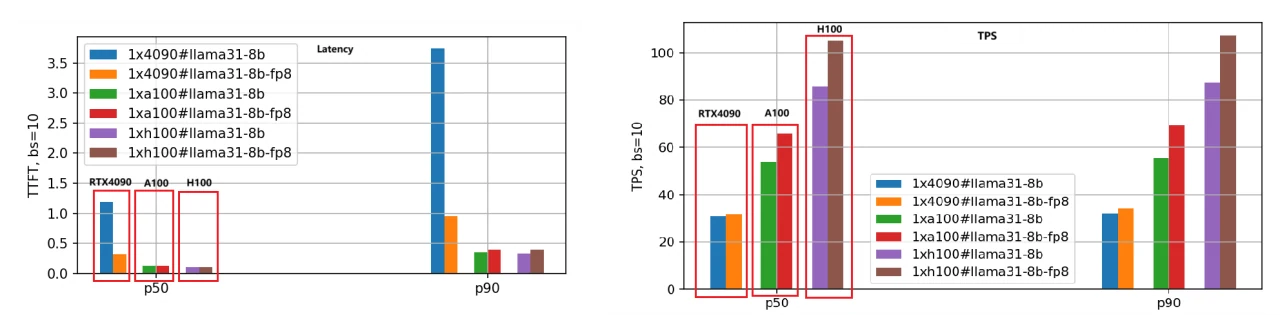
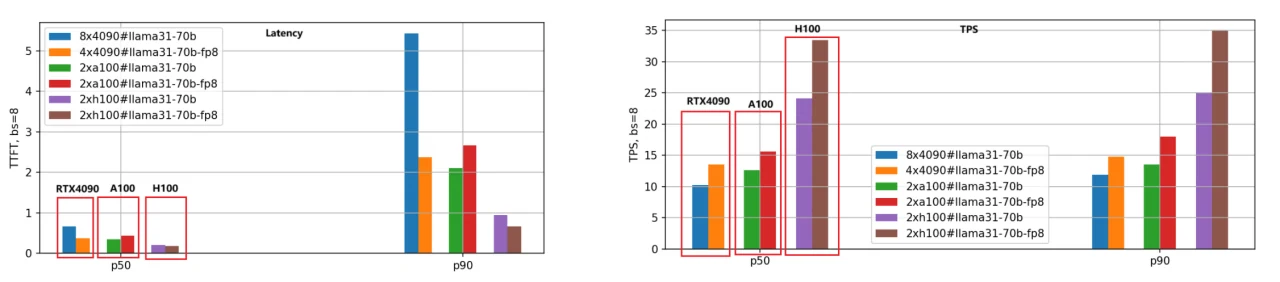
主な焦点は、レイテンシ(最初のトークンのレイテンシ)とスループット(1秒あたりのトークン数)です。レイテンシは低いほど良く、TPSは高いほど望ましいです。Llama-3.1–8BおよびLlama-3.1–70BモデルのBF16版とFP8版を3つのGPUで評価し、各リクエストの入出力長を5000/500に設定し、さまざまなバッチサイズでテストしました。以下は、Llama-3.1–8Bモデルのパフォーマンス比較結果であり、P50データを分析に使用しています。
- 最初のトークンのレイテンシ:
速度の順位は速い順にH100、A100、RTX 4090です。バッチサイズを1に設定した場合、A100の速度はRTX 4090の1.25倍、H100は1.66倍高速です。
バッチサイズが大きくなるにつれて、RTX 4090と他の2つのGPUとの差は顕著に広がります。バッチサイズが10に達すると、RTX 4090のレイテンシは3.5秒(P90パーセンタイル)を超え、多くのビジネスアプリケーションにとって許容できなくなります。対照的に、A100とH100は0.5秒未満のレイテンシを維持し、安定したパフォーマンスを示しています。
2. 1秒あたりのトークン数(TPS):
この指標はエンジンの生成速度を反映し、速度の順位は同じくH100、A100、RTX 4090です。バッチサイズ1の場合、A100のTPSはRTX 4090の約1.48倍、H100のTPSはRTX 4090の2.44倍であり、H100が最も高い生成効率を示しています。
バッチサイズが大きくなるにつれて、個々のリクエストのTPSは徐々に低下します。これはシステム負荷の増加とリクエストあたりのリソース減少によるものです。バッチサイズが10の場合、TPSはバッチサイズ1のTPSの約70%に低下します。
3. FP8モデル量子化:
FP8版は、BF16と比較して重みファイルが半分になり、システムリソースのオーバーヘッドが大幅に削減されるため、レイテンシとスループットが向上します。2番目の棒グラフのセットはこの結論を明確に示しており、特にTPS指標では、同じGPUの場合、FP8版のパフォーマンスはBF16版の約1.4倍です。
4. RTX 4090のバッチサイズに対する感度:
メモリと通信の制限により、RTX 4090はバッチサイズに非常に敏感です。バッチサイズが大きすぎると内部キューイングが発生し、レイテンシが高くなりスループットが低下します。RTX 4090にワークロードをデプロイする際には、バッチサイズの設定に特に注意する必要があります。
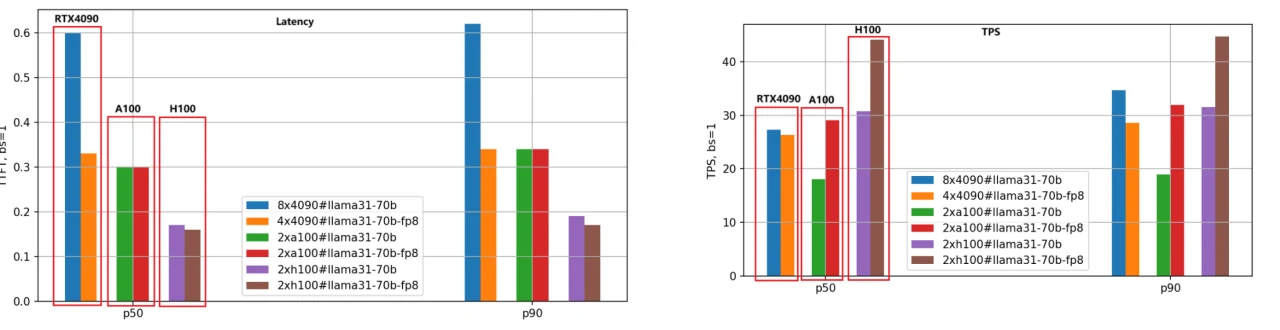
Llama-3.1–70Bモデルにも同じ評価方法を適用し、パフォーマンス比較を次の図に示します。
70Bモデルはサイズが大きいため、BF16版には8枚のRTX 4090 GPU、FP8版には4枚のRTX 4090 GPUを使用しました。一方、A100とH100 GPUは80GBのメモリを搭載しており、2枚で効果的に動作します。
図から、Llama-3.1–8Bモデルと同様の結論が得られます。H100は依然として最高パフォーマンスのGPUであり、FP8量子化版はBF16版よりも約1.4倍高速です。
総合的な費用対効果評価
実際のデプロイでは、パフォーマンス指標だけでなく、ソリューションの総コストも考慮して、最適な費用対効果比を特定する必要があります。
例えば、RTX 4090はパフォーマンス面では遅いかもしれませんが、価格が非常に低いため、全体的な費用対効果は競争力を持つ可能性があります。これを達成するには、どのGPUと推論ソリューションが最良の価値を提供するかを正確に判断するために、より科学的で専門的な評価方法が必要です。
「評価アプローチ」では、異なる推論ソリューションのコストとパフォーマンス指標を2次元座標系にプロットし、空間をリーダー、フォロワー、チャレンジャー、イリミネーターの4つの象限に分割することを提案しました。このアプローチに従い、Llama-3.1–70B、Llama-3.1–8BモデルとそのFP8量子化版のテストに焦点を当てました。
RTX 4090、A100、H100、H200の4つのGPUを選択し、入出力長を5000/500、バッチサイズを1から10に設定しました。さまざまな組み合わせをテストしてパフォーマンスと価格データを取得し、最終的に以下の2つの図にプロットしました。
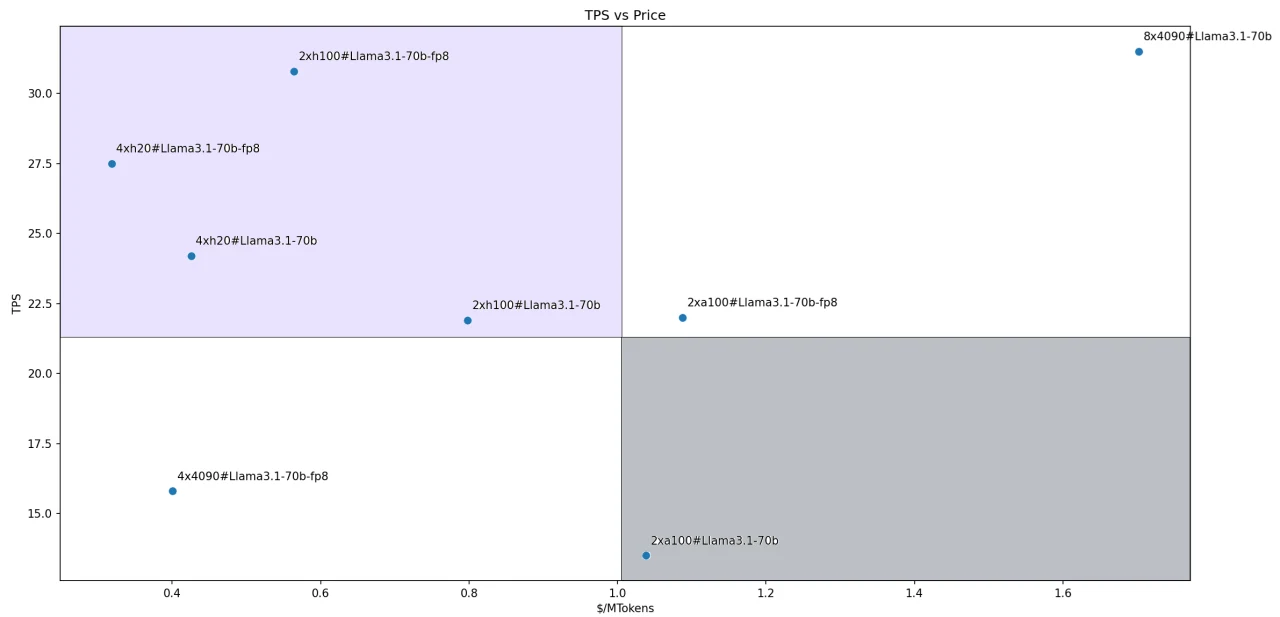
Llama-3.1–70Bモデルの場合、各ソリューションの費用対効果比を次の図に示します。4つのソリューションが、私たちが定義したリーダー象限に該当します。
- Llama3.1–70B-FP8@2xH100
- Llama3.1–70B-FP8@4xH200
- Llama3.1–70B@4xH200
- Llama3.1–70B@2xH100
図では、各ソリューションの座標点と原点を結ぶ線の傾きが、パフォーマンスと価格の比率を表します。傾きが急であるほど、費用対効果比が高いことを示します。
したがって、Llama3.1–70B-FP8@4xH200ソリューションは、評価されたすべての推論ソリューションの中で最も費用対効果の高いオプションとして際立っています。
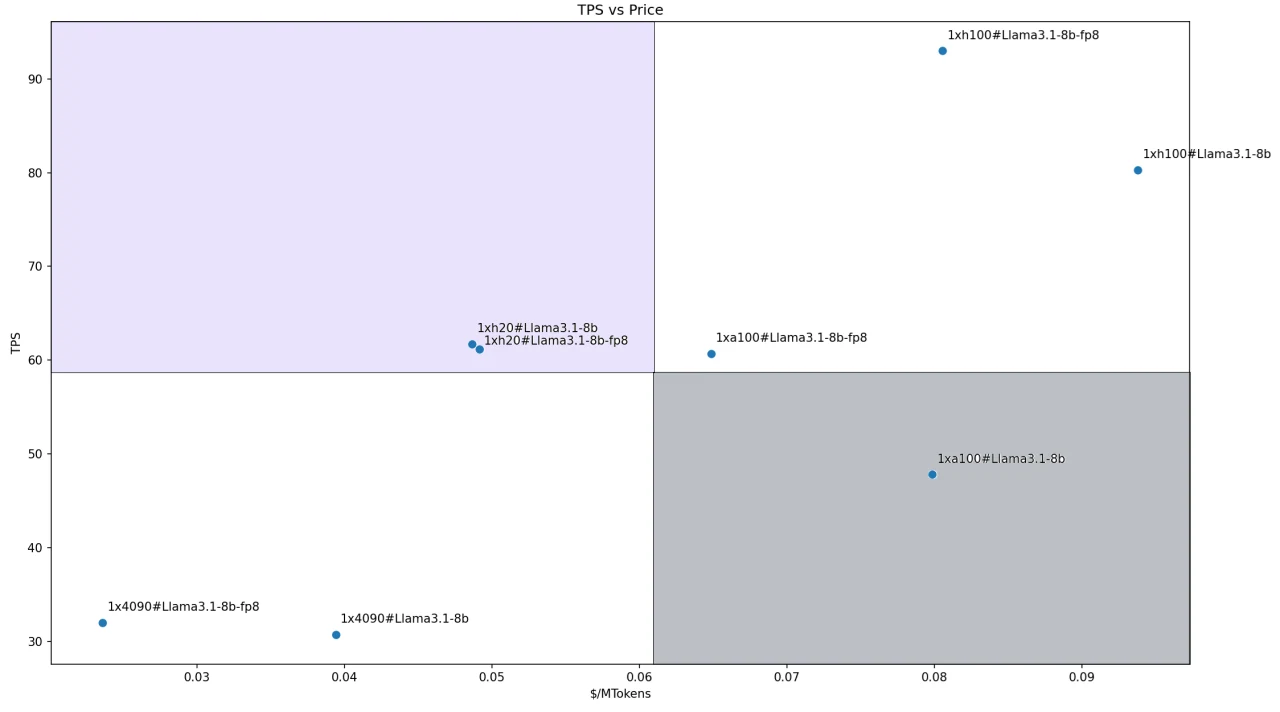
Llama3.1–8Bモデルの場合、サイズが小さいため、すべてのモデルを単一GPU構成でデプロイしました。各ソリューションの費用対効果比を次の図に示します。H200を使用した両方の構成が、私たちが定義したリーダー象限に該当します。
これは主に、H200の良好なパフォーマンス(特に優れたメモリ容量と帯域幅)と競争力のある価格によるものです。2つのRTX 4090構成は最も費用対効果が高いですが、パフォーマンスが低いため、フォロワー象限に分類されます。
結論
GPUコストは大規模モデル推論サービスの重要な部分を占めており、市場には多くのGPUハードウェアオプションが存在するため、最適なものを選択するのは困難です。特定のビジネスニーズに合わせた最良の費用対効果のGPUと推論ソリューションを特定することは、ビジネスの成否を左右する可能性があります。
大規模モデル推論サービスの提供を通じて得た経験により、私たちは豊富なデプロイ知識を蓄積し、効果的なGPU評価フレームワークを開発しました。このフレームワークは、継続的にビジネス開発を導き、クライアントに最良の費用対効果の推論サービスを提供します。
この記事では、実践的なアプリケーションからベストプラクティスを抽出し、主流の大規模モデルとGPU仕様に対する実際のテストを実施し、最良の費用対効果の推論ソリューションを特定するためのパフォーマンス比較を提供します。
私たちの評価アプローチは、複雑なハードウェア指標を超越し、実際のビジネスアプリケーションに焦点を当てているため、汎用性が高く実践的です。特に、さまざまなGPUモデルや推論エンジン間の比較テストに適しています。
最高級の大規模モデル推論サービスとソリューションの詳細については、Novita AI をご確認ください。
Novita AI は、シンプルなAPIを使用して開発者がAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを提供して構築とスケーリングを支援します。
おすすめの記事
1.KV Sparsity が vLLM の1.5倍高速化を実現する方法


