

O GLM-Image representa um avanço significativo na geração de imagens por IA, combinando arquiteturas autoregressivas e de difusão para expandir os limites da fidelidade visual. Para desenvolvedores e empresas que criam aplicativos visuais alimentados por IA, implantar esse modelo de forma eficiente é crucial — mas os processos de configuração tradicionais envolvem dependências complexas, configuração de ambiente e gerenciamento de infraestrutura.
A Novita AI elimina essas barreiras com modelos de GPU pré-configurados que permitem que você implante o GLM-Image em minutos, em vez de horas. Este guia orienta você por todo o processo de implantação, da seleção do modelo à execução da sua primeira inferência, além de estratégias de otimização para cargas de trabalho de produção.
Seja você prototipando uma ferramenta de geração de conteúdo, construindo uma plataforma de visualização para e-commerce ou integrando síntese de imagens avançada ao seu aplicativo, este tutorial fornece tudo o que você precisa para colocar o GLM-Image em funcionamento em infraestrutura GPU de nível empresarial.
O que é o GLM-Image?
O GLM-Image é um modelo avançado de geração de imagens que combina arquiteturas de decodificador autoregressivo e de difusão para entregar qualidade visual excepcional e renderização de detalhes refinados. Desenvolvido pela equipe ZAI, essa abordagem híbrida posiciona o GLM-Image como uma alternativa poderosa aos Modelos de Difusão Latente (LDM) tradicionais, se destacando especialmente em cenários de geração de imagens que exigem muito conhecimento.
A arquitetura exclusiva do modelo permite gerar imagens altamente detalhadas mantendo um desempenho competitivo em comparação com abordagens padrão da indústria. Seja você construindo ferramentas de design alimentadas por IA, plataformas de criação de conteúdo ou aplicativos de síntese visual, o GLM-Image oferece flexibilidade e precisão por meio de suas capacidades de geração de texto para imagem e de imagem para imagem.
Principais recursos:
- Arquitetura híbrida autoregressiva + difusão para fidelidade visual superior
- Geração de texto para imagem com compreensão detalhada de prompts
- Transformação de imagem para imagem e transferência de estilo
- Geração condicional de múltiplas imagens
- Suporte a saída em alta resolução (dimensões personalizáveis)
Para especificações técnicas completas e documentação do modelo, acesse o repositório oficial do GLM-Image.
Por que implantar o GLM-Image na Novita AI?
A infraestrutura GPU da Novita AI fornece o ambiente ideal para executar o GLM-Image, com modelos pré-configurados, implantação instantânea e recursos de computação escaláveis. Ao contrário de configurar ambientes locais ou gerenciar instâncias de nuvem manualmente, a Novita AI simplifica todo o processo de implantação, da seleção do modelo à execução de inferências.
Guia de Implantação Passo a Passo
Passo 1: Acesse o Console GPU
Navegue até a interface de GPU da Novita AI e clique em Começar para acessar o painel de gerenciamento de implantações.
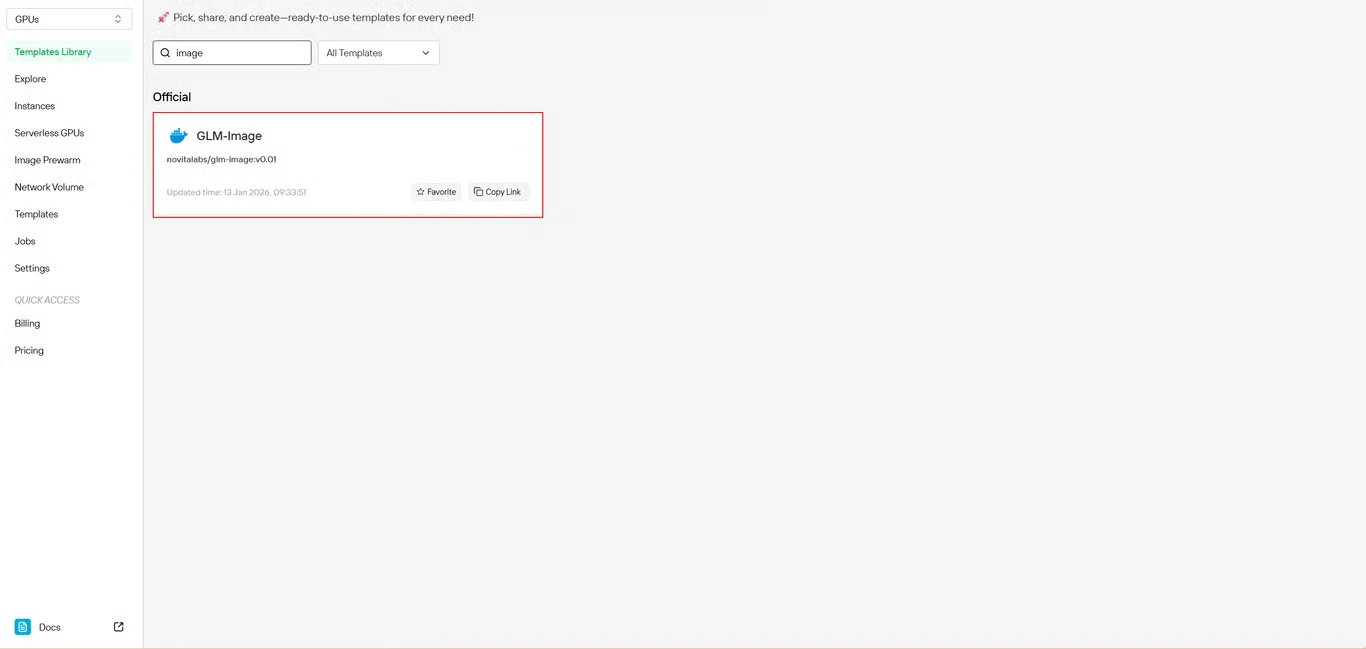
Passo 2: Selecione o Modelo do GLM-Image
Localize o GLM-Image no repositório de modelos. O modelo pré-construído da Novita AI inclui todas as dependências necessárias, eliminando a configuração complexa de ambiente.
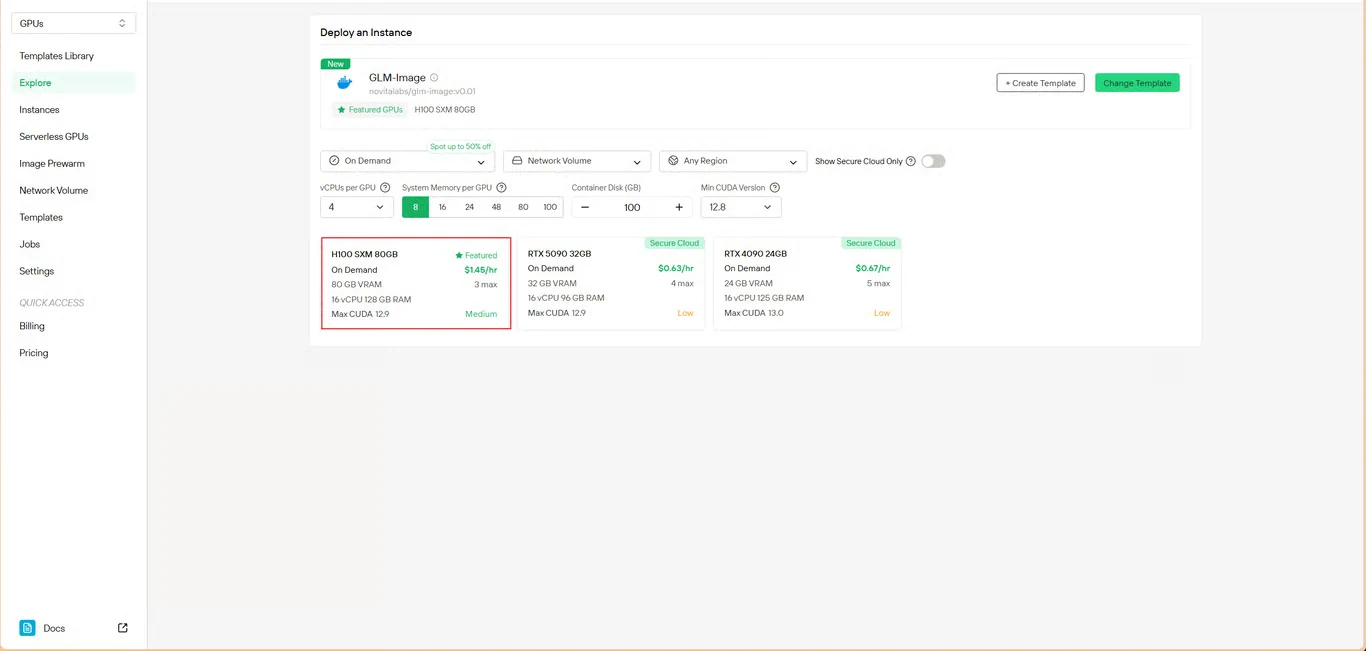
Passo 3: Configure a Infraestrutura
Defina seus parâmetros de computação:
- Alocação de memória: Garanta VRAM suficiente para os pesos do modelo
- Requisitos de armazenamento: Aloque espaço para arquivos de modelo e imagens geradas
- Configurações de rede: Ajuste de acordo com seus requisitos de acesso
Clique em Implantar para prosseguir com sua configuração.
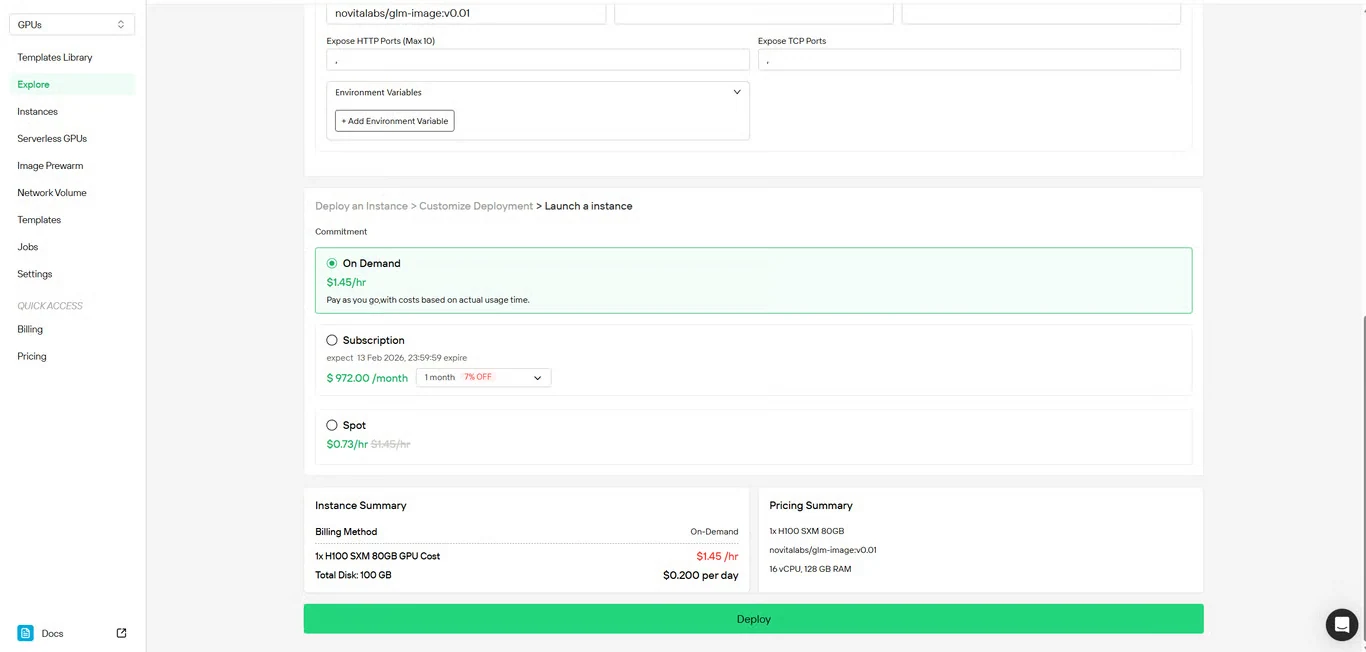
Passo 4: Revise a Configuração
Verifique novamente os detalhes da sua configuração e o resumo de custos. Quando estiver satisfeito, clique em Implantar para iniciar a criação da instância.
Passo 5: Monitore a Implantação
O sistema redireciona você automaticamente para a página de gerenciamento de instâncias. Sua instância do GLM-Image será criada em segundo plano — nenhuma intervenção manual é necessária.
Passo 6: Acompanhe o Progresso do Download
Monitore o status de download do modelo em tempo real. O status da sua instância mudará de Puxando para Em execução assim que a implantação for concluída. Clique no ícone de seta ao lado do nome da sua instância para obter informações detalhadas de progresso.
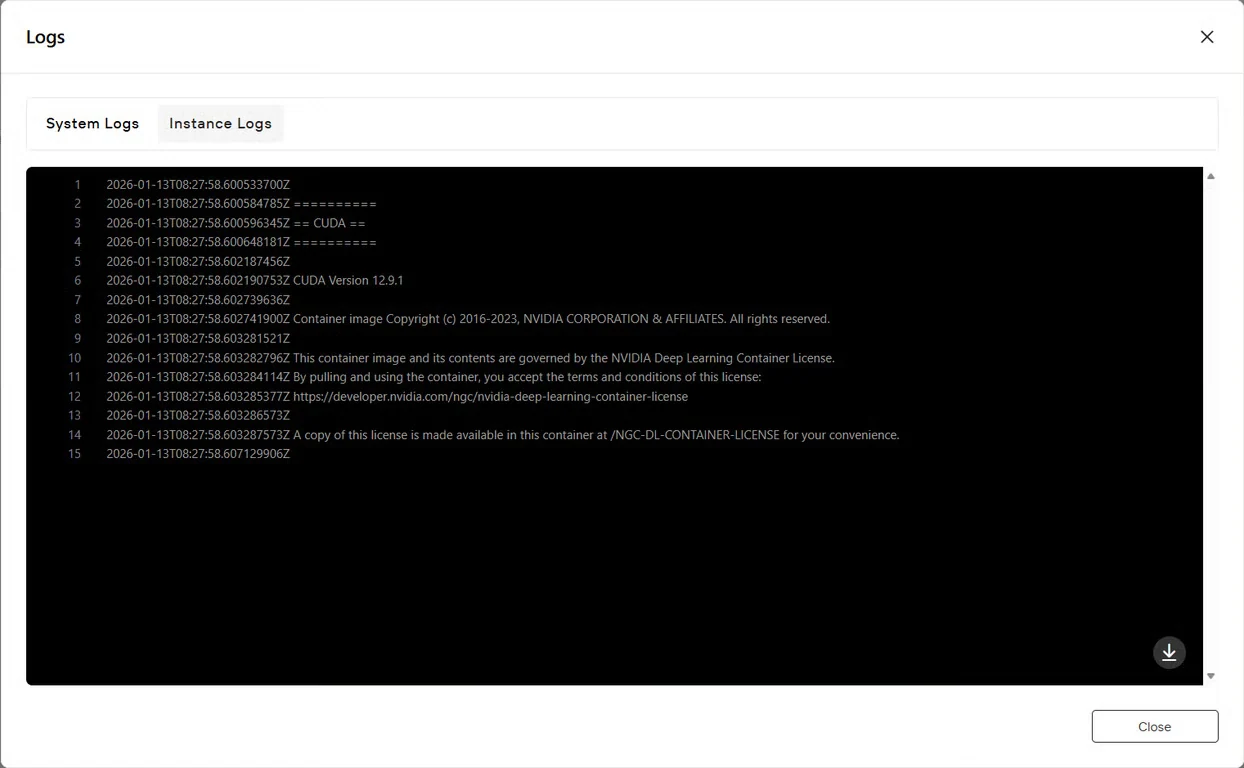
Passo 7: Verifique o Status do Serviço
Clique no botão Logs para visualizar os registros da instância e confirmar que o serviço do GLM-Image foi iniciado com sucesso. Procure por mensagens de confirmação de inicialização que indicam que o modelo está pronto para inferência.
Como começar
exemplo text2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
prompt = "A beautifully designed modern food magazine style dessert recipe illustration, themed around a raspberry mousse cake. The overall layout is clean and bright, divided into four main areas: the top left features a bold black title 'Raspberry Mousse Cake Recipe Guide', with a soft-lit close-up photo of the finished cake on the right, showcasing a light pink cake adorned with fresh raspberries and mint leaves; the bottom left contains an ingredient list section, titled 'Ingredients' in a simple font, listing 'Flour 150g', 'Eggs 3', 'Sugar 120g', 'Raspberry puree 200g', 'Gelatin sheets 10g', 'Whipping cream 300ml', and 'Fresh raspberries', each accompanied by minimalist line icons (like a flour bag, eggs, sugar jar, etc.); the bottom right displays four equally sized step boxes, each containing high-definition macro photos and corresponding instructions, arranged from top to bottom as follows: Step 1 shows a whisk whipping white foam (with the instruction 'Whip egg whites to stiff peaks'), Step 2 shows a red-and-white mixture being folded with a spatula (with the instruction 'Gently fold in the puree and batter'), Step 3 shows pink liquid being poured into a round mold (with the instruction 'Pour into mold and chill for 4 hours'), Step 4 shows the finished cake decorated with raspberries and mint leaves (with the instruction 'Decorate with raspberries and mint'); a light brown information bar runs along the bottom edge, with icons on the left representing 'Preparation time: 30 minutes', 'Cooking time: 20 minutes', and 'Servings: 8'. The overall color scheme is dominated by creamy white and light pink, with a subtle paper texture in the background, featuring compact and orderly text and image layout with clear information hierarchy."
image = pipe(
prompt=prompt,
height=32 * 32,
width=36 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_t2i.png")
Você pode modificar o prompt no text2image.py para executar ou usar os exemplos existentes para rodar diretamente.
python3 text2image
$ python3 text2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.47it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1391.52it/s, Materializing param=shared.weight]
Loading pipeline components...: 71%|██████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 5/7 [00:02<00:00, 2.91it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 359.59it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.02s/it]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30/30 [00:11<00:00, 2.69it/s]
output_t2i.png
exemplo image2image.py
import torch
from diffusers.pipelines.glm_image import GlmImagePipeline
from PIL import Image
pipe = GlmImagePipeline.from_pretrained("zai-org/GLM-Image", torch_dtype=torch.bfloat16, device_map="cuda")
image_path = "cond.jpg"
prompt = "Replace the background of the snow forest with an underground station featuring an automatic escalator."
image = Image.open(image_path).convert("RGB")
image = pipe(
prompt=prompt,
image=[image], # can input multiple images for multi-image-to-image generation such as [image, image1]
height=33 * 32,
width=32 * 32,
num_inference_steps=30,
guidance_scale=1.5,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("output_i2i.png")
Você pode modificar o prompt e a imagem no text2image.py para executar ou usar os exemplos existentes para rodar diretamente.
python3 image2image.py
$ python3 image2image.py
Couldn't connect to the Hub: Cannot reach https://huggingface.co/api/models/zai-org/GLM-Image: offline mode is enabled. To disable it, please unset the `HF_HUB_OFFLINE` environment variable..
Will try to load from local cache.
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████| 1011/1011 [00:02<00:00, 360.88it/s, Materializing param=model.vqmodel.quantize.embedding.weight]
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:02<00:00, 1.46it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1426.62it/s, Materializing param=shared.weight]
Loading pipeline components...: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.03s/it]
100%|███████████████████████████████████████████████████████████████████████████████████| 30/30 [00:10<00:00, 2.97it/s]
Casos de Uso do GLM-Image
A arquitetura híbrida do GLM-Image o torna particularmente eficaz para:
- E-commerce: Visualização de produtos e geração de variantes
- Marketing: Criativos de campanha e conteúdo para redes sociais
- Publicação: Ilustrações editoriais e infográficos
- Design: Arte conceitual e prototipagem visual
- Educação: Diagramas instrucionais e materiais de aprendizado visuais
O ponto forte do modelo na geração que exige muito conhecimento significa que ele pode renderizar cenas complexas com requisitos específicos com precisão — ideal para projetos que exigem tanto criatividade quanto precisão.
Comece a Usar o GLM-Image na Novita AI
Implante o GLM-Image na infraestrutura GPU da Novita AI hoje e acesse recursos de geração de imagens de nível empresarial sem a complexidade da configuração manual. Acesse a página do modelo do GLM-Image para iniciar sua implantação.
A Novita AI é uma plataforma de nuvem de IA líder que fornece aos desenvolvedores APIs fáceis de usar e infraestrutura GPU acessível e confiável para construir e escalar aplicativos de IA.



