

GLM-Image stellt einen bedeutenden Fortschritt in der KI-Bildgenerierung dar, der autoregressive und Diffusionsarchitekturen kombiniert, um die Grenzen der visuellen Treue zu erweitern. Für Entwickler und Unternehmen, die KI-gestützte visuelle Anwendungen erstellen, ist die effiziente Bereitstellung dieses Modells entscheidend – aber herkömmliche Einrichtungsprozesse beinhalten komplexe Abhängigkeiten, Umgebungskonfiguration und Infrastrukturverwaltung.
Novita AI beseitigt diese Hürden mit vorkonfigurierten GPU-Vorlagen, mit denen Sie GLM-Image in Minuten statt Stunden bereitstellen können. Diese Anleitung führt Sie durch den gesamten Bereitstellungsprozess, von der Auswahl der Vorlage bis zur Ausführung Ihrer ersten Inferenz, plus Optimierungsstrategien für Produktionsworkloads.
Egal, ob Sie ein Tool zur Inhaltsgenerierung prototypisieren, eine E-Commerce-Visualisierungsplattform erstellen oder fortschrittliche Bildsynthese in Ihre Anwendung integrieren – dieses Tutorial bietet alles, was Sie benötigen, um GLM-Image auf unternehmensgerechter GPU-Infrastruktur zum Laufen zu bringen.
Was ist GLM-Image?
GLM-Image ist ein fortschrittliches Bildgenerierungsmodell, das autoregressive und Diffusions-Decoder-Architekturen kombiniert, um außergewöhnliche visuelle Qualität und fein granulierte Detailwiedergabe zu liefern. Entwickelt vom ZAI-Team positioniert dieser hybride Ansatz GLM-Image als leistungsstarke Alternative zu herkömmlichen Latent Diffusion Models (LDM), insbesondere bei wissensintensiven Bildgenerierungsszenarien.
Die einzigartige Architektur des Modells ermöglicht es, hochdetaillierte Bilder zu generieren, während es gleichzeitig eine wettbewerbsfähige Leistung im Vergleich zu branchenüblichen Ansätzen beibehält. Egal, ob Sie KI-gestützte Designtools, Plattformen zur Inhaltserstellung oder visuelle Syntheseanwendungen erstellen – GLM-Image bietet sowohl Flexibilität als auch Präzision durch seine Text-zu-Bild- und Bild-zu-Bild-Generierungsfunktionen.
Hauptfunktionen:
- Hybride autoregressive + Diffusionsarchitektur für überlegene visuelle Treue
- Text-zu-Bild-Generierung mit detailliertem Prompt-Verständnis
- Bild-zu-Bild-Transformation und Stilübertragung
- Multibild-bedingte Generierung
- Unterstützung von hochauflösenden Ausgaben (anpassbare Abmessungen)
Vollständige technische Spezifikationen und Modelldokumentation finden Sie im offiziellen GLM-Image-Repository.
Warum GLM-Image auf Novita AI bereitstellen?
Die GPU-Infrastruktur von Novita AI bietet die ideale Umgebung für die Ausführung von GLM-Image mit vorkonfigurierten Vorlagen, sofortiger Bereitstellung und skalierbaren Rechenressourcen. Im Gegensatz zur Einrichtung lokaler Umgebungen oder der manuellen Verwaltung von Cloud-Instanzen optimiert Novita AI den gesamten Bereitstellungsprozess von der Vorlagenauswahl bis zur Ausführung der Inferenz.
Schritt-für-Schritt-Bereitstellungsanleitung
Schritt 1: Auf die GPU-Konsole zugreifen
Navigieren Sie zur GPU-Oberfläche von Novita AI und klicken Sie auf Get Started, um das Bereitstellungsverwaltungs-Dashboard aufzurufen.
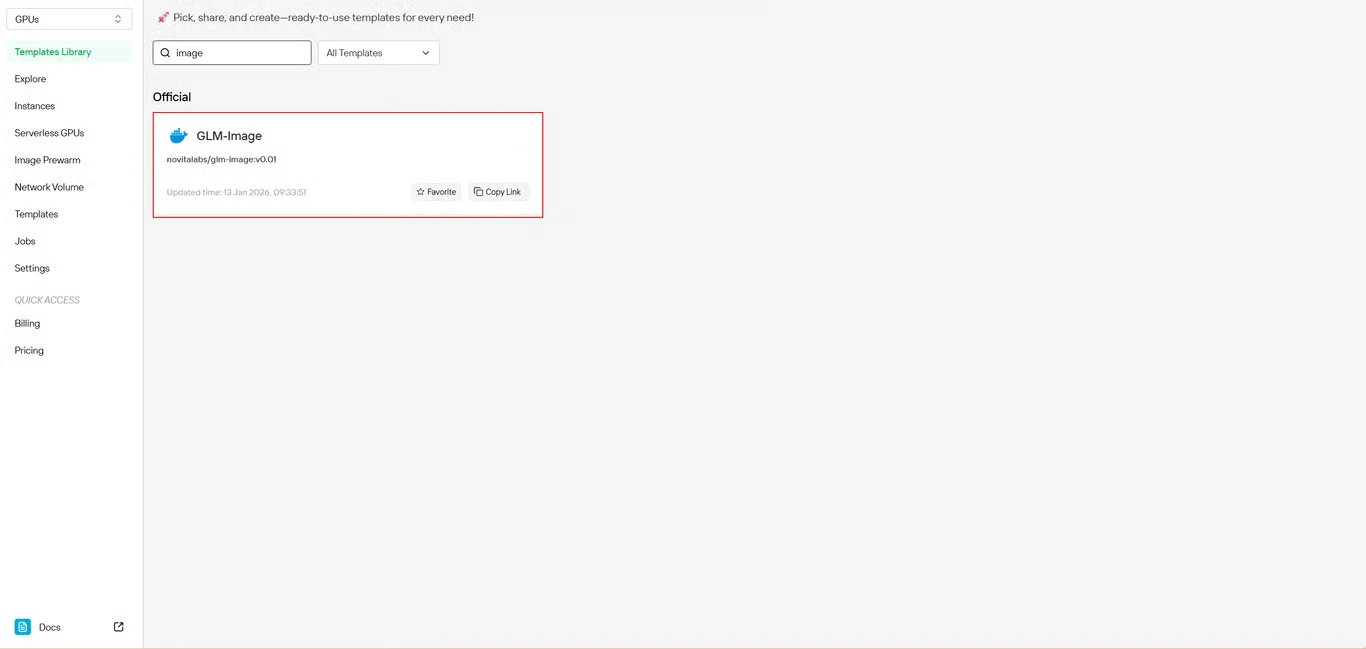
Schritt 2: GLM-Image-Vorlage auswählen
Suchen Sie GLM-Image im Vorlagenrepository. Die vorgefertigte Vorlage von Novita AI enthält alle erforderlichen Abhängigkeiten, sodass eine komplexe Umgebungseinrichtung entfällt.
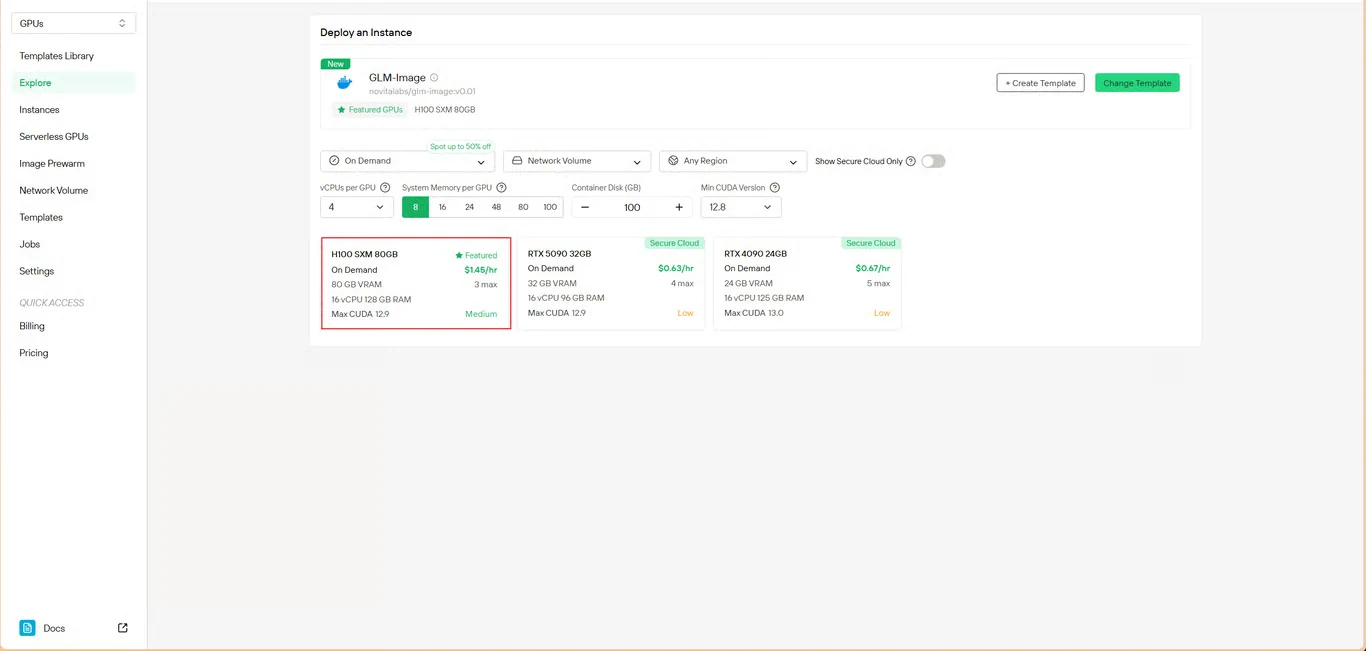
Schritt 3: Infrastruktur konfigurieren
Legen Sie Ihre Rechenparameter fest:
- Speicherzuweisung: Stellen Sie sicher, dass genügend VRAM für die Modellgewichte vorhanden ist
- Speicheranforderungen: Weisen Sie Speicherplatz für Modelldateien und generierte Bilder zu
- Netzwerkeinstellungen: Konfigurieren Sie diese entsprechend Ihren Zugriffsanforderungen
Klicken Sie auf Deploy, um mit Ihrer Konfiguration fortzufahren.
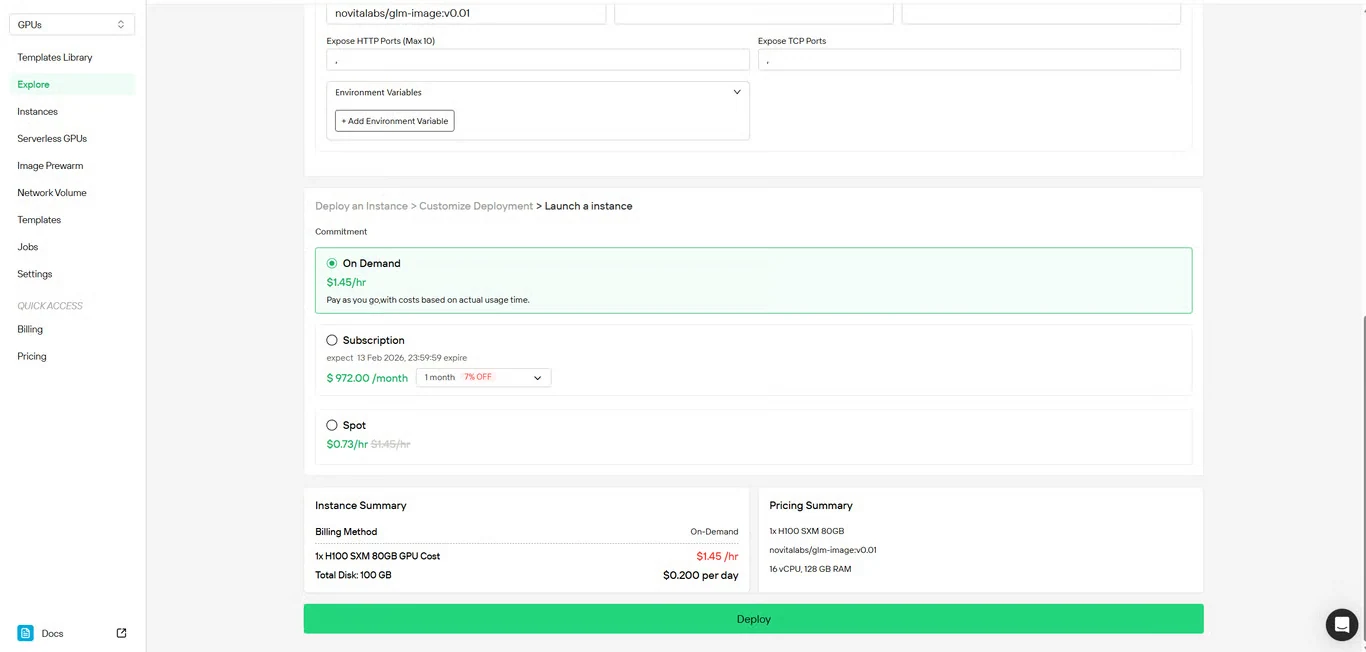
Schritt 4: Konfiguration überprüfen
Überprüfen Sie Ihre Setup-Details und die Kostenübersicht noch einmal. Wenn Sie zufrieden sind, klicken Sie auf Deploy, um die Instanzerstellung zu starten.
Schritt 5: Bereitstellung überwachen
Das System leitet Sie automatisch zur Instanzverwaltungsseite weiter. Ihre GLM-Image-Instanz wird im Hintergrund erstellt – keine manuelle Intervention erforderlich.
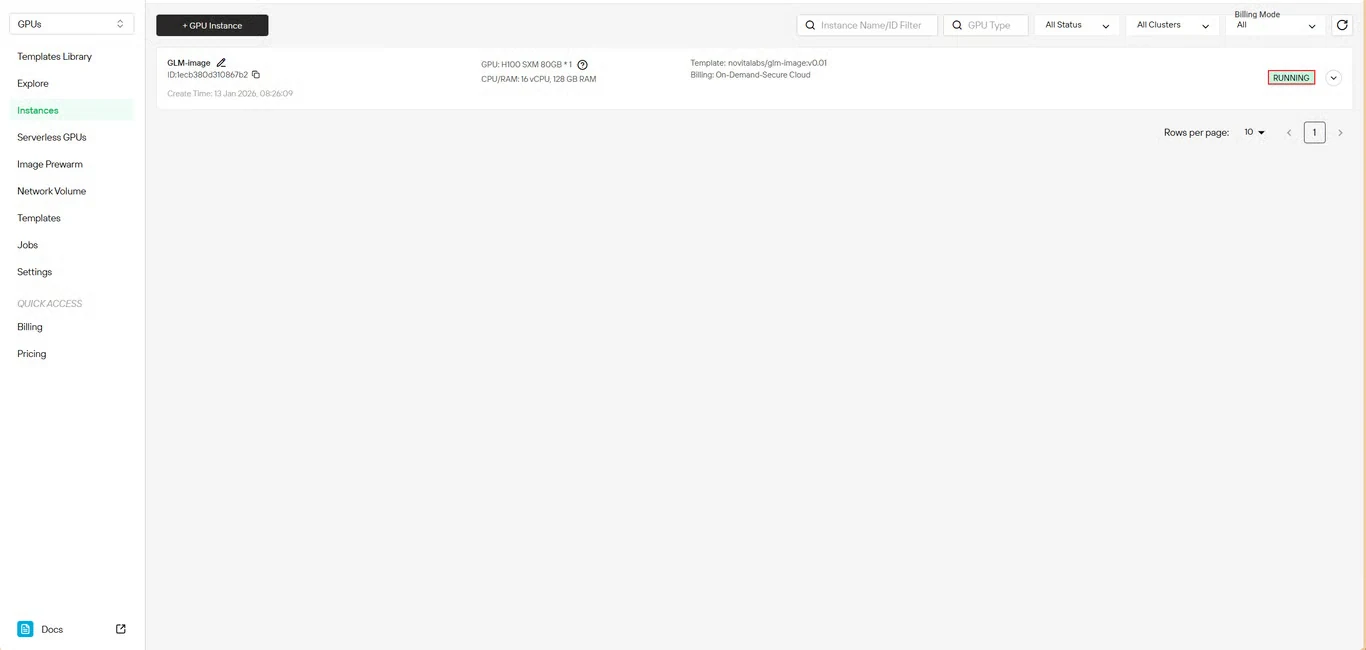
Schritt 6: Download-Fortschritt verfolgen
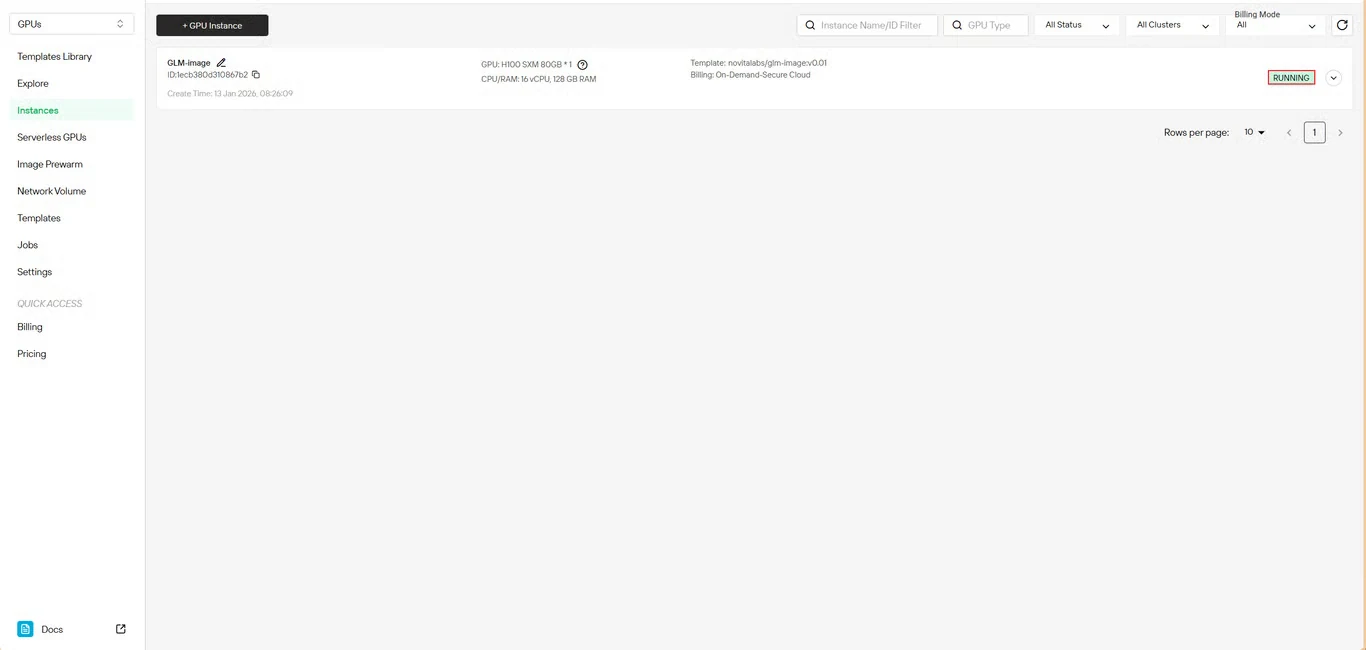
Überwachen Sie den Download-Status des Modells in Echtzeit. Der Status Ihrer Instanz wechselt von Pulling zu Running, sobald die Bereitstellung abgeschlossen ist. Klicken Sie auf das Pfeilsymbol neben dem Namen Ihrer Instanz, um detaillierte Fortschrittsinformationen zu erhalten.
Schritt 7: Dienststatus überprüfen
Klicken Sie auf die Schaltfläche Logs, um die Instanzprotokolle anzuzeigen und zu bestätigen, dass der GLM-Image-Dienst erfolgreich gestartet wurde. Suchen Sie nach Initialisierungsbestätigungsmeldungen, die anzeigen, dass das Modell für die Inferenz bereit ist.
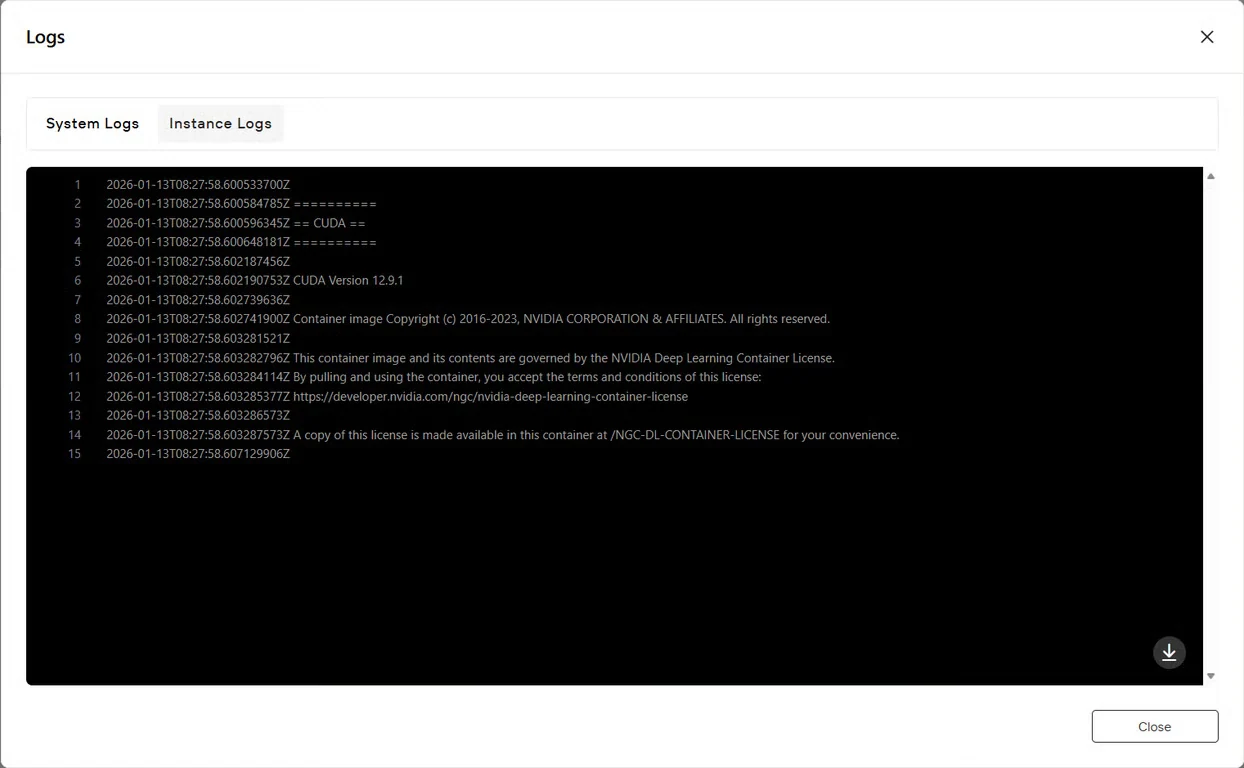
Erste Schritte
Beispiel text2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
prompt = "A beautifully designed modern food magazine style dessert recipe illustration, themed around a raspberry mousse cake. The overall layout is clean and bright, divided into four main areas: the top left features a bold black title 'Raspberry Mousse Cake Recipe Guide', with a soft-lit close-up photo of the finished cake on the right, showcasing a light pink cake adorned with fresh raspberries and mint leaves; the bottom left contains an ingredient list section, titled 'Ingredients' in a simple font, listing 'Flour 150g', 'Eggs 3', 'Sugar 120g', 'Raspberry puree 200g', 'Gelatin sheets 10g', 'Whipping cream 300ml', and 'Fresh raspberries', each accompanied by minimalist line icons (like a flour bag, eggs, sugar jar, etc.); the bottom right displays four equally sized step boxes, each containing high-definition macro photos and corresponding instructions, arranged from top to bottom as follows: Step 1 shows a whisk whipping white foam (with the instruction 'Whip egg whites to stiff peaks'), Step 2 shows a red-and-white mixture being folded with a spatula (with the instruction 'Gently fold in the puree and batter'), Step 3 shows pink liquid being poured into a round mold (with the instruction 'Pour into mold and chill for 4 hours'), Step 4 shows the finished cake decorated with raspberries and mint leaves (with the instruction 'Decorate with raspberries and mint'); a light brown information bar runs along the bottom edge, with icons on the left representing 'Preparation time: 30 minutes', 'Cooking time: 20 minutes', and 'Servings: 8'. The overall color scheme is dominated by creamy white and light pink, with a subtle paper texture in the background, featuring compact and orderly text and image layout with clear information hierarchy."
image = pipe(
prompt=prompt,
height=32 * 32,
width=36 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_t2i.png")
Sie können den Prompt in text2image.py anpassen, um ihn auszuführen, oder vorhandene Beispiele direkt verwenden.
python3 text2image
$ python3 text2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.47it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1391.52it/s, Materializing param=shared.weight]
Loading pipeline components...: 71%|██████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 5/7 [00:02<00:00, 2.91it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 359.59it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.02s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:11<00:00, 2.69it/s]
output_t2i.png
Beispiel image2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
from PIL import Image
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
image_path = "cond.jpg"
prompt = "Replace the background of the snow forest with an underground station featuring an automatic escalator."
image = Image.open(image_path).convert("RGB")
image = pipe(
prompt=prompt,
image=[image], # can input multiple images for multi-image-to-image generation such as [image, image1]
height=33 * 32,
width=32 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_i2i.png")
Sie können den Prompt und das Bild in text2image.py anpassen, um ihn auszuführen, oder vorhandene Beispiele direkt verwenden.
$ python3 image2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 360.88it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.46it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1426.62it/s, Materializing param=shared.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.03s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:10<00:00, 2.97it/s]
Anwendungsfälle für GLM-Image
Die hybride Architektur von GLM-Image macht es besonders effektiv für:
- E-Commerce: Produktvisualisierung und Variantengenerierung
- Marketing: Kampagnenkreationen und Social-Media-Inhalte
- Verlagswesen: Redaktionelle Illustrationen und Infografiken
- Design: Konzeptkunst und visuelles Prototyping
- Bildung: Anleitungsdiagramme und visuelle Lernmaterialien
Die Stärke des Modells bei wissensintensiver Generierung bedeutet, dass es komplexe Szenen mit spezifischen Anforderungen genau rendern kann – ideal für Projekte, die sowohl Kreativität als auch Präzision erfordern.
Erste Schritte mit GLM-Image auf Novita AI
Stellen Sie GLM-Image noch heute auf der GPU-Infrastruktur von Novita AI bereit und nutzen Sie unternehmensgerechte Bildgenerierungsfunktionen ohne die Komplexität einer manuellen Einrichtung. Besuchen Sie die GLM-Image-Vorlagenseite, um mit Ihrer Bereitstellung zu beginnen.
Novita AI ist eine führende KI-Cloud-Plattform, die Entwicklern benutzerfreundliche APIs sowie erschwingliche, zuverlässige GPU-Infrastruktur zum Erstellen und Skalieren von KI-Anwendungen bietet.



