

GLM-Image representa un avance significativo en la generación de imágenes mediante IA, combinando arquitecturas autoregresivas y de difusión para superar los límites de la fidelidad visual. Para desarrolladores y empresas que crean aplicaciones visuales basadas en IA, implementar este modelo de manera eficiente es crucial — pero los procesos de configuración tradicionales implican dependencias complejas, configuración de entornos y gestión de infraestructura.
Novita AI elimina estas barreras con plantillas GPU preconfiguradas que te permiten desplegar GLM-Image en minutos en lugar de horas. Esta guía te lleva por el proceso completo de despliegue, desde la selección de la plantilla hasta ejecutar tu primera inferencia, además de estrategias de optimización para cargas de trabajo en producción.
Ya sea que estés prototipando una herramienta de generación de contenido, construyendo una plataforma de visualización para comercio electrónico, o integrando síntesis avanzada de imágenes en tu aplicación, este tutorial te proporciona todo lo necesario para poner GLM-Image en funcionamiento sobre infraestructura GPU de nivel empresarial.
¿Qué es GLM-Image?
GLM-Image es un modelo avanzado de generación de imágenes que combina arquitecturas de decodificador autoregresivo y de difusión para ofrecer una calidad visual excepcional y un detalle fino en el renderizado. Desarrollado por el equipo ZAI, este enfoque híbrido posiciona a GLM-Image como una alternativa potente a los modelos tradicionales de difusión latente (LDM), destacando especialmente en escenarios de generación de imágenes con alto requerimiento de conocimiento.
La arquitectura única del modelo le permite generar imágenes altamente detalladas mientras mantiene un rendimiento competitivo con los enfoques estándar de la industria. Ya sea que estés construyendo herramientas de diseño impulsadas por IA, plataformas de creación de contenido o aplicaciones de síntesis visual, GLM-Image ofrece tanto flexibilidad como precisión a través de sus capacidades de generación de texto a imagen e imagen a imagen.
Capacidades clave:
- Arquitectura híbrida autoregresiva + de difusión para una fidelidad visual superior
- Generación de texto a imagen con comprensión detallada de indicaciones
- Transformación de imagen a imagen y transferencia de estilo
- Generación condicional con múltiples imágenes
- Soporte de salida en alta resolución (dimensiones personalizables)
Para especificaciones técnicas completas y documentación del modelo, visita el repositorio oficial de GLM-Image.
¿Por qué desplegar GLM-Image en Novita AI?
La infraestructura GPU de Novita AI proporciona el entorno ideal para ejecutar GLM-Image con plantillas preconfiguradas, despliegue instantáneo y recursos de cómputo escalables. A diferencia de configurar entornos locales o gestionar instancias en la nube manualmente, Novita AI simplifica todo el proceso de despliegue, desde la selección de la plantilla hasta la ejecución de inferencias.
Guía de despliegue paso a paso
Paso 1: Acceder a la consola GPU
Navega a la interfaz GPU de Novita AI y haz clic en Get Started para ingresar al panel de gestión de despliegues.
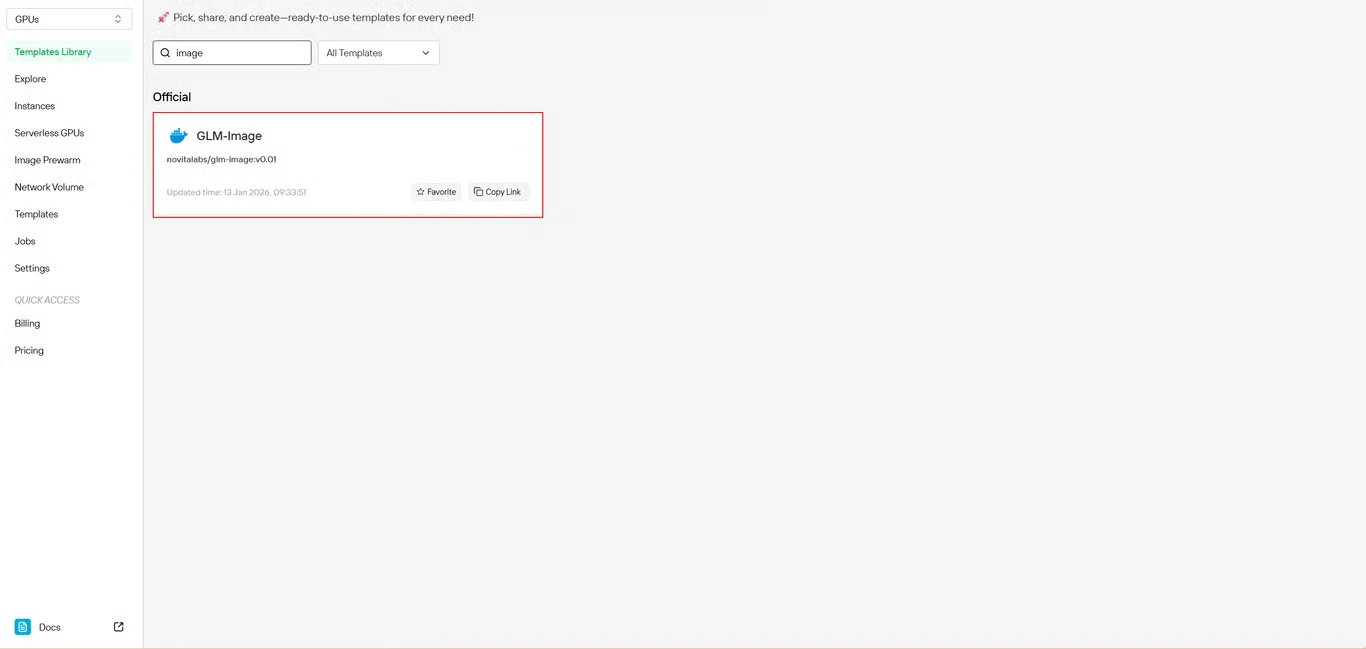
Paso 2: Seleccionar la plantilla GLM-Image
Localiza GLM-Image en el repositorio de plantillas. La plantilla preconstruida de Novita AI incluye todas las dependencias necesarias, eliminando la compleja configuración del entorno.
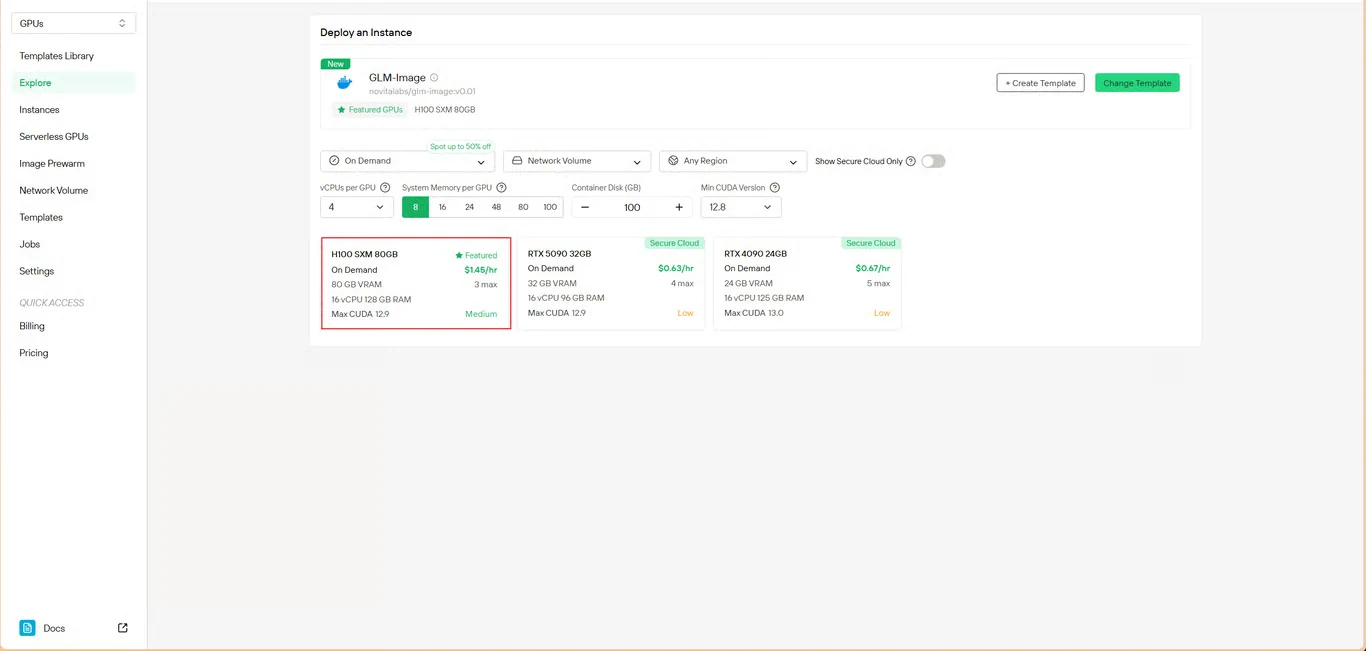
Paso 3: Configurar la infraestructura
Define tus parámetros de cómputo:
- Asignación de memoria: Asegura suficiente VRAM para los pesos del modelo
- Requisitos de almacenamiento: Asigna espacio para los archivos del modelo y las imágenes generadas
- Configuración de red: Configura según tus requisitos de acceso
Haz clic en Deploy para continuar con tu configuración.
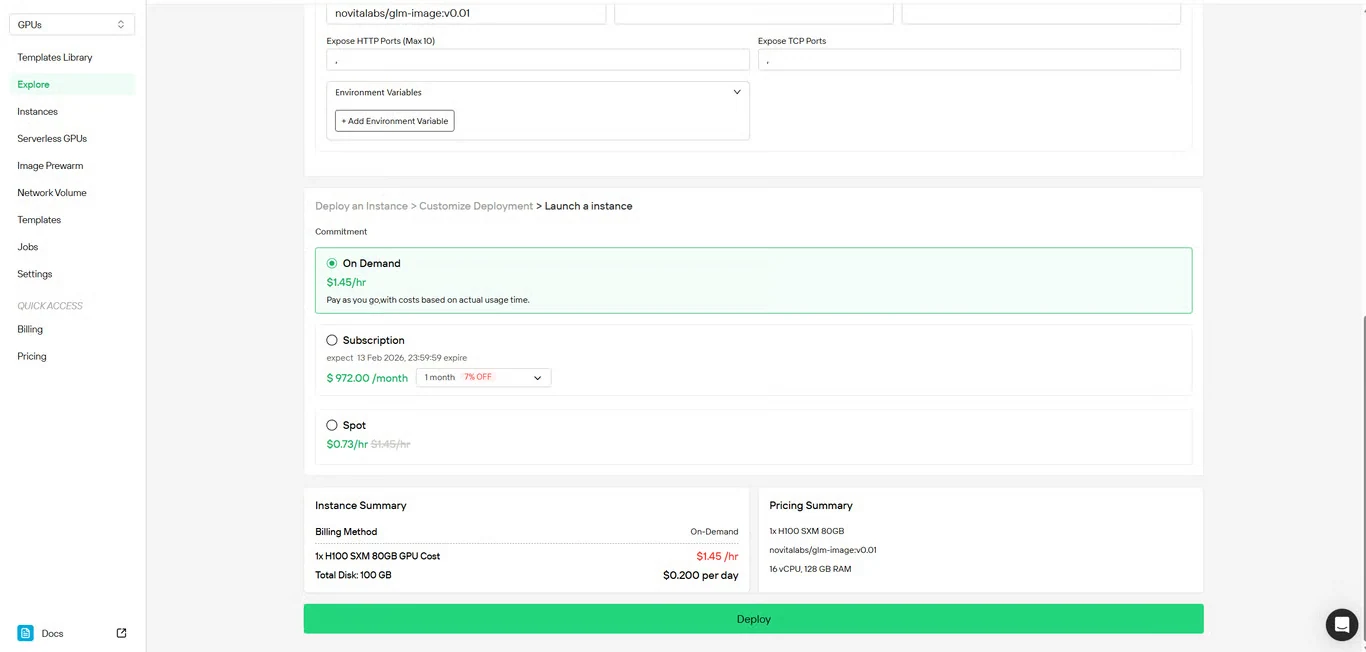
Paso 4: Revisar la configuración
Verifica los detalles de tu configuración y el resumen de costos. Cuando estés conforme, haz clic en Deploy para iniciar la creación de la instancia.
Paso 5: Monitorear el despliegue
El sistema te redirige automáticamente a la página de gestión de instancias. Tu instancia de GLM-Image se creará en segundo plano, sin necesidad de intervención manual.
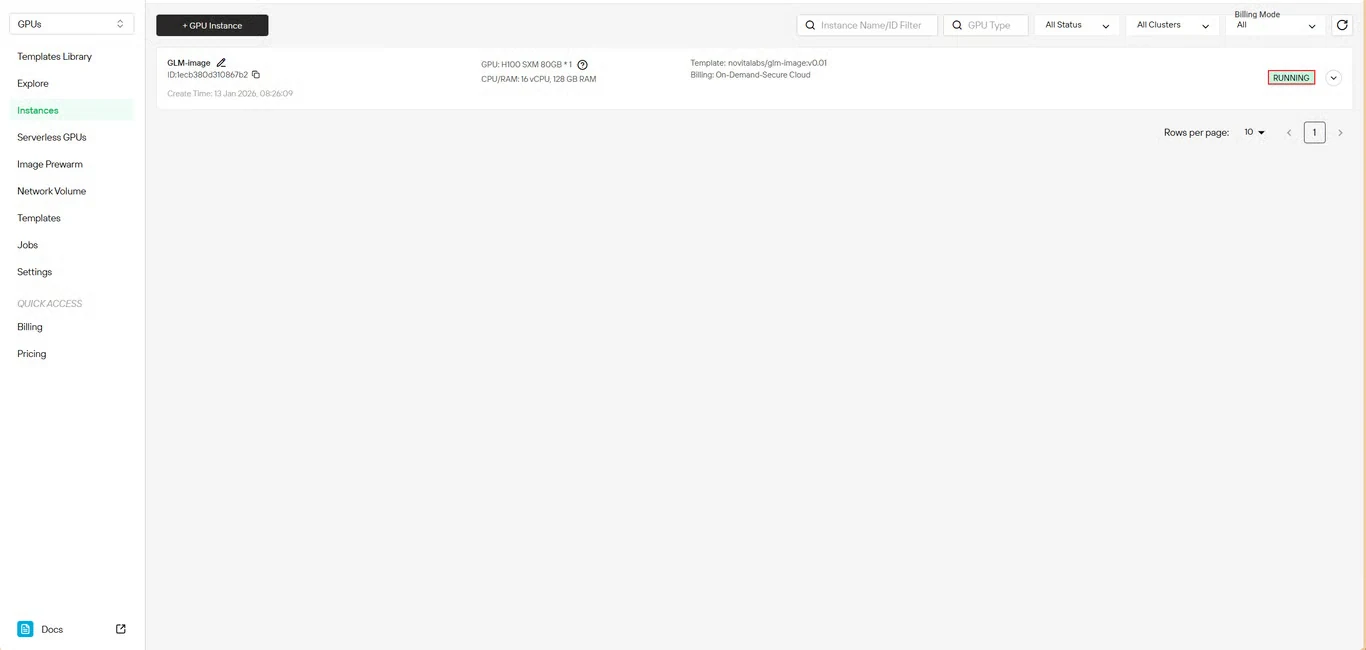
Paso 6: Seguir el progreso de descarga
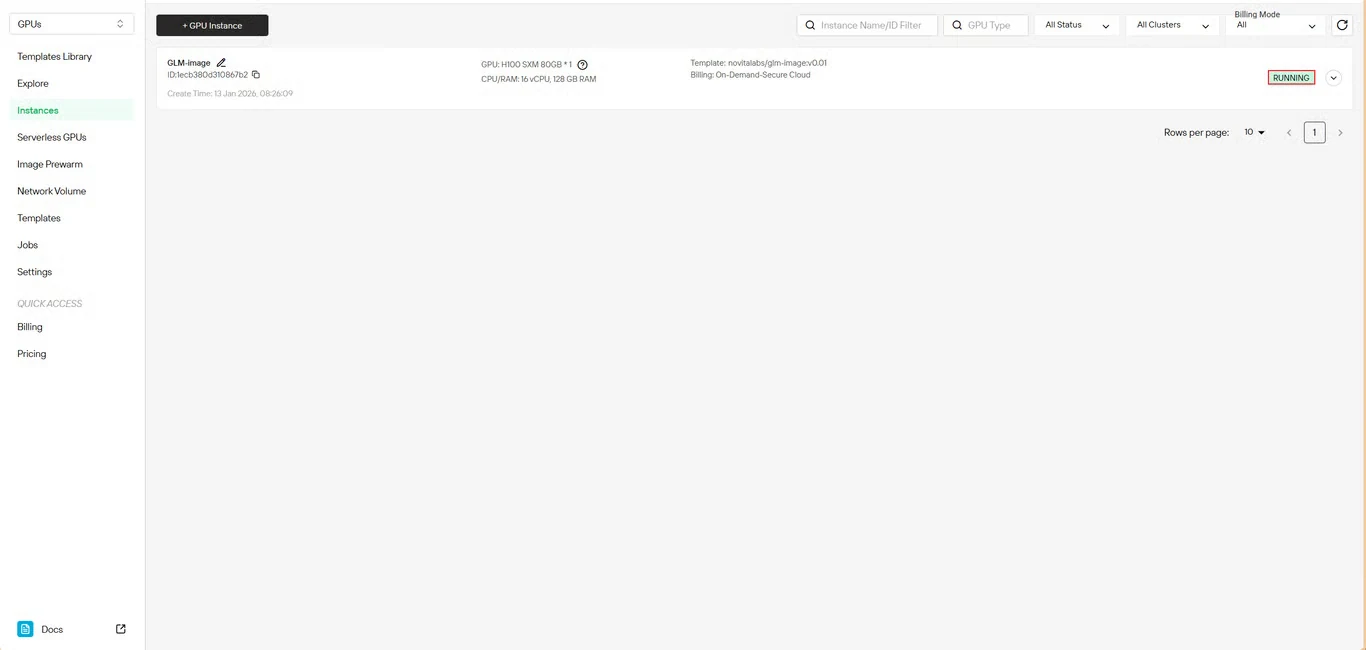
Monitorea en tiempo real el estado de descarga del modelo. El estado de tu instancia pasará de Pulling a Running una vez que el despliegue se complete. Haz clic en el icono de flecha junto al nombre de tu instancia para obtener información detallada del progreso.
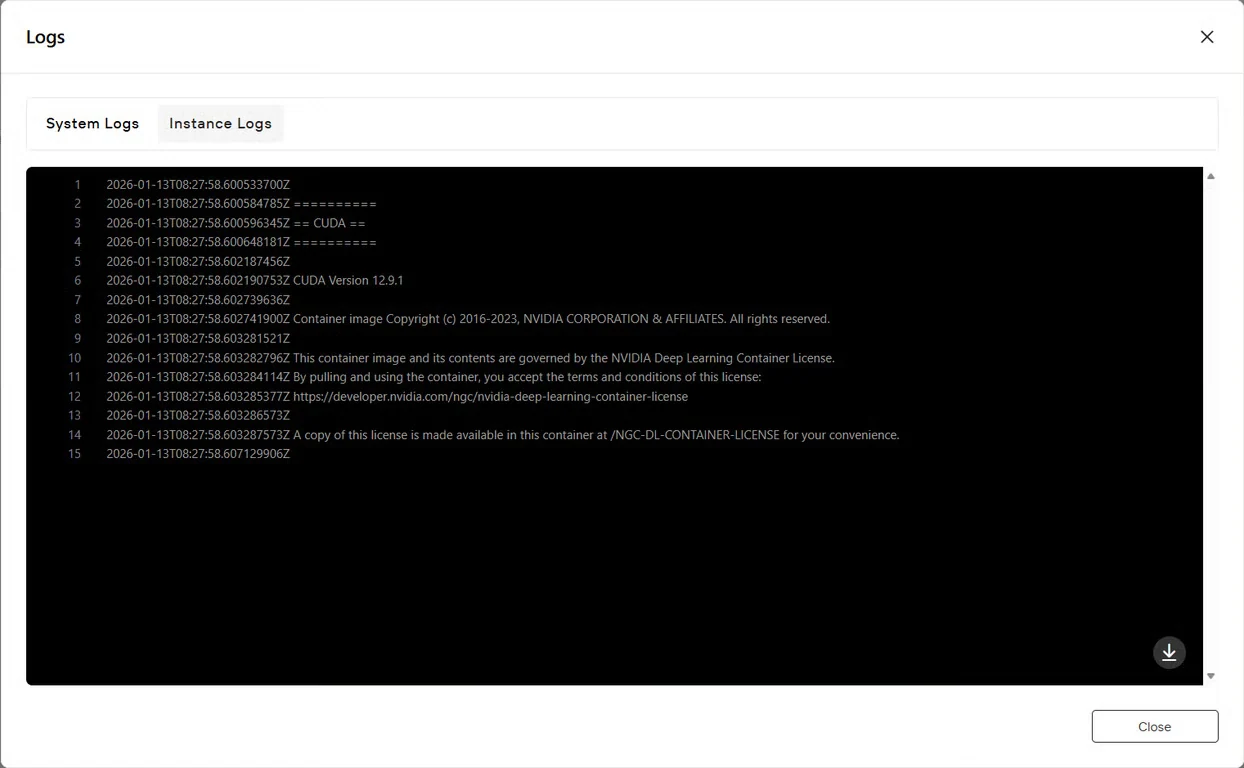
Paso 7: Verificar el estado del servicio
Haz clic en el botón Logs para ver los registros de la instancia y confirmar que el servicio de GLM-Image se ha iniciado correctamente. Busca mensajes de confirmación de inicialización que indiquen que el modelo está listo para la inferencia.
Cómo empezar
ejemplo text2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
prompt = "A beautifully designed modern food magazine style dessert recipe illustration, themed around a raspberry mousse cake. The overall layout is clean and bright, divided into four main areas: the top left features a bold black title 'Raspberry Mousse Cake Recipe Guide', with a soft-lit close-up photo of the finished cake on the right, showcasing a light pink cake adorned with fresh raspberries and mint leaves; the bottom left contains an ingredient list section, titled 'Ingredients' in a simple font, listing 'Flour 150g', 'Eggs 3', 'Sugar 120g', 'Raspberry puree 200g', 'Gelatin sheets 10g', 'Whipping cream 300ml', and 'Fresh raspberries', each accompanied by minimalist line icons (like a flour bag, eggs, sugar jar, etc.); the bottom right displays four equally sized step boxes, each containing high-definition macro photos and corresponding instructions, arranged from top to bottom as follows: Step 1 shows a whisk whipping white foam (with the instruction 'Whip egg whites to stiff peaks'), Step 2 shows a red-and-white mixture being folded with a spatula (with the instruction 'Gently fold in the puree and batter'), Step 3 shows pink liquid being poured into a round mold (with the instruction 'Pour into mold and chill for 4 hours'), Step 4 shows the finished cake decorated with raspberries and mint leaves (with the instruction 'Decorate with raspberries and mint'); a light brown information bar runs along the bottom edge, with icons on the left representing 'Preparation time: 30 minutes', 'Cooking time: 20 minutes', and 'Servings: 8'. The overall color scheme is dominated by creamy white and light pink, with a subtle paper texture in the background, featuring compact and orderly text and image layout with clear information hierarchy."
image = pipe(
prompt=prompt,
height=32 * 32,
width=36 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_t2i.png")
Puedes modificar el prompt en text2image.py para ejecutarlo, o usar los ejemplos existentes para ejecutarlo directamente.
python3 text2image
$ python3 text2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.47it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1391.52it/s, Materializing param=shared.weight]
Loading pipeline components...: 71%|██████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 5/7 [00:02<00:00, 2.91it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 359.59it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.02s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:11<00:00, 2.69it/s]
output_t2i.png
ejemplo image2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
from PIL import Image
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
image_path = "cond.jpg"
prompt = "Replace the background of the snow forest with an underground station featuring an automatic escalator."
image = Image.open(image_path).convert("RGB")
image = pipe(
prompt=prompt,
image=[image], # can input multiple images for multi-image-to-image generation such as [image, image1]
height=33 * 32,
width=32 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_i2i.png")
Puedes modificar el prompt y la imagen en text2image.py para ejecutarlo, o usar los ejemplos existentes para ejecutarlo directamente.
$ python3 image2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 360.88it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.46it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1426.62it/s, Materializing param=shared.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.03s/it]
100%|███████████████████████████████████████████████████████████████████████████████████| 30/30 [00:10<00:00, 2.97it/s]
Casos de uso para GLM-Image
La arquitectura híbrida de GLM-Image lo hace particularmente efectivo para:
- Comercio electrónico: Visualización de productos y generación de variantes
- Marketing: Creatividades de campañas y contenido para redes sociales
- Publicación: Ilustraciones editoriales e infografías
- Diseño: Arte conceptual y prototipado visual
- Educación: Diagramas instructivos y materiales de aprendizaje visual
La fortaleza del modelo en generación con alto nivel de conocimiento significa que puede renderizar con precisión escenas complejas con requisitos específicos, ideal para proyectos que demandan tanto creatividad como precisión.
Comienza con GLM-Image en Novita AI
Despliega GLM-Image en la infraestructura GPU de Novita AI hoy y accede a capacidades de generación de imágenes de nivel empresarial sin la complejidad de la configuración manual. Visita la página de la plantilla GLM-Image para comenzar tu despliegue.
Novita AIes una plataforma líder en la nube para IA que proporciona a los desarrolladores APIs fáciles de usar e infraestructura GPU asequible y confiable para construir y escalar aplicaciones de IA.



