

GLM-Image представляет собой значительный прорыв в области генерации изображений с помощью ИИ, сочетая авторегрессионные и диффузионные архитектуры для выхода за рамки визуальной точности. Для разработчиков и компаний, создающих визуальные приложения на базе ИИ, эффективное развертывание этой модели имеет решающее значение — но традиционные процессы настройки связаны со сложными зависимостями, конфигурацией окружения и управлением инфраструктурой.
Novita AI устраняет эти барьеры с помощью предварительно настроенных GPU-шаблонов, которые позволяют развернуть GLM-Image за несколько минут вместо часов. В этом руководстве мы подробно разберем полный процесс развертывания: от выбора шаблона до запуска первого инференса, а также стратегии оптимизации для рабочих нагрузок в продакшене.
Независимо от того, прототипируете ли вы инструмент для генерации контента, создаете платформу визуализации для электронной коммерции или интегрируете продвинутый синтез изображений в свое приложение, это руководство содержит все необходимое для запуска GLM-Image на корпоративной GPU-инфраструктуре.
Что такое GLM-Image?
GLM-Image — это продвинутая модель генерации изображений, которая сочетает авторегрессионные и диффузионные архитектуры декодера для обеспечения исключительного визуального качества и детализированной прорисовки. Разработанная командой ZAI, этот гибридный подход делает GLM-Image мощной альтернативой традиционным латентным диффузионным моделям (LDM), особенно преуспевая в сценариях генерации изображений, требующих больших объемов знаний.
Уникальная архитектура модели позволяет генерировать высокодетализированные изображения, сохраняя при этом конкурентоспособную производительность по сравнению с отраслевыми стандартными подходами. Независимо от того, создаете ли вы инструменты для дизайна на базе ИИ, платформы для создания контента или приложения для визуального синтеза, GLM-Image предлагает как гибкость, так и точность благодаря возможностям генерации из текста в изображение и из изображения в изображение.
Ключевые возможности:
- Гибридная авторегрессионная + диффузионная архитектура для превосходной визуальной точности
- Генерация изображений из текста с детальным пониманием промптов
- Преобразование изображений и перенос стиля
- Условная генерация по нескольким изображениям
- Поддержка вывода в высоком разрешении (настраиваемые размеры)
Полные технические спецификации и документацию к модели можно найти в официальном репозитории GLM-Image.
Почему стоит развертывать GLM-Image на Novita AI?
GPU-инфраструктура Novita AI предоставляет идеальную среду для запуска GLM-Image с предварительно настроенными шаблонами, мгновенным развертыванием и масштабируемыми вычислительными ресурсами. В отличие от настройки локальных окружений или ручного управления облачными инстансами, Novita AI оптимизирует весь процесс развертывания от выбора шаблона до запуска инференса.
Пошаговое руководство по развертыванию
Шаг 1: Доступ к консоли GPU
Перейдите в интерфейс GPU Novita AI и нажмите Начать работу, чтобы попасть в панель управления развертыванием.
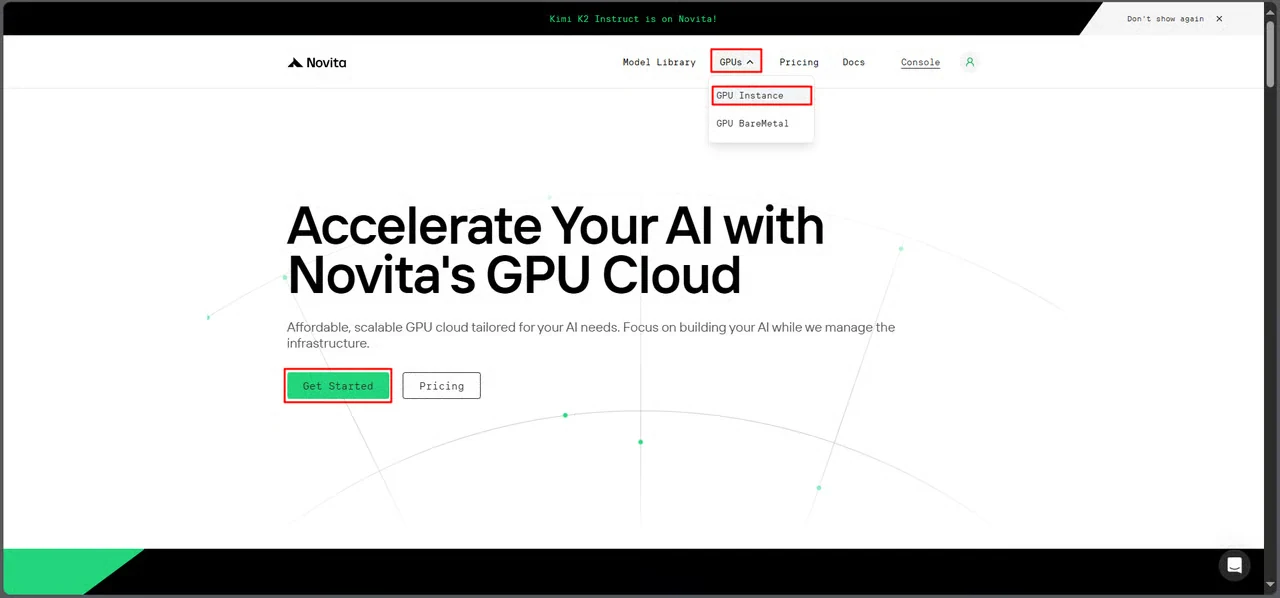
Шаг 2: Выбор шаблона GLM-Image
Найдите GLM-Image в репозитории шаблонов. Предварительно собранный шаблон Novita AI включает все необходимые зависимости, что исключает сложную настройку окружения.
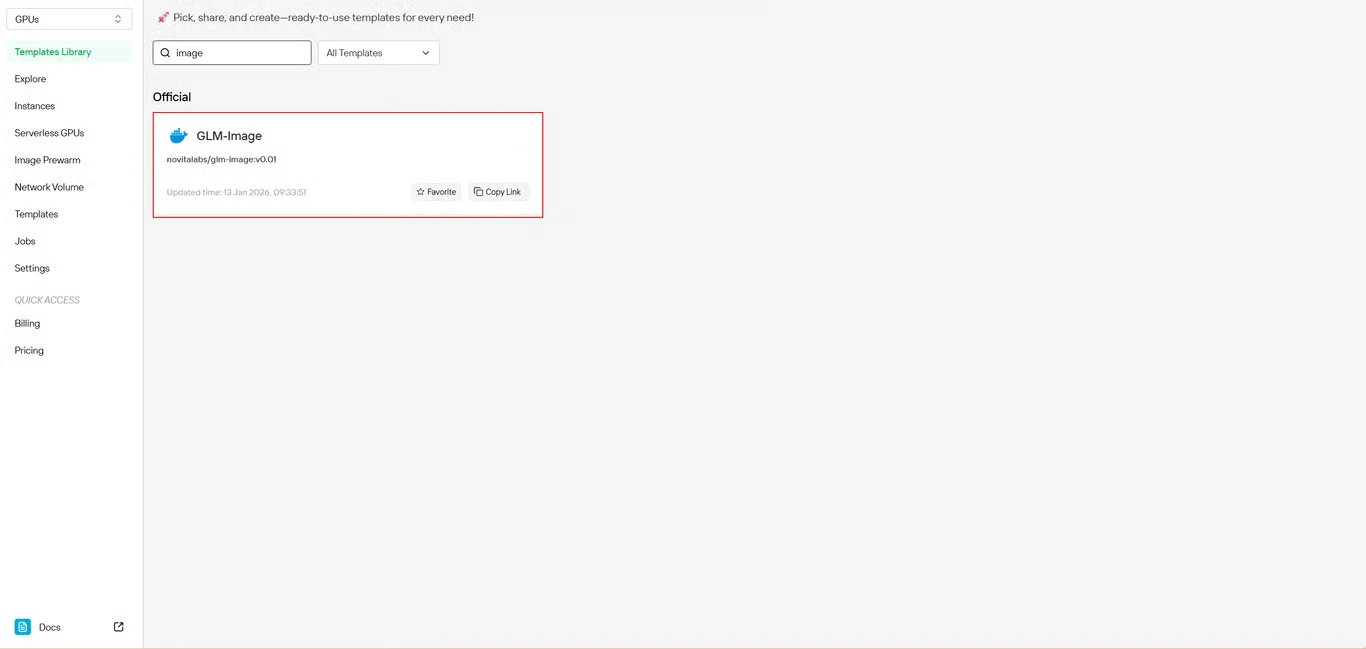
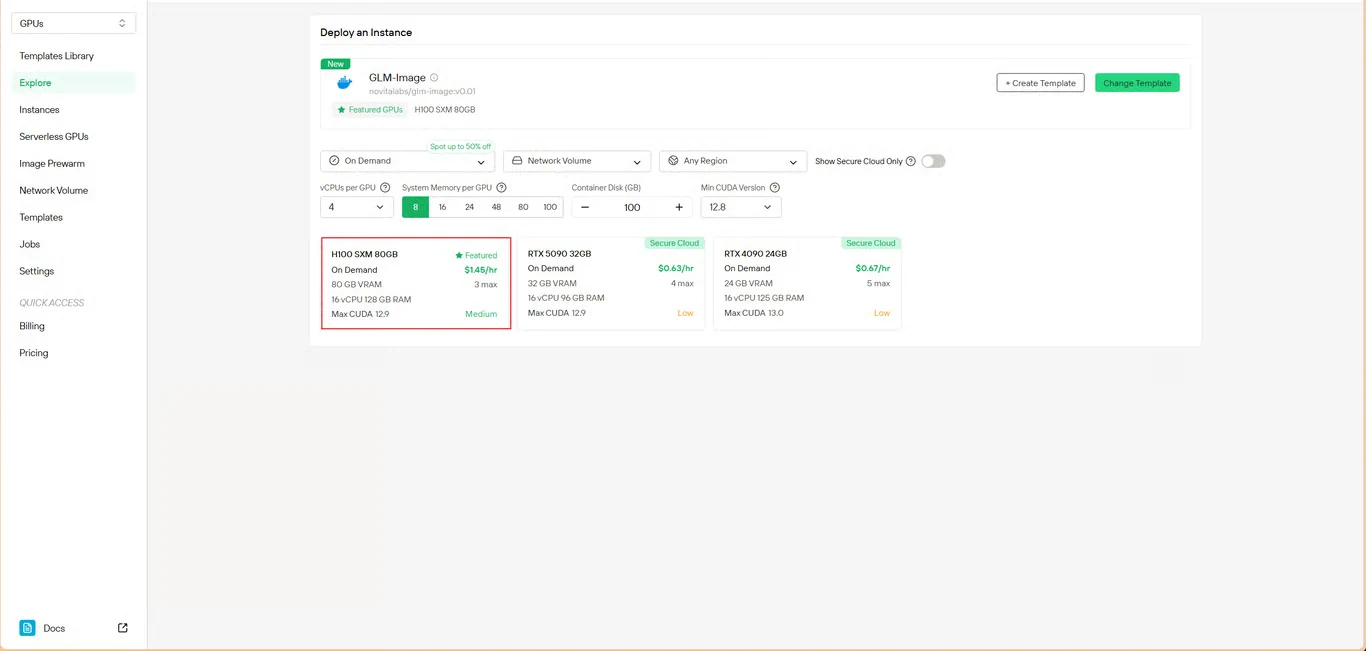
Шаг 3: Настройка инфраструктуры
Задайте параметры вычислений:
- Распределение памяти: Убедитесь, что выделено достаточно VRAM для весов модели
- Требования к хранилищу: Выделите место для файлов модели и сгенерированных изображений
- Сетевые настройки: Настройте в соответствии с вашими требованиями доступа
Нажмите Развернуть, чтобы продолжить настройку.
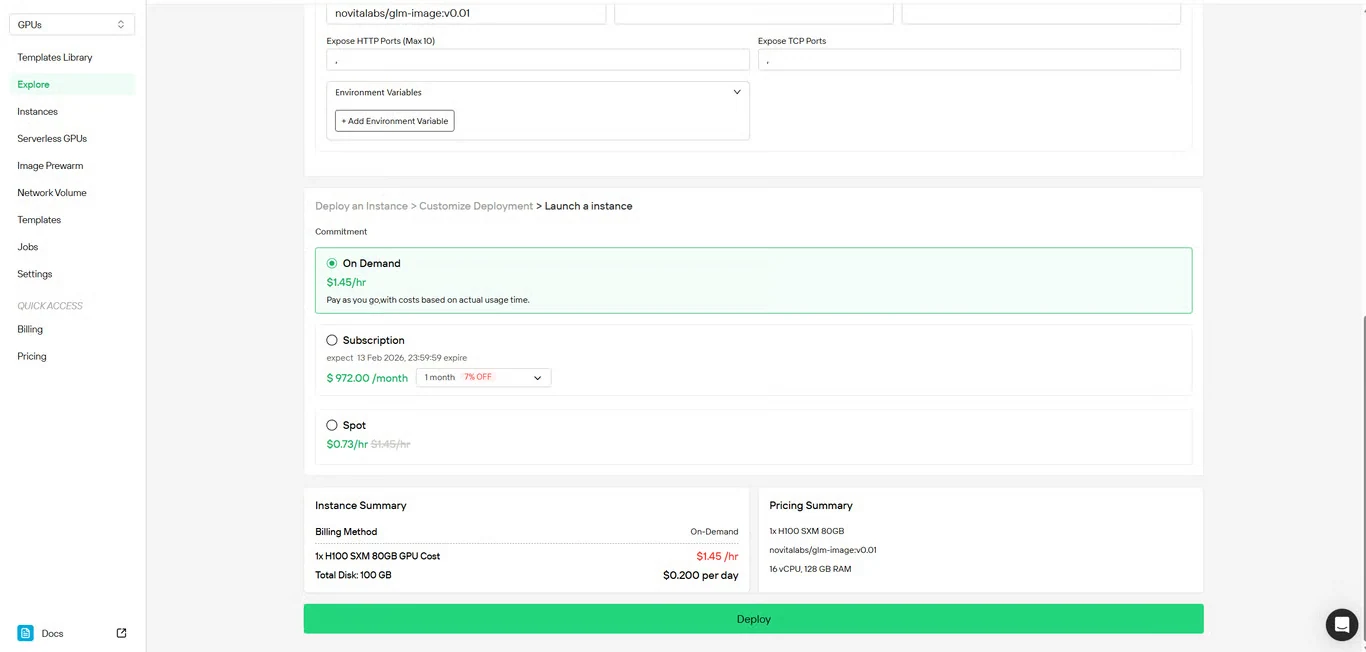
Шаг 4: Проверка конфигурации
Дважды проверьте детали вашей настройки и сводку по стоимости. Если все вас устраивает, нажмите Развернуть, чтобы начать создание инстанса.
Шаг 5: Мониторинг развертывания
Система автоматически перенаправит вас на страницу управления инстансами. Ваш инстанс GLM-Image будет создан в фоновом режиме — ручное вмешательство не требуется.
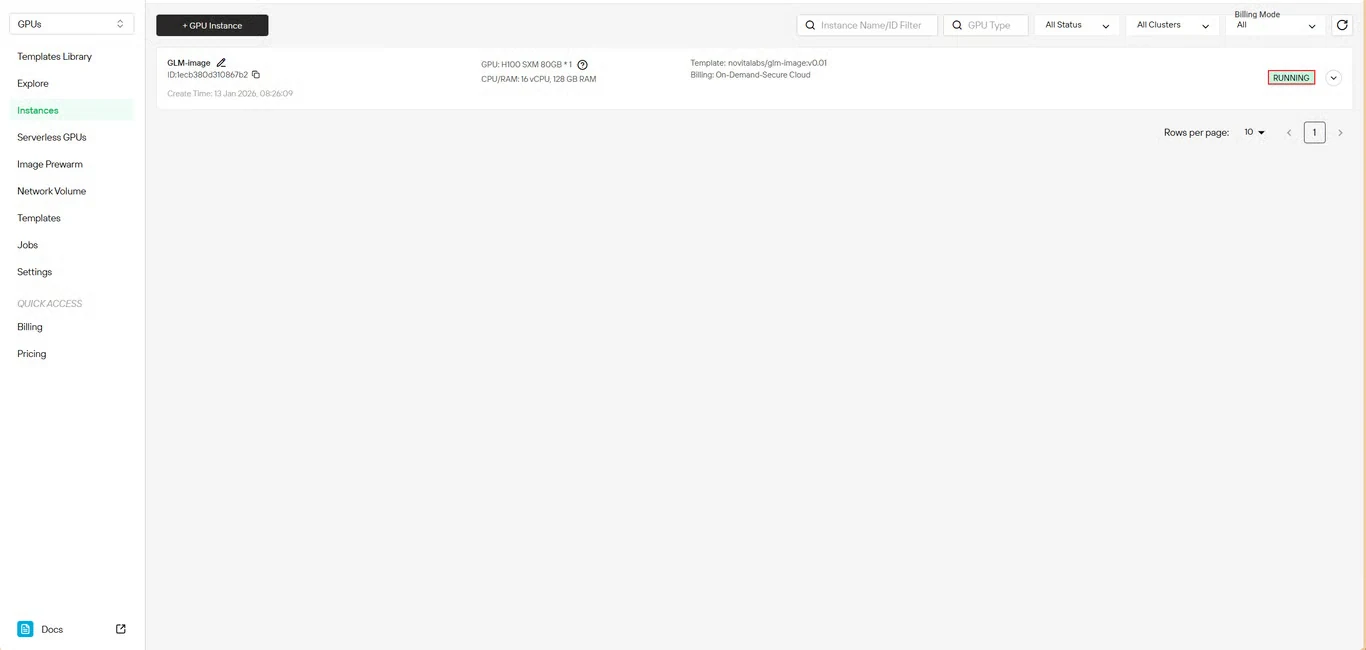
Шаг 6: Отслеживание прогресса загрузки
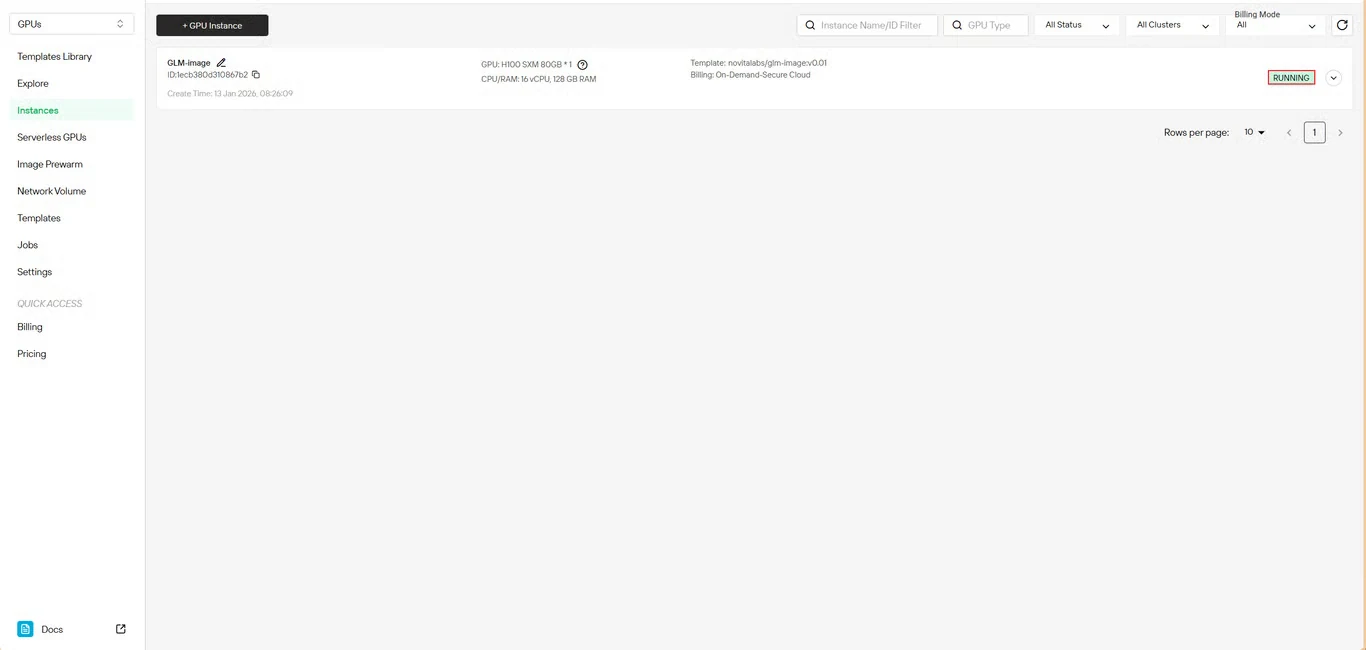
Отслеживайте статус загрузки модели в реальном времени. Статус вашего инстанса изменится с Загрузка на Работает после завершения развертывания. Нажмите на иконку стрелки рядом с именем вашего инстанса, чтобы получить подробную информацию о прогрессе.
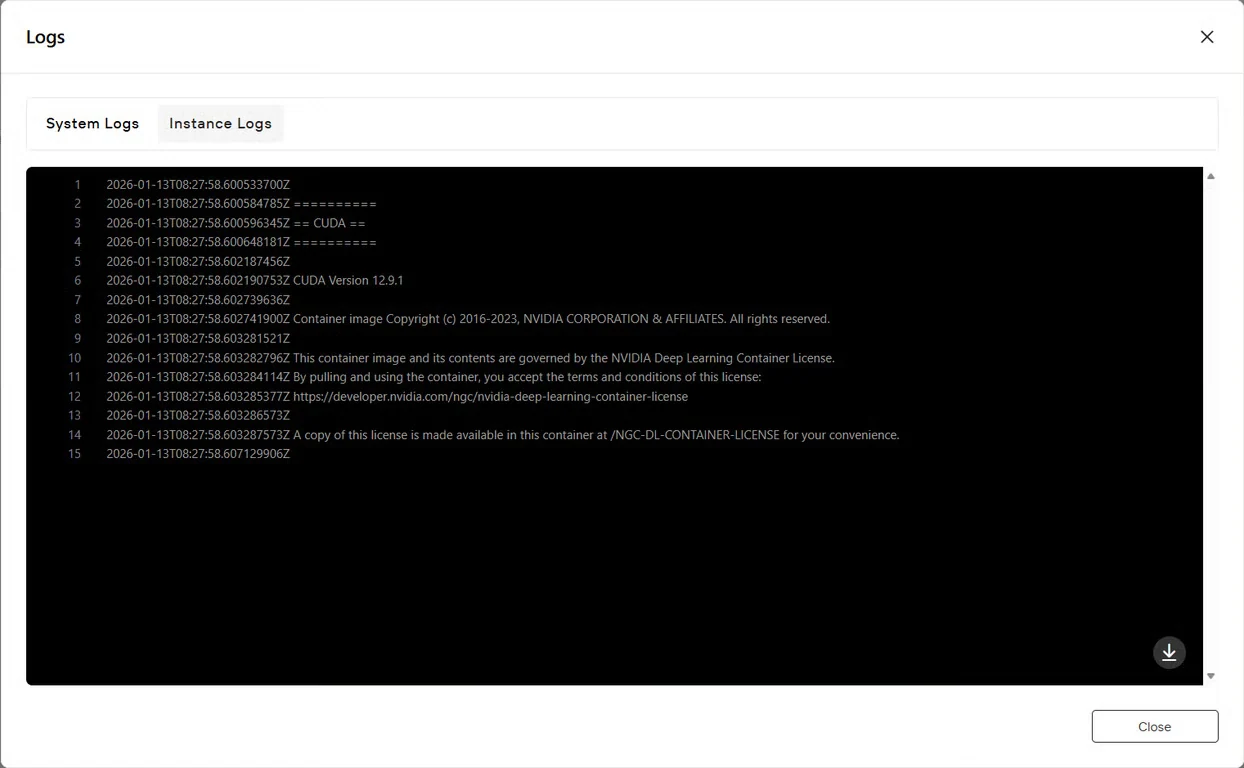
Шаг 7: Проверка статуса сервиса
Нажмите кнопку Логи, чтобы просмотреть логи инстанса и убедиться, что сервис GLM-Image успешно запустился. Ищите сообщения с подтверждением инициализации, указывающие, что модель готова к инференсу.
Как начать работу
Пример файла text2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
prompt = "A beautifully designed modern food magazine style dessert recipe illustration, themed around a raspberry mousse cake. The overall layout is clean and bright, divided into four main areas: the top left features a bold black title 'Raspberry Mousse Cake Recipe Guide', with a soft-lit close-up photo of the finished cake on the right, showcasing a light pink cake adorned with fresh raspberries and mint leaves; the bottom left contains an ingredient list section, titled 'Ingredients' in a simple font, listing 'Flour 150g', 'Eggs 3', 'Sugar 120g', 'Raspberry puree 200g', 'Gelatin sheets 10g', 'Whipping cream 300ml', and 'Fresh raspberries', each accompanied by minimalist line icons (like a flour bag, eggs, sugar jar, etc.); the bottom right displays four equally sized step boxes, each containing high-definition macro photos and corresponding instructions, arranged from top to bottom as follows: Step 1 shows a whisk whipping white foam (with the instruction 'Whip egg whites to stiff peaks'), Step 2 shows a red-and-white mixture being folded with a spatula (with the instruction 'Gently fold in the puree and batter'), Step 3 shows pink liquid being poured into a round mold (with the instruction 'Pour into mold and chill for 4 hours'), Step 4 shows the finished cake decorated with raspberries and mint leaves (with the instruction 'Decorate with raspberries and mint'); a light brown information bar runs along the bottom edge, with icons on the left representing 'Preparation time: 30 minutes', 'Cooking time: 20 minutes', and 'Servings: 8'. The overall color scheme is dominated by creamy white and light pink, with a subtle paper texture in the background, featuring compact and orderly text and image layout with clear information hierarchy."
image = pipe(
prompt=prompt,
height=32 * 32,
width=36 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_t2i.png")
Вы можете изменить промпт в файле text2image.py для запуска или использовать существующие примеры для прямого запуска.
python3 text2image
$ python3 text2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.47it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1391.52it/s, Materializing param=shared.weight]
Loading pipeline components...: 71%|██████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 5/7 [00:02<00:00, 2.91it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 359.59it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.02s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:11<00:00, 2.69it/s]
output_t2i.png
Пример файла image2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
from PIL import Image
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
image_path = "cond.jpg"
prompt = "Replace the background of the snow forest with an underground station featuring an automatic escalator."
image = Image.open(image_path).convert("RGB")
image = pipe(
prompt=prompt,
image=[image], # can input multiple images for multi-image-to-image generation such as [image, image1]
height=33 * 32,
width=32 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_i2i.png")
Вы можете изменить промпт и изображение в файле text2image.py для запуска или использовать существующие примеры для прямого запуска.
$ python3 image2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 360.88it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.46it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1426.62it/s, Materializing param=shared.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.03s/it]
100%|███████████████████████████████████████████████████████████████████████████████████| 30/30 [00:10<00:00, 2.97it/s]
Сценарии использования GLM-Image
Гибридная архитектура GLM-Image делает ее особенно эффективной для:
- Электронная коммерция: Визуализация продуктов и генерация вариантов
- Маркетинг: Креатив для рекламных кампаний и контент для социальных сетей
- Издательское дело: Редакционные иллюстрации и инфографика
- Дизайн: Концепт-арт и визуальное прототипирование
- Образование: Обучающие диаграммы и визуальные учебные материалы
Сильные стороны модели в генерации, требующей больших объемов знаний, означают, что она может точно рендерить сложные сцены с конкретными требованиями — идеально для проектов, требующих одновременно креативности и точности.
Начните работу с GLM-Image на Novita AI
Разверните GLM-Image на GPU-инфраструктуре Novita AI уже сегодня и получите доступ к возможностям генерации изображений корпоративного уровня без сложностей ручной настройки. Перейдите на страницу шаблона GLM-Image, чтобы начать развертывание.
Novita AI — ведущая облачная платформа для ИИ, которая предоставляет разработчикам простые в использовании API и доступную, надежную GPU-инфраструктуру для создания и масштабирования ИИ-приложений.



