

يُمثل نموذج GLM-Image تقدمًا كبيرًا في مجال توليد الصور بالذكاء الاصطناعي، حيث يجمع بين بنيتي النموذج الانتقائي الذاتي والانتشار لدفع حدود جودة الصورة البصرية. بالنسبة للمطورين والشركات التي تبني تطبيقات بصرية مدعومة بالذكاء الاصطناعي، فإن نشر هذا النموذج بكفاءة أمر بالغ الأهمية - لكن عمليات الإعداد التقليدية تتضمن تبعيات معقدة، وتكوين بيئة، وإدارة بنية تحتية.
تخلص منصة Novita AI من هذه العقبات من خلال قوالب GPU مُعدة مسبقًا التي تتيح لك نشر نموذج GLM-Image في دقائق بدلاً من ساعات. يرشدك هذا الدليل خلال عملية النشر الكاملة، من اختيار القالب إلى تشغيل أول استدلال لك، بالإضافة إلى استراتيجيات التحسين لأحمال العمل الإنتاجية.
سواء كنت تُنشئ نموذجًا أوليًا لأداة توليد محتوى، أو تبني منصة تصور للتجارة الإلكترونية، أو تدمج توليد صور متقدم في تطبيقك، يقدم هذا البرنامج التعليمي كل ما تحتاجه لتشغيل نموذج GLM-Image على بنية تحتية لـ GPU من الدرجة المؤسسية.
ما هو نموذج GLM-Image؟
نموذج GLM-Image هو نموذج توليد صور متقدم يجمع بين بنيتي فك التشفير الانتقائي الذاتي والانتشار لتقديم جودة بصرية استثنائية وعرض تفاصيل دقيقة. طُور هذا النموذج من قبل فريق ZAI، وتجعل هذه المقاربة الهجينة من GLM-Image بديلاً قوياً لنماذج الانتشار الكامنة (LDM) التقليدية، حيث يتفوق بشكل خاص في سيناريوهات توليد الصور التي تتطلب معرفة مكثفة.
تتيح البنية الفريدة للنموذج توليد صور عالية التفاصيل مع الحفاظ على أداء تنافسي مقارنة بالمناهج المعيارية في الصناعة. سواء كنت تبني أدوات تصميم مدعومة بالذكاء الاصطناعي، أو منصات إنشاء محتوى، أو تطبيقات تركيب بصري، يقدم GLM-Image كل من المرونة والدقة من خلال قدراته على التوليد من نص إلى صورة ومن صورة إلى صورة.
القدرات الرئيسية:
- بنية هجينة من النوع الانتقائي الذاتي + الانتشار لتحقيق وفاء بصري أعلى
- توليد الصور من النص مع فهم تفصيلي للأوامر النصية
- تحويل الصور من صورة إلى صورة ونقل الأنماط
- توليد مشروط متعدد الصور
- دعم إخراج عالي الدقة (أبعاد قابلة للتخصيص)
للحصول على المواصفات الفنية الكاملة ووثائق النموذج، قم بزيارة مستودع GLM-Image الرسمي.
لماذا تنشر نموذج GLM-Image على منصة Novita AI؟
توفر بنية GPU الخاصة بمنصة Novita AI البيئة المثالية لتشغيل نموذج GLM-Image مع قوالب مُعدة مسبقًا، ونشر فوري، وموارد حوسبة قابلة للتوسع. على عكس إعداد البيئات المحلية أو إدارة مثيلات السحابة يدويًا، تبسط منصة Novita AI عملية النشر بأكملها من اختيار القالب إلى تشغيل الاستدلال.
دليل نشر خطوة بخطوة
الخطوة 1: الوصول إلى وحدة تحكم GPU
انتقل إلى واجهة GPU الخاصة بمنصة Novita AI وانقر على ابدأ الآن للدخول إلى لوحة إدارة النشر.
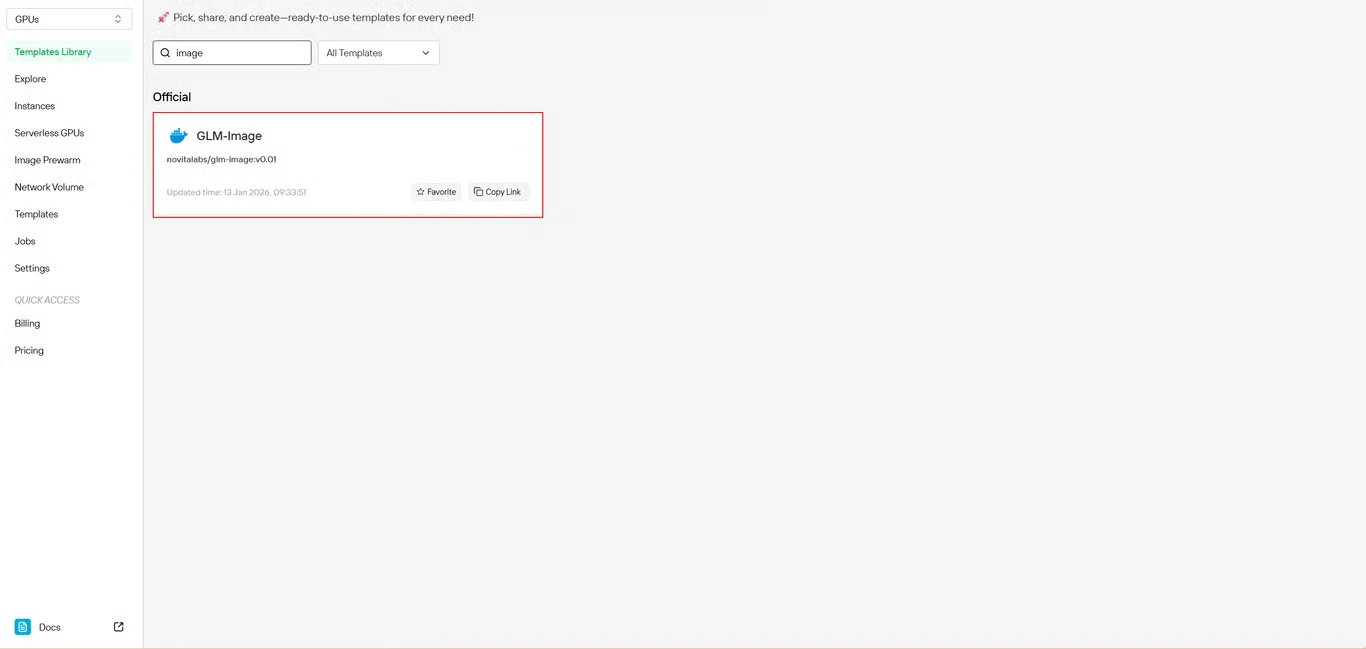
الخطوة 2: اختيار قالب GLM-Image
ابحث عن GLM-Image في مستودع القوالب. يتضمن القالب المُعد مسبقًا من Novita AI جميع التبعيات الضرورية، مما يلغي الحاجة إلى إعداد بيئة معقد.
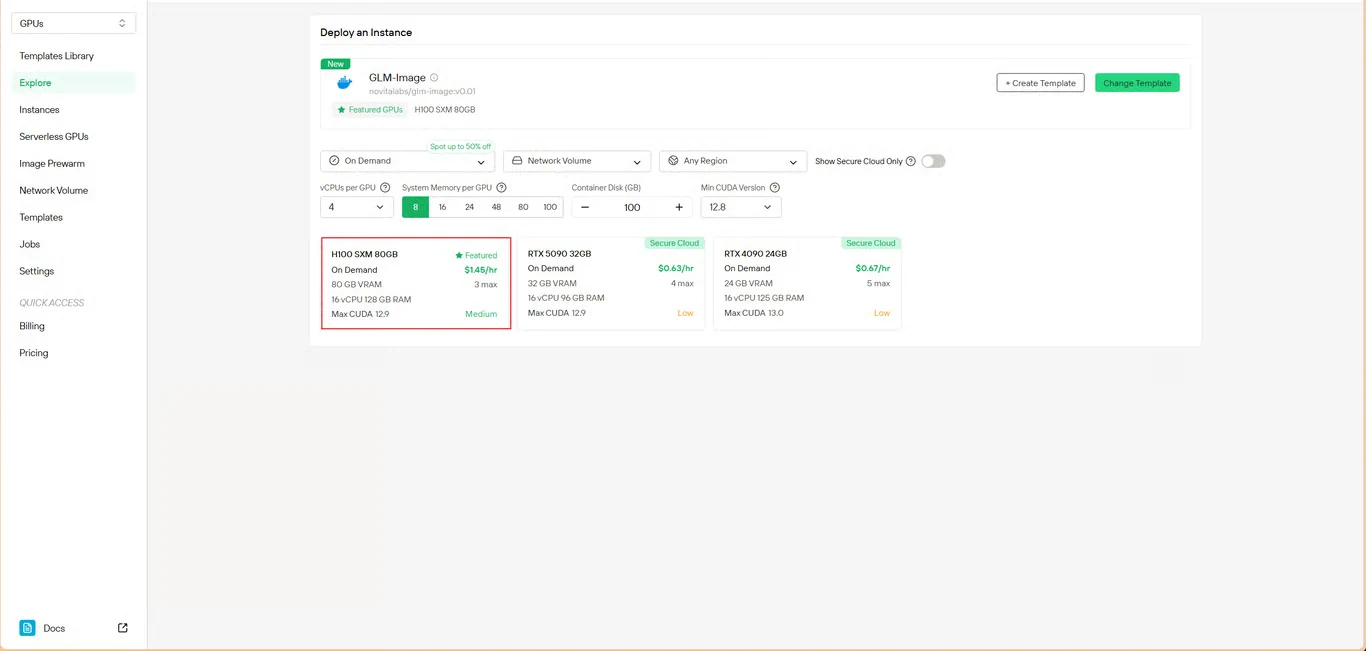
الخطوة 3: تكوين البنية التحتية
اضبط معلمات الحوسبة الخاصة بك:
- تخصيص الذاكرة: تأكد من توفر ذاكرة وصول عشوائي كافية للفيديو (VRAM) لأوزان النموذج
- متطلبات التخزين: خصص مساحة لملفات النموذج والصور المُولدة
- إعدادات الشبكة: قم بتكوينها وفقًا لمتطلبات الوصول الخاصة بك
انقر على نشر للمتابعة مع التكوين الخاص بك.
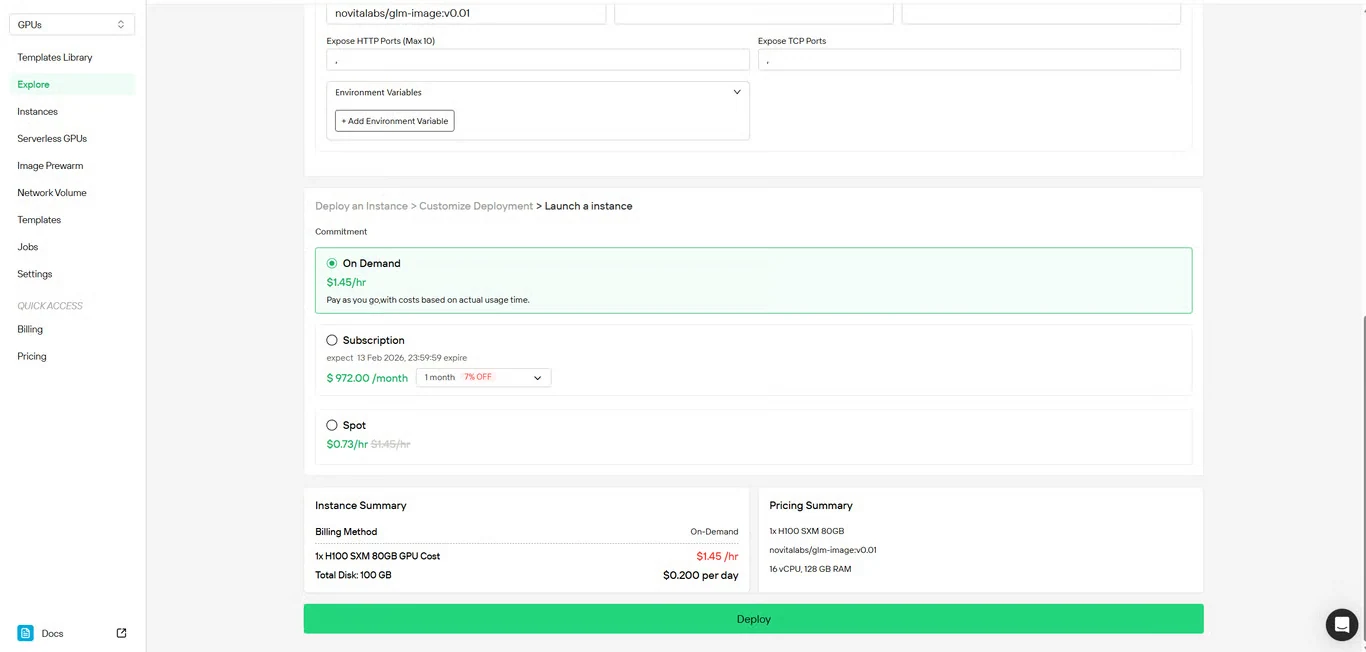
الخطوة 4: مراجعة التكوين
تحقق مرة أخرى من تفاصيل الإعداد والتلخيص الخاص بالتكاليف. عندما تكون راضيًا، انقر على نشر لبدء إنشاء المثيل.
الخطوة 5: مراقبة عملية النشر
يعيد النظام توجيهك تلقائيًا إلى صفحة إدارة المثيلات. سيتم إنشاء مثيل GLM-Image الخاص بك في الخلفية - لا حاجة إلى تدخل يدوي.
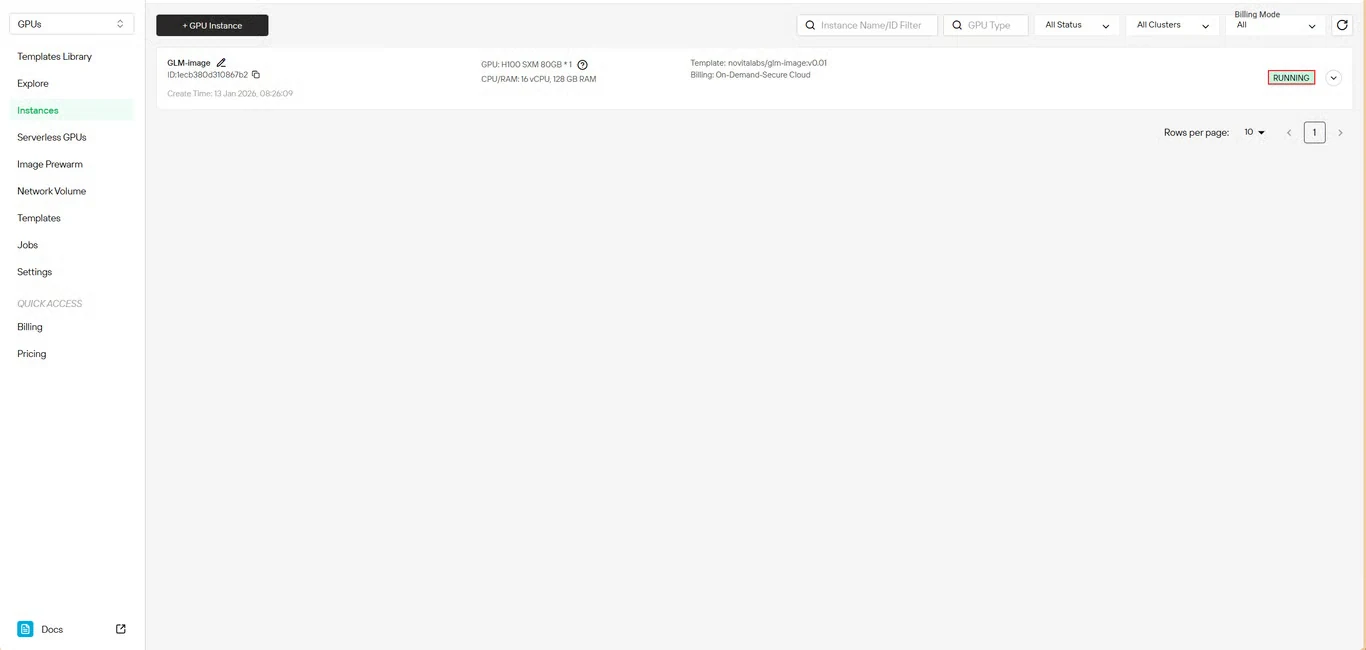
الخطوة 6: تتبع تقدم التنزيل
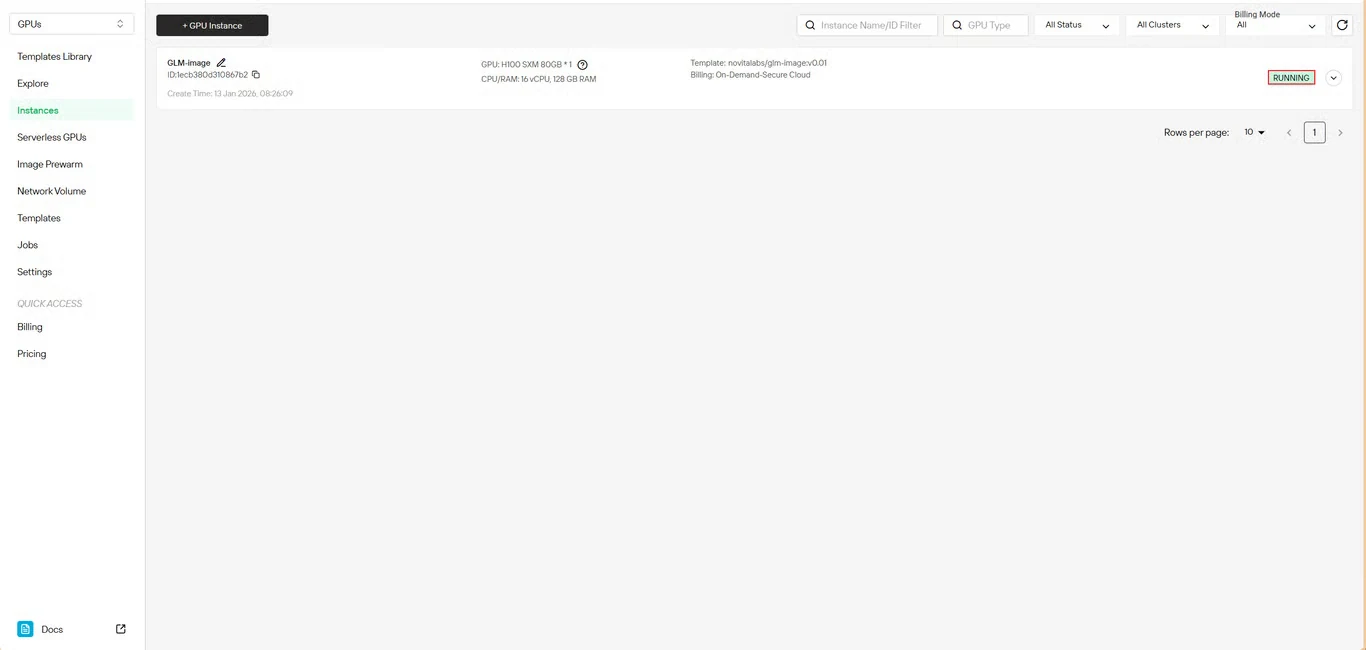
راقب حالة تنزيل النموذج في الوقت الفعلي. ستتغير حالة المثيل الخاص بك من سحب إلى قيد التشغيل بمجرد اكتمال عملية النشر. انقر على أيقونة السهم بجانب اسم المثيل للحصول على معلومات تفصيلية عن التقدم.
الخطوة 7: التحقق من حالة الخدمة
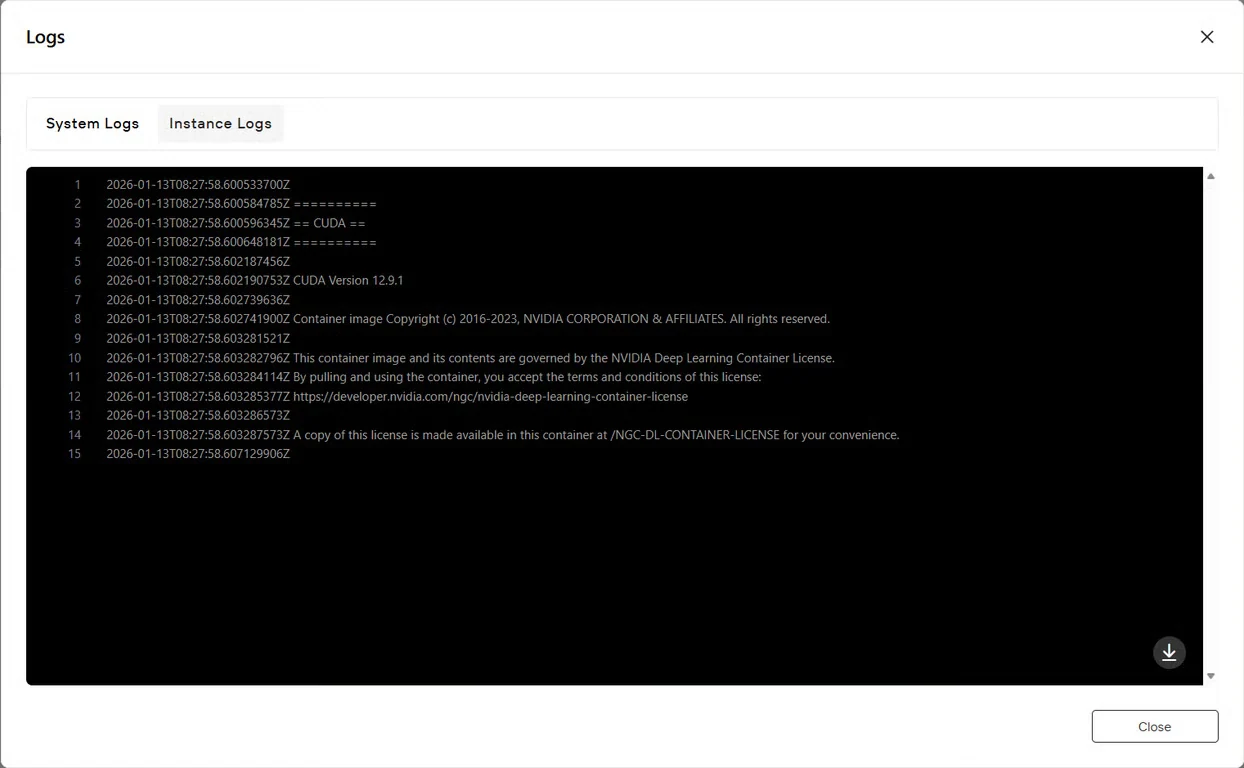
انقر على زر السجلات لعرض سجلات المثيل والتأكد من أن خدمة GLM-Image قد بدأت بنجاح. ابحث عن رسائل تأكيد التهيئة التي تشير إلى أن النموذج جاهز للاستدلال.
كيفية البدء
مثال text2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
prompt = "A beautifully designed modern food magazine style dessert recipe illustration, themed around a raspberry mousse cake. The overall layout is clean and bright, divided into four main areas: the top left features a bold black title 'Raspberry Mousse Cake Recipe Guide', with a soft-lit close-up photo of the finished cake on the right, showcasing a light pink cake adorned with fresh raspberries and mint leaves; the bottom left contains an ingredient list section, titled 'Ingredients' in a simple font, listing 'Flour 150g', 'Eggs 3', 'Sugar 120g', 'Raspberry puree 200g', 'Gelatin sheets 10g', 'Whipping cream 300ml', and 'Fresh raspberries', each accompanied by minimalist line icons (like a flour bag, eggs, sugar jar, etc.); the bottom right displays four equally sized step boxes, each containing high-definition macro photos and corresponding instructions, arranged from top to bottom as follows: Step 1 shows a whisk whipping white foam (with the instruction 'Whip egg whites to stiff peaks'), Step 2 shows a red-and-white mixture being folded with a spatula (with the instruction 'Gently fold in the puree and batter'), Step 3 shows pink liquid being poured into a round mold (with the instruction 'Pour into mold and chill for 4 hours'), Step 4 shows the finished cake decorated with raspberries and mint leaves (with the instruction 'Decorate with raspberries and mint'); a light brown information bar runs along the bottom edge, with icons on the left representing 'Preparation time: 30 minutes', 'Cooking time: 20 minutes', and 'Servings: 8'. The overall color scheme is dominated by creamy white and light pink, with a subtle paper texture in the background, featuring compact and orderly text and image layout with clear information hierarchy."
image = pipe(
prompt=prompt,
height=32 * 32,
width=36 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_t2i.png")
يمكنك تعديل الأمر النصي (prompt) في ملف text2image.py لتشغيله أو استخدام الأمثلة الموجودة للتشغيل مباشرة.
python3 text2image
$ python3 text2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.47it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1391.52it/s, Materializing param=shared.weight]
Loading pipeline components...: 71%|██████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 5/7 [00:02<00:00, 2.91it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 359.59it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.02s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:11<00:00, 2.69it/s]
output_t2i.png
مثال image2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
from PIL import Image
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
image_path = "cond.jpg"
prompt = "Replace the background of the snow forest with an underground station featuring an automatic escalator."
image = Image.open(image_path).convert("RGB")
image = pipe(
prompt=prompt,
image=[image], # can input multiple images for multi-image-to-image generation such as [image, image1]
height=33 * 32,
width=32 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_i2i.png")
يمكنك تعديل الأمر النصي (prompt) والصورة في ملف text2image.py لتشغيله أو استخدام الأمثلة الموجودة للتشغيل مباشرة.
$ python3 image2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 360.88it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.46it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1426.62it/s, Materializing param=shared.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.03s/it]
100%|███████████████████████████████████████████████████████████████████████████████████| 30/30 [00:10<00:00, 2.97it/s]
حالات استخدام نموذج GLM-Image
تجعل البنية الهجينة لنموذج GLM-Image فعالة بشكل خاص في:
- التجارة الإلكترونية: تصور المنتجات وتوليد متغيراتها
- التسويق: الإبداعات الحملاتية ومحتوى وسائل التواصل الاجتماعي
- النشر: الرسومات التوضيحية التحريرية والرسوم البيانية
- التصميم: فن المفاهيم والنماذج الأولية البصرية
- التعليم: المخططات التعليمية ومواد التعلم البصرية
تعني قوة النموذج في التوليد الذي يتطلب معرفة مكثفة أنه يمكنه عرض مشاهد معينة بمتطلبات محددة بدقة - مما يجعله مثالياً للمشاريع التي تتطلب كل من الإبداع والدقة.
ابدأ استخدام نموذج GLM-Image على منصة Novita AI
انشر نموذج GLM-Image على بنية GPU الخاصة بمنصة Novita AI اليوم واحصل على إمكانيات توليد الصور من الدرجة المؤسسية دون تعقيدات الإعداد اليدوي. قم بزيارة صفحة قالب GLM-Image لبدء عملية النشر الخاصة بك.
Novita AIهي منصة سحابة رائدة في مجال الذكاء الاصطناعي توفر للمطورين واجهات برمجة تطبيقات سهلة الاستخدام وبنية تحتية لـ GPU موثوقة وبأسعار معقولة لبناء وتوسيع نطاق تطبيقات الذكاء الاصطناعي.



