

GLM-Image représente une avancée majeure dans la génération d’images par IA, combinant des architectures autorégressives et de diffusion pour repousser les limites de la fidélité visuelle. Pour les développeurs et les entreprises qui créent des applications visuelles alimentées par l’IA, le déploiement efficace de ce modèle est crucial, mais les processus de configuration traditionnels impliquent des dépendances complexes, une configuration d’environnement et une gestion d’infrastructure.
Novita AI élimine ces obstacles grâce à des modèles GPU préconfigurés qui vous permettent de déployer GLM-Image en quelques minutes plutôt qu’en plusieurs heures. Ce guide vous accompagne dans l’ensemble du processus de déploiement, de la sélection du modèle à l’exécution de votre première inférence, ainsi que des stratégies d’optimisation pour les charges de travail de production.
Que vous prototypiez un outil de génération de contenu, que vous construisiez une plateforme de visualisation pour le e-commerce ou que vous intégriez une synthèse d’images avancée dans votre application, ce tutoriel vous fournit tout ce dont vous avez besoin pour faire fonctionner GLM-Image sur une infrastructure GPU de classe entreprise.
Qu’est-ce que GLM-Image ?
GLM-Image est un modèle de génération d’images avancé qui combine des architectures de décodeur autorégressif et de diffusion pour offrir une qualité visuelle exceptionnelle et un rendu de détails très précis. Développé par l’équipe ZAI, cette approche hybride positionne GLM-Image comme une alternative puissante aux modèles de diffusion latente (LDM) traditionnels, excellant particulièrement dans les scénarios de génération d’images nécessitant beaucoup de connaissances.
L’architecture unique du modèle lui permet de générer des images très détaillées tout en maintenant des performances compétitives par rapport aux approches standard de l’industrie. Que vous construisiez des outils de conception alimentés par l’IA, des plateformes de création de contenu ou des applications de synthèse visuelle, GLM-Image offre à la fois flexibilité et précision grâce à ses capacités de génération texte-vers-image et image-vers-image.
Fonctionnalités clés :
- Architecture hybride autorégressive + diffusion pour une fidélité visuelle supérieure
- Génération texte-vers-image avec compréhension détaillée des prompts
- Transformation image-vers-image et transfert de style
- Génération conditionnelle multi-images
- Prise en charge des sorties haute résolution (dimensions personnalisables)
Pour les spécifications techniques complètes et la documentation du modèle, consultez le dépôt officiel de GLM-Image.
Pourquoi déployer GLM-Image sur Novita AI ?
L’infrastructure GPU de Novita AI offre l’environnement idéal pour exécuter GLM-Image avec des modèles préconfigurés, un déploiement instantané et des ressources de calcul évolutives. Contrairement à la configuration d’environnements locaux ou à la gestion manuelle d’instances cloud, Novita AI rationalise l’ensemble du processus de déploiement, de la sélection du modèle à l’exécution de l’inférence.
Guide de déploiement étape par étape
Étape 1 : Accéder à la console GPU
Accédez à l’interface GPU de Novita AI et cliquez sur Commencer pour accéder au tableau de bord de gestion du déploiement.
Étape 2 : Sélectionner le modèle GLM-Image
Retrouvez GLM-Image dans le dépôt de modèles. Le modèle préconstruit de Novita AI inclut toutes les dépendances nécessaires, éliminant une configuration d’environnement complexe.
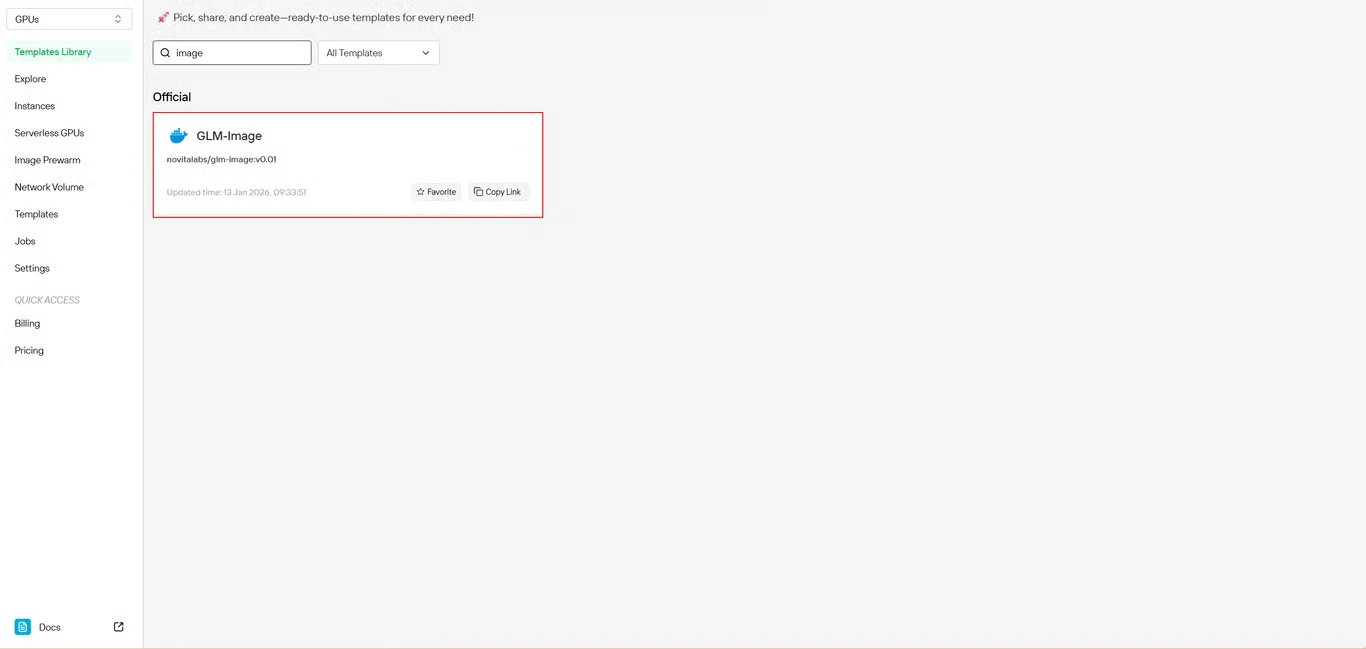
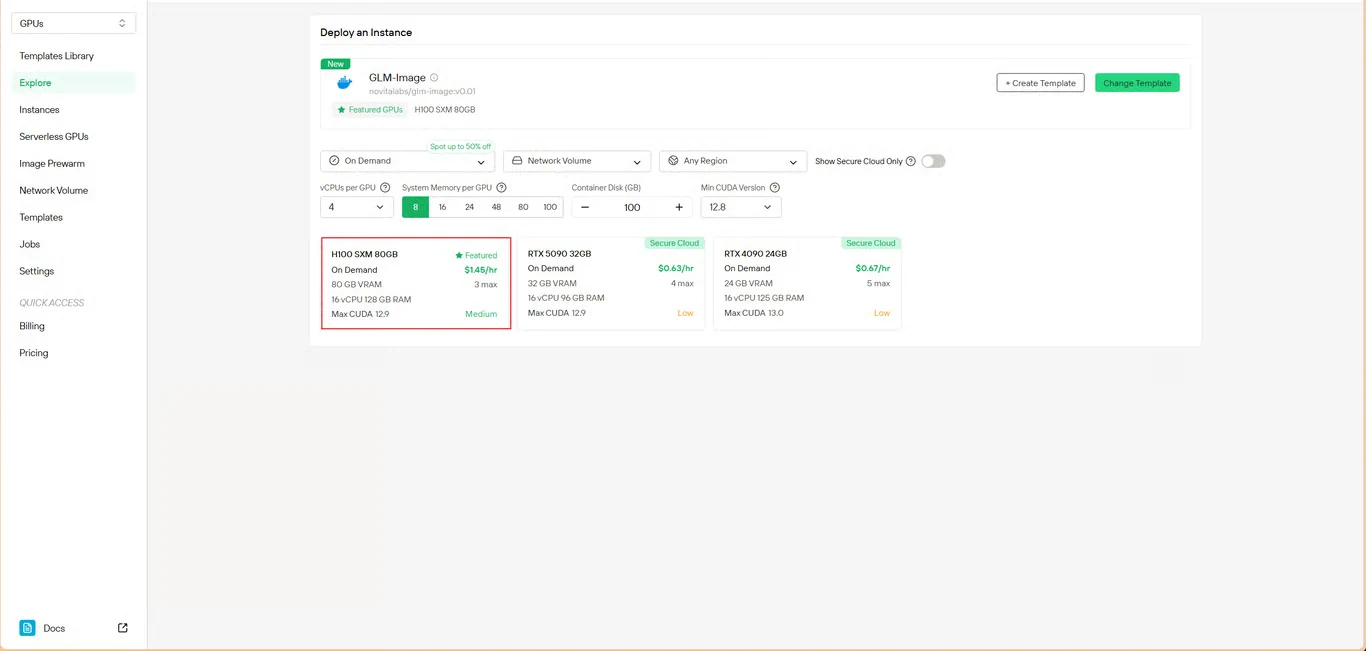
Étape 3 : Configurer l’infrastructure
Définissez vos paramètres de calcul :
- Allocation de mémoire : Assurez-vous d’avoir suffisamment de VRAM pour les poids du modèle
- Exigences de stockage : Allouez de l’espace pour les fichiers du modèle et les images générées
- Paramètres réseau : Configurez-les selon vos exigences d’accès
Cliquez sur Déployer pour poursuivre avec votre configuration.
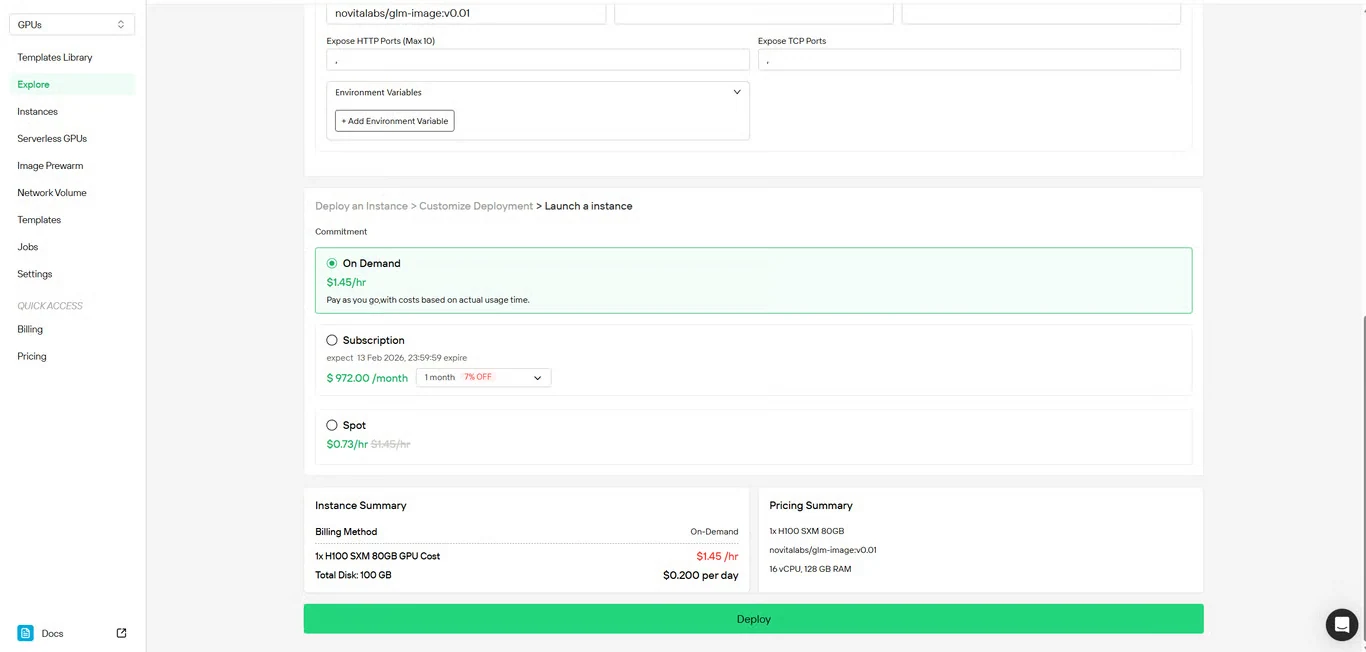
Étape 4 : Vérifier la configuration
Vérifiez à nouveau les détails de votre configuration et le récapitulatif des coûts. Lorsque vous êtes satisfait, cliquez sur Déployer pour lancer la création de l’instance.
Étape 5 : Surveiller le déploiement
Le système vous redirige automatiquement vers la page de gestion des instances. Votre instance GLM-Image sera créée en arrière-plan, aucune intervention manuelle n’est requise.
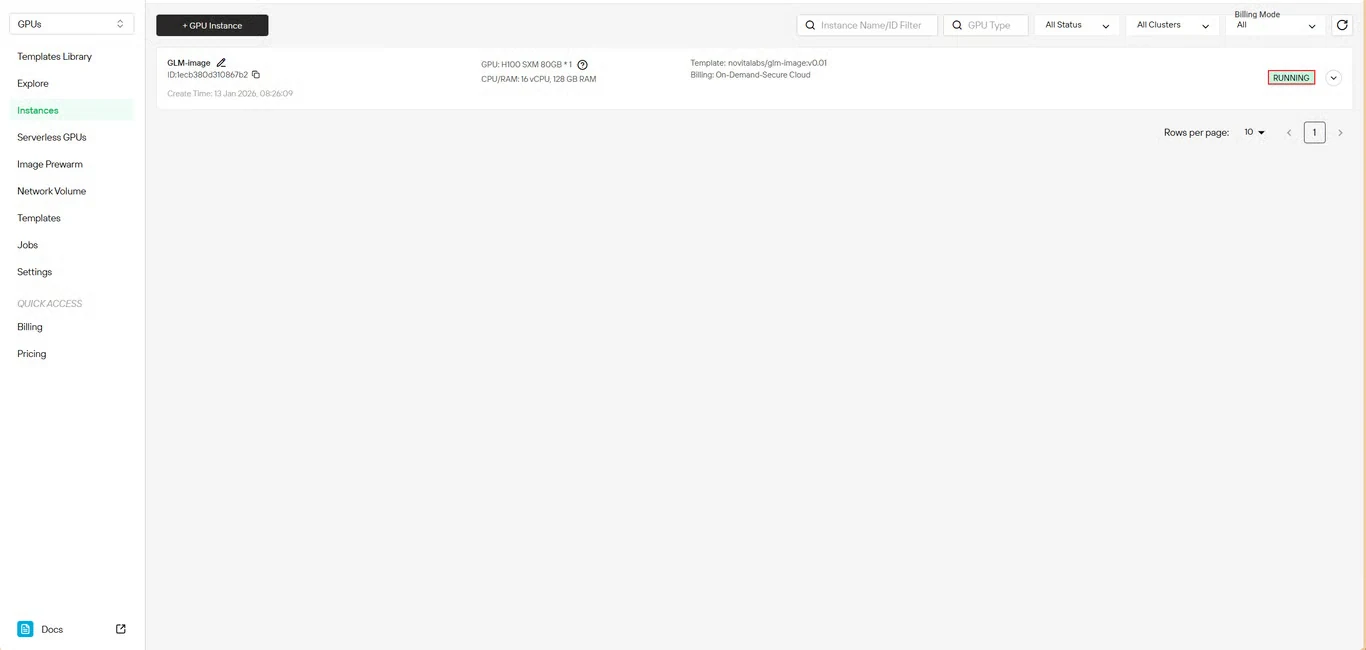
Étape 6 : Suivre la progression du téléchargement
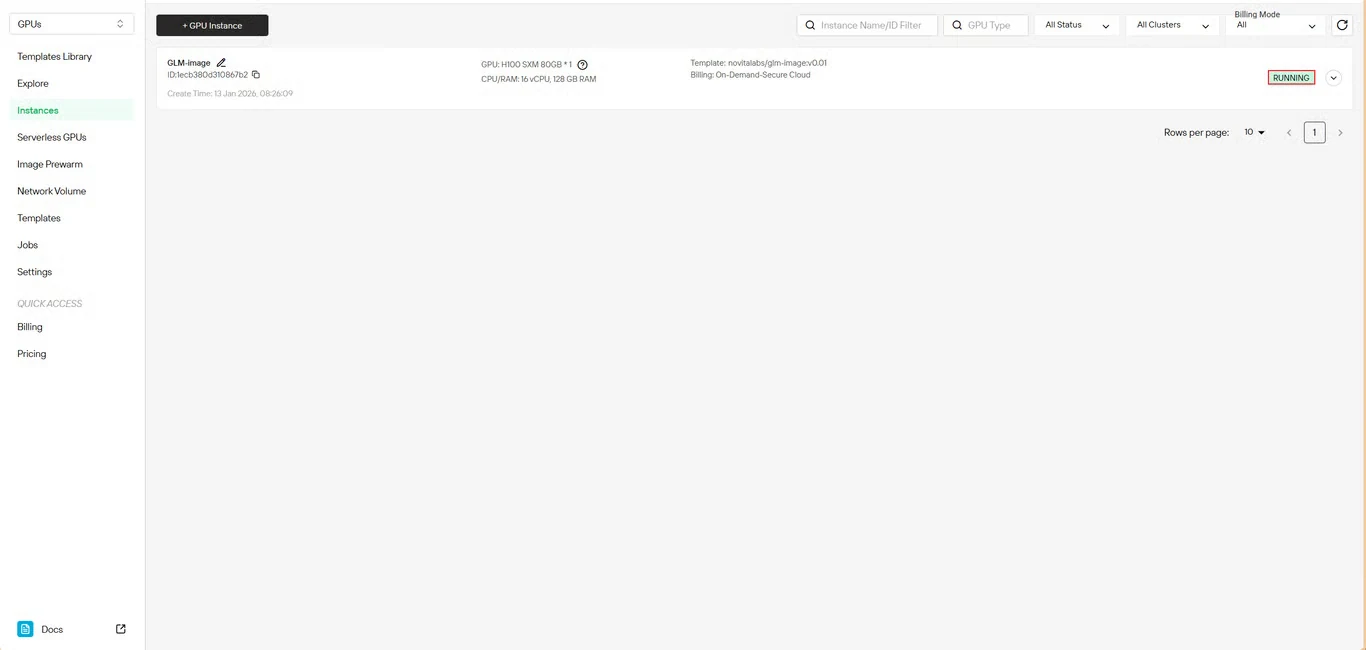 Surveillez l’état du téléchargement du modèle en temps réel. L’état de votre instance passera de Téléchargement à En cours d’exécution une fois le déploiement terminé. Cliquez sur l’icône de flèche à côté du nom de votre instance pour obtenir des informations détaillées sur la progression.
Surveillez l’état du téléchargement du modèle en temps réel. L’état de votre instance passera de Téléchargement à En cours d’exécution une fois le déploiement terminé. Cliquez sur l’icône de flèche à côté du nom de votre instance pour obtenir des informations détaillées sur la progression.
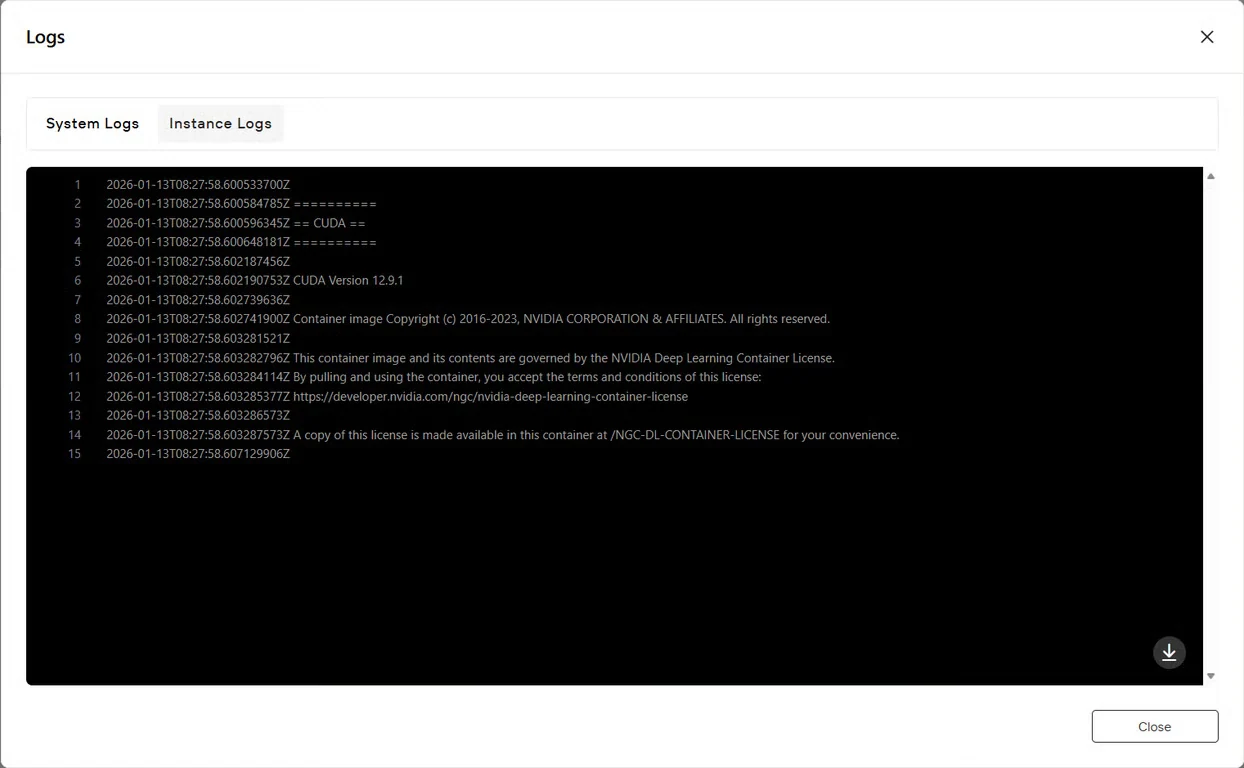
Étape 7 : Vérifier l’état du service
Cliquez sur le bouton Journaux pour afficher les journaux de l’instance et confirmer que le service GLM-Image a démarré avec succès. Recherchez des messages de confirmation d’initialisation indiquant que le modèle est prêt pour l’inférence.
Comment commencer
exemple text2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
prompt = "A beautifully designed modern food magazine style dessert recipe illustration, themed around a raspberry mousse cake. The overall layout is clean and bright, divided into four main areas: the top left features a bold black title 'Raspberry Mousse Cake Recipe Guide', with a soft-lit close-up photo of the finished cake on the right, showcasing a light pink cake adorned with fresh raspberries and mint leaves; the bottom left contains an ingredient list section, titled 'Ingredients' in a simple font, listing 'Flour 150g', 'Eggs 3', 'Sugar 120g', 'Raspberry puree 200g', 'Gelatin sheets 10g', 'Whipping cream 300ml', and 'Fresh raspberries', each accompanied by minimalist line icons (like a flour bag, eggs, sugar jar, etc.); the bottom right displays four equally sized step boxes, each containing high-definition macro photos and corresponding instructions, arranged from top to bottom as follows: Step 1 shows a whisk whipping white foam (with the instruction 'Whip egg whites to stiff peaks'), Step 2 shows a red-and-white mixture being folded with a spatula (with the instruction 'Gently fold in the puree and batter'), Step 3 shows pink liquid being poured into a round mold (with the instruction 'Pour into mold and chill for 4 hours'), Step 4 shows the finished cake decorated with raspberries and mint leaves (with the instruction 'Decorate with raspberries and mint'); a light brown information bar runs along the bottom edge, with icons on the left representing 'Preparation time: 30 minutes', 'Cooking time: 20 minutes', and 'Servings: 8'. The overall color scheme is dominated by creamy white and light pink, with a subtle paper texture in the background, featuring compact and orderly text and image layout with clear information hierarchy."
image = pipe(
prompt=prompt,
height=32 * 32,
width=36 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_t2i.png")
Vous pouvez modifier le prompt dans text2image.py pour l’exécuter ou utiliser les exemples existants pour l’exécuter directement.
python3 text2image
$ python3 text2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.47it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1391.52it/s, Materializing param=shared.weight]
Loading pipeline components...: 71%|██████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 5/7 [00:02<00:00, 2.91it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 359.59it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.02s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:11<00:00, 2.69it/s]
output_t2i.png
exemple image2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
from PIL import Image
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
image_path = "cond.jpg"
prompt = "Replace the background of the snow forest with an underground station featuring an automatic escalator."
image = Image.open(image_path).convert("RGB")
image = pipe(
prompt=prompt,
image=[image], # can input multiple images for multi-image-to-image generation such as [image, image1]
height=33 * 32,
width=32 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_i2i.png")
Vous pouvez modifier le prompt et l’image dans text2image.py pour l’exécuter ou utiliser les exemples existants pour l’exécuter directement.
$ python3 image2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 360.88it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.46it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1426.62it/s, Materializing param=shared.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.03s/it]
100%|███████████████████████████████████████████████████████████████████████████████████| 30/30 [00:10<00:00, 2.97it/s]
Cas d’utilisation de GLM-Image
L’architecture hybride de GLM-Image le rend particulièrement efficace pour :
- E-commerce : Visualisation de produits et génération de variantes
- Marketing : Créatifs de campagne et contenu pour les réseaux sociaux
- Édition : Illustrations éditoriales et infographies
- Design : Art conceptuel et prototypage visuel
- Éducation : Schémas pédagogiques et supports d’apprentissage visuels
La force du modèle dans la génération nécessitant beaucoup de connaissances signifie qu’il peut rendre avec précision des scènes complexes avec des exigences spécifiques, idéal pour les projets nécessitant à la fois créativité et précision.
Commencez avec GLM-Image sur Novita AI
Déployez GLM-Image sur l’infrastructure GPU de Novita AI dès aujourd’hui et accédez à des capacités de génération d’images de classe entreprise sans la complexité d’une configuration manuelle. Visitez la page du modèle GLM-Image pour commencer votre déploiement.
Novita AI est une plateforme cloud IA leader qui fournit aux développeurs des API faciles à utiliser et une infrastructure GPU abordable et fiable pour créer et mettre à l’échelle des applications IA.



