

يواجه المطورون اليوم صعوبة في تحويل المستندات البصرية المعقدة إلى مدخلات موثوقة ومنظمة لسير عمل الوكلاء ونماذج اللغة الكبيرة (LLM). يشرح هذا المقال لماذا أصبح التعرف الضوئي المتقدم على الحروف (OCR) إلزاميًا الآن، وكيف يحل DeepSeek-OCR 2 مشاكل فشل التخطيط وترتيب القراءة، وكيفية نشره في الإنتاج مع تكاليف API و GPU منخفضة وقابلة للتنبؤ.
لماذا تحتاج النماذج الحديثة بشكل عاجل إلى OCR متقدم؟
يحول التعرف الضوئي على الحروف (OCR) النص المرئي إلى نص مشفر آليًا وتمثيلات منظمة، مما يتيح البحث والفهرسة والتحليل الدلالي والتحرير والتكامل مع سير عمل المركزة على اللغة. ركز OCR التقليدي على الاستخراج على مستوى الأحرف، لكن سير عمل الذكاء الاصطناعي الناشئة تتطلب فهمًا أغنى للمستندات، بما في ذلك التخطيط والسياق الدلالي لتغذية أنظمة الرؤية واللغة أو التوليد المعزز بالاسترجاع. يظل OCR ضروريًا للمستندات والنماذج والجداول والفواتير وأوراق البحث والنص المشهدي — حالات استخدام منتشرة في جميع أنحاء الصناعة.

الابتكارات الأساسية في DeepSeek OCR 2
| الابتكار | الوصف | الأثر |
|---|---|---|
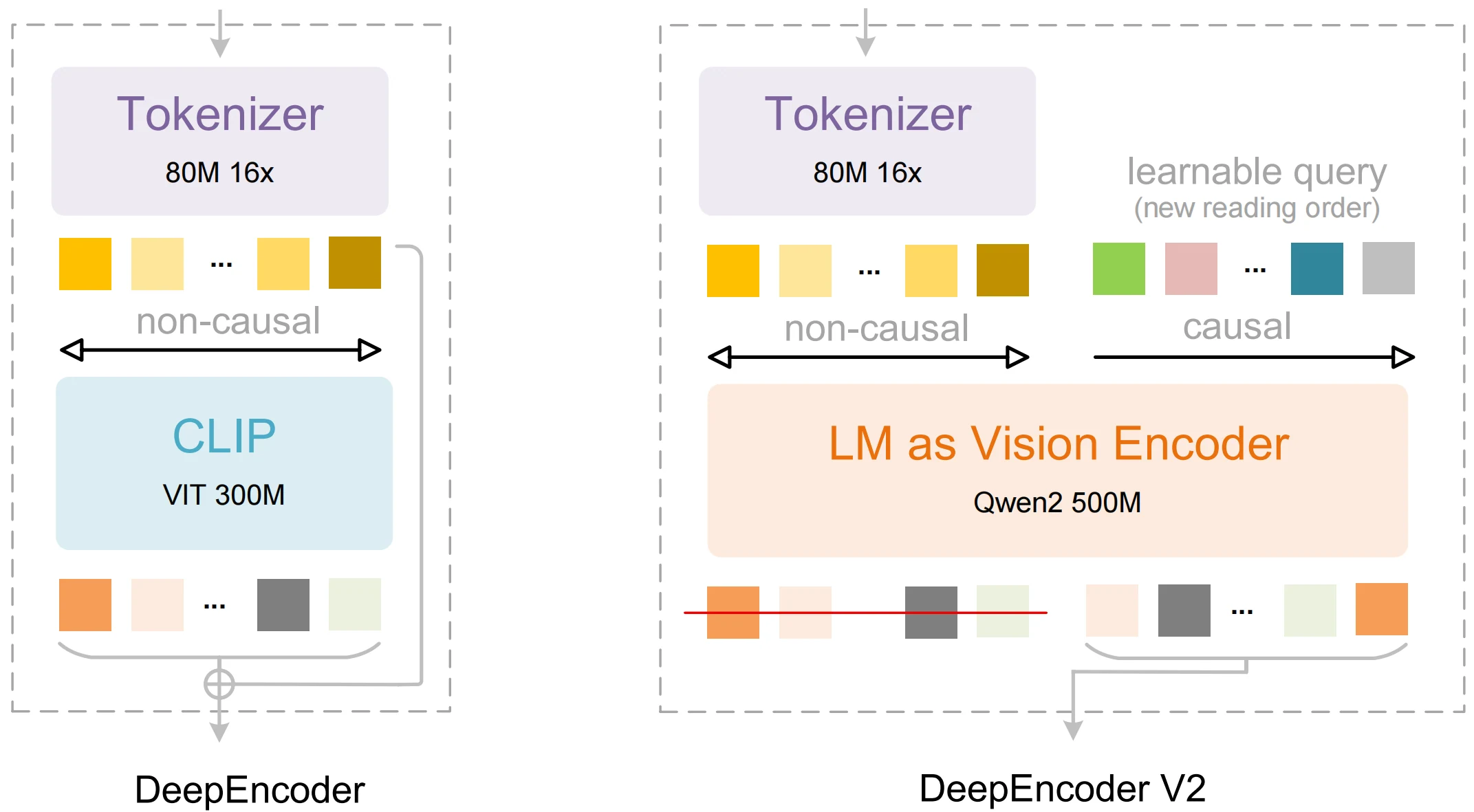
| DeepEncoder V2 | مشفر بصري يحاكي ترتيب القراءة البشري بدلاً من المسح الثابت. | استخراج منظم أفضل ووعي بالتخطيط. |
| Visual Causal Flow | فهم السياق العام قبل فك التشفير المتسلسل. | ترتيب أكثر دقة في المخرجات للجداول والنص متعدد الأعمدة. |
| تصميم بمعاملات 3 مليار | مدمج ولكنه قادر على الاستدلال المتقدم. | بصمة موارد أقل من العديد من البدائل مع منافسة في الدقة. |
| المعالجة متعددة الوسائط | تكامل الرؤية + اللغة لـ OCR والتفسير. | يتيح النص والتخطيط والدلالات على مستوى المستند. |
من github
قدرات DeepSeek OCR 2
الدقة
ينخفض دقة الأحرف الكلية من 82.7% إلى 91.1% (+8.4%)، ودقة الكلمات من 75.0% إلى 85.9% (+10.9%).
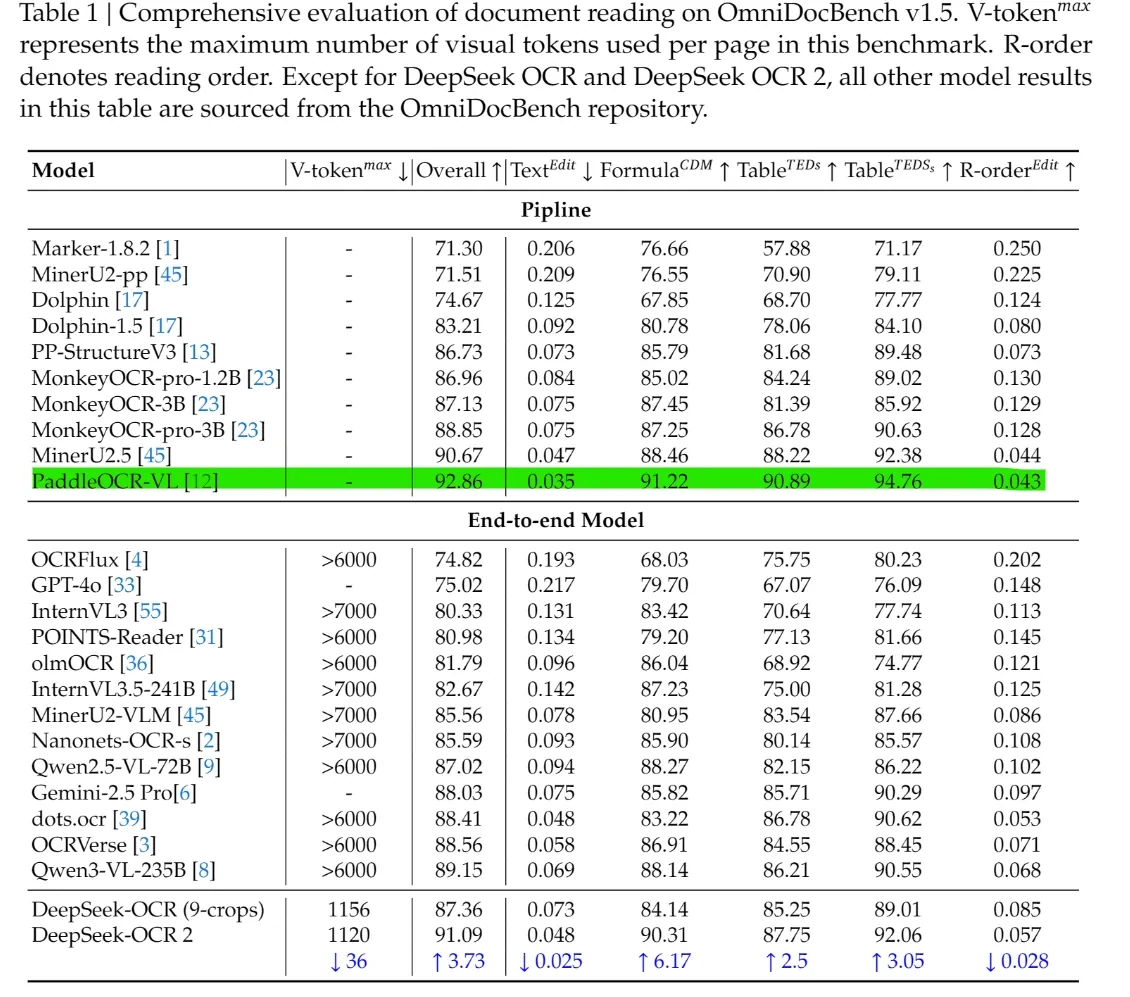
على منصة OmniDocBench v1.5، يصل الدرجة الكلية إلى 91.09، بتحسين قدره 3.73 نقاط مقارنة بالإصدار v1.0.
ترتيب القراءة
يصبح التعرف على ترتيب القراءة أكثر موثوقية، مع انخفاض مسافة التحرير من 0.085 إلى 0.057، مما يشير إلى إعادة بناء أكثر دقة لمنطق المستند.
استقرار الإنتاج
تنتقل التحسينات إلى النشرات الفعلية:
- ينخفض معدل تكرار سجلات المستخدمين عبر الإنترنت من 6.25% إلى 4.17%.
- ينخفض معدل تكرار معالجة ملفات PDF من 3.69% إلى 2.88%.
تعكس هذه التغييرات عددًا أقل من أخطاء التعرف والتخطيط في الإنتاج.
الكفاءة
يتم معالجة الصفحات المعقدة باستخدام 256 إلى 1120 رمزًا مرئيًا فقط.
بينما يحافظ الإصدار v1.0 على دقة 60% عند ضغط يصل إلى 20 ضعفًا، يتجاوز الإصدار v2.0 ذلك: على منصة OmniDocBench، يتفوق على GOT-OCR 2.0 باستخدام 100 رمز مرئي فقط مقابل 256.
من Reddit
على منصة OmniDocBench v1.5، يحقق DeepSeek-OCR 2 درجة كلية تبلغ 91.09، متفوقًا على معظم النماذج من البداية إلى النهاية مثل GPT-4o و Gemini-2.5 Pro و Qwen-VL. كما يتقدم في الأبعاد الهيكلية، مع درجات أقل لـ Text^Edit و R-order^Edit ودرجات أعلى للصيغ والجداول، مما يظهر نمذجة أقوى للتخطيط والجداول والصيغ وترتيب القراءة مقارنة بنماذج الرؤية واللغة العامة (VLMs).
الأهم من ذلك، تم الحصول على هذه النتائج باستخدام 1120 رمزًا مرئيًا فقط، بينما تتطلب معظم النماذج المنافسة من البداية إلى النهاية أكثر من 6000. يظهر هذا الفجوة أن DeepSeek-OCR 2 يقدم دقة أعلى لفهم المستندات بتكلفة حسابية أقل بشكل كبير، مع دمج القيادة في المعايير مع القابلية للنشر العملية.
متى تختار DeepSeek-OCR 2؟
الأفضل للتطبيقات التي تتطلب فهمًا على مستوى المستند، واستخراجًا منظمًا، وتكامل سير العمل مع أنظمة الذكاء الاصطناعي متعددة الوسائط.
حالات الاستخدام المثالية:
- أتمتة المستندات القانونية والمالية مع سلامة التخطيط.
- استيعاب أوراق البحث ومسارات التوصيف الهيكلي المنظمة.
- فهرسة مستندات المؤسسات مع الحفاظ على ترتيب القراءة.
القيود:
- يتطلب موارد GPU للاستدلال الفعال.
- استخراج الكتابة اليدوية ليس التركيز الأساسي (قد تتفوق النماذج المخصصة عليه).
كيفية إضافة OCR إلى تدفق الوكلاء الخاص بك مع تكاليف API قابلة للتنبؤ
تقدم Novita أدنى أسعار لـ H100 عند الطلب بسعر 1.80 دولارًا في الساعة، أرخص بنسبة تصل إلى 30% من مقدمي الخدمة الآخرين بأداء GPU متطابق.
وضع Spot الخاص بـ Novita AI هو خيار تأجير GPU مُحسّن التكلفة يستخدم سعة GPU غير المستخدمة أو الخاملة للمنصة. على عكس الحالات عند الطلب، التي تحجز أجهزة مخصصة للاستخدام المستمر المضمون، فإن حالات Spot قابلة للقطع — معروضة بأسعار أقل بشكل كبير، عادةً أرخص بنسبة 40–60%.
يعمل نموذج التسعير هذا لأن Novita تعيد تخصيص GPUs الخاملة ديناميكيًا للمستخدمين على المدى القصير بدلاً من تركها غير مستخدمة. من خلال القيام بذلك، تعمل المنصة على تحسين كفاءة استخدام البنية التحتية بشكل عام، بينما يستفيد المطورون من تكاليف حسابية أقل بكثير لأحمال العمل المرنة.
الخطوة 1: الدخول إلى وحدة التحكم
أطلق واجهة GPU واختر “ابدأ” للوصول إلى إدارة النشر.
الخطوة 2: اختيار الحزمة
ابحث عن PaddleOCR-VL في مستودع القوالب وابدأ تسلسل التثبيت.
الخطوة 3: إعداد البنية التحتية
اضبط معلمات الحساب بما في ذلك تخصيص الذاكرة ومتطلبات التخزين وإعدادات الشبكة. اختر “نشر” للتنفيذ.
الخطوة 4: المراجعة والإنشاء
تحقق مرة أخرى من تفاصيل التكوين الخاصة بك وملخص التكاليف. عندما تكون راضيًا، انقر على “نشر” لبدء عملية الإنشاء.
الخطوة 5: انتظر الإنشاء
بعد بدء النشر، سيقوم النظام بإعادة توجيهك تلقائيًا إلى صفحة إدارة المثيل. سيتم إنشاء مثيلك في الخلفية.
الخطوة 6: مراقبة تقدم التنزيل
تتبع تقدم تنزيل الصورة في الوقت الفعلي. سيتم تغيير حالة مثيلك من “سحب” إلى “قيد التشغيل” بمجرد اكتمال النشر. يمكنك عرض التقدم التفصيلي بالنقر على أيقونة السهم بجانب اسم مثيلك.
الخطوة 7: الوصول إلى البيئة
أطلق مساحة التطوير من خلال واجهة “اتصال”، ثم قم بتهيئة “بدء محطة الويب”.
مع ترتيب قراءة شبيه بالبشر، ودقة هيكلية قوية، واستخدام منخفض جدًا للرموز المرئية، يتفوق DeepSeek-OCR 2 على نماذج الرؤية واللغة العامة (VLMs) مع البقاء قابلًا للنشر. عند دمجه مع بنية GPU تحتية فعالة من حيث التكلفة، يتيح OCR قابل للتوسعة وقابل للتنبؤ داخل مسارات الوكلاء الفعلية.
لماذا يحتاج الوكلاء إلى DeepSeek-OCR 2 بدلاً من OCR الأساسي؟ يوفر DeepSeek-OCR 2 نمذجة للتخطيط وترتيب القراءة، مما يسمح للوكلاء باستهلاك الجداول وملفات PDF والمستندات متعددة الأعمدة كنص منظم.
ما مدى دقة DeepSeek-OCR 2 في سيناريوهات الإنتاج؟ يرفع DeepSeek-OCR 2 دقة الأحرف إلى 91.1% ويقلل من أخطاء ترتيب القراءة، مما يخفض معدلات التكرار في الأنظمة المباشرة.
لماذا DeepSeek-OCR 2 أرخص في التشغيل من نماذج الرؤية واللغة العامة (VLMs)؟ يصل DeepSeek-OCR 2 إلى قيادة المعايير باستخدام 256 إلى 1120 رمزًا مرئيًا فقط، أقل بكثير من الـ 6000+ رمز المطلوبة من قبل العديد من نماذج VLMs.
Novita AI هي منصة سحابة للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، مع توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسعة.




{kind=link}