

Developers today struggle to turn complex visual documents into reliable, structured inputs for agents and LLM workflows. This article explains why advanced OCR is now mandatory, how DeepSeek-OCR 2 solves layout and reading-order failures, and how to deploy it in production with predictable, low API and GPU costs.
Why Modern Models Urgently Need Advanced OCR?
Optical character recognition (OCR) converts visual text into machine-encoded text and structured representations, enabling search, indexing, semantic parsing, editing, and integration with language-centric workflows. Traditional OCR focused on character-level extraction, but emerging AI workflows require richer document understanding, including layout and semantic context to feed into vision-language systems or retrieval-augmented generation. OCR remains essential for documents, forms, tables, invoices, research papers, and scene text—use cases ubiquitous in industry.

From analyticsvidhya
Core Innovations in DeepSeek OCR 2
| Innovation | Description | Impact |
|---|---|---|
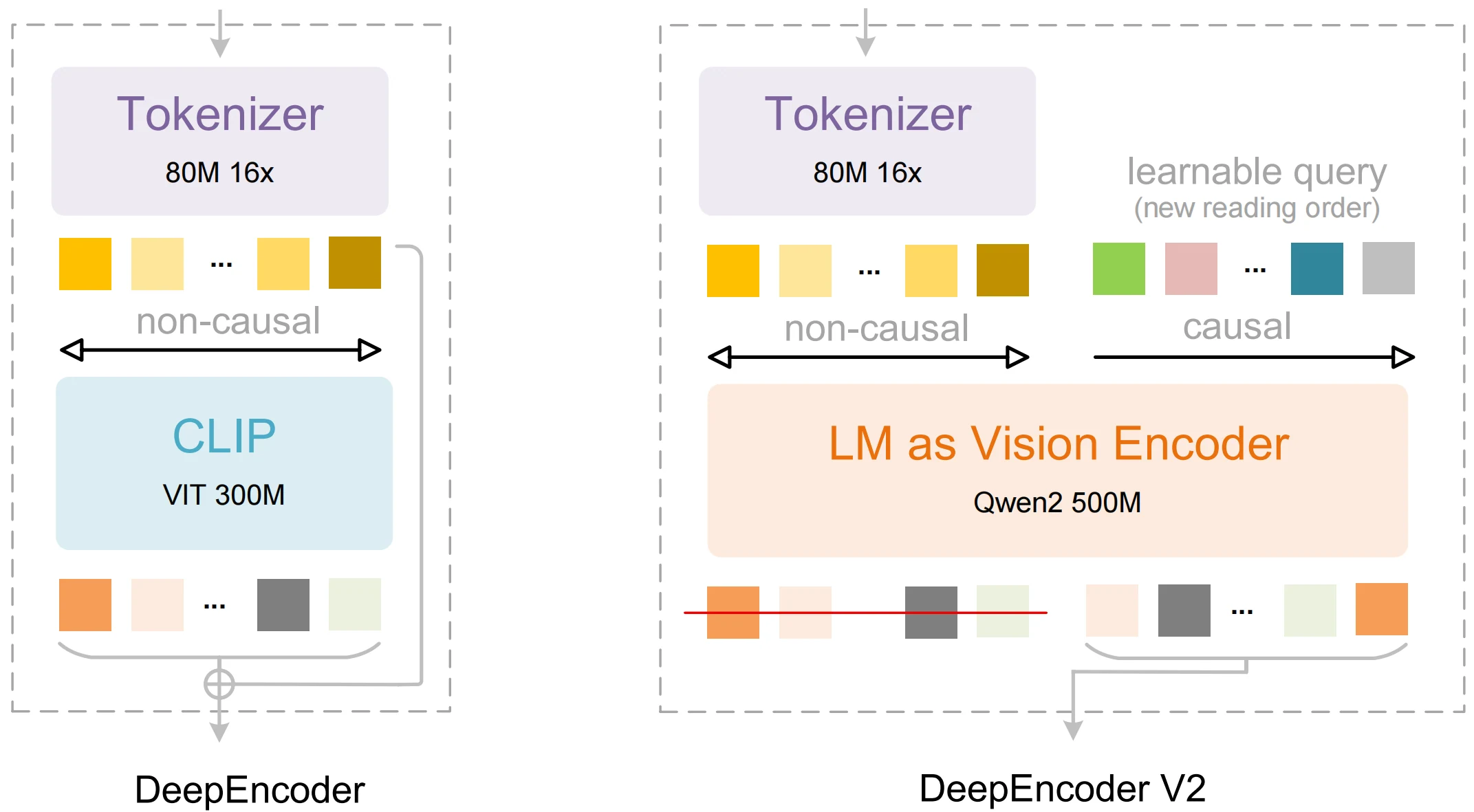
| DeepEncoder V2 | A vision encoder that mimics human reading order rather than fixed scanning. | Better structured extraction and layout awareness. |
| Visual Causal Flow | Global context comprehension before sequential decoding. | More accurate ordering in output for tables and multi-column text. |
| 3 B parameter design | Compact yet capable of advanced reasoning. | Lower resource footprint than many alternatives while competitive in accuracy. |
| Multimodal processing | Vision + language integration for OCR & interpretation. | Enables text, layout, and document-level semantics. |
From github
DeepSeek OCR 2‘s Ability
Accuracy
Overall character accuracy improves from 82.7% to 91.1% (+8.4%), and word accuracy from 75.0% to 85.9% (+10.9%).
On OmniDocBench v1.5, the Overall score reaches 91.09, improving by 3.73 points over v1.0.
Reading Order
Reading-order recognition becomes more reliable, with edit distance reduced from 0.085 to 0.057, indicating more accurate reconstruction of document logic.
Production Stability
Improvements carry into real deployments:
- Online user log duplication rate drops from 6.25% to 4.17%.
- PDF processing duplication rate drops from 3.69% to 2.88%.
These changes reflect fewer recognition and layout errors in production.
Efficiency
Complex pages are processed using only 256–1120 visual tokens.
While v1.0 maintains 60% accuracy at up to 20× compression, v2.0 goes further: on OmniDocBench, it surpasses GOT-OCR 2.0 using only 100 visual tokens versus 256.
From Reddit
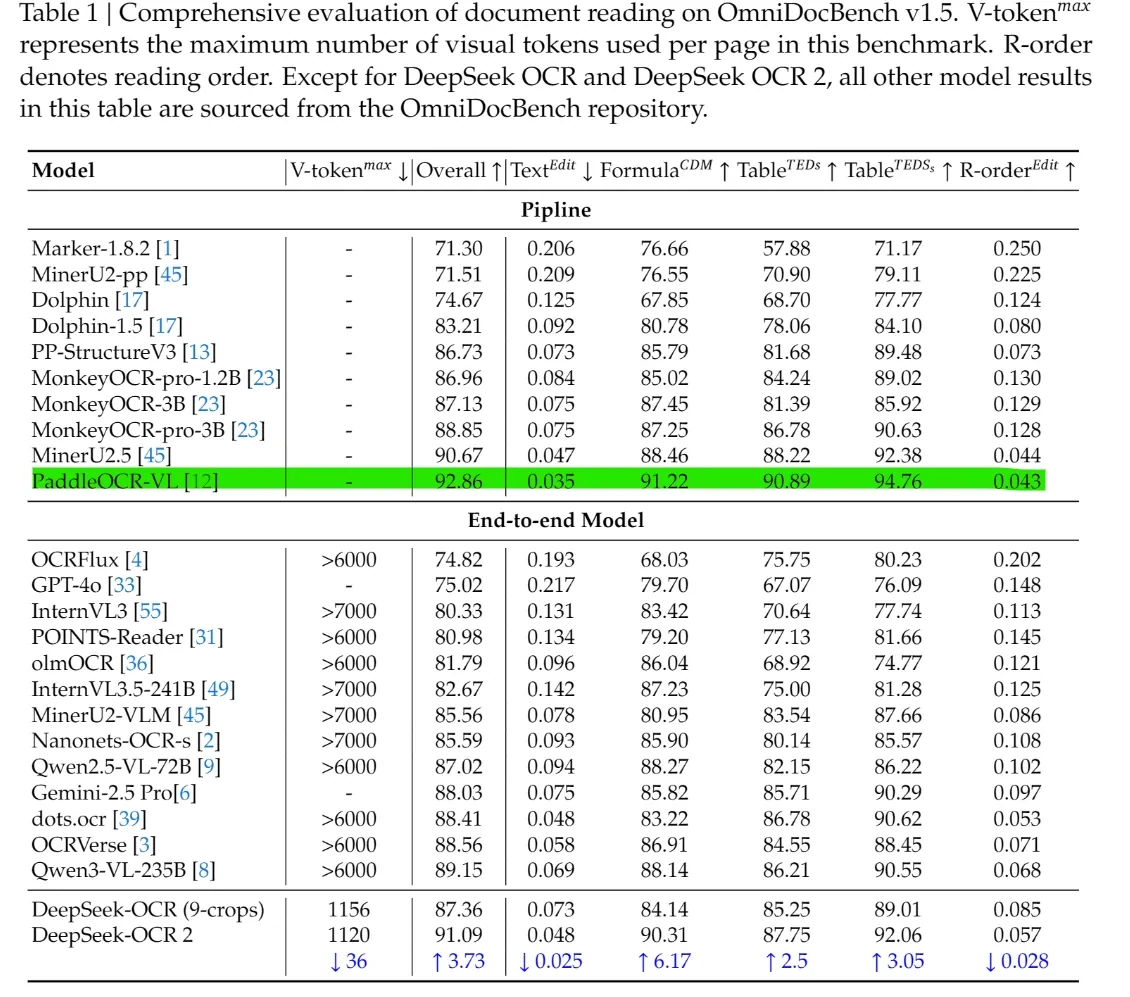
On OmniDocBench v1.5, DeepSeek-OCR 2 achieves an Overall score of 91.09, outperforming most end-to-end models such as GPT-4o, Gemini-2.5 Pro, and Qwen-VL. It also leads in structural dimensions, with lower Text^Edit and R-order^Edit and higher Formula and Table scores, demonstrating stronger layout, table, formula, and reading-order modeling than general VLMs.
Crucially, these results are obtained with only 1120 visual tokens, while most competing end-to-end models require more than 6000. This gap shows that DeepSeek-OCR 2 delivers higher document understanding accuracy under dramatically lower computational cost, combining benchmark leadership with practical deployability.
When to Choose DeepSeek-OCR 2?
Best suited for applications requiring document-level understanding, structured extraction, and workflow integration with multimodal AI systems.
Ideal use cases:
- Legal and financial document automation with layout integrity.
- Research paper ingestion and structured markup pipelines.
- Enterprise document indexing with reading-order preservation.
Limitations:
- Requires GPU resources for efficient inference.
- Handwriting extraction is not the primary focus (dedicated models may outperform).
How to Add OCR to Your Agent Stream with Predictable API Costs
Novita offers the lowest on-demand H100 pricing at $1.80/hr up to 30% cheaper than other providers with identical GPU performance.
Novita AI’s Spot mode is a cost-optimized GPU rental option that leverages the platform’s unused or idle GPU capacity. Unlike on-demand instances, which reserve dedicated hardware for guaranteed continuous use, Spot instances are interruptible—offered at significantly lower prices, typically 40–60% cheaper.
This pricing model works because Novita dynamically reallocates idle GPUs to short-term users instead of leaving them unused. By doing so, the platform improves overall infrastructure utilization efficiency, while developers benefit from much lower computational costs for flexible workloads.
Step 1: Console Entry
Launch the GPU interface and select Get Started to access deployment management.
Step 2: Package Selection
Locate PaddleOCR-VL in the template repository and begin installation sequence.
Step 3: Infrastructure Setup
Configure computing parameters including memory allocation, storage requirements, and network settings. Select Deploy to implement.
Step 4: Review and Create
Double-check your configuration details and cost summary. When satisfied, click Deploy to start the creation process.
Step 5: Wait for Creation
After initiating deployment, the system will automatically redirect you to the instance management page. Your instance will be created in the background.
Step 6: Monitor Download Progress
Track the image download progress in real-time. Your instance status will change from Pulling to Running once deployment is complete. You can view detailed progress by clicking the arrow icon next to your instance name.
Step 7: Environmental Access
Launch development space through Connect interface, then initialize Start Web Terminal.
With human-like reading order, strong structural accuracy, and ultra-low visual token usage, DeepSeek-OCR 2 outperforms general VLMs while remaining deployable. Paired with cost-efficient GPU infrastructure, it enables scalable, predictable OCR inside real agent pipelines.
Why do agents need DeepSeek-OCR 2 instead of basic OCR?
DeepSeek-OCR 2 provides layout and reading-order modeling, letting agents consume tables, PDFs, and multi-column documents as structured text.
How accurate is DeepSeek-OCR 2 in production scenarios?
DeepSeek-OCR 2 raises character accuracy to 91.1% and reduces reading-order errors, cutting duplication rates in live systems.
Why is DeepSeek-OCR 2 cheaper to run than general VLMs?
DeepSeek-OCR 2 reaches benchmark leadership using only 256–1120 visual tokens, far below the 6000+ tokens required by many VLMs.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing affordable and reliable GPU cloud for building and scaling.




{kind=link}