

GLM-Image는 자동회귀(autoregressive)와 확산(diffusion) 아키텍처를 결합하여 시각적 충실도의 한계를 넓히는 AI 이미지 생성의 중요한 발전을 나타냅니다. AI 기반 시각 애플리케이션을 구축하는 개발자와 비즈니스에게 이 모델을 효율적으로 배포하는 것은 매우 중요하지만, 기존 설정 프로세스는 복잡한 종속성, 환경 구성, 인프라 관리를 수반합니다.
Novita AI는 사전 구성된 GPU 템플릿을 제공하여 이러한 장벽을 제거하므로 몇 시간이 아닌 몇 분 만에 GLM-Image를 배포할 수 있습니다. 이 가이드는 템플릿 선택부터 첫 번째 추론 실행까지의 전체 배포 프로세스와 프로덕션 워크로드를 위한 최적화 전략을 안내합니다.
콘텐츠 생성 도구를 프로토타이핑하든, 전자상거래 시각화 플랫폼을 구축하든, 고급 이미지 합성을 애플리케이션에 통합하든, 이 튜토리얼은 엔터프라이즈급 GPU 인프라에서 GLM-Image를 실행하는 데 필요한 모든 것을 제공합니다.
GLM-Image란?
GLM-Image는 자동회귀 및 확산 디코더 아키텍처를 결합하여 뛰어난 시각적 품질과 세밀한 디테일 렌더링을 제공하는 고급 이미지 생성 모델입니다. ZAI 팀이 개발한 이 하이브리드 접근 방식은 전통적인 잠재 확산 모델(LDM)에 대한 강력한 대안으로, 특히 지식 집약적 이미지 생성 시나리오에서 탁월합니다.
이 모델의 독특한 아키텍처는 업계 표준 접근 방식과 경쟁력 있는 성능을 유지하면서 매우 상세한 이미지를 생성할 수 있게 합니다. AI 기반 디자인 도구, 콘텐츠 제작 플랫폼 또는 시각 합성 애플리케이션을 구축하든, GLM-Image는 텍스트-이미지 및 이미지-이미지 생성 기능을 통해 유연성과 정밀성을 모두 제공합니다.
주요 기능:
- 탁월한 시각적 충실도를 위한 하이브리드 자동회귀 + 확산 아키텍처
- 세부 프롬프트 이해가 가능한 텍스트-이미지 생성
- 이미지-이미지 변환 및 스타일 전송
- 다중 이미지 조건부 생성
- 고해상도 출력 지원 (사용자 지정 가능한 크기)
전체 기술 사양 및 모델 문서는 공식 GLM-Image 저장소를 참조하세요.
Novita AI에서 GLM-Image를 배포해야 하는 이유
Novita AI의 GPU 인프라는 사전 구성된 템플릿, 즉시 배포, 확장 가능한 컴퓨팅 리소스를 통해 GLM-Image를 실행하기에 이상적인 환경을 제공합니다. 로컬 환경을 설정하거나 클라우드 인스턴스를 수동으로 관리하는 것과 달리, Novita AI는 템플릿 선택부터 추론 실행까지 전체 배포 프로세스를 간소화합니다.
단계별 배포 가이드
1단계: GPU 콘솔 액세스
Novita AI의 GPU 인터페이스로 이동하여 Get Started를 클릭해 배포 관리 대시보드에 진입합니다.
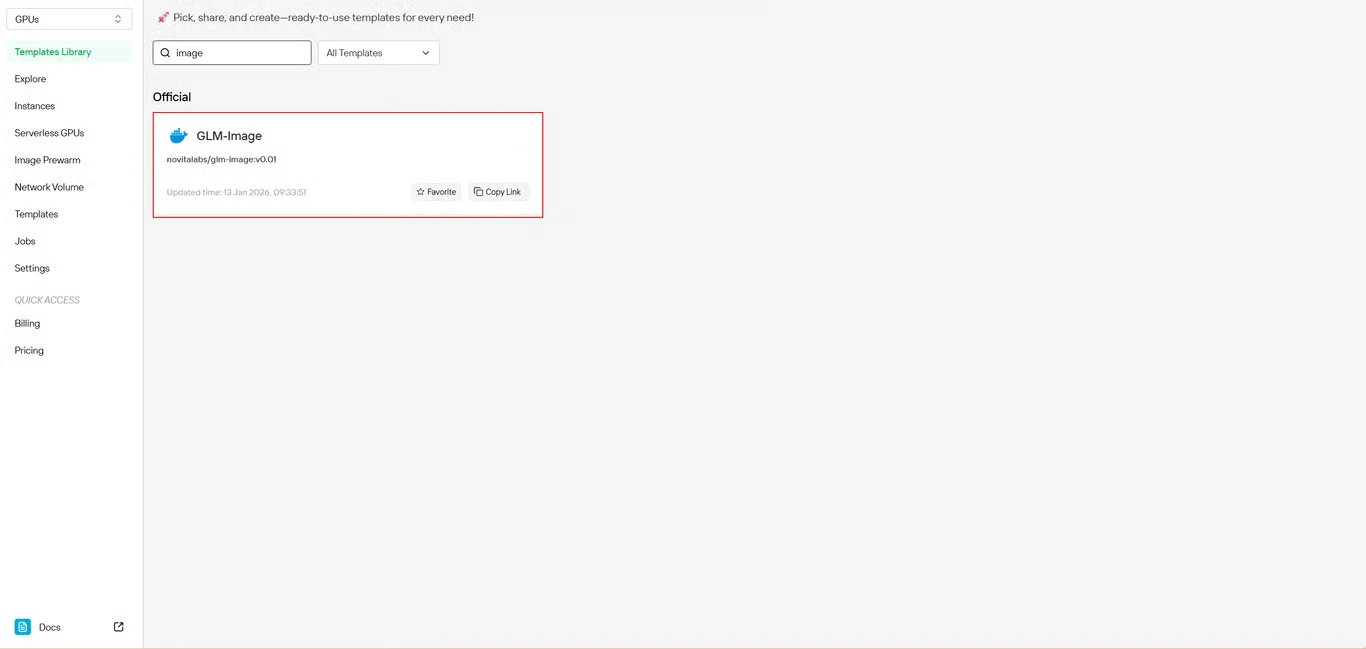
2단계: GLM-Image 템플릿 선택
템플릿 저장소에서 **GLM-Image**를 찾습니다. Novita AI의 사전 구축 템플릿은 모든 필수 종속성을 포함하므로 복잡한 환경 설정이 필요 없습니다.
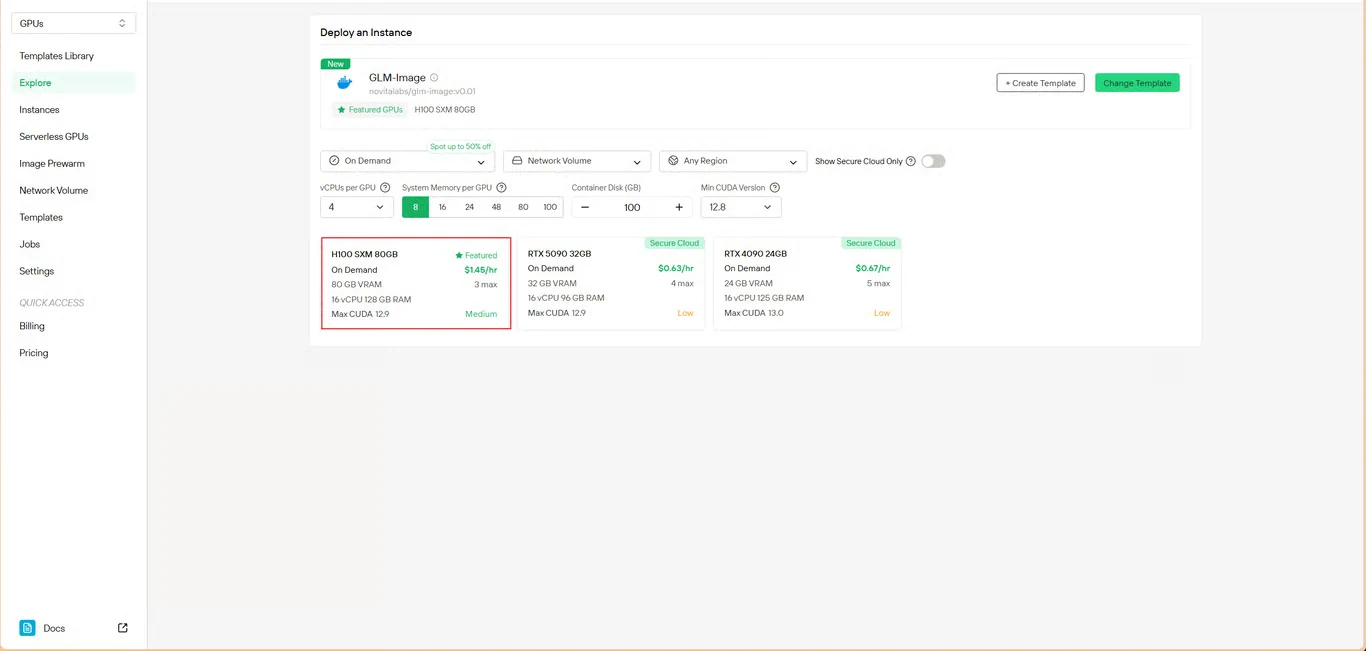
3단계: 인프라 구성
컴퓨팅 매개변수를 설정합니다.
- 메모리 할당: 모델 가중치에 충분한 VRAM 확보
- 스토리지 요구 사항: 모델 파일 및 생성된 이미지를 위한 공간 할당
- 네트워크 설정: 액세스 요구 사항에 따라 구성
Deploy를 클릭하여 구성을 진행합니다.
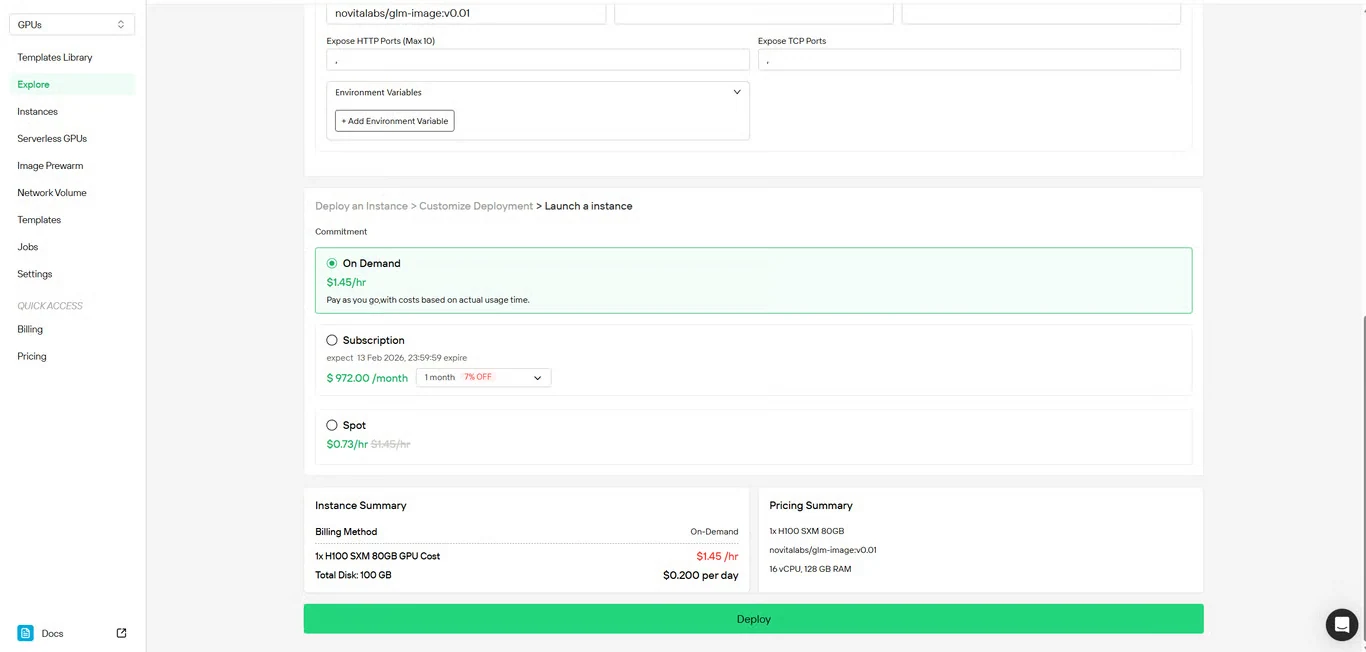
4단계: 구성 검토
설정 세부 정보와 비용 요약을 다시 확인합니다. 만족스러우면 Deploy를 클릭하여 인스턴스 생성을 시작합니다.
5단계: 배포 모니터링
시스템이 자동으로 인스턴스 관리 페이지로 리디렉션됩니다. GLM-Image 인스턴스는 백그라운드에서 생성되며 수동 개입이 필요하지 않습니다.
6단계: 다운로드 진행 상황 확인
모델 다운로드 상태를 실시간으로 모니터링합니다. 배포가 완료되면 인스턴스 상태가 Pulling에서 Running으로 전환됩니다. 인스턴스 이름 옆에 있는 화살표 아이콘을 클릭하면 자세한 진행 정보를 볼 수 있습니다.
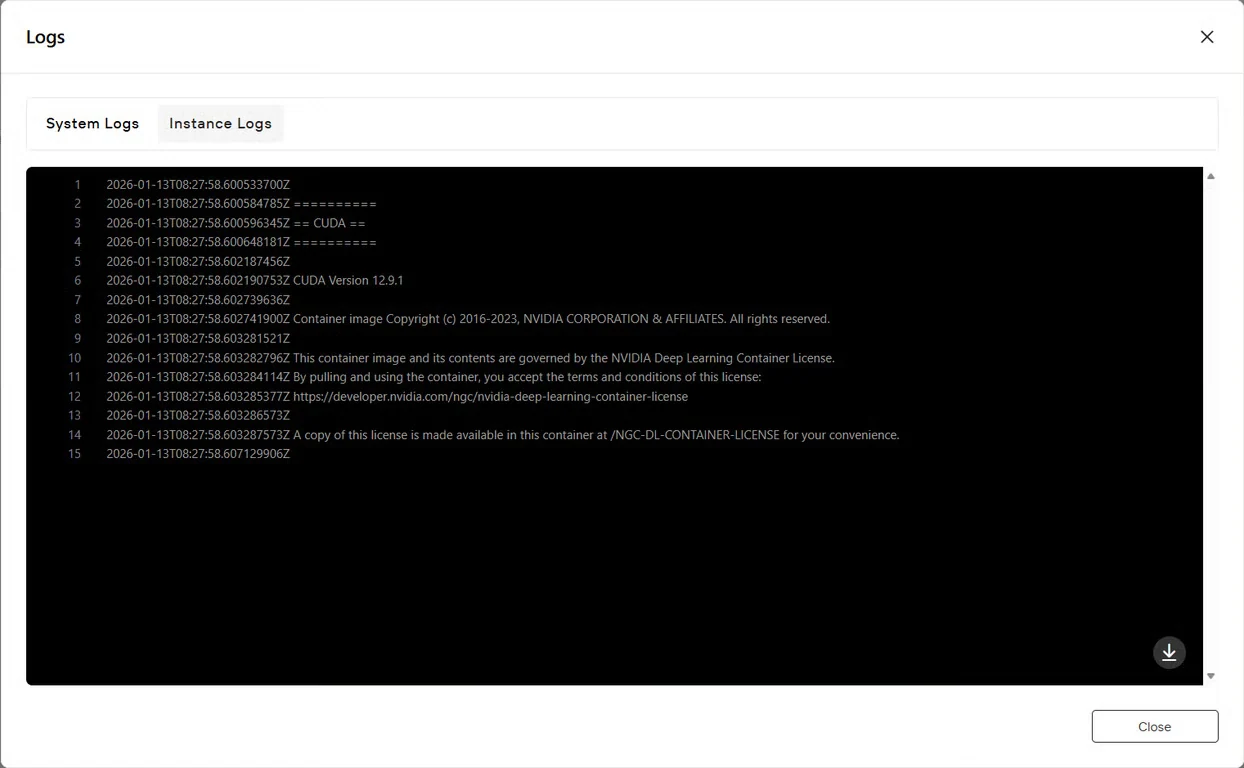
7단계: 서비스 상태 확인
Logs 버튼을 클릭하여 인스턴스 로그를 확인하고 GLM-Image 서비스가 성공적으로 시작되었는지 확인합니다. 모델이 추론 준비가 되었음을 나타내는 초기화 확인 메시지를 찾으세요.
시작하기
예제 text2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
prompt = "A beautifully designed modern food magazine style dessert recipe illustration, themed around a raspberry mousse cake. ..." # (원본 프롬프트는 번역하지 않음)
image = pipe(
prompt=prompt,
height=32 * 32,
width=36 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_t2i.png")
text2image.py에서 프롬프트를 수정하여 실행하거나 기존 예제를 그대로 사용할 수 있습니다.
$ python3 text2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.47it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1391.52it/s, Materializing param=shared.weight]
Loading pipeline components...: 71%|██████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 5/7 [00:02<00:00, 2.91it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 359.59it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.02s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:11<00:00, 2.69it/s]
output_t2i.png
예제 image2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
from PIL import Image
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
image_path = "cond.jpg"
prompt = "Replace the background of the snow forest with an underground station featuring an automatic escalator."
image = Image.open(image_path).convert("RGB")
image = pipe(
prompt=prompt,
image=[image], # can input multiple images for multi-image-to-image generation such as [image, image1]
height=33 * 32,
width=32 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_i2i.png")
text2image.py에서 프롬프트와 이미지를 수정하여 실행하거나 기존 예제를 그대로 사용할 수 있습니다.
$ python3 image2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 360.88it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.46it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1426.62it/s, Materializing param=shared.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.03s/it]
100%|███████████████████████████████████████████████████████████████████████████████████| 30/30 [00:10<00:00, 2.97it/s]
GLM-Image 사용 사례
GLM-Image의 하이브리드 아키텍처는 특히 다음과 같은 분야에서 효과적입니다:
- 전자상거래: 제품 시각화 및 변형 생성
- 마케팅: 캠페인 크리에이티브 및 소셜 미디어 콘텐츠
- 출판: 편집 일러스트 및 인포그래픽
- 디자인: 컨셉 아트 및 시각적 프로토타이핑
- 교육: 교육용 다이어그램 및 시각 학습 자료
지식 집약적 생성에서 이 모델의 강점은 특정 요구 사항이 있는 복잡한 장면을 정확하게 렌더링할 수 있다는 점이며, 이는 창의성과 정밀성을 모두 요구하는 프로젝트에 이상적입니다.
Novita AI에서 GLM-Image 시작하기
지금 Novita AI의 GPU 인프라에 GLM-Image를 배포하고, 수동 설정의 복잡성 없이 엔터프라이즈급 이미지 생성 기능을 활용하세요. GLM-Image 템플릿 페이지를 방문하여 배포를 시작하세요.
Novita AI는 개발자에게 사용하기 쉬운 API와 합리적인 가격의 안정적인 GPU 인프라를 제공하여 AI 애플리케이션을 구축하고 확장할 수 있도록 지원하는 선도적인 AI 클라우드 플랫폼입니다.



