

Entwickler haben heute Schwierigkeiten, komplexe visuelle Dokumente in zuverlässige, strukturierte Eingaben für Agenten und LLM-Workflows umzuwandeln. Dieser Artikel erklärt, warum fortschrittliche OCR heute unerlässlich ist, wie DeepSeek-OCR 2 Layout- und Lesereihenfolge-Fehler behebt und wie Sie es in der Produktion mit vorhersehbaren, niedrigen API- und GPU-Kosten bereitstellen.
Warum moderne Modelle dringend fortschrittliche OCR benötigen?
Optische Zeichenerkennung (OCR) wandelt visuellen Text in maschinencodierten Text und strukturierte Darstellungen um und ermöglicht so Suche, Indizierung, semantische Analyse, Bearbeitung und Integration in sprachzentrierte Workflows. Traditionelle OCR konzentrierte sich auf die Extraktion auf Zeichenebene, aber aufkommende KI-Workflows erfordern umfassenderes Dokumentenverständnis, einschließlich Layout- und semantischem Kontext, um in Vision-Language-Systeme oder retrieval-augmented generation eingespeist zu werden. OCR bleibt unerlässlich für Dokumente, Formulare, Tabellen, Rechnungen, Forschungsarbeiten und Szenentext – Anwendungsfälle, die in der Branche allgegenwärtig sind.

Von analyticsvidhya
Probieren Sie DeepSeek OCR 2 jetzt aus!
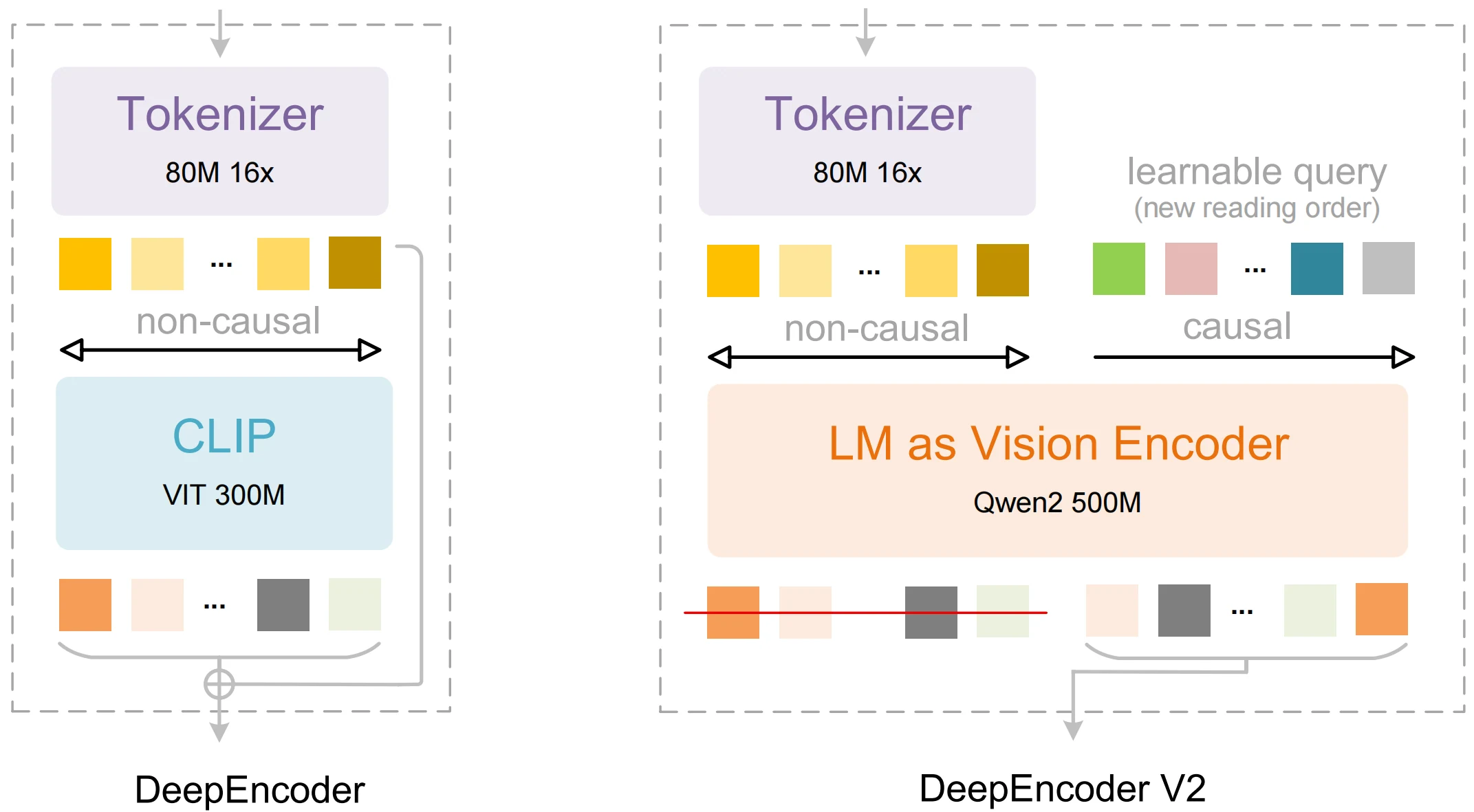
Kerninnovationen von DeepSeek OCR 2
| Innovation | Beschreibung | Auswirkung |
|---|---|---|
| DeepEncoder V2 | Ein Vision-Encoder, der die menschliche Lesereihenfolge statt festen Scannens nachahmt. | Bessere strukturierte Extraktion und Layout-Bewusstsein. |
| Visual Causal Flow | Globales Kontextverständnis vor sequenzieller Dekodierung. | Genauere Reihenfolge in der Ausgabe für Tabellen und mehrspaltigen Text. |
| 3-Milliarden-Parameter-Design | Kompakt, aber in der Lage zu fortgeschrittener Argumentation. | Geringerer Ressourcenbedarf als viele Alternativen bei wettbewerbsfähiger Genauigkeit. |
| Multimodale Verarbeitung | Integration von Vision und Sprache für OCR und Interpretation | Ermöglicht Text, Layout und dokumentenweite Semantik. |
Von github
Probieren Sie DeepSeek OCR 2 jetzt aus!
Fähigkeiten von DeepSeek OCR 2
Genauigkeit
Die gesamte Zeichengenauigkeit verbessert sich von 82,7 % auf 91,1 % (+8,4 %), die Wortgenauigkeit von 75,0 % auf 85,9 % (+10,9 %).
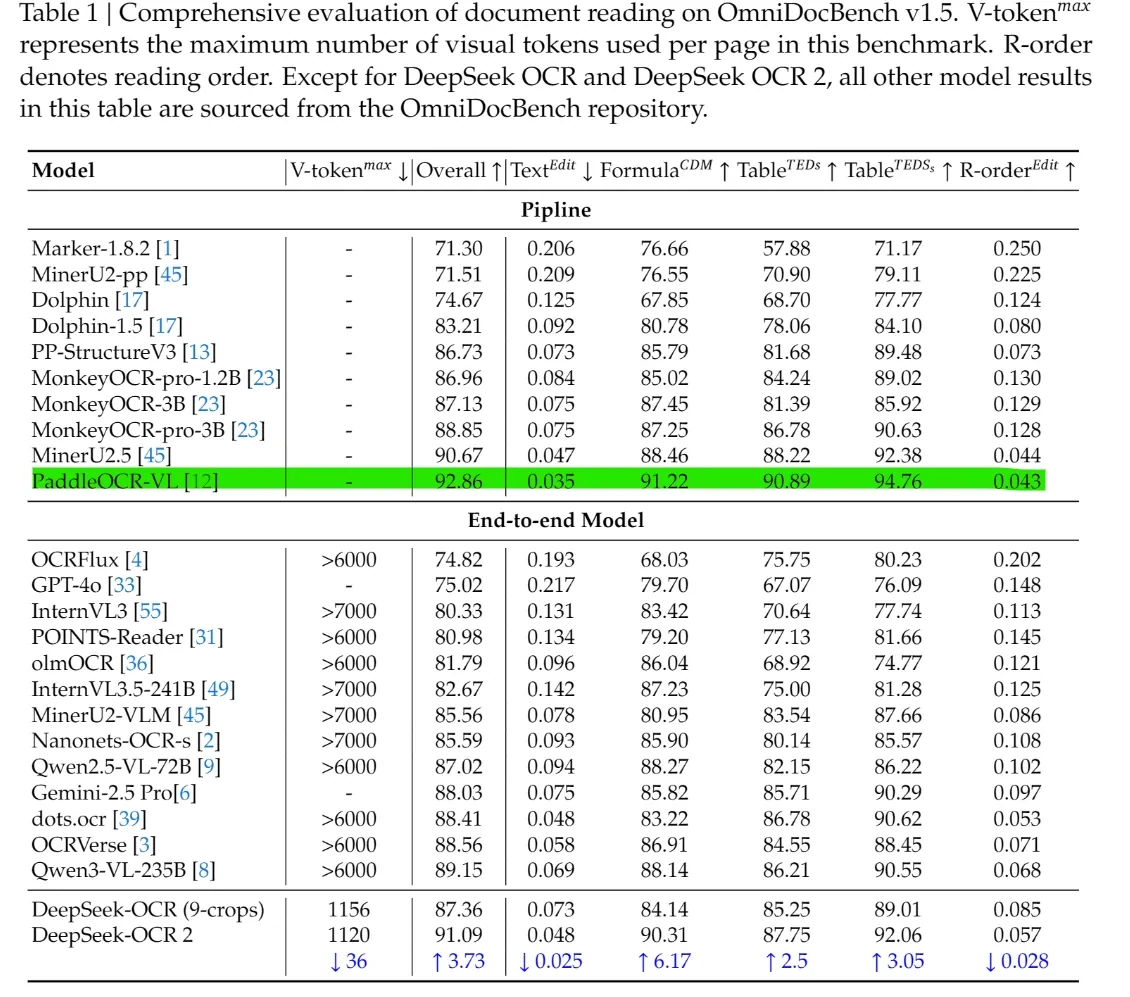
Auf OmniDocBench v1.5 erreicht der Gesamtscore 91,09, was eine Verbesserung um 3,73 Punkte gegenüber v1.0 bedeutet.
Lesereihenfolge
Die Erkennung der Lesereihenfolge wird zuverlässiger, die Editierdistanz sinkt von 0,085 auf 0,057, was eine genauere Rekonstruktion der Dokumentenlogik bedeutet.
Produktionsstabilität
Die Verbesserungen übertragen sich auf reale Bereitstellungen:
- Die Duplikationsrate von Online-Benutzerprotokollen sinkt von 6,25 % auf 4,17 %.
- Die Duplikationsrate bei PDF-Verarbeitung sinkt von 3,69 % auf 2,88 %.
Diese Veränderungen spiegeln weniger Erkennungs- und Layoutfehler in der Produktion wider.
Effizienz
Komplexe Seiten werden mit nur 256–1120 visuellen Tokens verarbeitet.
Während v1.0 eine Genauigkeit von 60 % bei bis zu 20-facher Komprimierung beibehält, geht v2.0 noch weiter: Auf OmniDocBench übertrifft es GOT-OCR 2.0 mit nur 100 visuellen Tokens im Vergleich zu 256.
Von Reddit
Auf OmniDocBench v1.5 erreicht DeepSeek-OCR 2 einen Gesamtscore von 91,09 und übertrifft damit die meisten End-to-End-Modelle wie GPT-4o, Gemini-2.5 Pro und Qwen-VL. Es führt auch in strukturellen Dimensionen, mit niedrigeren Text^Edit- und R-order^Edit-Werten und höheren Formel- und Tabellen-Scores, was ein stärkeres Modellierung von Layout, Tabellen, Formeln und Lesereihenfolge im Vergleich zu allgemeinen VLMs demonstriert.
Entscheidend ist, dass diese Ergebnisse mit nur 1120 visuellen Tokens erzielt werden, während die meisten konkurrierenden End-to-End-Modelle mehr als 6000 benötigen. Diese Lücke zeigt, dass DeepSeek-OCR 2 eine höhere Dokumentenverständnisgenauigkeit bei deutlich niedrigeren Rechenkosten bietet und Benchmark-Führung mit praktischer Einsetzbarkeit kombiniert.
Probieren Sie DeepSeek OCR 2 jetzt aus!
Wann sollten Sie DeepSeek-OCR 2 wählen?
Am besten geeignet für Anwendungen, die dokumentenweites Verständnis, strukturierte Extraktion und Workflow-Integration mit multimodalen KI-Systemen erfordern.
Ideale Anwendungsfälle:
- Automatisierung von Rechts- und Finanzdokumenten mit Layout-Integrität.
- Aufnahme von Forschungsarbeiten und strukturierte Markup-Pipelines.
- Unternehmensweite Dokumentenindizierung mit Erhaltung der Lesereihenfolge.
Einschränkungen:
- Erfordert GPU-Ressourcen für effiziente Inferenz.
- Die Extraktion von Handschrift ist nicht der primäre Fokus (spezialisierte Modelle können hier besser abschneiden).
So fügen Sie OCR mit vorhersehbaren API-Kosten zu Ihrem Agenten-Workflow hinzu
Novita bietet die niedrigsten On-Demand-H100-Preise von 1,80 $/Stunde, bis zu 30 % günstiger als andere Anbieter mit identischer GPU-Leistung.
Der Spot-Modus von Novita AI ist eine kostenoptimierte GPU-Mietoption, die die ungenutzte oder Leerlauf-GPU-Kapazität der Plattform nutzt. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für garantierte kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – sie werden zu deutlich niedrigeren Preisen angeboten, typischerweise 40–60 % günstiger.
Dieses Preismodell funktioniert, weil Novita ungenutzte GPUs dynamisch an Kurzzeitnutzer neu zuweist, anstatt sie ungenutzt zu lassen. Dadurch verbessert die Plattform die gesamte Infrastrukturnutzungseffizienz, während Entwickler von deutlich niedrigeren Rechenkosten für flexible Workloads profitieren.
Probieren Sie DeepSeek OCR 2 jetzt aus!
Schritt 1: Konsolenzugang
Starten Sie die GPU-Oberfläche und wählen Sie „Get Started“, um auf das Bereitstellungsmanagement zuzugreifen.
Schritt 2: Paketauswahl
Suchen Sie PaddleOCR-VL im Vorlagen-Repository und starten Sie den Installationsvorgang.
Schritt 3: Infrastruktur-Einrichtung
Konfigurieren Sie die Rechenparameter, einschließlich Speicherzuweisung, Speicheranforderungen und Netzwerkeinstellungen. Wählen Sie „Deploy“, um die Einrichtung durchzuführen.
Schritt 4: Überprüfen und Erstellen
Überprüfen Sie Ihre Konfigurationsdetails und die Kostenübersicht noch einmal. Wenn Sie zufrieden sind, klicken Sie auf „Deploy“, um den Erstellungsprozess zu starten.
Schritt 5: Auf die Erstellung warten
Nach dem Starten der Bereitstellung werden Sie automatisch zur Instanzverwaltungsseite weitergeleitet. Ihre Instanz wird im Hintergrund erstellt.
Schritt 6: Download-Fortschritt überwachen
Verfolgen Sie den Download-Fortschritt des Images in Echtzeit. Der Status Ihrer Instanz ändert sich von „Pulling“ zu „Running“, sobald die Bereitstellung abgeschlossen ist. Detaillierte Fortschritte können Sie durch Klicken auf das Pfeilsymbol neben dem Instanznamen einsehen.
Schritt 7: Zugriff auf die Umgebung
Starten Sie den Entwicklungsbereich über die „Connect“-Oberfläche und initialisieren Sie dann das Start-Web-Terminal.
Mit einer menschenähnlichen Lesereihenfolge, hoher struktureller Genauigkeit und extrem geringer Nutzung visueller Tokens übertrifft DeepSeek-OCR 2 allgemeine VLMs und bleibt gleichzeitig einsetzbar. In Kombination mit kosteneffizienter GPU-Infrastruktur ermöglicht es skalierbare, vorhersehbare OCR in echten Agenten-Pipelines.
Warum brauchen Agenten DeepSeek-OCR 2 statt einfacher OCR?
DeepSeek-OCR 2 bietet Layout- und Lesereihenfolge-Modellierung, sodass Agenten Tabellen, PDFs und mehrspaltige Dokumente als strukturierten Text verarbeiten können.
Wie genau ist DeepSeek-OCR 2 in Produktionsszenarien?
DeepSeek-OCR 2 erhöht die Zeichengenauigkeit auf 91,1 % und reduziert Lesereihenfolge-Fehler, wodurch Duplikationsraten in Live-Systemen gesenkt werden.
Warum ist DeepSeek-OCR 2 günstiger in der Ausführung als allgemeine VLMs?
DeepSeek-OCR 2 erreicht Benchmark-Führung mit nur 256–1120 visuellen Tokens, weit unter den 6000+ Tokens, die viele VLMs benötigen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bereitstellt.




{kind=link}